 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
AHD ConvNet for Speech Emotion Classification
Jun 21, 2022
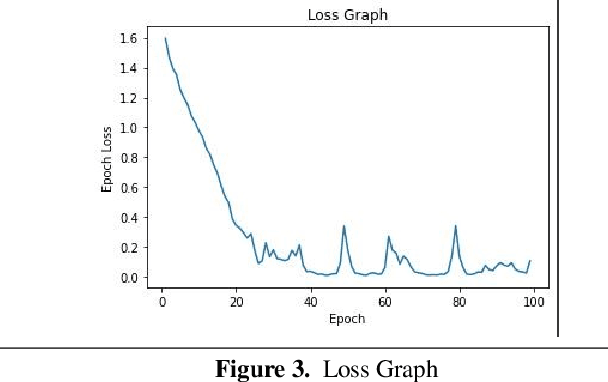
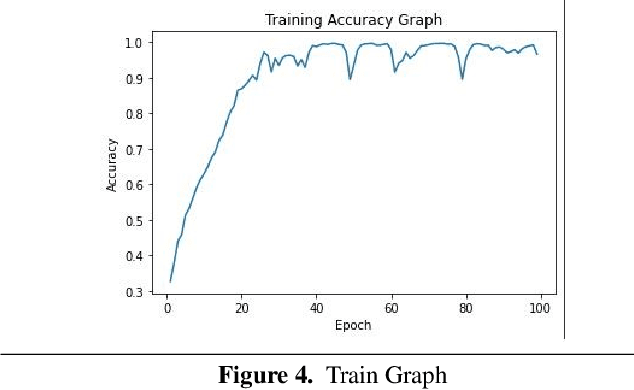
Accomplishments in the field of artificial intelligence are utilized in the advancement of computing and making of intelligent machines for facilitating mankind and improving user experience. Emotions are rudimentary for people, affecting thinking and ordinary exercises like correspondence, learning and direction. Speech emotion recognition is domain of interest in this regard and in this work, we propose a novel mel spectrogram learning approach in which our model uses the datapoints to learn emotions from the given wav form voice notes in the popular CREMA-D dataset. Our model uses log mel-spectrogram as feature with number of mels = 64. It took less training time compared to other approaches used to address the problem of emotion speech recognition.
Object Representations as Fixed Points: Training Iterative Refinement Algorithms with Implicit Differentiation
Jul 02, 2022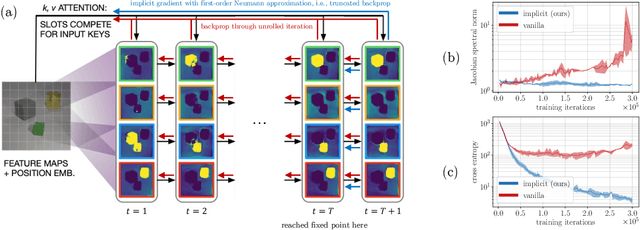

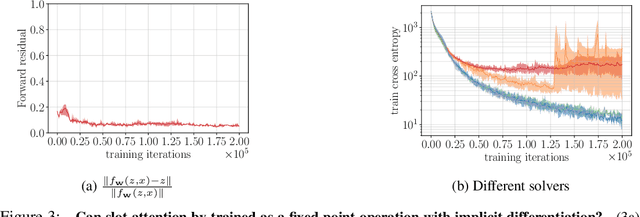

Iterative refinement -- start with a random guess, then iteratively improve the guess -- is a useful paradigm for representation learning because it offers a way to break symmetries among equally plausible explanations for the data. This property enables the application of such methods to infer representations of sets of entities, such as objects in physical scenes, structurally resembling clustering algorithms in latent space. However, most prior works differentiate through the unrolled refinement process, which can make optimization challenging. We observe that such methods can be made differentiable by means of the implicit function theorem, and develop an implicit differentiation approach that improves the stability and tractability of training by decoupling the forward and backward passes. This connection enables us to apply advances in optimizing implicit layers to not only improve the optimization of the slot attention module in SLATE, a state-of-the-art method for learning entity representations, but do so with constant space and time complexity in backpropagation and only one additional line of code.
A Deep Model for Partial Multi-Label Image Classification with Curriculum Based Disambiguation
Jul 06, 2022
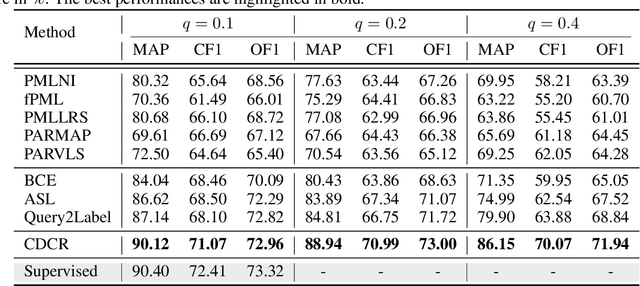
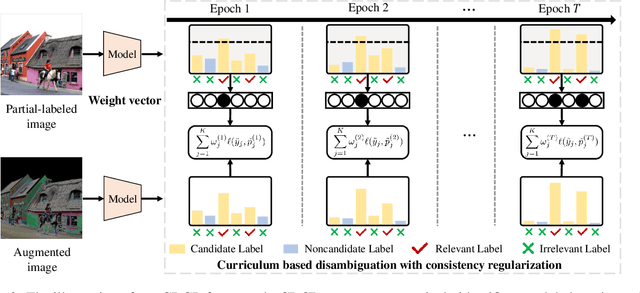
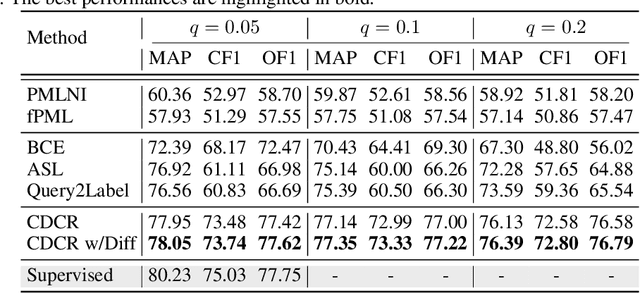
In this paper, we study the partial multi-label (PML) image classification problem, where each image is annotated with a candidate label set consists of multiple relevant labels and other noisy labels. Existing PML methods typically design a disambiguation strategy to filter out noisy labels by utilizing prior knowledge with extra assumptions, which unfortunately is unavailable in many real tasks. Furthermore, because the objective function for disambiguation is usually elaborately designed on the whole training set, it can be hardly optimized in a deep model with SGD on mini-batches. In this paper, for the first time we propose a deep model for PML to enhance the representation and discrimination ability. On one hand, we propose a novel curriculum based disambiguation strategy to progressively identify ground-truth labels by incorporating the varied difficulties of different classes. On the other hand, a consistency regularization is introduced for model retraining to balance fitting identified easy labels and exploiting potential relevant labels. Extensive experimental results on the commonly used benchmark datasets show the proposed method significantly outperforms the SOTA methods.
A Two-Stage Bayesian Optimisation for Automatic Tuning of an Unscented Kalman Filter for Vehicle Sideslip Angle Estimation
Jun 30, 2022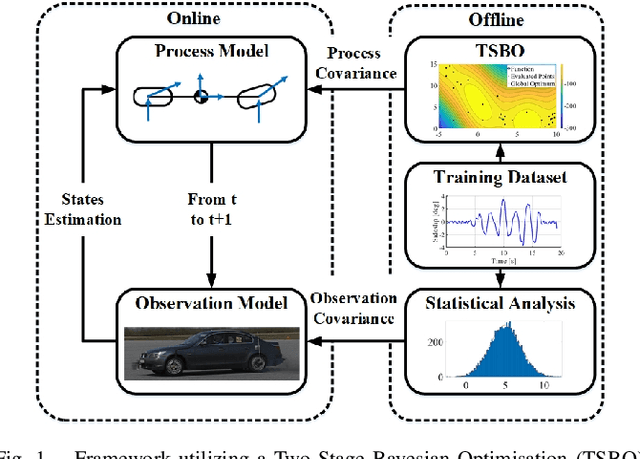
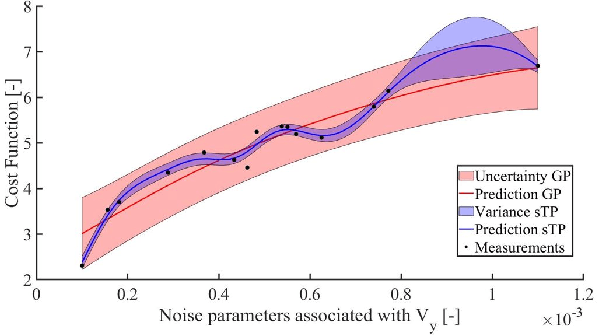
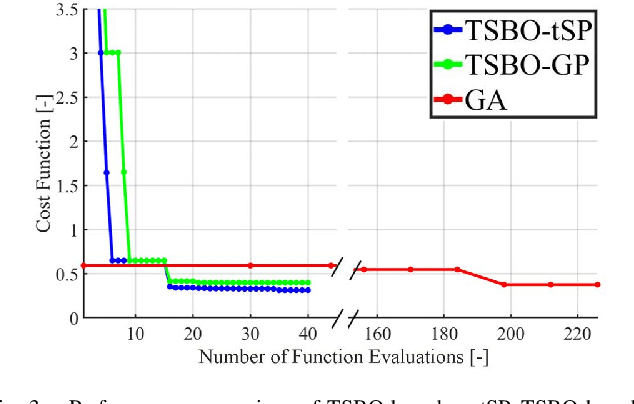
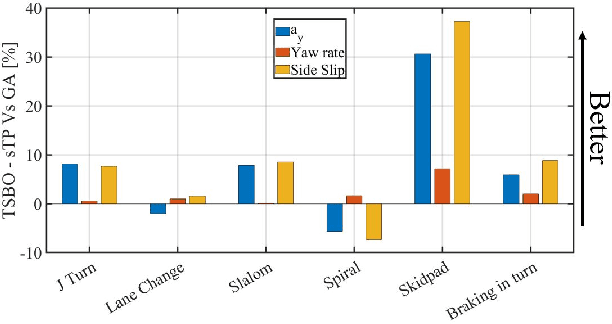
This paper presents a novel methodology to auto-tune an Unscented Kalman Filter (UKF). It involves using a Two-Stage Bayesian Optimisation (TSBO), based on a t-Student Process to optimise the process noise parameters of a UKF for vehicle sideslip angle estimation. Our method minimises performance metrics, given by the average sum of the states' and measurement' estimation error for various vehicle manoeuvres covering a wide range of vehicle behaviour. The predefined cost function is minimised through a TSBO which aims to find a location in the feasible region that maximises the probability of improving the current best solution. Results on an experimental dataset show the capability to tune the UKF in 79.9% less time than using a genetic algorithm (GA) and the overall capacity to improve the estimation performance in an experimental test dataset of 9.9% to the current state-of-the-art GA.
Liver Segmentation using Turbolift Learning for CT and Cone-beam C-arm Perfusion Imaging
Jul 20, 2022
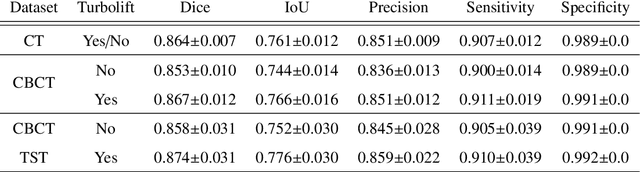

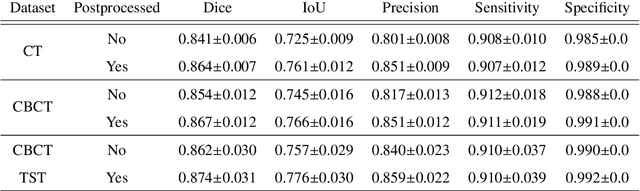
Model-based reconstruction employing the time separation technique (TST) was found to improve dynamic perfusion imaging of the liver using C-arm cone-beam computed tomography (CBCT). To apply TST using prior knowledge extracted from CT perfusion data, the liver should be accurately segmented from the CT scans. Reconstructions of primary and model-based CBCT data need to be segmented for proper visualisation and interpretation of perfusion maps. This research proposes Turbolift learning, which trains a modified version of the multi-scale Attention UNet on different liver segmentation tasks serially, following the order of the trainings CT, CBCT, CBCT TST - making the previous trainings act as pre-training stages for the subsequent ones - addressing the problem of limited number of datasets for training. For the final task of liver segmentation from CBCT TST, the proposed method achieved an overall Dice scores of 0.874$\pm$0.031 and 0.905$\pm$0.007 in 6-fold and 4-fold cross-validation experiments, respectively - securing statistically significant improvements over the model, which was trained only for that task. Experiments revealed that Turbolift not only improves the overall performance of the model but also makes it robust against artefacts originating from the embolisation materials and truncation artefacts. Additionally, in-depth analyses confirmed the order of the segmentation tasks. This paper shows the potential of segmenting the liver from CT, CBCT, and CBCT TST, learning from the available limited training data, which can possibly be used in the future for the visualisation and evaluation of the perfusion maps for the treatment evaluation of liver diseases.
Inner Monologue: Embodied Reasoning through Planning with Language Models
Jul 12, 2022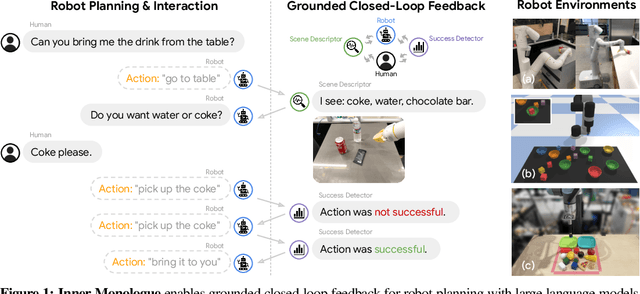
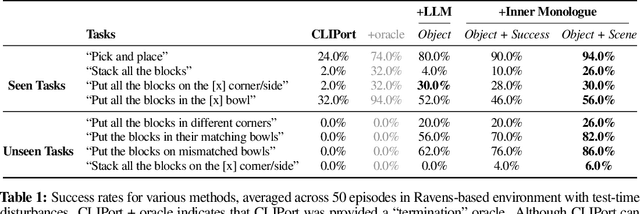


Recent works have shown how the reasoning capabilities of Large Language Models (LLMs) can be applied to domains beyond natural language processing, such as planning and interaction for robots. These embodied problems require an agent to understand many semantic aspects of the world: the repertoire of skills available, how these skills influence the world, and how changes to the world map back to the language. LLMs planning in embodied environments need to consider not just what skills to do, but also how and when to do them - answers that change over time in response to the agent's own choices. In this work, we investigate to what extent LLMs used in such embodied contexts can reason over sources of feedback provided through natural language, without any additional training. We propose that by leveraging environment feedback, LLMs are able to form an inner monologue that allows them to more richly process and plan in robotic control scenarios. We investigate a variety of sources of feedback, such as success detection, scene description, and human interaction. We find that closed-loop language feedback significantly improves high-level instruction completion on three domains, including simulated and real table top rearrangement tasks and long-horizon mobile manipulation tasks in a kitchen environment in the real world.
Unsupervised Symbolic Music Segmentation using Ensemble Temporal Prediction Errors
Jul 02, 2022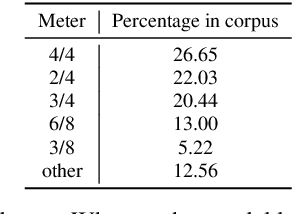
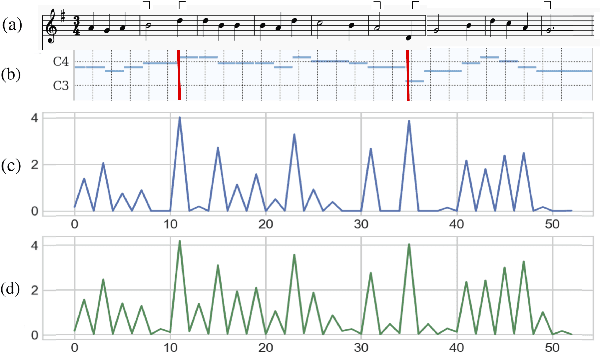
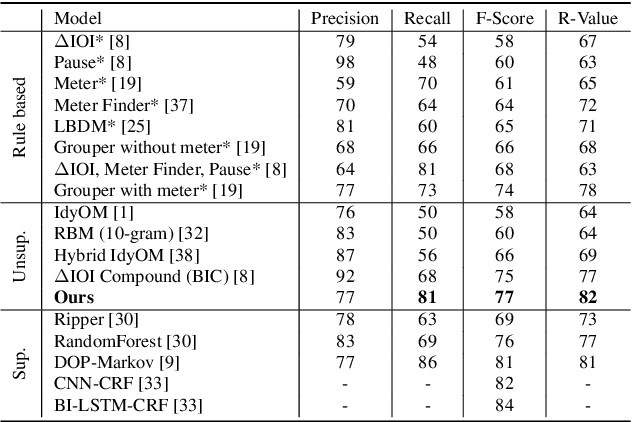
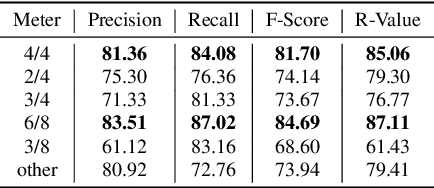
Symbolic music segmentation is the process of dividing symbolic melodies into smaller meaningful groups, such as melodic phrases. We proposed an unsupervised method for segmenting symbolic music. The proposed model is based on an ensemble of temporal prediction error models. During training, each model predicts the next token to identify musical phrase changes. While at test time, we perform a peak detection algorithm to select segment candidates. Finally, we aggregate the predictions of each of the models participating in the ensemble to predict the final segmentation. Results suggest the proposed method reaches state-of-the-art performance on the Essen Folksong dataset under the unsupervised setting when considering F-Score and R-value. We additionally provide an ablation study to better assess the contribution of each of the model components to the final results. As expected, the proposed method is inferior to the supervised setting, which leaves room for improvement in future research considering closing the gap between unsupervised and supervised methods.
GACT: Activation Compressed Training for General Architectures
Jun 28, 2022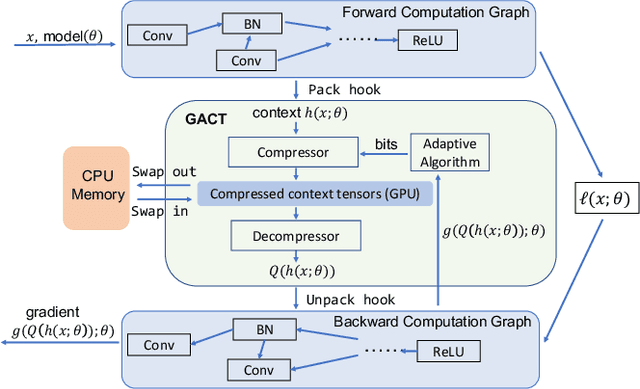
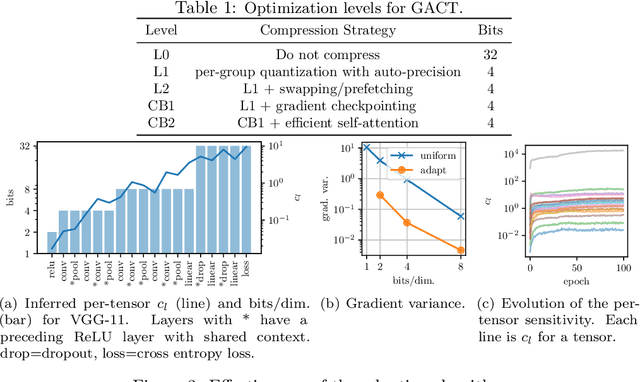

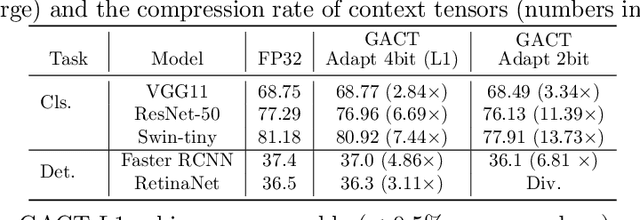
Training large neural network (NN) models requires extensive memory resources, and Activation Compressed Training (ACT) is a promising approach to reduce training memory footprint. This paper presents GACT, an ACT framework to support a broad range of machine learning tasks for generic NN architectures with limited domain knowledge. By analyzing a linearized version of ACT's approximate gradient, we prove the convergence of GACT without prior knowledge on operator type or model architecture. To make training stable, we propose an algorithm that decides the compression ratio for each tensor by estimating its impact on the gradient at run time. We implement GACT as a PyTorch library that readily applies to any NN architecture. GACT reduces the activation memory for convolutional NNs, transformers, and graph NNs by up to 8.1x, enabling training with a 4.2x to 24.7x larger batch size, with negligible accuracy loss.
MANI-Rank: Multiple Attribute and Intersectional Group Fairness for Consensus Ranking
Jul 20, 2022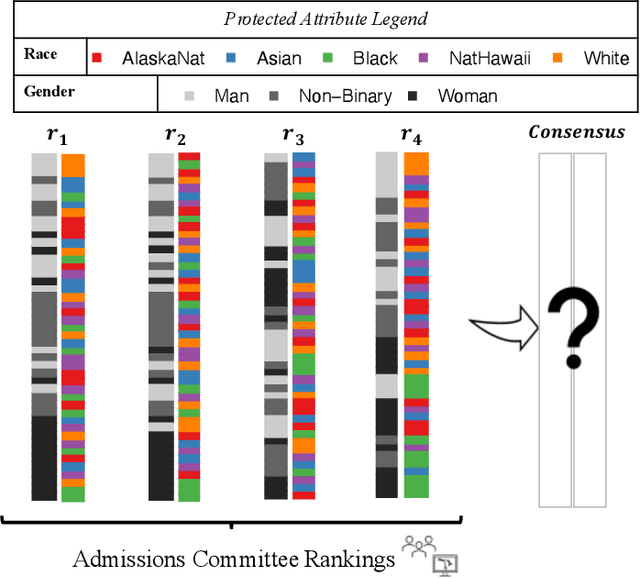

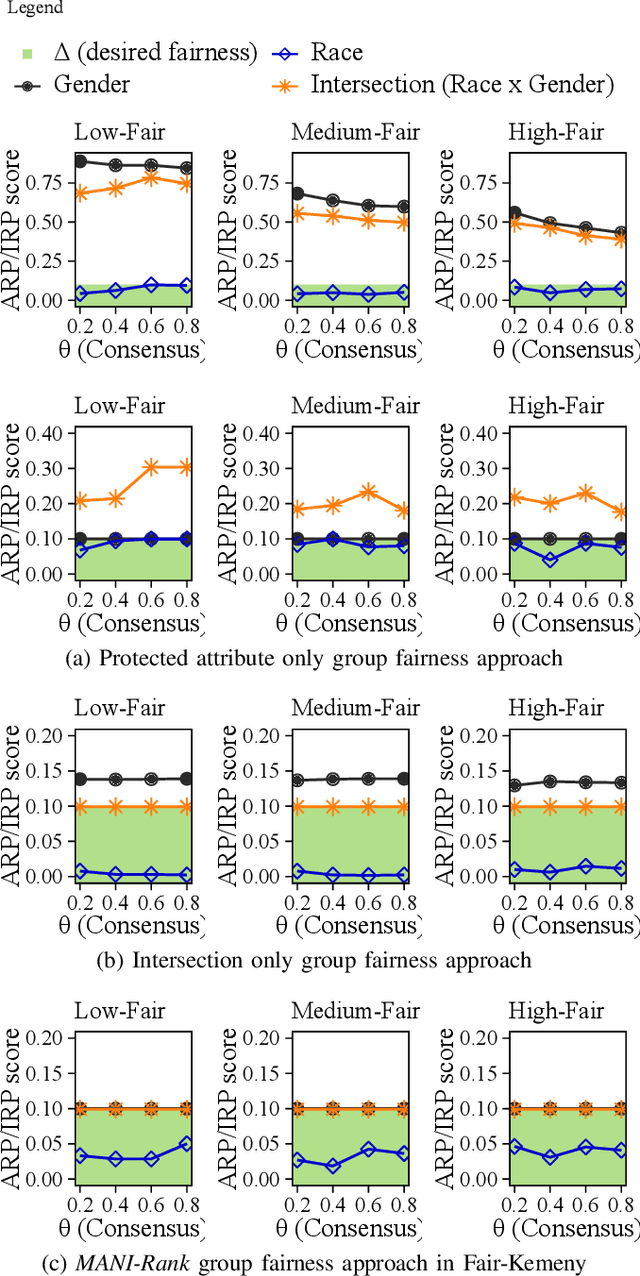
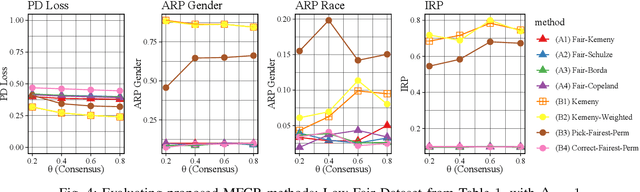
Combining the preferences of many rankers into one single consensus ranking is critical for consequential applications from hiring and admissions to lending. While group fairness has been extensively studied for classification, group fairness in rankings and in particular rank aggregation remains in its infancy. Recent work introduced the concept of fair rank aggregation for combining rankings but restricted to the case when candidates have a single binary protected attribute, i.e., they fall into two groups only. Yet it remains an open problem how to create a consensus ranking that represents the preferences of all rankers while ensuring fair treatment for candidates with multiple protected attributes such as gender, race, and nationality. In this work, we are the first to define and solve this open Multi-attribute Fair Consensus Ranking (MFCR) problem. As a foundation, we design novel group fairness criteria for rankings, called MANI-RANK, ensuring fair treatment of groups defined by individual protected attributes and their intersection. Leveraging the MANI-RANK criteria, we develop a series of algorithms that for the first time tackle the MFCR problem. Our experimental study with a rich variety of consensus scenarios demonstrates our MFCR methodology is the only approach to achieve both intersectional and protected attribute fairness while also representing the preferences expressed through many base rankings. Our real-world case study on merit scholarships illustrates the effectiveness of our MFCR methods to mitigate bias across multiple protected attributes and their intersections. This is an extended version of "MANI-Rank: Multiple Attribute and Intersectional Group Fairness for Consensus Ranking", to appear in ICDE 2022.
PSTNet: Point Spatio-Temporal Convolution on Point Cloud Sequences
May 27, 2022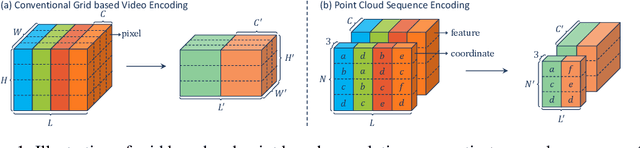
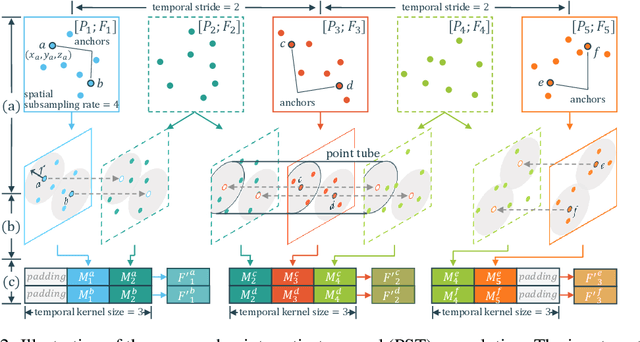
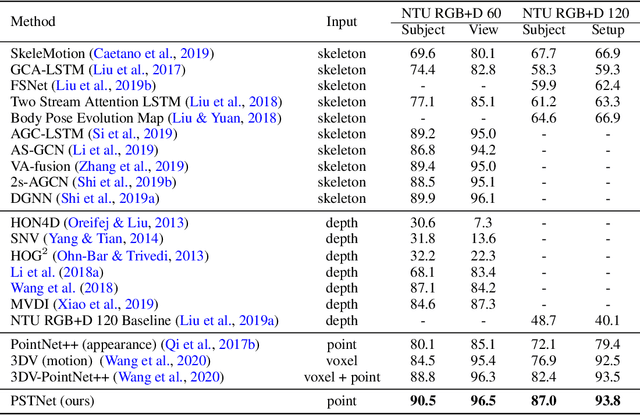
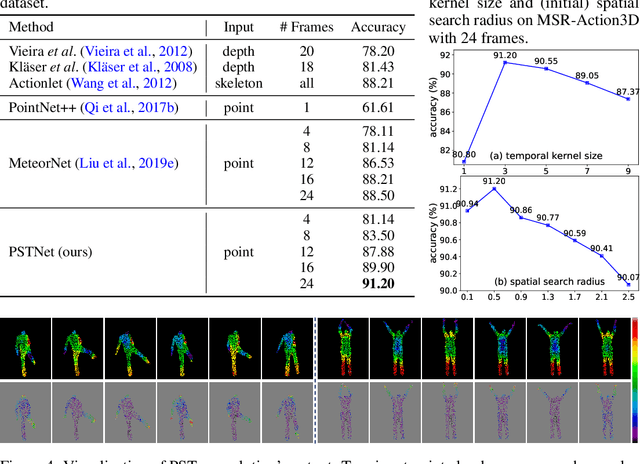
Point cloud sequences are irregular and unordered in the spatial dimension while exhibiting regularities and order in the temporal dimension. Therefore, existing grid based convolutions for conventional video processing cannot be directly applied to spatio-temporal modeling of raw point cloud sequences. In this paper, we propose a point spatio-temporal (PST) convolution to achieve informative representations of point cloud sequences. The proposed PST convolution first disentangles space and time in point cloud sequences. Then, a spatial convolution is employed to capture the local structure of points in the 3D space, and a temporal convolution is used to model the dynamics of the spatial regions along the time dimension. Furthermore, we incorporate the proposed PST convolution into a deep network, namely PSTNet, to extract features of point cloud sequences in a hierarchical manner. Extensive experiments on widely-used 3D action recognition and 4D semantic segmentation datasets demonstrate the effectiveness of PSTNet to model point cloud sequences.