 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Analyzing the Effects of Classifier Lipschitzness on Explainers
Jun 24, 2022
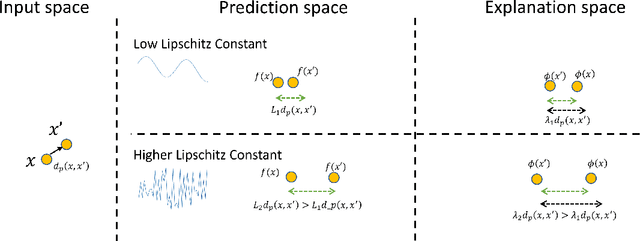
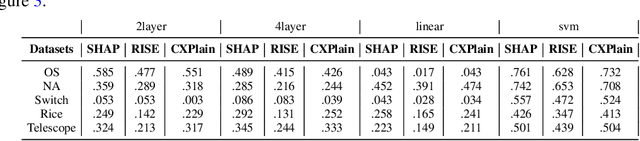
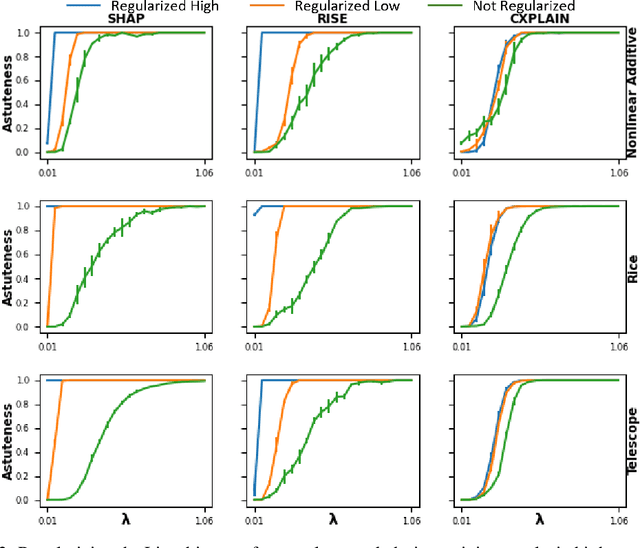
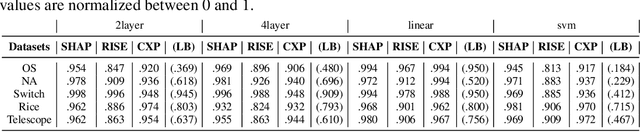
Machine learning methods are getting increasingly better at making predictions, but at the same time they are also becoming more complicated and less transparent. As a result, explainers are often relied on to provide interpretability to these black-box prediction models. As crucial diagnostics tools, it is important that these explainers themselves are reliable. In this paper we focus on one particular aspect of reliability, namely that an explainer should give similar explanations for similar data inputs. We formalize this notion by introducing and defining explainer astuteness, analogous to astuteness of classifiers. Our formalism is inspired by the concept of probabilistic Lipschitzness, which captures the probability of local smoothness of a function. For a variety of explainers (e.g., SHAP, RISE, CXPlain), we provide lower bound guarantees on the astuteness of these explainers given the Lipschitzness of the prediction function. These theoretical results imply that locally smooth prediction functions lend themselves to locally robust explanations. We evaluate these results empirically on simulated as well as real datasets.
DeepGraviLens: a Multi-Modal Architecture for Classifying Gravitational Lensing Data
May 03, 2022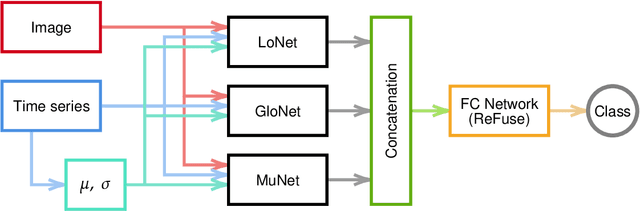
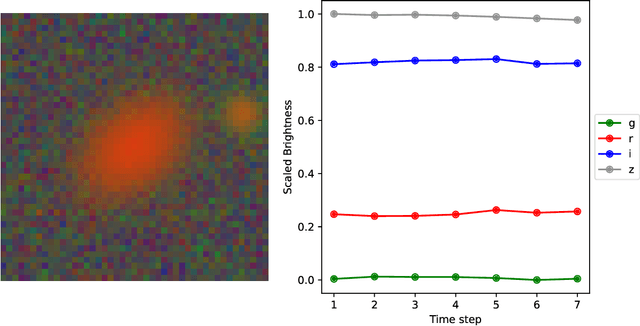
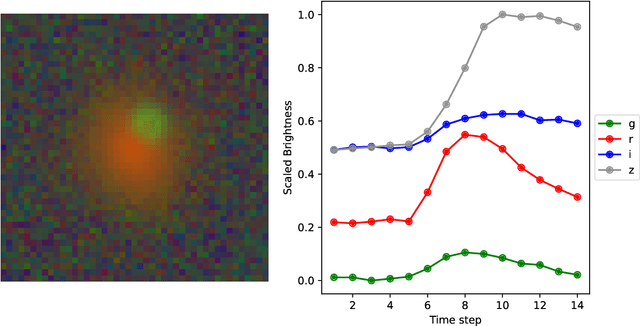
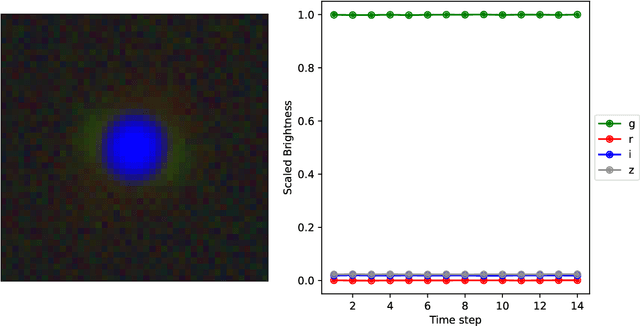
Gravitational lensing is the relativistic effect generated by massive bodies, which bend the space-time surrounding them. It is a deeply investigated topic in astrophysics and allows validating theoretical relativistic results and studying faint astrophysical objects that would not be visible otherwise. In recent years Machine Learning methods have been applied to support the analysis of the gravitational lensing phenomena by detecting lensing effects in data sets consisting of images associated with brightness variation time series. However, the state-of-art approaches either consider only images and neglect time-series data or achieve relatively low accuracy on the most difficult data sets. This paper introduces DeepGraviLens, a novel multi-modal network that classifies spatio-temporal data belonging to one non-lensed system type and three lensed system types. It surpasses the current state of the art accuracy results by $\approx$ 19% to $\approx$ 43%, depending on the considered data set. Such an improvement will enable the acceleration of the analysis of lensed objects in upcoming astrophysical surveys, which will exploit the petabytes of data collected, e.g., from the Vera C. Rubin Observatory.
Humanoid Self-Collision Avoidance Using Whole-Body Control with Control Barrier Functions
Jul 01, 2022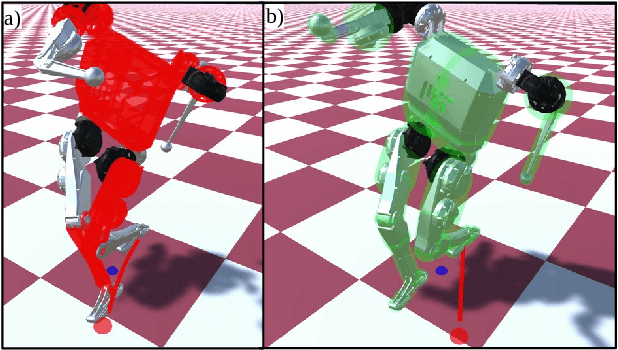

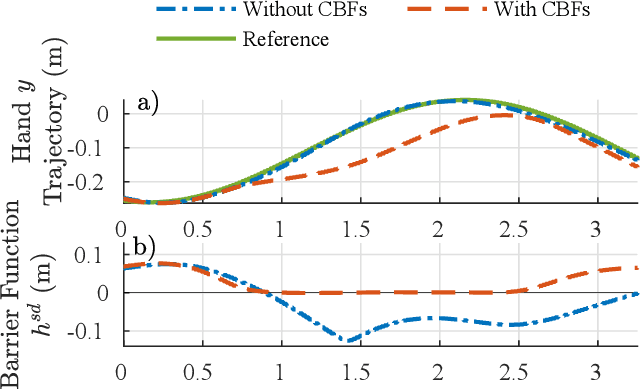
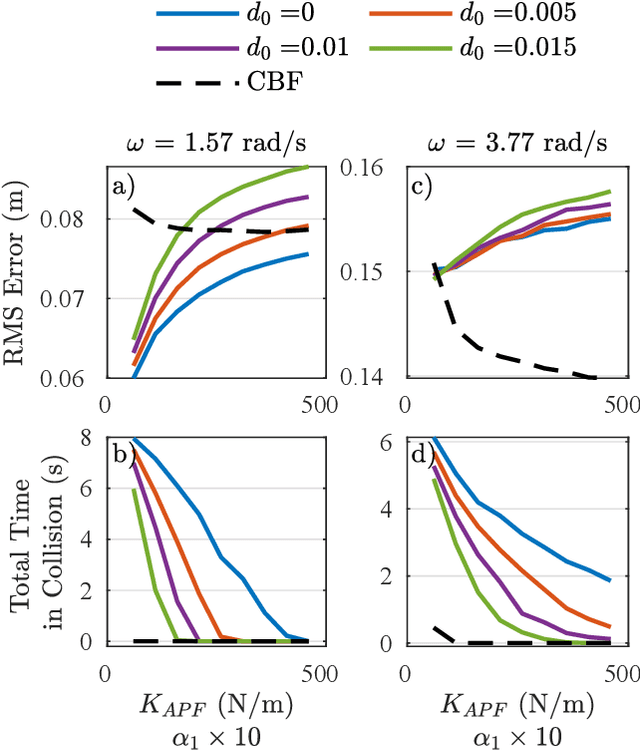
This work combines control barrier functions (CBFs) with a whole-body controller to enable self-collision avoidance for the MIT Humanoid. Existing reactive controllers for self-collision avoidance cannot guarantee collision-free trajectories as they do not leverage the robot's full dynamics, thus compromising kinematic feasibility. In comparison, the proposed CBF-WBC controller can reason about the robot's underactuated dynamics in real-time to guarantee collision-free motions. The effectiveness of this approach is validated in simulation. First, a simple hand-reaching experiment shows that the CBF-WBC enables the robot's hand to deviate from an infeasible reference trajectory to avoid self-collisions. Second, the CBF-WBC is combined with a linear model predictive controller (LMPC) designed for dynamic locomotion, and the CBF-WBC is used to track the LMPC predictions. A centroidal angular momentum task is also used to generate arm motions that assist humanoid locomotion and disturbance recovery. Walking experiments show that CBFs allow the centroidal angular momentum task to generate feasible arm motions and avoid leg self-collisions when the footstep location or swing trajectory provided by the high-level planner are infeasible for the real robot.
Learning in games from a stochastic approximation viewpoint
Jun 08, 2022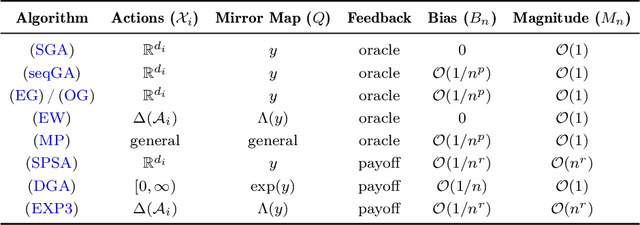
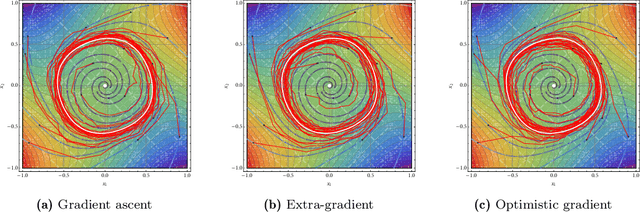
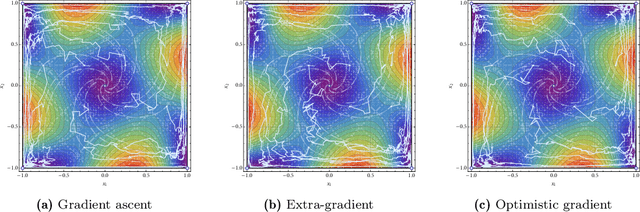
We develop a unified stochastic approximation framework for analyzing the long-run behavior of multi-agent online learning in games. Our framework is based on a "primal-dual", mirrored Robbins-Monro (MRM) template which encompasses a wide array of popular game-theoretic learning algorithms (gradient methods, their optimistic variants, the EXP3 algorithm for learning with payoff-based feedback in finite games, etc.). In addition to providing an integrated view of these algorithms, the proposed MRM blueprint allows us to obtain a broad range of new convergence results, both asymptotic and in finite time, in both continuous and finite games.
Real-time Emotion Appraisal with Circumplex Model for Human-Robot Interaction
Feb 20, 2022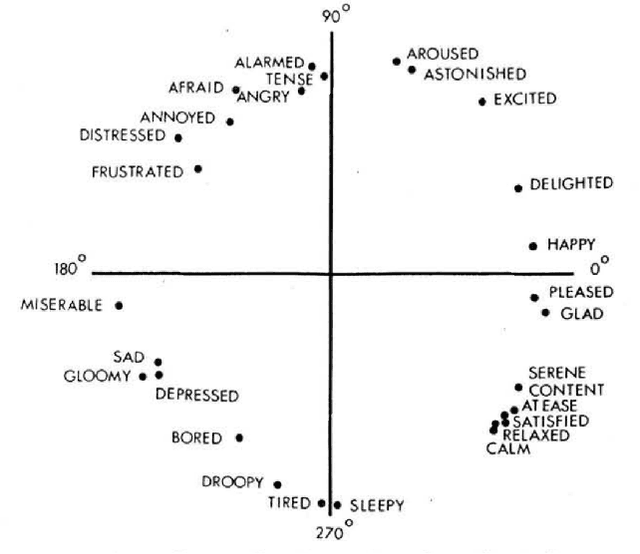
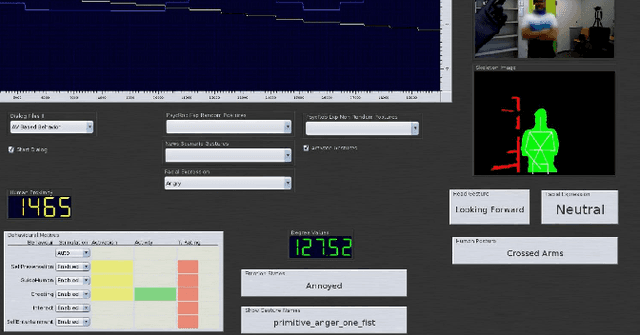
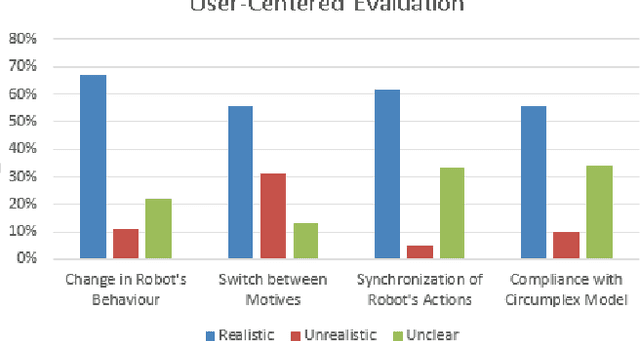

Emotions are the intrinsic or extrinsic representations of our experiences. The importance of emotions during a human-human interaction is immense as it formulates the basis of our interaction framework. There are several approaches in psychology to evaluate emotional states in humans based on the perceived stimuli. However, the topic has been less explored as far as human-robot interaction is concerned. This paper uses an appropriate emotion appraisal mechanism from psychology, generating an emotional state in a humanoid robot on-the-fly during human-robot interaction. Since the exhibition of only six basic emotions is not sufficient to cater to diverse situations, the use of the Circumplex Model in this work has allowed the life-sized robot called ROBIN to experience 28 emotional states in different interaction scenarios. Realistic robot behaviour has been generated based on the proposed appraisal system in various interaction scenarios.
Precise Change Point Detection using Spectral Drift Detection
May 13, 2022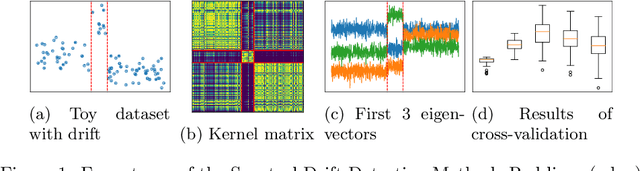
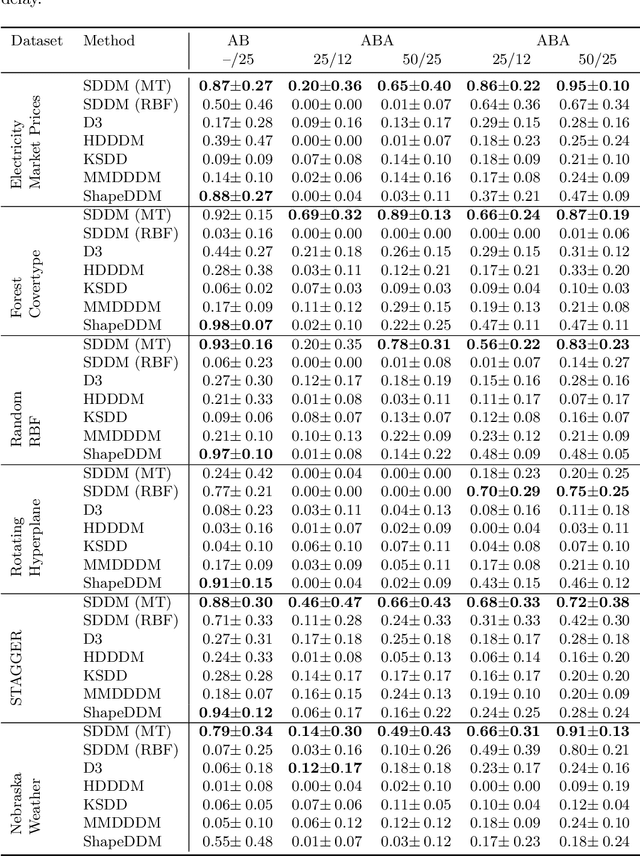
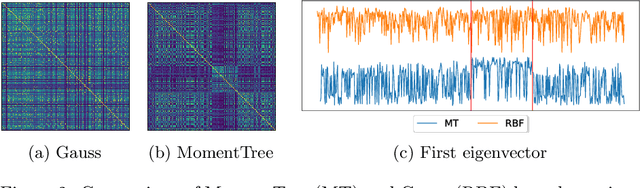
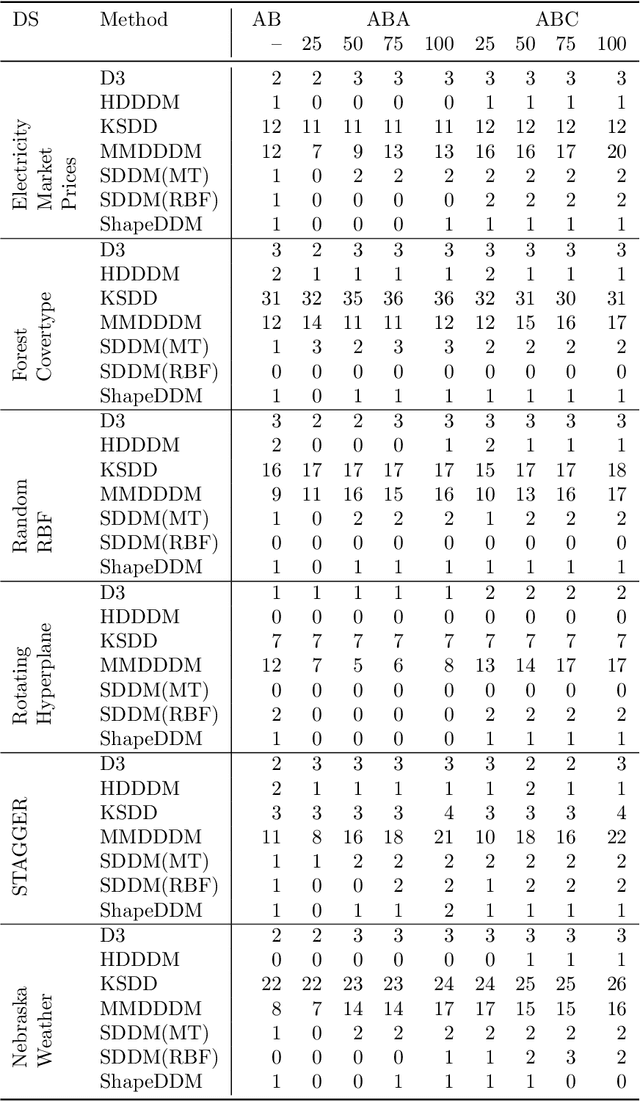
The notion of concept drift refers to the phenomenon that the data generating distribution changes over time; as a consequence machine learning models may become inaccurate and need adjustment. In this paper we consider the problem of detecting those change points in unsupervised learning. Many unsupervised approaches rely on the discrepancy between the sample distributions of two time windows. This procedure is noisy for small windows, hence prone to induce false positives and not able to deal with more than one drift event in a window. In this paper we rely on structural properties of drift induced signals, which use spectral properties of kernel embedding of distributions. Based thereon we derive a new unsupervised drift detection algorithm, investigate its mathematical properties, and demonstrate its usefulness in several experiments.
Policy Evaluation and Temporal-Difference Learning in Continuous Time and Space: A Martingale Approach
Aug 15, 2021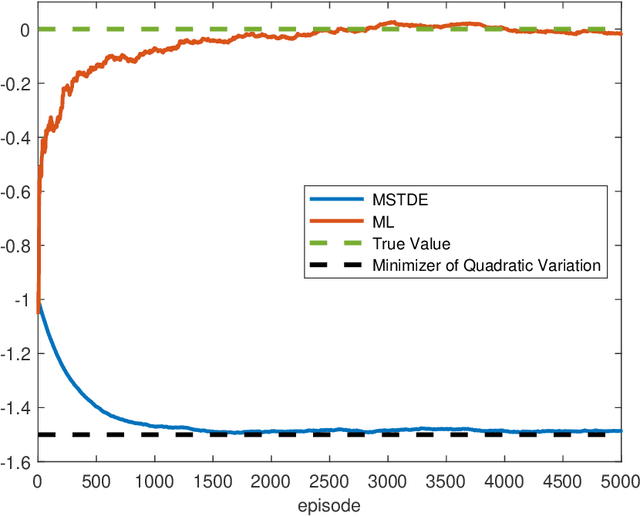
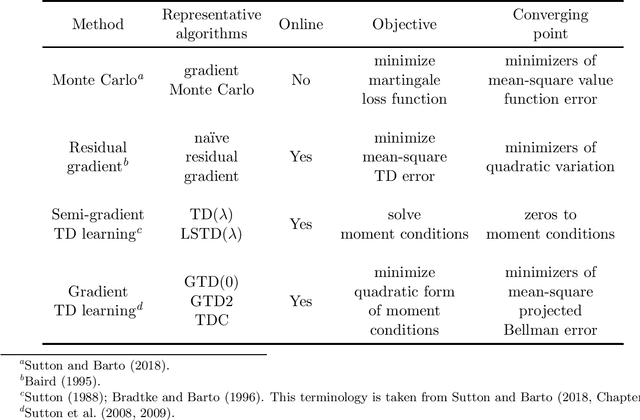
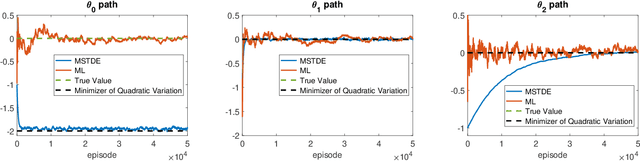
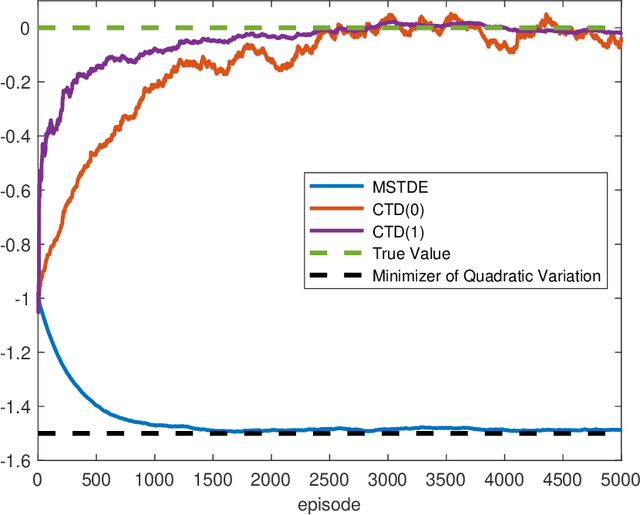
We propose a unified framework to study policy evaluation (PE) and the associated temporal difference (TD) methods for reinforcement learning in continuous time and space. We show that PE is equivalent to maintaining the martingale condition of a process. From this perspective, we find that the mean--square TD error approximates the quadratic variation of the martingale and thus is not a suitable objective for PE. We present two methods to use the martingale characterization for designing PE algorithms. The first one minimizes a "martingale loss function", whose solution is proved to be the best approximation of the true value function in the mean--square sense. This method interprets the classical gradient Monte-Carlo algorithm. The second method is based on a system of equations called the "martingale orthogonality conditions" with "test functions". Solving these equations in different ways recovers various classical TD algorithms, such as TD($\lambda$), LSTD, and GTD. Different choices of test functions determine in what sense the resulting solutions approximate the true value function. Moreover, we prove that any convergent time-discretized algorithm converges to its continuous-time counterpart as the mesh size goes to zero. We demonstrate the theoretical results and corresponding algorithms with numerical experiments and applications.
Real-Time Event-Based Tracking and Detection for Maritime Environments
Feb 09, 2022
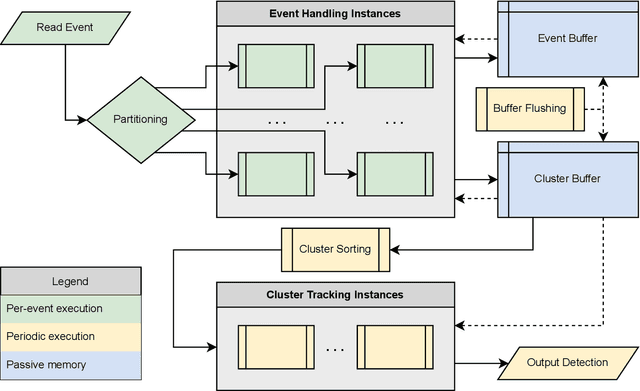

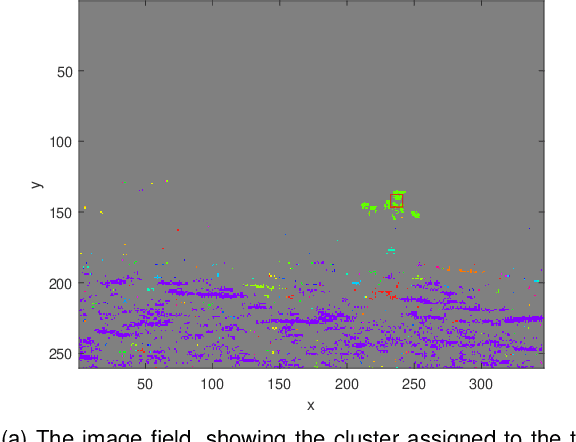
Event cameras are ideal for object tracking applications due to their ability to capture fast-moving objects while mitigating latency and data redundancy. Existing event-based clustering and feature tracking approaches for surveillance and object detection work well in the majority of cases, but fall short in a maritime environment. Our application of maritime vessel detection and tracking requires a process that can identify features and output a confidence score representing the likelihood that the feature was produced by a vessel, which may trigger a subsequent alert or activate a classification system. However, the maritime environment presents unique challenges such as the tendency of waves to produce the majority of events, demanding the majority of computational processing and producing false positive detections. By filtering redundant events and analyzing the movement of each event cluster, we can identify and track vessels while ignoring shorter lived and erratic features such as those produced by waves.
SAQAM: Spatial Audio Quality Assessment Metric
Jun 24, 2022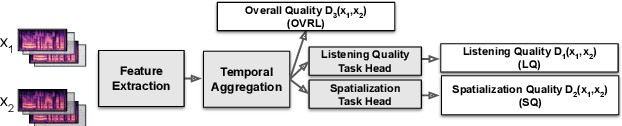

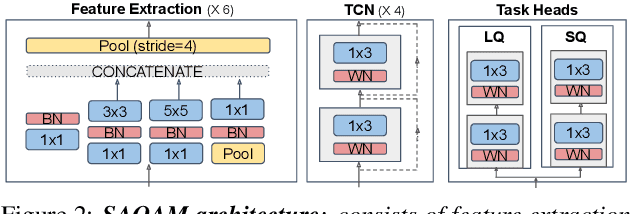

Audio quality assessment is critical for assessing the perceptual realism of sounds. However, the time and expense of obtaining ''gold standard'' human judgments limit the availability of such data. For AR&VR, good perceived sound quality and localizability of sources are among the key elements to ensure complete immersion of the user. Our work introduces SAQAM which uses a multi-task learning framework to assess listening quality (LQ) and spatialization quality (SQ) between any given pair of binaural signals without using any subjective data. We model LQ by training on a simulated dataset of triplet human judgments, and SQ by utilizing activation-level distances from networks trained for direction of arrival (DOA) estimation. We show that SAQAM correlates well with human responses across four diverse datasets. Since it is a deep network, the metric is differentiable, making it suitable as a loss function for other tasks. For example, simply replacing an existing loss with our metric yields improvement in a speech-enhancement network.
Non-Stationary Bandits under Recharging Payoffs: Improved Planning with Sublinear Regret
May 29, 2022The stochastic multi-armed bandit setting has been recently studied in the non-stationary regime, where the mean payoff of each action is a non-decreasing function of the number of rounds passed since it was last played. This model captures natural behavioral aspects of the users which crucially determine the performance of recommendation platforms, ad placement systems, and more. Even assuming prior knowledge of the mean payoff functions, computing an optimal planning in the above model is NP-hard, while the state-of-the-art is a $1/4$-approximation algorithm for the case where at most one arm can be played per round. We first focus on the setting where the mean payoff functions are known. In this setting, we significantly improve the best-known guarantees for the planning problem by developing a polynomial-time $(1-{1}/{e})$-approximation algorithm (asymptotically and in expectation), based on a novel combination of randomized LP rounding and a time-correlated (interleaved) scheduling method. Furthermore, our algorithm achieves improved guarantees -- compared to prior work -- for the case where more than one arm can be played at each round. Moving to the bandit setting, when the mean payoff functions are initially unknown, we show how our algorithm can be transformed into a bandit algorithm with sublinear regret.