 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Stream-based Active Learning with Verification Latency in Non-stationary Environments
Apr 14, 2022
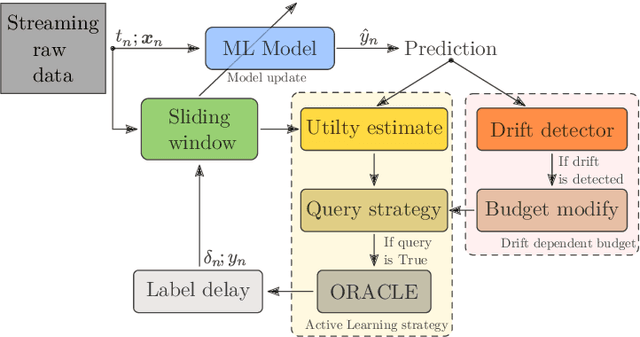
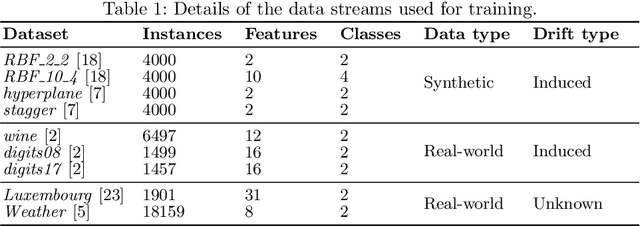
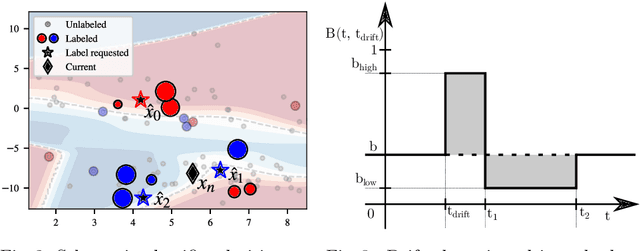
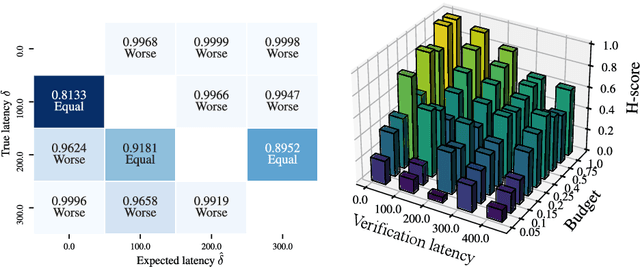
Data stream classification is an important problem in the field of machine learning. Due to the non-stationary nature of the data where the underlying distribution changes over time (concept drift), the model needs to continuously adapt to new data statistics. Stream-based Active Learning (AL) approaches address this problem by interactively querying a human expert to provide new data labels for the most recent samples, within a limited budget. Existing AL strategies assume that labels are immediately available, while in a real-world scenario the expert requires time to provide a queried label (verification latency), and by the time the requested labels arrive they may not be relevant anymore. In this article, we investigate the influence of finite, time-variable, and unknown verification delay, in the presence of concept drift on AL approaches. We propose PRopagate (PR), a latency independent utility estimator which also predicts the requested, but not yet known, labels. Furthermore, we propose a drift-dependent dynamic budget strategy, which uses a variable distribution of the labelling budget over time, after a detected drift. Thorough experimental evaluation, with both synthetic and real-world non-stationary datasets, and different settings of verification latency and budget are conducted and analyzed. We empirically show that the proposed method consistently outperforms the state-of-the-art. Additionally, we demonstrate that with variable budget allocation in time, it is possible to boost the performance of AL strategies, without increasing the overall labeling budget.
Real-time Detection of Practical Universal Adversarial Perturbations
May 22, 2021

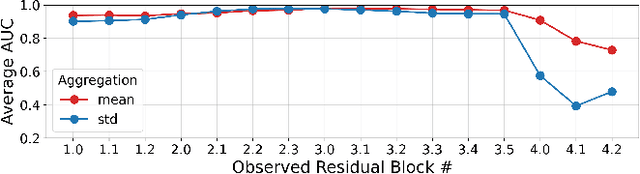
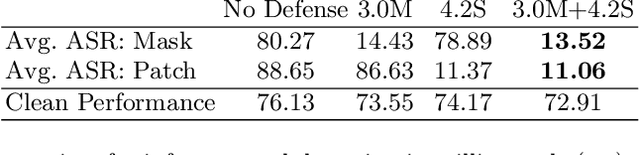
Universal Adversarial Perturbations (UAPs) are a prominent class of adversarial examples that exploit the systemic vulnerabilities and enable physically realizable and robust attacks against Deep Neural Networks (DNNs). UAPs generalize across many different inputs; this leads to realistic and effective attacks that can be applied at scale. In this paper we propose HyperNeuron, an efficient and scalable algorithm that allows for the real-time detection of UAPs by identifying suspicious neuron hyper-activations. Our results show the effectiveness of HyperNeuron on multiple tasks (image classification, object detection), against a wide variety of universal attacks, and in realistic scenarios, like perceptual ad-blocking and adversarial patches. HyperNeuron is able to simultaneously detect both adversarial mask and patch UAPs with comparable or better performance than existing UAP defenses whilst introducing a significantly reduced latency of only 0.86 milliseconds per image. This suggests that many realistic and practical universal attacks can be reliably mitigated in real-time, which shows promise for the robust deployment of machine learning systems.
Improving Variational Autoencoder based Out-of-Distribution Detection for Embedded Real-time Applications
Jul 25, 2021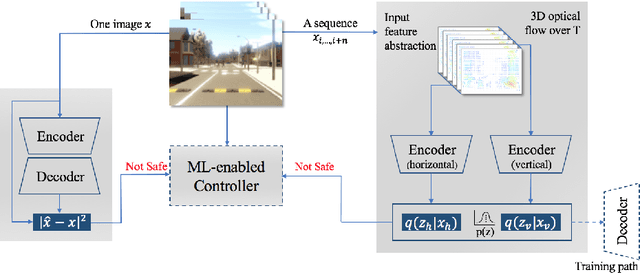
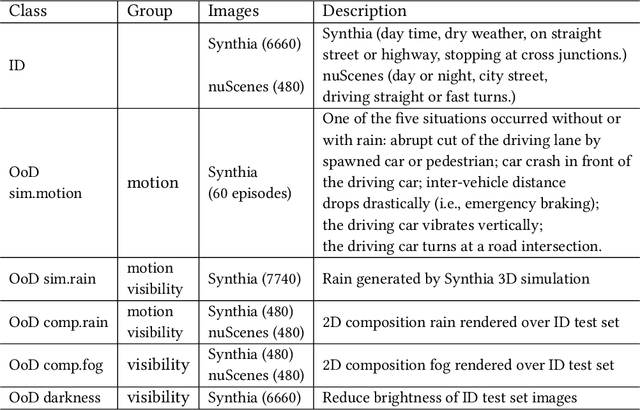

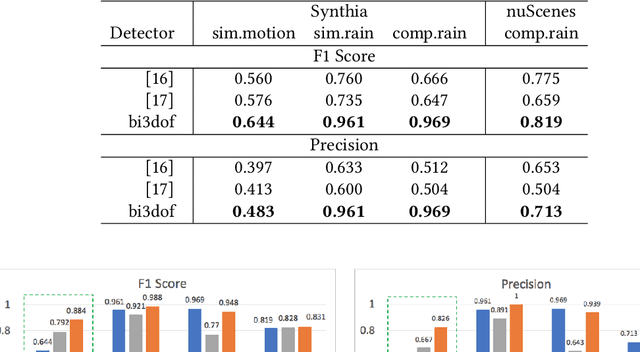
Uncertainties in machine learning are a significant roadblock for its application in safety-critical cyber-physical systems (CPS). One source of uncertainty arises from distribution shifts in the input data between training and test scenarios. Detecting such distribution shifts in real-time is an emerging approach to address the challenge. The high dimensional input space in CPS applications involving imaging adds extra difficulty to the task. Generative learning models are widely adopted for the task, namely out-of-distribution (OoD) detection. To improve the state-of-the-art, we studied existing proposals from both machine learning and CPS fields. In the latter, safety monitoring in real-time for autonomous driving agents has been a focus. Exploiting the spatiotemporal correlation of motion in videos, we can robustly detect hazardous motion around autonomous driving agents. Inspired by the latest advances in the Variational Autoencoder (VAE) theory and practice, we tapped into the prior knowledge in data to further boost OoD detection's robustness. Comparison studies over nuScenes and Synthia data sets show our methods significantly improve detection capabilities of OoD factors unique to driving scenarios, 42% better than state-of-the-art approaches. Our model also generalized near-perfectly, 97% better than the state-of-the-art across the real-world and simulation driving data sets experimented. Finally, we customized one proposed method into a twin-encoder model that can be deployed to resource limited embedded devices for real-time OoD detection. Its execution time was reduced over four times in low-precision 8-bit integer inference, while detection capability is comparable to its corresponding floating-point model.
Explainable vision transformer enabled convolutional neural network for plant disease identification: PlantXViT
Jul 16, 2022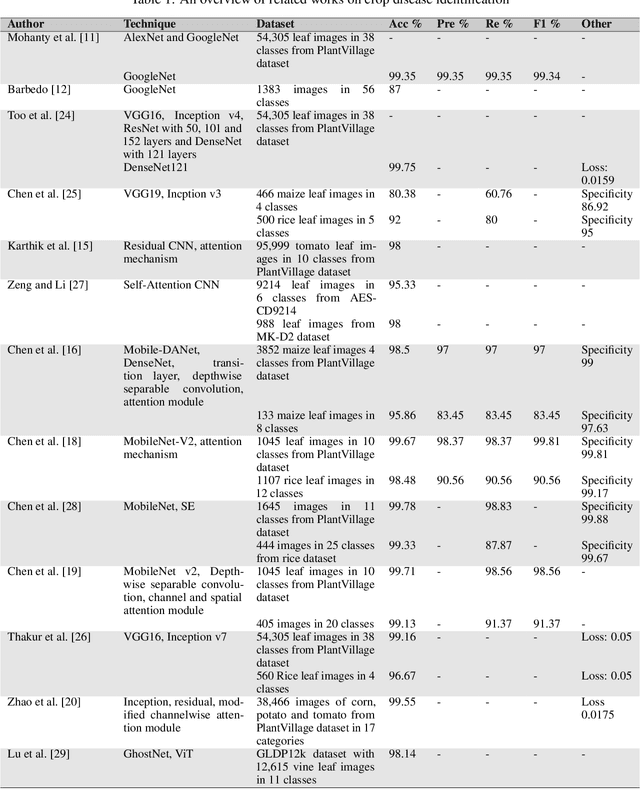
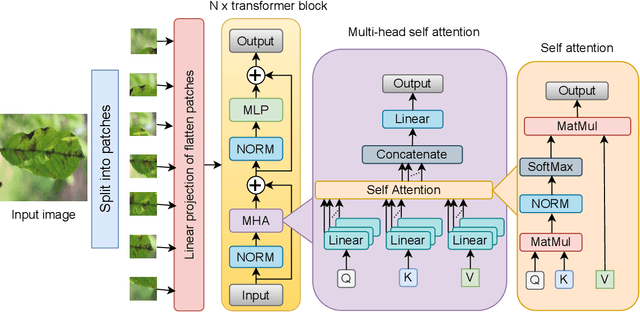
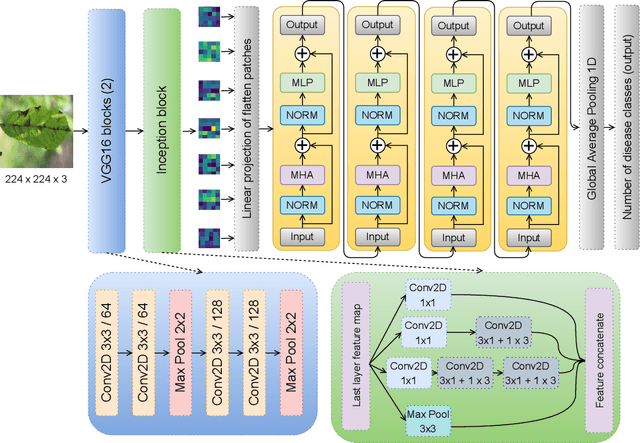
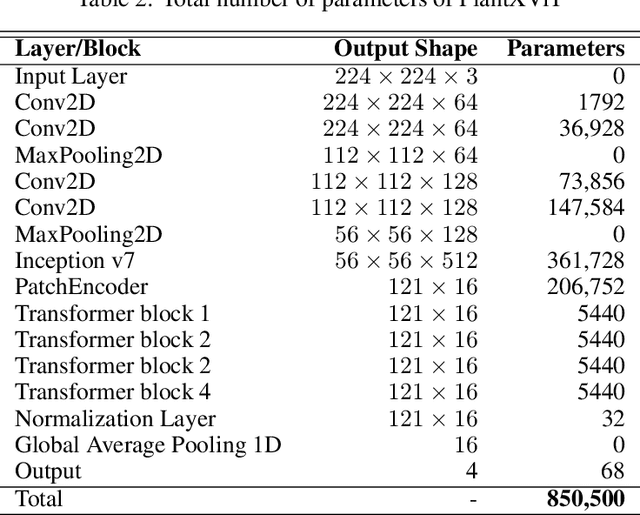
Plant diseases are the primary cause of crop losses globally, with an impact on the world economy. To deal with these issues, smart agriculture solutions are evolving that combine the Internet of Things and machine learning for early disease detection and control. Many such systems use vision-based machine learning methods for real-time disease detection and diagnosis. With the advancement in deep learning techniques, new methods have emerged that employ convolutional neural networks for plant disease detection and identification. Another trend in vision-based deep learning is the use of vision transformers, which have proved to be powerful models for classification and other problems. However, vision transformers have rarely been investigated for plant pathology applications. In this study, a Vision Transformer enabled Convolutional Neural Network model called "PlantXViT" is proposed for plant disease identification. The proposed model combines the capabilities of traditional convolutional neural networks with the Vision Transformers to efficiently identify a large number of plant diseases for several crops. The proposed model has a lightweight structure with only 0.8 million trainable parameters, which makes it suitable for IoT-based smart agriculture services. The performance of PlantXViT is evaluated on five publicly available datasets. The proposed PlantXViT network performs better than five state-of-the-art methods on all five datasets. The average accuracy for recognising plant diseases is shown to exceed 93.55%, 92.59%, and 98.33% on Apple, Maize, and Rice datasets, respectively, even under challenging background conditions. The efficiency in terms of explainability of the proposed model is evaluated using gradient-weighted class activation maps and Local Interpretable Model Agnostic Explanation.
Machine Learning Model Sizes and the Parameter Gap
Jul 05, 2022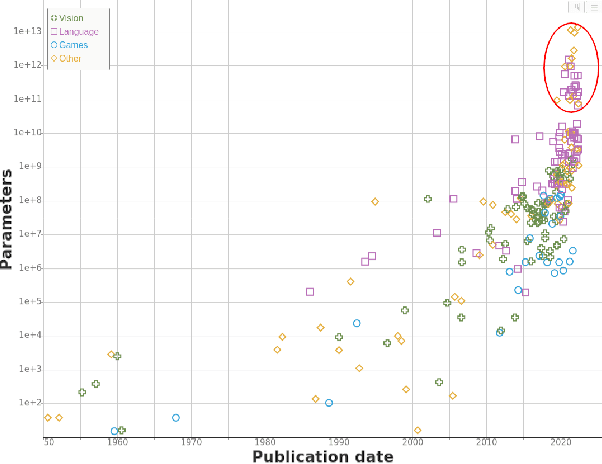
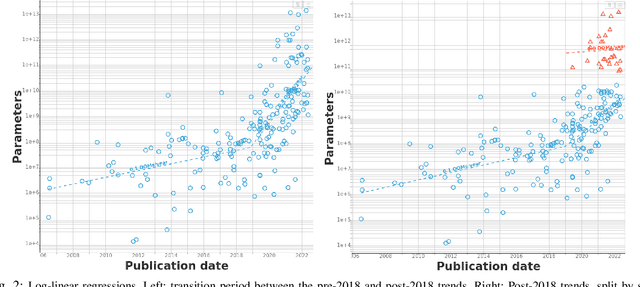
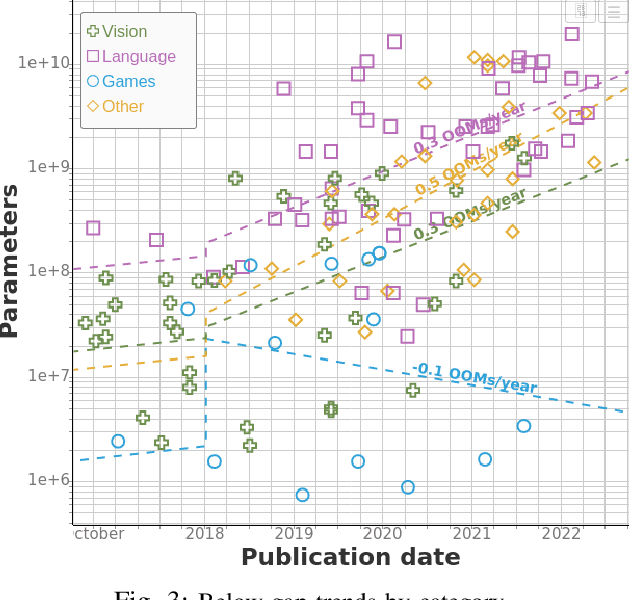
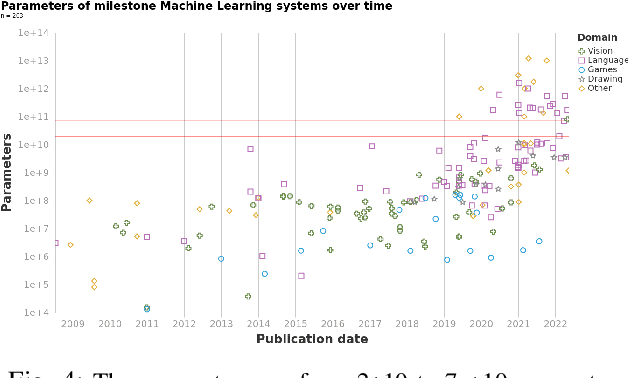
We study trends in model size of notable machine learning systems over time using a curated dataset. From 1950 to 2018, model size in language models increased steadily by seven orders of magnitude. The trend then accelerated, with model size increasing by another five orders of magnitude in just 4 years from 2018 to 2022. Vision models grew at a more constant pace, totaling 7 orders of magnitude of growth between 1950 and 2022. We also identify that, since 2020, there have been many language models below 20B parameters, many models above 70B parameters, but a scarcity of models in the 20-70B parameter range. We refer to that scarcity as the parameter gap. We provide some stylized facts about the parameter gap and propose a few hypotheses to explain it. The explanations we favor are: (a) increasing model size beyond 20B parameters requires adopting different parallelism techniques, which makes mid-sized models less cost-effective, (b) GPT-3 was one order of magnitude larger than previous language models, and researchers afterwards primarily experimented with bigger models to outperform it. While these dynamics likely exist, and we believe they play some role in generating the gap, we don't have high confidence that there are no other, more important dynamics at play.
SHIFT: A Synthetic Driving Dataset for Continuous Multi-Task Domain Adaptation
Jun 16, 2022
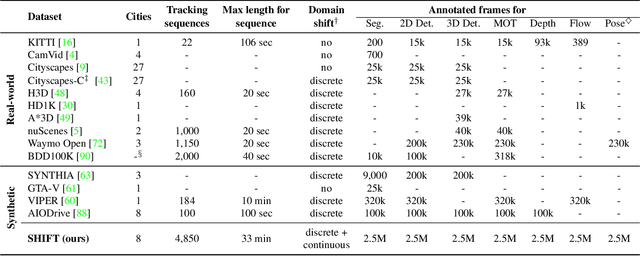
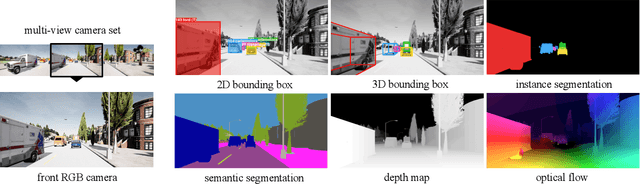

Adapting to a continuously evolving environment is a safety-critical challenge inevitably faced by all autonomous driving systems. Existing image and video driving datasets, however, fall short of capturing the mutable nature of the real world. In this paper, we introduce the largest multi-task synthetic dataset for autonomous driving, SHIFT. It presents discrete and continuous shifts in cloudiness, rain and fog intensity, time of day, and vehicle and pedestrian density. Featuring a comprehensive sensor suite and annotations for several mainstream perception tasks, SHIFT allows investigating the degradation of a perception system performance at increasing levels of domain shift, fostering the development of continuous adaptation strategies to mitigate this problem and assess model robustness and generality. Our dataset and benchmark toolkit are publicly available at www.vis.xyz/shift.
SInGE: Sparsity via Integrated Gradients Estimation of Neuron Relevance
Jul 08, 2022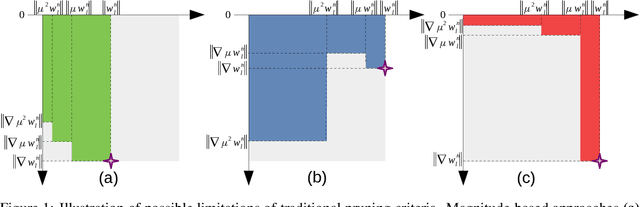

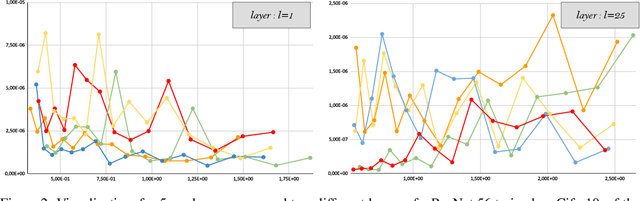
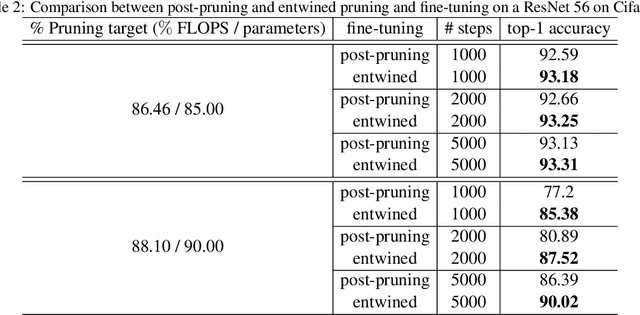
The leap in performance in state-of-the-art computer vision methods is attributed to the development of deep neural networks. However it often comes at a computational price which may hinder their deployment. To alleviate this limitation, structured pruning is a well known technique which consists in removing channels, neurons or filters, and is commonly applied in order to produce more compact models. In most cases, the computations to remove are selected based on a relative importance criterion. At the same time, the need for explainable predictive models has risen tremendously and motivated the development of robust attribution methods that highlight the relative importance of pixels of an input image or feature map. In this work, we discuss the limitations of existing pruning heuristics, among which magnitude and gradient-based methods. We draw inspiration from attribution methods to design a novel integrated gradient pruning criterion, in which the relevance of each neuron is defined as the integral of the gradient variation on a path towards this neuron removal. Furthermore, we propose an entwined DNN pruning and fine-tuning flowchart to better preserve DNN accuracy while removing parameters. We show through extensive validation on several datasets, architectures as well as pruning scenarios that the proposed method, dubbed SInGE, significantly outperforms existing state-of-the-art DNN pruning methods.
DeepGraviLens: a Multi-Modal Architecture for Classifying Gravitational Lensing Data
May 03, 2022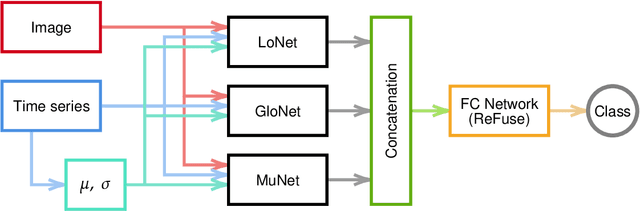
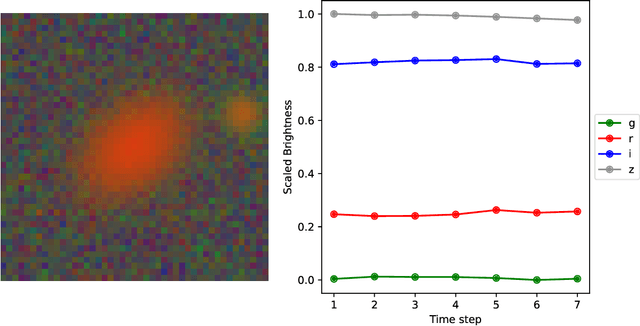
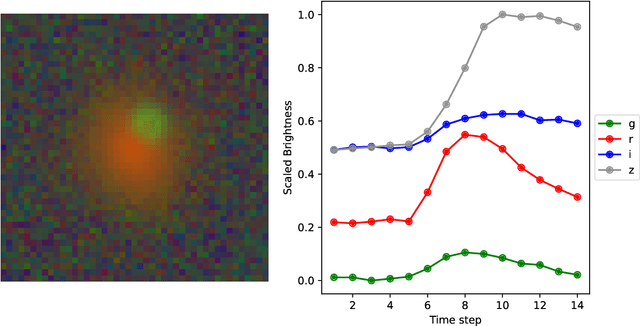
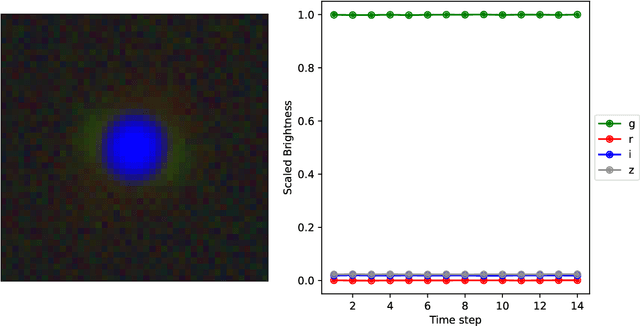
Gravitational lensing is the relativistic effect generated by massive bodies, which bend the space-time surrounding them. It is a deeply investigated topic in astrophysics and allows validating theoretical relativistic results and studying faint astrophysical objects that would not be visible otherwise. In recent years Machine Learning methods have been applied to support the analysis of the gravitational lensing phenomena by detecting lensing effects in data sets consisting of images associated with brightness variation time series. However, the state-of-art approaches either consider only images and neglect time-series data or achieve relatively low accuracy on the most difficult data sets. This paper introduces DeepGraviLens, a novel multi-modal network that classifies spatio-temporal data belonging to one non-lensed system type and three lensed system types. It surpasses the current state of the art accuracy results by $\approx$ 19% to $\approx$ 43%, depending on the considered data set. Such an improvement will enable the acceleration of the analysis of lensed objects in upcoming astrophysical surveys, which will exploit the petabytes of data collected, e.g., from the Vera C. Rubin Observatory.
A Unifying Framework for Causal Explanation of Sequential Decision Making
May 30, 2022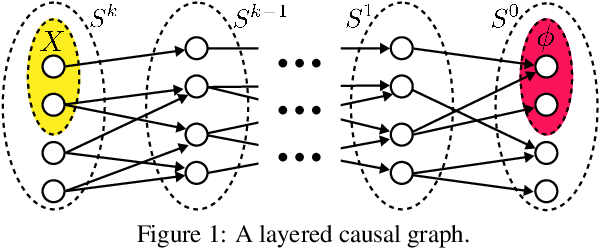
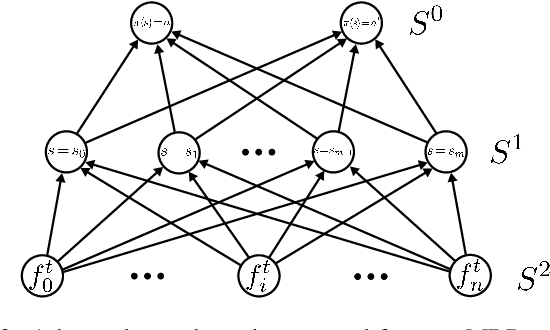
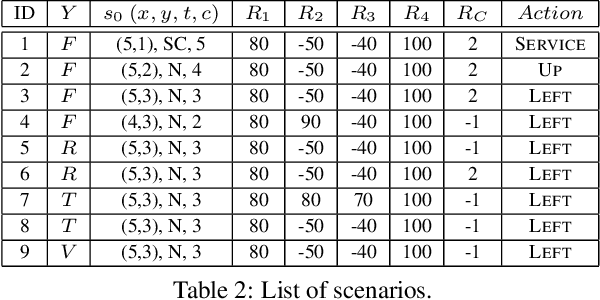
We present a novel framework for causal explanations of stochastic, sequential decision-making systems. Building on the well-studied structural causal model paradigm for causal reasoning, we show how to identify semantically distinct types of explanations for agent actions using a single unified approach. We provide results on the generality of this framework, run time bounds, and offer several approximate techniques. Finally, we discuss several qualitative scenarios that illustrate the framework's flexibility and efficacy.
CoBEVT: Cooperative Bird's Eye View Semantic Segmentation with Sparse Transformers
Jul 05, 2022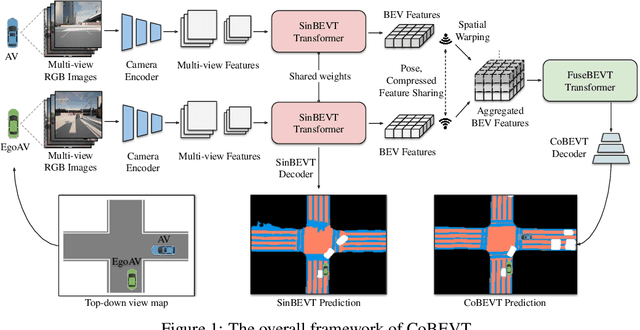

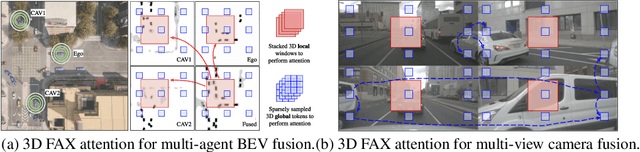
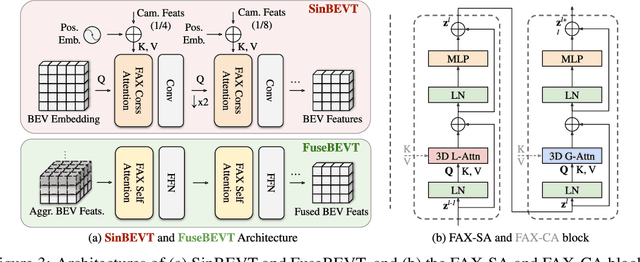
Bird's eye view (BEV) semantic segmentation plays a crucial role in spatial sensing for autonomous driving. Although recent literature has made significant progress on BEV map understanding, they are all based on single-agent camera-based systems which are difficult to handle occlusions and detect distant objects in complex traffic scenes. Vehicle-to-Vehicle (V2V) communication technologies have enabled autonomous vehicles to share sensing information, which can dramatically improve the perception performance and range as compared to single-agent systems. In this paper, we propose CoBEVT, the first generic multi-agent multi-camera perception framework that can cooperatively generate BEV map predictions. To efficiently fuse camera features from multi-view and multi-agent data in an underlying Transformer architecture, we design a fused axial attention or FAX module, which can capture sparsely local and global spatial interactions across views and agents. The extensive experiments on the V2V perception dataset, OPV2V, demonstrate that CoBEVT achieves state-of-the-art performance for cooperative BEV semantic segmentation. Moreover, CoBEVT is shown to be generalizable to other tasks, including 1) BEV segmentation with single-agent multi-camera and 2) 3D object detection with multi-agent LiDAR systems, and achieves state-of-the-art performance with real-time inference speed.