 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Collaborative Best Arm Identification with Limited Communication on Non-IID Data
Jul 16, 2022
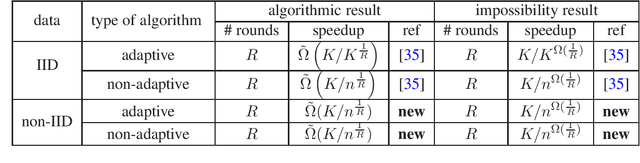
In this paper, we study the tradeoffs between time-speedup and the number of communication rounds of the learning process in the collaborative learning model on non-IID data, where multiple agents interact with possibly different environments and they want to learn an objective in the aggregated environment. We use a basic problem in bandit theory called best arm identification in multi-armed bandits as a vehicle to deliver the following conceptual message: Collaborative learning on non-IID data is provably more difficult than that on IID data. In particular, we show the following: a) The speedup in the non-IID data setting can be less than $1$ (that is, a slowdown). When the number of rounds $R = O(1)$, we will need at least a polynomial number of agents (in terms of the number of arms) to achieve a speedup greater than $1$. This is in sharp contrast with the IID data setting, in which the speedup is always at least $1$ when $R \ge 2$ regardless of number of agents. b) Adaptivity in the learning process cannot help much in the non-IID data setting. This is in sharp contrast with the IID data setting, in which to achieve the same speedup, the best non-adaptive algorithm requires a significantly larger number of rounds than the best adaptive algorithm. In the technique space, we have further developed the generalized round elimination technique introduced in arXiv:1904.03293. We show that implicit representations of distribution classes can be very useful when working with complex hard input distributions and proving lower bounds directly for adaptive algorithms.
Traversing Supervisor Problem: An Approximately Optimal Approach to Multi-Robot Assistance
May 03, 2022
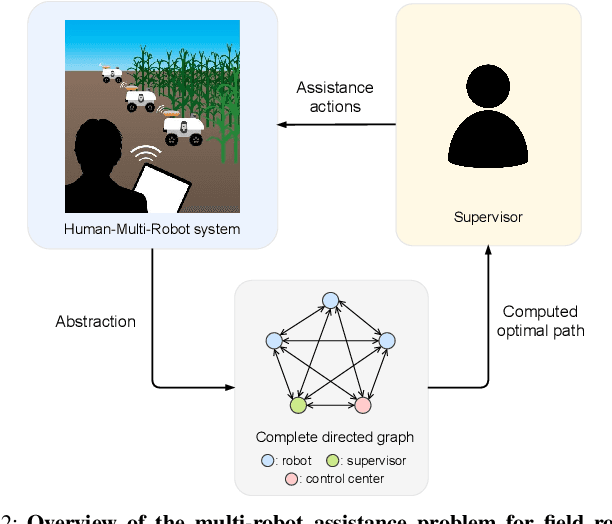
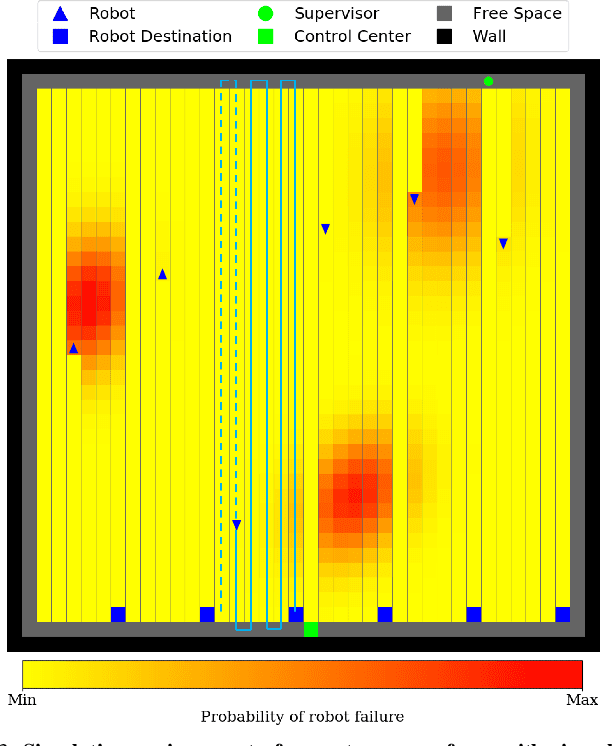
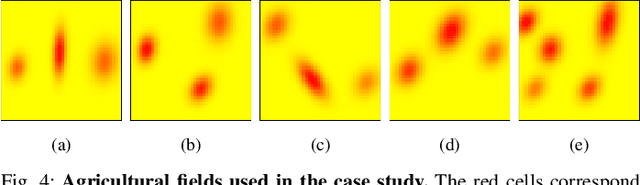
The number of multi-robot systems deployed in field applications has increased dramatically over the years. Despite the recent advancement of navigation algorithms, autonomous robots often encounter challenging situations where the control policy fails and the human assistance is required to resume robot tasks. Human-robot collaboration can help achieve high-levels of autonomy, but monitoring and managing multiple robots at once by a single human supervisor remains a challenging problem. Our goal is to help a supervisor decide which robots to assist in which order such that the team performance can be maximized. We formulate the one-to-many supervision problem in uncertain environments as a dynamic graph traversal problem. An approximation algorithm based on the profitable tour problem on a static graph is developed to solve the original problem, and the approximation error is bounded and analyzed. Our case study on a simulated autonomous farm demonstrates superior team performance than baseline methods in task completion time and human working time, and that our method can be deployed in real-time for robot fleets with moderate size.
VRKitchen2.0-IndoorKit: A Tutorial for Augmented Indoor Scene Building in Omniverse
Jun 23, 2022

With the recent progress of simulations by 3D modeling software and game engines, many researchers have focused on Embodied AI tasks in the virtual environment. However, the research community lacks a platform that can easily serve both indoor scene synthesis and model benchmarking with various algorithms. Meanwhile, computer graphics-related tasks need a toolkit for implementing advanced synthesizing techniques. To facilitate the study of indoor scene building methods and their potential robotics applications, we introduce INDOORKIT: a built-in toolkit for NVIDIA OMNIVERSE that provides flexible pipelines for indoor scene building, scene randomizing, and animation controls. Besides, combining Python coding in the animation software INDOORKIT assists researchers in creating real-time training and controlling avatars and robotics. The source code for this toolkit is available at https://github.com/realvcla/VRKitchen2.0-Tutorial, and the tutorial along with the toolkit is available at https://vrkitchen20-tutorial.readthedocs.io/en/
A prediction perspective on the Wiener-Hopf equations for discrete time series
Jul 11, 2021The Wiener-Hopf equations are a Toeplitz system of linear equations that have several applications in time series. These include the update and prediction step of the stationary Kalman filter equations and the prediction of bivariate time series. The Wiener-Hopf technique is the classical tool for solving the equations, and is based on a comparison of coefficients in a Fourier series expansion. The purpose of this note is to revisit the (discrete) Wiener-Hopf equations and obtain an alternative expression for the solution that is more in the spirit of time series analysis. Specifically, we propose a solution to the Wiener-Hopf equations that combines linear prediction with deconvolution. The solution of the Wiener-Hopf equations requires one to obtain the spectral factorization of the underlying spectral density function. For general spectral density functions this is infeasible. Therefore, it is usually assumed that the spectral density is rational, which allows one to obtain a computationally tractable solution. This leads to an approximation error when the underlying spectral density is not a rational function. We use the proposed solution together with Baxter's inequality to derive an error bound for the rational spectral density approximation.
Rethinking Audio-visual Synchronization for Active Speaker Detection
Jun 21, 2022
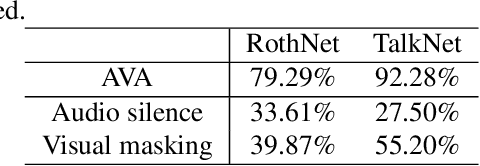

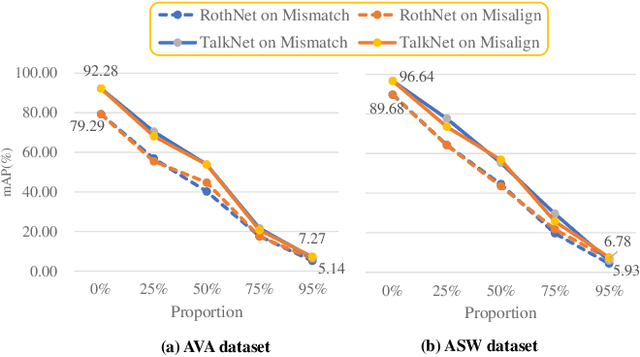
Active speaker detection (ASD) systems are important modules for analyzing multi-talker conversations. They aim to detect which speakers or none are talking in a visual scene at any given time. Existing research on ASD does not agree on the definition of active speakers. We clarify the definition in this work and require synchronization between the audio and visual speaking activities. This clarification of definition is motivated by our extensive experiments, through which we discover that existing ASD methods fail in modeling the audio-visual synchronization and often classify unsynchronized videos as active speaking. To address this problem, we propose a cross-modal contrastive learning strategy and apply positional encoding in attention modules for supervised ASD models to leverage the synchronization cue. Experimental results suggest that our model can successfully detect unsynchronized speaking as not speaking, addressing the limitation of current models.
YOLOSA: Object detection based on 2D local feature superimposed self-attention
Jun 23, 2022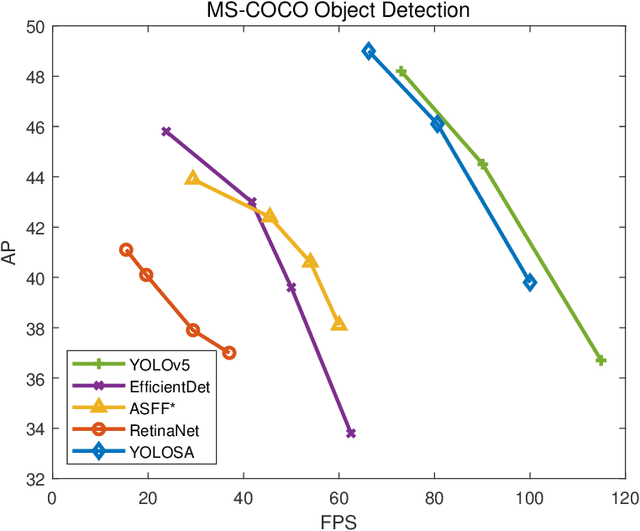
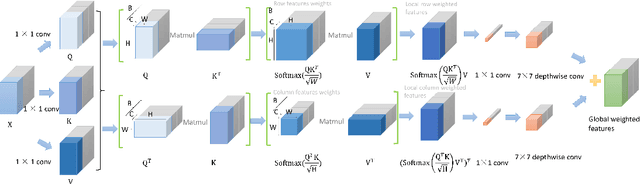

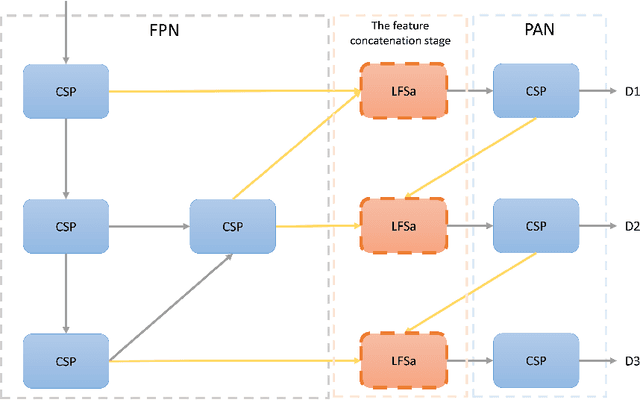
We analyzed the network structure of real-time object detection models and found that the features in the feature concatenation stage are very rich. Applying an attention module here can effectively improve the detection accuracy of the model. However, the commonly used attention module or self-attention module shows poor performance in detection accuracy and inference efficiency. Therefore, we propose a novel self-attention module, called 2D local feature superimposed self-attention, for the feature concatenation stage of the neck network. This self-attention module reflects global features through local features and local receptive fields. We also propose and optimize an efficient decoupled head and AB-OTA, and achieve SOTA results. Average precisions of 49.0\% (66.2 FPS), 46.1\% (80.6 FPS), and 39.1\% (100 FPS) were obtained for large, medium, and small-scale models built using our proposed improvements. Our models exceeded YOLOv5 by 0.8\% -- 3.1\% in average precision.
Real-time Detection of Practical Universal Adversarial Perturbations
May 22, 2021

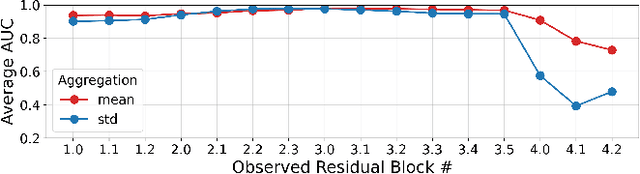
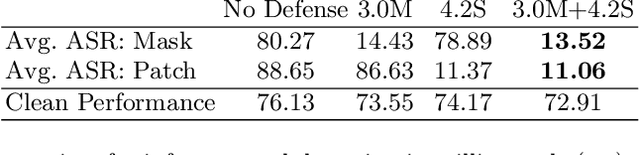
Universal Adversarial Perturbations (UAPs) are a prominent class of adversarial examples that exploit the systemic vulnerabilities and enable physically realizable and robust attacks against Deep Neural Networks (DNNs). UAPs generalize across many different inputs; this leads to realistic and effective attacks that can be applied at scale. In this paper we propose HyperNeuron, an efficient and scalable algorithm that allows for the real-time detection of UAPs by identifying suspicious neuron hyper-activations. Our results show the effectiveness of HyperNeuron on multiple tasks (image classification, object detection), against a wide variety of universal attacks, and in realistic scenarios, like perceptual ad-blocking and adversarial patches. HyperNeuron is able to simultaneously detect both adversarial mask and patch UAPs with comparable or better performance than existing UAP defenses whilst introducing a significantly reduced latency of only 0.86 milliseconds per image. This suggests that many realistic and practical universal attacks can be reliably mitigated in real-time, which shows promise for the robust deployment of machine learning systems.
Deep Reinforcement Learning for Distributed and Uncoordinated Cognitive Radios Resource Allocation
May 27, 2022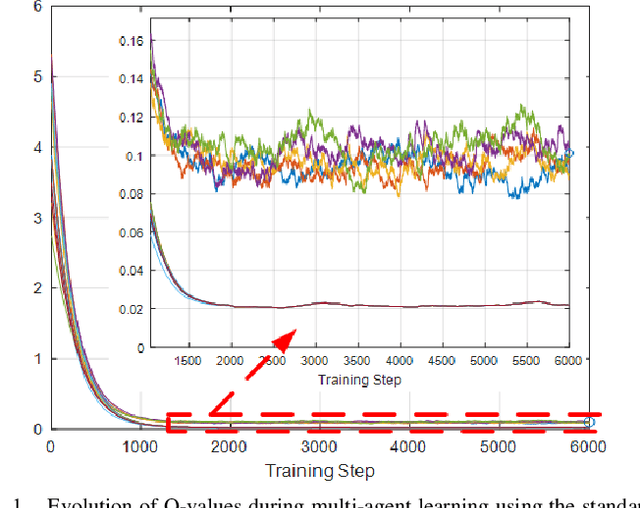
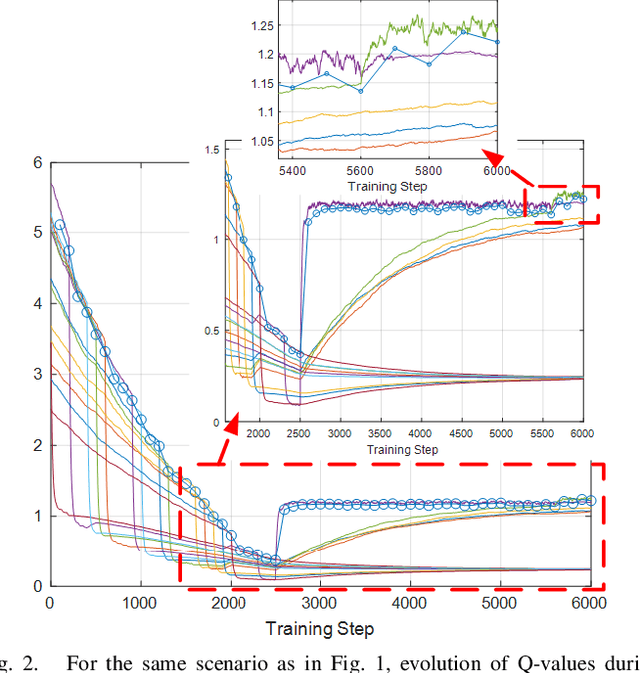
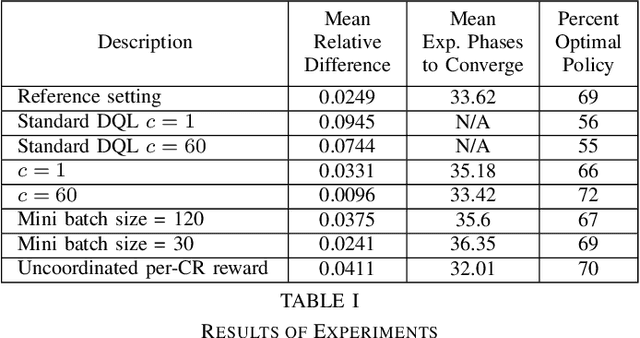
This paper presents a novel deep reinforcement learning-based resource allocation technique for the multi-agent environment presented by a cognitive radio network where the interactions of the agents during learning may lead to a non-stationary environment. The resource allocation technique presented in this work is distributed, not requiring coordination with other agents. It is shown by considering aspects specific to deep reinforcement learning that the presented algorithm converges in an arbitrarily long time to equilibrium policies in a non-stationary multi-agent environment that results from the uncoordinated dynamic interaction between radios through the shared wireless environment. Simulation results show that the presented technique achieves a faster learning performance compared to an equivalent table-based Q-learning algorithm and is able to find the optimal policy in 99% of cases for a sufficiently long learning time. In addition, simulations show that our DQL approach requires less than half the number of learning steps to achieve the same performance as an equivalent table-based implementation. Moreover, it is shown that the use of a standard single-agent deep reinforcement learning approach may not achieve convergence when used in an uncoordinated interacting multi-radio scenario
Improving Variational Autoencoder based Out-of-Distribution Detection for Embedded Real-time Applications
Jul 25, 2021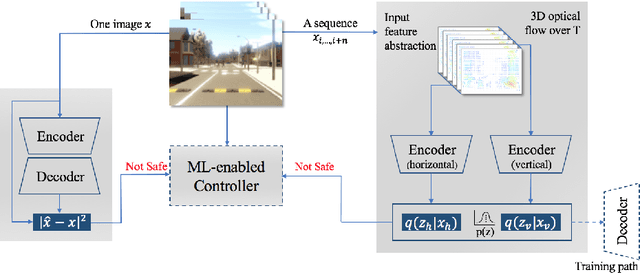
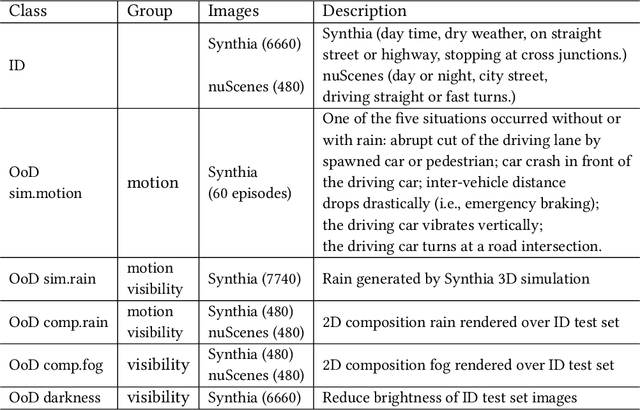

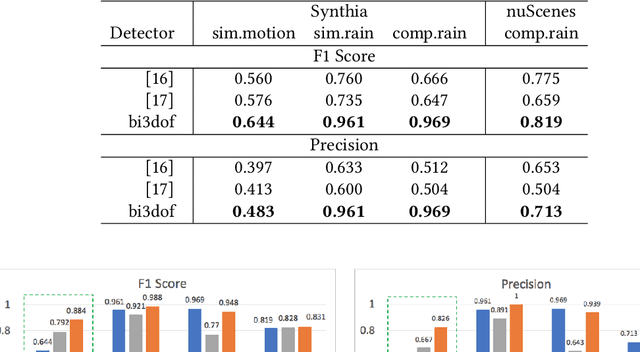
Uncertainties in machine learning are a significant roadblock for its application in safety-critical cyber-physical systems (CPS). One source of uncertainty arises from distribution shifts in the input data between training and test scenarios. Detecting such distribution shifts in real-time is an emerging approach to address the challenge. The high dimensional input space in CPS applications involving imaging adds extra difficulty to the task. Generative learning models are widely adopted for the task, namely out-of-distribution (OoD) detection. To improve the state-of-the-art, we studied existing proposals from both machine learning and CPS fields. In the latter, safety monitoring in real-time for autonomous driving agents has been a focus. Exploiting the spatiotemporal correlation of motion in videos, we can robustly detect hazardous motion around autonomous driving agents. Inspired by the latest advances in the Variational Autoencoder (VAE) theory and practice, we tapped into the prior knowledge in data to further boost OoD detection's robustness. Comparison studies over nuScenes and Synthia data sets show our methods significantly improve detection capabilities of OoD factors unique to driving scenarios, 42% better than state-of-the-art approaches. Our model also generalized near-perfectly, 97% better than the state-of-the-art across the real-world and simulation driving data sets experimented. Finally, we customized one proposed method into a twin-encoder model that can be deployed to resource limited embedded devices for real-time OoD detection. Its execution time was reduced over four times in low-precision 8-bit integer inference, while detection capability is comparable to its corresponding floating-point model.
Variational Quantum Approximate Support Vector Machine With Inference Transfer
Jun 29, 2022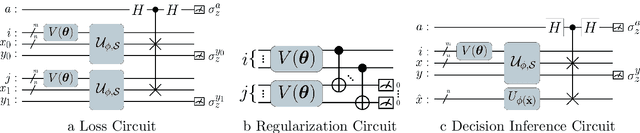
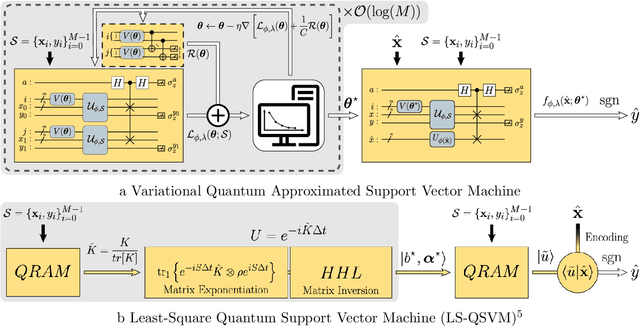
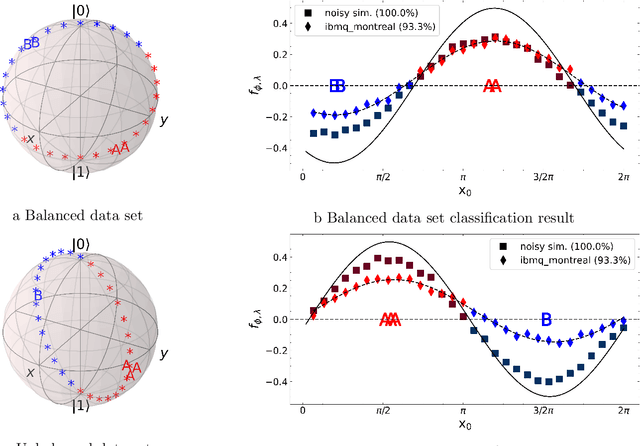
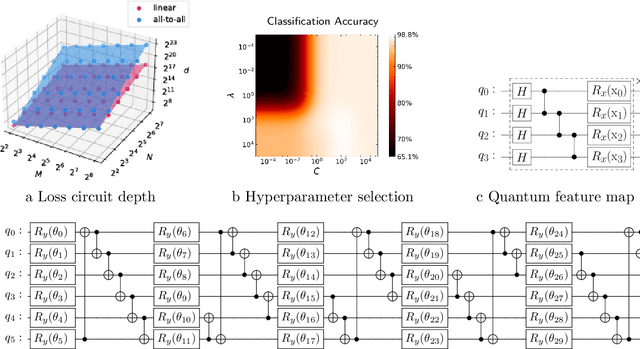
A kernel-based quantum classifier is the most interesting and powerful quantum machine learning technique for hyperlinear classification of complex data, which can be easily realized in shallow-depth quantum circuits such as a SWAP test classifier. Surprisingly, a support vector machine can be realized inherently and explicitly on these circuits by introduction of a variational scheme to map the quadratic optimization problem of the SVM theory to a quantum-classical variational optimization problem. This scheme is realized with parameterized quantum circuits (PQC) to create a nonuniform weight vector to index qubits that can evaluate training loss and classification score in a linear time. We train the classical parameters of this Variational Quantum Approximate Support Vector Machine (VQASVM), which can be transferred to many copies of other VQASVM decision inference circuits for classification of new query data. Our VQASVM algorithm is experimented with toy example data sets on cloud-based quantum machines for feasibility evaluation, and numerically investigated to evaluate its performance on a standard iris flower data set. The accuracy of iris data classification reached 98.8%.