 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Universality and approximation bounds for echo state networks with random weights
Jun 12, 2022
We study the uniform approximation of echo state networks with randomly generated internal weights. These models, in which only the readout weights are optimized during training, have made empirical success in learning dynamical systems. We address the representational capacity of these models by showing that they are universal under weak conditions. Our main result gives a sufficient condition for the activation function and a sampling procedure for the internal weights so that echo state networks can approximate any continuous casual time-invariant operators with high probability. In particular, for ReLU activation, we quantify the approximation error of echo state networks for sufficiently regular operators.
YOLOSA: Object detection based on 2D local feature superimposed self-attention
Jun 23, 2022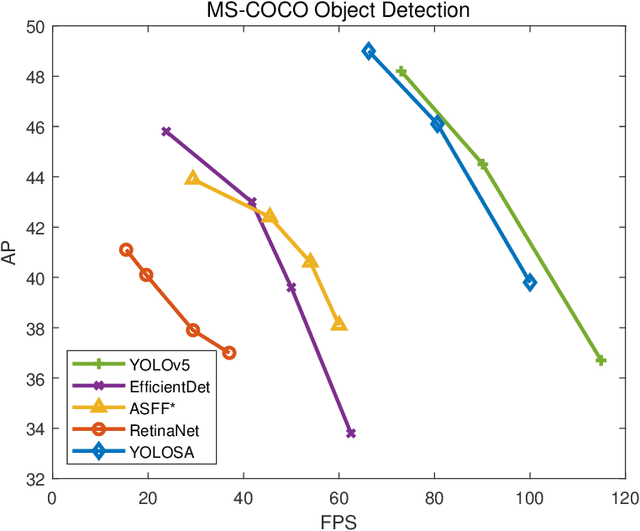
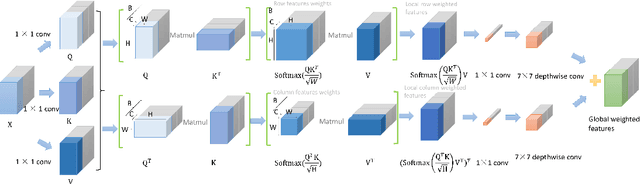

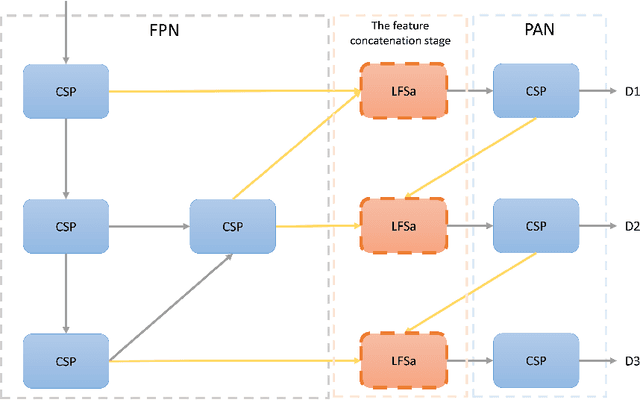
We analyzed the network structure of real-time object detection models and found that the features in the feature concatenation stage are very rich. Applying an attention module here can effectively improve the detection accuracy of the model. However, the commonly used attention module or self-attention module shows poor performance in detection accuracy and inference efficiency. Therefore, we propose a novel self-attention module, called 2D local feature superimposed self-attention, for the feature concatenation stage of the neck network. This self-attention module reflects global features through local features and local receptive fields. We also propose and optimize an efficient decoupled head and AB-OTA, and achieve SOTA results. Average precisions of 49.0\% (66.2 FPS), 46.1\% (80.6 FPS), and 39.1\% (100 FPS) were obtained for large, medium, and small-scale models built using our proposed improvements. Our models exceeded YOLOv5 by 0.8\% -- 3.1\% in average precision.
Rethinking Audio-visual Synchronization for Active Speaker Detection
Jun 21, 2022
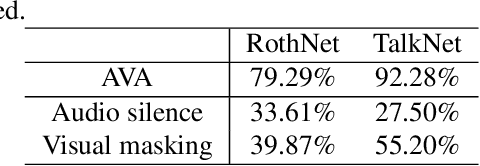

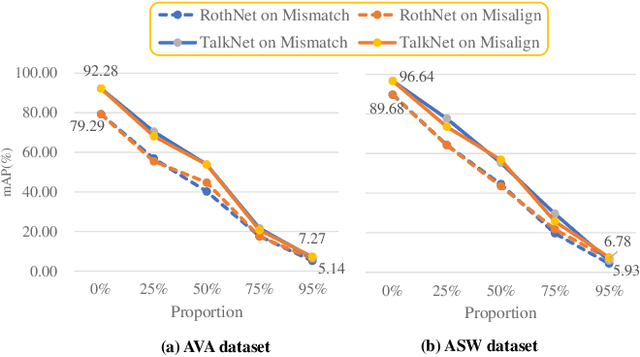
Active speaker detection (ASD) systems are important modules for analyzing multi-talker conversations. They aim to detect which speakers or none are talking in a visual scene at any given time. Existing research on ASD does not agree on the definition of active speakers. We clarify the definition in this work and require synchronization between the audio and visual speaking activities. This clarification of definition is motivated by our extensive experiments, through which we discover that existing ASD methods fail in modeling the audio-visual synchronization and often classify unsynchronized videos as active speaking. To address this problem, we propose a cross-modal contrastive learning strategy and apply positional encoding in attention modules for supervised ASD models to leverage the synchronization cue. Experimental results suggest that our model can successfully detect unsynchronized speaking as not speaking, addressing the limitation of current models.
Variational Quantum Approximate Support Vector Machine With Inference Transfer
Jun 29, 2022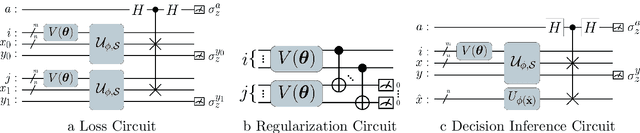
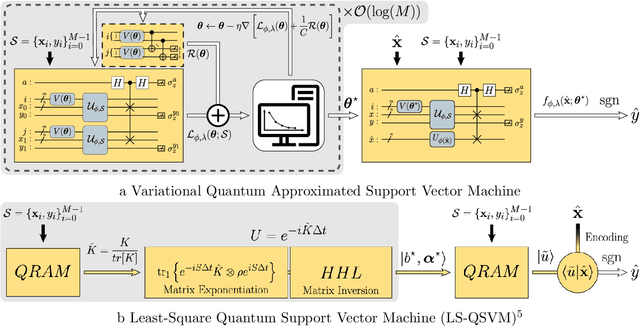
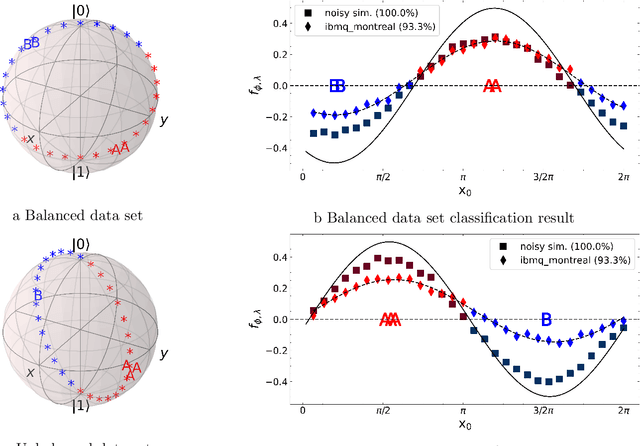
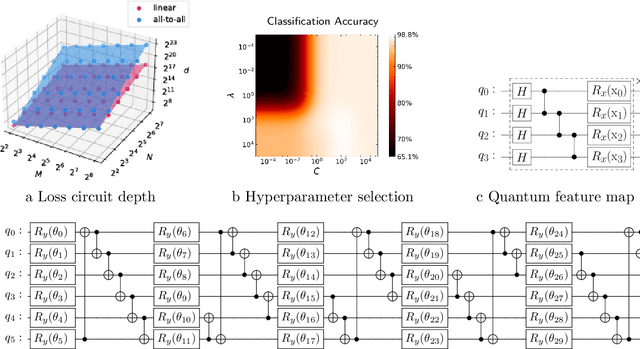
A kernel-based quantum classifier is the most interesting and powerful quantum machine learning technique for hyperlinear classification of complex data, which can be easily realized in shallow-depth quantum circuits such as a SWAP test classifier. Surprisingly, a support vector machine can be realized inherently and explicitly on these circuits by introduction of a variational scheme to map the quadratic optimization problem of the SVM theory to a quantum-classical variational optimization problem. This scheme is realized with parameterized quantum circuits (PQC) to create a nonuniform weight vector to index qubits that can evaluate training loss and classification score in a linear time. We train the classical parameters of this Variational Quantum Approximate Support Vector Machine (VQASVM), which can be transferred to many copies of other VQASVM decision inference circuits for classification of new query data. Our VQASVM algorithm is experimented with toy example data sets on cloud-based quantum machines for feasibility evaluation, and numerically investigated to evaluate its performance on a standard iris flower data set. The accuracy of iris data classification reached 98.8%.
Safety Certification for Stochastic Systems via Neural Barrier Functions
Jun 03, 2022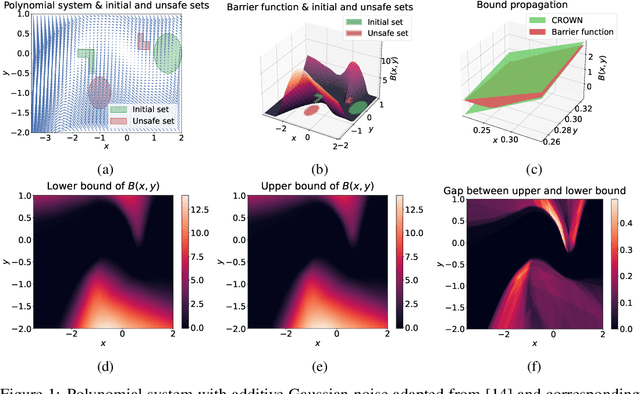
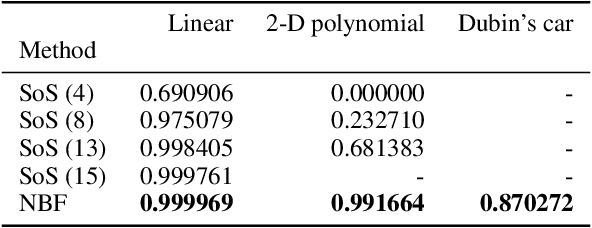
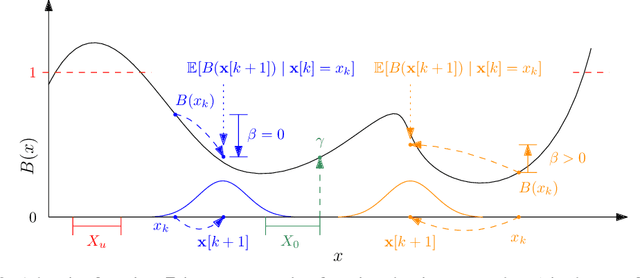
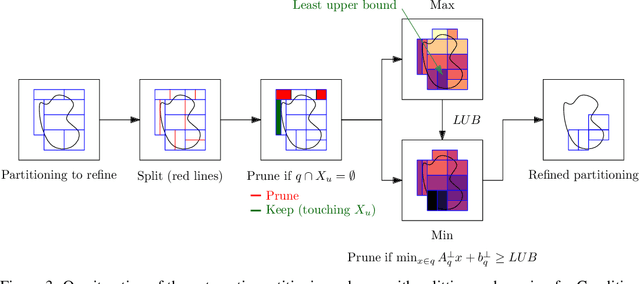
Providing non-trivial certificates of safety for non-linear stochastic systems is an important open problem that limits the wider adoption of autonomous systems in safety-critical applications. One promising solution to address this problem is barrier functions. The composition of a barrier function with a stochastic system forms a supermartingale, thus enabling the computation of the probability that the system stays in a safe set over a finite time horizon via martingale inequalities. However, existing approaches to find barrier functions for stochastic systems generally rely on convex optimization programs that restrict the search of a barrier to a small class of functions such as low degree SoS polynomials and can be computationally expensive. In this paper, we parameterize a barrier function as a neural network and show that techniques for robust training of neural networks can be successfully employed to find neural barrier functions. Specifically, we leverage bound propagation techniques to certify that a neural network satisfies the conditions to be a barrier function via linear programming and then employ the resulting bounds at training time to enforce the satisfaction of these conditions. We also present a branch-and-bound scheme that makes the certification framework scalable. We show that our approach outperforms existing methods in several case studies and often returns certificates of safety that are orders of magnitude larger.
Automated Mobility Context Detection with Inertial Signals
May 16, 2022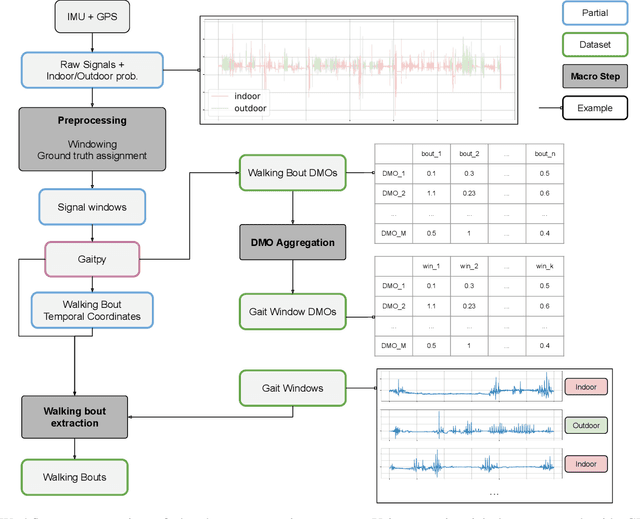
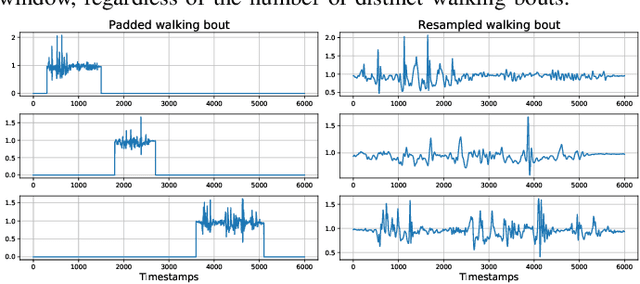
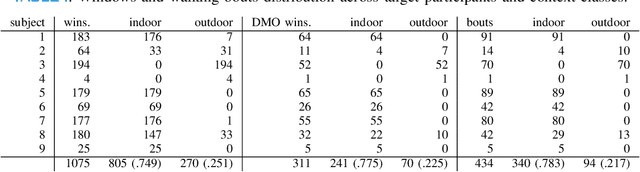
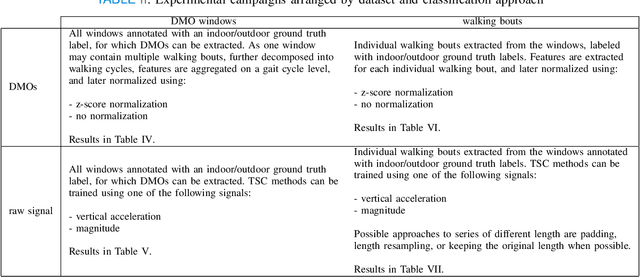
Remote monitoring of motor functions is a powerful approach for health assessment, especially among the elderly population or among subjects affected by pathologies that negatively impact their walking capabilities. This is further supported by the continuous development of wearable sensor devices, which are getting progressively smaller, cheaper, and more energy efficient. The external environment and mobility context have an impact on walking performance, hence one of the biggest challenges when remotely analysing gait episodes is the ability to detect the context within which those episodes occurred. The primary goal of this paper is the investigation of context detection for remote monitoring of daily motor functions. We aim to understand whether inertial signals sampled with wearable accelerometers, provide reliable information to classify gait-related activities as either indoor or outdoor. We explore two different approaches to this task: (1) using gait descriptors and features extracted from the input inertial signals sampled during walking episodes, together with classic machine learning algorithms, and (2) treating the input inertial signals as time series data and leveraging end-to-end state-of-the-art time series classifiers. We directly compare the two approaches through a set of experiments based on data collected from 9 healthy individuals. Our results indicate that the indoor/outdoor context can be successfully derived from inertial data streams. We also observe that time series classification models achieve better accuracy than any other feature-based models, while preserving efficiency and ease of use.
Explainable vision transformer enabled convolutional neural network for plant disease identification: PlantXViT
Jul 16, 2022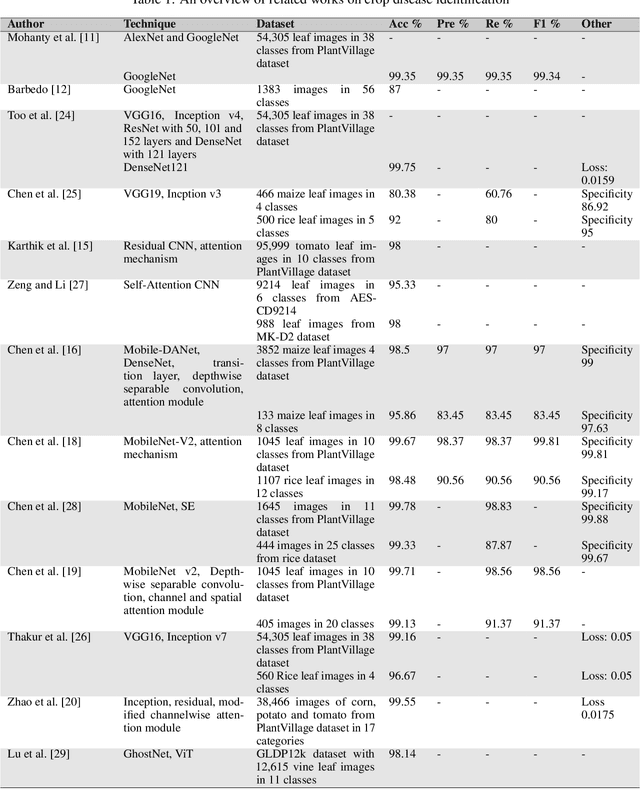
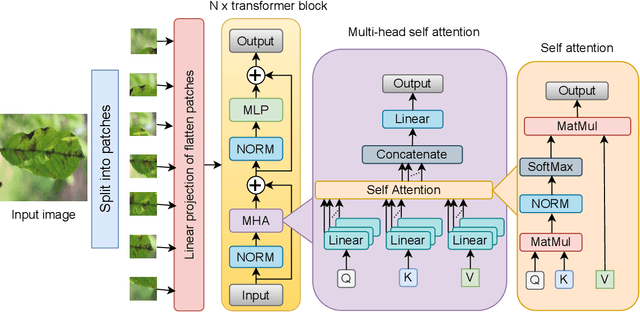
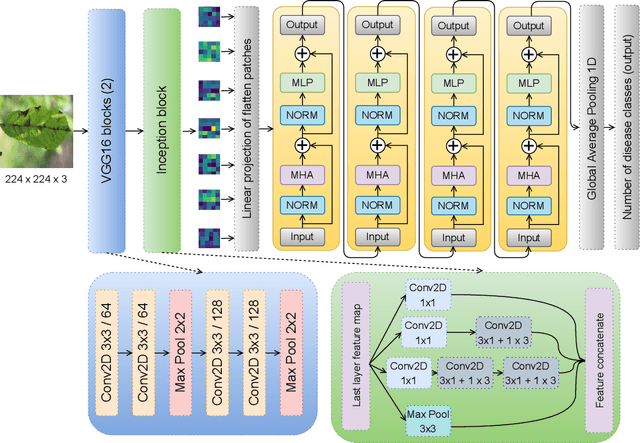
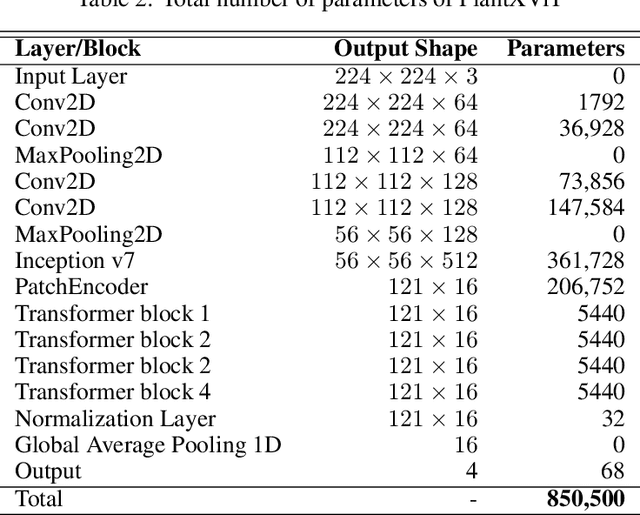
Plant diseases are the primary cause of crop losses globally, with an impact on the world economy. To deal with these issues, smart agriculture solutions are evolving that combine the Internet of Things and machine learning for early disease detection and control. Many such systems use vision-based machine learning methods for real-time disease detection and diagnosis. With the advancement in deep learning techniques, new methods have emerged that employ convolutional neural networks for plant disease detection and identification. Another trend in vision-based deep learning is the use of vision transformers, which have proved to be powerful models for classification and other problems. However, vision transformers have rarely been investigated for plant pathology applications. In this study, a Vision Transformer enabled Convolutional Neural Network model called "PlantXViT" is proposed for plant disease identification. The proposed model combines the capabilities of traditional convolutional neural networks with the Vision Transformers to efficiently identify a large number of plant diseases for several crops. The proposed model has a lightweight structure with only 0.8 million trainable parameters, which makes it suitable for IoT-based smart agriculture services. The performance of PlantXViT is evaluated on five publicly available datasets. The proposed PlantXViT network performs better than five state-of-the-art methods on all five datasets. The average accuracy for recognising plant diseases is shown to exceed 93.55%, 92.59%, and 98.33% on Apple, Maize, and Rice datasets, respectively, even under challenging background conditions. The efficiency in terms of explainability of the proposed model is evaluated using gradient-weighted class activation maps and Local Interpretable Model Agnostic Explanation.
Online and Real-Time Tracking in a Surveillance Scenario
Jun 02, 2021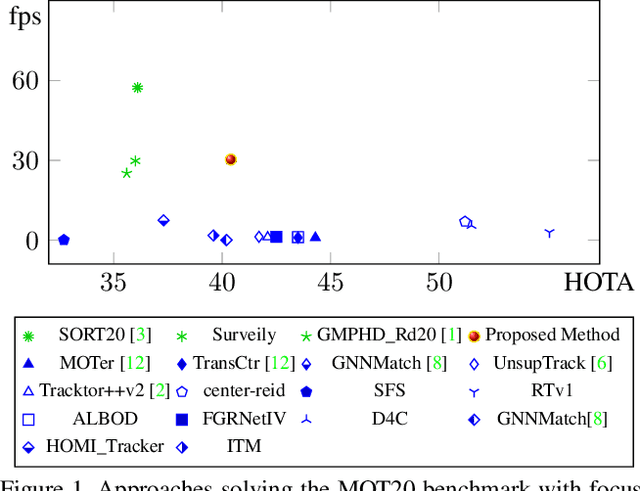
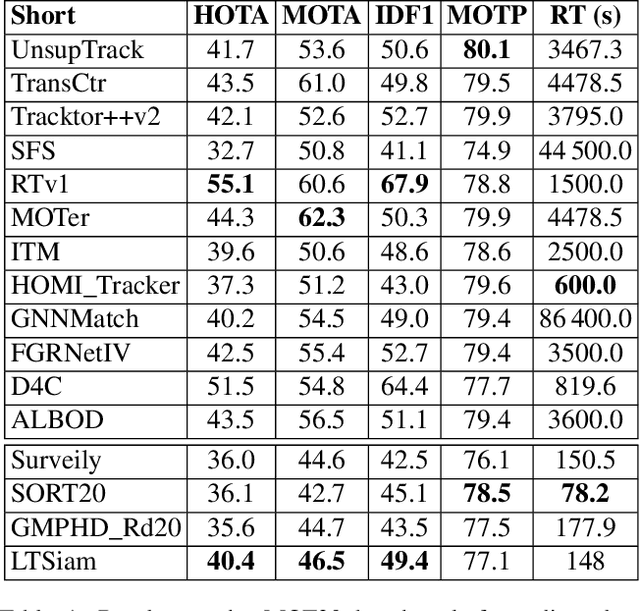
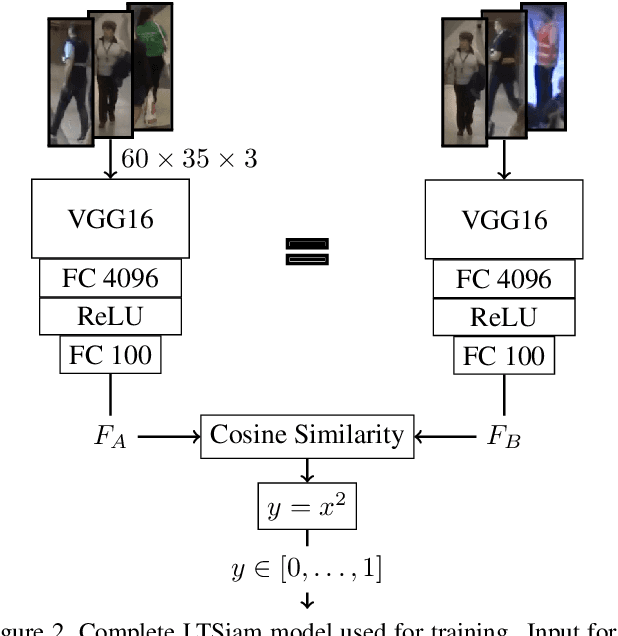
This paper presents an approach for tracking in a surveillance scenario. Typical aspects for this scenario are a 24/7 operation with a static camera mounted above the height of a human with many objects or people. The Multiple Object Tracking Benchmark 20 (MOT20) reflects this scenario best. We can show that our approach is real-time capable on this benchmark and outperforms all other real-time capable approaches in HOTA, MOTA, and IDF1. We achieve this by contributing a fast Siamese network reformulated for linear runtime (instead of quadratic) to generate fingerprints from detections. Thus, it is possible to associate the detections to Kalman filters based on multiple tracking specific ratings: Cosine similarity of fingerprints, Intersection over Union, and pixel distance ratio in the image.
Microsimulation of Space Time Trellis Code
Feb 25, 2021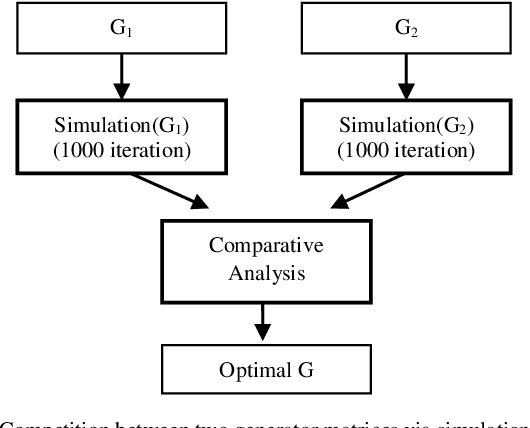

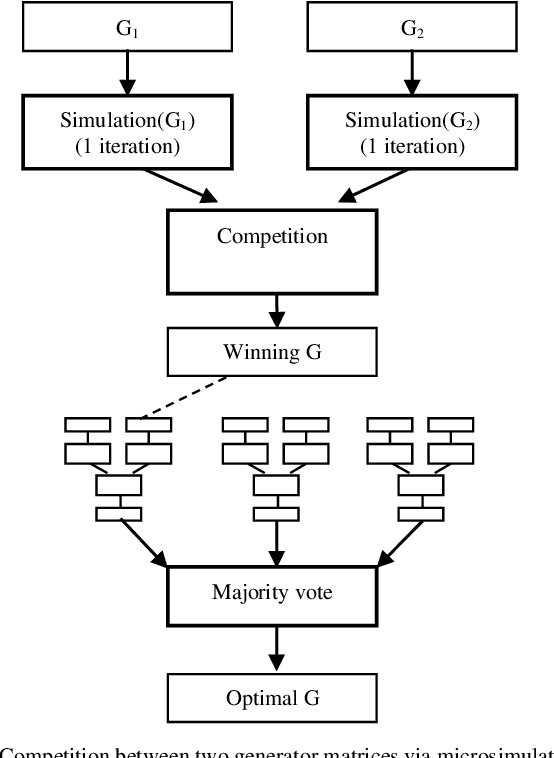

This letter explores the possibility of using microsimulation in space time trellis code. Performing a pairwise comparison between generator matrices is essential in the validation of optimality. This is often done with simulation, which can be a time consuming process altogether. Microsimulation considerably cuts down the computational cost of simulation by employing smaller data and iteration. The effort is feasible with the assistance of a machine learning model known as multilayer perceptron. When properly conducted, it can offer 93.86% accuracy and 98.25% reduction in temporal cost.
Incorporating Voice Instructions in Model-Based Reinforcement Learning for Self-Driving Cars
Jun 21, 2022
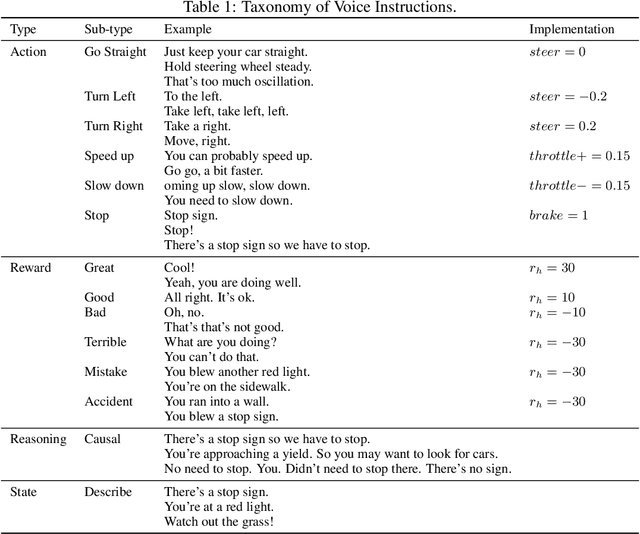
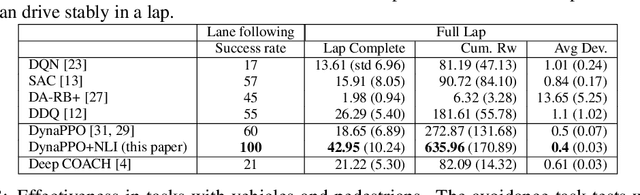
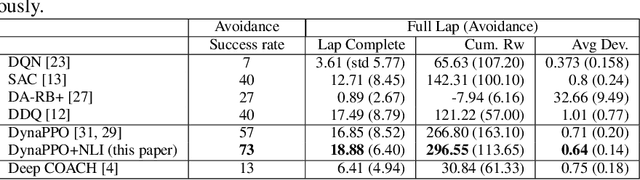
This paper presents a novel approach that supports natural language voice instructions to guide deep reinforcement learning (DRL) algorithms when training self-driving cars. DRL methods are popular approaches for autonomous vehicle (AV) agents. However, most existing methods are sample- and time-inefficient and lack a natural communication channel with the human expert. In this paper, how new human drivers learn from human coaches motivates us to study new ways of human-in-the-loop learning and a more natural and approachable training interface for the agents. We propose incorporating natural language voice instructions (NLI) in model-based deep reinforcement learning to train self-driving cars. We evaluate the proposed method together with a few state-of-the-art DRL methods in the CARLA simulator. The results show that NLI can help ease the training process and significantly boost the agents' learning speed.