 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
MAS2HP: A Multi Agent System to predict protein structure in 2D HP model
May 11, 2022
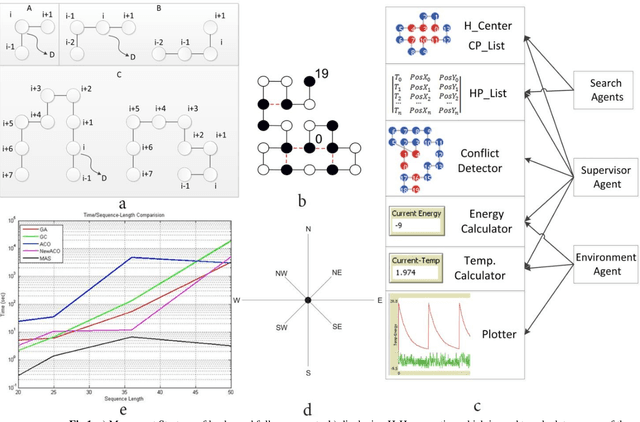
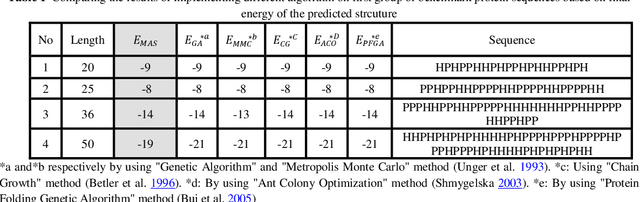
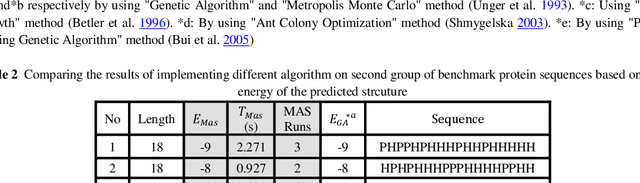
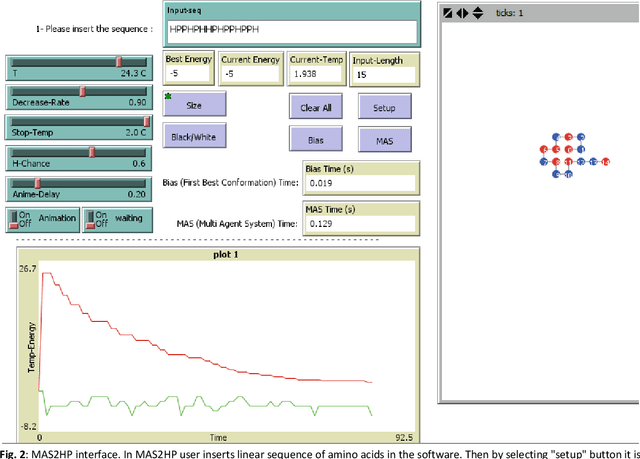
Protein Structure Prediction (PSP) is an unsolved problem in the field of computational biology. The problem of protein structure prediction is about predicting the native conformation of a protein, while its sequence of amino acids is known. Regarding processing limitations of current computer systems, all-atom simulations for proteins are typically unpractical; several reduced models of proteins have been proposed. Additionally, due to intrinsic hardness of calculations even in reduced models, many computational methods mainly based on artificial intelligence have been proposed to solve the problem. Agent-based modeling is a relatively new method for modeling systems composed of interacting items. In this paper we proposed a new approach for protein structure prediction by using agent-based modeling (ABM) in two dimensional hydrophobic-hydrophilic model. We broke the whole process of protein structure prediction into two steps: the first step, which was introduced in our previous paper, is about biasing the linear sequence to gain a primary energy, and the next step, which will be explained in this paper, is about using ABM with a predefined set of rules, to find the best conformation in the least possible amount of time and steps. This method was implemented in NETLOGO. We have tested this algorithm on several benchmark sequences ranging from 20 to 50-mers in two dimensional Hydrophobic-Hydrophilic lattice models. Comparing to the result of the other algorithms, our method is capable of finding the best known conformations in a significantly shorter time. A major problem in PSP simulation is that as the sequence length increases the time consumed to predict a valid structure will exponentially increase. In contrast, by using MAS2HP the effect of increase in sequence length on spent time has changed from exponentially to linear.
Computer Vision for Volunteer Cotton Detection in a Corn Field with UAS Remote Sensing Imagery and Spot Spray Applications
Jul 15, 2022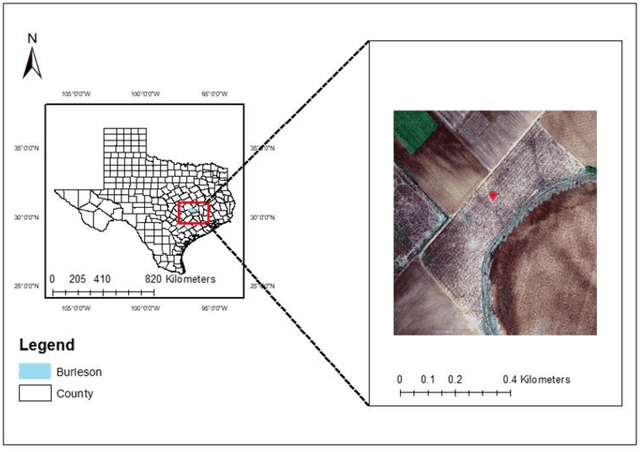
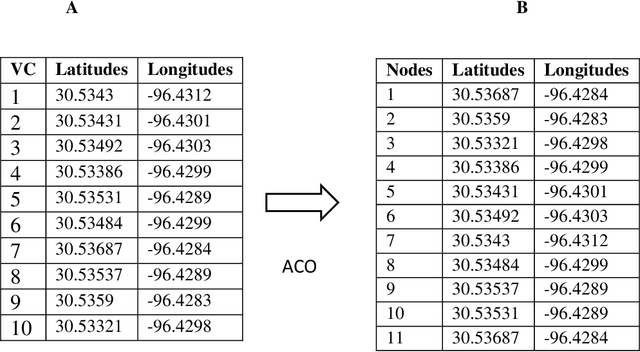


To control boll weevil (Anthonomus grandis L.) pest re-infestation in cotton fields, the current practices of volunteer cotton (VC) (Gossypium hirsutum L.) plant detection in fields of rotation crops like corn (Zea mays L.) and sorghum (Sorghum bicolor L.) involve manual field scouting at the edges of fields. This leads to many VC plants growing in the middle of fields remain undetected that continue to grow side by side along with corn and sorghum. When they reach pinhead squaring stage (5-6 leaves), they can serve as hosts for the boll weevil pests. Therefore, it is required to detect, locate and then precisely spot-spray them with chemicals. In this paper, we present the application of YOLOv5m on radiometrically and gamma-corrected low resolution (1.2 Megapixel) multispectral imagery for detecting and locating VC plants growing in the middle of tasseling (VT) growth stage of cornfield. Our results show that VC plants can be detected with a mean average precision (mAP) of 79% and classification accuracy of 78% on images of size 1207 x 923 pixels at an average inference speed of nearly 47 frames per second (FPS) on NVIDIA Tesla P100 GPU-16GB and 0.4 FPS on NVIDIA Jetson TX2 GPU. We also demonstrate the application of a customized unmanned aircraft systems (UAS) for spot-spray applications based on the developed computer vision (CV) algorithm and how it can be used for near real-time detection and mitigation of VC plants growing in corn fields for efficient management of the boll weevil pests.
GACT: Activation Compressed Training for General Architectures
Jun 22, 2022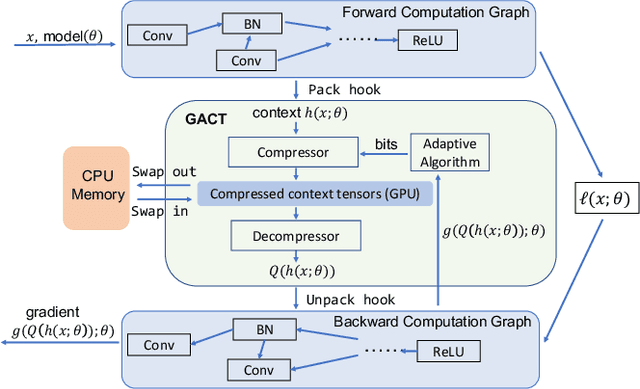
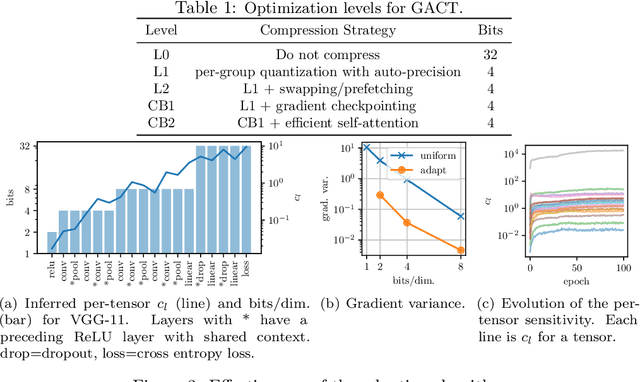

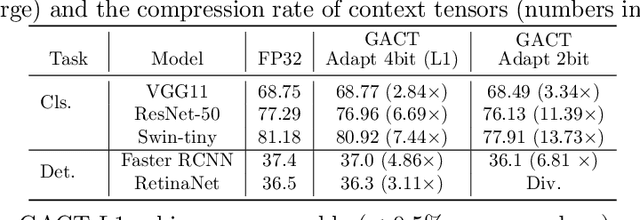
Training large neural network (NN) models requires extensive memory resources, and Activation Compressed Training (ACT) is a promising approach to reduce training memory footprint. This paper presents GACT, an ACT framework to support a broad range of machine learning tasks for generic NN architectures with limited domain knowledge. By analyzing a linearized version of ACT's approximate gradient, we prove the convergence of GACT without prior knowledge on operator type or model architecture. To make training stable, we propose an algorithm that decides the compression ratio for each tensor by estimating its impact on the gradient at run time. We implement GACT as a PyTorch library that readily applies to any NN architecture. GACT reduces the activation memory for convolutional NNs, transformers, and graph NNs by up to 8.1x, enabling training with a 4.2x to 24.7x larger batch size, with negligible accuracy loss.
All-Clear Flare Prediction Using Interval-based Time Series Classifiers
May 03, 2021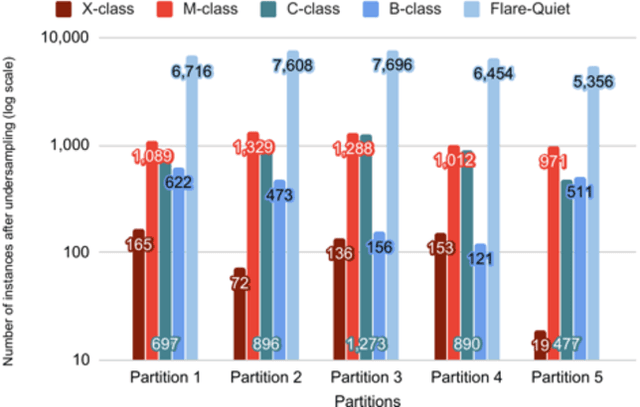
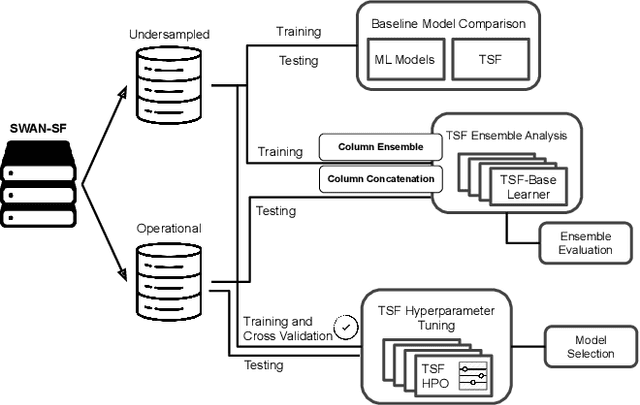
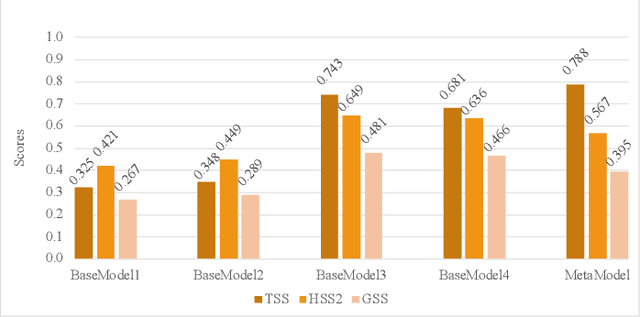
An all-clear flare prediction is a type of solar flare forecasting that puts more emphasis on predicting non-flaring instances (often relatively small flares and flare quiet regions) with high precision while still maintaining valuable predictive results. While many flare prediction studies do not address this problem directly, all-clear predictions can be useful in operational context. However, in all-clear predictions, finding the right balance between avoiding false negatives (misses) and reducing the false positives (false alarms) is often challenging. Our study focuses on training and testing a set of interval-based time series classifiers named Time Series Forest (TSF). These classifiers will be used towards building an all-clear flare prediction system by utilizing multivariate time series data. Throughout this paper, we demonstrate our data collection, predictive model building and evaluation processes, and compare our time series classification models with baselines using our benchmark datasets. Our results show that time series classifiers provide better forecasting results in terms of skill scores, precision and recall metrics, and they can be further improved for more precise all-clear forecasts by tuning model hyperparameters.
Automatic Contact Tracing using Bluetooth Low Energy Signals and IMU Sensor Readings
Jun 13, 2022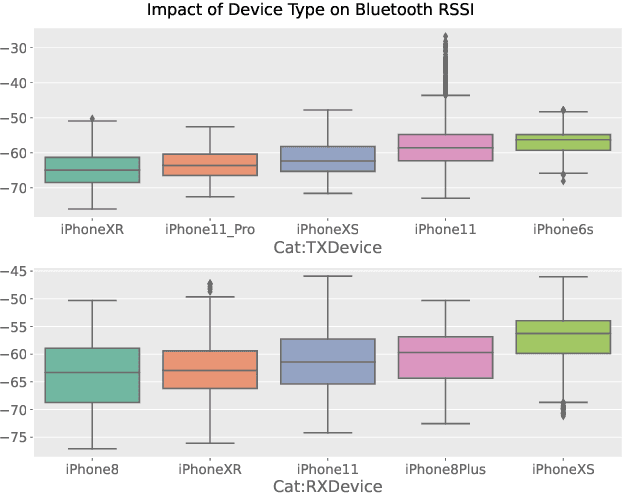
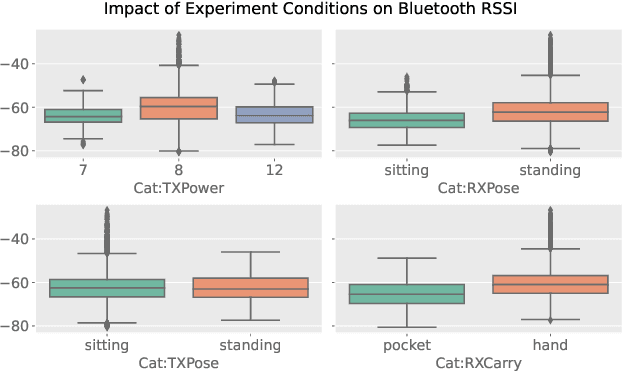
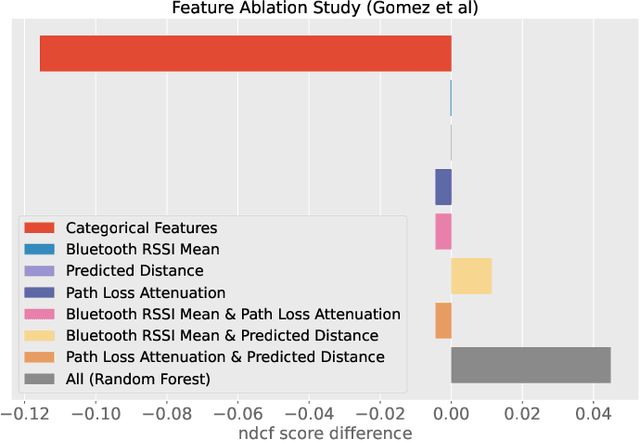
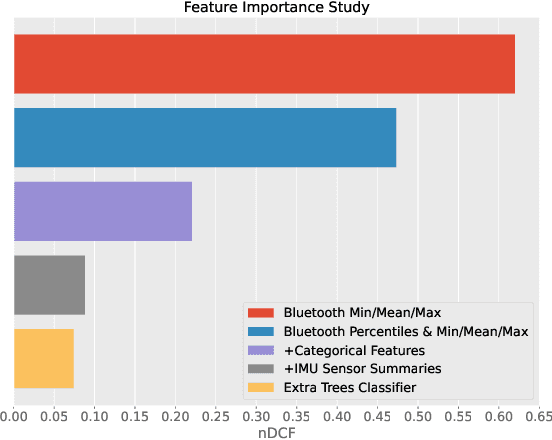
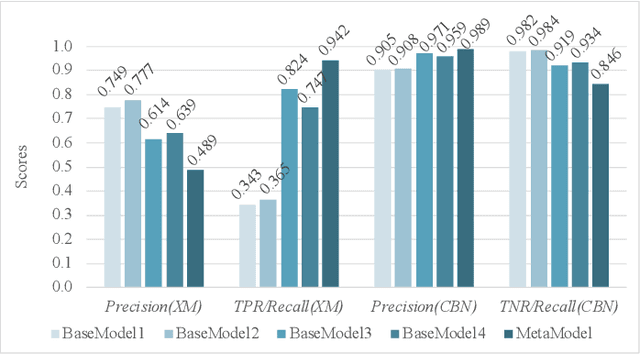
In this report, we present our solution to the challenge provided by the SFI Centre for Machine Learning (ML-Labs) in which the distance between two phones needs to be estimated. It is a modified version of the NIST Too Close For Too Long (TC4TL) Challenge, as the time aspect is excluded. We propose a feature-based approach based on Bluetooth RSSI and IMU sensory data, that outperforms the previous state of the art by a significant margin, reducing the error down to 0.071. We perform an ablation study of our model that reveals interesting insights about the relationship between the distance and the Bluetooth RSSI readings.
Interpolating Compressed Parameter Subspaces
May 19, 2022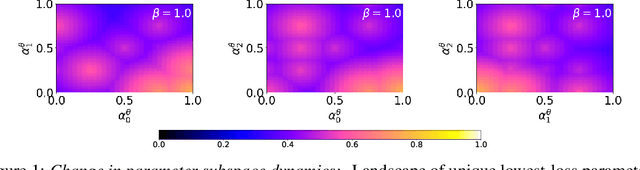
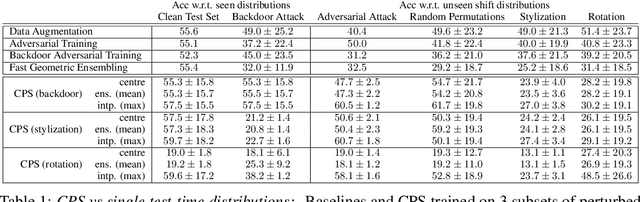
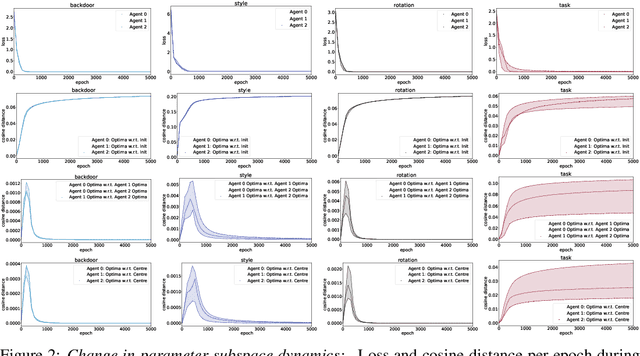
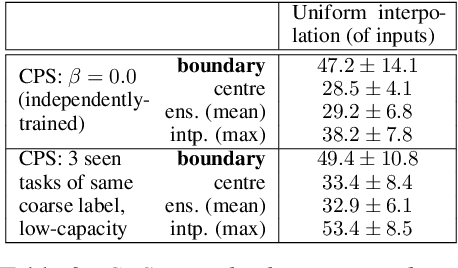
Inspired by recent work on neural subspaces and mode connectivity, we revisit parameter subspace sampling for shifted and/or interpolatable input distributions (instead of a single, unshifted distribution). We enforce a compressed geometric structure upon a set of trained parameters mapped to a set of train-time distributions, denoting the resulting subspaces as Compressed Parameter Subspaces (CPS). We show the success and failure modes of the types of shifted distributions whose optimal parameters reside in the CPS. We find that ensembling point-estimates within a CPS can yield a high average accuracy across a range of test-time distributions, including backdoor, adversarial, permutation, stylization and rotation perturbations. We also find that the CPS can contain low-loss point-estimates for various task shifts (albeit interpolated, perturbed, unseen or non-identical coarse labels). We further demonstrate this property in a continual learning setting with CIFAR100.
TINC: Temporally Informed Non-Contrastive Learning for Disease Progression Modeling in Retinal OCT Volumes
Jun 30, 2022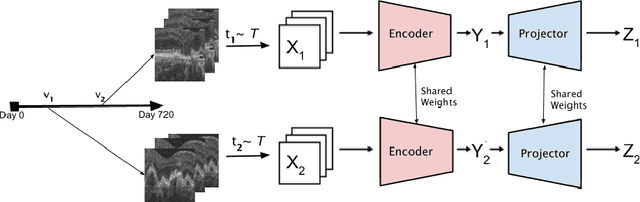

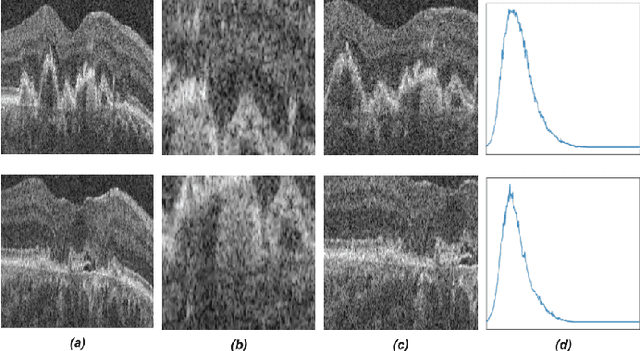

Recent contrastive learning methods achieved state-of-the-art in low label regimes. However, the training requires large batch sizes and heavy augmentations to create multiple views of an image. With non-contrastive methods, the negatives are implicitly incorporated in the loss, allowing different images and modalities as pairs. Although the meta-information (i.e., age, sex) in medical imaging is abundant, the annotations are noisy and prone to class imbalance. In this work, we exploited already existing temporal information (different visits from a patient) in a longitudinal optical coherence tomography (OCT) dataset using temporally informed non-contrastive loss (TINC) without increasing complexity and need for negative pairs. Moreover, our novel pair-forming scheme can avoid heavy augmentations and implicitly incorporates the temporal information in the pairs. Finally, these representations learned from the pretraining are more successful in predicting disease progression where the temporal information is crucial for the downstream task. More specifically, our model outperforms existing models in predicting the risk of conversion within a time frame from intermediate age-related macular degeneration (AMD) to the late wet-AMD stage.
Device-Cloud Collaborative Recommendation via Meta Controller
Jul 07, 2022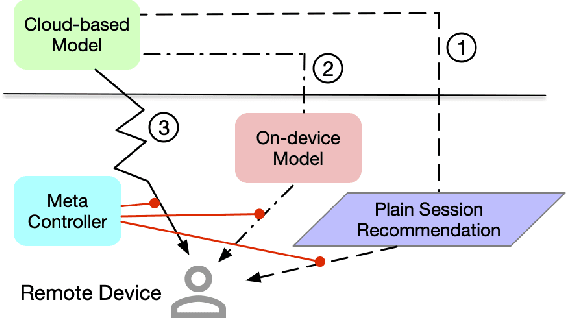
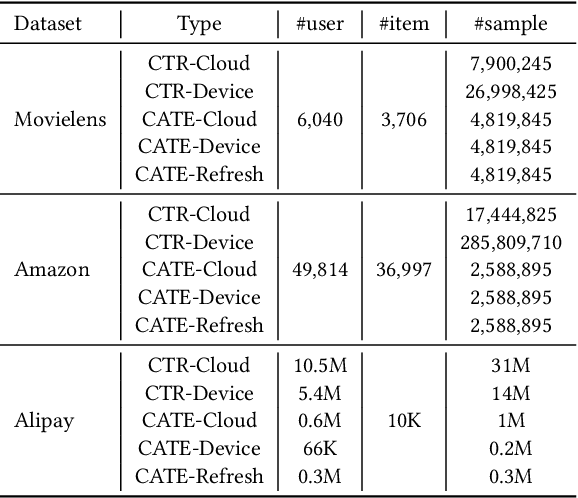
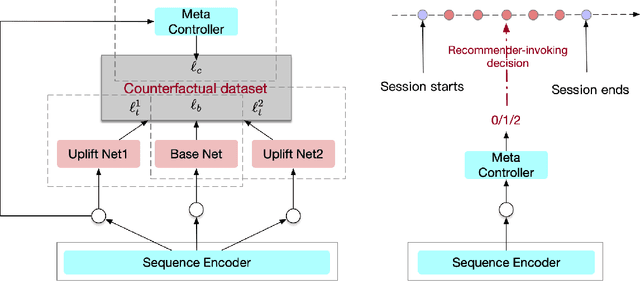
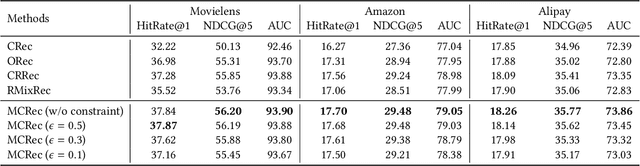
On-device machine learning enables the lightweight deployment of recommendation models in local clients, which reduces the burden of the cloud-based recommenders and simultaneously incorporates more real-time user features. Nevertheless, the cloud-based recommendation in the industry is still very important considering its powerful model capacity and the efficient candidate generation from the billion-scale item pool. Previous attempts to integrate the merits of both paradigms mainly resort to a sequential mechanism, which builds the on-device recommender on top of the cloud-based recommendation. However, such a design is inflexible when user interests dramatically change: the on-device model is stuck by the limited item cache while the cloud-based recommendation based on the large item pool do not respond without the new re-fresh feedback. To overcome this issue, we propose a meta controller to dynamically manage the collaboration between the on-device recommender and the cloud-based recommender, and introduce a novel efficient sample construction from the causal perspective to solve the dataset absence issue of meta controller. On the basis of the counterfactual samples and the extended training, extensive experiments in the industrial recommendation scenarios show the promise of meta controller in the device-cloud collaboration.
Localizing the Recurrent Laryngeal Nerve via Ultrasound with a Bayesian Shape Framework
Jun 30, 2022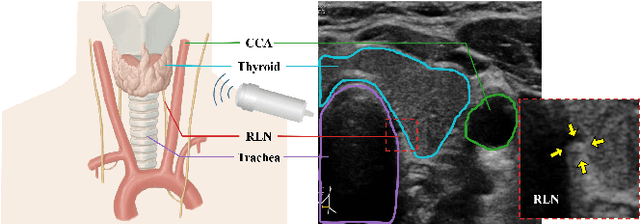
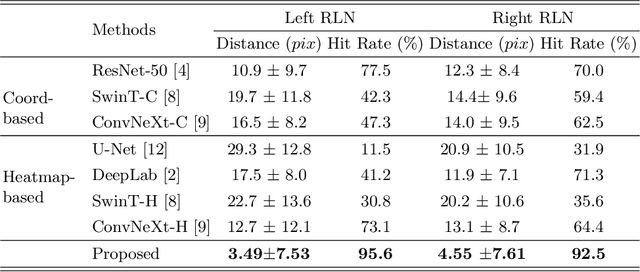
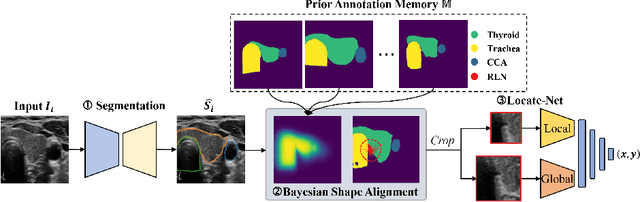
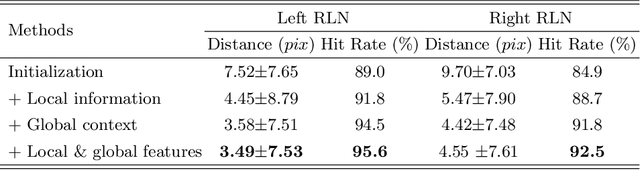
Tumor infiltration of the recurrent laryngeal nerve (RLN) is a contraindication for robotic thyroidectomy and can be difficult to detect via standard laryngoscopy. Ultrasound (US) is a viable alternative for RLN detection due to its safety and ability to provide real-time feedback. However, the tininess of the RLN, with a diameter typically less than 3mm, poses significant challenges to the accurate localization of the RLN. In this work, we propose a knowledge-driven framework for RLN localization, mimicking the standard approach surgeons take to identify the RLN according to its surrounding organs. We construct a prior anatomical model based on the inherent relative spatial relationships between organs. Through Bayesian shape alignment (BSA), we obtain the candidate coordinates of the center of a region of interest (ROI) that encloses the RLN. The ROI allows a decreased field of view for determining the refined centroid of the RLN using a dual-path identification network, based on multi-scale semantic information. Experimental results indicate that the proposed method achieves superior hit rates and substantially smaller distance errors compared with state-of-the-art methods.
CTrGAN: Cycle Transformers GAN for Gait Transfer
Jun 30, 2022
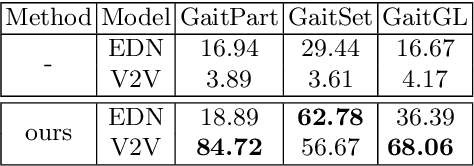
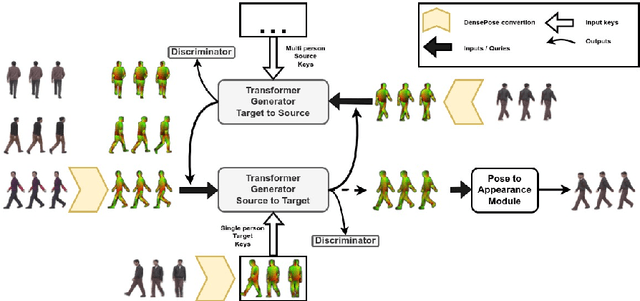
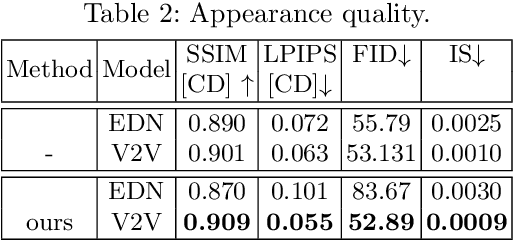
We attempt for the first time to address the problem of gait transfer. In contrast to motion transfer, the objective here is not to imitate the source's normal motions, but rather to transform the source's motion into a typical gait pattern for the target. Using gait recognition models, we demonstrate that existing techniques yield a discrepancy that can be easily detected. We introduce a novel model, Cycle Transformers GAN (CTrGAN), that can successfully generate the target's natural gait. CTrGAN's generators consist of a decoder and encoder, both Transformers, where the attention is on the temporal domain between complete images rather than the spatial domain between patches. While recent Transformer studies in computer vision mainly focused on discriminative tasks, we introduce an architecture that can be applied to synthesis tasks. Using a widely-used gait recognition dataset, we demonstrate that our approach is capable of producing over an order of magnitude more realistic personalized gaits than existing methods, even when used with sources that were not available during training.