 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
CROM: Continuous Reduced-Order Modeling of PDEs Using Implicit Neural Representations
Jun 06, 2022
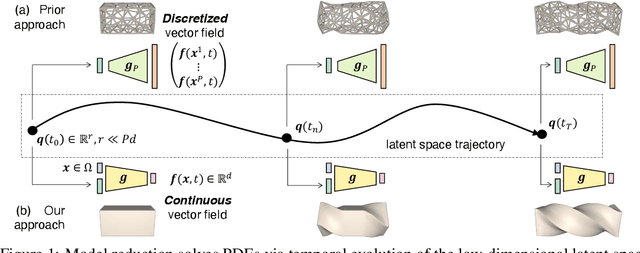
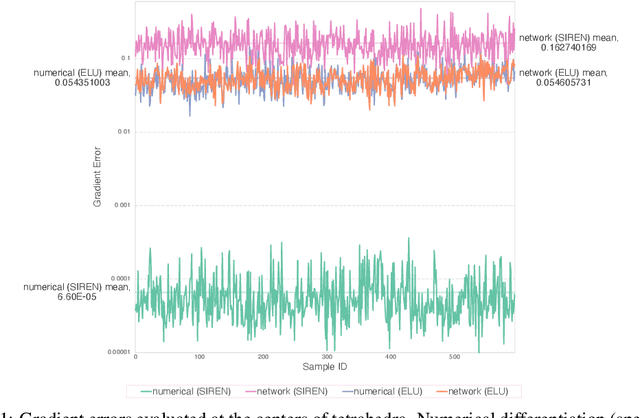
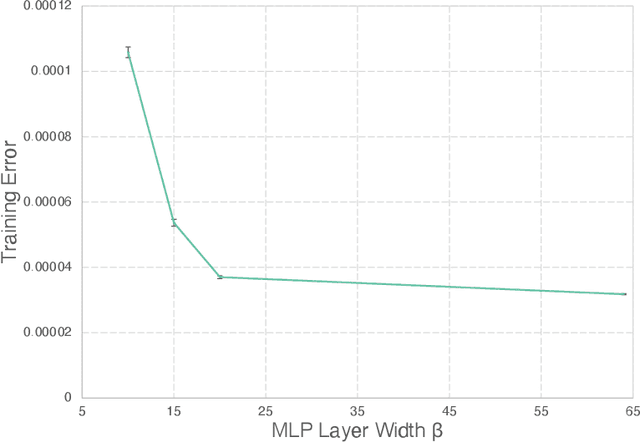

The excessive runtime of high-fidelity partial differential equation (PDE) solvers makes them unsuitable for time-critical applications. We propose to accelerate PDE solvers using reduced-order modeling (ROM). Whereas prior ROM approaches reduce the dimensionality of discretized vector fields, our continuous reduced-order modeling (CROM) approach builds a smooth, low-dimensional manifold of the continuous vector fields themselves, not their discretization. We represent this reduced manifold using neural fields, relying on their continuous and differentiable nature to efficiently solve the PDEs. CROM may train on any and all available numerical solutions of the continuous system, even when they are obtained using diverse methods or discretizations. After the low-dimensional manifolds are built, solving PDEs requires significantly less computational resources. Since CROM is discretization-agnostic, CROM-based PDE solvers may optimally adapt discretization resolution over time to economize computation. We validate our approach on an extensive range of PDEs with training data from voxel grids, meshes, and point clouds. Large-scale experiments demonstrate that our approach obtains speed, memory, and accuracy advantages over prior ROM approaches while gaining 109$\times$ wall-clock speedup over full-order models on CPUs and 89$\times$ speedup on GPUs.
GLEAM: Greedy Learning for Large-Scale Accelerated MRI Reconstruction
Jul 18, 2022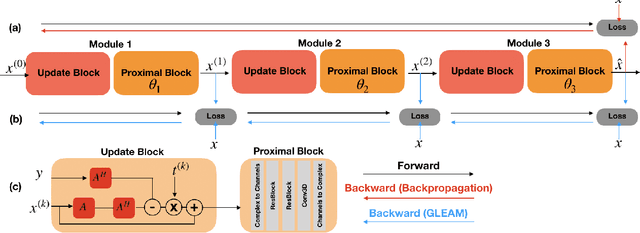
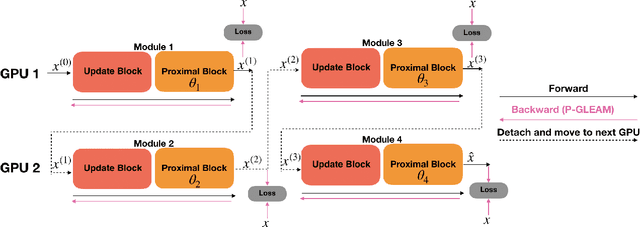
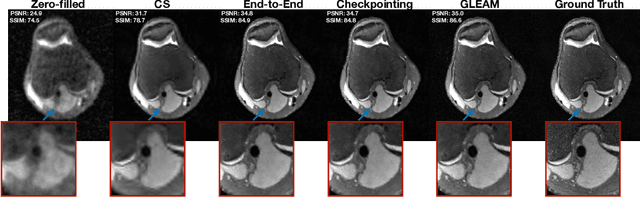
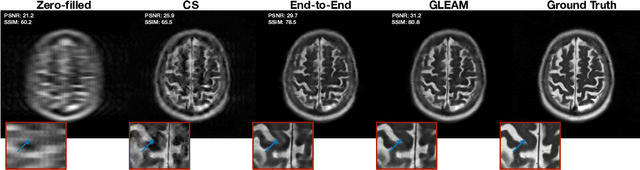
Unrolled neural networks have recently achieved state-of-the-art accelerated MRI reconstruction. These networks unroll iterative optimization algorithms by alternating between physics-based consistency and neural-network based regularization. However, they require several iterations of a large neural network to handle high-dimensional imaging tasks such as 3D MRI. This limits traditional training algorithms based on backpropagation due to prohibitively large memory and compute requirements for calculating gradients and storing intermediate activations. To address this challenge, we propose Greedy LEarning for Accelerated MRI (GLEAM) reconstruction, an efficient training strategy for high-dimensional imaging settings. GLEAM splits the end-to-end network into decoupled network modules. Each module is optimized in a greedy manner with decoupled gradient updates, reducing the memory footprint during training. We show that the decoupled gradient updates can be performed in parallel on multiple graphical processing units (GPUs) to further reduce training time. We present experiments with 2D and 3D datasets including multi-coil knee, brain, and dynamic cardiac cine MRI. We observe that: i) GLEAM generalizes as well as state-of-the-art memory-efficient baselines such as gradient checkpointing and invertible networks with the same memory footprint, but with 1.3x faster training; ii) for the same memory footprint, GLEAM yields 1.1dB PSNR gain in 2D and 1.8 dB in 3D over end-to-end baselines.
Stronger Together: Air-Ground Robotic Collaboration Using Semantics
Jun 28, 2022
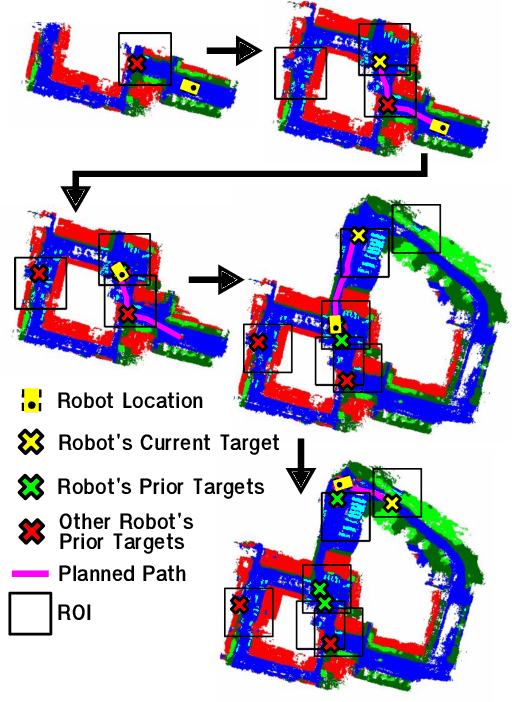
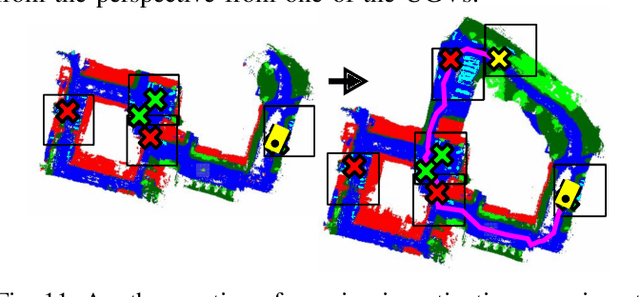
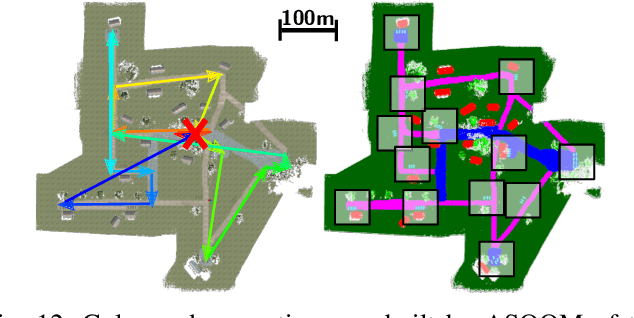
In this work, we present an end-to-end heterogeneous multi-robot system framework where ground robots are able to localize, plan, and navigate in a semantic map created in real time by a high-altitude quadrotor. The ground robots choose and deconflict their targets independently, without any external intervention. Moreover, they perform cross-view localization by matching their local maps with the overhead map using semantics. The communication backbone is opportunistic and distributed, allowing the entire system to operate with no external infrastructure aside from GPS for the quadrotor. We extensively tested our system by performing different missions on top of our framework over multiple experiments in different environments. Our ground robots travelled over 6 km autonomously with minimal intervention in the real world and over 96 km in simulation without interventions.
Supervised Contrastive ResNet and Transfer Learning for the In-vehicle Intrusion Detection System
Jul 18, 2022
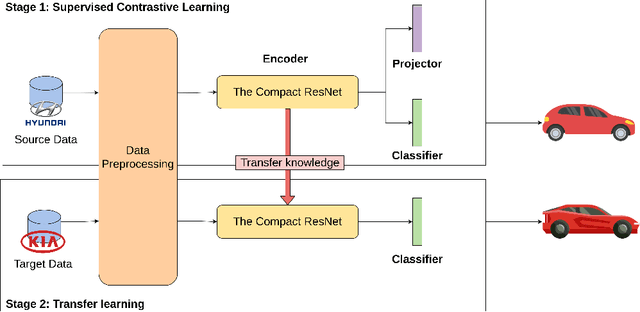
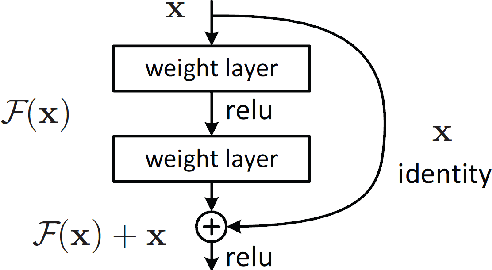
High-end vehicles have been furnished with a number of electronic control units (ECUs), which provide upgrading functions to enhance the driving experience. The controller area network (CAN) is a well-known protocol that connects these ECUs because of its modesty and efficiency. However, the CAN bus is vulnerable to various types of attacks. Although the intrusion detection system (IDS) is proposed to address the security problem of the CAN bus, most previous studies only provide alerts when attacks occur without knowing the specific type of attack. Moreover, an IDS is designed for a specific car model due to diverse car manufacturers. In this study, we proposed a novel deep learning model called supervised contrastive (SupCon) ResNet, which can handle multiple attack identification on the CAN bus. Furthermore, the model can be used to improve the performance of a limited-size dataset using a transfer learning technique. The capability of the proposed model is evaluated on two real car datasets. When tested with the car hacking dataset, the experiment results show that the SupCon ResNet model improves the overall false-negative rates of four types of attack by four times on average, compared to other models. In addition, the model achieves the highest F1 score at 0.9994 on the survival dataset by utilizing transfer learning. Finally, the model can adapt to hardware constraints in terms of memory size and running time.
GP22: A Car Styling Dataset for Automotive Designers
Jul 05, 2022

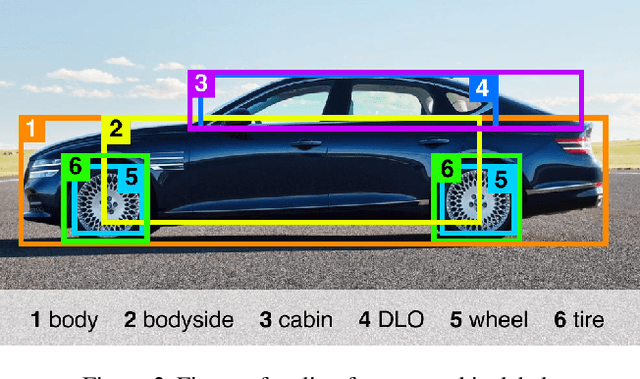

An automated design data archiving could reduce the time wasted by designers from working creatively and effectively. Though many datasets on classifying, detecting, and instance segmenting on car exterior exist, these large datasets are not relevant for design practices as the primary purpose lies in autonomous driving or vehicle verification. Therefore, we release GP22, composed of car styling features defined by automotive designers. The dataset contains 1480 car side profile images from 37 brands and ten car segments. It also contains annotations of design features that follow the taxonomy of the car exterior design features defined in the eye of the automotive designer. We trained the baseline model using YOLO v5 as the design feature detection model with the dataset. The presented model resulted in an mAP score of 0.995 and a recall of 0.984. Furthermore, exploration of the model performance on sketches and rendering images of the car side profile implies the scalability of the dataset for design purposes.
* 5th CVFAD workshop, CVPR2022
TYolov5: A Temporal Yolov5 Detector Based on Quasi-Recurrent Neural Networks for Real-Time Handgun Detection in Video
Nov 19, 2021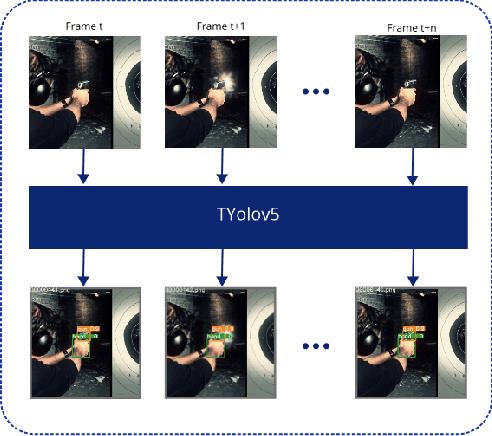
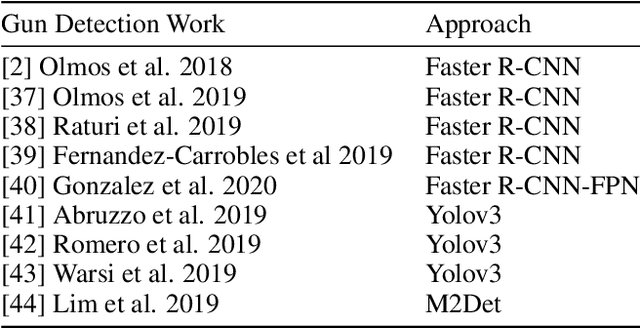
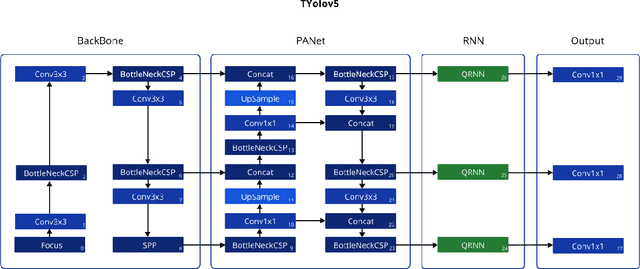
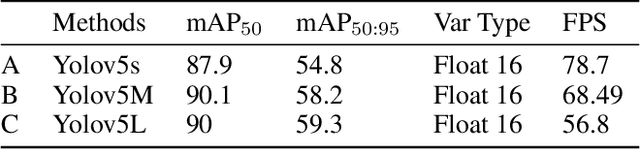
Timely handgun detection is a crucial problem to improve public safety; nevertheless, the effectiveness of many surveillance systems still depends of finite human attention. Much of the previous research on handgun detection is based on static image detectors, leaving aside valuable temporal information that could be used to improve object detection in videos. To improve the performance of surveillance systems, a real-time temporal handgun detection system should be built. Using Temporal Yolov5, an architecture based on Quasi-Recurrent Neural Networks, temporal information is extracted from video to improve the results of handgun detection. Moreover, two publicly available datasets are proposed, labeled with hands, guns, and phones. One containing 2199 static images to train static detectors, and another with 5960 frames of videos to train temporal modules. Additionally, we explore two temporal data augmentation techniques based on Mosaic and Mixup. The resulting systems are three temporal architectures: one focused in reducing inference with a mAP$_{50:95}$ of 55.9, another in having a good balance between inference and accuracy with a mAP$_{50:95}$ of 59, and a last one specialized in accuracy with a mAP$_{50:95}$ of 60.2. Temporal Yolov5 achieves real-time detection in the small and medium architectures. Moreover, it takes advantage of temporal features contained in videos to perform better than Yolov5 in our temporal dataset, making TYolov5 suitable for real-world applications. The source code is publicly available at https://github.com/MarioDuran/TYolov5.
End-to-End License Plate Recognition Pipeline for Real-time Low Resource Video Based Applications
Aug 18, 2021

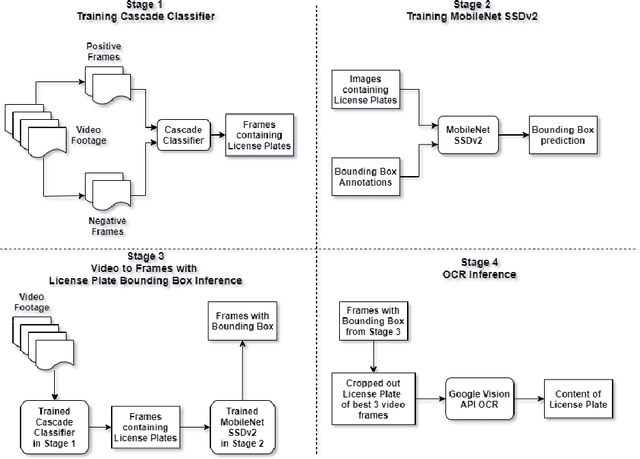
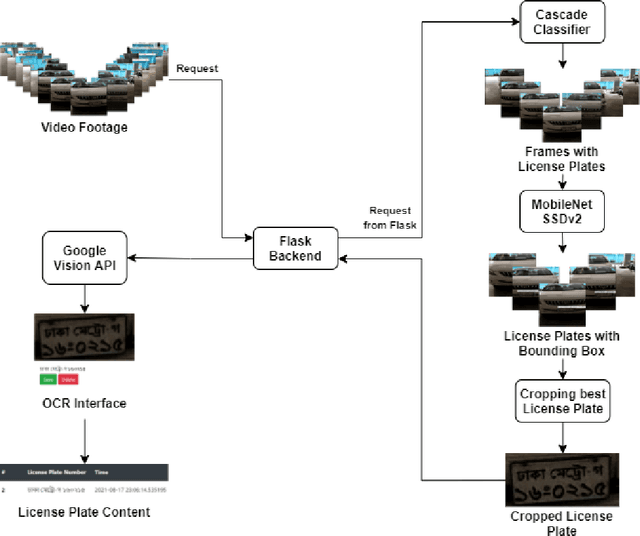
Automatic License Plate Recognition systems aim to provide an end-to-end solution towards detecting, localizing, and recognizing license plate characters from vehicles appearing in video frames. However, deploying such systems in the real world requires real-time performance in low-resource environments. In our paper, we propose a novel two-stage detection pipeline paired with Vision API that aims to provide real-time inference speed along with consistently accurate detection and recognition performance. We used a haar-cascade classifier as a filter on top of our backbone MobileNet SSDv2 detection model. This reduces inference time by only focusing on high confidence detections and using them for recognition. We also impose a temporal frame separation strategy to identify multiple vehicle license plates in the same clip. Furthermore, there are no publicly available Bangla license plate datasets, for which we created an image dataset and a video dataset containing license plates in the wild. We trained our models on the image dataset and achieved an AP(0.5) score of 86% and tested our pipeline on the video dataset and observed reasonable detection and recognition performance (82.7% detection rate, and 60.8% OCR F1 score) with real-time processing speed (27.2 frames per second).
Benchmarking Unsupervised Anomaly Detection and Localization
May 30, 2022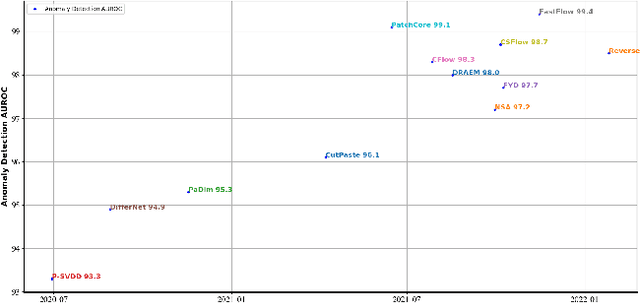
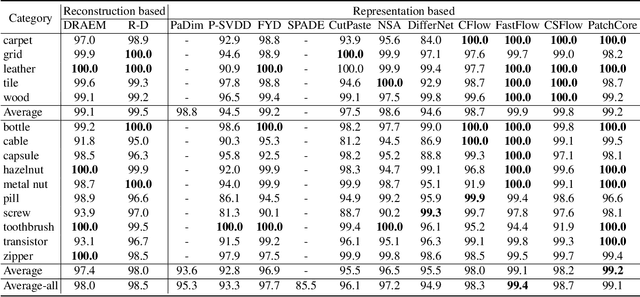
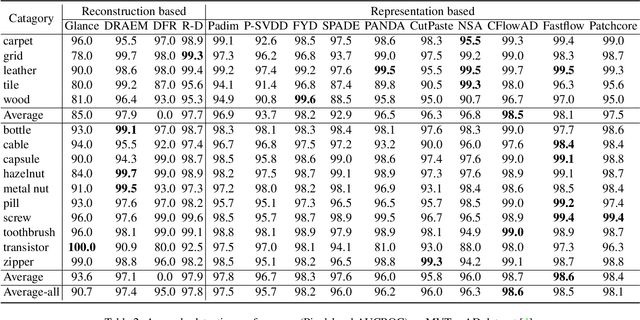
Unsupervised anomaly detection and localization, as of one the most practical and challenging problems in computer vision, has received great attention in recent years. From the time the MVTec AD dataset was proposed to the present, new research methods that are constantly being proposed push its precision to saturation. It is the time to conduct a comprehensive comparison of existing methods to inspire further research. This paper extensively compares 13 papers in terms of the performance in unsupervised anomaly detection and localization tasks, and adds a comparison of inference efficiency previously ignored by the community. Meanwhile, analysis of the MVTec AD dataset are also given, especially the label ambiguity that affects the model fails to achieve full marks. Moreover, considering the proposal of the new MVTec 3D-AD dataset, this paper also conducts experiments using the existing state-of-the-art 2D methods on this new dataset, and reports the corresponding results with analysis.
CompText: Visualizing, Comparing & Understanding Text Corpus
Jul 27, 2022



A common practice in Natural Language Processing (NLP) is to visualize the text corpus without reading through the entire literature, still grasping the central idea and key points described. For a long time, researchers focused on extracting topics from the text and visualizing them based on their relative significance in the corpus. However, recently, researchers started coming up with more complex systems that not only expose the topics of the corpus but also word closely related to the topic to give users a holistic view. These detailed visualizations spawned research on comparing text corpora based on their visualization. Topics are often compared to idealize the difference between corpora. However, to capture greater semantics from different corpora, researchers have started to compare texts based on the sentiment of the topics related to the text. Comparing the words carrying the most weightage, we can get an idea about the important topics for corpus. There are multiple existing texts comparing methods present that compare topics rather than sentiments but we feel that focusing on sentiment-carrying words would better compare the two corpora. Since only sentiments can explain the real feeling of the text and not just the topic, topics without sentiments are just nouns. We aim to differentiate the corpus with a focus on sentiment, as opposed to comparing all the words appearing in the two corpora. The rationale behind this is, that the two corpora do not many have identical words for side-by-side comparison, so comparing the sentiment words gives us an idea of how the corpora are appealing to the emotions of the reader. We can argue that the entropy or the unexpectedness and divergence of topics should also be of importance and help us to identify key pivot points and the importance of certain topics in the corpus alongside relative sentiment.
Trajectory PMB Filters for Extended Object Tracking Using Belief Propagation
Jul 20, 2022

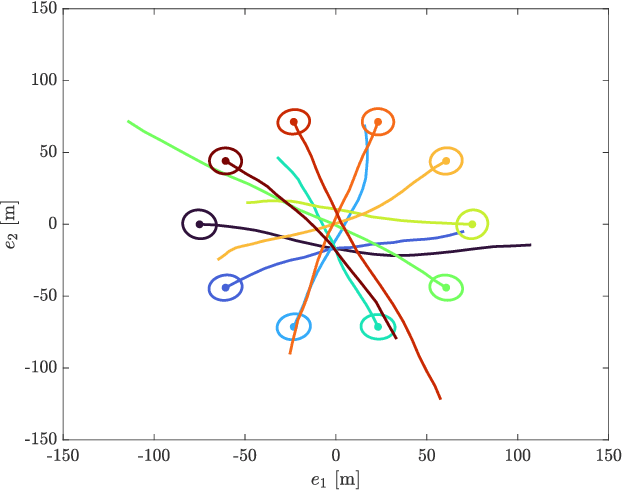
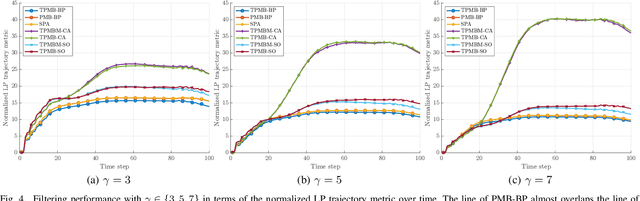
In this paper, we propose a Poisson multi-Bernoulli (PMB) filter for extended object tracking (EOT), which directly estimates the set of object trajectories, using belief propagation (BP). The proposed filter propagates a PMB density on the posterior of sets of trajectories through the filtering recursions over time, where the PMB mixture (PMBM) posterior after the update step is approximated as a PMB. The efficient PMB approximation relies on several important theoretical contributions. First, we present a PMBM conjugate prior on the posterior of sets of trajectories for a generalized measurement model, in which each object generates an independent set of measurements. The PMBM density is a conjugate prior in the sense that both the prediction and the update steps preserve the PMBM form of the density. Second, we present a factor graph representation of the joint posterior of the PMBM set of trajectories and association variables for the Poisson spatial measurement model. Importantly, leveraging the PMBM conjugacy and the factor graph formulation enables an elegant treatment on undetected objects via a Poisson point process and efficient inference on sets of trajectories using BP, where the approximate marginal densities in the PMB approximation can be obtained without enumeration of different data association hypotheses. To achieve this, we present a particle-based implementation of the proposed filter, where smoothed trajectory estimates, if desired, can be obtained via single-object particle smoothing methods, and its performance for EOT with ellipsoidal shapes is evaluated in a simulation study.