 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Comparing Conventional Pitch Detection Algorithms with a Neural Network Approach
Jun 29, 2022
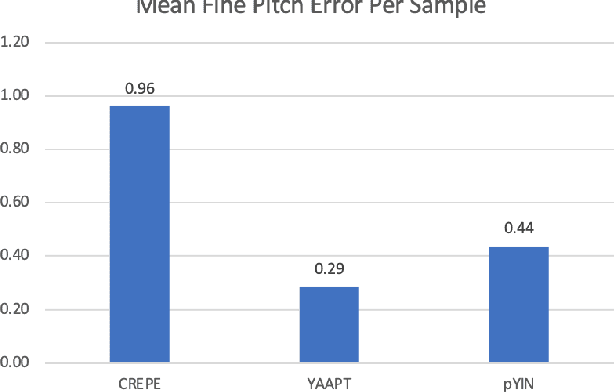
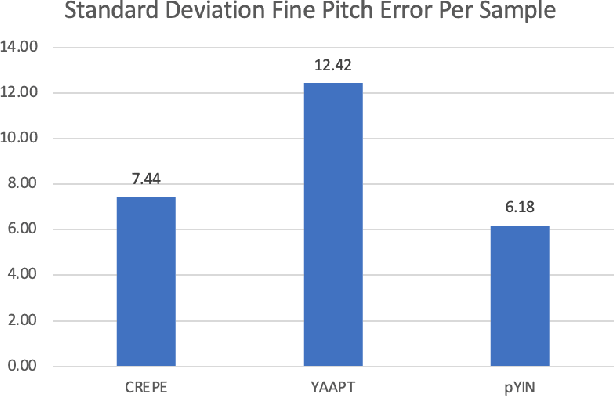
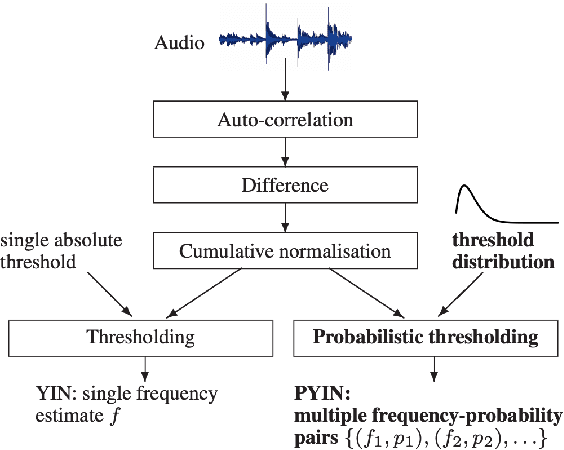
Despite much research, traditional methods to pitch prediction are still not perfect. With the emergence of neural networks (NNs), researchers hope to create a NN-based pitch predictor that outperforms traditional methods. Three pitch detection algorithms (PDAs), pYIN, YAAPT, and CREPE are compared in this paper. pYIN and YAAPT are conventional approaches considering time domain and frequency domain processing. CREPE utilizes a data-trained deep convolutional neural network to estimate pitch. It involves 6 densely connected convolutional hidden layers and determines pitch probabilities for a given input signal. The performance of CREPE representing neural network pitch predictors is compared to more classical approaches represented by pYIN and YAAPT. The figure of merit (FOM) will include the amount of unvoiced-to-voiced errors, voiced-to-voiced errors, gross pitch errors, and fine pitch errors.
Comparative Validation of AI and non-AI Methods in MRI Volumetry to Diagnose Parkinsonian Syndromes
Jul 23, 2022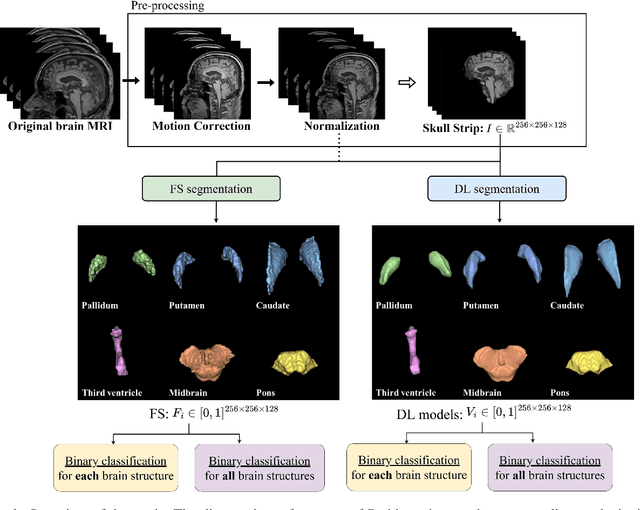

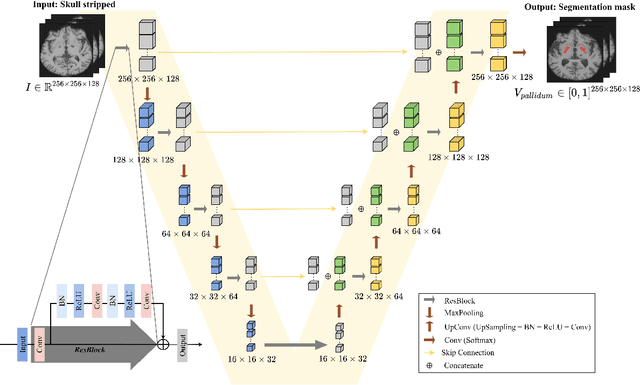
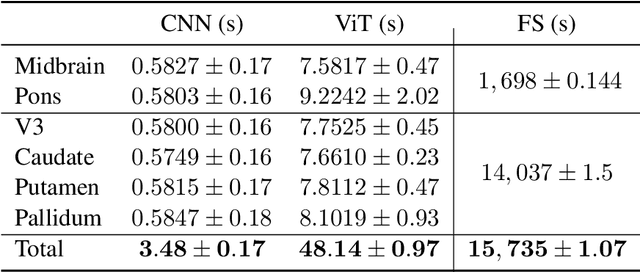
Automated segmentation and volumetry of brain magnetic resonance imaging (MRI) scans are essential for the diagnosis of Parkinson's disease (PD) and Parkinson's plus syndromes (P-plus). To enhance the diagnostic performance, we adopt deep learning (DL) models in brain segmentation and compared their performance with the gold-standard non-DL method. We collected brain MRI scans of healthy controls (n=105) and patients with PD (n=105), multiple systemic atrophy (n=132), and progressive supranuclear palsy (n=69) at Samsung Medical Center from January 2017 to December 2020. Using the gold-standard non-DL model, FreeSurfer (FS), we segmented six brain structures: midbrain, pons, caudate, putamen, pallidum, and third ventricle, and considered them as annotating data for DL models, the representative V-Net and UNETR. The Dice scores and area under the curve (AUC) for differentiating normal, PD, and P-plus cases were calculated. The segmentation times of V-Net and UNETR for the six brain structures per patient were 3.48 +- 0.17 and 48.14 +- 0.97 s, respectively, being at least 300 times faster than FS (15,735 +- 1.07 s). Dice scores of both DL models were sufficiently high (>0.85), and their AUCs for disease classification were superior to that of FS. For classification of normal vs. P-plus and PD vs. multiple systemic atrophy (cerebellar type), the DL models and FS showed AUCs above 0.8. DL significantly reduces the analysis time without compromising the performance of brain segmentation and differential diagnosis. Our findings may contribute to the adoption of DL brain MRI segmentation in clinical settings and advance brain research.
End-to-End License Plate Recognition Pipeline for Real-time Low Resource Video Based Applications
Aug 18, 2021

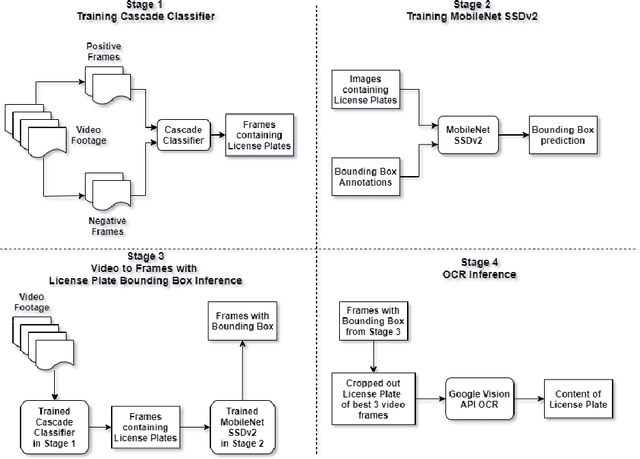
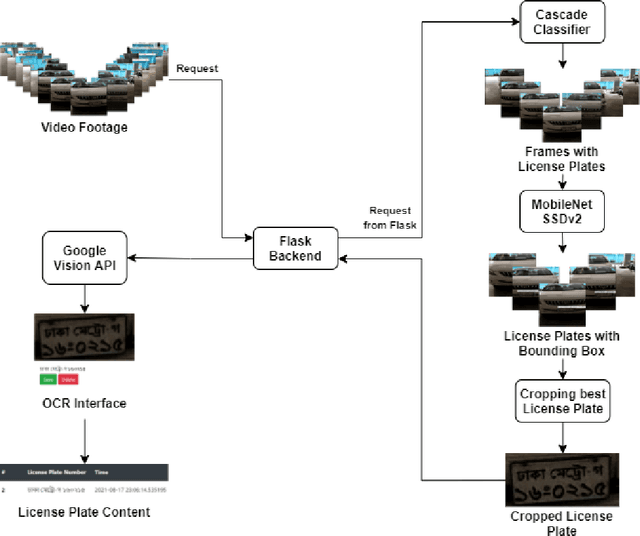
Automatic License Plate Recognition systems aim to provide an end-to-end solution towards detecting, localizing, and recognizing license plate characters from vehicles appearing in video frames. However, deploying such systems in the real world requires real-time performance in low-resource environments. In our paper, we propose a novel two-stage detection pipeline paired with Vision API that aims to provide real-time inference speed along with consistently accurate detection and recognition performance. We used a haar-cascade classifier as a filter on top of our backbone MobileNet SSDv2 detection model. This reduces inference time by only focusing on high confidence detections and using them for recognition. We also impose a temporal frame separation strategy to identify multiple vehicle license plates in the same clip. Furthermore, there are no publicly available Bangla license plate datasets, for which we created an image dataset and a video dataset containing license plates in the wild. We trained our models on the image dataset and achieved an AP(0.5) score of 86% and tested our pipeline on the video dataset and observed reasonable detection and recognition performance (82.7% detection rate, and 60.8% OCR F1 score) with real-time processing speed (27.2 frames per second).
TYolov5: A Temporal Yolov5 Detector Based on Quasi-Recurrent Neural Networks for Real-Time Handgun Detection in Video
Nov 19, 2021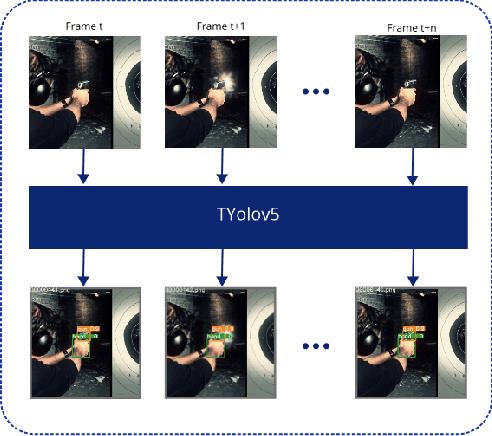
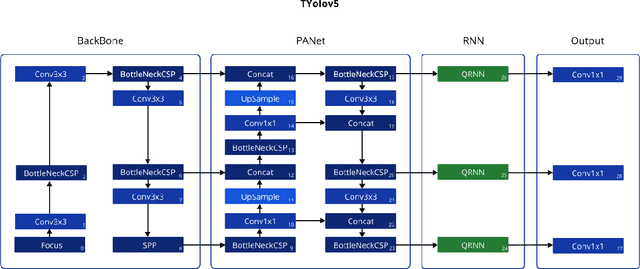
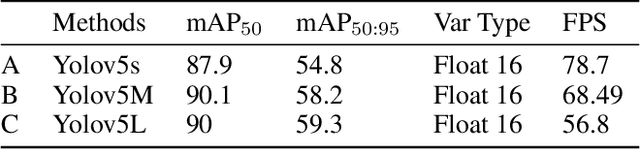
Timely handgun detection is a crucial problem to improve public safety; nevertheless, the effectiveness of many surveillance systems still depends of finite human attention. Much of the previous research on handgun detection is based on static image detectors, leaving aside valuable temporal information that could be used to improve object detection in videos. To improve the performance of surveillance systems, a real-time temporal handgun detection system should be built. Using Temporal Yolov5, an architecture based on Quasi-Recurrent Neural Networks, temporal information is extracted from video to improve the results of handgun detection. Moreover, two publicly available datasets are proposed, labeled with hands, guns, and phones. One containing 2199 static images to train static detectors, and another with 5960 frames of videos to train temporal modules. Additionally, we explore two temporal data augmentation techniques based on Mosaic and Mixup. The resulting systems are three temporal architectures: one focused in reducing inference with a mAP$_{50:95}$ of 55.9, another in having a good balance between inference and accuracy with a mAP$_{50:95}$ of 59, and a last one specialized in accuracy with a mAP$_{50:95}$ of 60.2. Temporal Yolov5 achieves real-time detection in the small and medium architectures. Moreover, it takes advantage of temporal features contained in videos to perform better than Yolov5 in our temporal dataset, making TYolov5 suitable for real-world applications. The source code is publicly available at https://github.com/MarioDuran/TYolov5.
Wound Segmentation with Dynamic Illumination Correction and Dual-view Semantic Fusion
Jul 12, 2022
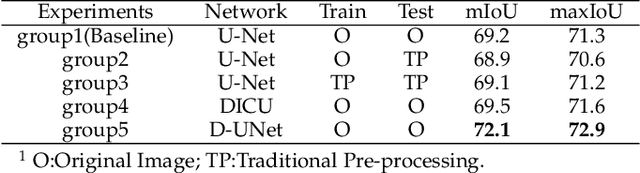
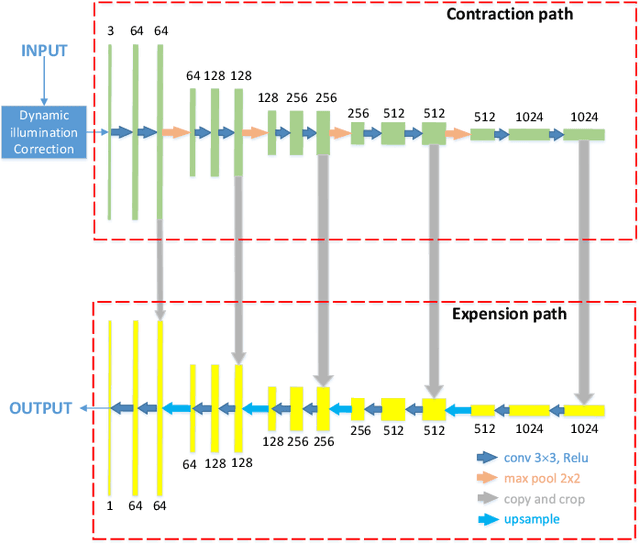

Wound image segmentation is a critical component for the clinical diagnosis and in-time treatment of wounds. Recently, deep learning has become the mainstream methodology for wound image segmentation. However, the pre-processing of the wound image, such as the illumination correction, is required before the training phase as the performance can be greatly improved. The correction procedure and the training of deep models are independent of each other, which leads to sub-optimal segmentation performance as the fixed illumination correction may not be suitable for all images. To address aforementioned issues, an end-to-end dual-view segmentation approach was proposed in this paper, by incorporating a learn-able illumination correction module into the deep segmentation models. The parameters of the module can be learned and updated during the training stage automatically, while the dual-view fusion can fully employ the features from both the raw images and the enhanced ones. To demonstrate the effectiveness and robustness of the proposed framework, the extensive experiments are conducted on the benchmark datasets. The encouraging results suggest that our framework can significantly improve the segmentation performance, compared to the state-of-the-art methods.
Distribution-Aware Graph Representation Learning for Transient Stability Assessment of Power System
May 12, 2022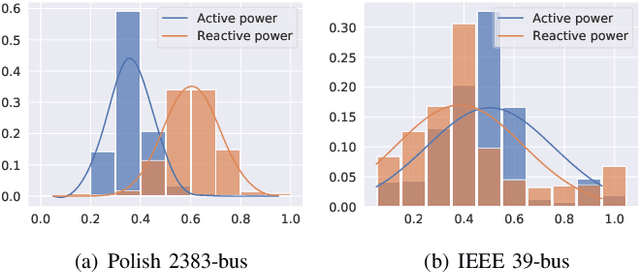
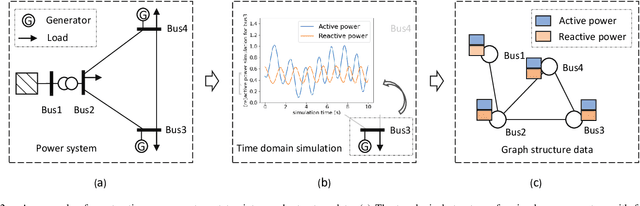
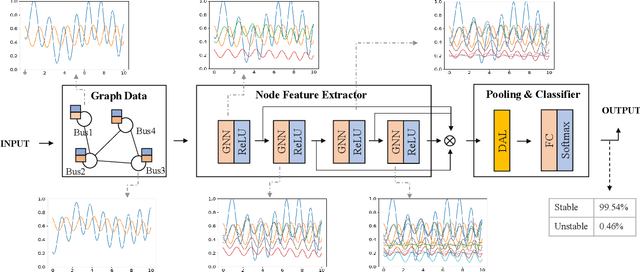
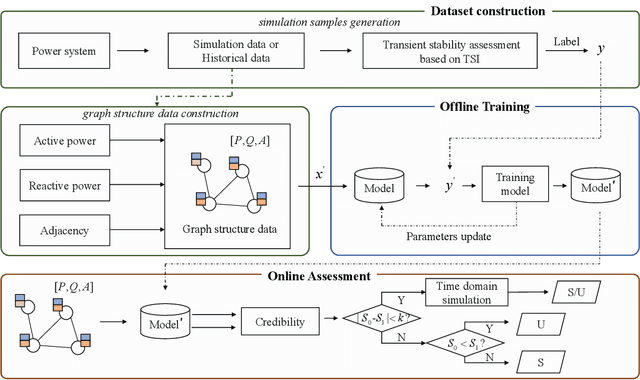
The real-time transient stability assessment (TSA) plays a critical role in the secure operation of the power system. Although the classic numerical integration method, \textit{i.e.} time-domain simulation (TDS), has been widely used in industry practice, it is inevitably trapped in a high computational complexity due to the high latitude sophistication of the power system. In this work, a data-driven power system estimation method is proposed to quickly predict the stability of the power system before TDS reaches the end of simulating time windows, which can reduce the average simulation time of stability assessment without loss of accuracy. As the topology of the power system is in the form of graph structure, graph neural network based representation learning is naturally suitable for learning the status of the power system. Motivated by observing the distribution information of crucial active power and reactive power on the power system's bus nodes, we thus propose a distribution-aware learning~(DAL) module to explore an informative graph representation vector for describing the status of a power system. Then, TSA is re-defined as a binary classification task, and the stability of the system is determined directly from the resulting graph representation without numerical integration. Finally, we apply our method to the online TSA task. The case studies on the IEEE 39-bus system and Polish 2383-bus system demonstrate the effectiveness of our proposed method.
Sampling-free Inference for Ab-Initio Potential Energy Surface Networks
May 30, 2022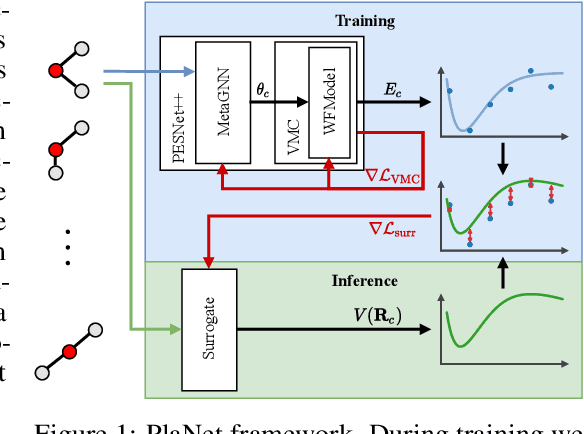
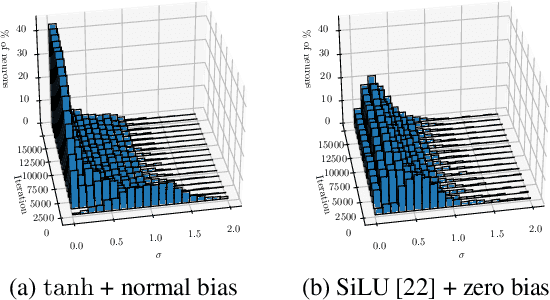

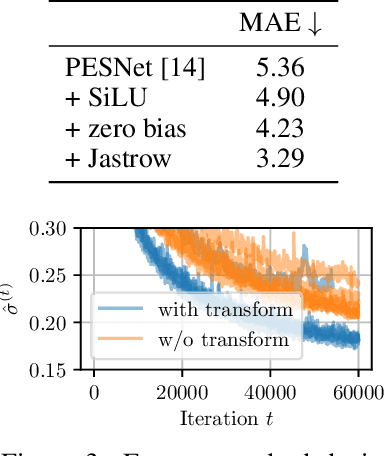
Obtaining the energy of molecular systems typically requires solving the associated Schr\"odinger equation. Unfortunately, analytical solutions only exist for single-electron systems, and accurate approximate solutions are expensive. In recent work, the potential energy surface network (PESNet) has been proposed to reduce training time by solving the Schr\"odinger equation for many geometries simultaneously. While training significantly faster, inference still required numerical integration limiting the evaluation to a few geometries. Here, we address the inference shortcomings by proposing the Potential learning from ab-initio Networks (PlaNet) framework to simultaneously train a surrogate model that avoids expensive Monte-Carlo integration and, thus, reduces inference time from minutes or even hours to milliseconds. In this way, we can accurately model high-resolution multi-dimensional energy surfaces that previously would have been unobtainable via neural wave functions. Finally, we present PESNet++, an architectural improvement to PESNet, that reduces errors by up to 39% and provides new state-of-the-art results for neural wave functions across all systems evaluated.
Deriving Surface Resistivity from Polarimetric SAR Data Using Dual-Input UNet
Jul 05, 2022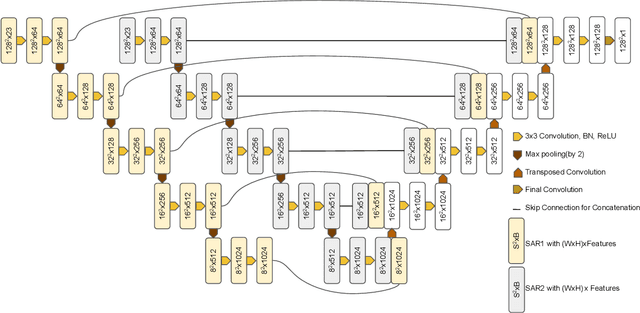
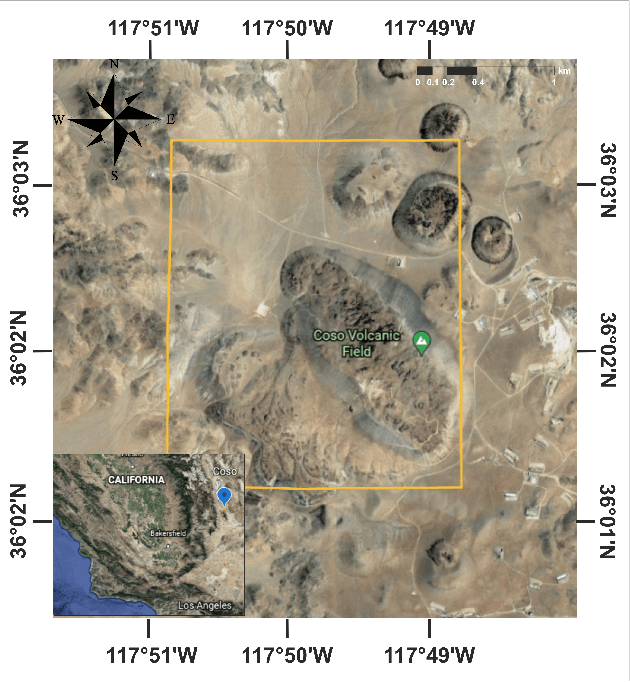


Traditional survey methods for finding surface resistivity are time-consuming and labor intensive. Very few studies have focused on finding the resistivity/conductivity using remote sensing data and deep learning techniques. In this line of work, we assessed the correlation between surface resistivity and Synthetic Aperture Radar (SAR) by applying various deep learning methods and tested our hypothesis in the Coso Geothermal Area, USA. For detecting the resistivity, L-band full polarimetric SAR data acquired by UAVSAR were used, and MT (Magnetotellurics) inverted resistivity data of the area were used as the ground truth. We conducted experiments to compare various deep learning architectures and suggest the use of Dual Input UNet (DI-UNet) architecture. DI-UNet uses a deep learning architecture to predict the resistivity using full polarimetric SAR data by promising a quick survey addition to the traditional method. Our proposed approach accomplished improved outcomes for the mapping of MT resistivity from SAR data.
Privacy-Preserving Face Recognition with Learnable Privacy Budgets in Frequency Domain
Jul 18, 2022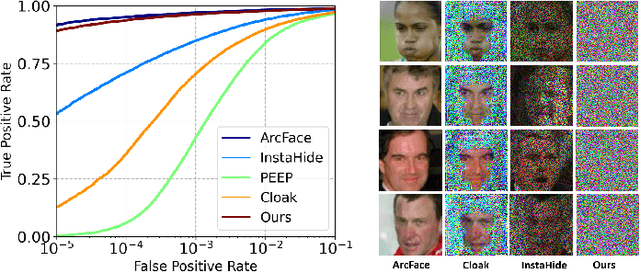

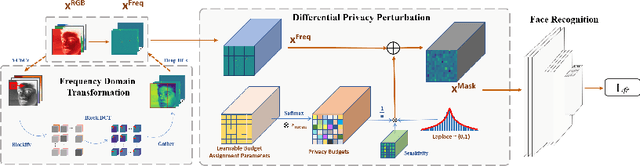
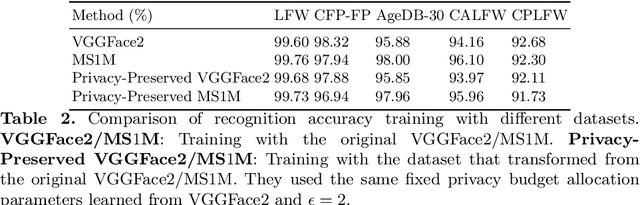
Face recognition technology has been used in many fields due to its high recognition accuracy, including the face unlocking of mobile devices, community access control systems, and city surveillance. As the current high accuracy is guaranteed by very deep network structures, facial images often need to be transmitted to third-party servers with high computational power for inference. However, facial images visually reveal the user's identity information. In this process, both untrusted service providers and malicious users can significantly increase the risk of a personal privacy breach. Current privacy-preserving approaches to face recognition are often accompanied by many side effects, such as a significant increase in inference time or a noticeable decrease in recognition accuracy. This paper proposes a privacy-preserving face recognition method using differential privacy in the frequency domain. Due to the utilization of differential privacy, it offers a guarantee of privacy in theory. Meanwhile, the loss of accuracy is very slight. This method first converts the original image to the frequency domain and removes the direct component termed DC. Then a privacy budget allocation method can be learned based on the loss of the back-end face recognition network within the differential privacy framework. Finally, it adds the corresponding noise to the frequency domain features. Our method performs very well with several classical face recognition test sets according to the extensive experiments.
Cross-Attention Transformer for Video Interpolation
Jul 08, 2022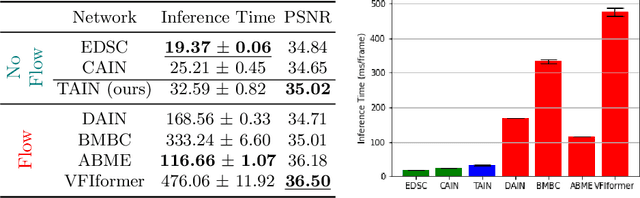
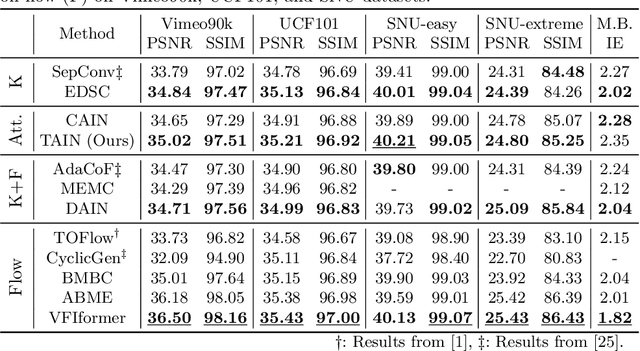
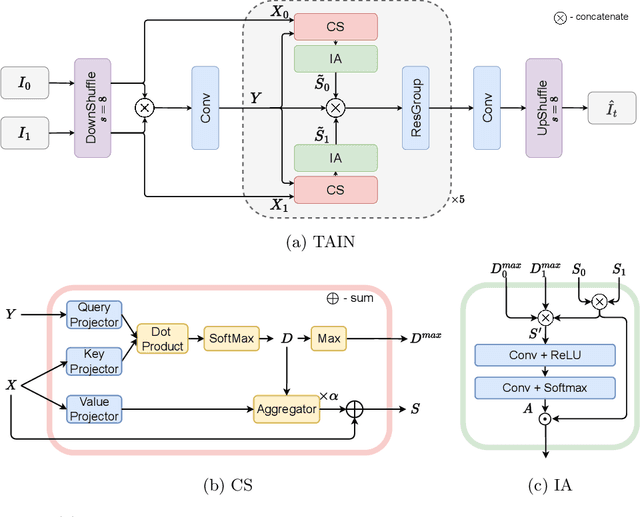
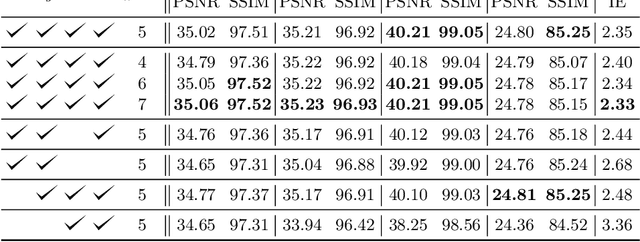
We propose TAIN (Transformers and Attention for video INterpolation), a residual neural network for video interpolation, which aims to interpolate an intermediate frame given two consecutive image frames around it. We first present a novel visual transformer module, named Cross-Similarity (CS), to globally aggregate input image features with similar appearance as those of the predicted interpolated frame. These CS features are then used to refine the interpolated prediction. To account for occlusions in the CS features, we propose an Image Attention (IA) module to allow the network to focus on CS features from one frame over those of the other. Additionally, we augment our training dataset with an occluder patch that moves across frames to improve the network's robustness to occlusions and large motion. Because existing methods yield smooth predictions especially near MBs, we use an additional training loss based on image gradient to yield sharper predictions. TAIN outperforms existing methods that do not require flow estimation and performs comparably to flow-based methods while being computationally efficient in terms of inference time on Vimeo90k, UCF101, and SNU-FILM benchmarks.