 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Improving Continuous-time Conflict Based Search
Jan 24, 2021
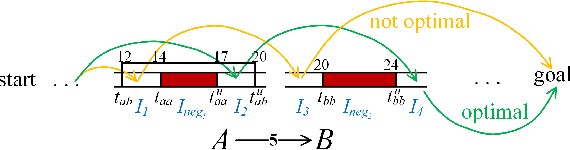

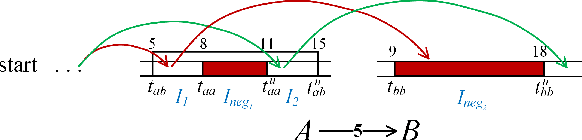
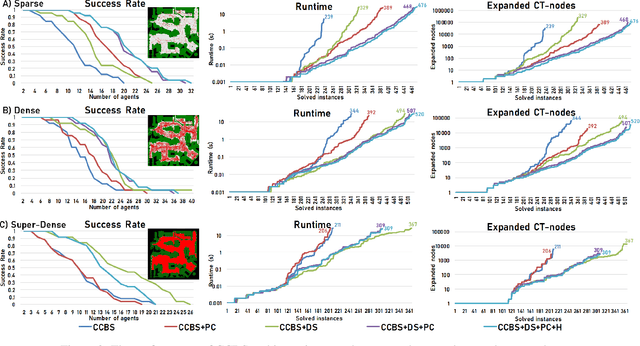
Conflict-Based Search (CBS) is a powerful algorithmic framework for optimally solving classical multi-agent path finding (MAPF) problems, where time is discretized into the time steps. Continuous-time CBS (CCBS) is a recently proposed version of CBS that guarantees optimal solutions without the need to discretize time. However, the scalability of CCBS is limited because it does not include any known improvements of CBS. In this paper, we begin to close this gap and explore how to adapt successful CBS improvements, namely, prioritizing conflicts (PC), disjoint splitting (DS), and high-level heuristics, to the continuous time setting of CCBS. These adaptions are not trivial, and require careful handling of different types of constraints, applying a generalized version of the Safe interval path planning (SIPP) algorithm, and extending the notion of cardinal conflicts. We evaluate the effect of the suggested enhancements by running experiments both on general graphs and $2^k$-neighborhood grids. CCBS with these improvements significantly outperforms vanilla CCBS, solving problems with almost twice as many agents in some cases and pushing the limits of multiagent path finding in continuous-time domains.
My View is the Best View: Procedure Learning from Egocentric Videos
Jul 22, 2022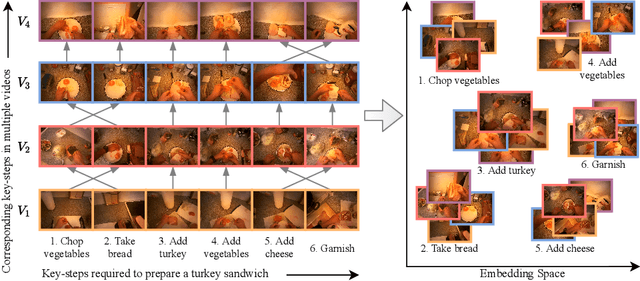


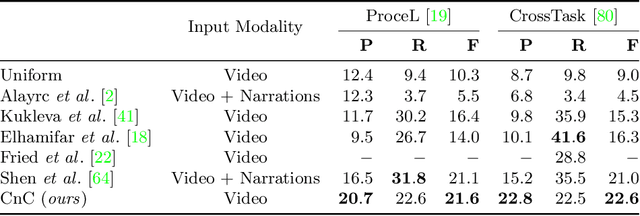
Procedure learning involves identifying the key-steps and determining their logical order to perform a task. Existing approaches commonly use third-person videos for learning the procedure, making the manipulated object small in appearance and often occluded by the actor, leading to significant errors. In contrast, we observe that videos obtained from first-person (egocentric) wearable cameras provide an unobstructed and clear view of the action. However, procedure learning from egocentric videos is challenging because (a) the camera view undergoes extreme changes due to the wearer's head motion, and (b) the presence of unrelated frames due to the unconstrained nature of the videos. Due to this, current state-of-the-art methods' assumptions that the actions occur at approximately the same time and are of the same duration, do not hold. Instead, we propose to use the signal provided by the temporal correspondences between key-steps across videos. To this end, we present a novel self-supervised Correspond and Cut (CnC) framework for procedure learning. CnC identifies and utilizes the temporal correspondences between the key-steps across multiple videos to learn the procedure. Our experiments show that CnC outperforms the state-of-the-art on the benchmark ProceL and CrossTask datasets by 5.2% and 6.3%, respectively. Furthermore, for procedure learning using egocentric videos, we propose the EgoProceL dataset consisting of 62 hours of videos captured by 130 subjects performing 16 tasks. The source code and the dataset are available on the project page https://sid2697.github.io/egoprocel/.
Privacy-Preserving Face Recognition with Learnable Privacy Budgets in Frequency Domain
Jul 19, 2022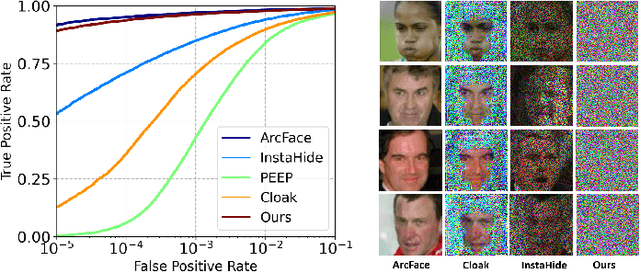

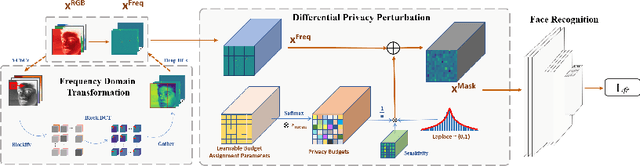
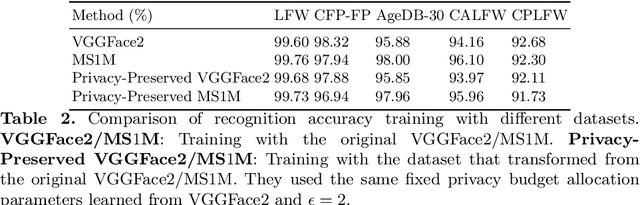
Face recognition technology has been used in many fields due to its high recognition accuracy, including the face unlocking of mobile devices, community access control systems, and city surveillance. As the current high accuracy is guaranteed by very deep network structures, facial images often need to be transmitted to third-party servers with high computational power for inference. However, facial images visually reveal the user's identity information. In this process, both untrusted service providers and malicious users can significantly increase the risk of a personal privacy breach. Current privacy-preserving approaches to face recognition are often accompanied by many side effects, such as a significant increase in inference time or a noticeable decrease in recognition accuracy. This paper proposes a privacy-preserving face recognition method using differential privacy in the frequency domain. Due to the utilization of differential privacy, it offers a guarantee of privacy in theory. Meanwhile, the loss of accuracy is very slight. This method first converts the original image to the frequency domain and removes the direct component termed DC. Then a privacy budget allocation method can be learned based on the loss of the back-end face recognition network within the differential privacy framework. Finally, it adds the corresponding noise to the frequency domain features. Our method performs very well with several classical face recognition test sets according to the extensive experiments.
Multiple Kernel Clustering with Dual Noise Minimization
Jul 13, 2022
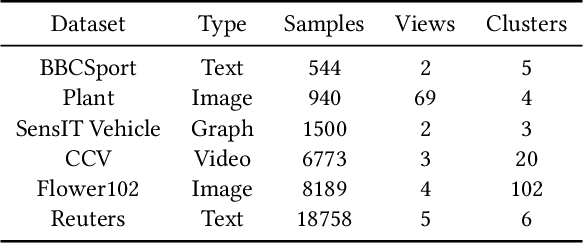
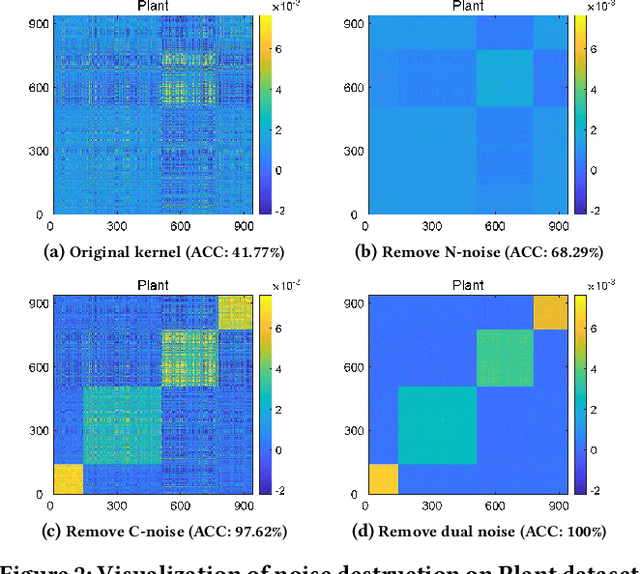
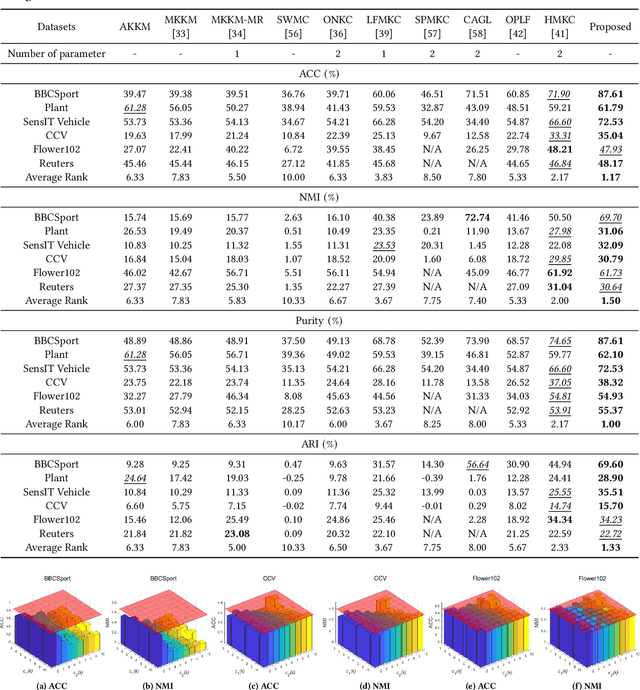
Clustering is a representative unsupervised method widely applied in multi-modal and multi-view scenarios. Multiple kernel clustering (MKC) aims to group data by integrating complementary information from base kernels. As a representative, late fusion MKC first decomposes the kernels into orthogonal partition matrices, then learns a consensus one from them, achieving promising performance recently. However, these methods fail to consider the noise inside the partition matrix, preventing further improvement of clustering performance. We discover that the noise can be disassembled into separable dual parts, i.e. N-noise and C-noise (Null space noise and Column space noise). In this paper, we rigorously define dual noise and propose a novel parameter-free MKC algorithm by minimizing them. To solve the resultant optimization problem, we design an efficient two-step iterative strategy. To our best knowledge, it is the first time to investigate dual noise within the partition in the kernel space. We observe that dual noise will pollute the block diagonal structures and incur the degeneration of clustering performance, and C-noise exhibits stronger destruction than N-noise. Owing to our efficient mechanism to minimize dual noise, the proposed algorithm surpasses the recent methods by large margins.
CLTS-GAN: Color-Lighting-Texture-Specular Reflection Augmentation for Colonoscopy
Jun 29, 2022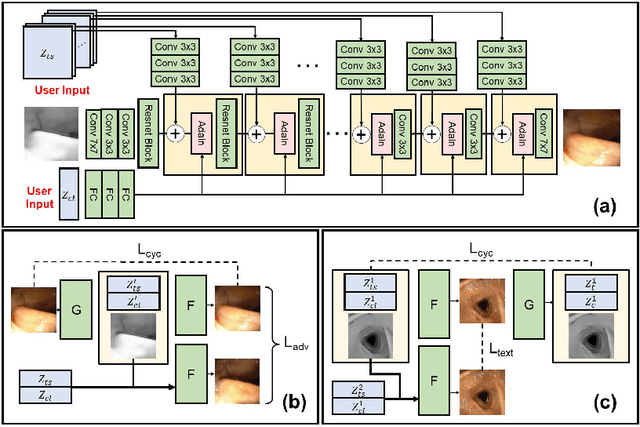


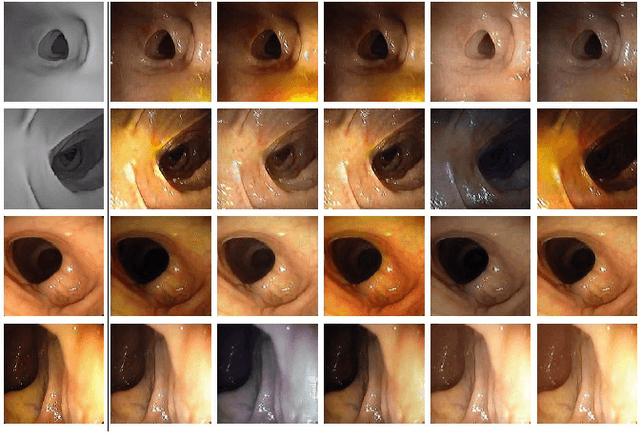
Automated analysis of optical colonoscopy (OC) video frames (to assist endoscopists during OC) is challenging due to variations in color, lighting, texture, and specular reflections. Previous methods either remove some of these variations via preprocessing (making pipelines cumbersome) or add diverse training data with annotations (but expensive and time-consuming). We present CLTS-GAN, a new deep learning model that gives fine control over color, lighting, texture, and specular reflection synthesis for OC video frames. We show that adding these colonoscopy-specific augmentations to the training data can improve state-of-the-art polyp detection/segmentation methods as well as drive next generation of OC simulators for training medical students. The code and pre-trained models for CLTS-GAN are available on Computational Endoscopy Platform GitHub (https://github.com/nadeemlab/CEP).
Nonlinear Two-Time-Scale Stochastic Approximation: Convergence and Finite-Time Performance
Nov 03, 2020Two-time-scale stochastic approximation, a generalized version of the popular stochastic approximation, has found broad applications in many areas including stochastic control, optimization, and machine learning. Despite of its popularity, theoretical guarantees of this method, especially its finite-time performance, are mostly achieved for the linear case while the results for the nonlinear counterpart are very sparse. Motivated by the classic control theory for singularly perturbed systems, we study in this paper the asymptotic convergence and finite-time analysis of the nonlinear two-time-scale stochastic approximation. Under some fairly standard assumptions, we provide a formula that characterizes the rate of convergence of the main iterates to the desired solutions. In particular, we show that the method achieves a convergence in expectation at a rate $\mathcal{O}(1/k^{2/3})$, where $k$ is the number of iterations. The key idea in our analysis is to properly choose the two step sizes to characterize the coupling between the fast and slow-time-scale iterates.
Fast-Spanning Ant Colony Optimisation (FaSACO) for Mobile Robot Coverage Path Planning
May 31, 2022
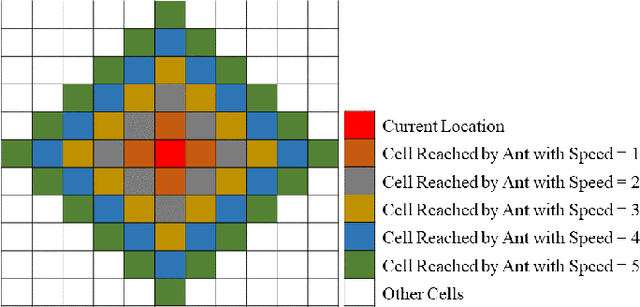
Coverage path planning acts as a key component for applications such as mobile robot vacuum cleaners and hospital disinfecting robots. However, the coverage path planning problem remains a challenge due to its NP-hard nature. Bio-inspired algorithms such as Ant Colony Optimisation (ACO) have been exploited to solve the problem because they can utilise heuristic information to mitigate the path planning complexity. This paper proposes a new variant of ACO - the Fast-Spanning Ant Colony Optimisation (FaSACO), where ants can explore the environment with various velocities. By doing so, ants with higher velocities can find targets or obstacles faster and keep lower velocity ants informed by communicating such information via trail pheromones. This mechanism ensures the optimal path is found while reducing the overall path planning time. Experimental results show that FaSACO is $19.3-32.3\%$ more efficient than ACO, and re-covers $6.9-12.5\%$ fewer cells than ACO. This makes FaSACO more appealing in real-time and energy-limited applications.
Hybrid Architectures for Distributed Machine Learning in Heterogeneous Wireless Networks
Jun 04, 2022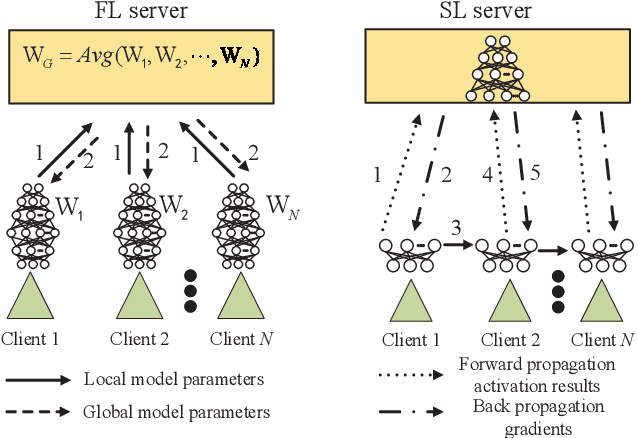
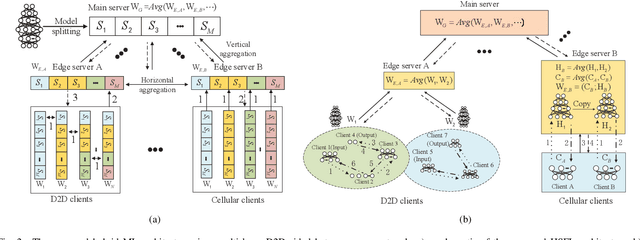
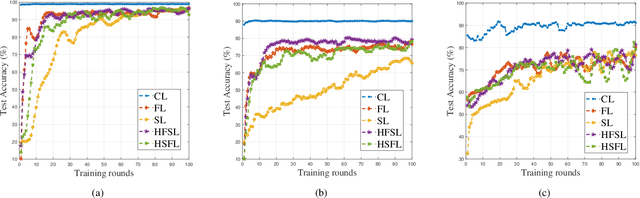
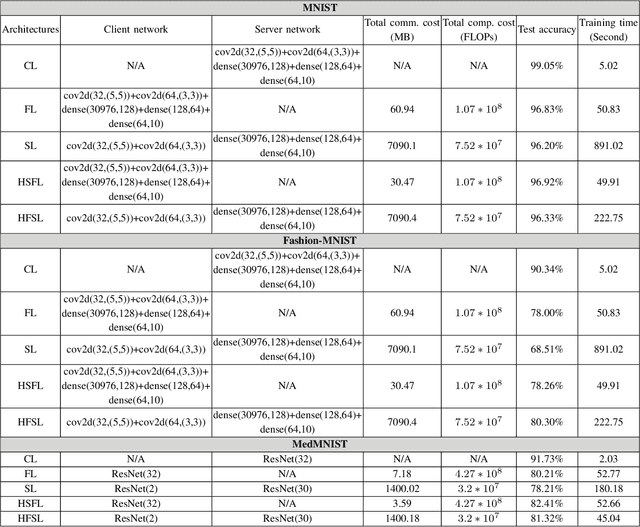
The ever-growing data privacy concerns have transformed machine learning (ML) architectures from centralized to distributed, leading to federated learning (FL) and split learning (SL) as the two most popular privacy-preserving ML paradigms. However, implementing either conventional FL or SL alone with diverse network conditions (e.g., device-to-device (D2D) and cellular communications) and heterogeneous clients (e.g., heterogeneous computation/communication/energy capabilities) may face significant challenges, particularly poor architecture scalability and long training time. To this end, this article proposes two novel hybrid distributed ML architectures, namely, hybrid split FL (HSFL) and hybrid federated SL (HFSL), by combining the advantages of both FL and SL in D2D-enabled heterogeneous wireless networks. Specifically, the performance comparison and advantages of HSFL and HFSL are analyzed generally. Promising open research directions are presented to offer commendable reference for future research. Finally, primary simulations are conducted upon considering three datasets under non-independent and identically distributed settings, to verify the feasibility of our proposed architectures, which can significantly reduce communication/computation cost and training time, as compared with conventional FL and SL.
Resolution Limits of Non-Adaptive 20 Questions Search for a Moving Target
Jun 14, 2022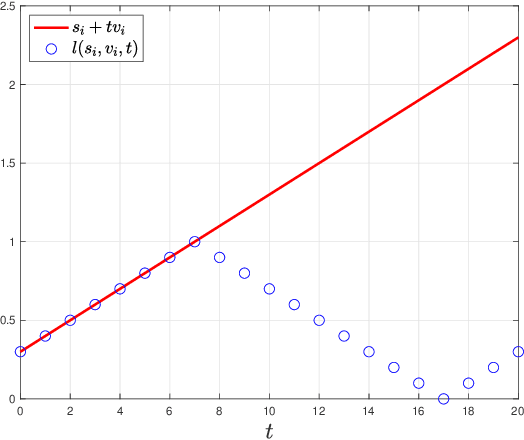
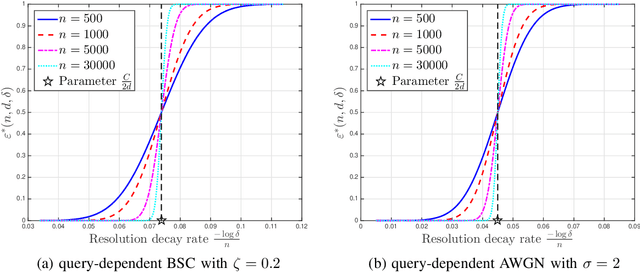
Using the 20 questions estimation framework with query-dependent noise, we study non-adaptive search strategies for a moving target over the unit cube with unknown initial location and velocities under a piecewise constant velocity model. In this search problem, there is an oracle who knows the instantaneous location of the target at any time. Our task is to query the oracle as few times as possible to accurately estimate the location of the target at any specified time. We first study the case where the oracle's answer to each query is corrupted by discrete noise and then generalize our results to the case of additive white Gaussian noise. In our formulation, the performance criterion is the resolution, which is defined as the maximal $L_\infty$ distance between the true locations and estimated locations. We characterize the minimal resolution of an optimal non-adaptive query procedure with a finite number of queries by deriving non-asymptotic and asymptotic bounds. Our bounds are tight in the first-order asymptotic sense when the number of queries satisfies a certain condition and our bounds are tight in the stronger second-order asymptotic sense when the target moves with a constant velocity. To prove our results, we relate the current problem to channel coding, borrow ideas from finite blocklength information theory and construct bounds on the number of possible quantized target trajectories.
Provably Constant-time Planning and Replanning for Real-time Grasping Objects off a Conveyor Belt
Jan 15, 2021
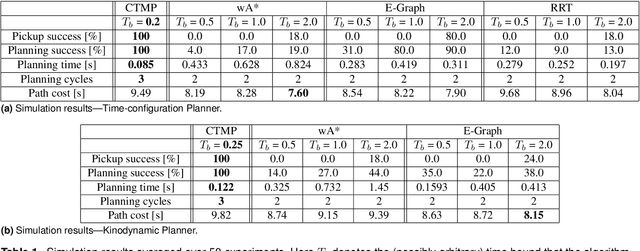
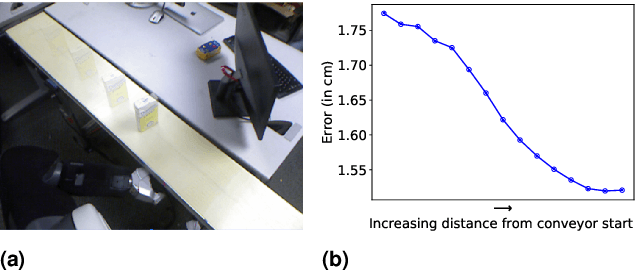
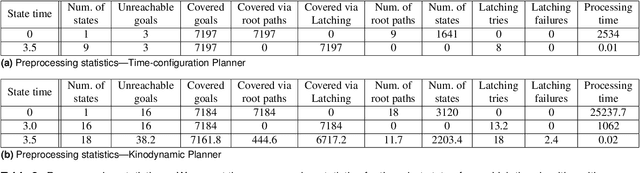
In warehouse and manufacturing environments, manipulation platforms are frequently deployed at conveyor belts to perform pick and place tasks. Because objects on the conveyor belts are moving, robots have limited time to pick them up. This brings the requirement for fast and reliable motion planners that could provide provable real-time planning guarantees, which the existing algorithms do not provide. Besides the planning efficiency, the success of manipulation tasks relies heavily on the accuracy of the perception system which is often noisy, especially if the target objects are perceived from a distance. For fast moving conveyor belts, the robot cannot wait for a perfect estimate before it starts executing its motion. In order to be able to reach the object in time, it must start moving early on (relying on the initial noisy estimates) and adjust its motion on-the-fly in response to the pose updates from perception. We propose a planning framework that meets these requirements by providing provable constant-time planning and replanning guarantees. To this end, we first introduce and formalize a new class of algorithms called Constant-Time Motion Planning algorithms (CTMP) that guarantee to plan in constant time and within a user-defined time bound. We then present our planning framework for grasping objects off a conveyor belt as an instance of the CTMP class of algorithms.