 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fast Object Placement Assessment
May 28, 2022
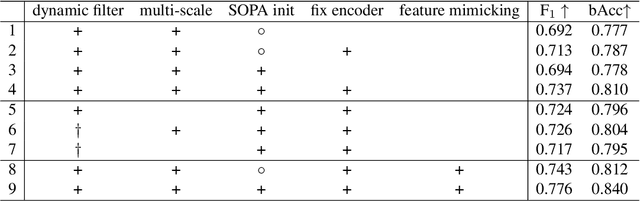
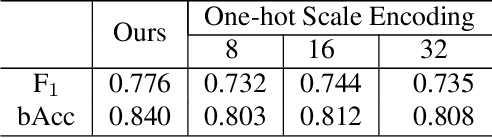
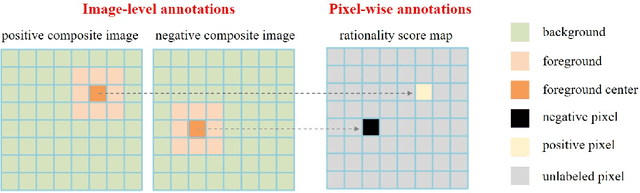

Object placement assessment (OPA) aims to predict the rationality score of a composite image in terms of the placement (e.g., scale, location) of inserted foreground object. However, given a pair of scaled foreground and background, to enumerate all the reasonable locations, existing OPA model needs to place the foreground at each location on the background and pass the obtained composite image through the model one at a time, which is very time-consuming. In this work, we investigate a new task named as fast OPA. Specifically, provided with a scaled foreground and a background, we only pass them through the model once and predict the rationality scores for all locations. To accomplish this task, we propose a pioneering fast OPA model with several innovations (i.e., foreground dynamic filter, background prior transfer, and composite feature mimicking) to bridge the performance gap between slow OPA model and fast OPA model. Extensive experiments on OPA dataset show that our proposed fast OPA model performs on par with slow OPA model but runs significantly faster.
Automatic Mapping of the Best-Suited DNN Pruning Schemes for Real-Time Mobile Acceleration
Nov 22, 2021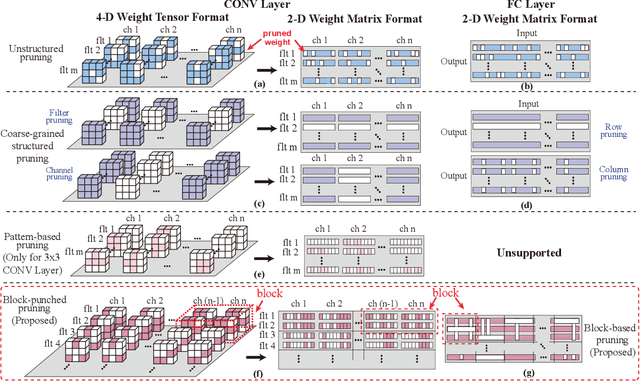

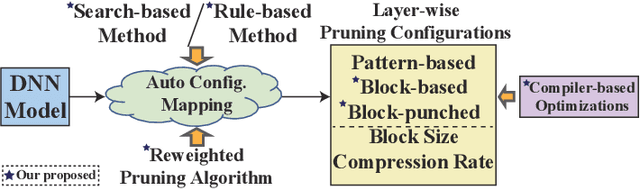
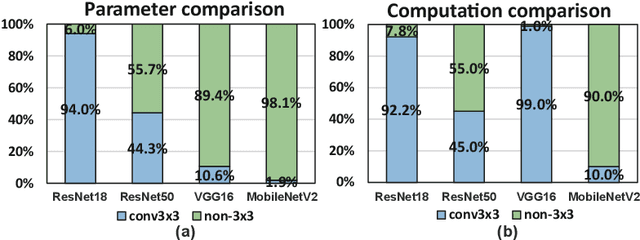
Weight pruning is an effective model compression technique to tackle the challenges of achieving real-time deep neural network (DNN) inference on mobile devices. However, prior pruning schemes have limited application scenarios due to accuracy degradation, difficulty in leveraging hardware acceleration, and/or restriction on certain types of DNN layers. In this paper, we propose a general, fine-grained structured pruning scheme and corresponding compiler optimizations that are applicable to any type of DNN layer while achieving high accuracy and hardware inference performance. With the flexibility of applying different pruning schemes to different layers enabled by our compiler optimizations, we further probe into the new problem of determining the best-suited pruning scheme considering the different acceleration and accuracy performance of various pruning schemes. Two pruning scheme mapping methods, one is search-based and the other is rule-based, are proposed to automatically derive the best-suited pruning regularity and block size for each layer of any given DNN. Experimental results demonstrate that our pruning scheme mapping methods, together with the general fine-grained structured pruning scheme, outperform the state-of-the-art DNN optimization framework with up to 2.48$\times$ and 1.73$\times$ DNN inference acceleration on CIFAR-10 and ImageNet dataset without accuracy loss.
Structure Parameter Optimized Kernel Based Online Prediction with a Generalized Optimization Strategy for Nonstationary Time Series
Aug 18, 2021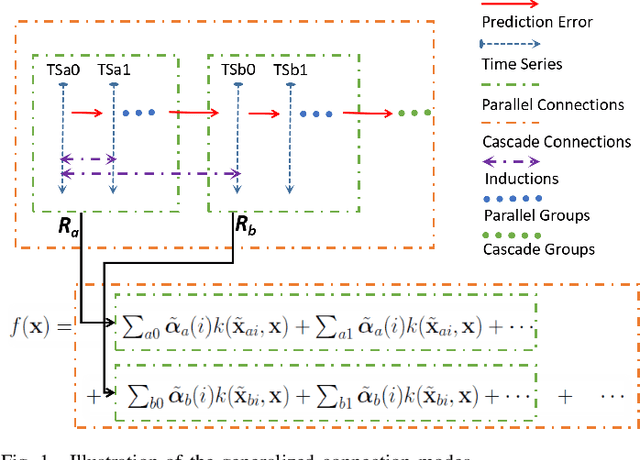
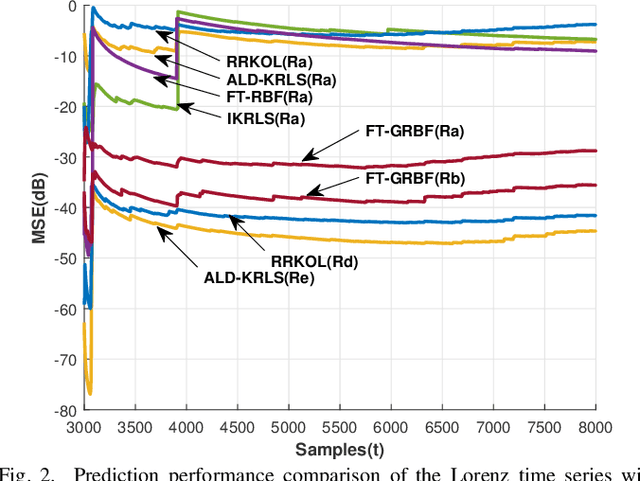
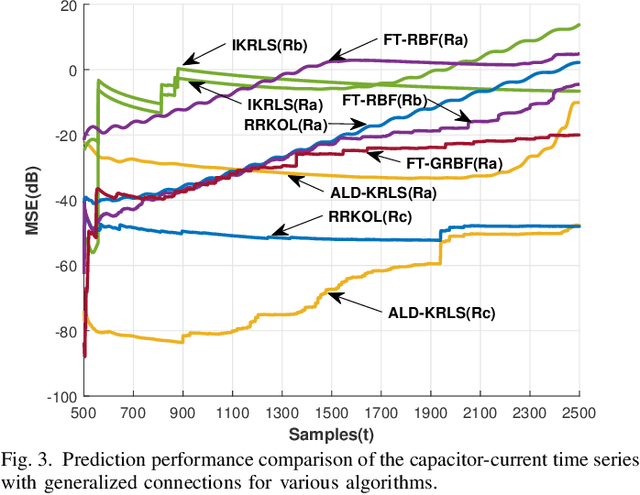
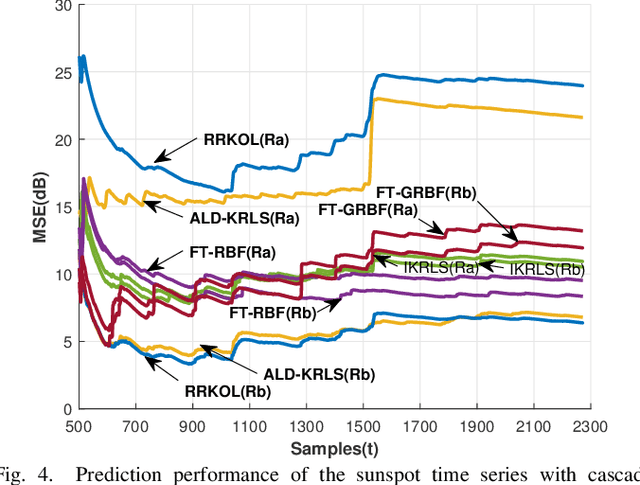
In this paper, sparsification techniques aided online prediction algorithms in a reproducing kernel Hilbert space are studied for nonstationary time series. The online prediction algorithms as usual consist of the selection of kernel structure parameters and the kernel weight vector updating. For structure parameters, the kernel dictionary is selected by some sparsification techniques with online selective modeling criteria, and moreover the kernel covariance matrix is intermittently optimized in the light of the covariance matrix adaptation evolution strategy (CMA-ES). Optimizing the real symmetric covariance matrix can not only improve the kernel structure's flexibility by the cross relatedness of the input variables, but also partly alleviate the prediction uncertainty caused by the kernel dictionary selection for nonstationary time series. In order to sufficiently capture the underlying dynamic characteristics in prediction-error time series, a generalized optimization strategy is designed to construct the kernel dictionary sequentially in multiple kernel connection modes. The generalized optimization strategy provides a more self-contained way to construct the entire kernel connections, which enhances the ability to adaptively track the changing dynamic characteristics. Numerical simulations have demonstrated that the proposed approach has superior prediction performance for nonstationary time series.
Evaluating object detector ensembles for improving the robustness of artifact detection in endoscopic video streams
Jun 15, 2022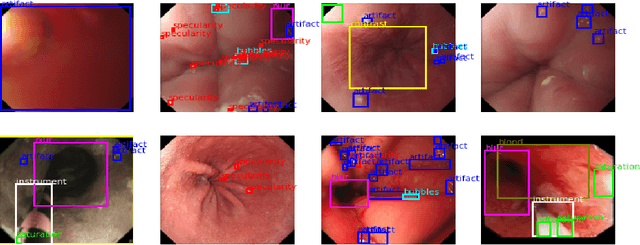
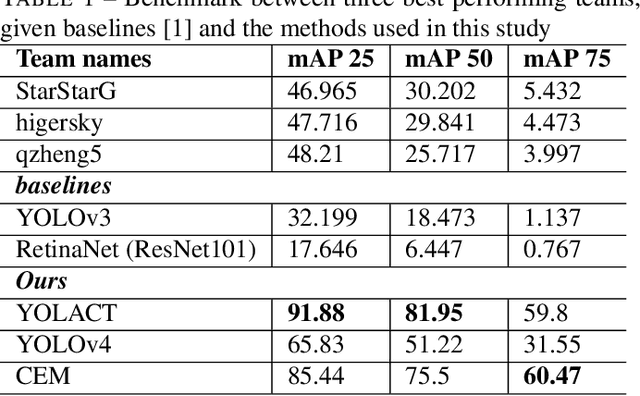
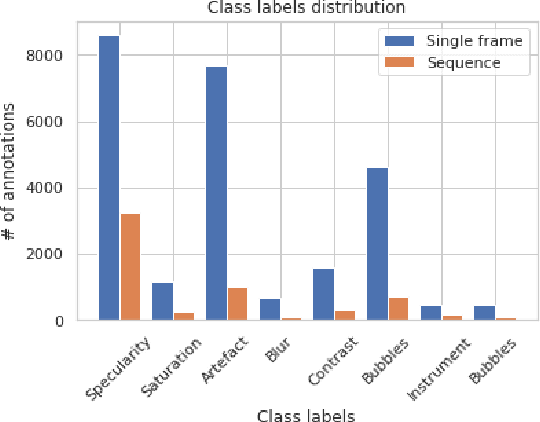
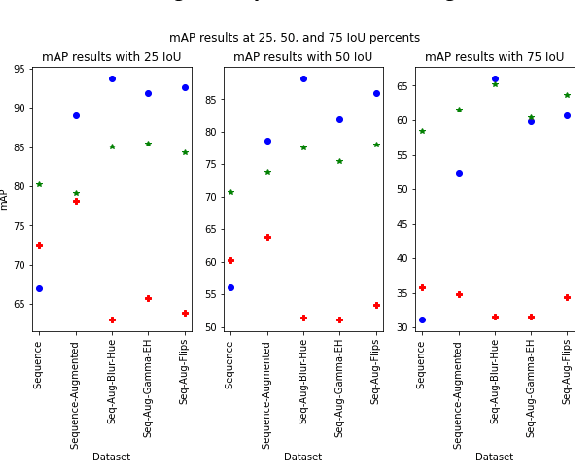
In this contribution we use an ensemble deep-learning method for combining the prediction of two individual one-stage detectors (i.e., YOLOv4 and Yolact) with the aim to detect artefacts in endoscopic images. This ensemble strategy enabled us to improve the robustness of the individual models without harming their real-time computation capabilities. We demonstrated the effectiveness of our approach by training and testing the two individual models and various ensemble configurations on the "Endoscopic Artifact Detection Challenge" dataset. Extensive experiments show the superiority, in terms of mean average precision, of the ensemble approach over the individual models and previous works in the state of the art.
A Novel Partitioned Approach for Reduced Order Model -- Finite Element Model (ROM-FEM) and ROM-ROM Coupling
Jun 09, 2022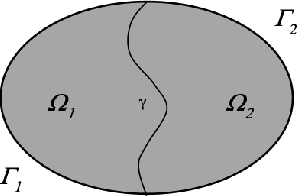
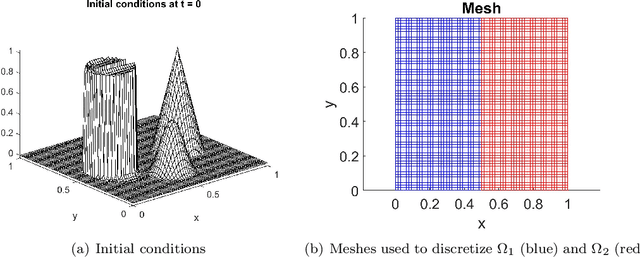
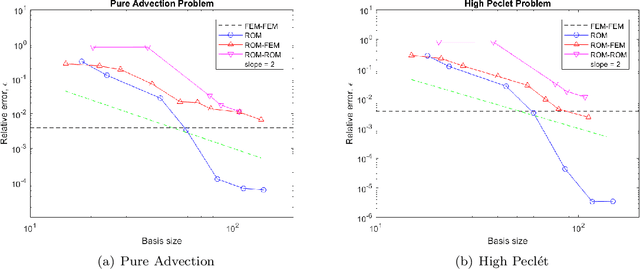
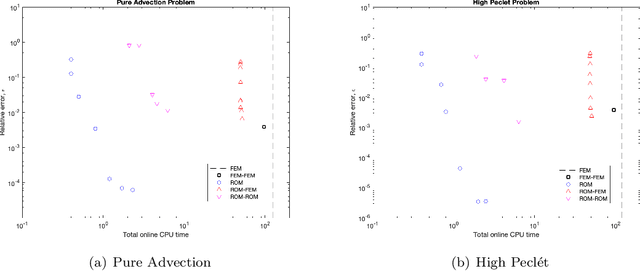
Partitioned methods allow one to build a simulation capability for coupled problems by reusing existing single-component codes. In so doing, partitioned methods can shorten code development and validation times for multiphysics and multiscale applications. In this work, we consider a scenario in which one or more of the "codes" being coupled are projection-based reduced order models (ROMs), introduced to lower the computational cost associated with a particular component. We simulate this scenario by considering a model interface problem that is discretized independently on two non-overlapping subdomains. We then formulate a partitioned scheme for this problem that allows the coupling between a ROM "code" for one of the subdomains with a finite element model (FEM) or ROM "code" for the other subdomain. The ROM "codes" are constructed by performing proper orthogonal decomposition (POD) on a snapshot ensemble to obtain a low-dimensional reduced order basis, followed by a Galerkin projection onto this basis. The ROM and/or FEM "codes" on each subdomain are then coupled using a Lagrange multiplier representing the interface flux. To partition the resulting monolithic problem, we first eliminate the flux through a dual Schur complement. Application of an explicit time integration scheme to the transformed monolithic problem decouples the subdomain equations, allowing their independent solution for the next time step. We show numerical results that demonstrate the proposed method's efficacy in achieving both ROM-FEM and ROM-ROM coupling.
An adaptive admittance controller for collaborative drilling with a robot based on subtask classification via deep learning
May 31, 2022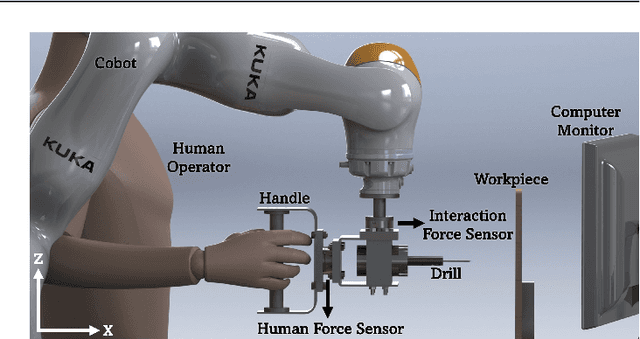
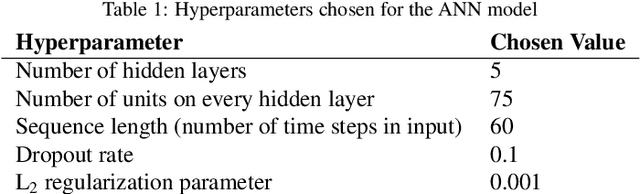
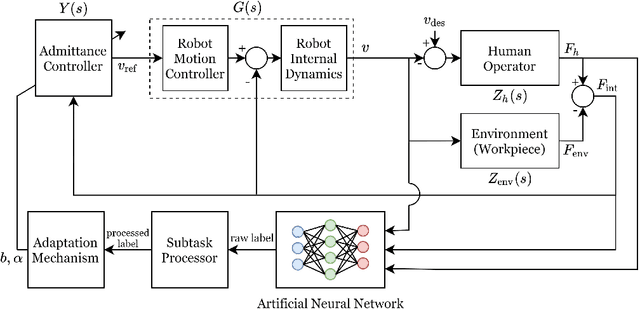
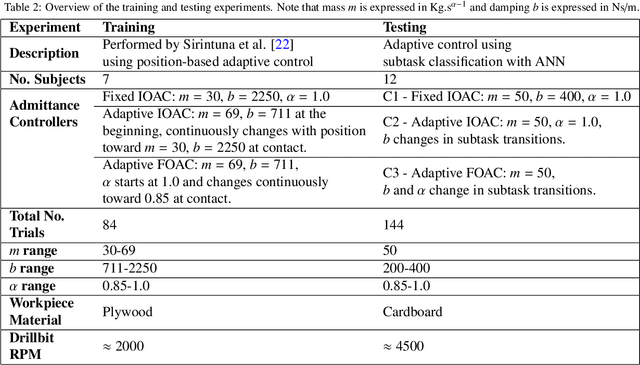
In this paper, we propose a supervised learning approach based on an Artificial Neural Network (ANN) model for real-time classification of subtasks in a physical human-robot interaction (pHRI) task involving contact with a stiff environment. In this regard, we consider three subtasks for a given pHRI task: Idle, Driving, and Contact. Based on this classification, the parameters of an admittance controller that regulates the interaction between human and robot are adjusted adaptively in real time to make the robot more transparent to the operator (i.e. less resistant) during the Driving phase and more stable during the Contact phase. The Idle phase is primarily used to detect the initiation of task. Experimental results have shown that the ANN model can learn to detect the subtasks under different admittance controller conditions with an accuracy of 98% for 12 participants. Finally, we show that the admittance adaptation based on the proposed subtask classifier leads to 20% lower human effort (i.e. higher transparency) in the Driving phase and 25% lower oscillation amplitude (i.e. higher stability) during drilling in the Contact phase compared to an admittance controller with fixed parameters.
Contaminant source identification in groundwater by means of artificial neural network
Jul 19, 2022
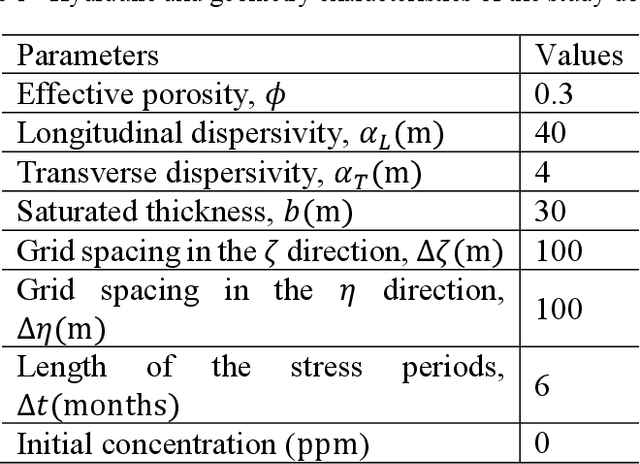
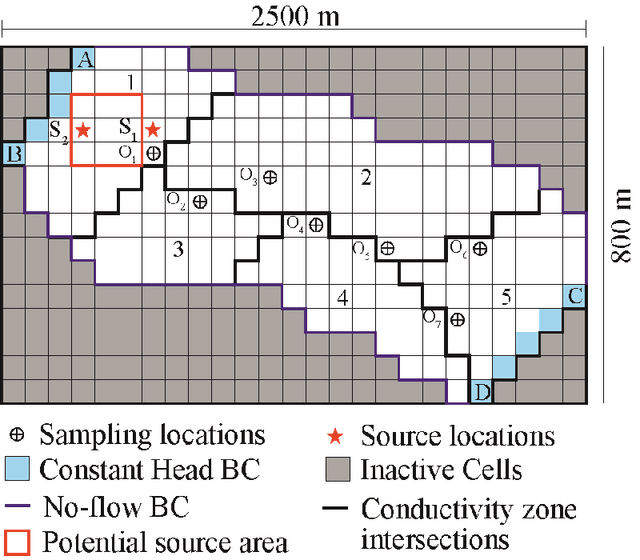
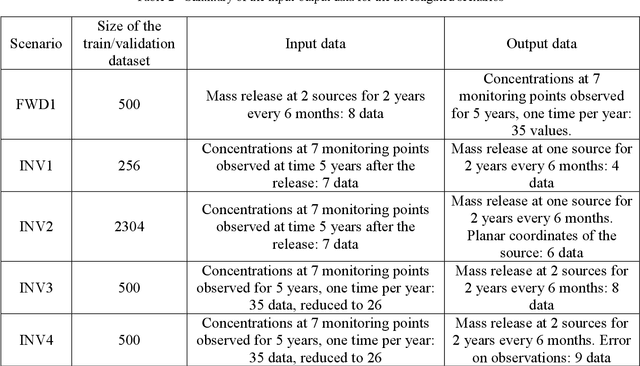
In a desired environmental protection system, groundwater may not be excluded. In addition to the problem of over-exploitation, in total disagreement with the concept of sustainable development, another not negligible issue concerns the groundwater contamination. Mainly, this aspect is due to intensive agricultural activities or industrialized areas. In literature, several papers have dealt with transport problem, especially for inverse problems in which the release history or the source location are identified. The innovative aim of the paper is to develop a data-driven model that is able to analyze multiple scenarios, even strongly non-linear, in order to solve forward and inverse transport problems, preserving the reliability of the results and reducing the uncertainty. Furthermore, this tool has the characteristic of providing extremely fast responses, essential to identify remediation strategies immediately. The advantages produced by the model were compared with literature studies. In this regard, a feedforward artificial neural network, which has been trained to handle different cases, represents the data-driven model. Firstly, to identify the concentration of the pollutant at specific observation points in the study area (forward problem); secondly, to deal with inverse problems identifying the release history at known source location; then, in case of one contaminant source, identifying the release history and, at the same time, the location of the source in a specific sub-domain of the investigated area. At last, the observation error is investigated and estimated. The results are satisfactorily achieved, highlighting the capability of the ANN to deal with multiple scenarios by approximating nonlinear functions without the physical point of view that describes the phenomenon, providing reliable results, with very low computational burden and uncertainty.
* Published on Journal of Hydrology
TöRF: Time-of-Flight Radiance Fields for Dynamic Scene View Synthesis
Sep 30, 2021
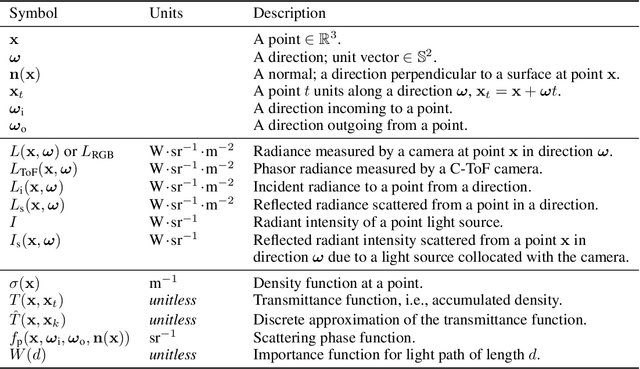
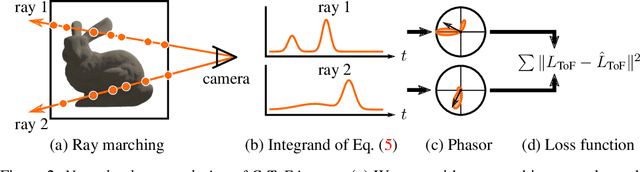
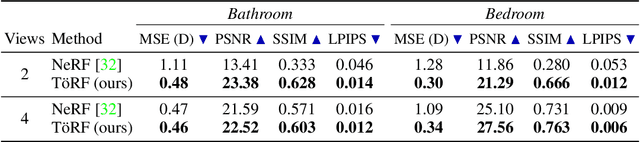
Neural networks can represent and accurately reconstruct radiance fields for static 3D scenes (e.g., NeRF). Several works extend these to dynamic scenes captured with monocular video, with promising performance. However, the monocular setting is known to be an under-constrained problem, and so methods rely on data-driven priors for reconstructing dynamic content. We replace these priors with measurements from a time-of-flight (ToF) camera, and introduce a neural representation based on an image formation model for continuous-wave ToF cameras. Instead of working with processed depth maps, we model the raw ToF sensor measurements to improve reconstruction quality and avoid issues with low reflectance regions, multi-path interference, and a sensor's limited unambiguous depth range. We show that this approach improves robustness of dynamic scene reconstruction to erroneous calibration and large motions, and discuss the benefits and limitations of integrating RGB+ToF sensors that are now available on modern smartphones.
Probability flow solution of the Fokker-Planck equation
Jun 09, 2022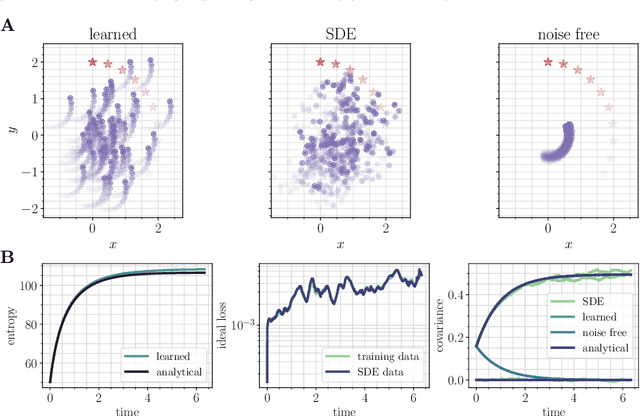
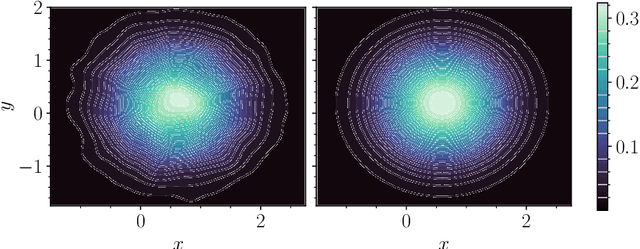
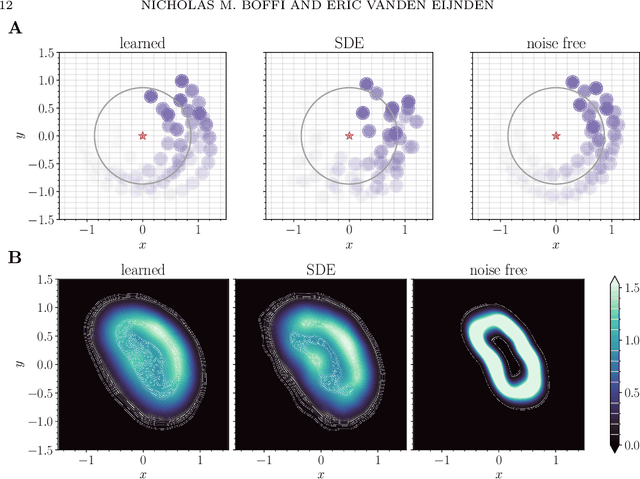
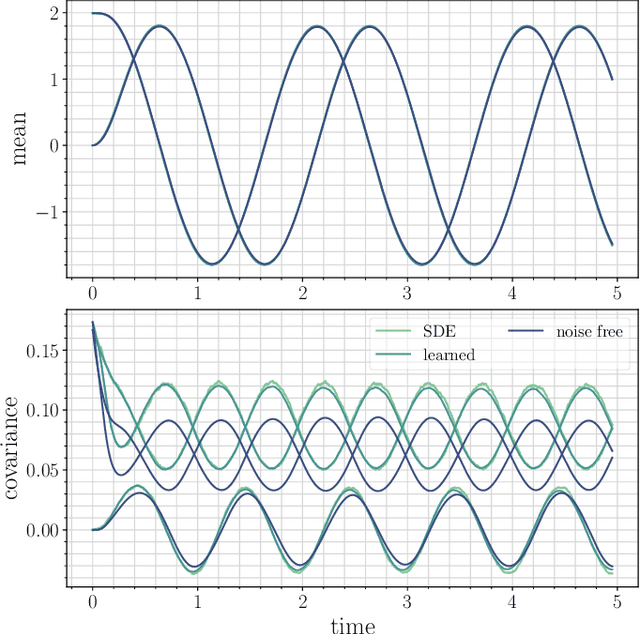
The method of choice for integrating the time-dependent Fokker-Planck equation in high-dimension is to generate samples from the solution via integration of the associated stochastic differential equation. Here, we introduce an alternative scheme based on integrating an ordinary differential equation that describes the flow of probability. Unlike the stochastic dynamics, this equation deterministically pushes samples from the initial density onto samples from the solution at any later time. The method has the advantage of giving direct access to quantities that are challenging to estimate only given samples from the solution, such as the probability current, the density itself, and its entropy. The probability flow equation depends on the gradient of the logarithm of the solution (its "score"), and so is a-priori unknown. To resolve this dependence, we model the score with a deep neural network that is learned on-the-fly by propagating a set of particles according to the instantaneous probability current. Our approach is based on recent advances in score-based diffusion for generative modeling, with the important difference that the training procedure is self-contained and does not require samples from the target density to be available beforehand. To demonstrate the validity of the approach, we consider several examples from the physics of interacting particle systems; we find that the method scales well to high-dimensional systems, and accurately matches available analytical solutions and moments computed via Monte-Carlo.
Distributed Gaussian Process Mapping for Robot Teams with Time-varying Communication
Oct 12, 2021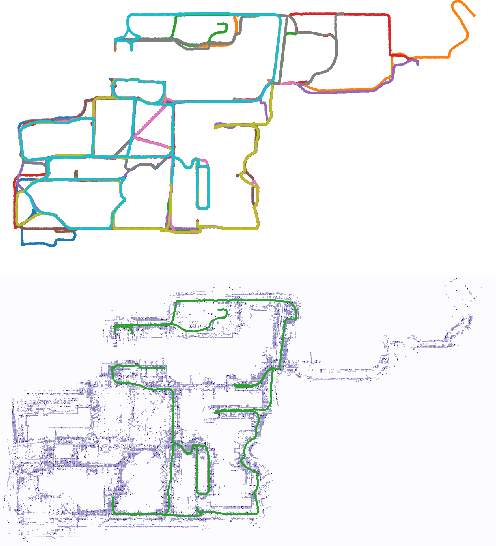
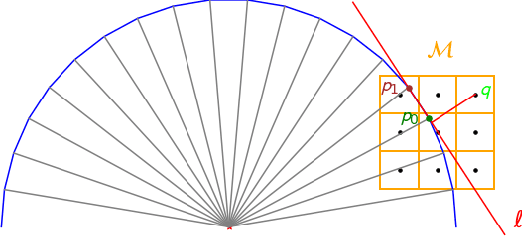
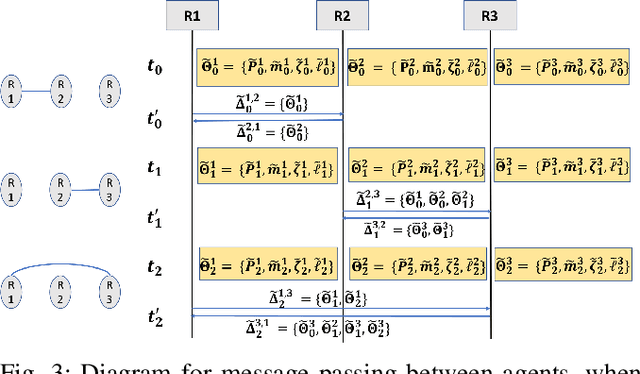
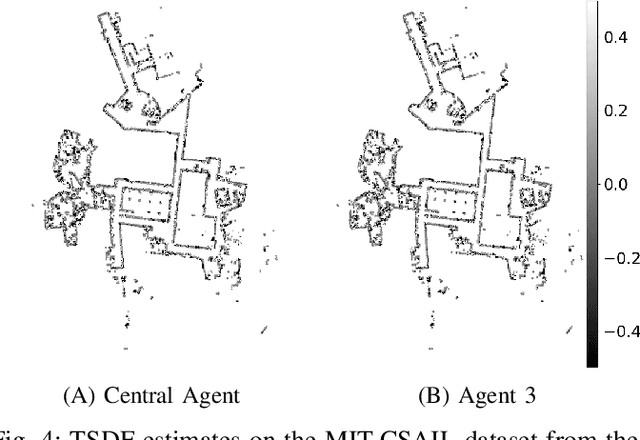
Multi-agent mapping is a fundamentally important capability for autonomous robot task coordination and execution in complex environments. While successful algorithms have been proposed for mapping using individual platforms, cooperative online mapping for teams of robots remains largely a challenge. We focus on probabilistic variants of mapping due to its potential utility in downstream tasks such as uncertainty-aware path-planning. A critical question to enabling this capability is how to process and aggregate incrementally observed local information among individual platforms, especially when their ability to communicate is intermittent. We put forth an Incremental Sparse Gaussian Process (GP) methodology for multi-robot mapping, where the regression is over a truncated signed-distance field (TSDF). Doing so permits each robot in the network to track a local estimate of a pseudo-point approximation GP posterior and perform weighted averaging of its parameters with those of its (possibly time-varying) set of neighbors. We establish conditions on the pseudo-point representation, as well as communication protocol, such that robots' local GPs converge to the one with globally aggregated information. We further provide experiments that corroborate our theoretical findings for probabilistic multi-robot mapping.