 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Event-Based Feature Tracking in Continuous Time with Sliding Window Optimization
Jul 09, 2021
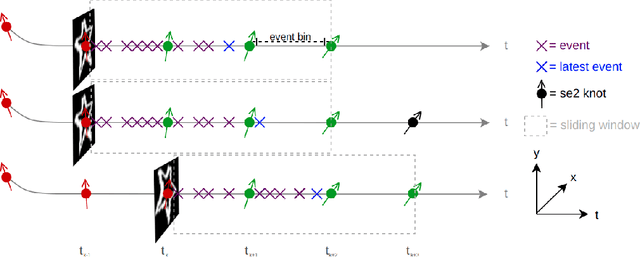
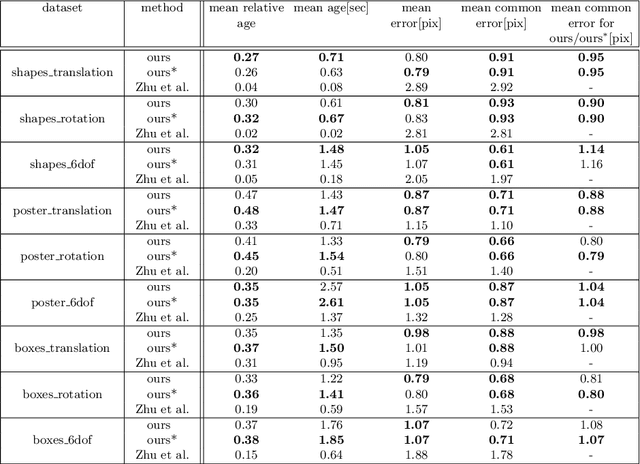
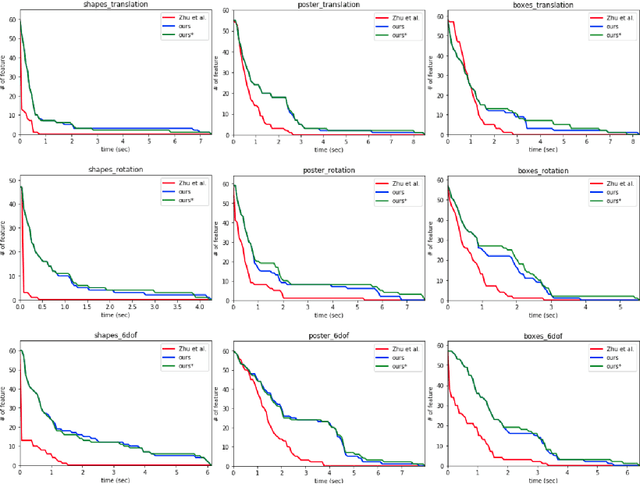

We propose a novel method for continuous-time feature tracking in event cameras. To this end, we track features by aligning events along an estimated trajectory in space-time such that the projection on the image plane results in maximally sharp event patch images. The trajectory is parameterized by $n^{th}$ order B-splines, which are continuous up to $(n-2)^{th}$ derivative. In contrast to previous work, we optimize the curve parameters in a sliding window fashion. On a public dataset we experimentally confirm that the proposed sliding-window B-spline optimization leads to longer and more accurate feature tracks than in previous work.
Constrained Reinforcement Learning for Short Video Recommendation
May 26, 2022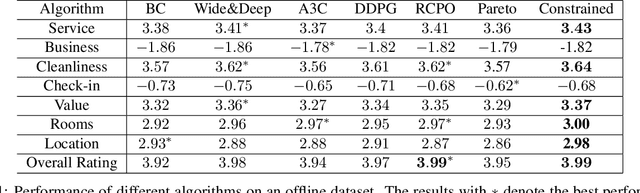
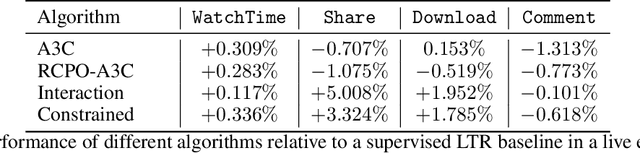
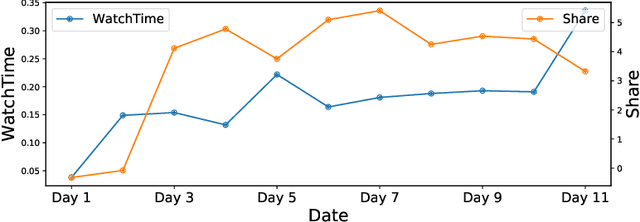
The wide popularity of short videos on social media poses new opportunities and challenges to optimize recommender systems on the video-sharing platforms. Users provide complex and multi-faceted responses towards recommendations, including watch time and various types of interactions with videos. As a result, established recommendation algorithms that concern a single objective are not adequate to meet this new demand of optimizing comprehensive user experiences. In this paper, we formulate the problem of short video recommendation as a constrained Markov Decision Process (MDP), where platforms want to optimize the main goal of user watch time in long term, with the constraint of accommodating the auxiliary responses of user interactions such as sharing/downloading videos. To solve the constrained MDP, we propose a two-stage reinforcement learning approach based on actor-critic framework. At stage one, we learn individual policies to optimize each auxiliary response. At stage two, we learn a policy to (i) optimize the main response and (ii) stay close to policies learned at the first stage, which effectively guarantees the performance of this main policy on the auxiliaries. Through extensive simulations, we demonstrate effectiveness of our approach over alternatives in both optimizing the main goal as well as balancing the others. We further show the advantage of our approach in live experiments of short video recommendations, where it significantly outperforms other baselines in terms of watch time and interactions from video views. Our approach has been fully launched in the production system to optimize user experiences on the platform.
Real-time Deep Dynamic Characters
May 04, 2021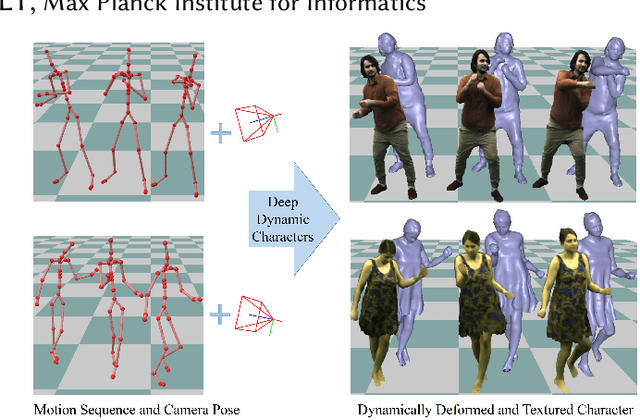

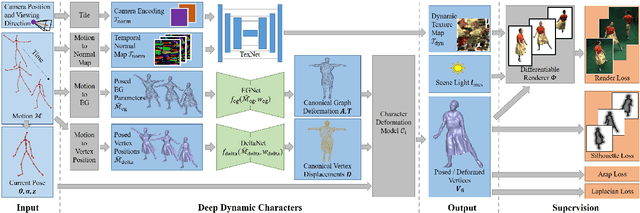

We propose a deep videorealistic 3D human character model displaying highly realistic shape, motion, and dynamic appearance learned in a new weakly supervised way from multi-view imagery. In contrast to previous work, our controllable 3D character displays dynamics, e.g., the swing of the skirt, dependent on skeletal body motion in an efficient data-driven way, without requiring complex physics simulation. Our character model also features a learned dynamic texture model that accounts for photo-realistic motion-dependent appearance details, as well as view-dependent lighting effects. During training, we do not need to resort to difficult dynamic 3D capture of the human; instead we can train our model entirely from multi-view video in a weakly supervised manner. To this end, we propose a parametric and differentiable character representation which allows us to model coarse and fine dynamic deformations, e.g., garment wrinkles, as explicit space-time coherent mesh geometry that is augmented with high-quality dynamic textures dependent on motion and view point. As input to the model, only an arbitrary 3D skeleton motion is required, making it directly compatible with the established 3D animation pipeline. We use a novel graph convolutional network architecture to enable motion-dependent deformation learning of body and clothing, including dynamics, and a neural generative dynamic texture model creates corresponding dynamic texture maps. We show that by merely providing new skeletal motions, our model creates motion-dependent surface deformations, physically plausible dynamic clothing deformations, as well as video-realistic surface textures at a much higher level of detail than previous state of the art approaches, and even in real-time.
Safe Human-Robot Collaborative Transportation via Trust-Driven Role Adaptation
Jul 13, 2022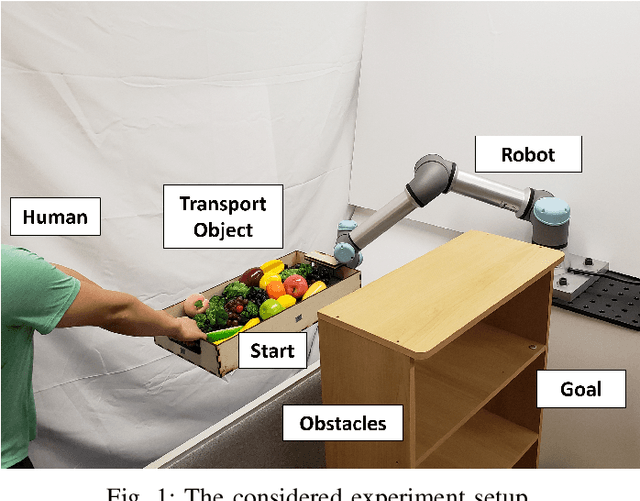
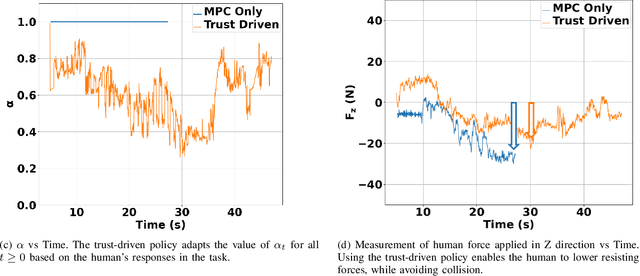
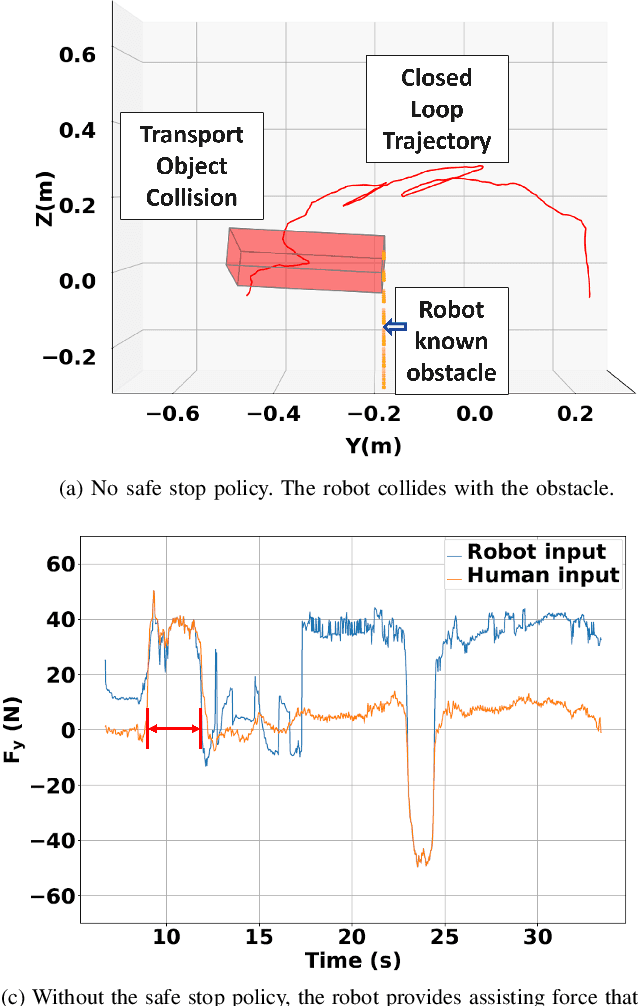
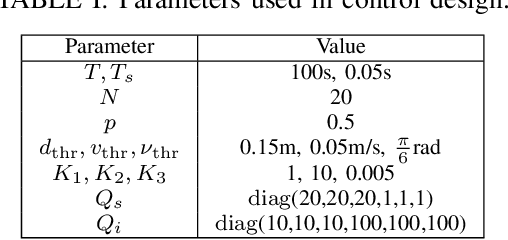
We study a human-robot collaborative transportation task in presence of obstacles. The task for each agent is to carry a rigid object to a common target position, while safely avoiding obstacles and satisfying the compliance and actuation constraints of the other agent. Human and robot do not share the local view of the environment. The human policy either assists the robot when they deem the robot actions safe based on their perception of the environment, or actively leads the task. Using estimated human inputs, the robot plans a trajectory for the transported object by solving a constrained finite time optimal control problem. Sensors on the robot measure the inputs applied by the human. The robot then appropriately applies a weighted combination of the human's applied and its own planned inputs, where the weights are chosen based on the robot's trust value on its estimates of the human's inputs. This allows for a dynamic leader-follower role adaptation of the robot throughout the task. Furthermore, under a low value of trust, if the robot approaches any obstacle potentially unknown to the human, it triggers a safe stopping policy, maintaining safety of the system and signaling a required change in the human's intent. With experimental results, we demonstrate the efficacy of the proposed approach.
Interpolation, extrapolation, and local generalization in common neural networks
Jul 18, 2022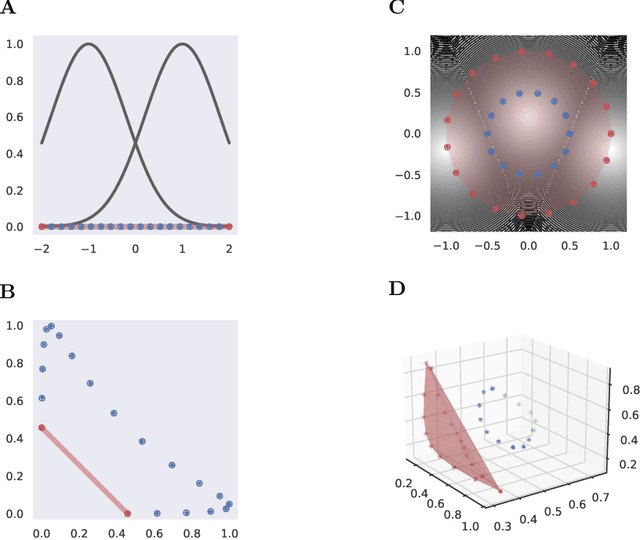
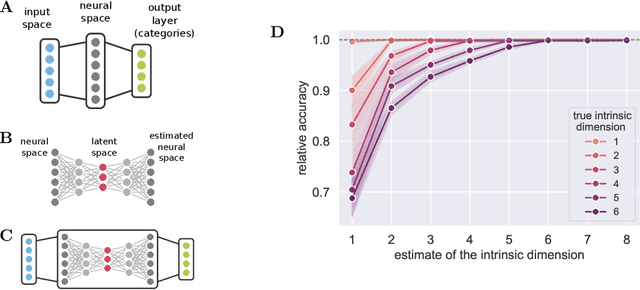
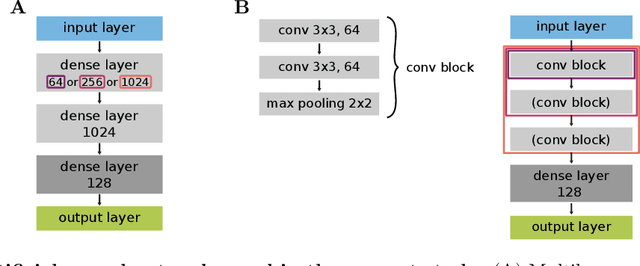
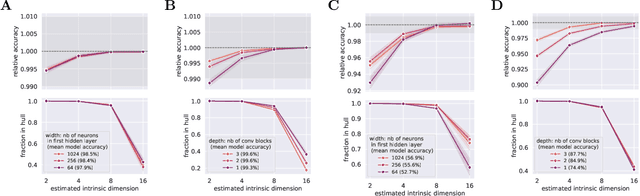
There has been a long history of works showing that neural networks have hard time extrapolating beyond the training set. A recent study by Balestriero et al. (2021) challenges this view: defining interpolation as the state of belonging to the convex hull of the training set, they show that the test set, either in input or neural space, cannot lie for the most part in this convex hull, due to the high dimensionality of the data, invoking the well known curse of dimensionality. Neural networks are then assumed to necessarily work in extrapolative mode. We here study the neural activities of the last hidden layer of typical neural networks. Using an autoencoder to uncover the intrinsic space underlying the neural activities, we show that this space is actually low-dimensional, and that the better the model, the lower the dimensionality of this intrinsic space. In this space, most samples of the test set actually lie in the convex hull of the training set: under the convex hull definition, the models thus happen to work in interpolation regime. Moreover, we show that belonging to the convex hull does not seem to be the relevant criteria. Different measures of proximity to the training set are actually better related to performance accuracy. Thus, typical neural networks do seem to operate in interpolation regime. Good generalization performances are linked to the ability of a neural network to operate well in such a regime.
Machine learning based iterative learning control for non-repetitive time-varying systems
Jul 01, 2021
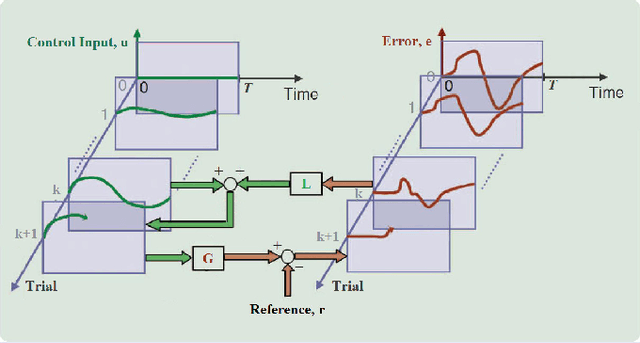
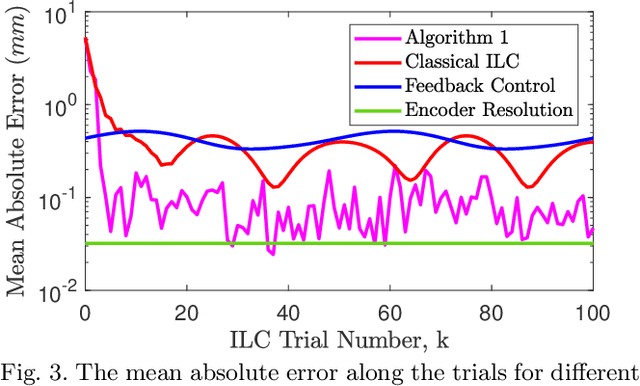
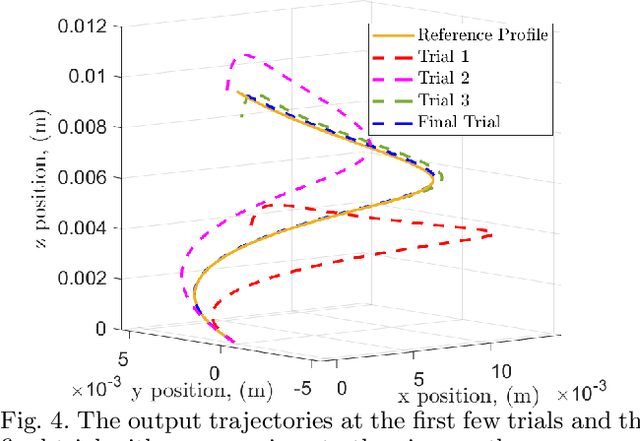
The repetitive tracking task for time-varying systems (TVSs) with non-repetitive time-varying parameters, which is also called non-repetitive TVSs, is realized in this paper using iterative learning control (ILC). A machine learning (ML) based nominal model update mechanism, which utilizes the linear regression technique to update the nominal model at each ILC trial only using the current trial information, is proposed for non-repetitive TVSs in order to enhance the ILC performance. Given that the ML mechanism forces the model uncertainties to remain within the ILC robust tolerance, an ILC update law is proposed to deal with non-repetitive TVSs. How to tune parameters inside ML and ILC algorithms to achieve the desired aggregate performance is also provided. The robustness and reliability of the proposed method are verified by simulations. Comparison with current state-of-the-art demonstrates its superior control performance in terms of controlling precision. This paper broadens ILC applications from time-invariant systems to non-repetitive TVSs, adopts ML regression technique to estimate non-repetitive time-varying parameters between two ILC trials and proposes a detailed parameter tuning mechanism to achieve desired performance, which are the main contributions.
Adaptive Graph Spatial-Temporal Transformer Network for Traffic Flow Forecasting
Jul 09, 2022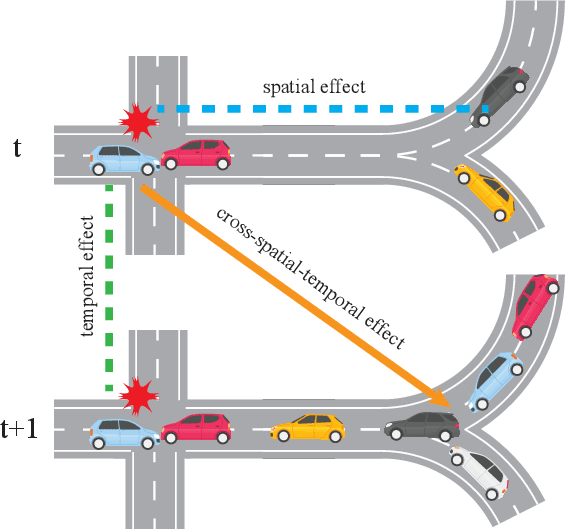
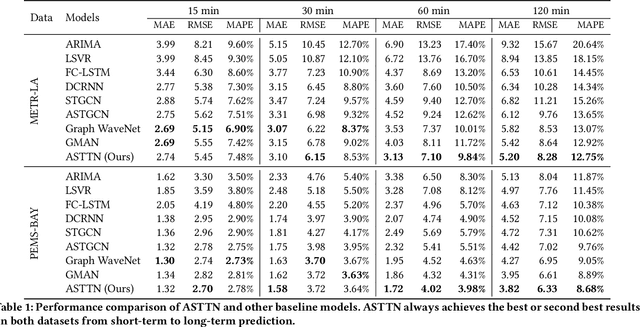
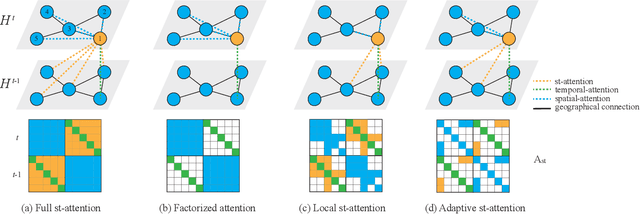
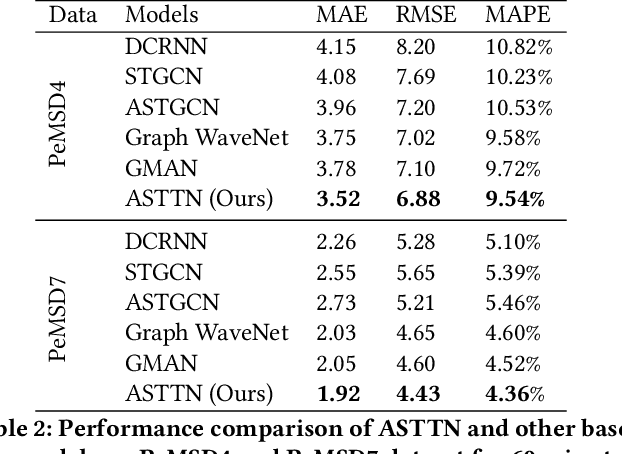
Traffic flow forecasting on graphs has real-world applications in many fields, such as transportation system and computer networks. Traffic forecasting can be highly challenging due to complex spatial-temporal correlations and non-linear traffic patterns. Existing works mostly model such spatial-temporal dependencies by considering spatial correlations and temporal correlations separately and fail to model the direct spatial-temporal correlations. Inspired by the recent success of transformers in the graph domain, in this paper, we propose to directly model the cross-spatial-temporal correlations on the spatial-temporal graph using local multi-head self-attentions. To reduce the time complexity, we set the attention receptive field to the spatially neighboring nodes, and we also introduce an adaptive graph to capture the hidden spatial-temporal dependencies. Based on these attention mechanisms, we propose a novel Adaptive Graph Spatial-Temporal Transformer Network (ASTTN), which stacks multiple spatial-temporal attention layers to apply self-attention on the input graph, followed by linear layers for predictions. Experimental results on public traffic network datasets, METR-LA PEMS-BAY, PeMSD4, and PeMSD7, demonstrate the superior performance of our model.
MegazordNet: combining statistical and machine learning standpoints for time series forecasting
Jun 23, 2021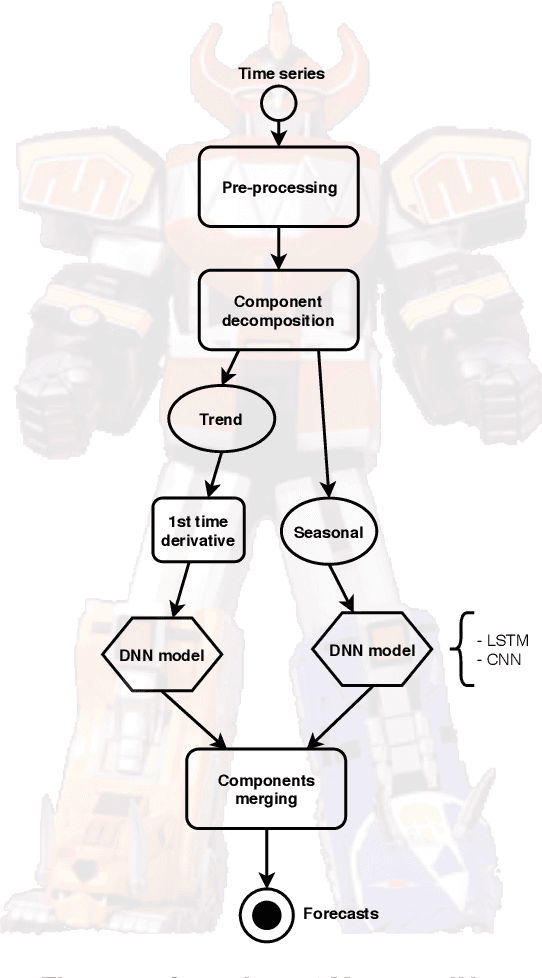

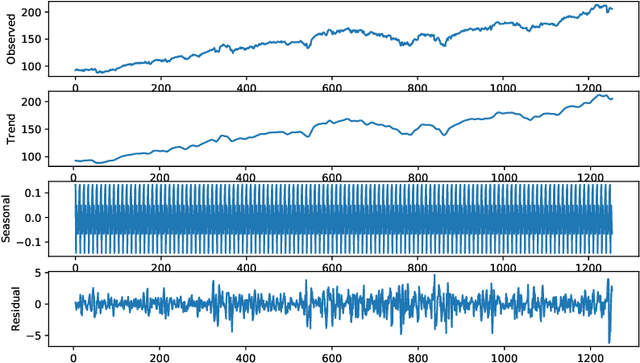

Forecasting financial time series is considered to be a difficult task due to the chaotic feature of the series. Statistical approaches have shown solid results in some specific problems such as predicting market direction and single-price of stocks; however, with the recent advances in deep learning and big data techniques, new promising options have arises to tackle financial time series forecasting. Moreover, recent literature has shown that employing a combination of statistics and machine learning may improve accuracy in the forecasts in comparison to single solutions. Taking into consideration the mentioned aspects, in this work, we proposed the MegazordNet, a framework that explores statistical features within a financial series combined with a structured deep learning model for time series forecasting. We evaluated our approach predicting the closing price of stocks in the S&P 500 using different metrics, and we were able to beat single statistical and machine learning methods.
TadML: A fast temporal action detection with Mechanics-MLP
Jun 07, 2022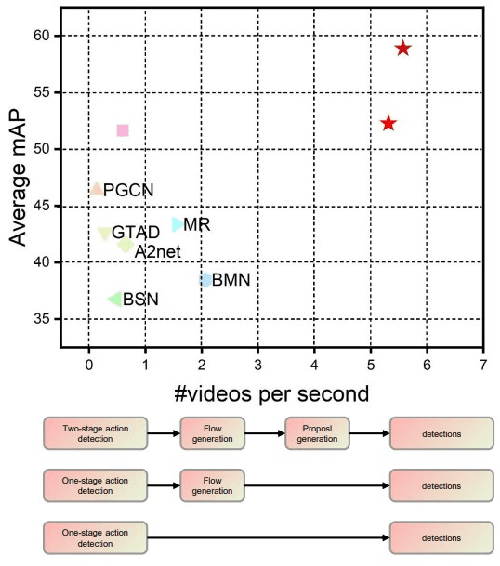
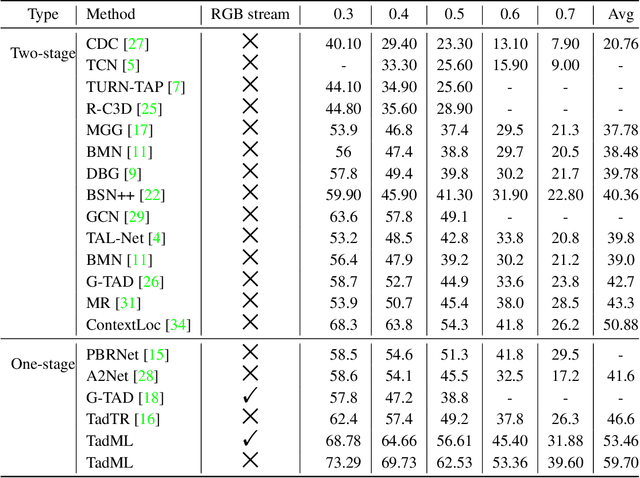
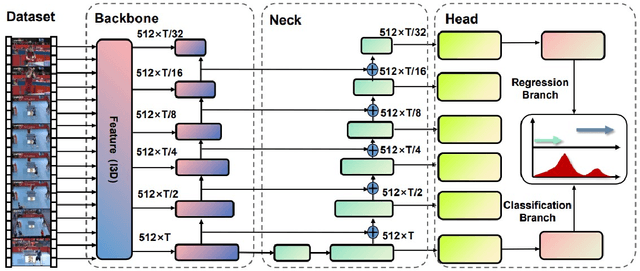
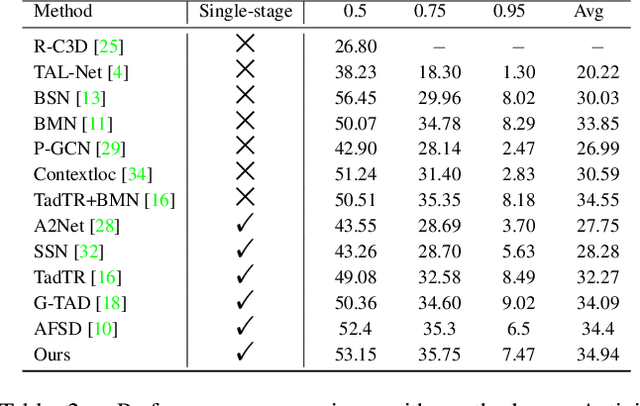
Temporal Action Detection(TAD) is a crucial but challenging task in video understanding.It is aimed at detecting both the type and start-end frame for each action instance in a long, untrimmed video.Most current models adopt both RGB and Optical-Flow streams for the TAD task. Thus, original RGB frames must be converted manually into Optical-Flow frames with additional computation and time cost, which is an obstacle to achieve real-time processing. At present, many models adopt two-stage strategies, which would slow the inference speed down and complicatedly tuning on proposals generating.By comparison, we propose a one-stage anchor-free temporal localization method with RGB stream only, in which a novel Newtonian \emph{Mechanics-MLP} architecture is established. It has comparable accuracy with all existing state-of-the-art models, while surpasses the inference speed of these methods by a large margin. The typical inference speed in this paper is astounding 4.44 video per second on THUMOS14. In applications, because there is no need to convert optical flow, the inference speed will be faster.It also proves that \emph{MLP} has great potential in downstream tasks such as TAD. The source code is available at \url{https://github.com/BonedDeng/TadML}
AHD ConvNet for Speech Emotion Classification
Jun 21, 2022
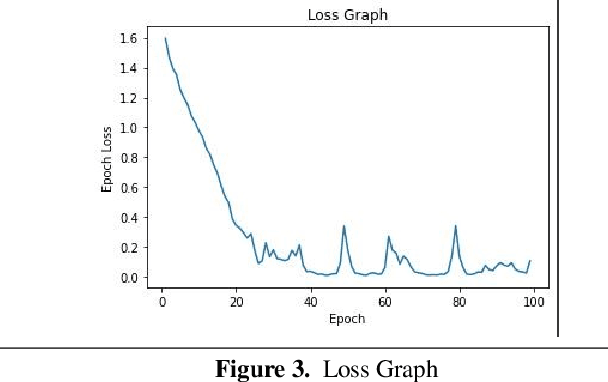
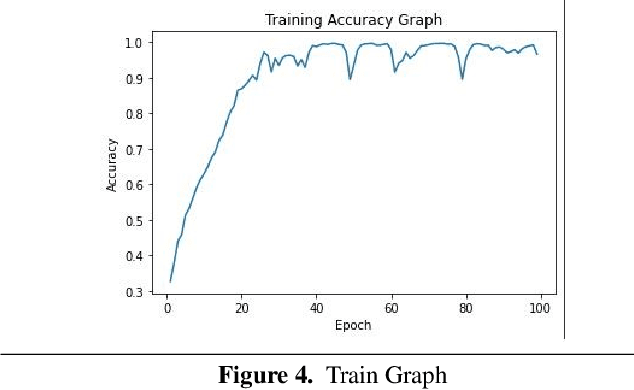
Accomplishments in the field of artificial intelligence are utilized in the advancement of computing and making of intelligent machines for facilitating mankind and improving user experience. Emotions are rudimentary for people, affecting thinking and ordinary exercises like correspondence, learning and direction. Speech emotion recognition is domain of interest in this regard and in this work, we propose a novel mel spectrogram learning approach in which our model uses the datapoints to learn emotions from the given wav form voice notes in the popular CREMA-D dataset. Our model uses log mel-spectrogram as feature with number of mels = 64. It took less training time compared to other approaches used to address the problem of emotion speech recognition.