 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Joint domain adaptation and speech bandwidth extension using time-domain GANs for speaker verification
Mar 30, 2022
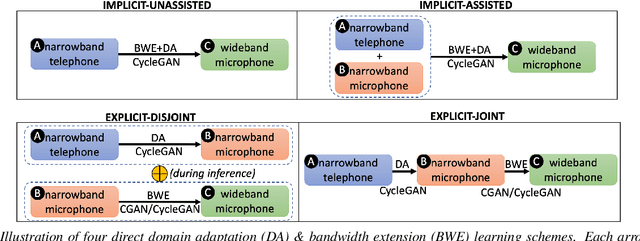
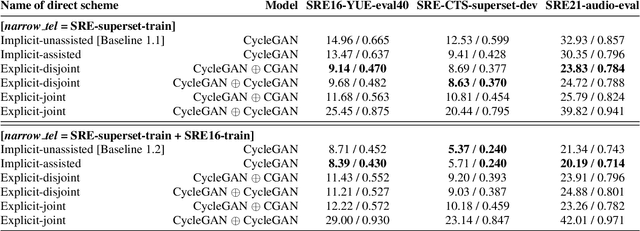
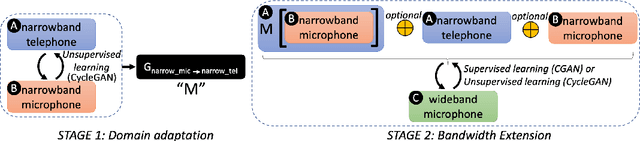

Speech systems developed for a particular choice of acoustic domain and sampling frequency do not translate easily to others. The usual practice is to learn domain adaptation and bandwidth extension models independently. Contrary to this, we propose to learn both tasks together. Particularly, we learn to map narrowband conversational telephone speech to wideband microphone speech. We developed parallel and non-parallel learning solutions which utilize both paired and unpaired data. First, we first discuss joint and disjoint training of multiple generative models for our tasks. Then, we propose a two-stage learning solution where we use a pre-trained domain adaptation system for pre-processing in bandwidth extension training. We evaluated our schemes on a Speaker Verification downstream task. We used the JHU-MIT experimental setup for NIST SRE21, which comprises SRE16, SRE-CTS Superset and SRE21. Our results provide the first evidence that learning both tasks is better than learning just one. On SRE16, our best system achieves 22% relative improvement in Equal Error Rate w.r.t. a direct learning baseline and 8% w.r.t. a strong bandwidth expansion system.
Scalable Vehicle Re-Identification via Self-Supervision
May 16, 2022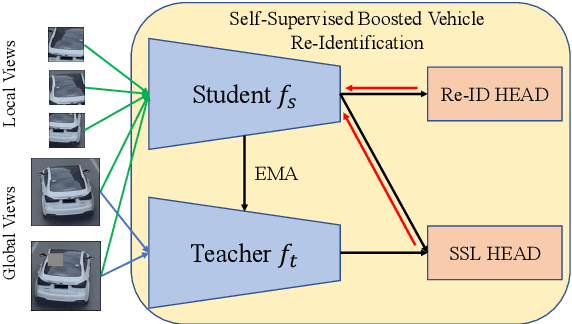
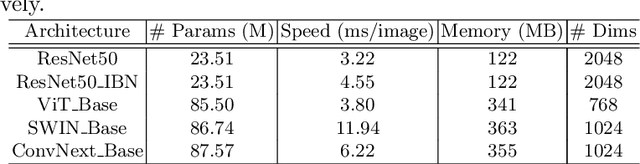
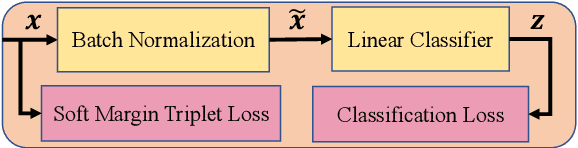
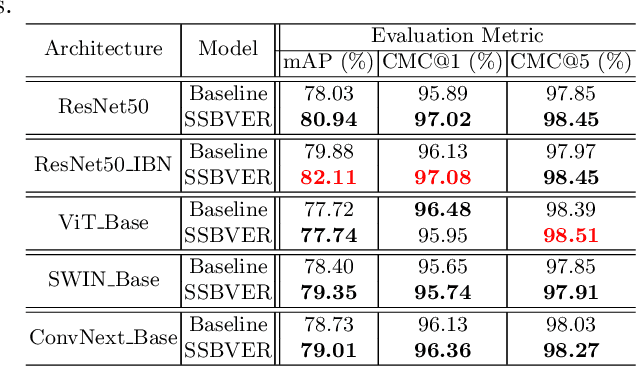
As Computer Vision technologies become more mature for intelligent transportation applications, it is time to ask how efficient and scalable they are for large-scale and real-time deployment. Among these technologies is Vehicle Re-Identification which is one of the key elements in city-scale vehicle analytics systems. Many state-of-the-art solutions for vehicle re-id mostly focus on improving the accuracy on existing re-id benchmarks and often ignore computational complexity. To balance the demands of accuracy and computational efficiency, in this work we propose a simple yet effective hybrid solution empowered by self-supervised training which only uses a single network during inference time and is free of intricate and computation-demanding add-on modules often seen in state-of-the-art approaches. Through extensive experiments, we show our approach, termed Self-Supervised and Boosted VEhicle Re-Identification (SSBVER), is on par with state-of-the-art alternatives in terms of accuracy without introducing any additional overhead during deployment. Additionally we show that our approach, generalizes to different backbone architectures which facilitates various resource constraints and consistently results in a significant accuracy boost.
Rhythm and form in music: a complex systems approach
Jul 07, 2022
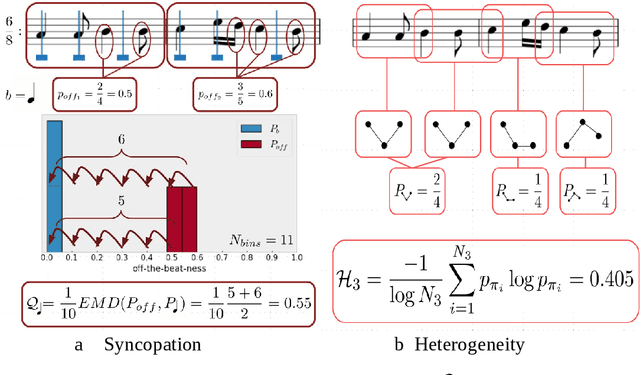
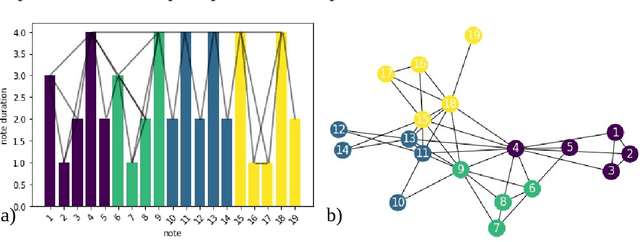

There has been an everlasting discussion around the concept of form in music. This work is motivated by such debate by using a complex systems framework in which we study the form as an emergent property of rhythm. Such a framework corresponds with the traditional notion of musical form and allows us to generalize this concept to more general shapes and structures in music. We develop the three following metrics of the rhythmic complexity of a musical piece and its parts: 1) the rhythmic heterogeneity, based on the permutation entropy, where high values indicate a wide variety of rhythmic patterns; 2) the syncopation, based on the distribution of on-beat onsets, where high values indicate a high proportion of off-the-beat notes; and 3) the component extractor, based on the communities of a visibility graph of the rhythmic figures over time, where we identify structural components that constitute the piece at a (to be explained) perceptual level. With the same parameters, our metrics are comparable within a piece or between pieces.
Problem Decomposition and Multi-shot ASP Solving for Job-shop Scheduling
May 16, 2022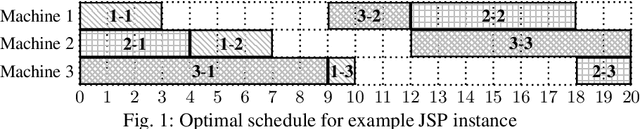
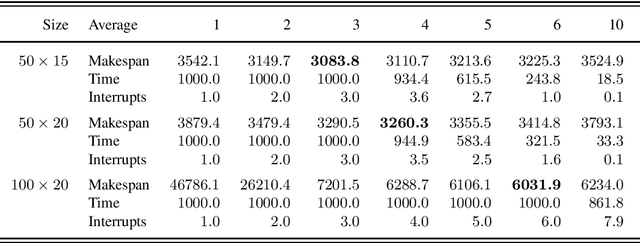

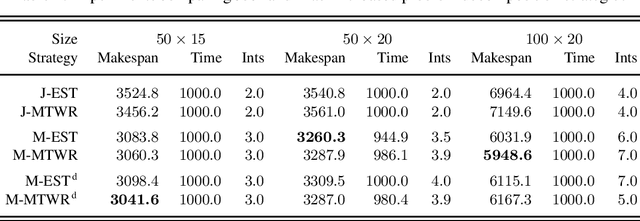
The Job-shop Scheduling Problem (JSP) is a well-known and challenging combinatorial optimization problem in which tasks sharing a machine are to be arranged in a sequence such that encompassing jobs can be completed as early as possible. In this paper, we propose problem decomposition into time windows whose operations can be successively scheduled and optimized by means of multi-shot Answer Set Programming (ASP) solving. Decomposition aims to split highly complex scheduling tasks into better manageable sub-problems with a balanced number of operations so that good quality or even optimal partial solutions can be reliably found in a small fraction of runtime. Problem decomposition must respect the precedence of operations within their jobs and partial schedules optimized by time windows should yield better global solutions than obtainable in similar runtime on the entire instance. We devise and investigate a variety of decomposition strategies in terms of the number and size of time windows as well as heuristics for choosing their operations. Moreover, we incorporate time window overlapping and compression techniques into the iterative scheduling process to counteract window-wise optimization limitations restricted to partial schedules. Our experiments on JSP benchmark sets of several sizes show that successive optimization by multi-shot ASP solving leads to substantially better schedules within the runtime limit than global optimization on the full problem, where the gap increases with the number of operations to schedule. While the obtained solution quality still remains behind a state-of-the-art Constraint Programming system, our multi-shot solving approach comes closer the larger the instance size, demonstrating good scalability by problem decomposition.
United States Politicians' Tone Became More Negative with 2016 Primary Campaigns
Jul 17, 2022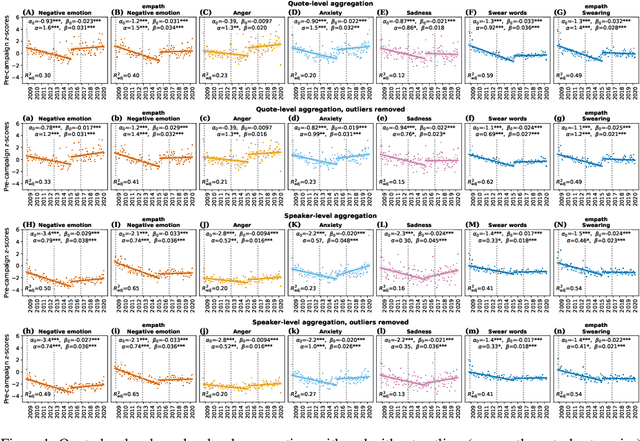
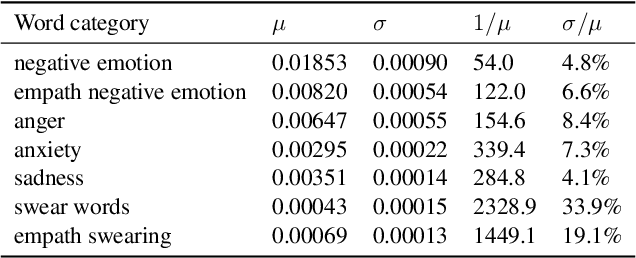
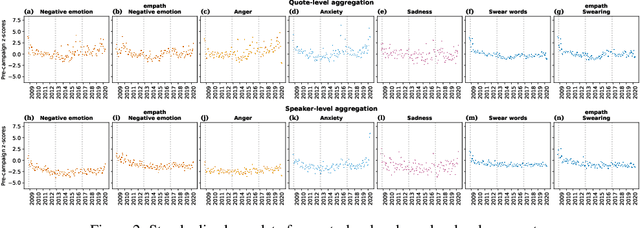
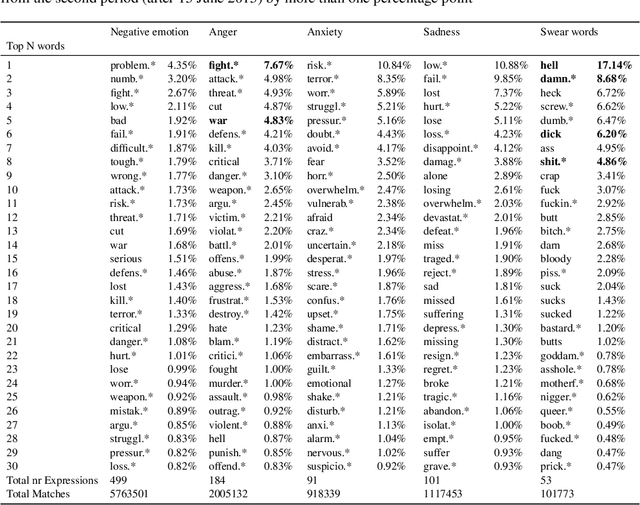
There is a widespread belief that the tone of US political language has become more negative recently, in particular when Donald Trump entered politics. At the same time, there is disagreement as to whether Trump changed or merely continued previous trends. To date, data-driven evidence regarding these questions is scarce, partly due to the difficulty of obtaining a comprehensive, longitudinal record of politicians' utterances. Here we apply psycholinguistic tools to a novel, comprehensive corpus of 24 million quotes from online news attributed to 18,627 US politicians in order to analyze how the tone of US politicians' language evolved between 2008 and 2020. We show that, whereas the frequency of negative emotion words had decreased continuously during Obama's tenure, it suddenly and lastingly increased with the 2016 primary campaigns, by 1.6 pre-campaign standard deviations, or 8% of the pre-campaign mean, in a pattern that emerges across parties. The effect size drops by 40% when omitting Trump's quotes, and by 50% when averaging over speakers rather than quotes, implying that prominent speakers, and Trump in particular, have disproportionately, though not exclusively, contributed to the rise in negative language. This work provides the first large-scale data-driven evidence of a drastic shift toward a more negative political tone following Trump's campaign start as a catalyst, with important implications for the debate about the state of US politics.
Gated Transformer Networks for Multivariate Time Series Classification
Mar 26, 2021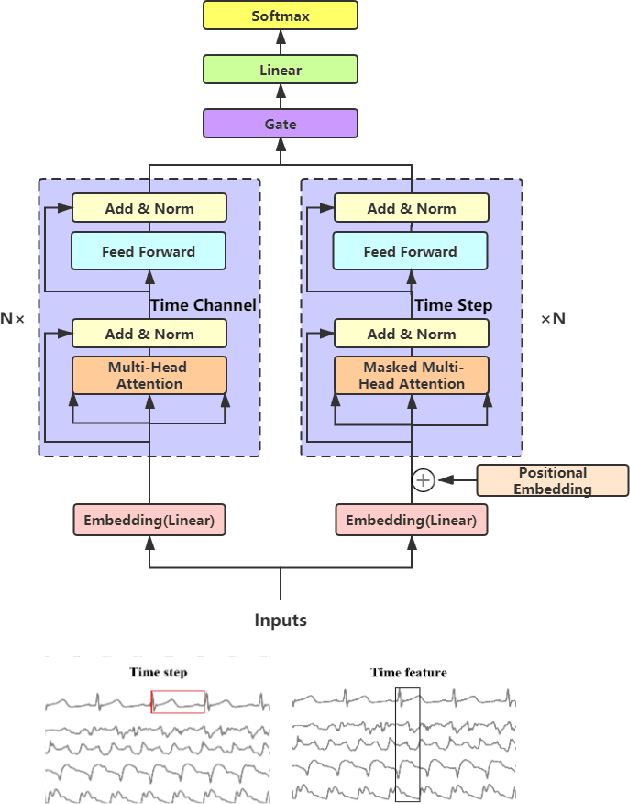
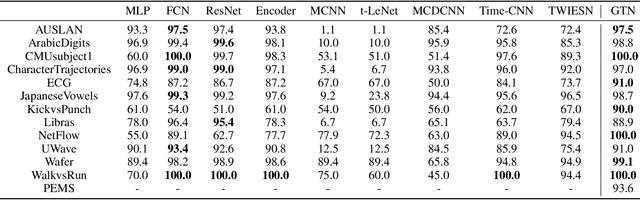
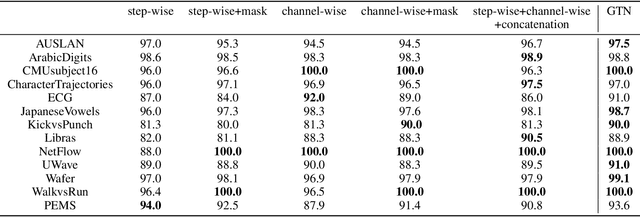
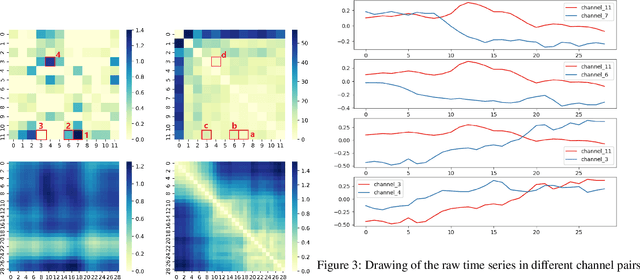
Deep learning model (primarily convolutional networks and LSTM) for time series classification has been studied broadly by the community with the wide applications in different domains like healthcare, finance, industrial engineering and IoT. Meanwhile, Transformer Networks recently achieved frontier performance on various natural language processing and computer vision tasks. In this work, we explored a simple extension of the current Transformer Networks with gating, named Gated Transformer Networks (GTN) for the multivariate time series classification problem. With the gating that merges two towers of Transformer which model the channel-wise and step-wise correlations respectively, we show how GTN is naturally and effectively suitable for the multivariate time series classification task. We conduct comprehensive experiments on thirteen dataset with full ablation study. Our results show that GTN is able to achieve competing results with current state-of-the-art deep learning models. We also explored the attention map for the natural interpretability of GTN on time series modeling. Our preliminary results provide a strong baseline for the Transformer Networks on multivariate time series classification task and grounds the foundation for future research.
Polynomial Time Reinforcement Learning in Correlated FMDPs with Linear Value Functions
Jul 12, 2021Many reinforcement learning (RL) environments in practice feature enormous state spaces that may be described compactly by a "factored" structure, that may be modeled by Factored Markov Decision Processes (FMDPs). We present the first polynomial-time algorithm for RL with FMDPs that does not rely on an oracle planner, and instead of requiring a linear transition model, only requires a linear value function with a suitable local basis with respect to the factorization. With this assumption, we can solve FMDPs in polynomial time by constructing an efficient separation oracle for convex optimization. Importantly, and in contrast to prior work, we do not assume that the transitions on various factors are independent.
AASeg: Attention Aware Network for Real Time Semantic Segmentation
Aug 11, 2021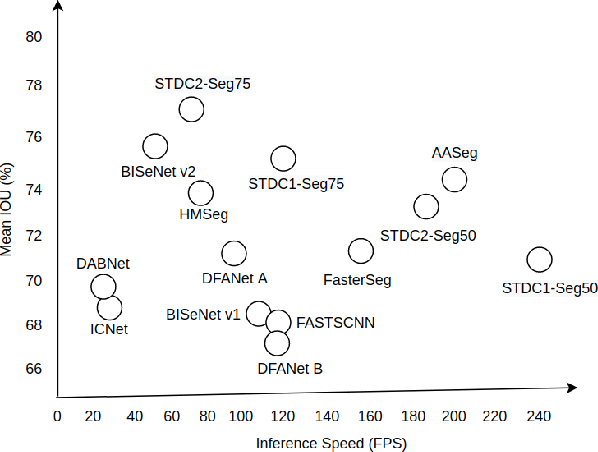
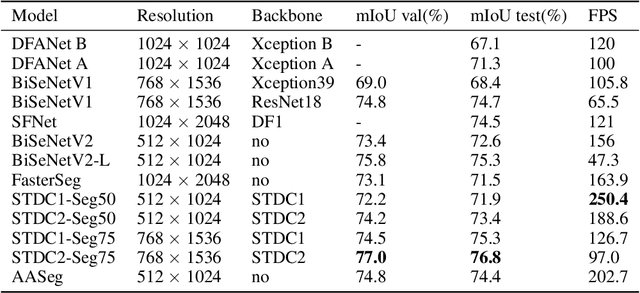
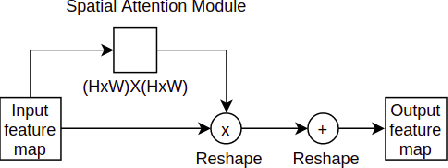
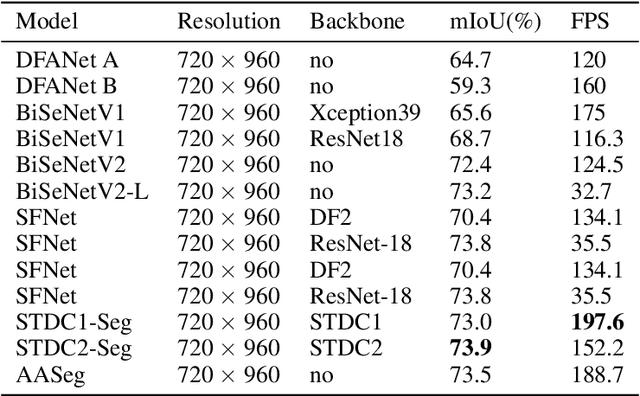
In this paper, we present a new network named Attention Aware Network (AASeg) for real time semantic image segmentation. Our network incorporates spatial and channel information using Spatial Attention (SA) and Channel Attention (CA) modules respectively. It also uses dense local multi-scale context information using Multi Scale Context (MSC) module. The feature maps are concatenated individually to produce the final segmentation map. We demonstrate the effectiveness of our method using a comprehensive analysis, quantitative experimental results and ablation study using Cityscapes, ADE20K and Camvid datasets. Our network performs better than most previous architectures with a 74.4\% Mean IOU on Cityscapes test dataset while running at 202.7 FPS.
Hybrid iLQR Model Predictive Control for Contact Implicit Stabilization on Legged Robots
Jul 11, 2022

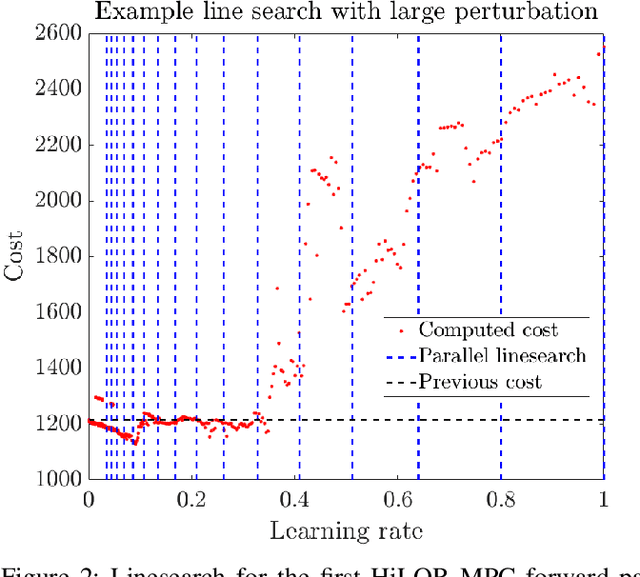
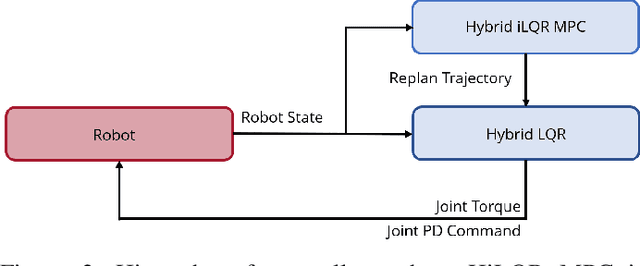
Model Predictive Control (MPC) is a popular strategy for controlling robots but is difficult for systems with contact due to the complex nature of hybrid dynamics. To implement MPC for systems with contact, dynamic models are often simplified or contact sequences fixed in time in order to plan trajectories efficiently. In this work, we extend Hybrid iterative Linear Quadratic Regulator to work in a MPC fashion (HiLQR MPC) by 1) modifying how the cost function is computed when contact modes do not align, 2) utilizing parallelizations when simulating rigid body dynamics, and 3) using efficient analytical derivative computations of the rigid body dynamics. The result is a system that can modify the contact sequence of the reference behavior and plan whole body motions cohesively -- which is crucial when dealing with large perturbations. HiLQR MPC is tested on two systems: first, the hybrid cost modification is validated on a simple actuated bouncing ball hybrid system. Then HiLQR MPC is compared against methods that utilize centroidal dynamic assumptions on a quadruped robot (Unitree A1). HiLQR MPC outperforms the centroidal methods in both simulation and hardware tests.
Two-Pass Low Latency End-to-End Spoken Language Understanding
Jul 14, 2022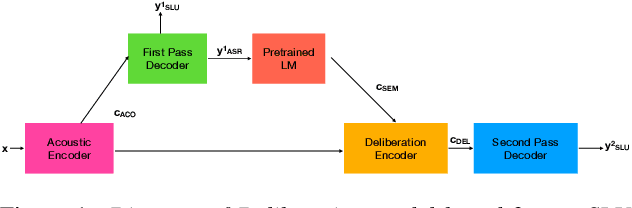
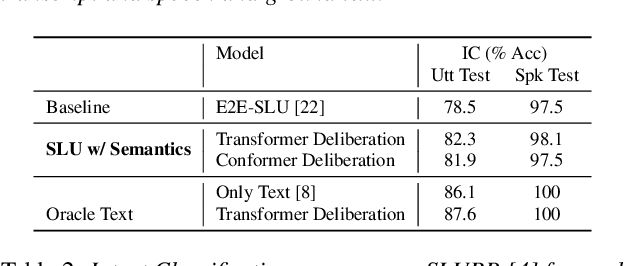

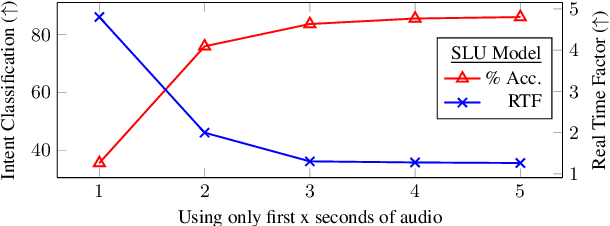
End-to-end (E2E) models are becoming increasingly popular for spoken language understanding (SLU) systems and are beginning to achieve competitive performance to pipeline-based approaches. However, recent work has shown that these models struggle to generalize to new phrasings for the same intent indicating that models cannot understand the semantic content of the given utterance. In this work, we incorporated language models pre-trained on unlabeled text data inside E2E-SLU frameworks to build strong semantic representations. Incorporating both semantic and acoustic information can increase the inference time, leading to high latency when deployed for applications like voice assistants. We developed a 2-pass SLU system that makes low latency prediction using acoustic information from the few seconds of the audio in the first pass and makes higher quality prediction in the second pass by combining semantic and acoustic representations. We take inspiration from prior work on 2-pass end-to-end speech recognition systems that attends on both audio and first-pass hypothesis using a deliberation network. The proposed 2-pass SLU system outperforms the acoustic-based SLU model on the Fluent Speech Commands Challenge Set and SLURP dataset and reduces latency, thus improving user experience. Our code and models are publicly available as part of the ESPnet-SLU toolkit.