 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Offline Vehicle Routing Problem with Online Bookings: A Novel Problem Formulation with Applications to Paratransit
May 05, 2022
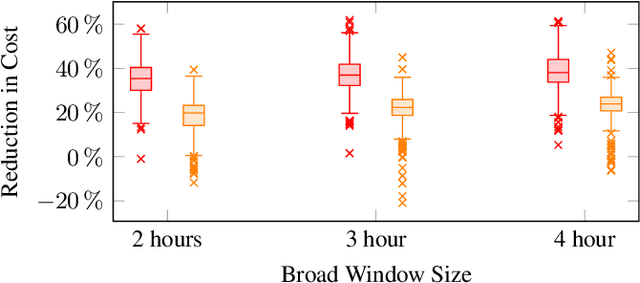
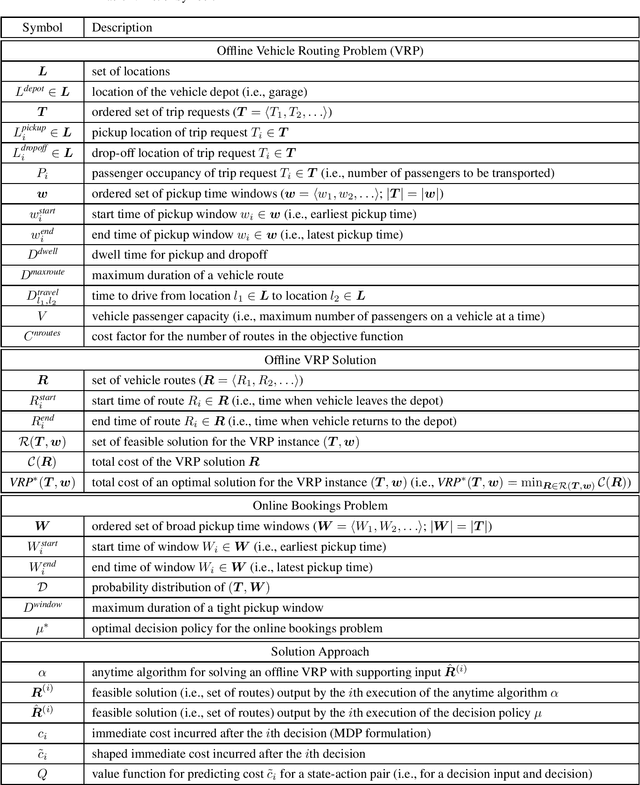
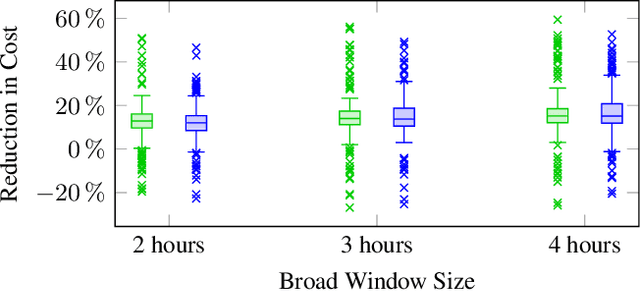
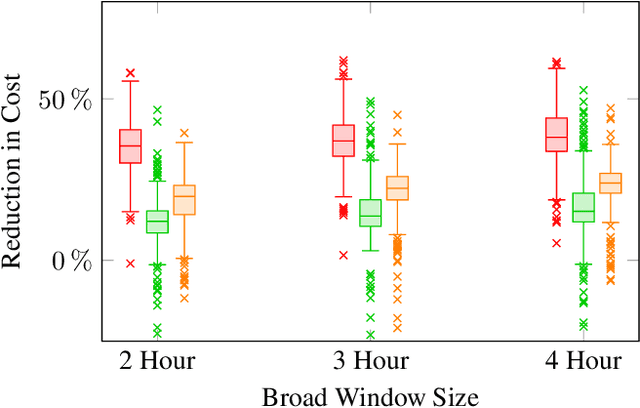
Vehicle routing problems (VRPs) can be divided into two major categories: offline VRPs, which consider a given set of trip requests to be served, and online VRPs, which consider requests as they arrive in real-time. Based on discussions with public transit agencies, we identify a real-world problem that is not addressed by existing formulations: booking trips with flexible pickup windows (e.g., 3 hours) in advance (e.g., the day before) and confirming tight pickup windows (e.g., 30 minutes) at the time of booking. Such a service model is often required in paratransit service settings, where passengers typically book trips for the next day over the phone. To address this gap between offline and online problems, we introduce a novel formulation, the offline vehicle routing problem with online bookings. This problem is very challenging computationally since it faces the complexity of considering large sets of requests -- similar to offline VRPs -- but must abide by strict constraints on running time -- similar to online VRPs. To solve this problem, we propose a novel computational approach, which combines an anytime algorithm with a learning-based policy for real-time decisions. Based on a paratransit dataset obtained from the public transit agency of Chattanooga, TN, we demonstrate that our novel formulation and computational approach lead to significantly better outcomes in this setting than existing algorithms.
Transcormer: Transformer for Sentence Scoring with Sliding Language Modeling
Jun 05, 2022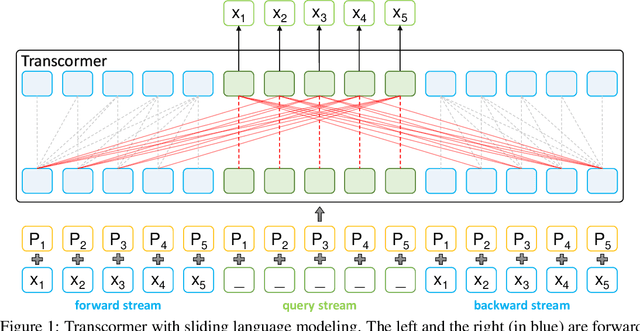

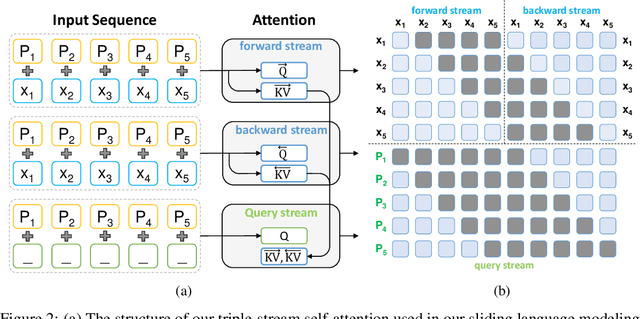
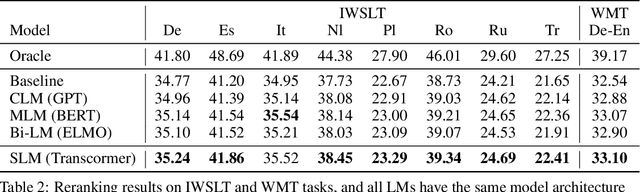
Sentence scoring aims at measuring the likelihood score of a sentence and is widely used in many natural language processing scenarios, like reranking, which is to select the best sentence from multiple candidates. Previous works on sentence scoring mainly adopted either causal language modeling (CLM) like GPT or masked language modeling (MLM) like BERT, which have some limitations: 1) CLM only utilizes unidirectional information for the probability estimation of a sentence without considering bidirectional context, which affects the scoring quality; 2) MLM can only estimate the probability of partial tokens at a time and thus requires multiple forward passes to estimate the probability of the whole sentence, which incurs large computation and time cost. In this paper, we propose \textit{Transcormer} -- a Transformer model with a novel \textit{sliding language modeling} (SLM) for sentence scoring. Specifically, our SLM adopts a triple-stream self-attention mechanism to estimate the probability of all tokens in a sentence with bidirectional context and only requires a single forward pass. SLM can avoid the limitations of CLM (only unidirectional context) and MLM (multiple forward passes) and inherit their advantages, and thus achieve high effectiveness and efficiency in scoring. Experimental results on multiple tasks demonstrate that our method achieves better performance than other language modelings.
It's a super deal -- train recurrent network on noisy data and get smooth prediction free
Jun 09, 2022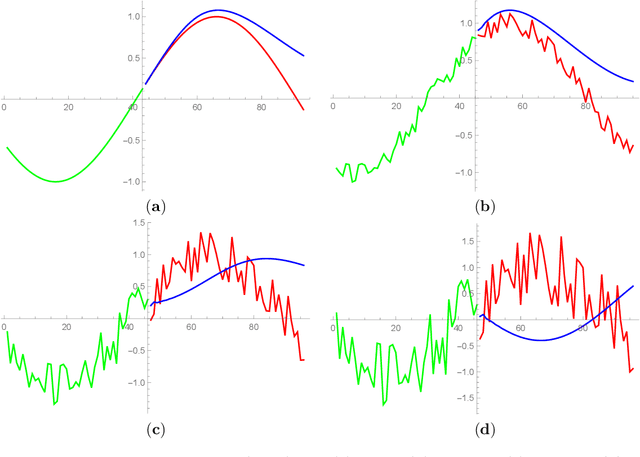
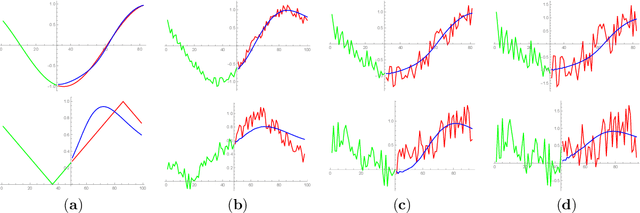
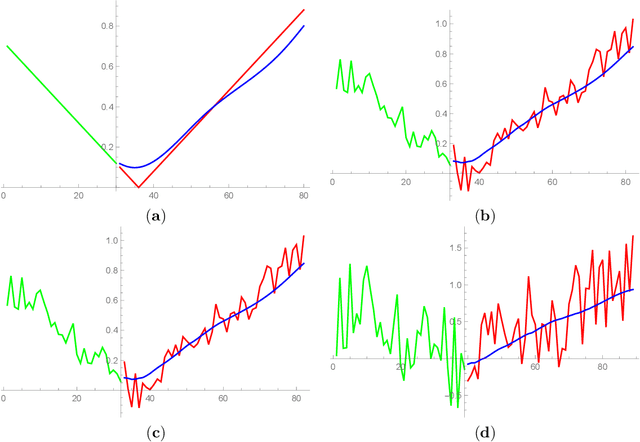
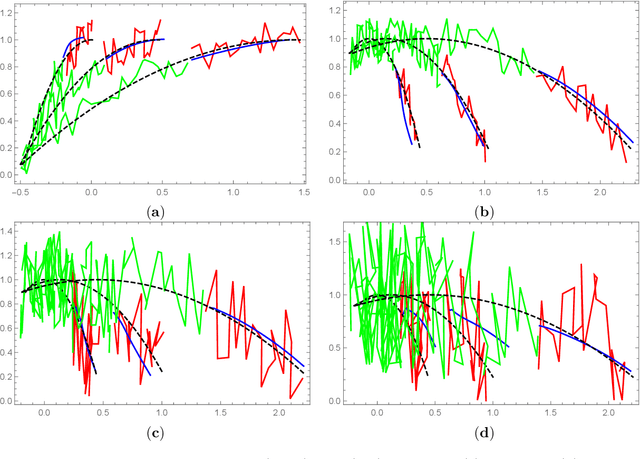
Recent research demonstrate that prediction of time series by predictive recurrent neural networks based on the noisy input generates a {\it smooth} anticipated trajectory. We examine influence of the noise component in both the training data sets and the input sequences on network prediction quality. We propose and discuss an explanation of the observed noise compression in the predictive process. We also discuss importance of this property of recurrent networks in the neuroscience context for the evolution of living organisms.
Event-Based Feature Tracking in Continuous Time with Sliding Window Optimization
Jul 09, 2021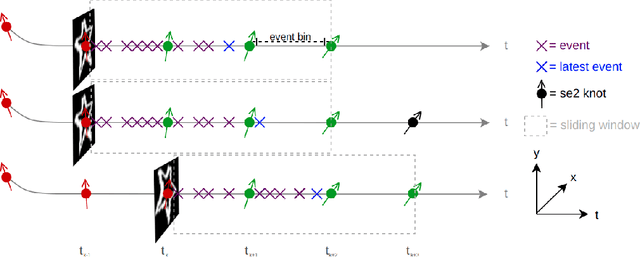
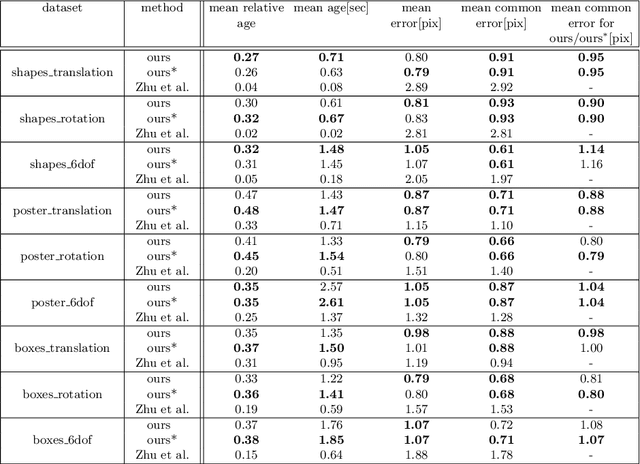
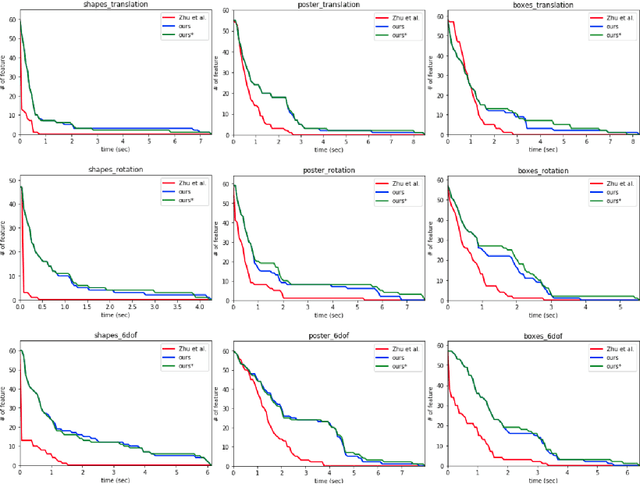

We propose a novel method for continuous-time feature tracking in event cameras. To this end, we track features by aligning events along an estimated trajectory in space-time such that the projection on the image plane results in maximally sharp event patch images. The trajectory is parameterized by $n^{th}$ order B-splines, which are continuous up to $(n-2)^{th}$ derivative. In contrast to previous work, we optimize the curve parameters in a sliding window fashion. On a public dataset we experimentally confirm that the proposed sliding-window B-spline optimization leads to longer and more accurate feature tracks than in previous work.
Proactive Distributed Constraint Optimization of Heterogeneous Incident Vehicle Teams
Jul 16, 2022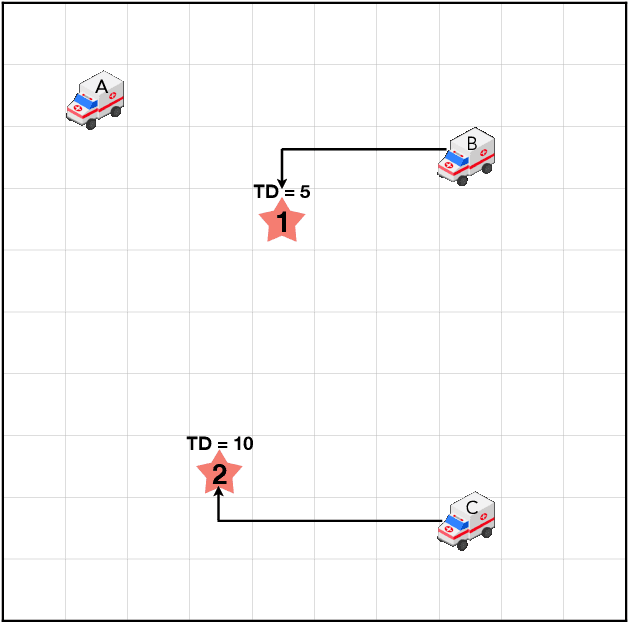

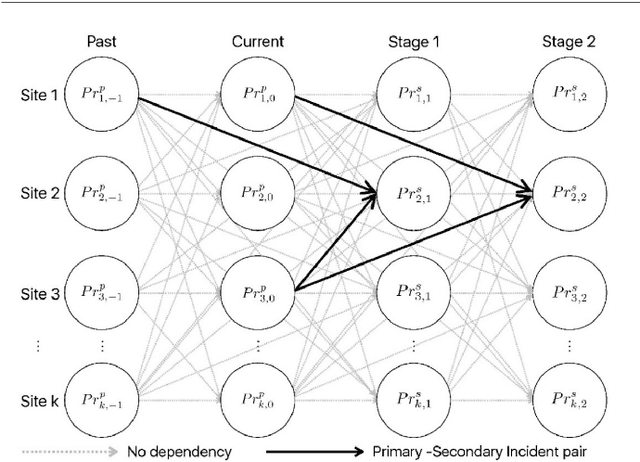
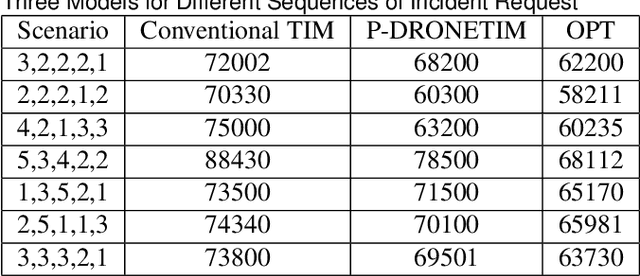
Traditionally, traffic incident management (TIM) programs coordinate the deployment of emergency resources to immediate incident requests without accommodating the interdependencies on incident evolutions in the environment. However, ignoring inherent interdependencies on the evolution of incidents in the environment while making current deployment decisions is shortsighted, and the resulting naive deployment strategy can significantly worsen the overall incident delay impact on the network. The interdependencies on incident evolution in the environment, including those between incident occurrences, and those between resource availability in near-future requests and the anticipated duration of the immediate incident request, should be considered through a look-ahead model when making current-stage deployment decisions. This study develops a new proactive framework based on the distributed constraint optimization problem (DCOP) to address the above limitations, overcoming conventional TIM models that cannot accommodate the dependencies in the TIM problem. Furthermore, the optimization objective is formulated to incorporate Unmanned Aerial Vehicles (UAVs). The UAVs' role in TIM includes exploring uncertain traffic conditions, detecting unexpected events, and augmenting information from roadway traffic sensors. Robustness analysis of our model for multiple TIM scenarios shows satisfactory performance using local search exploration heuristics. Overall, our model reports a significant reduction in total incident delay compared to conventional TIM models. With UAV support, we demonstrate a further decrease in the overall incident delay through the shorter response time of emergency vehicles, and a reduction in uncertainties associated with the estimated incident delay impact.
Vehicle Teleoperation: Successive Reference-Pose Tracking
Jun 08, 2022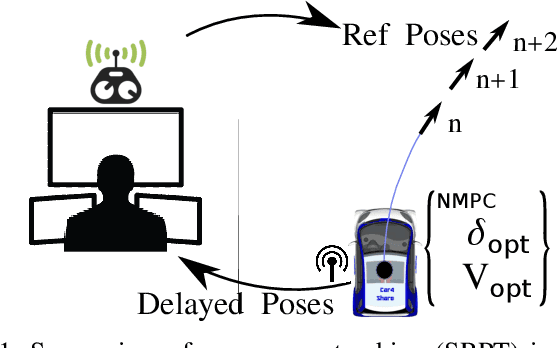
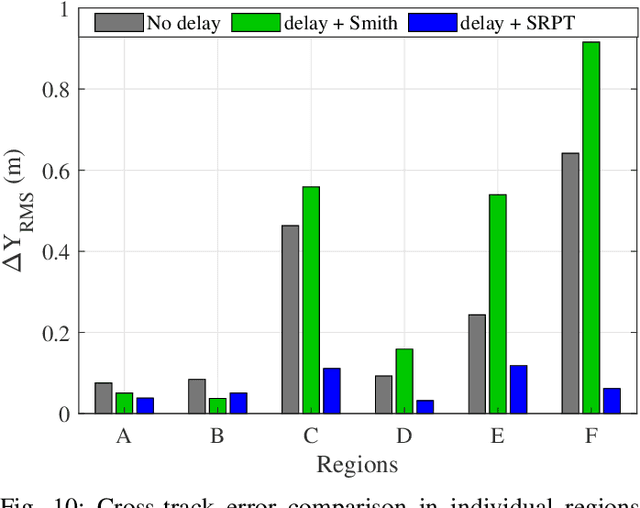
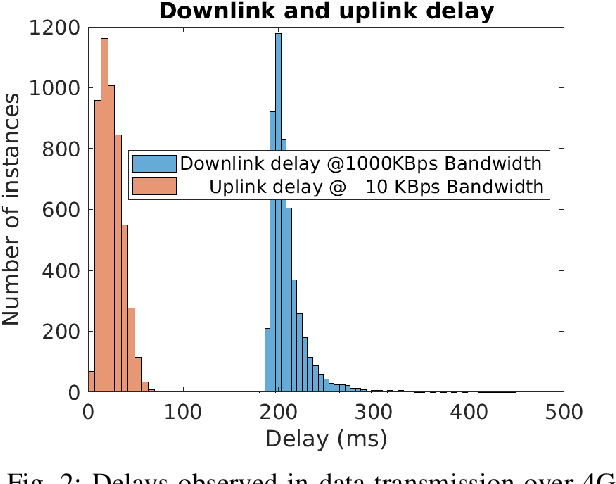
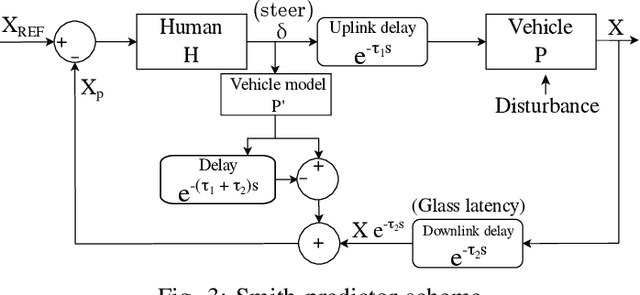
Vehicle teleoperation is an interesting feature in many fields. A typical problem of teleoperation is communication time delay which, together with actuator saturation and environmental disturbance, can cause a vehicle deviation from the target trajectory imposed by the human operator who imposes to the vehicle a steering wheel angle reference and a speed/acceleration reference. With predictive techniques, time-delay can be accounted at sufficient extent. But, in presence of disturbances, due to the absence of instantaneous haptic and visual feedback, human-operator steering command transmitted to the the vehicle is unaccounted with disturbances observed by the vehicle. To improve reference tracking without losing promptness in driving control, reference trajectory in the form of successive reference poses can be transmitted instead of steering commands to the vehicle. We introduce this new concept, namely, the 'successive reference-pose tracking (SRPT)' to improve path tracking in vehicle teleoperation. This paper discusses feasibility and advantages of this new method, compare to the smith predictor control approach. Simulations are performed in SIMULINK environment, where a 14-dof vehicle model is being controlled with Smith and SRPT controllers in presence of variable network delay. Scenarios for performance comparison are low adhesion ground, strong lateral wind and steer-rate demanding maneuvers. Simulation result shows significant improvement in reference tracking with SRPT approach.
Architectural Optimization and Feature Learning for High-Dimensional Time Series Datasets
Feb 27, 2022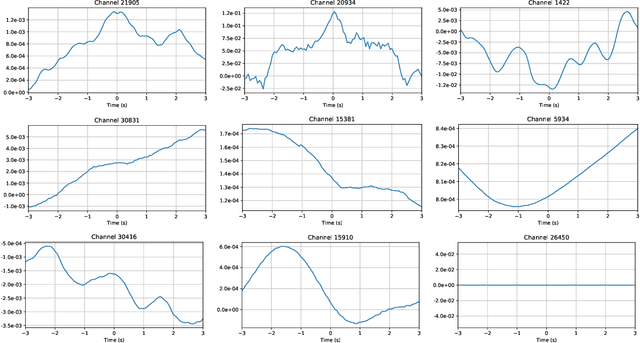
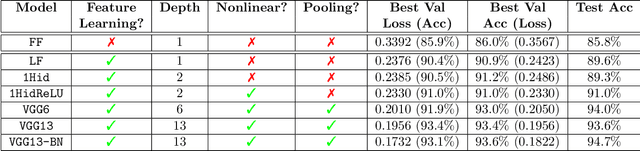
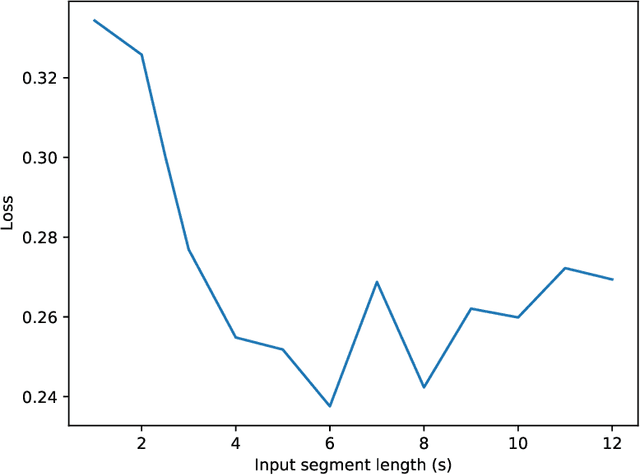

As our ability to sense increases, we are experiencing a transition from data-poor problems, in which the central issue is a lack of relevant data, to data-rich problems, in which the central issue is to identify a few relevant features in a sea of observations. Motivated by applications in gravitational-wave astrophysics, we study the problem of predicting the presence of transient noise artifacts in a gravitational wave detector from a rich collection of measurements from the detector and its environment. We argue that feature learning--in which relevant features are optimized from data--is critical to achieving high accuracy. We introduce models that reduce the error rate by over 60\% compared to the previous state of the art, which used fixed, hand-crafted features. Feature learning is useful not only because it improves performance on prediction tasks; the results provide valuable information about patterns associated with phenomena of interest that would otherwise be undiscoverable. In our application, features found to be associated with transient noise provide diagnostic information about its origin and suggest mitigation strategies. Learning in high-dimensional settings is challenging. Through experiments with a variety of architectures, we identify two key factors in successful models: sparsity, for selecting relevant variables within the high-dimensional observations; and depth, which confers flexibility for handling complex interactions and robustness with respect to temporal variations. We illustrate their significance through systematic experiments on real detector data. Our results provide experimental corroboration of common assumptions in the machine-learning community and have direct applicability to improving our ability to sense gravitational waves, as well as to many other problem settings with similarly high-dimensional, noisy, or partly irrelevant data.
Online TSP with Predictions
Jun 30, 2022We initiate the study of online routing problems with predictions, inspired by recent exciting results in the area of learning-augmented algorithms. A learning-augmented online algorithm which incorporates predictions in a black-box manner to outperform existing algorithms if the predictions are accurate while otherwise maintaining theoretical guarantees even when the predictions are extremely erroneous is a popular framework for overcoming pessimistic worst-case competitive analysis. In this study, we particularly begin investigating the classical online traveling salesman problem (OLTSP), where future requests are augmented with predictions. Unlike the prediction models in other previous studies, each actual request in the OLTSP, associated with its arrival time and position, may not coincide with the predicted ones, which, as imagined, leads to a troublesome situation. Our main result is to study different prediction models and design algorithms to improve the best-known results in the different settings. Moreover, we generalize the proposed results to the online dial-a-ride problem.
Multi-task Envisioning Transformer-based Autoencoder for Corporate Credit Rating Migration Early Prediction
Jul 10, 2022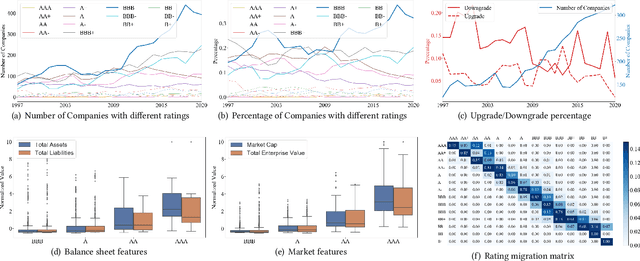

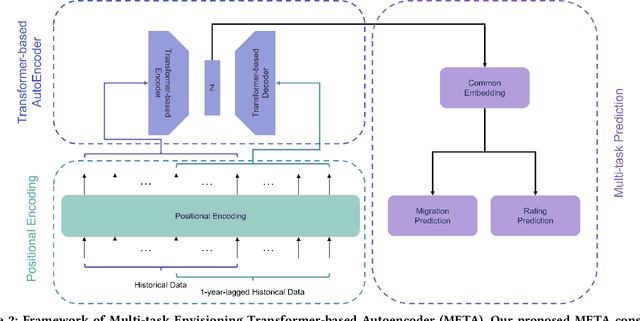
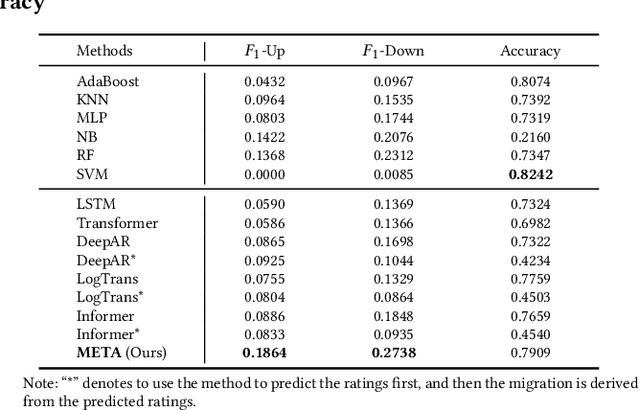
Corporate credit ratings issued by third-party rating agencies are quantified assessments of a company's creditworthiness. Credit Ratings highly correlate to the likelihood of a company defaulting on its debt obligations. These ratings play critical roles in investment decision-making as one of the key risk factors. They are also central to the regulatory framework such as BASEL II in calculating necessary capital for financial institutions. Being able to predict rating changes will greatly benefit both investors and regulators alike. In this paper, we consider the corporate credit rating migration early prediction problem, which predicts the credit rating of an issuer will be upgraded, unchanged, or downgraded after 12 months based on its latest financial reporting information at the time. We investigate the effectiveness of different standard machine learning algorithms and conclude these models deliver inferior performance. As part of our contribution, we propose a new Multi-task Envisioning Transformer-based Autoencoder (META) model to tackle this challenging problem. META consists of Positional Encoding, Transformer-based Autoencoder, and Multi-task Prediction to learn effective representations for both migration prediction and rating prediction. This enables META to better explore the historical data in the training stage for one-year later prediction. Experimental results show that META outperforms all baseline models.
Revisiting Competitive Coding Approach for Palmprint Recognition: A Linear Discriminant Analysis Perspective
Jun 30, 2022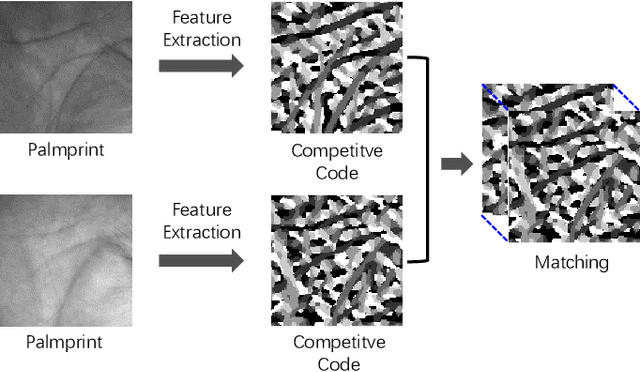

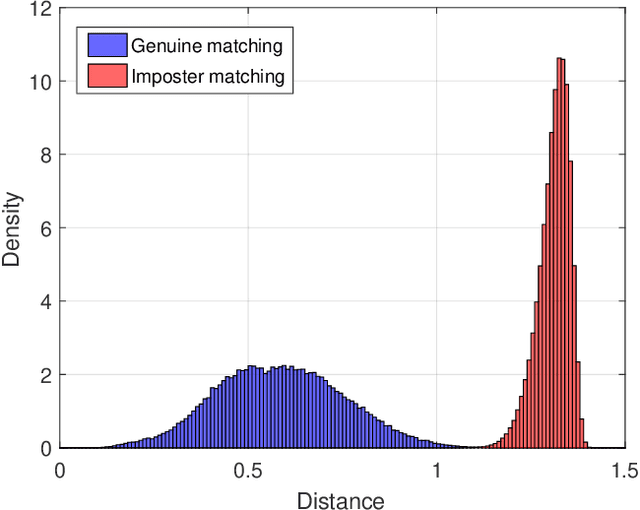
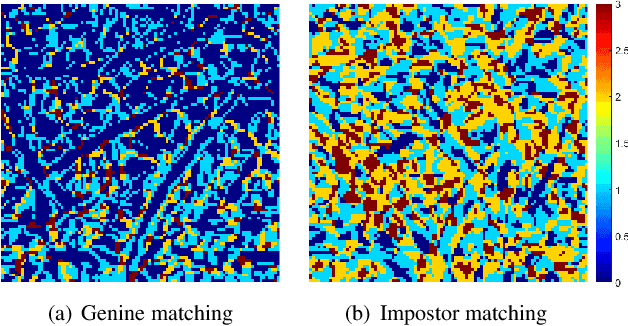
The competitive Coding approach (CompCode) is one of the most promising methods for palmprint recognition. Due to its high performance and simple formulation, it has been continuously studied for many years. However, although numerous variations of CompCode have been proposed, a detailed analysis of the method is still absent. In this paper, we provide a detailed analysis of CompCode from the perspective of linear discriminant analysis (LDA) for the first time. A non-trivial sufficient condition under which the CompCode is optimal in the sense of Fisher's criterion is presented. Based on our analysis, we examined the statistics of palmprints and concluded that CompCode deviates from the optimal condition. To mitigate the deviation, we propose a new method called Class-Specific CompCode that improves CompCode by excluding non-palm-line areas from matching. A nonlinear mapping of the competitive code is also applied in this method to further enhance accuracy. Experiments on two public databases demonstrate the effectiveness of the proposed method.