 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning Large-scale Universal User Representation with Sparse Mixture of Experts
Jul 11, 2022
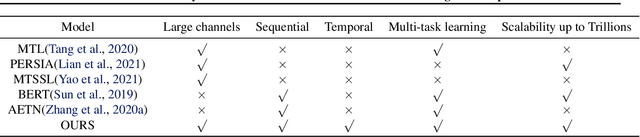
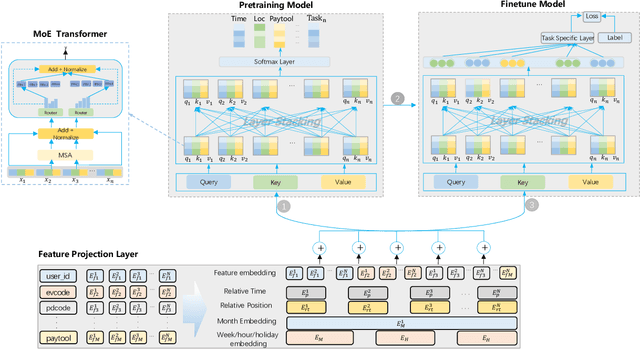
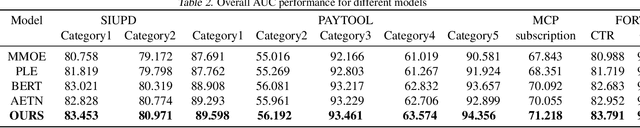
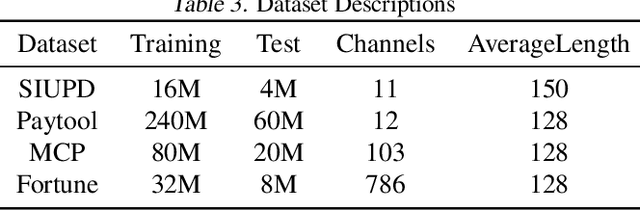
Learning user sequence behaviour embedding is very sophisticated and challenging due to the complicated feature interactions over time and high dimensions of user features. Recent emerging foundation models, e.g., BERT and its variants, encourage a large body of researchers to investigate in this field. However, unlike natural language processing (NLP) tasks, the parameters of user behaviour model come mostly from user embedding layer, which makes most existing works fail in training a universal user embedding of large scale. Furthermore, user representations are learned from multiple downstream tasks, and the past research work do not address the seesaw phenomenon. In this paper, we propose SUPERMOE, a generic framework to obtain high quality user representation from multiple tasks. Specifically, the user behaviour sequences are encoded by MoE transformer, and we can thus increase the model capacity to billions of parameters, or even to trillions of parameters. In order to deal with seesaw phenomenon when learning across multiple tasks, we design a new loss function with task indicators. We perform extensive offline experiments on public datasets and online experiments on private real-world business scenarios. Our approach achieves the best performance over state-of-the-art models, and the results demonstrate the effectiveness of our framework.
* Accepted by ICML 2022 Pre-training Workshop
A Hybrid Energy Harvesting Protocol for Cooperative NOMA: Error Performance Approach
Jul 01, 2022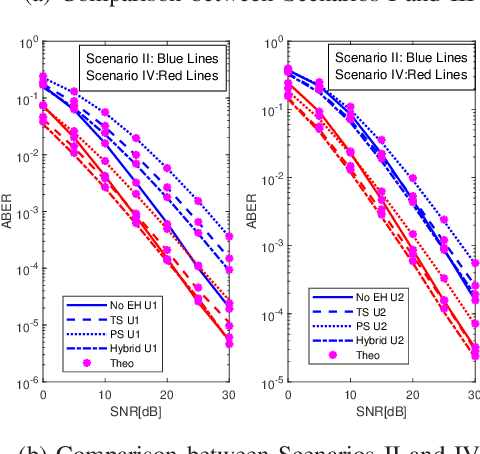
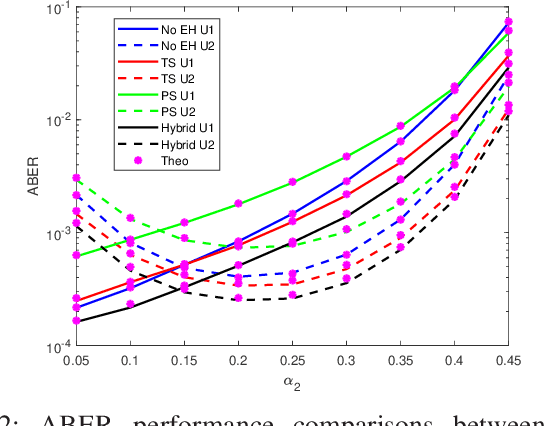
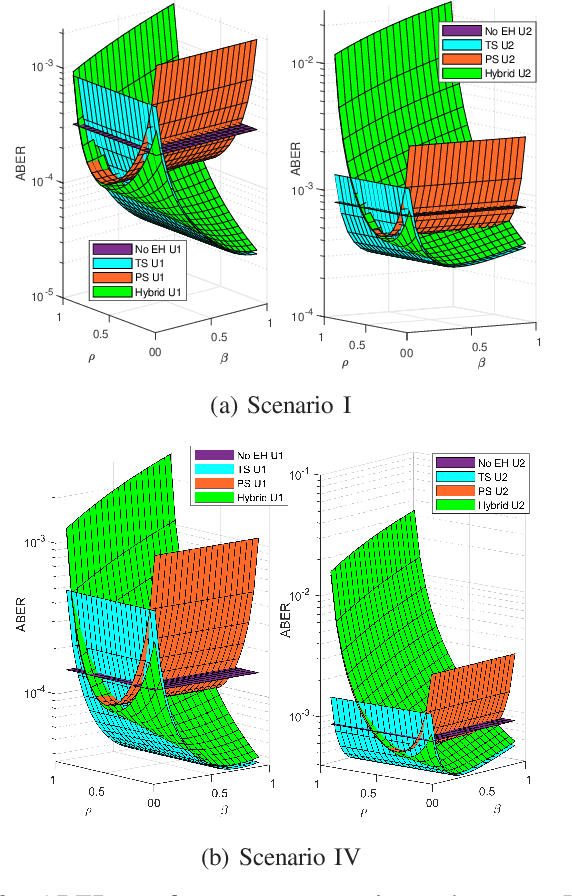
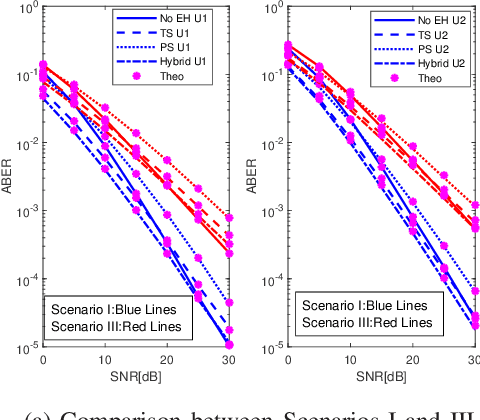
Cooperative non-orthogonal multiple access (CNOMA) has recently been adapted with energy harvesting (EH) to increase energy efficiency and extend the lifetime of energy-constrained wireless networks. This paper proposes a hybrid EH protocol-assisted CNOMA, which is a combination of the two main existing EH protocols (power splitting (PS) and time switching (TS)). The end-to-end bit error rate (BER) expressions of users in the proposed scheme are obtained over Nakagami-$m$ fading channels. The proposed hybrid EH (HEH) protocol is compared with the benchmark schemes (i.e., existing EH protocols and no EH). Based on the extensive simulations, we reveal that the analytical results match perfectly with simulations which proves the correctness of the derivations. Numerical results also show that the HEH-CNOMA outperforms the benchmarks significantly. In addition, we discuss the optimum value of EH factors to minimize the error probability in HEH-CNOMA and show that an optimum value can be obtained according to channel parameters.
TIMo -- A Dataset for Indoor Building Monitoring with a Time-of-Flight Camera
Aug 27, 2021
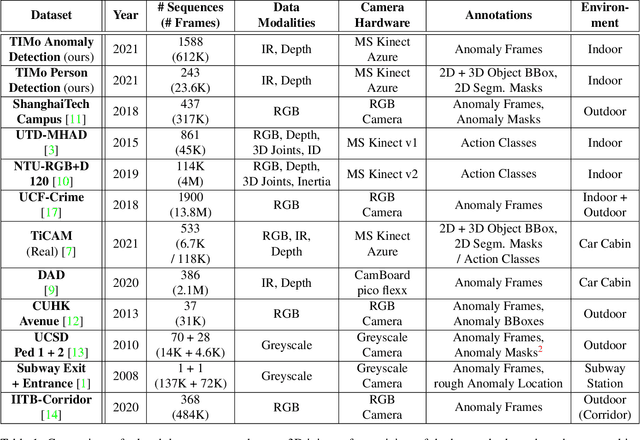

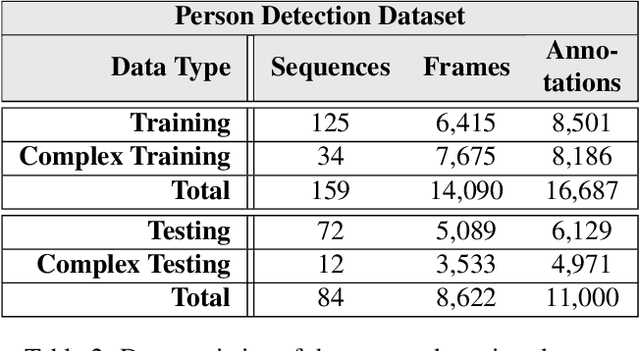
We present TIMo (Time-of-flight Indoor Monitoring), a dataset for video-based monitoring of indoor spaces captured using a time-of-flight (ToF) camera. The resulting depth videos feature people performing a set of different predefined actions, for which we provide detailed annotations. Person detection for people counting and anomaly detection are the two targeted applications. Most existing surveillance video datasets provide either grayscale or RGB videos. Depth information, on the other hand, is still a rarity in this class of datasets in spite of being popular and much more common in other research fields within computer vision. Our dataset addresses this gap in the landscape of surveillance video datasets. The recordings took place at two different locations with the ToF camera set up either in a top-down or a tilted perspective on the scene. The dataset is publicly available at https://vizta-tof.kl.dfki.de/timo-dataset-overview/.
Forecasting Foreign Exchange Rates With Parameter-Free Regression Networks Tuned By Bayesian Optimization
Apr 26, 2022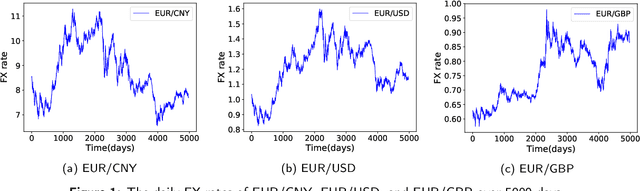

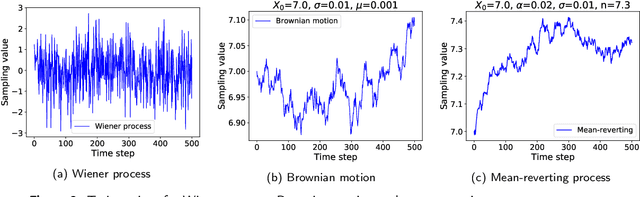

The article is concerned with the problem of multi-step financial time series forecasting of Foreign Exchange (FX) rates. To address this problem, we introduce a parameter-free regression network termed RegPred Net. The exchange rate to forecast is treated as a stochastic process. It is assumed to follow a generalization of Brownian motion and the mean-reverting process referred to as the generalized Ornstein-Uhlenbeck (OU) process, with time-dependent coefficients. Using past observed values of the input time series, these coefficients can be regressed online by the cells of the first half of the network (Reg). The regressed coefficients depend only on - but are very sensitive to - a small number of hyperparameters required to be set by a global optimization procedure for which, Bayesian optimization is an adequate heuristic. Thanks to its multi-layered architecture, the second half of the regression network (Pred) can project time-dependent values for the OU process coefficients and generate realistic trajectories of the time series. Predictions can be easily derived in the form of expected values estimated by averaging values obtained by Monte Carlo simulation. The forecasting accuracy on a 100 days horizon is evaluated for several of the most important FX rates such as EUR/USD, EUR/CNY, and EUR/GBP. Our experimental results show that the RegPred Net significantly outperforms ARMA, ARIMA, LSTMs, and Autoencoder-LSTM models in this task.
A multi-level interpretable sleep stage scoring system by infusing experts' knowledge into a deep network architecture
Jul 11, 2022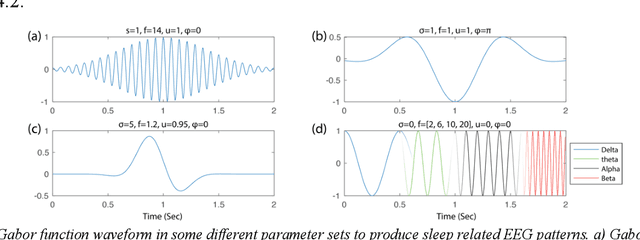
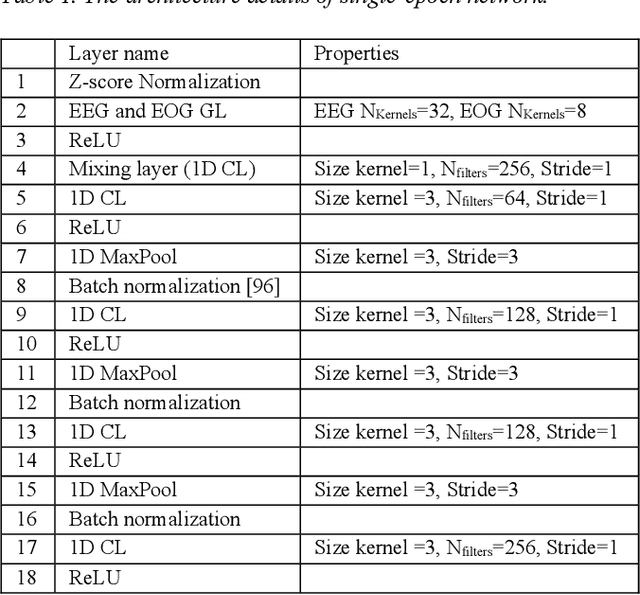
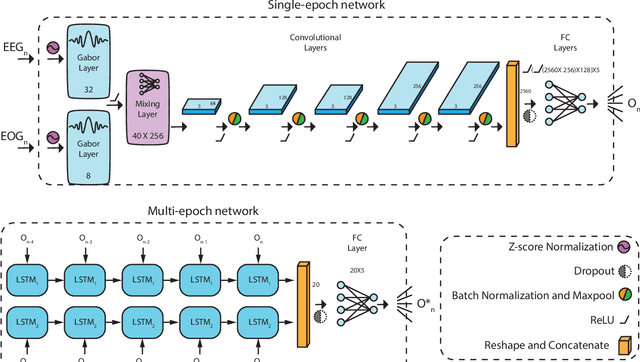
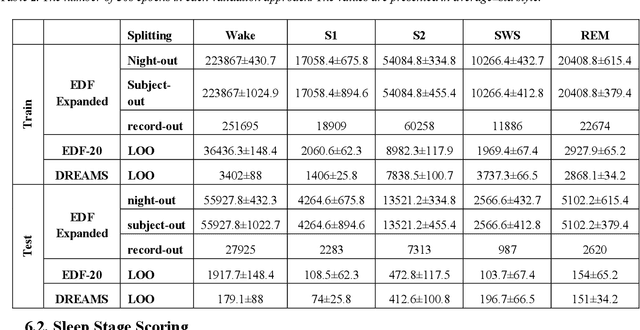
In recent years, deep learning has shown potential and efficiency in a wide area including computer vision, image and signal processing. Yet, translational challenges remain for user applications due to a lack of interpretability of algorithmic decisions and results. This black box problem is particularly problematic for high-risk applications such as medical-related decision-making. The current study goal was to design an interpretable deep learning system for time series classification of electroencephalogram (EEG) for sleep stage scoring as a step toward designing a transparent system. We have developed an interpretable deep neural network that includes a kernel-based layer based on a set of principles used for sleep scoring by human experts in the visual analysis of polysomnographic records. A kernel-based convolutional layer was defined and used as the first layer of the system and made available for user interpretation. The trained system and its results were interpreted in four levels from the microstructure of EEG signals, such as trained kernels and the effect of each kernel on the detected stages, to macrostructures, such as the transition between stages. The proposed system demonstrated greater performance than prior studies and the results of interpretation showed that the system learned information which was consistent with expert knowledge.
Hessian-Free Second-Order Adversarial Examples for Adversarial Learning
Jul 04, 2022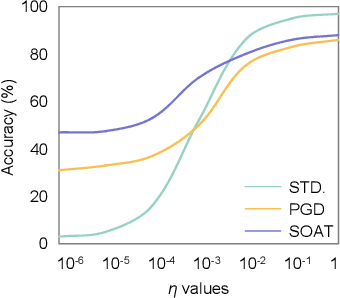
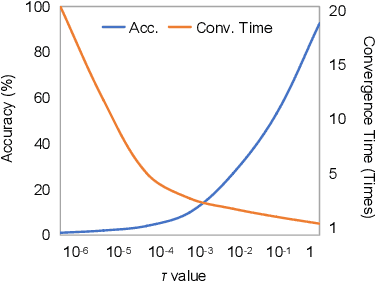
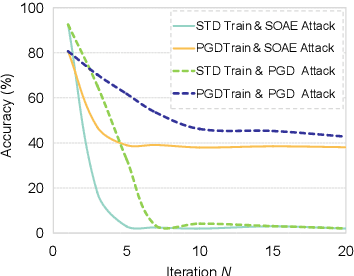
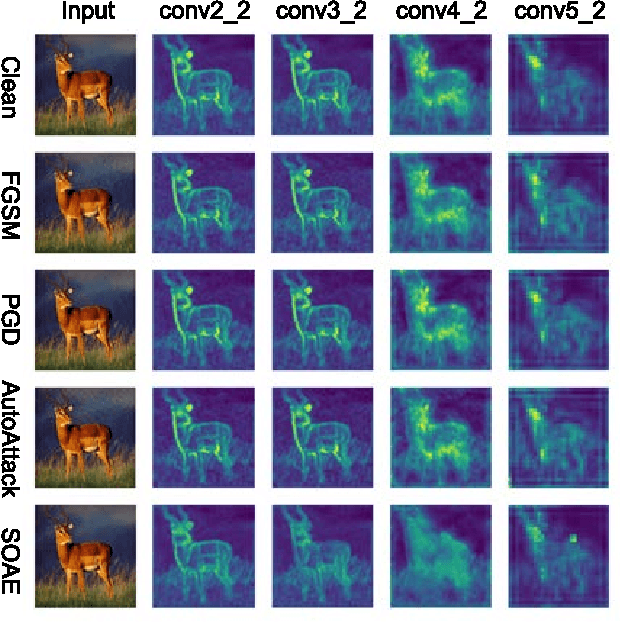
Recent studies show deep neural networks (DNNs) are extremely vulnerable to the elaborately designed adversarial examples. Adversarial learning with those adversarial examples has been proved as one of the most effective methods to defend against such an attack. At present, most existing adversarial examples generation methods are based on first-order gradients, which can hardly further improve models' robustness, especially when facing second-order adversarial attacks. Compared with first-order gradients, second-order gradients provide a more accurate approximation of the loss landscape with respect to natural examples. Inspired by this, our work crafts second-order adversarial examples and uses them to train DNNs. Nevertheless, second-order optimization involves time-consuming calculation for Hessian-inverse. We propose an approximation method through transforming the problem into an optimization in the Krylov subspace, which remarkably reduce the computational complexity to speed up the training procedure. Extensive experiments conducted on the MINIST and CIFAR-10 datasets show that our adversarial learning with second-order adversarial examples outperforms other fisrt-order methods, which can improve the model robustness against a wide range of attacks.
Measuring Forgetting of Memorized Training Examples
Jun 30, 2022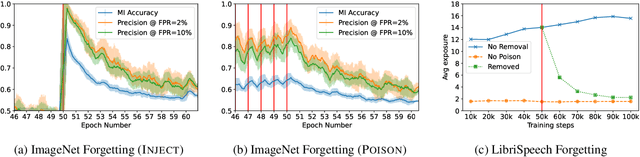
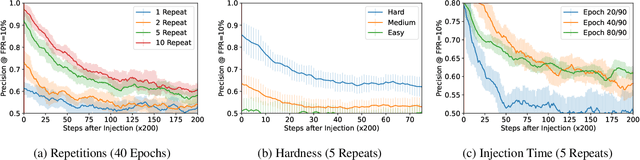
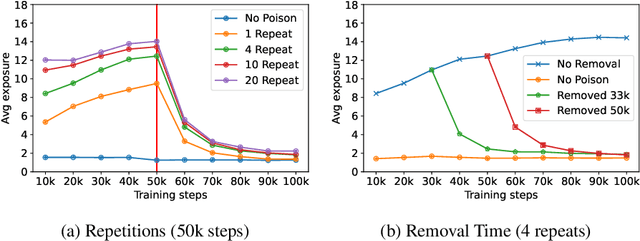
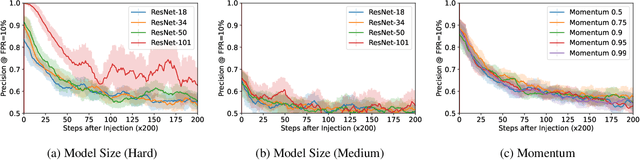
Machine learning models exhibit two seemingly contradictory phenomena: training data memorization and various forms of forgetting. In memorization, models overfit specific training examples and become susceptible to privacy attacks. In forgetting, examples which appeared early in training are forgotten by the end. In this work, we connect these phenomena. We propose a technique to measure to what extent models ``forget'' the specifics of training examples, becoming less susceptible to privacy attacks on examples they have not seen recently. We show that, while non-convexity can prevent forgetting from happening in the worst-case, standard image and speech models empirically do forget examples over time. We identify nondeterminism as a potential explanation, showing that deterministically trained models do not forget. Our results suggest that examples seen early when training with extremely large datasets -- for instance those examples used to pre-train a model -- may observe privacy benefits at the expense of examples seen later.
Formalizing the Problem of Side Effect Regularization
Jun 24, 2022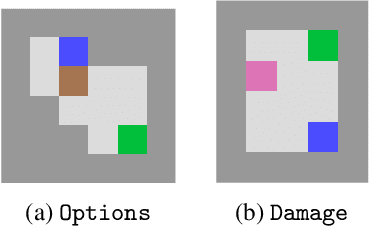
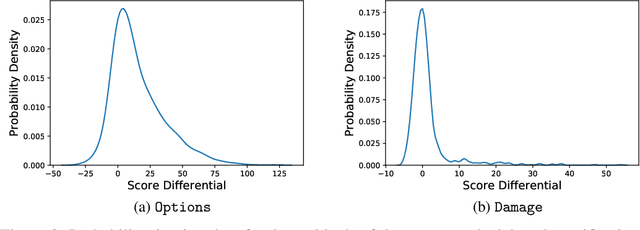
AI objectives are often hard to specify properly. Some approaches tackle this problem by regularizing the AI's side effects: Agents must weigh off "how much of a mess they make" with an imperfectly specified proxy objective. We propose a formal criterion for side effect regularization via the assistance game framework. In these games, the agent solves a partially observable Markov decision process (POMDP) representing its uncertainty about the objective function it should optimize. We consider the setting where the true objective is revealed to the agent at a later time step. We show that this POMDP is solved by trading off the proxy reward with the agent's ability to achieve a range of future tasks. We empirically demonstrate the reasonableness of our problem formalization via ground-truth evaluation in two gridworld environments.
Proactive Distributed Constraint Optimization of Heterogeneous Incident Vehicle Teams
Jul 16, 2022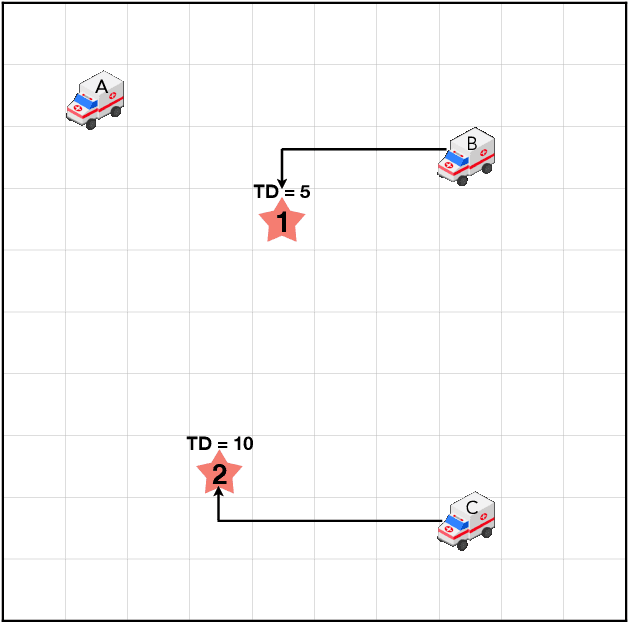

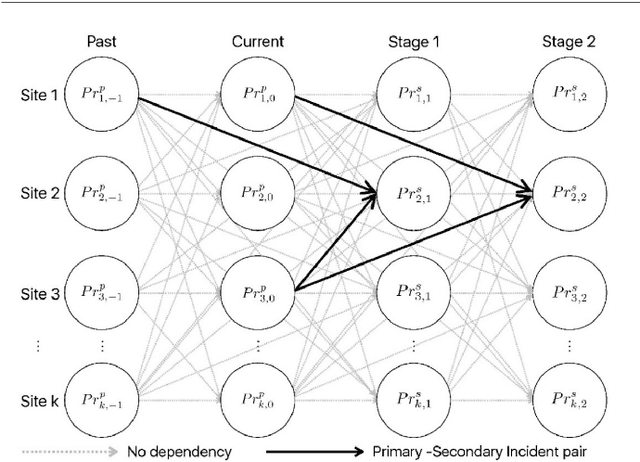
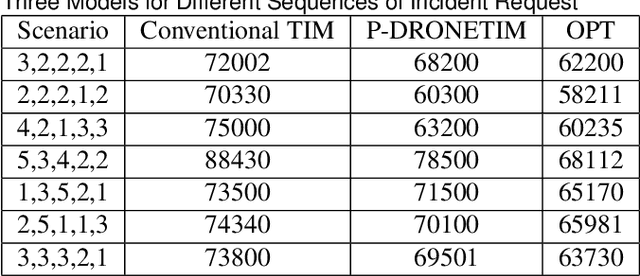
Traditionally, traffic incident management (TIM) programs coordinate the deployment of emergency resources to immediate incident requests without accommodating the interdependencies on incident evolutions in the environment. However, ignoring inherent interdependencies on the evolution of incidents in the environment while making current deployment decisions is shortsighted, and the resulting naive deployment strategy can significantly worsen the overall incident delay impact on the network. The interdependencies on incident evolution in the environment, including those between incident occurrences, and those between resource availability in near-future requests and the anticipated duration of the immediate incident request, should be considered through a look-ahead model when making current-stage deployment decisions. This study develops a new proactive framework based on the distributed constraint optimization problem (DCOP) to address the above limitations, overcoming conventional TIM models that cannot accommodate the dependencies in the TIM problem. Furthermore, the optimization objective is formulated to incorporate Unmanned Aerial Vehicles (UAVs). The UAVs' role in TIM includes exploring uncertain traffic conditions, detecting unexpected events, and augmenting information from roadway traffic sensors. Robustness analysis of our model for multiple TIM scenarios shows satisfactory performance using local search exploration heuristics. Overall, our model reports a significant reduction in total incident delay compared to conventional TIM models. With UAV support, we demonstrate a further decrease in the overall incident delay through the shorter response time of emergency vehicles, and a reduction in uncertainties associated with the estimated incident delay impact.
Stationary Multi-source AI-powered Real-time Tomography (SMART) for Dynamic Cardiac Imaging
Aug 27, 2021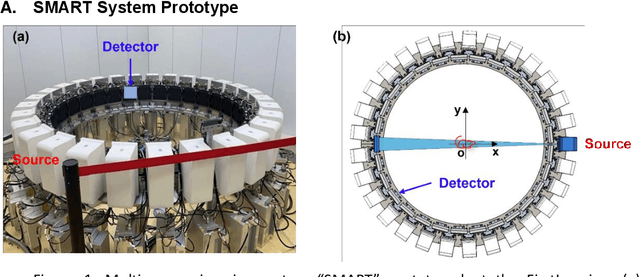
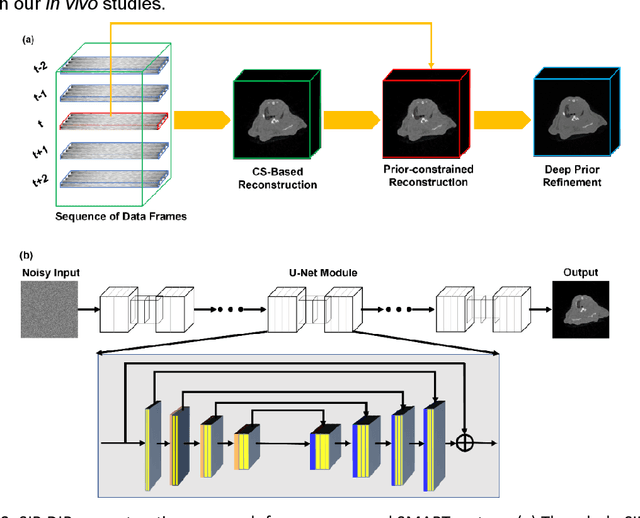
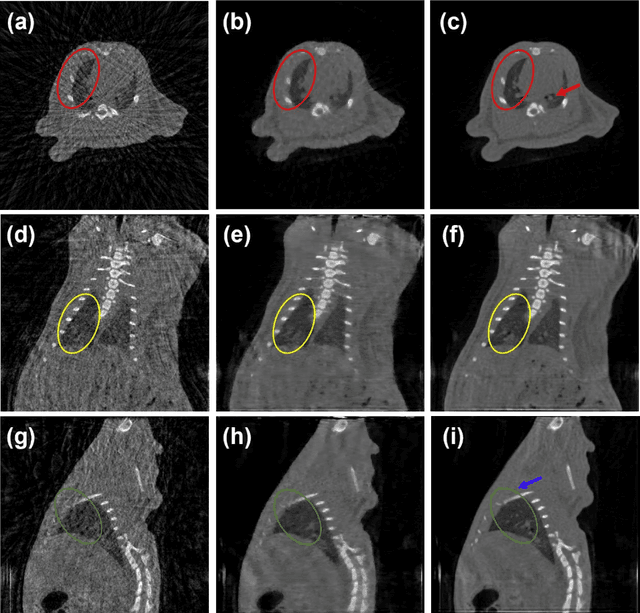

A first stationary multi-source computed tomography (CT) system is prototyped for preclinical imaging to achieve real-time temporal resolution for dynamic cardiac imaging. This unique is featured by 29 source-detector pairs fixed on a circular track for each detector to collect x-ray signals only from the opposite x-ray source. The new system architecture potentially leads to a major improvement in temporal resolution. To demonstrate the feasibility of this Stationary Multi-source AI-based Real-time Tomography (SMART) system, we develop a novel reconstruction scheme integrating both sparsified image prior (SIP) and deep image prior (DIP), which is referred to as the SIP-DIP network. Then, the SIP-DIP network for cardiac imaging is evaluated on preclinical cardiac datasets of alive rats. The reconstructed image volumes demonstrate the feasibility of the SMART system and the SIP-DIP network and the merits over other reconstruction methods.