 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
MegazordNet: combining statistical and machine learning standpoints for time series forecasting
Jun 23, 2021
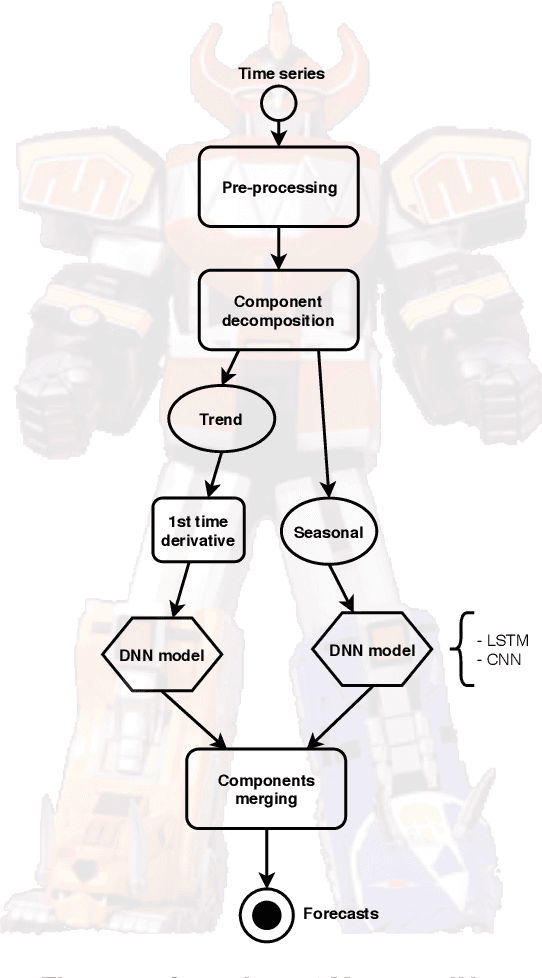

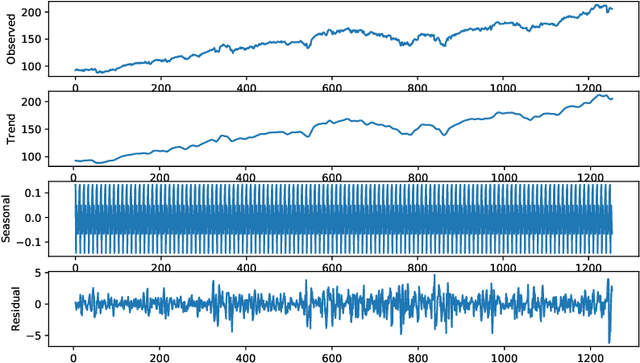

Forecasting financial time series is considered to be a difficult task due to the chaotic feature of the series. Statistical approaches have shown solid results in some specific problems such as predicting market direction and single-price of stocks; however, with the recent advances in deep learning and big data techniques, new promising options have arises to tackle financial time series forecasting. Moreover, recent literature has shown that employing a combination of statistics and machine learning may improve accuracy in the forecasts in comparison to single solutions. Taking into consideration the mentioned aspects, in this work, we proposed the MegazordNet, a framework that explores statistical features within a financial series combined with a structured deep learning model for time series forecasting. We evaluated our approach predicting the closing price of stocks in the S&P 500 using different metrics, and we were able to beat single statistical and machine learning methods.
Segmenting Moving Objects via an Object-Centric Layered Representation
Jul 05, 2022
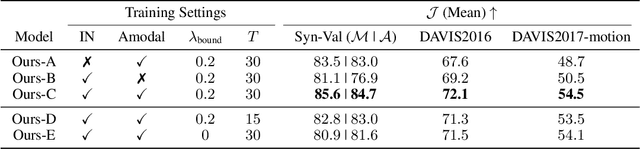
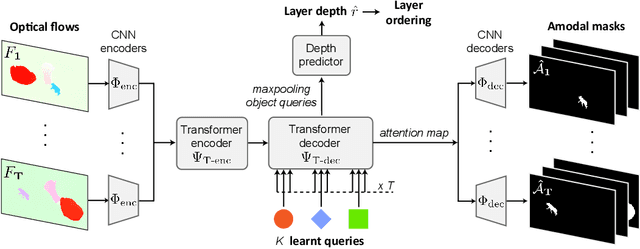
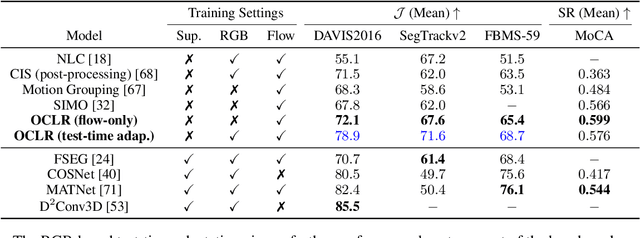
The objective of this paper is a model that is able to discover, track and segment multiple moving objects in a video. We make four contributions: First, we introduce an object-centric segmentation model with a depth-ordered layer representation. This is implemented using a variant of the transformer architecture that ingests optical flow, where each query vector specifies an object and its layer for the entire video. The model can effectively discover multiple moving objects and handle mutual occlusions; Second, we introduce a scalable pipeline for generating synthetic training data with multiple objects, significantly reducing the requirements for labour-intensive annotations, and supporting Sim2Real generalisation; Third, we show that the model is able to learn object permanence and temporal shape consistency, and is able to predict amodal segmentation masks; Fourth, we evaluate the model on standard video segmentation benchmarks, DAVIS, MoCA, SegTrack, FBMS-59, and achieve state-of-the-art unsupervised segmentation performance, even outperforming several supervised approaches. With test-time adaptation, we observe further performance boosts.
PSTNet: Point Spatio-Temporal Convolution on Point Cloud Sequences
May 27, 2022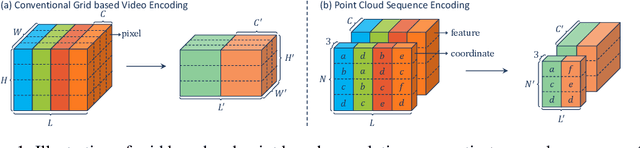
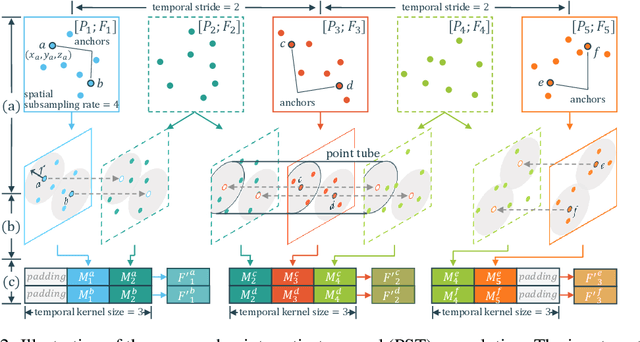
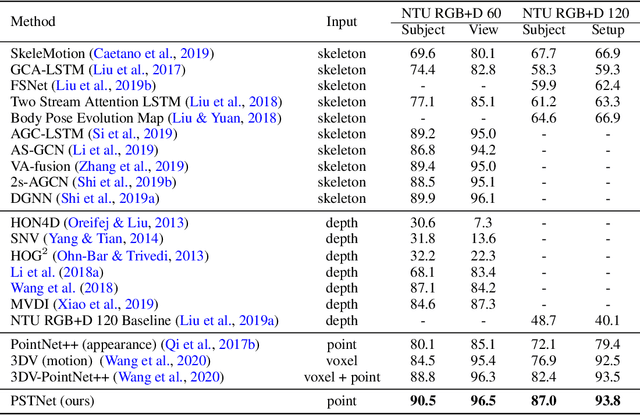
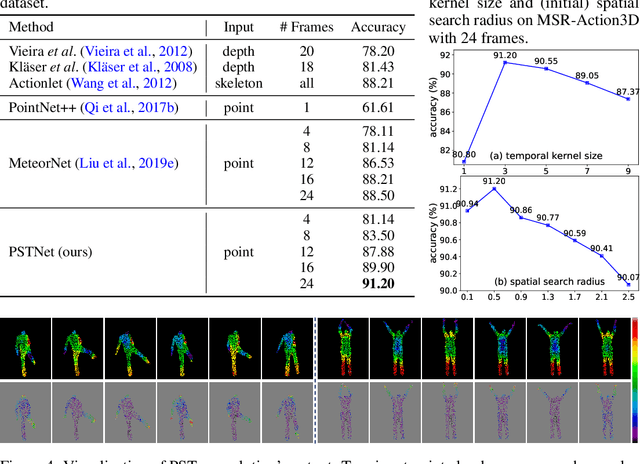
Point cloud sequences are irregular and unordered in the spatial dimension while exhibiting regularities and order in the temporal dimension. Therefore, existing grid based convolutions for conventional video processing cannot be directly applied to spatio-temporal modeling of raw point cloud sequences. In this paper, we propose a point spatio-temporal (PST) convolution to achieve informative representations of point cloud sequences. The proposed PST convolution first disentangles space and time in point cloud sequences. Then, a spatial convolution is employed to capture the local structure of points in the 3D space, and a temporal convolution is used to model the dynamics of the spatial regions along the time dimension. Furthermore, we incorporate the proposed PST convolution into a deep network, namely PSTNet, to extract features of point cloud sequences in a hierarchical manner. Extensive experiments on widely-used 3D action recognition and 4D semantic segmentation datasets demonstrate the effectiveness of PSTNet to model point cloud sequences.
Drivable Volumetric Avatars using Texel-Aligned Features
Jul 20, 2022
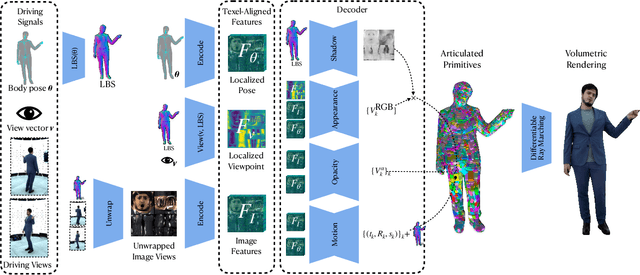
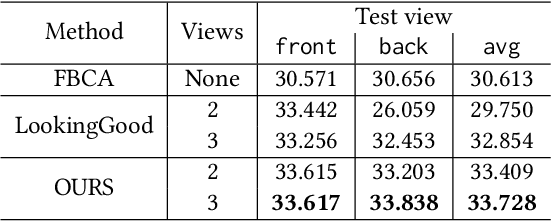
Photorealistic telepresence requires both high-fidelity body modeling and faithful driving to enable dynamically synthesized appearance that is indistinguishable from reality. In this work, we propose an end-to-end framework that addresses two core challenges in modeling and driving full-body avatars of real people. One challenge is driving an avatar while staying faithful to details and dynamics that cannot be captured by a global low-dimensional parameterization such as body pose. Our approach supports driving of clothed avatars with wrinkles and motion that a real driving performer exhibits beyond the training corpus. Unlike existing global state representations or non-parametric screen-space approaches, we introduce texel-aligned features -- a localised representation which can leverage both the structural prior of a skeleton-based parametric model and observed sparse image signals at the same time. Another challenge is modeling a temporally coherent clothed avatar, which typically requires precise surface tracking. To circumvent this, we propose a novel volumetric avatar representation by extending mixtures of volumetric primitives to articulated objects. By explicitly incorporating articulation, our approach naturally generalizes to unseen poses. We also introduce a localized viewpoint conditioning, which leads to a large improvement in generalization of view-dependent appearance. The proposed volumetric representation does not require high-quality mesh tracking as a prerequisite and brings significant quality improvements compared to mesh-based counterparts. In our experiments, we carefully examine our design choices and demonstrate the efficacy of our approach, outperforming the state-of-the-art methods on challenging driving scenarios.
Robotic Detection of a Human-Comprehensible Gestural Language for Underwater Multi-Human-Robot Collaboration
Jul 12, 2022
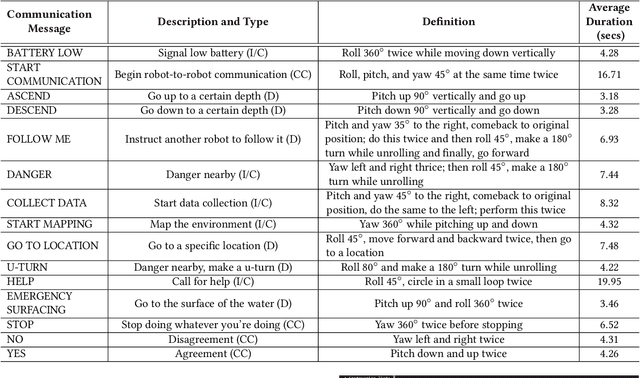

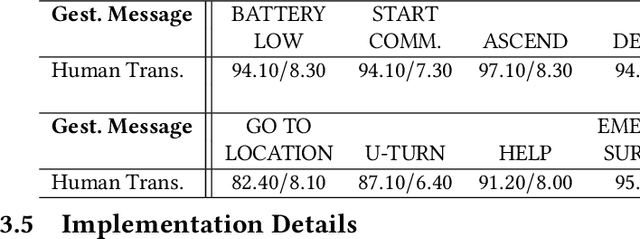
In this paper, we present a motion-based robotic communication framework that enables non-verbal communication among autonomous underwater vehicles (AUVs) and human divers. We design a gestural language for AUV-to-AUV communication which can be easily understood by divers observing the conversation unlike typical radio frequency, light, or audio based AUV communication. To allow AUVs to visually understand a gesture from another AUV, we propose a deep network (RRCommNet) which exploits a self-attention mechanism to learn to recognize each message by extracting maximally discriminative spatio-temporal features. We train this network on diverse simulated and real-world data. Our experimental evaluations, both in simulation and in closed-water robot trials, demonstrate that the proposed RRCommNet architecture is able to decipher gesture-based messages with an average accuracy of 88-94% on simulated data, 73-83% on real data (depending on the version of the model used). Further, by performing a message transcription study with human participants, we also show that the proposed language can be understood by humans, with an overall transcription accuracy of 88%. Finally, we discuss the inference runtime of RRCommNet on embedded GPU hardware, for real-time use on board AUVs in the field.
Simulation and Measurement of Human Respiration and Heartbeat with Millimeter- Wave Radar
Jul 22, 2022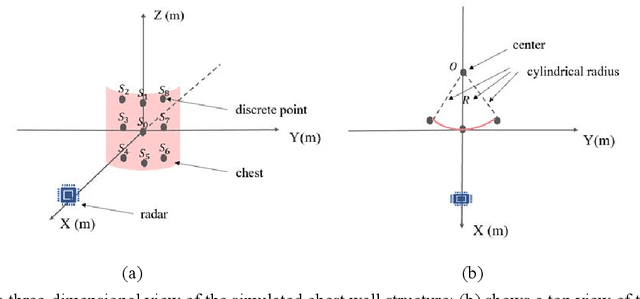
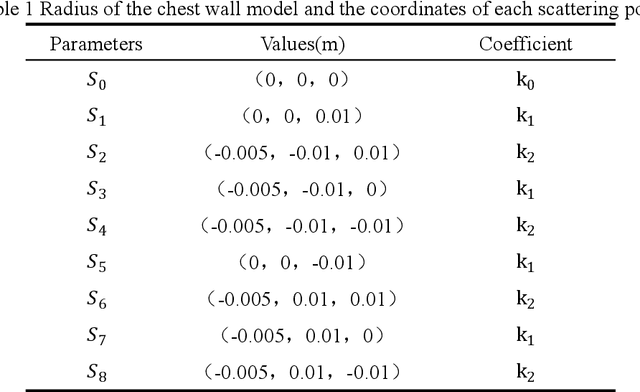
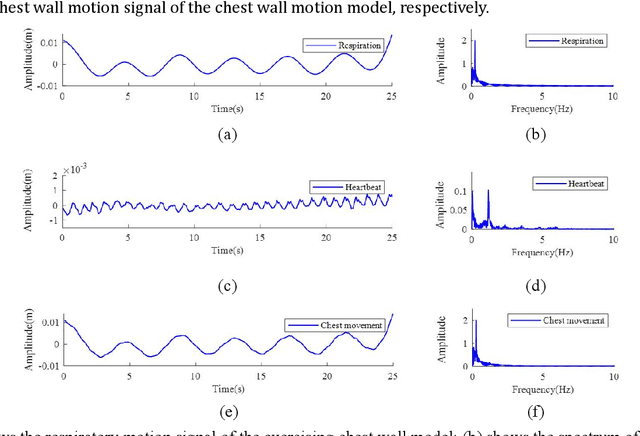
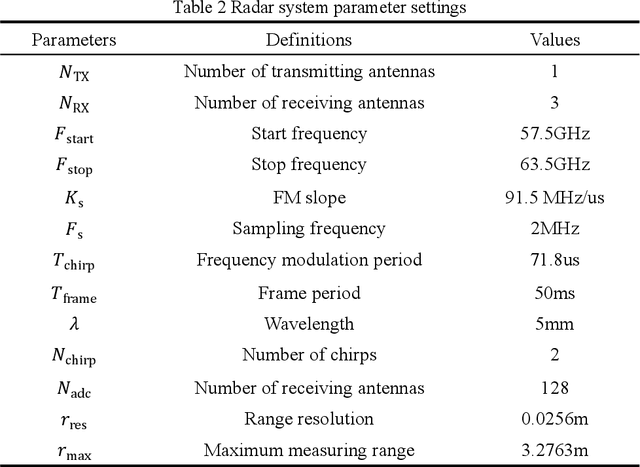
This paper establishes a multi-scattering point chest wall motion model by combining the human respiration signal (RS) and HS (HS) measured by radar. An algorithmic process is designed based on the model to accurately separate the human respiration and heartbeat motion. Firstly, a human maximum motion velocity constraint method is proposed to correct human chest wall tracking, determine the radial position of the chest wall relative to the radar, and extract the phase signal corresponding to the chest wall motion. Then an improved time-difference method is proposed to suppress the interference of RS harmonics on HS and the interference of low-frequency noise on RS. Finally, an adaptive Gaussian weighting filter is designed to extract the RS with less distortion from the phase signal. A low-order finite-length unit impulse response (FIR) filter is used to extract the HS with less distortion from the phase signal. To verify the effectiveness of the proposed algorithm, simulating the process of measuring the RS and HS of the chest wall motion model by radar. The simulation results show that, ideally, the radar measurement results of the RS and HS are less distorted relative to the actual values. In addition, we used a millimeter-wave experimental radar system in the 60 GHz band to measure the respiration rate (RR) and HR (HR) of two subjects. The experimental results showed that the measured RR and HR correlated well with the actual values. The quantitative analysis of simulation results and experimental results show that the proposed method can achieve accurate and robust measurement of RS and HS.
Gigapixel Whole-Slide Images Classification using Locally Supervised Learning
Jul 17, 2022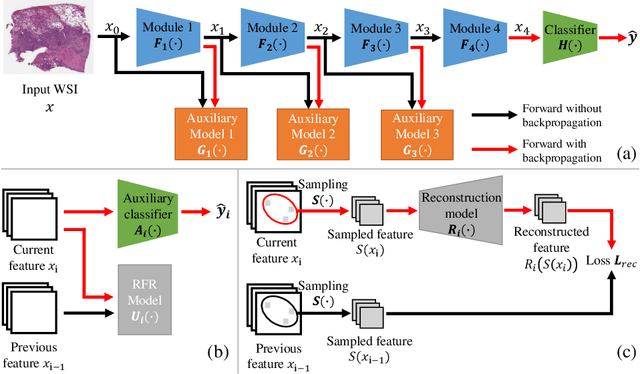
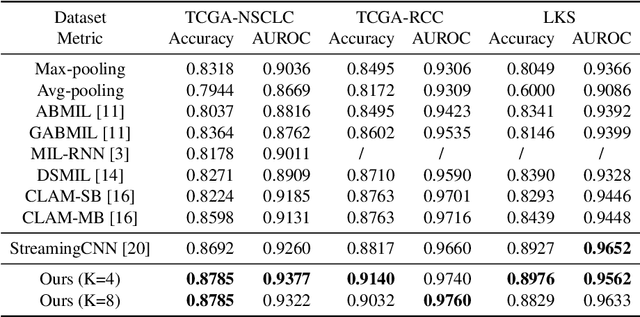


Histopathology whole slide images (WSIs) play a very important role in clinical studies and serve as the gold standard for many cancer diagnoses. However, generating automatic tools for processing WSIs is challenging due to their enormous sizes. Currently, to deal with this issue, conventional methods rely on a multiple instance learning (MIL) strategy to process a WSI at patch level. Although effective, such methods are computationally expensive, because tiling a WSI into patches takes time and does not explore the spatial relations between these tiles. To tackle these limitations, we propose a locally supervised learning framework which processes the entire slide by exploring the entire local and global information that it contains. This framework divides a pre-trained network into several modules and optimizes each module locally using an auxiliary model. We also introduce a random feature reconstruction unit (RFR) to preserve distinguishing features during training and improve the performance of our method by 1% to 3%. Extensive experiments on three publicly available WSI datasets: TCGA-NSCLC, TCGA-RCC and LKS, highlight the superiority of our method on different classification tasks. Our method outperforms the state-of-the-art MIL methods by 2% to 5% in accuracy, while being 7 to 10 times faster. Additionally, when dividing it into eight modules, our method requires as little as 20% of the total gpu memory required by end-to-end training. Our code is available at https://github.com/cvlab-stonybrook/local_learning_wsi.
Neural Networks and the Chomsky Hierarchy
Jul 05, 2022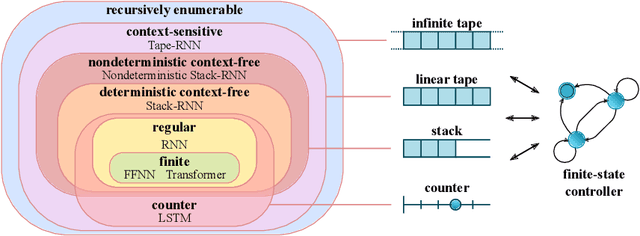



Reliable generalization lies at the heart of safe ML and AI. However, understanding when and how neural networks generalize remains one of the most important unsolved problems in the field. In this work, we conduct an extensive empirical study (2200 models, 16 tasks) to investigate whether insights from the theory of computation can predict the limits of neural network generalization in practice. We demonstrate that grouping tasks according to the Chomsky hierarchy allows us to forecast whether certain architectures will be able to generalize to out-of-distribution inputs. This includes negative results where even extensive amounts of data and training time never led to any non-trivial generalization, despite models having sufficient capacity to perfectly fit the training data. Our results show that, for our subset of tasks, RNNs and Transformers fail to generalize on non-regular tasks, LSTMs can solve regular and counter-language tasks, and only networks augmented with structured memory (such as a stack or memory tape) can successfully generalize on context-free and context-sensitive tasks.
Pseudo value-based Deep Neural Networks for Multi-state Survival Analysis
Jul 12, 2022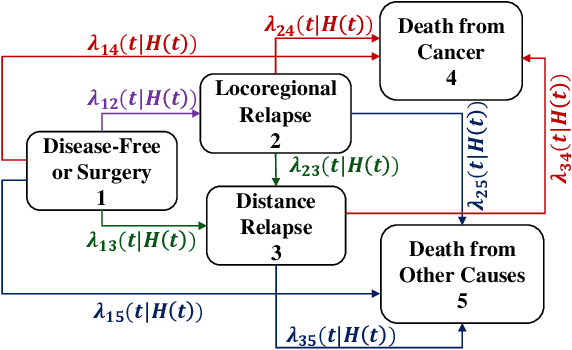
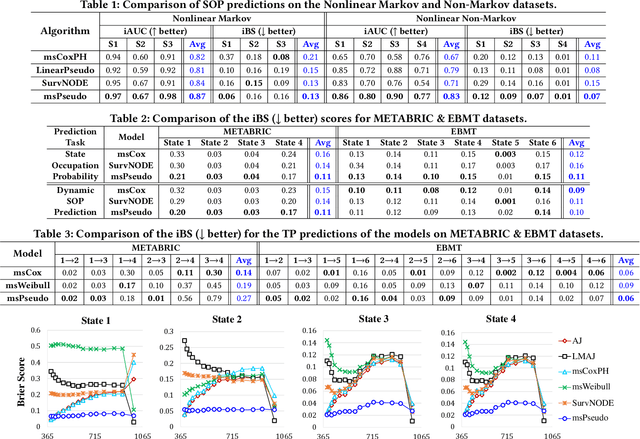
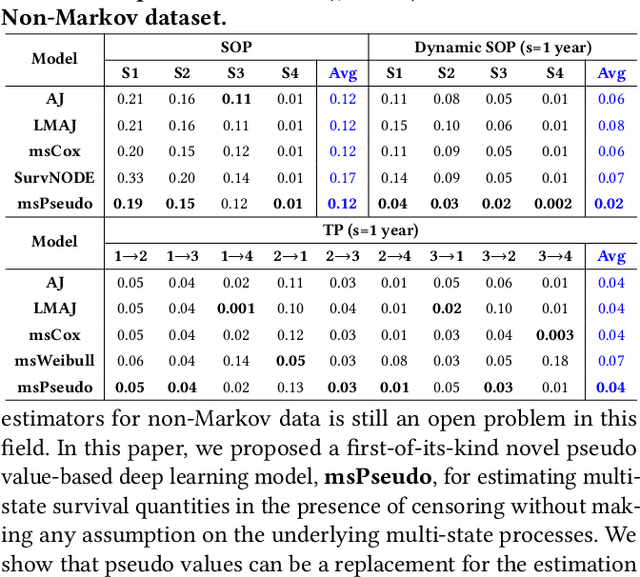
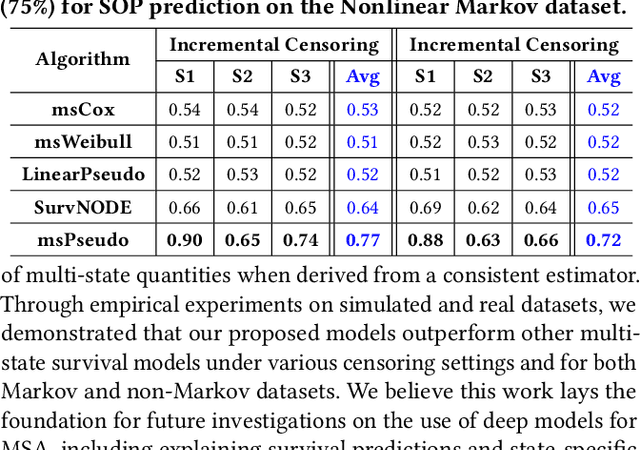
Multi-state survival analysis (MSA) uses multi-state models for the analysis of time-to-event data. In medical applications, MSA can provide insights about the complex disease progression in patients. A key challenge in MSA is the accurate subject-specific prediction of multi-state model quantities such as transition probability and state occupation probability in the presence of censoring. Traditional multi-state methods such as Aalen-Johansen (AJ) estimators and Cox-based methods are respectively limited by Markov and proportional hazards assumptions and are infeasible for making subject-specific predictions. Neural ordinary differential equations for MSA relax these assumptions but are computationally expensive and do not directly model the transition probabilities. To address these limitations, we propose a new class of pseudo-value-based deep learning models for multi-state survival analysis, where we show that pseudo values - designed to handle censoring - can be a natural replacement for estimating the multi-state model quantities when derived from a consistent estimator. In particular, we provide an algorithm to derive pseudo values from consistent estimators to directly predict the multi-state survival quantities from the subject's covariates. Empirical results on synthetic and real-world datasets show that our proposed models achieve state-of-the-art results under various censoring settings.
Few 'Zero Level Set'-Shot Learning of Shape Signed Distance Functions in Feature Space
Jul 09, 2022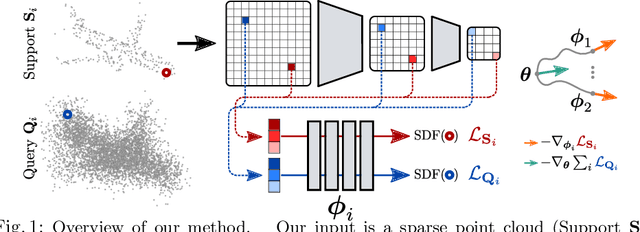



We explore a new idea for learning based shape reconstruction from a point cloud, based on the recently popularized implicit neural shape representations. We cast the problem as a few-shot learning of implicit neural signed distance functions in feature space, that we approach using gradient based meta-learning. We use a convolutional encoder to build a feature space given the input point cloud. An implicit decoder learns to predict signed distance values given points represented in this feature space. Setting the input point cloud, i.e. samples from the target shape function's zero level set, as the support (i.e. context) in few-shot learning terms, we train the decoder such that it can adapt its weights to the underlying shape of this context with a few (5) tuning steps. We thus combine two types of implicit neural network conditioning mechanisms simultaneously for the first time, namely feature encoding and meta-learning. Our numerical and qualitative evaluation shows that in the context of implicit reconstruction from a sparse point cloud, our proposed strategy, i.e. meta-learning in feature space, outperforms existing alternatives, namely standard supervised learning in feature space, and meta-learning in euclidean space, while still providing fast inference.