 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Cross Vision-RF Gait Re-identification with Low-cost RGB-D Cameras and mmWave Radars
Jul 16, 2022
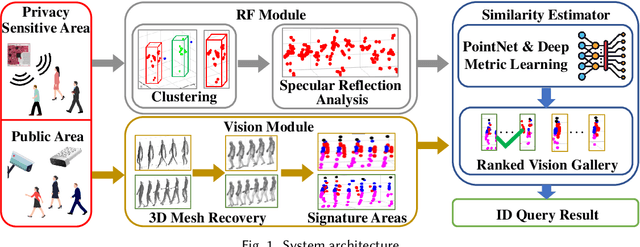
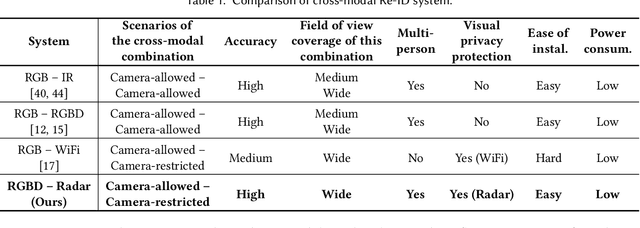
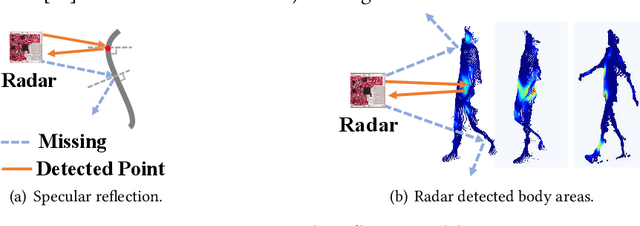
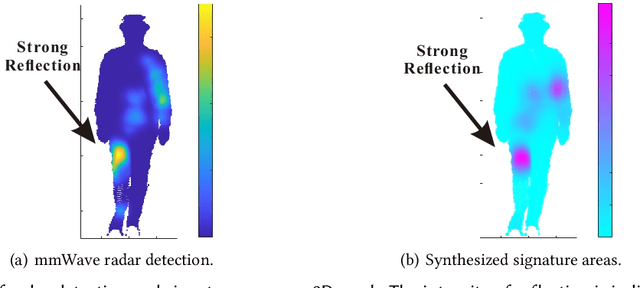
Human identification is a key requirement for many applications in everyday life, such as personalized services, automatic surveillance, continuous authentication, and contact tracing during pandemics, etc. This work studies the problem of cross-modal human re-identification (ReID), in response to the regular human movements across camera-allowed regions (e.g., streets) and camera-restricted regions (e.g., offices) deployed with heterogeneous sensors. By leveraging the emerging low-cost RGB-D cameras and mmWave radars, we propose the first-of-its-kind vision-RF system for cross-modal multi-person ReID at the same time. Firstly, to address the fundamental inter-modality discrepancy, we propose a novel signature synthesis algorithm based on the observed specular reflection model of a human body. Secondly, an effective cross-modal deep metric learning model is introduced to deal with interference caused by unsynchronized data across radars and cameras. Through extensive experiments in both indoor and outdoor environments, we demonstrate that our proposed system is able to achieve ~92.5% top-1 accuracy and ~97.5% top-5 accuracy out of 56 volunteers. We also show that our proposed system is able to robustly reidentify subjects even when multiple subjects are present in the sensors' field of view.
Batch-efficient EigenDecomposition for Small and Medium Matrices
Jul 09, 2022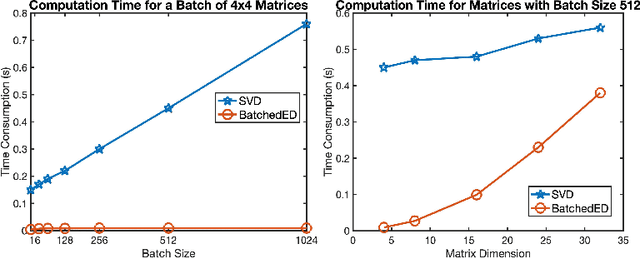

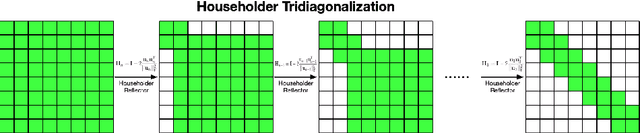
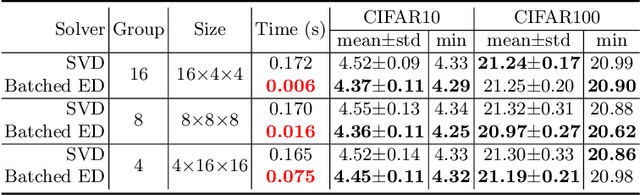
EigenDecomposition (ED) is at the heart of many computer vision algorithms and applications. One crucial bottleneck limiting its usage is the expensive computation cost, particularly for a mini-batch of matrices in the deep neural networks. In this paper, we propose a QR-based ED method dedicated to the application scenarios of computer vision. Our proposed method performs the ED entirely by batched matrix/vector multiplication, which processes all the matrices simultaneously and thus fully utilizes the power of GPUs. Our technique is based on the explicit QR iterations by Givens rotation with double Wilkinson shifts. With several acceleration techniques, the time complexity of QR iterations is reduced from $O{(}n^5{)}$ to $O{(}n^3{)}$. The numerical test shows that for small and medium batched matrices (\emph{e.g.,} $dim{<}32$) our method can be much faster than the Pytorch SVD function. Experimental results on visual recognition and image generation demonstrate that our methods also achieve competitive performances.
Room geometry blind inference based on the localization of real sound source and first order reflections
Jul 22, 2022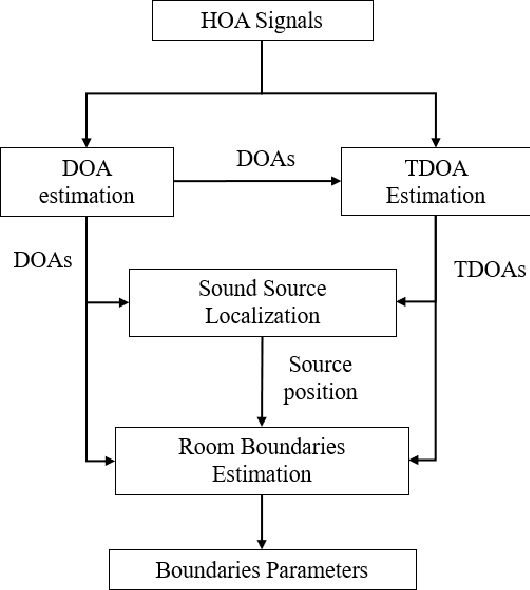
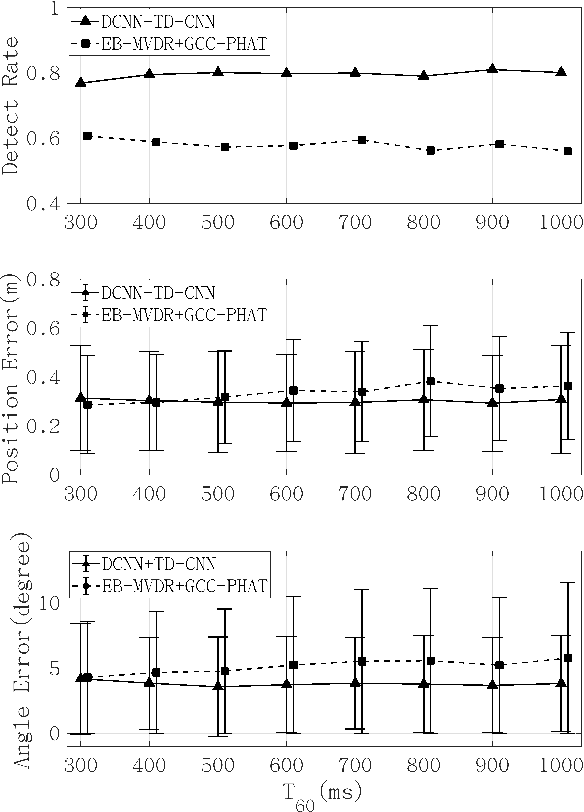

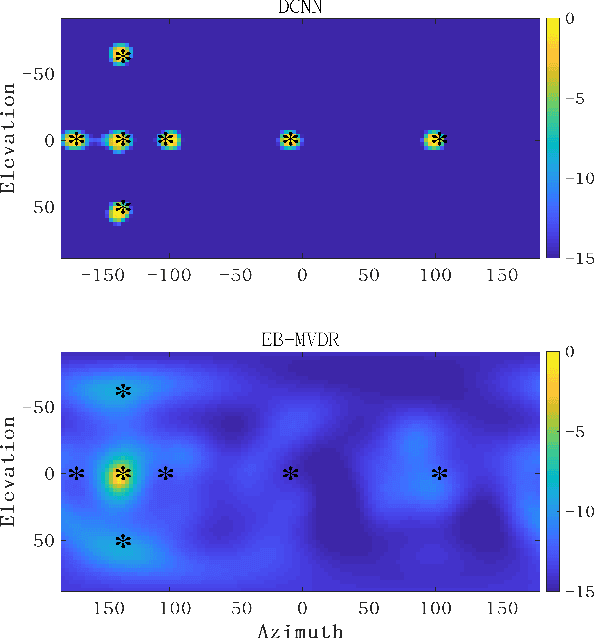
The conventional room geometry blind inference techniques with acoustic signals are conducted based on the prior knowledge of the environment, such as the room impulse response (RIR) or the sound source position, which will limit its application under unknown scenarios. To solve this problem, we have proposed a room geometry reconstruction method in this paper by using the geometric relation between the direct signal and first-order reflections. In addition to the information of the compact microphone array itself, this method does not need any precognition of the environmental parameters. Besides, the learning-based DNN models are designed and used to improve the accuracy and integrity of the localization results of the direct source and first-order reflections. The direction of arrival (DOA) and time difference of arrival (TDOA) information of the direct and reflected signals are firstly estimated using the proposed DCNN and TD-CNN models, which have higher sensitivity and accuracy than the conventional methods. Then the position of the sound source is inferred by integrating the DOA, TDOA and array height using the proposed DNN model. After that, the positions of image sources and corresponding boundaries are derived based on the geometric relation. Experimental results of both simulations and real measurements verify the effectiveness and accuracy of the proposed techniques compared with the conventional methods under different reverberant environments.
Yankee Swap: a Fast and Simple Fair Allocation Mechanism for Matroid Rank Valuations
Jun 28, 2022
We study fair allocation of indivisible goods when agents have matroid rank valuations. Our main contribution is a simple algorithm based on the colloquial Yankee Swap procedure that computes provably fair and efficient Lorenz dominating allocations. While there exist polynomial time algorithms to compute such allocations, our proposed method improves on them in two ways. (a) Our approach is easy to understand and does not use complex matroid optimization algorithms as subroutines. (b) Our approach is scalable; it is provably faster than all known algorithms to compute Lorenz dominating allocations. These two properties are key to the adoption of algorithms in any real fair allocation setting; our contribution brings us one step closer to this goal.
Trajectory and Resource Optimization for UAV Synthetic Aperture Radar
Jul 12, 2022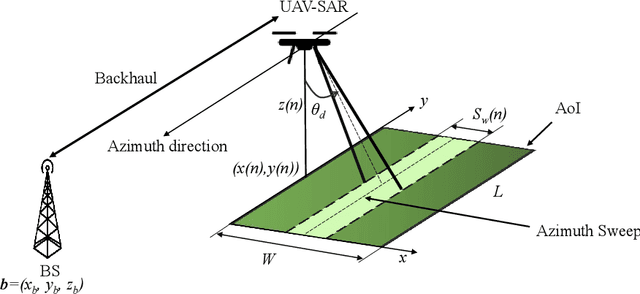
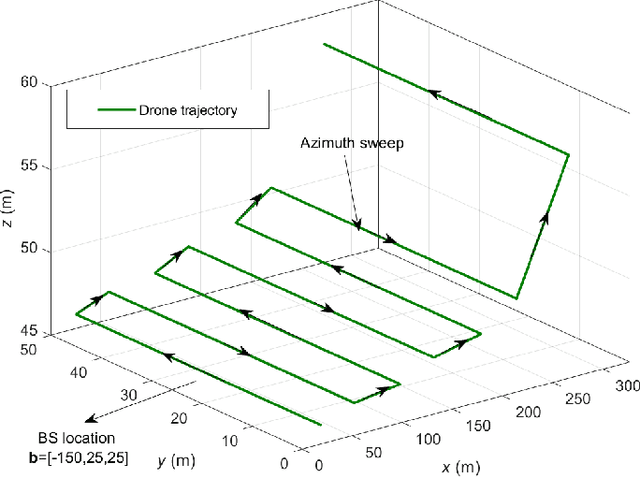
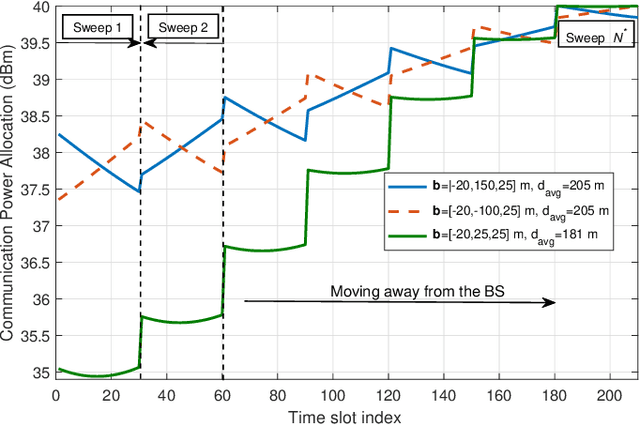
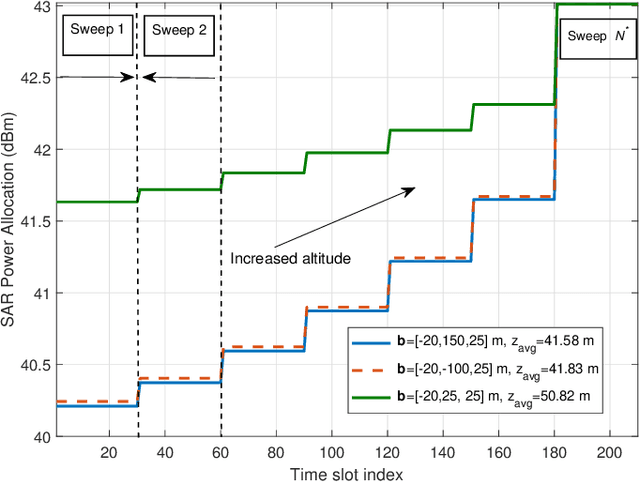
In this paper, we study the trajectory and resource optimization for lightweight rotary-wing unmanned aerial vehicles (UAVs) equipped with a synthetic aperture radar (SAR) system. The UAV's mission is to perform SAR imaging of a given area of interest (AoI). In this setup, real-time communication with a base station (BS) is required to facilitate live mission planning for the drone. For this purpose, a non-convex mixed-integer non-linear program (MINLP) is formulated such that the UAV resources and three-dimensional (3D) trajectory are jointly optimized for maximization of the drone radar ground coverage. We present a low-complexity sub-optimal algorithm based on successive convex approximation (SCA) for solving the problem, and perform a finite search to optimize the total distance traversed by the UAV for maximal coverage. We show that the proposed 3D trajectory planning achieves at least 70% improvement in radar ground coverage compared to benchmark schemes employing constant powers for communication or radar imaging. We also show that positioning the BS near the AoI can significantly improve the radar coverage of the UAV.
Constrained Iterative LQG for Real-Time Chance-Constrained Gaussian Belief Space Planning
Aug 21, 2021

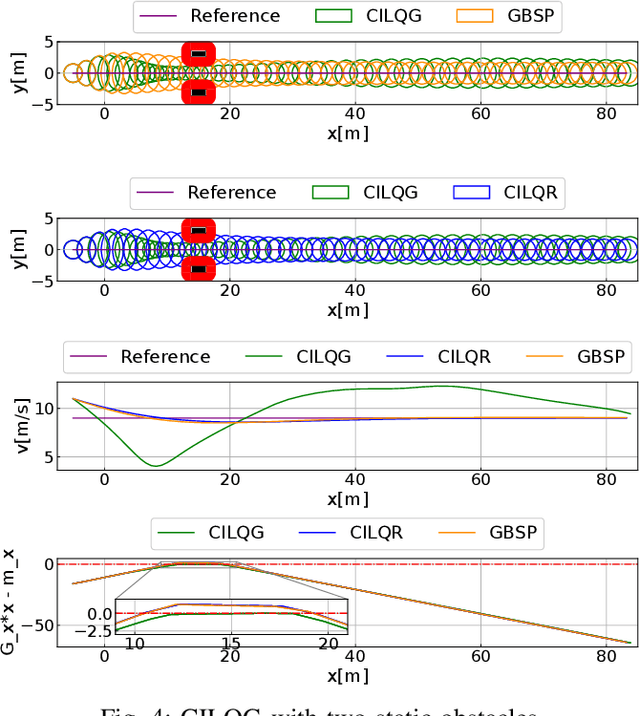
Motion planning under uncertainty is of significant importance for safety-critical systems such as autonomous vehicles. Such systems have to satisfy necessary constraints (e.g., collision avoidance) with potential uncertainties coming from either disturbed system dynamics or noisy sensor measurements. However, existing motion planning methods cannot efficiently find the robust optimal solutions under general nonlinear and non-convex settings. In this paper, we formulate such problem as chance-constrained Gaussian belief space planning and propose the constrained iterative Linear Quadratic Gaussian (CILQG) algorithm as a real-time solution. In this algorithm, we iteratively calculate a Gaussian approximation of the belief and transform the chance-constraints. We evaluate the effectiveness of our method in simulations of autonomous driving planning tasks with static and dynamic obstacles. Results show that CILQG can handle uncertainties more appropriately and has faster computation time than baseline methods.
Single Stage Virtual Try-on via Deformable Attention Flows
Jul 19, 2022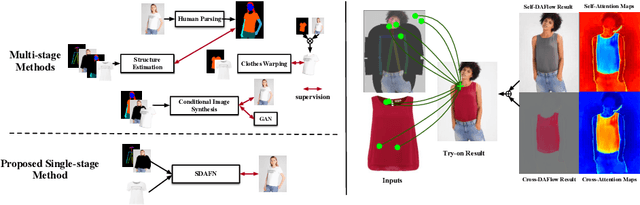

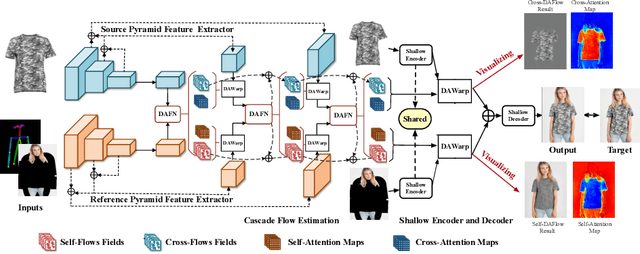
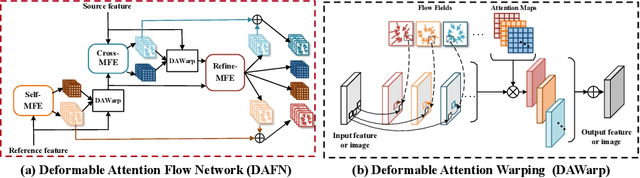
Virtual try-on aims to generate a photo-realistic fitting result given an in-shop garment and a reference person image. Existing methods usually build up multi-stage frameworks to deal with clothes warping and body blending respectively, or rely heavily on intermediate parser-based labels which may be noisy or even inaccurate. To solve the above challenges, we propose a single-stage try-on framework by developing a novel Deformable Attention Flow (DAFlow), which applies the deformable attention scheme to multi-flow estimation. With pose keypoints as the guidance only, the self- and cross-deformable attention flows are estimated for the reference person and the garment images, respectively. By sampling multiple flow fields, the feature-level and pixel-level information from different semantic areas are simultaneously extracted and merged through the attention mechanism. It enables clothes warping and body synthesizing at the same time which leads to photo-realistic results in an end-to-end manner. Extensive experiments on two try-on datasets demonstrate that our proposed method achieves state-of-the-art performance both qualitatively and quantitatively. Furthermore, additional experiments on the other two image editing tasks illustrate the versatility of our method for multi-view synthesis and image animation.
Sedentary Behavior Estimation with Hip-worn Accelerometer Data: Segmentation, Classification and Thresholding
Jul 05, 2022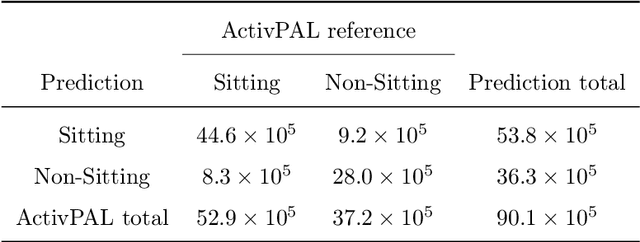
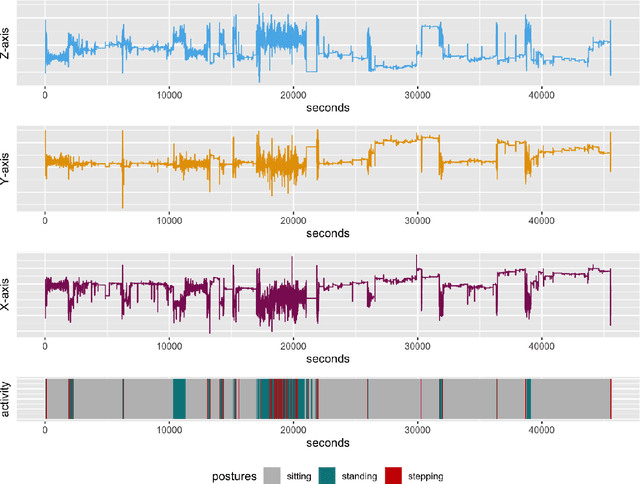
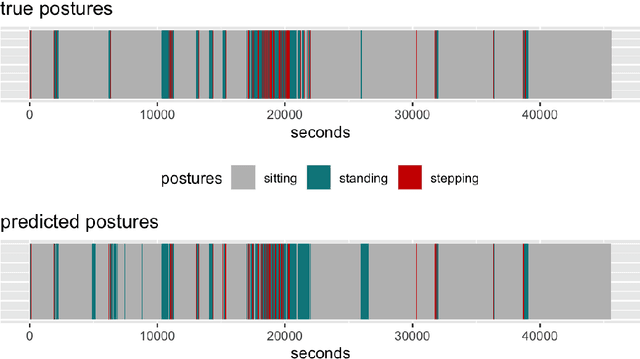
Cohort studies are increasingly using accelerometers for physical activity and sedentary behavior estimation. These devices tend to be less error-prone than self-report, can capture activity throughout the day, and are economical. However, previous methods for estimating sedentary behavior based on hip-worn data are often invalid or suboptimal under free-living situations and subject-to-subject variation. In this paper, we propose a local Markov switching model that takes this situation into account, and introduce a general procedure for posture classification and sedentary behavior analysis that fits the model naturally. Our method features changepoint detection methods in time series and also a two stage classification step that labels data into 3 classes(sitting, standing, stepping). Through a rigorous training-testing paradigm, we showed that our approach achieves > 80% accuracy. In addition, our method is robust and easy to interpret.
Multi-label Classification with High-rank and High-order Label Correlations
Jul 09, 2022
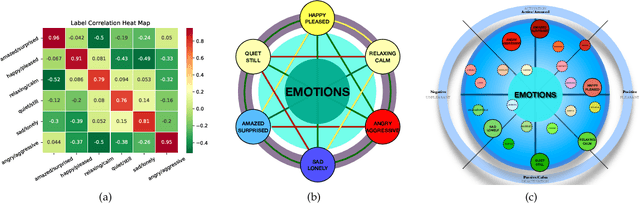

Exploiting label correlations is important to multi-label classification. Previous methods capture the high-order label correlations mainly by transforming the label matrix to a latent label space with low-rank matrix factorization. However, the label matrix is generally a full-rank or approximate full-rank matrix, making the low-rank factorization inappropriate. Besides, in the latent space, the label correlations will become implicit. To this end, we propose a simple yet effective method to depict the high-order label correlations explicitly, and at the same time maintain the high-rank of the label matrix. Moreover, we estimate the label correlations and infer model parameters simultaneously via the local geometric structure of the input to achieve mutual enhancement. Comparative studies over ten benchmark data sets validate the effectiveness of the proposed algorithm in multi-label classification. The exploited high-order label correlations are consistent with common sense empirically. Our code is publicly available at https://github.com/601175936/HOMI.
Learning to Estimate External Forces of Human Motion in Video
Jul 12, 2022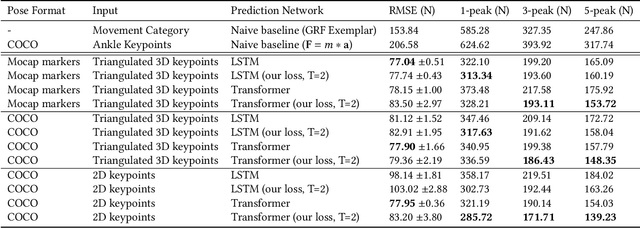


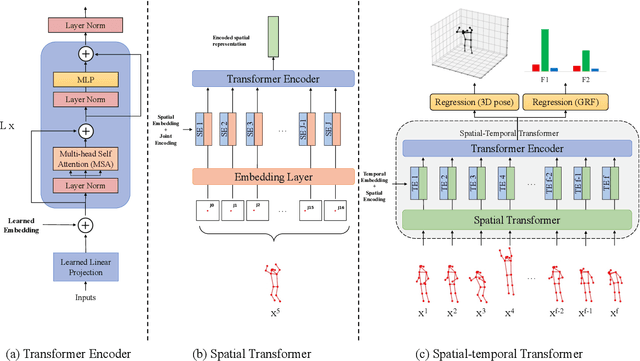
Analyzing sports performance or preventing injuries requires capturing ground reaction forces (GRFs) exerted by the human body during certain movements. Standard practice uses physical markers paired with force plates in a controlled environment, but this is marred by high costs, lengthy implementation time, and variance in repeat experiments; hence, we propose GRF inference from video. While recent work has used LSTMs to estimate GRFs from 2D viewpoints, these can be limited in their modeling and representation capacity. First, we propose using a transformer architecture to tackle the GRF from video task, being the first to do so. Then we introduce a new loss to minimize high impact peaks in regressed curves. We also show that pre-training and multi-task learning on 2D-to-3D human pose estimation improves generalization to unseen motions. And pre-training on this different task provides good initial weights when finetuning on smaller (rarer) GRF datasets. We evaluate on LAAS Parkour and a newly collected ForcePose dataset; we show up to 19% decrease in error compared to prior approaches.