 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
PAGP: A physics-assisted Gaussian process framework with active learning for forward and inverse problems of partial differential equations
Apr 06, 2022
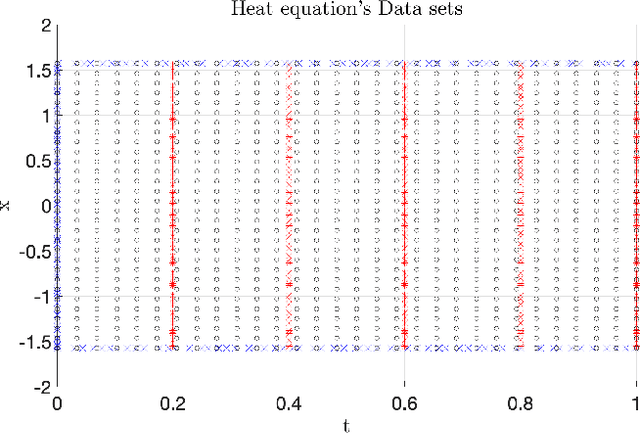
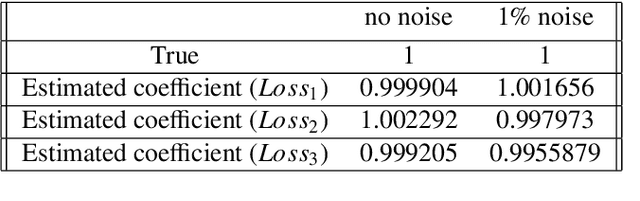
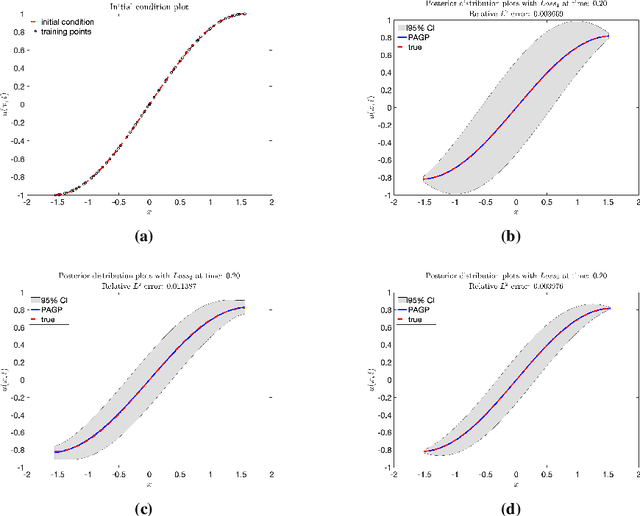

In this work, a Gaussian process regression(GPR) model incorporated with given physical information in partial differential equations(PDEs) is developed: physics-assisted Gaussian processes(PAGP). The targets of this model can be divided into two types of problem: finding solutions or discovering unknown coefficients of given PDEs with initial and boundary conditions. We introduce three different models: continuous time, discrete time and hybrid models. The given physical information is integrated into Gaussian process model through our designed GP loss functions. Three types of loss function are provided in this paper based on two different approaches to train the standard GP model. The first part of the paper introduces the continuous time model which treats temporal domain the same as spatial domain. The unknown coefficients in given PDEs can be jointly learned with GP hyper-parameters by minimizing the designed loss function. In the discrete time models, we first choose a time discretization scheme to discretize the temporal domain. Then the PAGP model is applied at each time step together with the scheme to approximate PDE solutions at given test points of final time. To discover unknown coefficients in this setting, observations at two specific time are needed and a mixed mean square error function is constructed to obtain the optimal coefficients. In the last part, a novel hybrid model combining the continuous and discrete time models is presented. It merges the flexibility of continuous time model and the accuracy of the discrete time model. The performance of choosing different models with different GP loss functions is also discussed. The effectiveness of the proposed PAGP methods is illustrated in our numerical section.
Diverse Video Generation from a Single Video
May 11, 2022

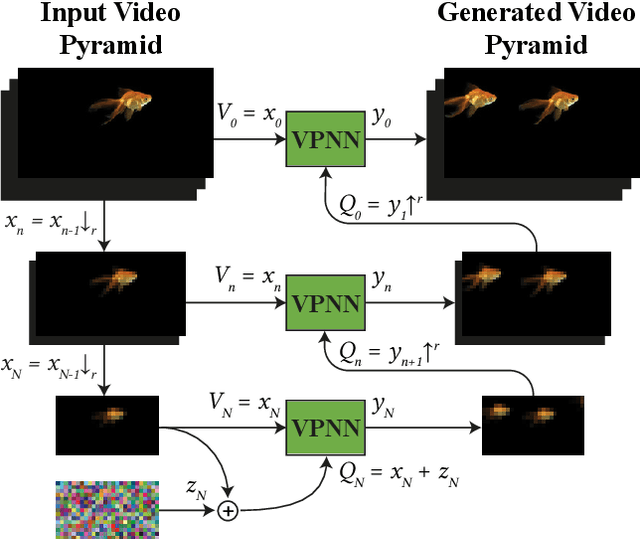
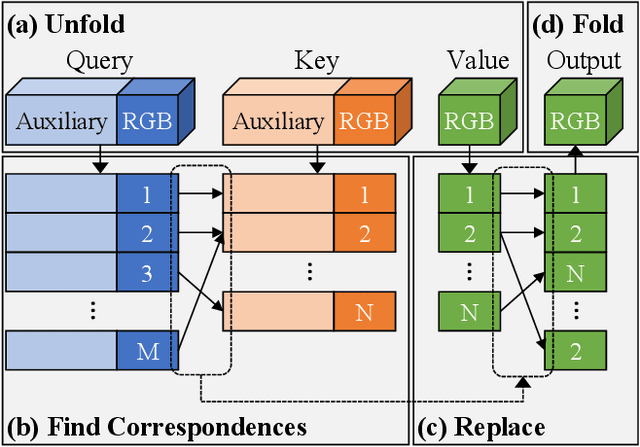
GANs are able to perform generation and manipulation tasks, trained on a single video. However, these single video GANs require unreasonable amount of time to train on a single video, rendering them almost impractical. In this paper we question the necessity of a GAN for generation from a single video, and introduce a non-parametric baseline for a variety of generation and manipulation tasks. We revive classical space-time patches-nearest-neighbors approaches and adapt them to a scalable unconditional generative model, without any learning. This simple baseline surprisingly outperforms single-video GANs in visual quality and realism (confirmed by quantitative and qualitative evaluations), and is disproportionately faster (runtime reduced from several days to seconds). Our approach is easily scaled to Full-HD videos. We also use the same framework to demonstrate video analogies and spatio-temporal retargeting. These observations show that classical approaches significantly outperform heavy deep learning machinery for these tasks. This sets a new baseline for single-video generation and manipulation tasks, and no less important -- makes diverse generation from a single video practically possible for the first time.
TIMo -- A Dataset for Indoor Building Monitoring with a Time-of-Flight Camera
Aug 27, 2021
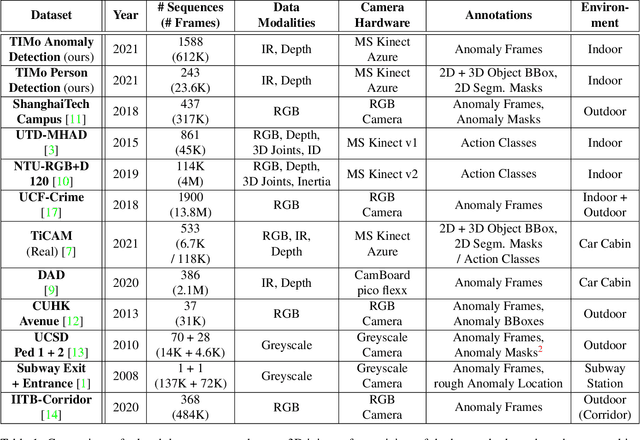

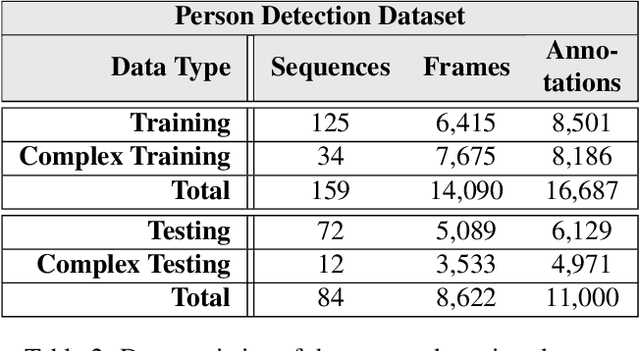
We present TIMo (Time-of-flight Indoor Monitoring), a dataset for video-based monitoring of indoor spaces captured using a time-of-flight (ToF) camera. The resulting depth videos feature people performing a set of different predefined actions, for which we provide detailed annotations. Person detection for people counting and anomaly detection are the two targeted applications. Most existing surveillance video datasets provide either grayscale or RGB videos. Depth information, on the other hand, is still a rarity in this class of datasets in spite of being popular and much more common in other research fields within computer vision. Our dataset addresses this gap in the landscape of surveillance video datasets. The recordings took place at two different locations with the ToF camera set up either in a top-down or a tilted perspective on the scene. The dataset is publicly available at https://vizta-tof.kl.dfki.de/timo-dataset-overview/.
Interpolation, extrapolation, and local generalization in common neural networks
Jul 18, 2022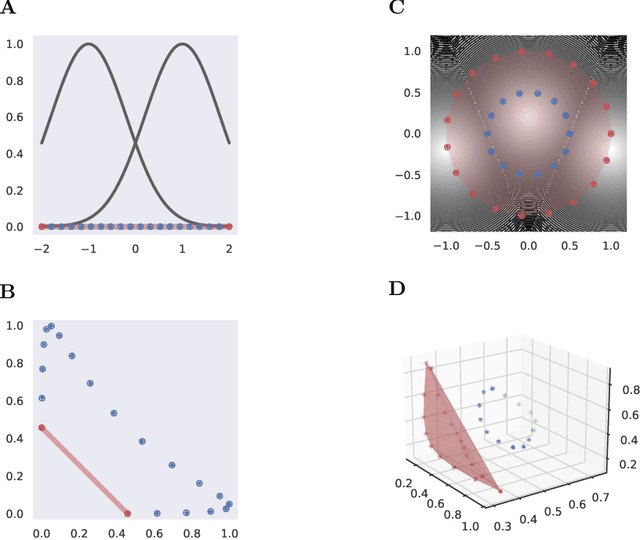
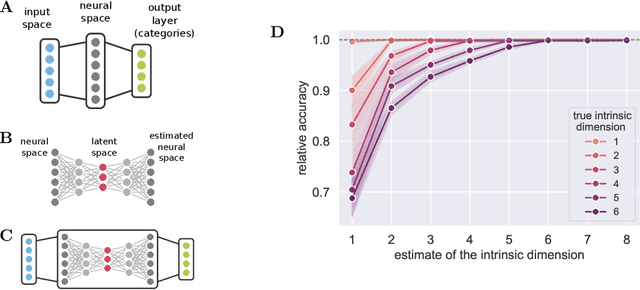
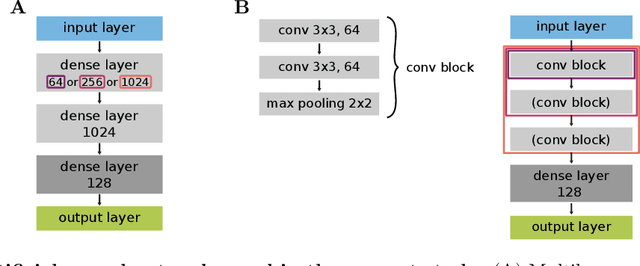
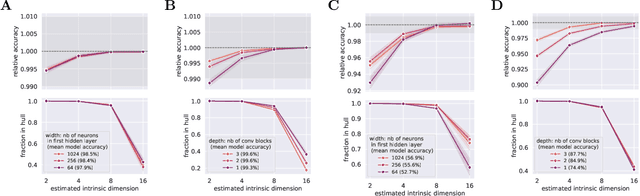
There has been a long history of works showing that neural networks have hard time extrapolating beyond the training set. A recent study by Balestriero et al. (2021) challenges this view: defining interpolation as the state of belonging to the convex hull of the training set, they show that the test set, either in input or neural space, cannot lie for the most part in this convex hull, due to the high dimensionality of the data, invoking the well known curse of dimensionality. Neural networks are then assumed to necessarily work in extrapolative mode. We here study the neural activities of the last hidden layer of typical neural networks. Using an autoencoder to uncover the intrinsic space underlying the neural activities, we show that this space is actually low-dimensional, and that the better the model, the lower the dimensionality of this intrinsic space. In this space, most samples of the test set actually lie in the convex hull of the training set: under the convex hull definition, the models thus happen to work in interpolation regime. Moreover, we show that belonging to the convex hull does not seem to be the relevant criteria. Different measures of proximity to the training set are actually better related to performance accuracy. Thus, typical neural networks do seem to operate in interpolation regime. Good generalization performances are linked to the ability of a neural network to operate well in such a regime.
Safe Human-Robot Collaborative Transportation via Trust-Driven Role Adaptation
Jul 13, 2022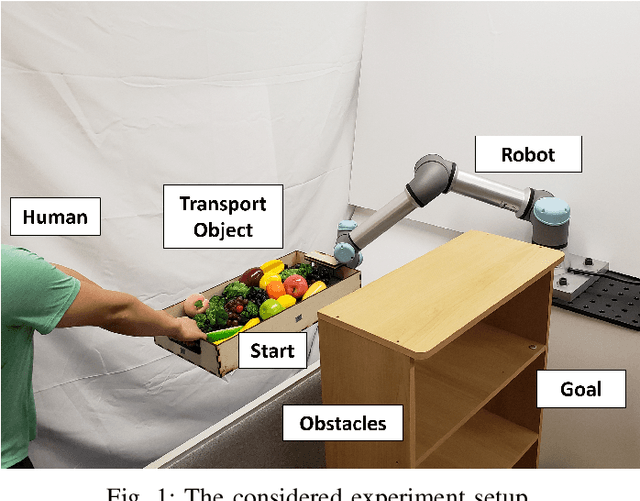
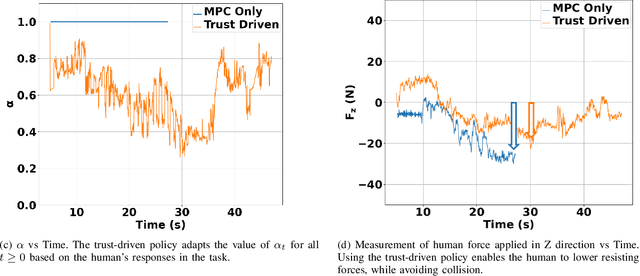
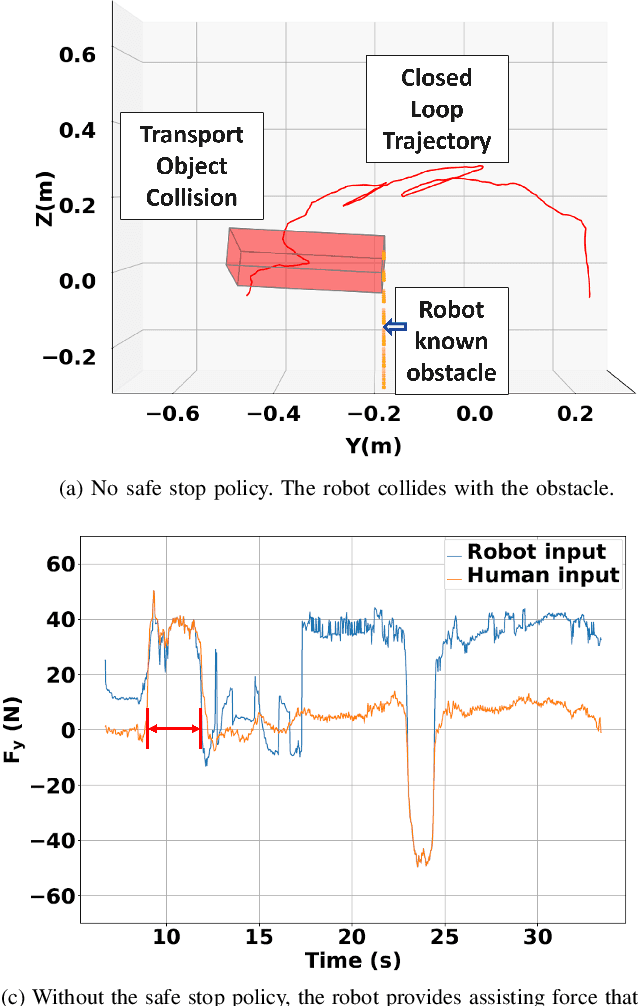
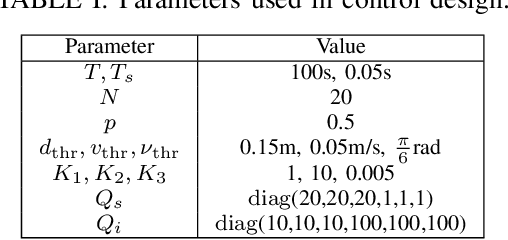
We study a human-robot collaborative transportation task in presence of obstacles. The task for each agent is to carry a rigid object to a common target position, while safely avoiding obstacles and satisfying the compliance and actuation constraints of the other agent. Human and robot do not share the local view of the environment. The human policy either assists the robot when they deem the robot actions safe based on their perception of the environment, or actively leads the task. Using estimated human inputs, the robot plans a trajectory for the transported object by solving a constrained finite time optimal control problem. Sensors on the robot measure the inputs applied by the human. The robot then appropriately applies a weighted combination of the human's applied and its own planned inputs, where the weights are chosen based on the robot's trust value on its estimates of the human's inputs. This allows for a dynamic leader-follower role adaptation of the robot throughout the task. Furthermore, under a low value of trust, if the robot approaches any obstacle potentially unknown to the human, it triggers a safe stopping policy, maintaining safety of the system and signaling a required change in the human's intent. With experimental results, we demonstrate the efficacy of the proposed approach.
Constrained Reinforcement Learning for Short Video Recommendation
May 26, 2022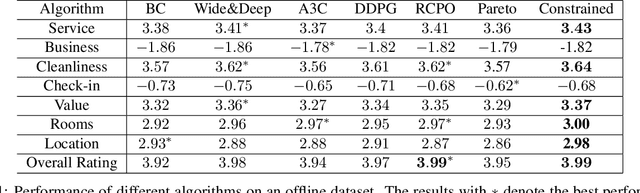
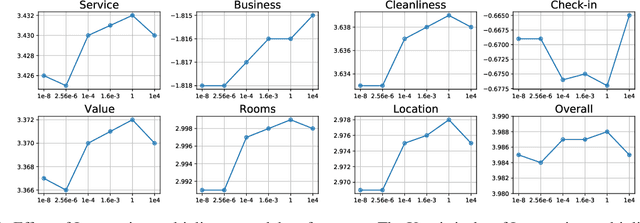
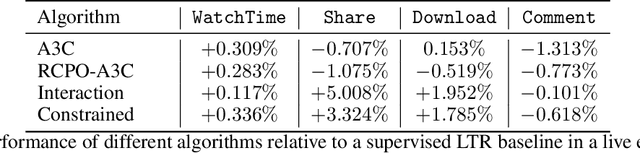
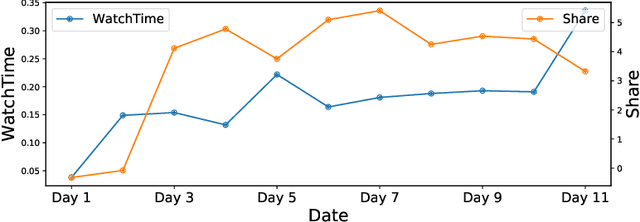
The wide popularity of short videos on social media poses new opportunities and challenges to optimize recommender systems on the video-sharing platforms. Users provide complex and multi-faceted responses towards recommendations, including watch time and various types of interactions with videos. As a result, established recommendation algorithms that concern a single objective are not adequate to meet this new demand of optimizing comprehensive user experiences. In this paper, we formulate the problem of short video recommendation as a constrained Markov Decision Process (MDP), where platforms want to optimize the main goal of user watch time in long term, with the constraint of accommodating the auxiliary responses of user interactions such as sharing/downloading videos. To solve the constrained MDP, we propose a two-stage reinforcement learning approach based on actor-critic framework. At stage one, we learn individual policies to optimize each auxiliary response. At stage two, we learn a policy to (i) optimize the main response and (ii) stay close to policies learned at the first stage, which effectively guarantees the performance of this main policy on the auxiliaries. Through extensive simulations, we demonstrate effectiveness of our approach over alternatives in both optimizing the main goal as well as balancing the others. We further show the advantage of our approach in live experiments of short video recommendations, where it significantly outperforms other baselines in terms of watch time and interactions from video views. Our approach has been fully launched in the production system to optimize user experiences on the platform.
Recovery of Missing Sensor Data by Reconstructing Time-varying Graph Signals
Mar 01, 2022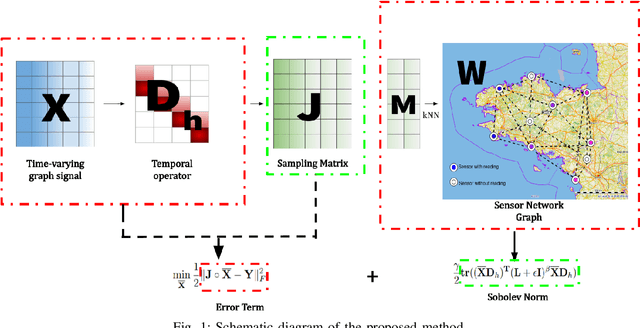
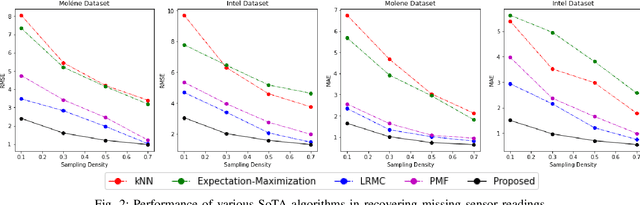
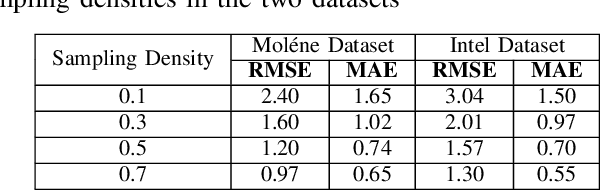
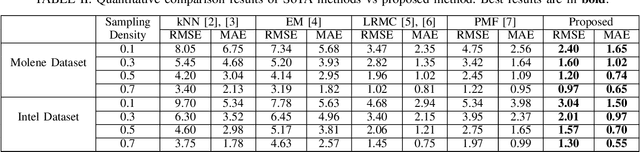
Wireless sensor networks are among the most promising technologies of the current era because of their small size, lower cost, and ease of deployment. With the increasing number of wireless sensors, the probability of generating missing data also rises. This incomplete data could lead to disastrous consequences if used for decision-making. There is rich literature dealing with this problem. However, most approaches show performance degradation when a sizable amount of data is lost. Inspired by the emerging field of graph signal processing, this paper performs a new study of a Sobolev reconstruction algorithm in wireless sensor networks. Experimental comparisons on several publicly available datasets demonstrate that the algorithm surpasses multiple state-of-the-art techniques by a maximum margin of 54%. We further show that this algorithm consistently retrieves the missing data even during massive data loss situations.
Adaptive Graph Spatial-Temporal Transformer Network for Traffic Flow Forecasting
Jul 09, 2022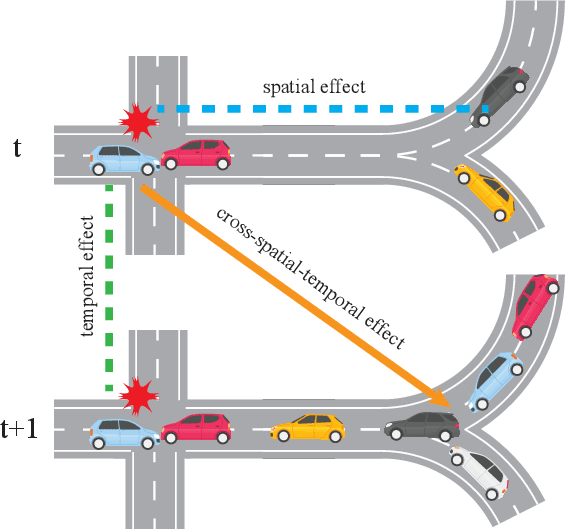
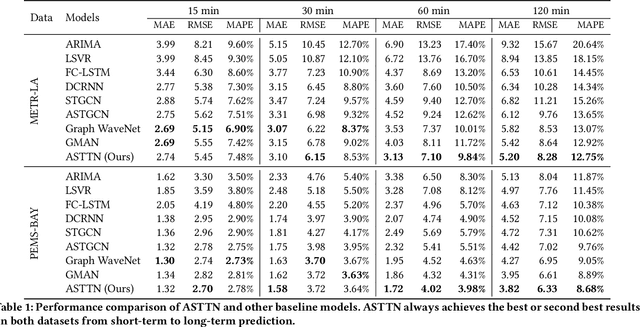
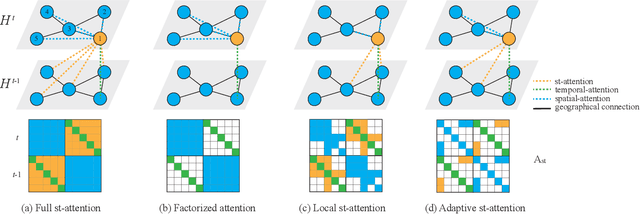
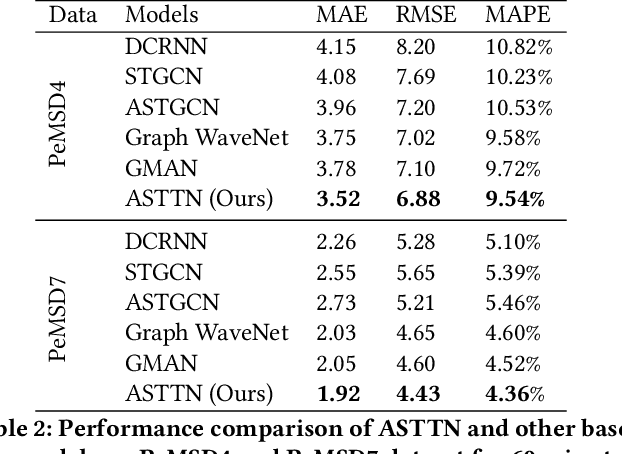
Traffic flow forecasting on graphs has real-world applications in many fields, such as transportation system and computer networks. Traffic forecasting can be highly challenging due to complex spatial-temporal correlations and non-linear traffic patterns. Existing works mostly model such spatial-temporal dependencies by considering spatial correlations and temporal correlations separately and fail to model the direct spatial-temporal correlations. Inspired by the recent success of transformers in the graph domain, in this paper, we propose to directly model the cross-spatial-temporal correlations on the spatial-temporal graph using local multi-head self-attentions. To reduce the time complexity, we set the attention receptive field to the spatially neighboring nodes, and we also introduce an adaptive graph to capture the hidden spatial-temporal dependencies. Based on these attention mechanisms, we propose a novel Adaptive Graph Spatial-Temporal Transformer Network (ASTTN), which stacks multiple spatial-temporal attention layers to apply self-attention on the input graph, followed by linear layers for predictions. Experimental results on public traffic network datasets, METR-LA PEMS-BAY, PeMSD4, and PeMSD7, demonstrate the superior performance of our model.
Stationary Multi-source AI-powered Real-time Tomography (SMART) for Dynamic Cardiac Imaging
Aug 27, 2021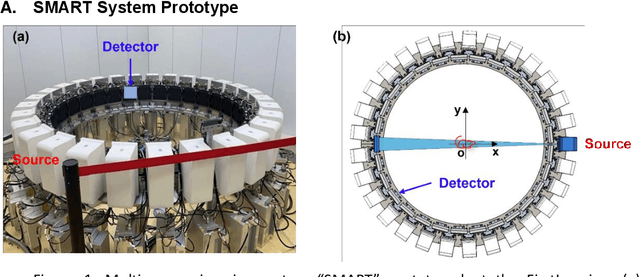
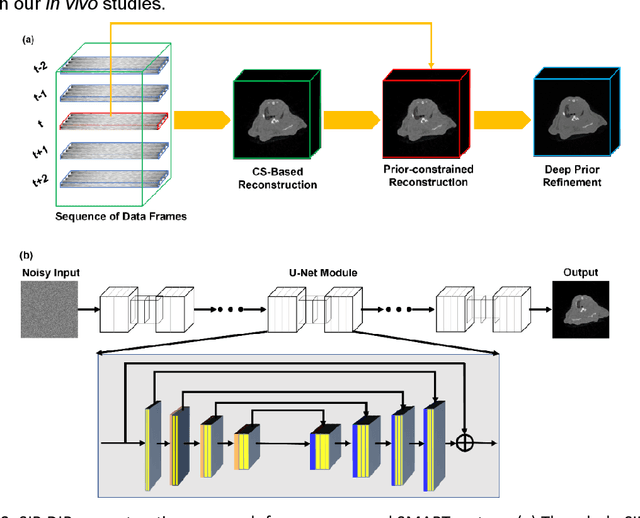
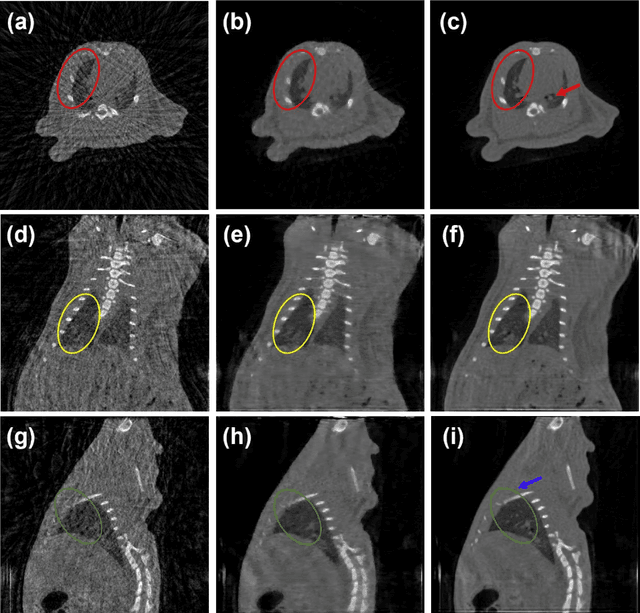

A first stationary multi-source computed tomography (CT) system is prototyped for preclinical imaging to achieve real-time temporal resolution for dynamic cardiac imaging. This unique is featured by 29 source-detector pairs fixed on a circular track for each detector to collect x-ray signals only from the opposite x-ray source. The new system architecture potentially leads to a major improvement in temporal resolution. To demonstrate the feasibility of this Stationary Multi-source AI-based Real-time Tomography (SMART) system, we develop a novel reconstruction scheme integrating both sparsified image prior (SIP) and deep image prior (DIP), which is referred to as the SIP-DIP network. Then, the SIP-DIP network for cardiac imaging is evaluated on preclinical cardiac datasets of alive rats. The reconstructed image volumes demonstrate the feasibility of the SMART system and the SIP-DIP network and the merits over other reconstruction methods.
TadML: A fast temporal action detection with Mechanics-MLP
Jun 07, 2022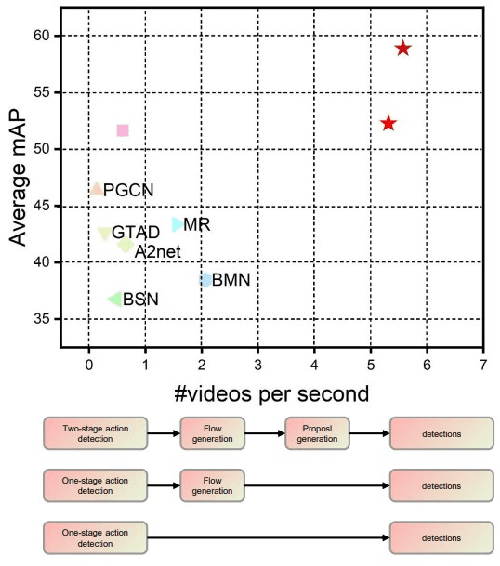
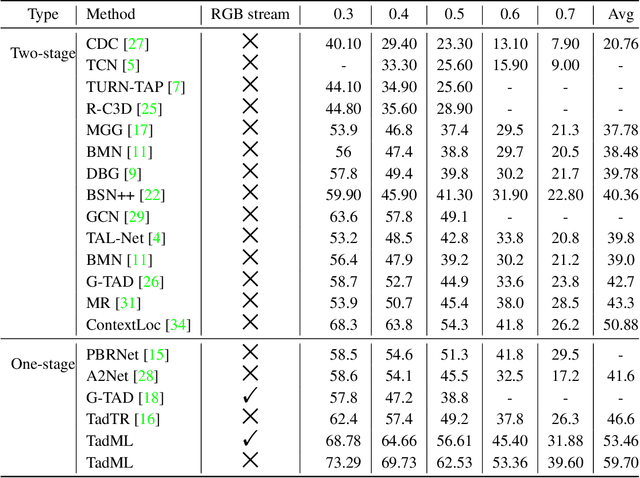
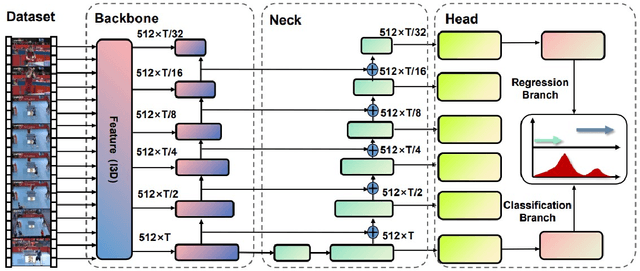
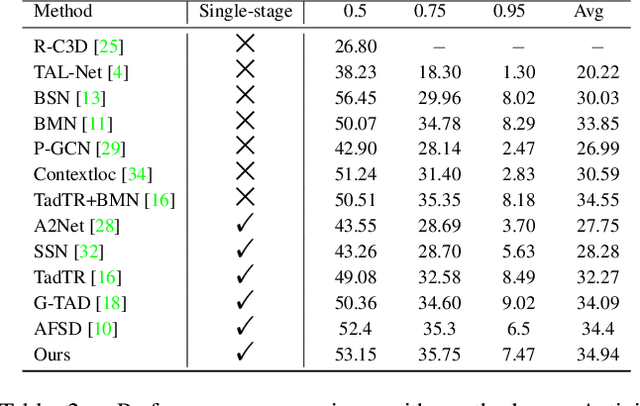
Temporal Action Detection(TAD) is a crucial but challenging task in video understanding.It is aimed at detecting both the type and start-end frame for each action instance in a long, untrimmed video.Most current models adopt both RGB and Optical-Flow streams for the TAD task. Thus, original RGB frames must be converted manually into Optical-Flow frames with additional computation and time cost, which is an obstacle to achieve real-time processing. At present, many models adopt two-stage strategies, which would slow the inference speed down and complicatedly tuning on proposals generating.By comparison, we propose a one-stage anchor-free temporal localization method with RGB stream only, in which a novel Newtonian \emph{Mechanics-MLP} architecture is established. It has comparable accuracy with all existing state-of-the-art models, while surpasses the inference speed of these methods by a large margin. The typical inference speed in this paper is astounding 4.44 video per second on THUMOS14. In applications, because there is no need to convert optical flow, the inference speed will be faster.It also proves that \emph{MLP} has great potential in downstream tasks such as TAD. The source code is available at \url{https://github.com/BonedDeng/TadML}