 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Robust Vehicle Positioning based on Multi-Epoch and Multi-Antenna TOAs in Harsh Environments
Jul 17, 2022
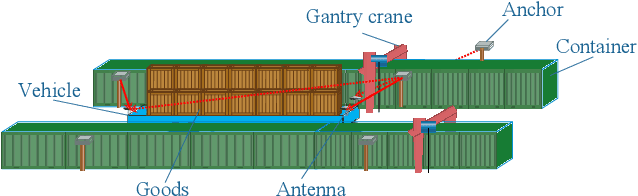
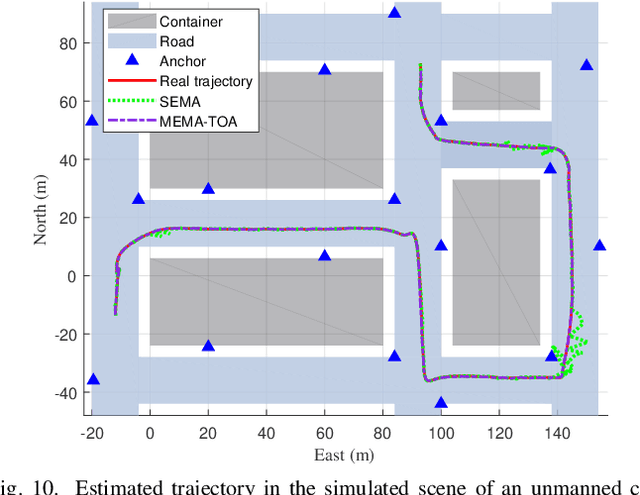
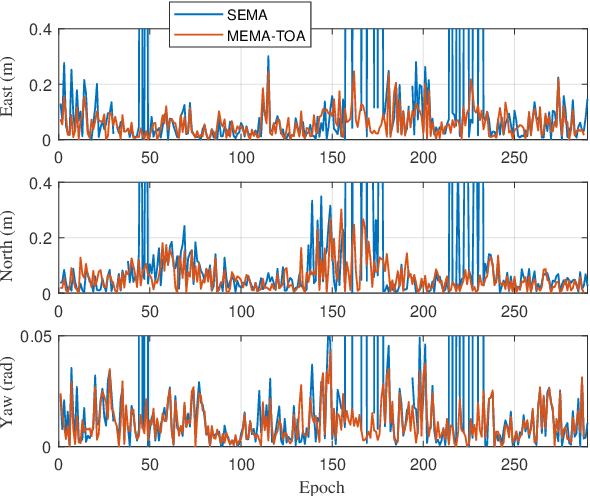
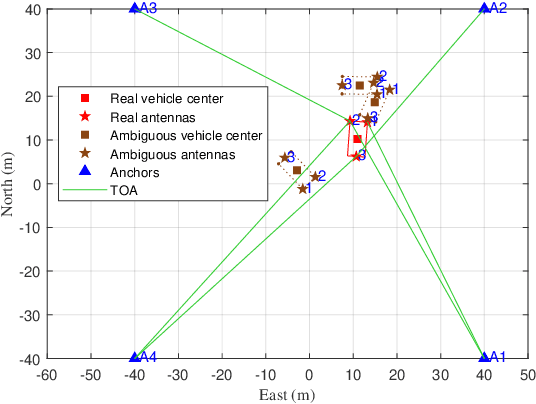
For radio-based time-of-arrival (TOA) positioning systems applied in harsh environments, obstacles in the surroundings and on the vehicle itself will block the signals from the anchors, reduce the number of available TOA measurements and thus degrade the localization performance. Conventional multi-antenna positioning technique requires a good initialization to avoid local minima, and suffers from location ambiguity due to insufficient number of TOA measurements and/or poor geometry of anchors at a single epoch. A new initialization method based on semidefinite programming (SDP), namely MEMA-SDP, is first designed to address the initialization problem of the MEMA-TOA method. Then, an iterative refinement step is developed to obtain the optimal positioning result based on the MEMA-SDP initialization. We derive the Cramer-Rao lower bound (CRLB) to analyze the accuracy of the new MEMA-TOA method theoretically, and show its superior positioning performance over the conventional single-epoch and multi-antenna (SEMA) localization method. Simulation results in harsh environments demonstrate that i) the new MEMA-SDP provides an initial estimation that is close to the real location, and empirically guarantees the global optimality of the final refined positioning solution, and ii) compared with the conventional SEMA method, the new MEMA-TOA method has higher positioning accuracy without location ambiguity, consistent with the theoretical analysis.
Landscape Learning for Neural Network Inversion
Jun 17, 2022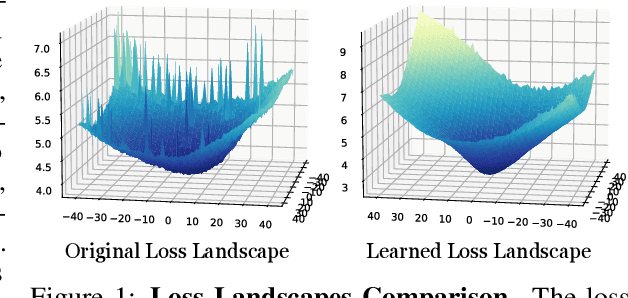
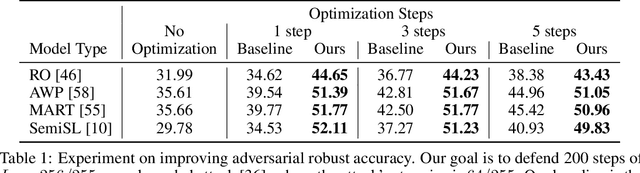
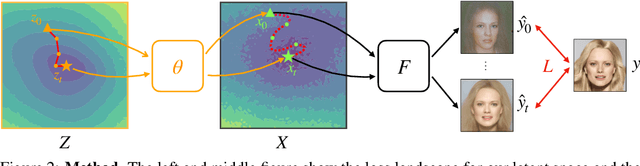

Many machine learning methods operate by inverting a neural network at inference time, which has become a popular technique for solving inverse problems in computer vision, robotics, and graphics. However, these methods often involve gradient descent through a highly non-convex loss landscape, causing the optimization process to be unstable and slow. We introduce a method that learns a loss landscape where gradient descent is efficient, bringing massive improvement and acceleration to the inversion process. We demonstrate this advantage on a number of methods for both generative and discriminative tasks, including GAN inversion, adversarial defense, and 3D human pose reconstruction.
ExpansionNet: exploring the sequence length bottleneck in the Transformer for Image Captioning
Jul 07, 2022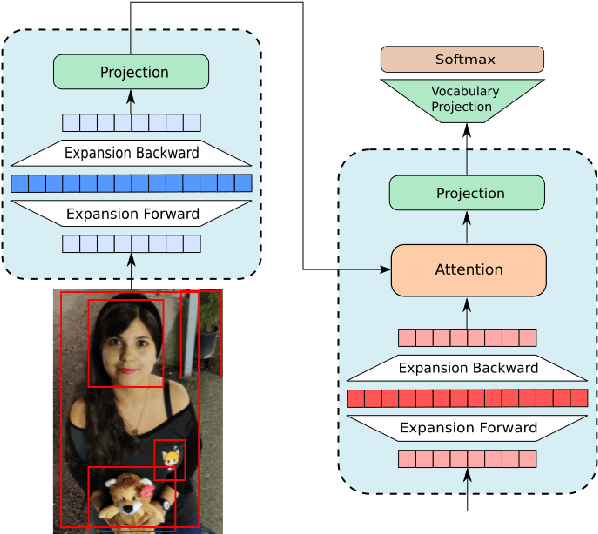
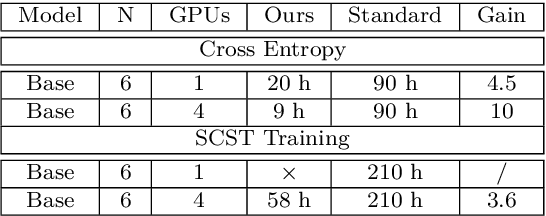
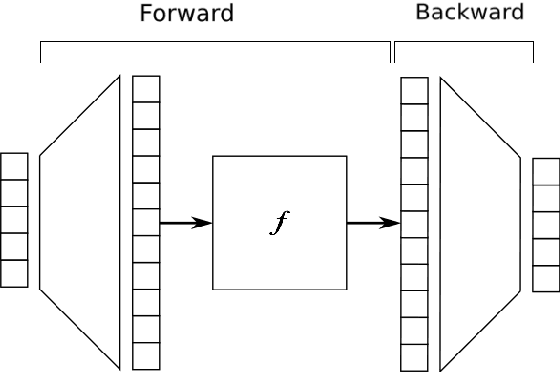
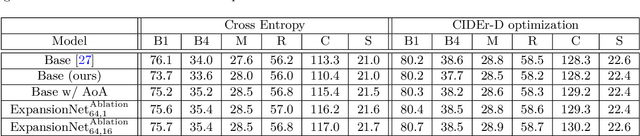
Most recent state of art architectures rely on combinations and variations of three approaches: convolutional, recurrent and self-attentive methods. Our work attempts in laying the basis for a new research direction for sequence modeling based upon the idea of modifying the sequence length. In order to do that, we propose a new method called ``Expansion Mechanism'' which transforms either dynamically or statically the input sequence into a new one featuring a different sequence length. Furthermore, we introduce a novel architecture that exploits such method and achieves competitive performances on the MS-COCO 2014 data set, yielding 134.6 and 131.4 CIDEr-D on the Karpathy test split in the ensemble and single model configuration respectively and 130 CIDEr-D in the official online testing server, despite being neither recurrent nor fully attentive. At the same time we address the efficiency aspect in our design and introduce a convenient training strategy suitable for most computational resources in contrast to the standard one. Source code is available at https://github.com/jchenghu/ExpansionNet
Speaker Diarization and Identification from Single-Channel Classroom Audio Recording Using Virtual Microphones
Jul 01, 2022
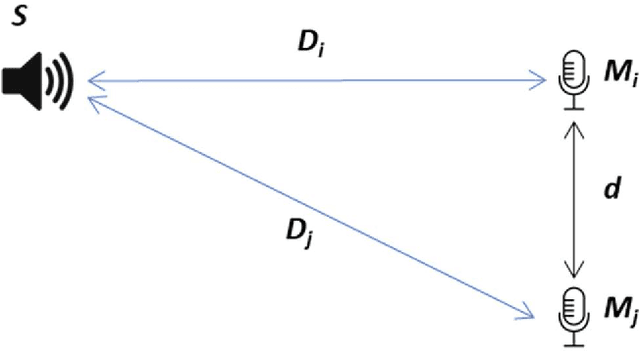
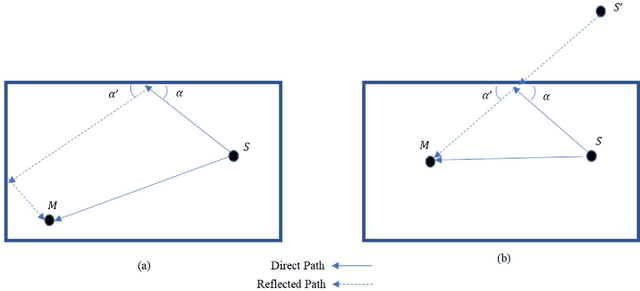
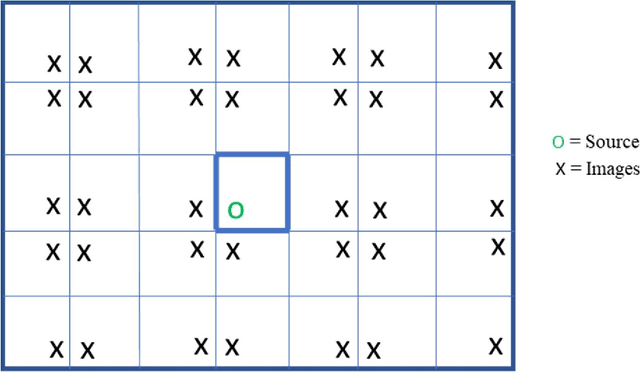
Speaker identification in noisy audio recordings, specifically those from collaborative learning environments, can be extremely challenging. There is a need to identify individual students talking in small groups from other students talking at the same time. To solve the problem, we assume the use of a single microphone per student group without any access to previous large datasets for training. This dissertation proposes a method of speaker identification using cross-correlation patterns associated to an array of virtual microphones, centered around the physical microphone. The virtual microphones are simulated by using approximate speaker geometry observed from a video recording. The patterns are constructed based on estimates of the room impulse responses for each virtual microphone. The correlation patterns are then used to identify the speakers. The proposed method is validated with classroom audios and shown to substantially outperform diarization services provided by Google Cloud and Amazon AWS.
AoA Estimation for OAM Communication Systems With Mode-Frequency Multi-Time ESPRIT Method
Oct 18, 2021
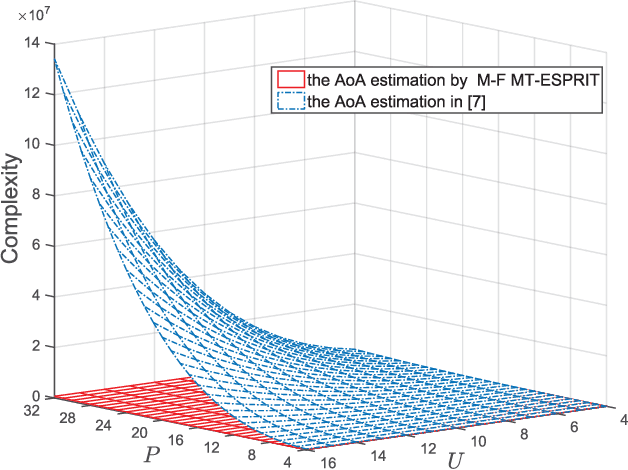
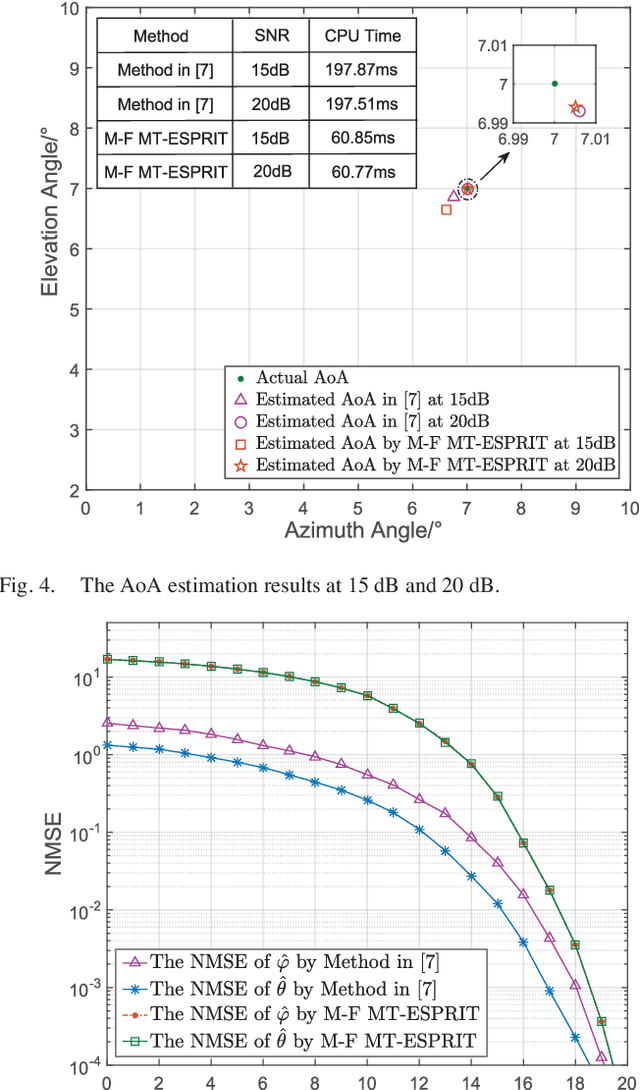
Radio orbital angular momentum (OAM) communications require accurate alignment between the transmit and receive beam directions. Accordingly, a key feature of OAM receivers is the ability to reliably estimate the angle of arrival (AoA) of multi-mode OAM beams. Considering the limitations of existing AoA estimation techniques, in this paper, we propose an easier-to-implement AoA estimation method based on applying multiple times the estimating signal parameters via rotational invariance techniques (ESPRIT) algorithm to the received training signals in OAM mode and frequency domains, which is denoted as the mode-frequency (M-F) multi-time (MT)-ESPRIT algorithm. With this method, the misalignment error of real OAM channels can be greatly reduced and the performance approaches that of ideally aligned OAM channels.
A Convolutional Attention Based Deep Network Solution for UAV Network Attack Recognition over Fading Channels and Interference
Jul 16, 2022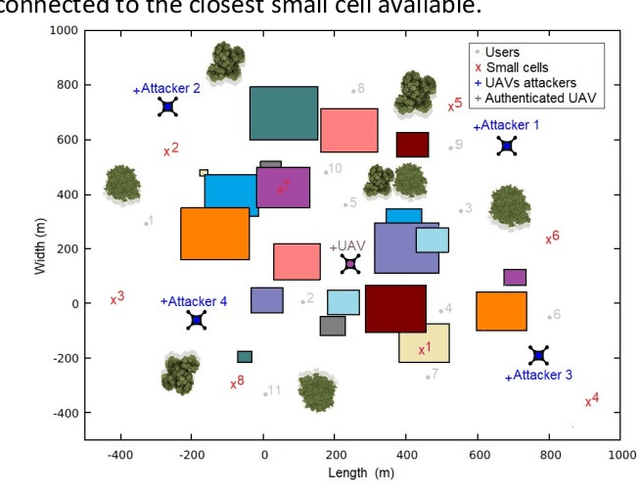
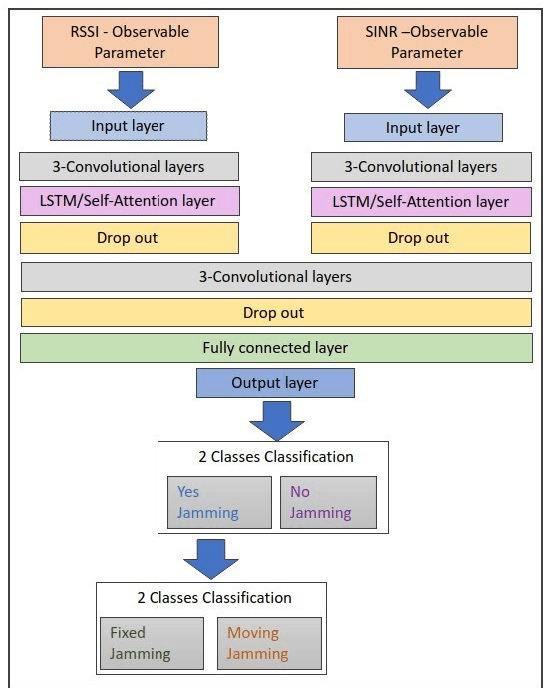

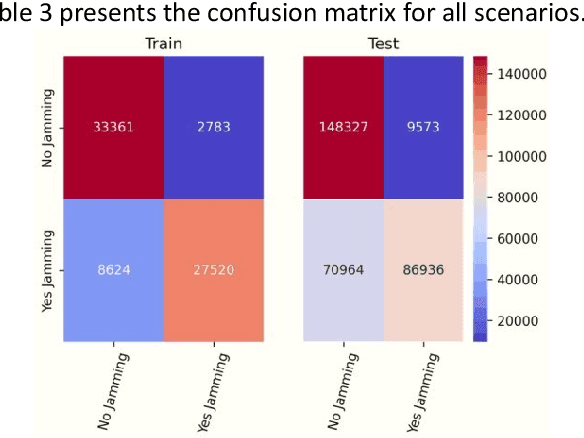
When users exchange data with Unmanned Aerial vehicles - (UAVs) over air-to-ground (A2G) wireless communication networks, they expose the link to attacks that could increase packet loss and might disrupt connectivity. For example, in emergency deliveries, losing control information (i.e data related to the UAV control communication) might result in accidents that cause UAV destruction and damage to buildings or other elements in a city. To prevent these problems, these issues must be addressed in 5G and 6G scenarios. This research offers a deep learning (DL) approach for detecting attacks in UAVs equipped with orthogonal frequency division multiplexing (OFDM) receivers on Clustered Delay Line (CDL) channels in highly complex scenarios involving authenticated terrestrial users, as well as attackers in unknown locations. We use the two observable parameters available in 5G UAV connections: the Received Signal Strength Indicator (RSSI) and the Signal to Interference plus Noise Ratio (SINR). The prospective algorithm is generalizable regarding attack identification, which does not occur during training. Further, it can identify all the attackers in the environment with 20 terrestrial users. A deeper investigation into the timing requirements for recognizing attacks show that after training, the minimum time necessary after the attack begins is 100 ms, and the minimum attack power is 2 dBm, which is the same power that the authenticated UAV uses. Our algorithm also detects moving attackers from a distance of 500 m.
An Exploration of How Training Set Composition Bias in Machine Learning Affects Identifying Rare Objects
Jul 07, 2022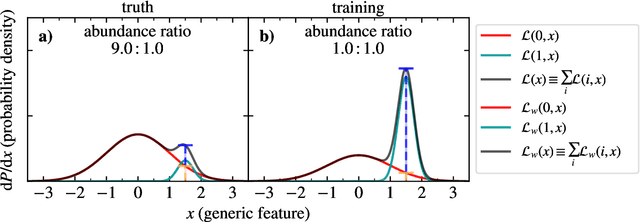
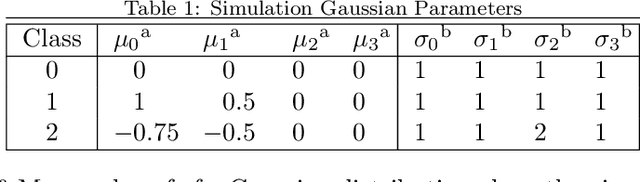
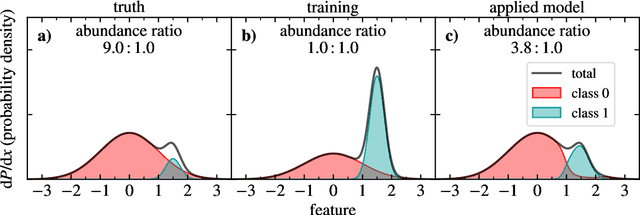
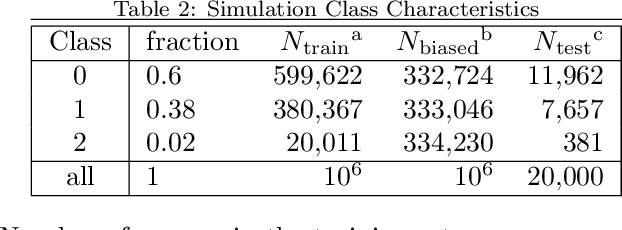
When training a machine learning classifier on data where one of the classes is intrinsically rare, the classifier will often assign too few sources to the rare class. To address this, it is common to up-weight the examples of the rare class to ensure it isn't ignored. It is also a frequent practice to train on restricted data where the balance of source types is closer to equal for the same reason. Here we show that these practices can bias the model toward over-assigning sources to the rare class. We also explore how to detect when training data bias has had a statistically significant impact on the trained model's predictions, and how to reduce the bias's impact. While the magnitude of the impact of the techniques developed here will vary with the details of the application, for most cases it should be modest. They are, however, universally applicable to every time a machine learning classification model is used, making them analogous to Bessel's correction to the sample variance.
Forecasting COVID-19 Caseloads Using Unsupervised Embedding Clusters of Social Media Posts
May 20, 2022
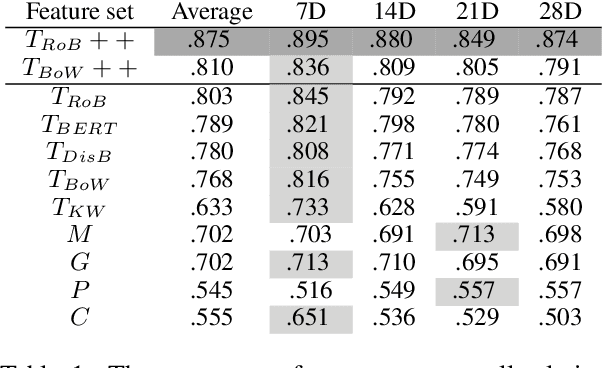
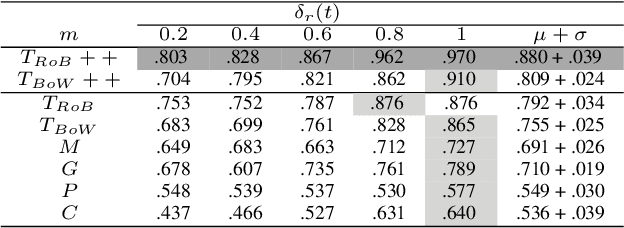
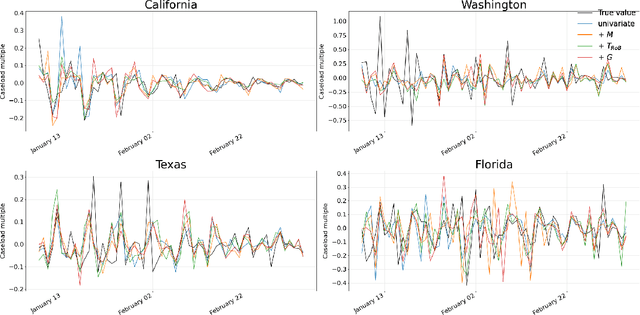
We present a novel approach incorporating transformer-based language models into infectious disease modelling. Text-derived features are quantified by tracking high-density clusters of sentence-level representations of Reddit posts within specific US states' COVID-19 subreddits. We benchmark these clustered embedding features against features extracted from other high-quality datasets. In a threshold-classification task, we show that they outperform all other feature types at predicting upward trend signals, a significant result for infectious disease modelling in areas where epidemiological data is unreliable. Subsequently, in a time-series forecasting task we fully utilise the predictive power of the caseload and compare the relative strengths of using different supplementary datasets as covariate feature sets in a transformer-based time-series model.
Not All Models Are Equal: Predicting Model Transferability in a Self-challenging Fisher Space
Jul 19, 2022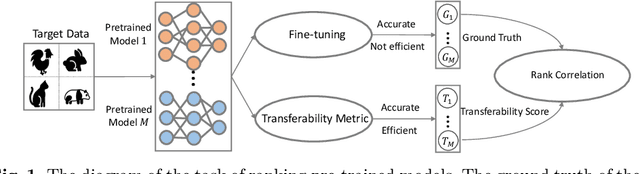
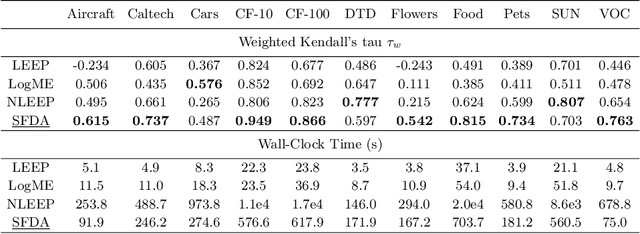
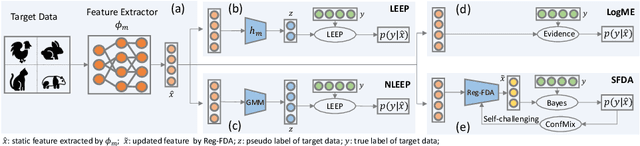
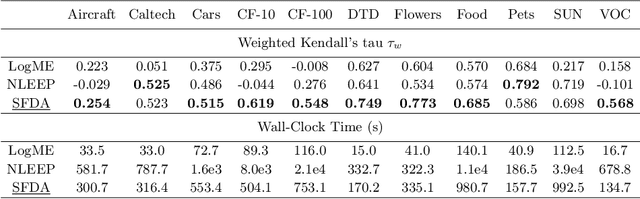
This paper addresses an important problem of ranking the pre-trained deep neural networks and screening the most transferable ones for downstream tasks. It is challenging because the ground-truth model ranking for each task can only be generated by fine-tuning the pre-trained models on the target dataset, which is brute-force and computationally expensive. Recent advanced methods proposed several lightweight transferability metrics to predict the fine-tuning results. However, these approaches only capture static representations but neglect the fine-tuning dynamics. To this end, this paper proposes a new transferability metric, called \textbf{S}elf-challenging \textbf{F}isher \textbf{D}iscriminant \textbf{A}nalysis (\textbf{SFDA}), which has many appealing benefits that existing works do not have. First, SFDA can embed the static features into a Fisher space and refine them for better separability between classes. Second, SFDA uses a self-challenging mechanism to encourage different pre-trained models to differentiate on hard examples. Third, SFDA can easily select multiple pre-trained models for the model ensemble. Extensive experiments on $33$ pre-trained models of $11$ downstream tasks show that SFDA is efficient, effective, and robust when measuring the transferability of pre-trained models. For instance, compared with the state-of-the-art method NLEEP, SFDA demonstrates an average of $59.1$\% gain while bringing $22.5$x speedup in wall-clock time. The code will be available at \url{https://github.com/TencentARC/SFDA}.
FastHebb: Scaling Hebbian Training of Deep Neural Networks to ImageNet Level
Jul 07, 2022
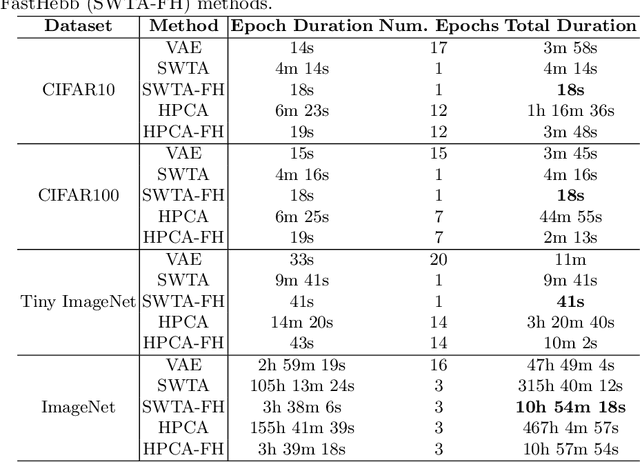
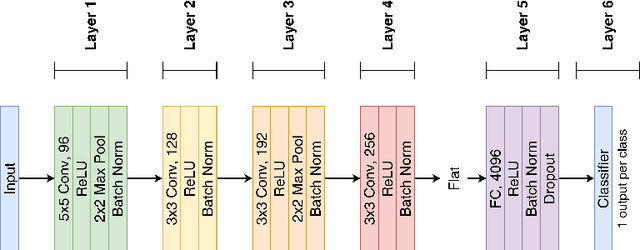

Learning algorithms for Deep Neural Networks are typically based on supervised end-to-end Stochastic Gradient Descent (SGD) training with error backpropagation (backprop). Backprop algorithms require a large number of labelled training samples to achieve high performance. However, in many realistic applications, even if there is plenty of image samples, very few of them are labelled, and semi-supervised sample-efficient training strategies have to be used. Hebbian learning represents a possible approach towards sample efficient training; however, in current solutions, it does not scale well to large datasets. In this paper, we present FastHebb, an efficient and scalable solution for Hebbian learning which achieves higher efficiency by 1) merging together update computation and aggregation over a batch of inputs, and 2) leveraging efficient matrix multiplication algorithms on GPU. We validate our approach on different computer vision benchmarks, in a semi-supervised learning scenario. FastHebb outperforms previous solutions by up to 50 times in terms of training speed, and notably, for the first time, we are able to bring Hebbian algorithms to ImageNet scale.