 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Learning-based Damage Mapping with InSAR Coherence Time Series
May 24, 2021
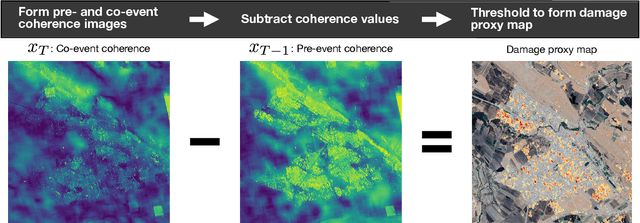
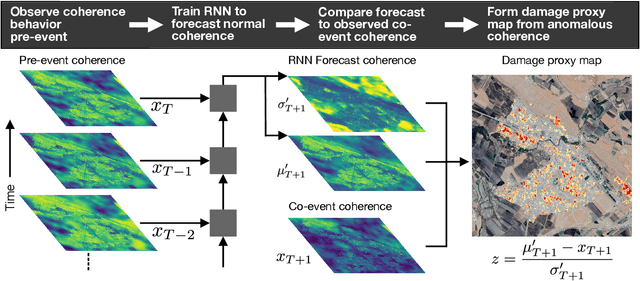
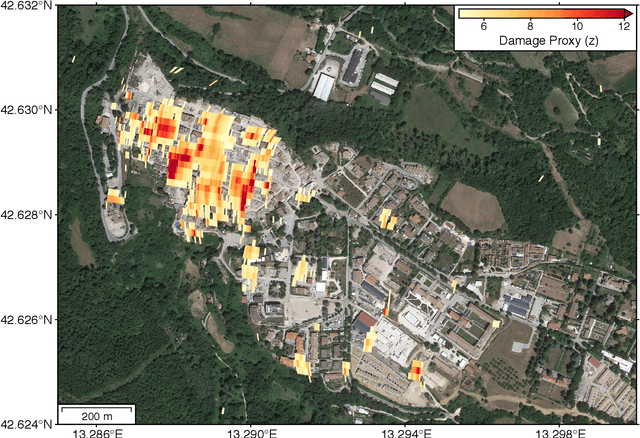
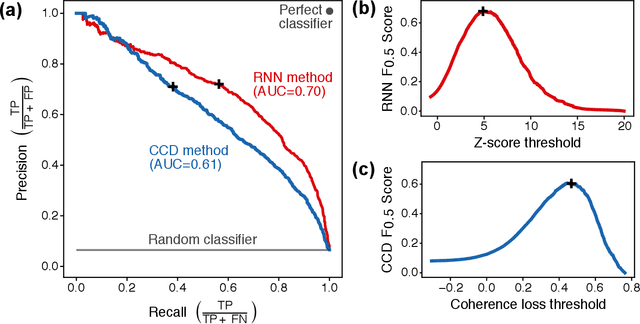
Satellite remote sensing is playing an increasing role in the rapid mapping of damage after natural disasters. In particular, synthetic aperture radar (SAR) can image the Earth's surface and map damage in all weather conditions, day and night. However, current SAR damage mapping methods struggle to separate damage from other changes in the Earth's surface. In this study, we propose a novel approach to damage mapping, combining deep learning with the full time history of SAR observations of an impacted region in order to detect anomalous variations in the Earth's surface properties due to a natural disaster. We quantify Earth surface change using time series of Interferometric SAR coherence, then use a recurrent neural network (RNN) as a probabilistic anomaly detector on these coherence time series. The RNN is first trained on pre-event coherence time series, and then forecasts a probability distribution of the coherence between pre- and post-event SAR images. The difference between the forecast and observed co-event coherence provides a measure of the confidence in the identification of damage. The method allows the user to choose a damage detection threshold that is customized for each location, based on the local behavior of coherence through time before the event. We apply this method to calculate estimates of damage for three earthquakes using multi-year time series of Sentinel-1 SAR acquisitions. Our approach shows good agreement with observed damage and quantitative improvement compared to using pre- to co-event coherence loss as a damage proxy.
Scalable Vehicle Re-Identification via Self-Supervision
May 16, 2022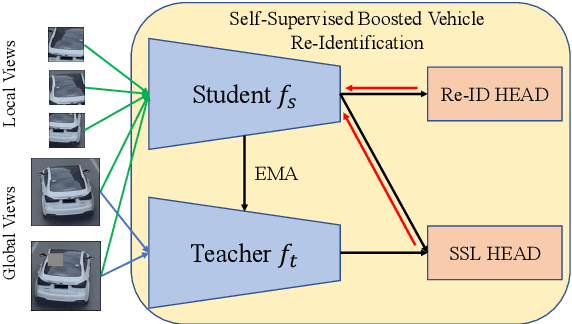
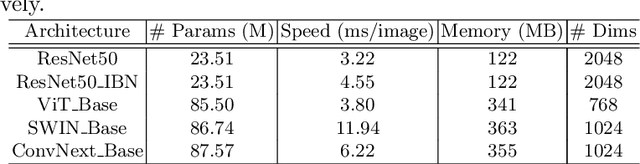
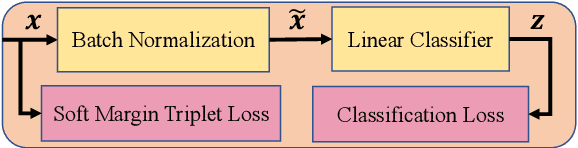
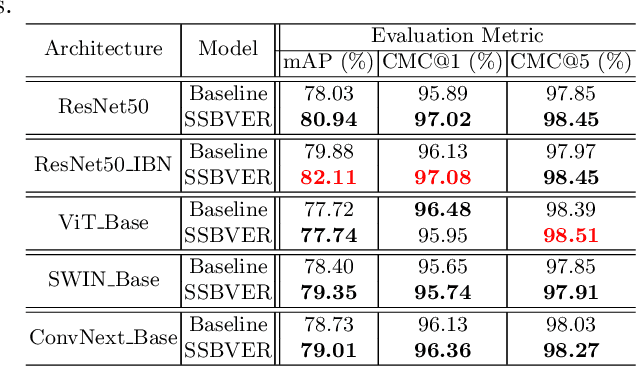
As Computer Vision technologies become more mature for intelligent transportation applications, it is time to ask how efficient and scalable they are for large-scale and real-time deployment. Among these technologies is Vehicle Re-Identification which is one of the key elements in city-scale vehicle analytics systems. Many state-of-the-art solutions for vehicle re-id mostly focus on improving the accuracy on existing re-id benchmarks and often ignore computational complexity. To balance the demands of accuracy and computational efficiency, in this work we propose a simple yet effective hybrid solution empowered by self-supervised training which only uses a single network during inference time and is free of intricate and computation-demanding add-on modules often seen in state-of-the-art approaches. Through extensive experiments, we show our approach, termed Self-Supervised and Boosted VEhicle Re-Identification (SSBVER), is on par with state-of-the-art alternatives in terms of accuracy without introducing any additional overhead during deployment. Additionally we show that our approach, generalizes to different backbone architectures which facilitates various resource constraints and consistently results in a significant accuracy boost.
Problem Decomposition and Multi-shot ASP Solving for Job-shop Scheduling
May 16, 2022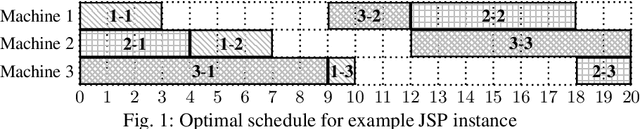
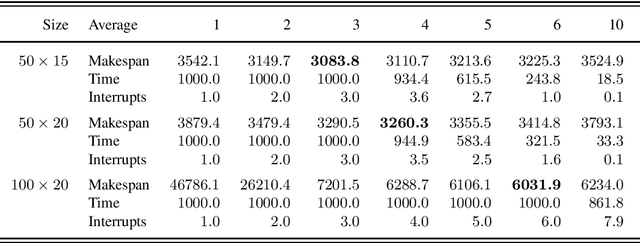

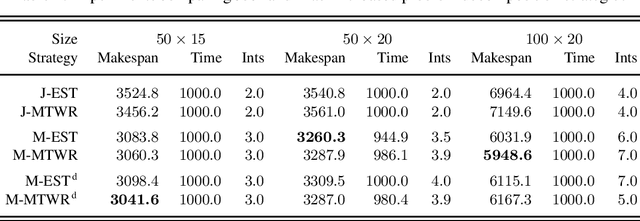
The Job-shop Scheduling Problem (JSP) is a well-known and challenging combinatorial optimization problem in which tasks sharing a machine are to be arranged in a sequence such that encompassing jobs can be completed as early as possible. In this paper, we propose problem decomposition into time windows whose operations can be successively scheduled and optimized by means of multi-shot Answer Set Programming (ASP) solving. Decomposition aims to split highly complex scheduling tasks into better manageable sub-problems with a balanced number of operations so that good quality or even optimal partial solutions can be reliably found in a small fraction of runtime. Problem decomposition must respect the precedence of operations within their jobs and partial schedules optimized by time windows should yield better global solutions than obtainable in similar runtime on the entire instance. We devise and investigate a variety of decomposition strategies in terms of the number and size of time windows as well as heuristics for choosing their operations. Moreover, we incorporate time window overlapping and compression techniques into the iterative scheduling process to counteract window-wise optimization limitations restricted to partial schedules. Our experiments on JSP benchmark sets of several sizes show that successive optimization by multi-shot ASP solving leads to substantially better schedules within the runtime limit than global optimization on the full problem, where the gap increases with the number of operations to schedule. While the obtained solution quality still remains behind a state-of-the-art Constraint Programming system, our multi-shot solving approach comes closer the larger the instance size, demonstrating good scalability by problem decomposition.
Efficient Augmentation for Imbalanced Deep Learning
Jul 13, 2022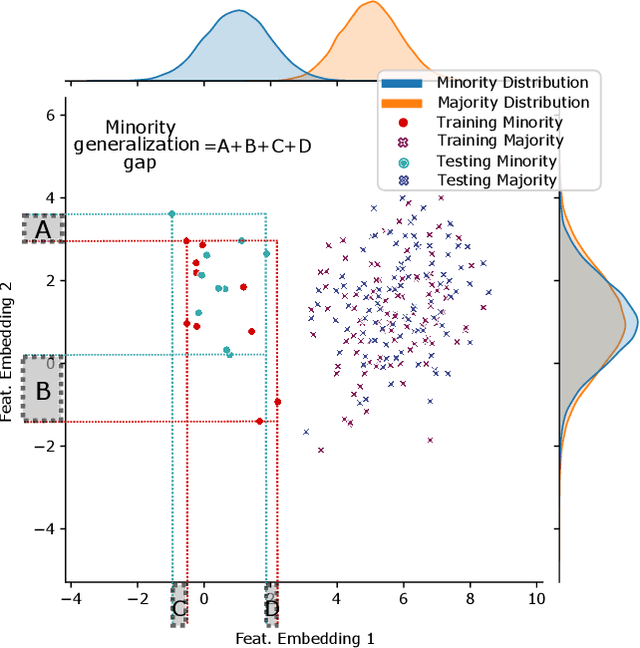
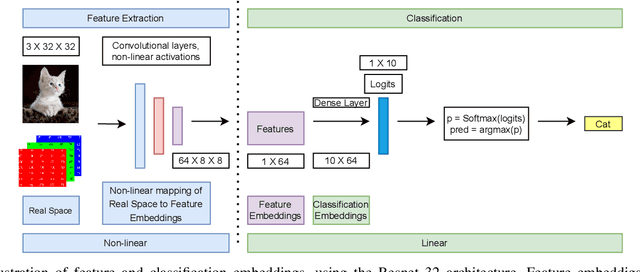
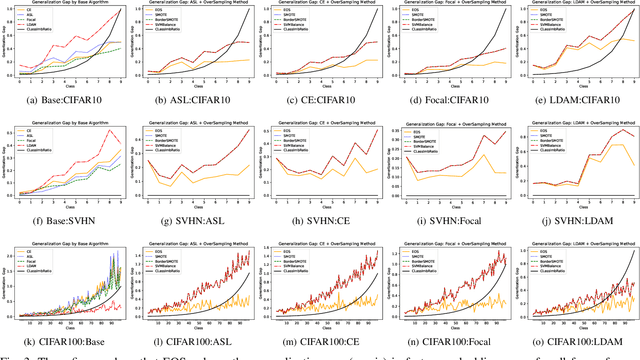
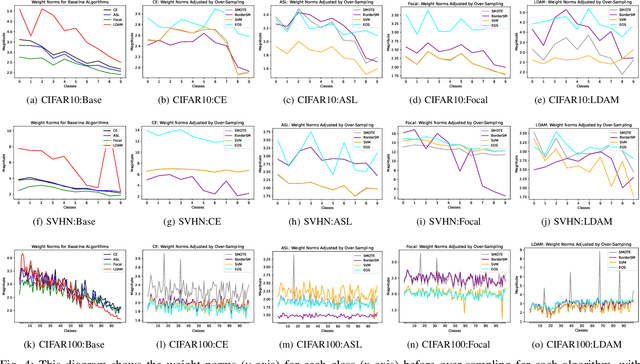
Deep learning models memorize training data, which hurts their ability to generalize to under-represented classes. We empirically study a convolutional neural network's internal representation of imbalanced image data and measure the generalization gap between a model's feature embeddings in the training and test sets, showing that the gap is wider for minority classes. This insight enables us to design an efficient three-phase CNN training framework for imbalanced data. The framework involves training the network end-to-end on imbalanced data to learn accurate feature embeddings, performing data augmentation in the learned embedded space to balance the train distribution, and fine-tuning the classifier head on the embedded balanced training data. We propose Expansive Over-Sampling (EOS) as a data augmentation technique to utilize in the training framework. EOS forms synthetic training instances as convex combinations between the minority class samples and their nearest enemies in the embedded space to reduce the generalization gap. The proposed framework improves the accuracy over leading cost-sensitive and resampling methods commonly used in imbalanced learning. Moreover, it is more computationally efficient than standard data pre-processing methods, such as SMOTE and GAN-based oversampling, as it requires fewer parameters and less training time.
Efficient Decoder-free Object Detection with Transformers
Jun 17, 2022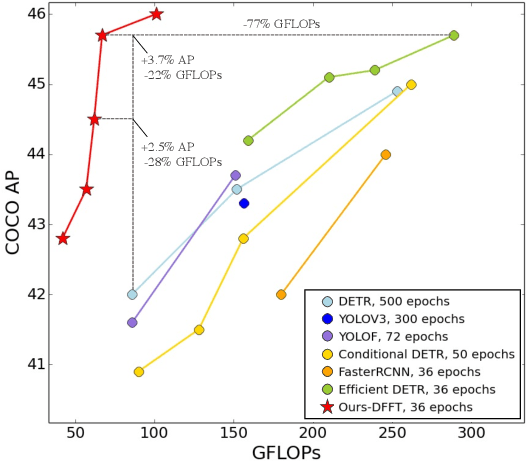
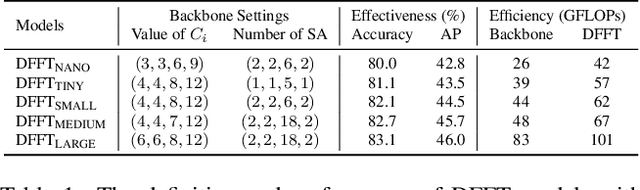
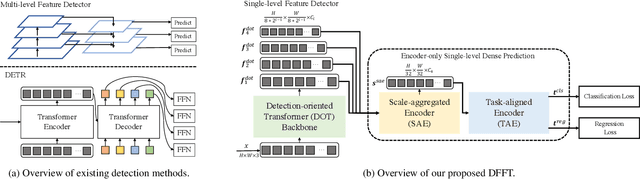
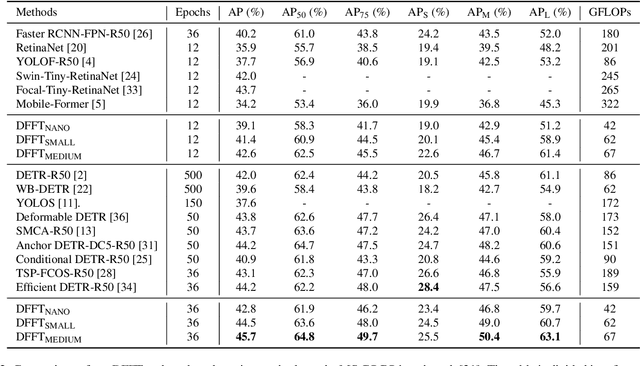
Vision transformers (ViTs) are changing the landscape of object detection approaches. A natural usage of ViTs in detection is to replace the CNN-based backbone with a transformer-based backbone, which is straightforward and effective, with the price of bringing considerable computation burden for inference. More subtle usage is the DETR family, which eliminates the need for many hand-designed components in object detection but introduces a decoder demanding an extra-long time to converge. As a result, transformer-based object detection can not prevail in large-scale applications. To overcome these issues, we propose a novel decoder-free fully transformer-based (DFFT) object detector, achieving high efficiency in both training and inference stages, for the first time. We simplify objection detection into an encoder-only single-level anchor-based dense prediction problem by centering around two entry points: 1) Eliminate the training-inefficient decoder and leverage two strong encoders to preserve the accuracy of single-level feature map prediction; 2) Explore low-level semantic features for the detection task with limited computational resources. In particular, we design a novel lightweight detection-oriented transformer backbone that efficiently captures low-level features with rich semantics based on a well-conceived ablation study. Extensive experiments on the MS COCO benchmark demonstrate that DFFT_SMALL outperforms DETR by 2.5% AP with 28% computation cost reduction and more than $10$x fewer training epochs. Compared with the cutting-edge anchor-based detector RetinaNet, DFFT_SMALL obtains over 5.5% AP gain while cutting down 70% computation cost.
Structure learning in polynomial time: Greedy algorithms, Bregman information, and exponential families
Oct 28, 2021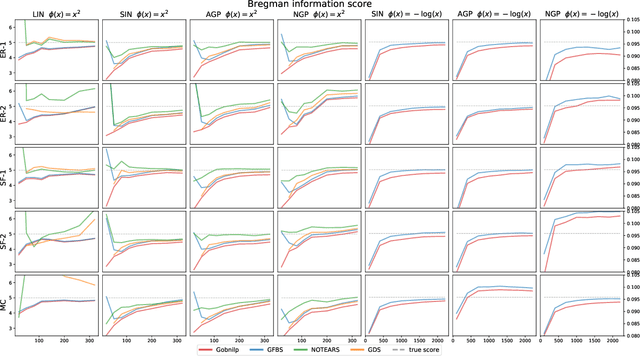
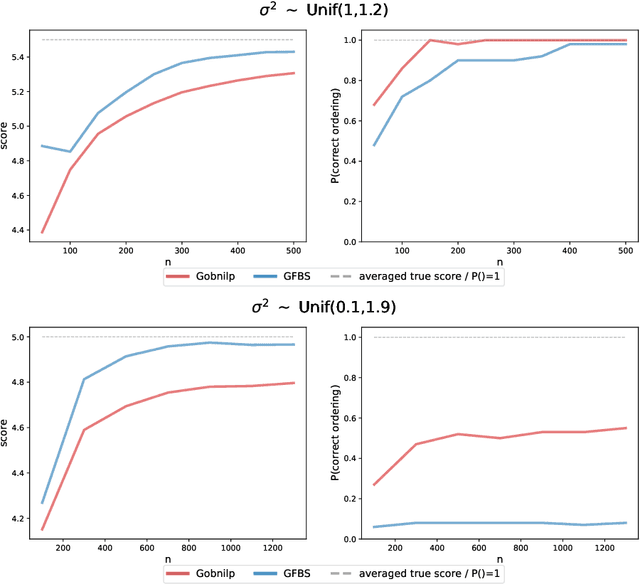
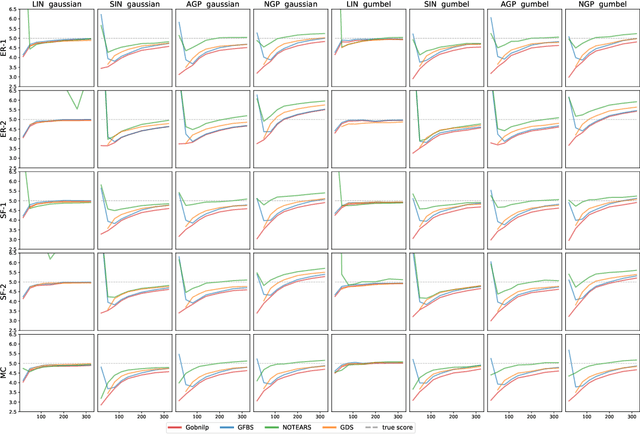
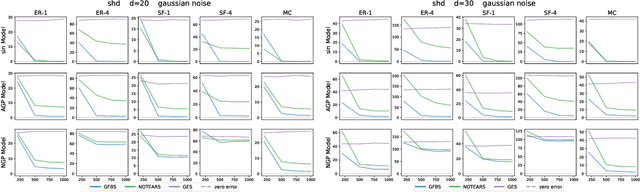
Greedy algorithms have long been a workhorse for learning graphical models, and more broadly for learning statistical models with sparse structure. In the context of learning directed acyclic graphs, greedy algorithms are popular despite their worst-case exponential runtime. In practice, however, they are very efficient. We provide new insight into this phenomenon by studying a general greedy score-based algorithm for learning DAGs. Unlike edge-greedy algorithms such as the popular GES and hill-climbing algorithms, our approach is vertex-greedy and requires at most a polynomial number of score evaluations. We then show how recent polynomial-time algorithms for learning DAG models are a special case of this algorithm, thereby illustrating how these order-based algorithms can be rigourously interpreted as score-based algorithms. This observation suggests new score functions and optimality conditions based on the duality between Bregman divergences and exponential families, which we explore in detail. Explicit sample and computational complexity bounds are derived. Finally, we provide extensive experiments suggesting that this algorithm indeed optimizes the score in a variety of settings.
ICE-NODE: Integration of Clinical Embeddings with Neural Ordinary Differential Equations
Jul 06, 2022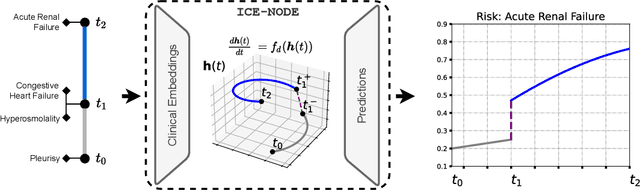
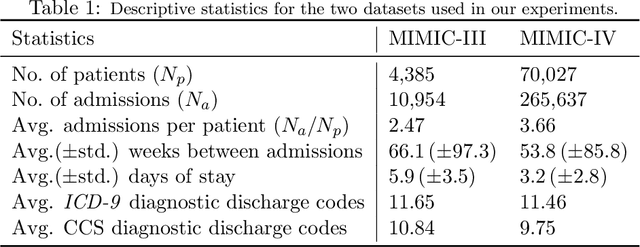
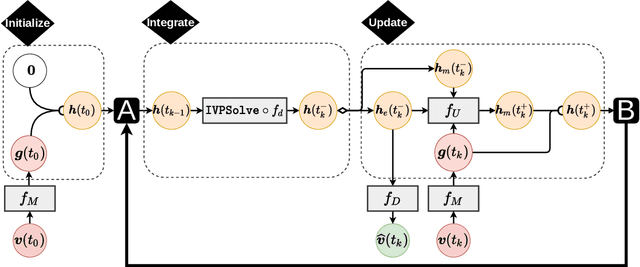
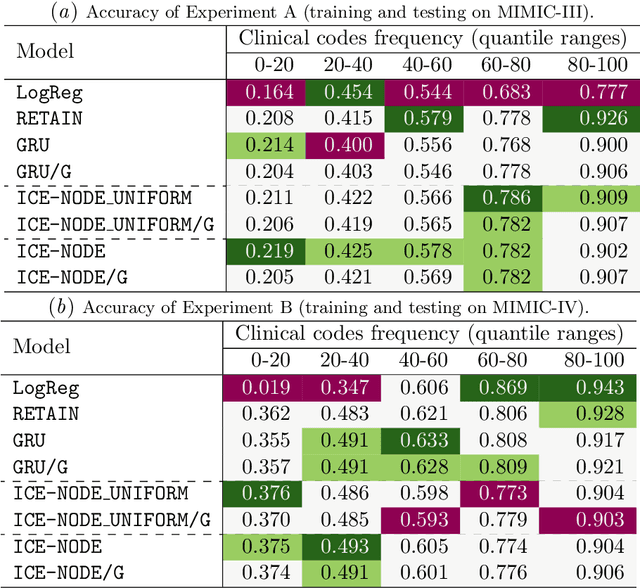
Early diagnosis of disease can result in improved health outcomes, such as higher survival rates and lower treatment costs. With the massive amount of information in electronic health records (EHRs), there is great potential to use machine learning (ML) methods to model disease progression aimed at early prediction of disease onset and other outcomes. In this work, we employ recent innovations in neural ODEs to harness the full temporal information of EHRs. We propose ICE-NODE (Integration of Clinical Embeddings with Neural Ordinary Differential Equations), an architecture that temporally integrates embeddings of clinical codes and neural ODEs to learn and predict patient trajectories in EHRs. We apply our method to the publicly available MIMIC-III and MIMIC-IV datasets, reporting improved prediction results compared to state-of-the-art methods, specifically for clinical codes that are not frequently observed in EHRs. We also show that ICE-NODE is more competent at predicting certain medical conditions, like acute renal failure and pulmonary heart disease, and is also able to produce patient risk trajectories over time that can be exploited for further predictions.
Position-enhanced and Time-aware Graph Convolutional Network for Sequential Recommendations
Jul 12, 2021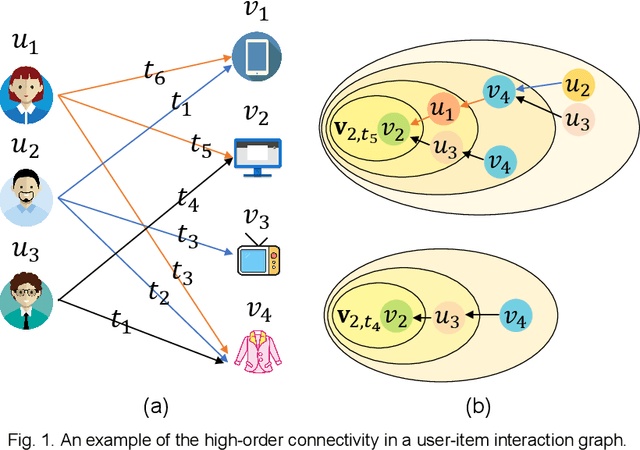

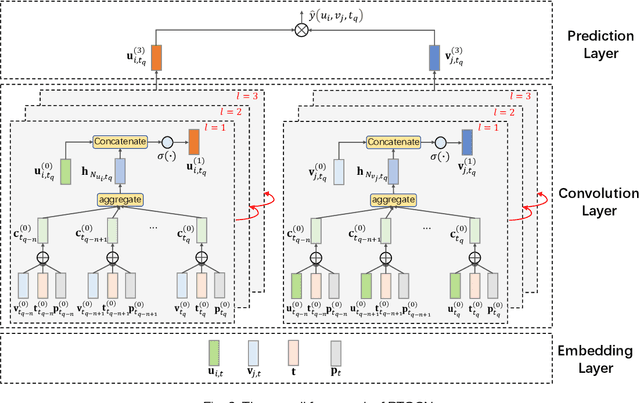

Most of the existing deep learning-based sequential recommendation approaches utilize the recurrent neural network architecture or self-attention to model the sequential patterns and temporal influence among a user's historical behavior and learn the user's preference at a specific time. However, these methods have two main drawbacks. First, they focus on modeling users' dynamic states from a user-centric perspective and always neglect the dynamics of items over time. Second, most of them deal with only the first-order user-item interactions and do not consider the high-order connectivity between users and items, which has recently been proved helpful for the sequential recommendation. To address the above problems, in this article, we attempt to model user-item interactions by a bipartite graph structure and propose a new recommendation approach based on a Position-enhanced and Time-aware Graph Convolutional Network (PTGCN) for the sequential recommendation. PTGCN models the sequential patterns and temporal dynamics between user-item interactions by defining a position-enhanced and time-aware graph convolution operation and learning the dynamic representations of users and items simultaneously on the bipartite graph with a self-attention aggregator. Also, it realizes the high-order connectivity between users and items by stacking multi-layer graph convolutions. To demonstrate the effectiveness of PTGCN, we carried out a comprehensive evaluation of PTGCN on three real-world datasets of different sizes compared with a few competitive baselines. Experimental results indicate that PTGCN outperforms several state-of-the-art models in terms of two commonly-used evaluation metrics for ranking.
CHARM: A Hierarchical Deep Learning Model for Classification of Complex Human Activities Using Motion Sensors
Jul 16, 2022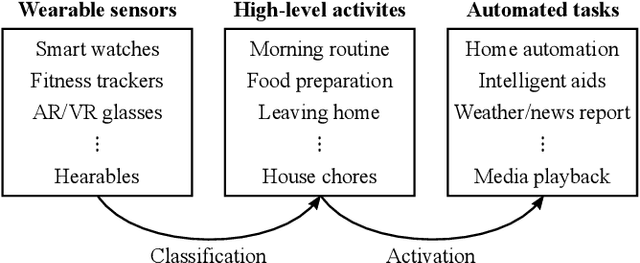
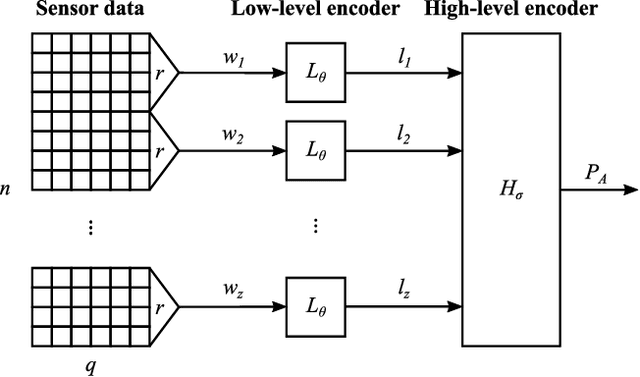
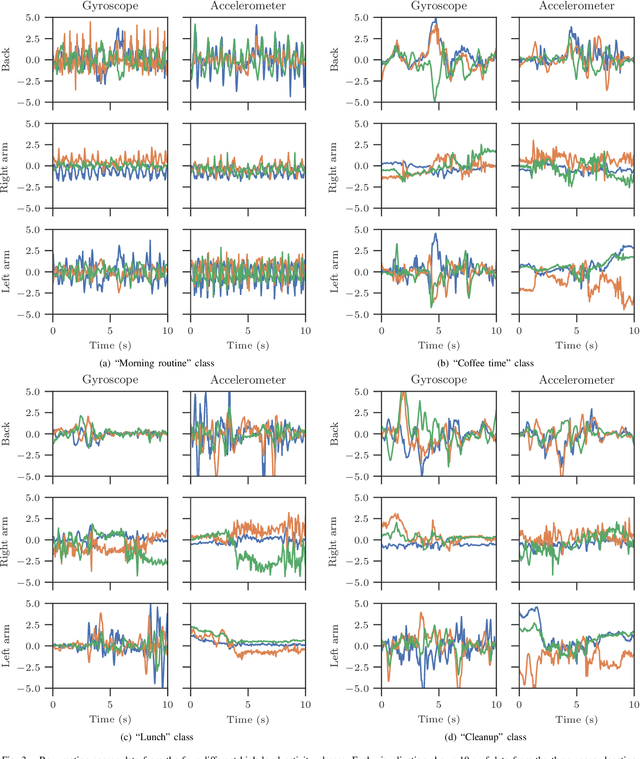
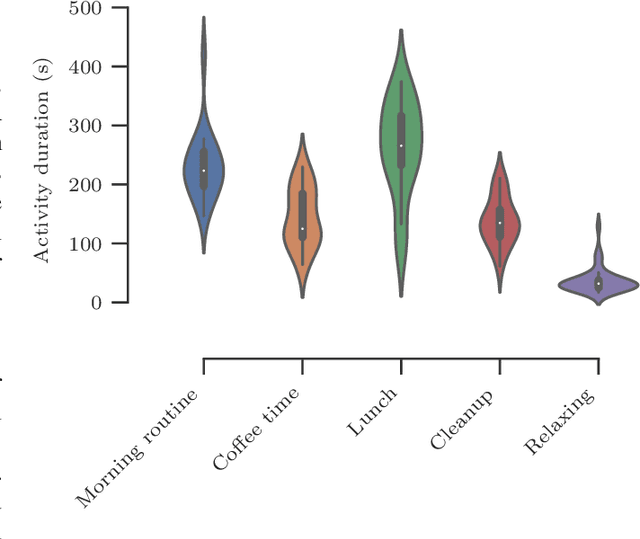
In this paper, we report a hierarchical deep learning model for classification of complex human activities using motion sensors. In contrast to traditional Human Activity Recognition (HAR) models used for event-based activity recognition, such as step counting, fall detection, and gesture identification, this new deep learning model, which we refer to as CHARM (Complex Human Activity Recognition Model), is aimed for recognition of high-level human activities that are composed of multiple different low-level activities in a non-deterministic sequence, such as meal preparation, house chores, and daily routines. CHARM not only quantitatively outperforms state-of-the-art supervised learning approaches for high-level activity recognition in terms of average accuracy and F1 scores, but also automatically learns to recognize low-level activities, such as manipulation gestures and locomotion modes, without any explicit labels for such activities. This opens new avenues for Human-Machine Interaction (HMI) modalities using wearable sensors, where the user can choose to associate an automated task with a high-level activity, such as controlling home automation (e.g., robotic vacuum cleaners, lights, and thermostats) or presenting contextually relevant information at the right time (e.g., reminders, status updates, and weather/news reports). In addition, the ability to learn low-level user activities when trained using only high-level activity labels may pave the way to semi-supervised learning of HAR tasks that are inherently difficult to label.
Forecasting COVID-19 Caseloads Using Unsupervised Embedding Clusters of Social Media Posts
May 20, 2022
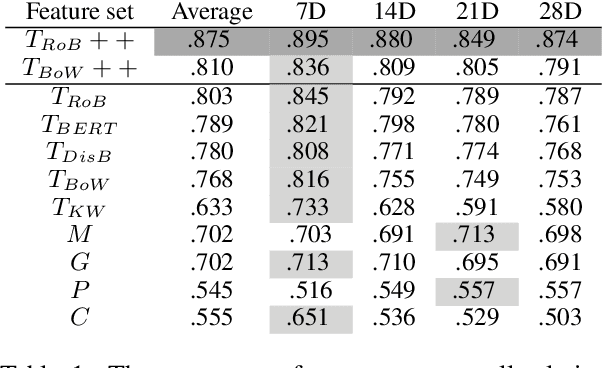
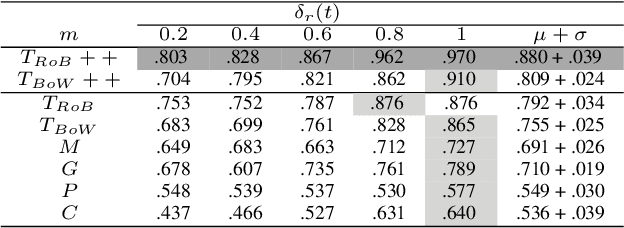
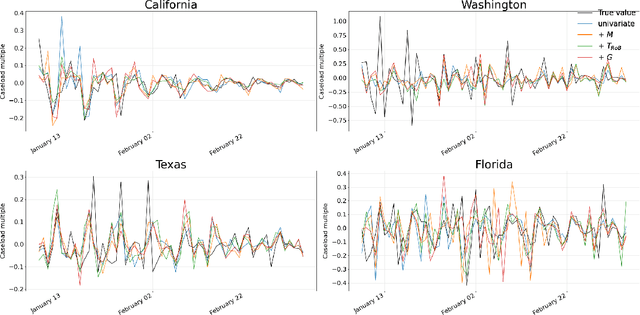
We present a novel approach incorporating transformer-based language models into infectious disease modelling. Text-derived features are quantified by tracking high-density clusters of sentence-level representations of Reddit posts within specific US states' COVID-19 subreddits. We benchmark these clustered embedding features against features extracted from other high-quality datasets. In a threshold-classification task, we show that they outperform all other feature types at predicting upward trend signals, a significant result for infectious disease modelling in areas where epidemiological data is unreliable. Subsequently, in a time-series forecasting task we fully utilise the predictive power of the caseload and compare the relative strengths of using different supplementary datasets as covariate feature sets in a transformer-based time-series model.