 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Unified Approach to Reinforcement Learning, Quantal Response Equilibria, and Two-Player Zero-Sum Games
Jun 12, 2022
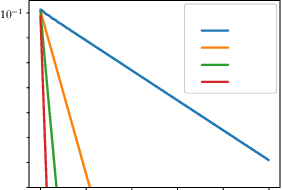
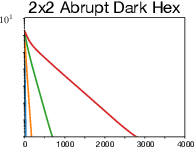

Algorithms designed for single-agent reinforcement learning (RL) generally fail to converge to equilibria in two-player zero-sum (2p0s) games. Conversely, game-theoretic algorithms for approximating Nash and quantal response equilibria (QREs) in 2p0s games are not typically competitive for RL and can be difficult to scale. As a result, algorithms for these two cases are generally developed and evaluated separately. In this work, we show that a single algorithm -- a simple extension to mirror descent with proximal regularization that we call magnetic mirror descent (MMD) -- can produce strong results in both settings, despite their fundamental differences. From a theoretical standpoint, we prove that MMD converges linearly to QREs in extensive-form games -- this is the first time linear convergence has been proven for a first order solver. Moreover, applied as a tabular Nash equilibrium solver via self-play, we show empirically that MMD produces results competitive with CFR in both normal-form and extensive-form games with full feedback (this is the first time that a standard RL algorithm has done so) and also that MMD empirically converges in black-box feedback settings. Furthermore, for single-agent deep RL, on a small collection of Atari and Mujoco games, we show that MMD can produce results competitive with those of PPO. Lastly, for multi-agent deep RL, we show MMD can outperform NFSP in 3x3 Abrupt Dark Hex.
Improving Task-free Continual Learning by Distributionally Robust Memory Evolution
Jul 15, 2022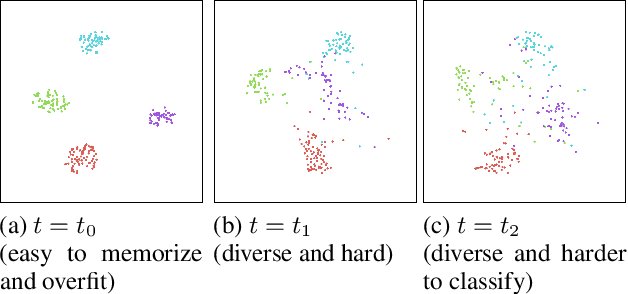
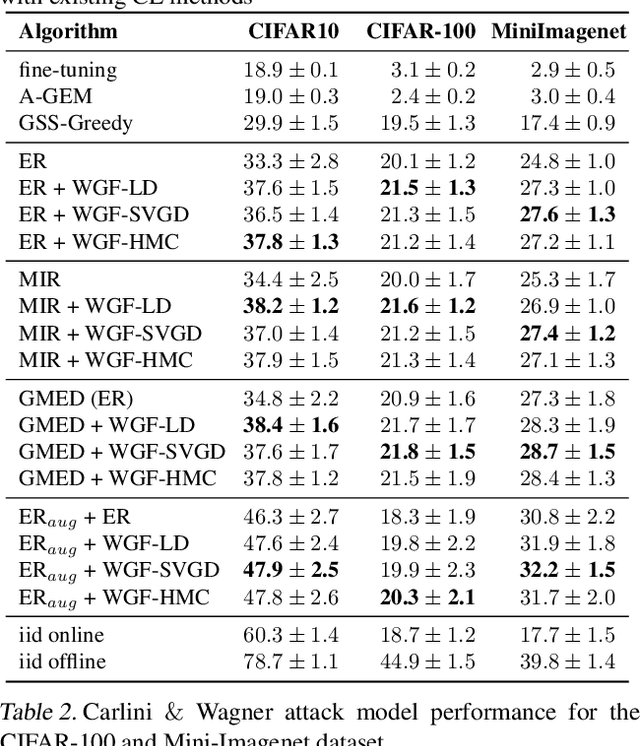
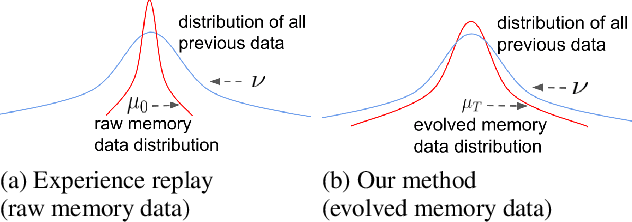
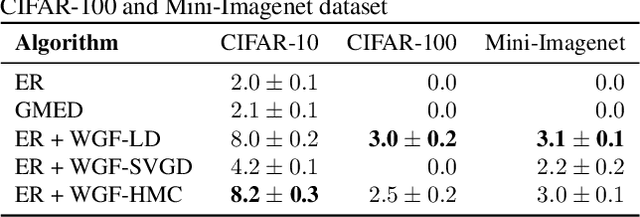
Task-free continual learning (CL) aims to learn a non-stationary data stream without explicit task definitions and not forget previous knowledge. The widely adopted memory replay approach could gradually become less effective for long data streams, as the model may memorize the stored examples and overfit the memory buffer. Second, existing methods overlook the high uncertainty in the memory data distribution since there is a big gap between the memory data distribution and the distribution of all the previous data examples. To address these problems, for the first time, we propose a principled memory evolution framework to dynamically evolve the memory data distribution by making the memory buffer gradually harder to be memorized with distributionally robust optimization (DRO). We then derive a family of methods to evolve the memory buffer data in the continuous probability measure space with Wasserstein gradient flow (WGF). The proposed DRO is w.r.t the worst-case evolved memory data distribution, thus guarantees the model performance and learns significantly more robust features than existing memory-replay-based methods. Extensive experiments on existing benchmarks demonstrate the effectiveness of the proposed methods for alleviating forgetting. As a by-product of the proposed framework, our method is more robust to adversarial examples than existing task-free CL methods.
Efficient Search of the k Shortest Non-Homotopic Paths by Eliminating Non-k-Optimal Topologies
Jul 27, 2022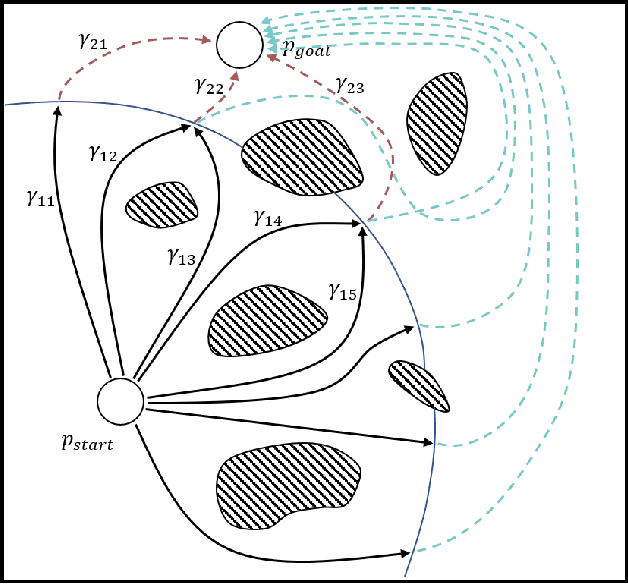
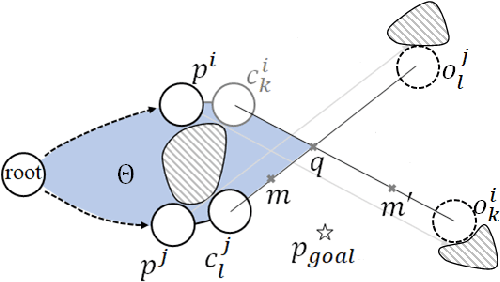
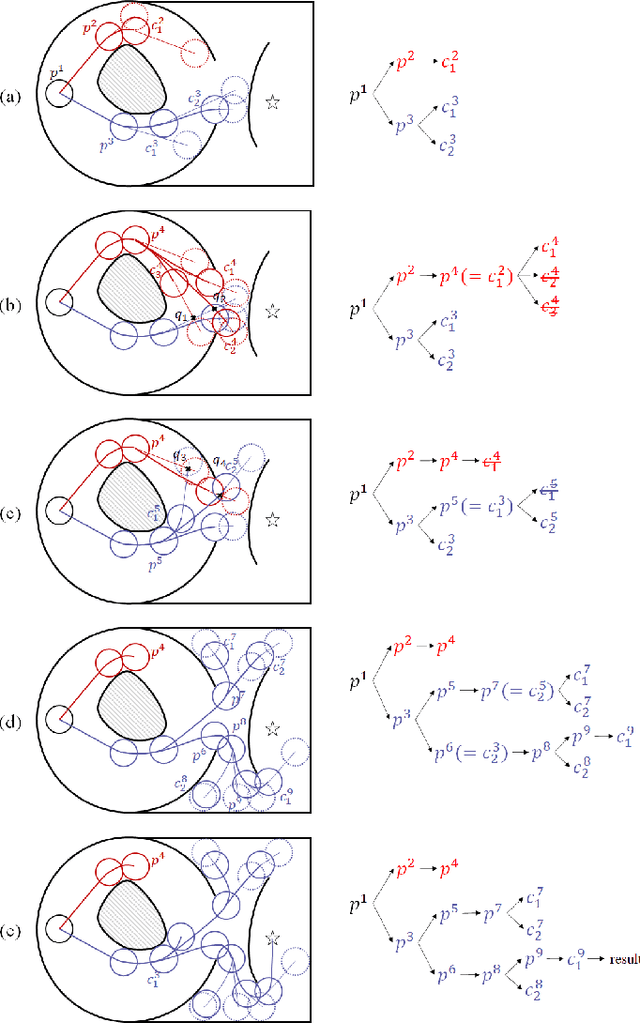
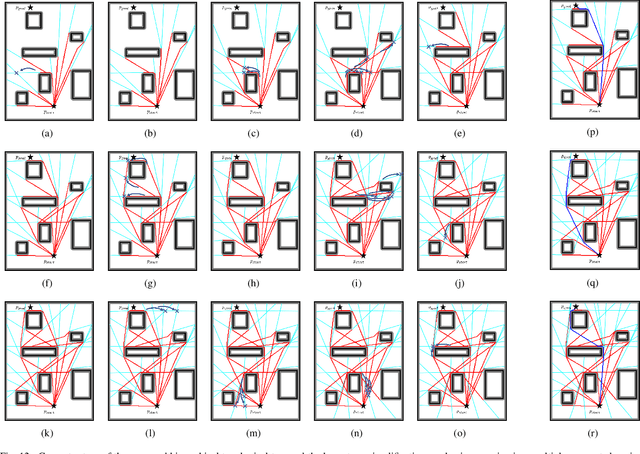
An efficient algorithm to solve the $k$ shortest non-homotopic path planning ($k$-SNPP) problem in a 2D environment is proposed in this paper. Motivated by accelerating the inefficient exploration of the homotopy-augmented space of the 2D environment, our fundamental idea is to identify the non-$k$-optimal path topologies as early as possible and terminate the pathfinding along them. This is a non-trivial practice because it has to be done at an intermediate state of the path planning process when locally shortest paths have not been fully constructed. In other words, the paths to be compared have not rendezvoused at the goal location, which makes the homotopy theory, modelling the spatial relationship among the paths having the same endpoint, not applicable. This paper is the first work that develops a systematic distance-based topology simplification mechanism to solve the $k$-SNPP task, whose core contribution is to assert the distance-based order of non-homotopic locally shortest paths before constructing them. If the order can be predicted, then those path topologies having more than $k$ better topologies are proven free of the desired $k$ paths and thus can be safely discarded during the path planning process. To this end, a hierarchical topological tree is proposed as an implementation of the mechanism, whose nodes are proven to expand in non-homotopic directions and edges (collision-free path segments) are proven locally shortest. With efficient criteria that observe the order relations between partly constructed locally shortest paths being imparted into the tree, the tree nodes that expand in non-$k$-optimal topologies will not be expanded. As a result, the computational time for solving the $k$-SNPP problem is reduced by near two orders of magnitude.
Online Self-Attentive Gated RNNs for Real-Time Speaker Separation
Jul 27, 2021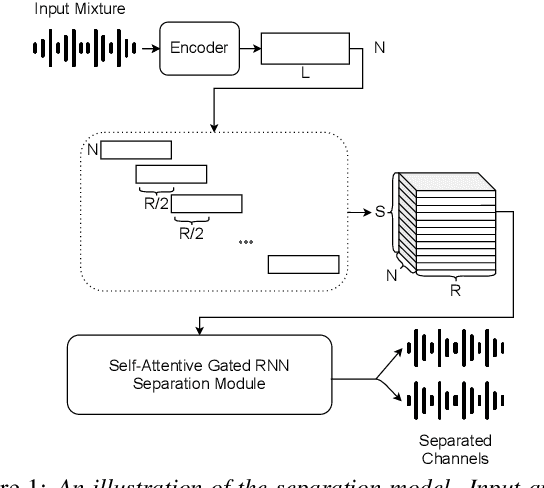
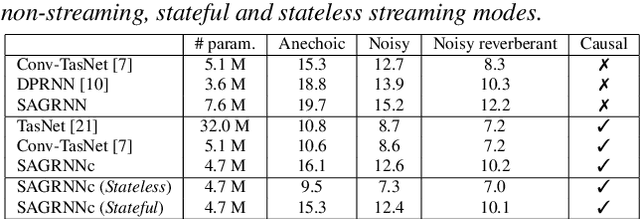
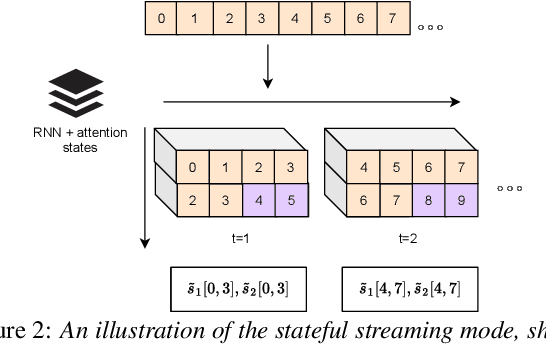

Deep neural networks have recently shown great success in the task of blind source separation, both under monaural and binaural settings. Although these methods were shown to produce high-quality separations, they were mainly applied under offline settings, in which the model has access to the full input signal while separating the signal. In this study, we convert a non-causal state-of-the-art separation model into a causal and real-time model and evaluate its performance under both online and offline settings. We compare the performance of the proposed model to several baseline methods under anechoic, noisy, and noisy-reverberant recording conditions while exploring both monaural and binaural inputs and outputs. Our findings shed light on the relative difference between causal and non-causal models when performing separation. Our stateful implementation for online separation leads to a minor drop in performance compared to the offline model; 0.8dB for monaural inputs and 0.3dB for binaural inputs while reaching a real-time factor of 0.65. Samples can be found under the following link: https://kwanum.github.io/sagrnnc-stream-results/.
Robot Vitals and Robot Health: Towards Systematically Quantifying Runtime Performance Degradation in Robots Under Adverse Conditions
Jul 04, 2022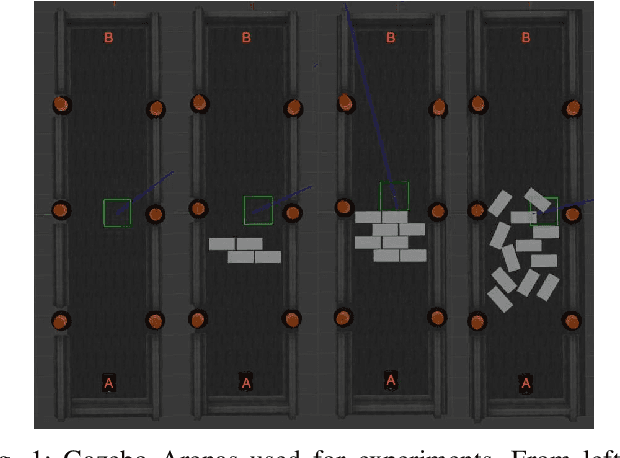
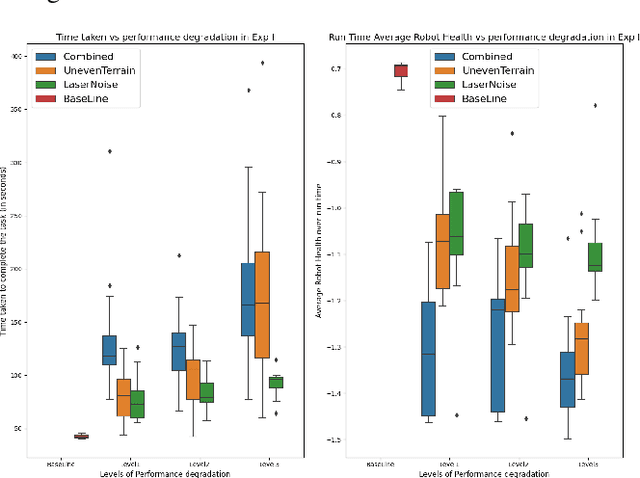

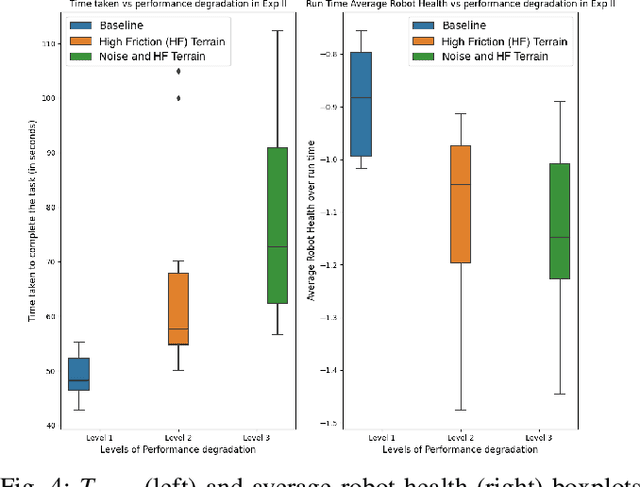
This paper addresses the problem of automatically detecting and quantifying performance degradation in remote mobile robots during task execution. A robot may encounter a variety of uncertainties and adversities during task execution, which can impair its ability to carry out tasks effectively and cause its performance to degrade. Such situations can be mitigated or averted by timely detection and intervention (e.g., by a remote human supervisor taking over control in teleoperation mode). Inspired by patient triaging systems in hospitals, we introduce the framework of "robot vitals" for estimating overall "robot health". A robot's vitals are a set of indicators that estimate the extent of performance degradation faced by a robot at a given point in time. Robot health is a metric that combines robot vitals into a single scalar value estimate of performance degradation. Experiments, both in simulation and on a real mobile robot, demonstrate that the proposed robot vitals and robot health can be used effectively to estimate robot performance degradation during runtime.
Probable Domain Generalization via Quantile Risk Minimization
Jul 20, 2022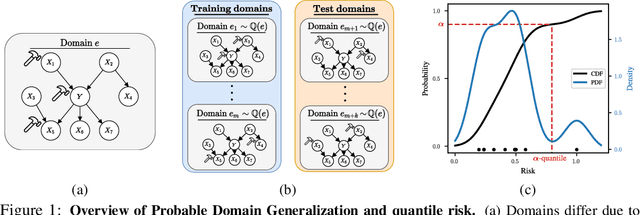
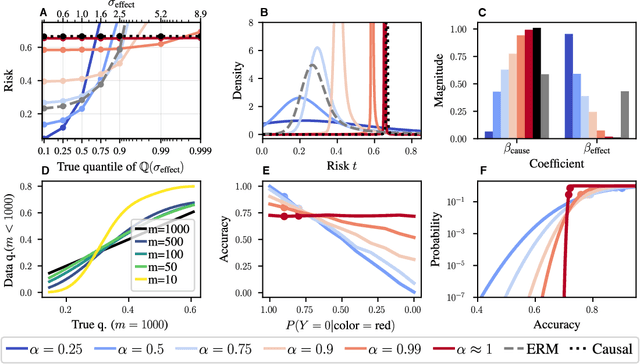
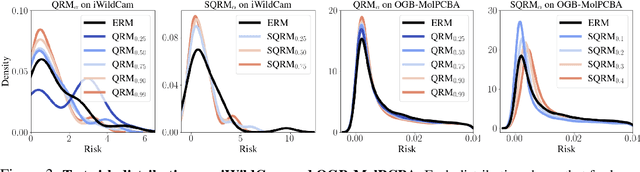
Domain generalization (DG) seeks predictors which perform well on unseen test distributions by leveraging labeled training data from multiple related distributions or domains. To achieve this, the standard formulation optimizes for worst-case performance over the set of all possible domains. However, with worst-case shifts very unlikely in practice, this generally leads to overly-conservative solutions. In fact, a recent study found that no DG algorithm outperformed empirical risk minimization in terms of average performance. In this work, we argue that DG is neither a worst-case problem nor an average-case problem, but rather a probabilistic one. To this end, we propose a probabilistic framework for DG, which we call Probable Domain Generalization, wherein our key idea is that distribution shifts seen during training should inform us of probable shifts at test time. To realize this, we explicitly relate training and test domains as draws from the same underlying meta-distribution, and propose a new optimization problem -- Quantile Risk Minimization (QRM) -- which requires that predictors generalize with high probability. We then prove that QRM: (i) produces predictors that generalize to new domains with a desired probability, given sufficiently many domains and samples; and (ii) recovers the causal predictor as the desired probability of generalization approaches one. In our experiments, we introduce a more holistic quantile-focused evaluation protocol for DG, and show that our algorithms outperform state-of-the-art baselines on real and synthetic data.
Entangled Residual Mappings
Jun 02, 2022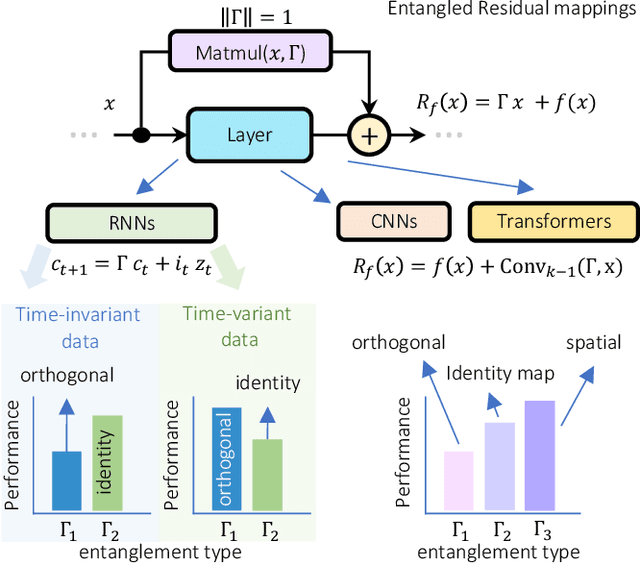
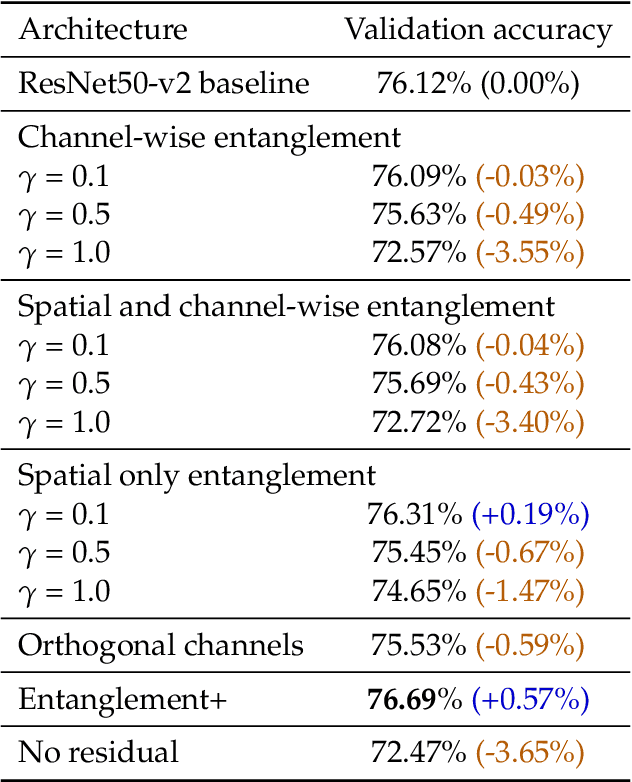
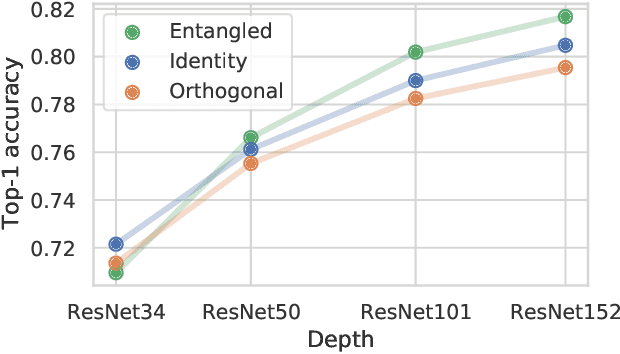
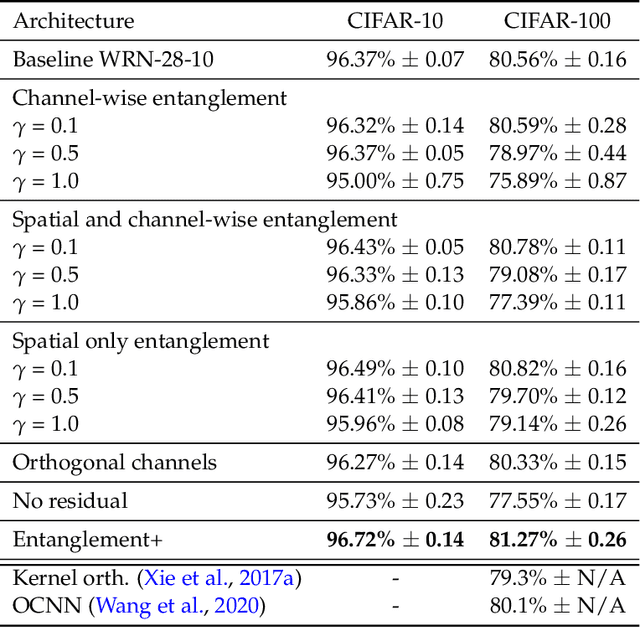
Residual mappings have been shown to perform representation learning in the first layers and iterative feature refinement in higher layers. This interplay, combined with their stabilizing effect on the gradient norms, enables them to train very deep networks. In this paper, we take a step further and introduce entangled residual mappings to generalize the structure of the residual connections and evaluate their role in iterative learning representations. An entangled residual mapping replaces the identity skip connections with specialized entangled mappings such as orthogonal, sparse, and structural correlation matrices that share key attributes (eigenvalues, structure, and Jacobian norm) with identity mappings. We show that while entangled mappings can preserve the iterative refinement of features across various deep models, they influence the representation learning process in convolutional networks differently than attention-based models and recurrent neural networks. In general, we find that for CNNs and Vision Transformers entangled sparse mapping can help generalization while orthogonal mappings hurt performance. For recurrent networks, orthogonal residual mappings form an inductive bias for time-variant sequences, which degrades accuracy on time-invariant tasks.
Bringing Image Scene Structure to Video via Frame-Clip Consistency of Object Tokens
Jun 15, 2022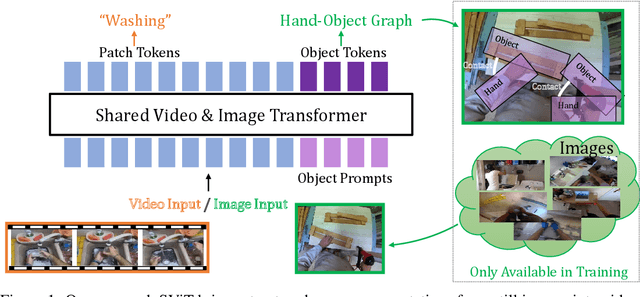
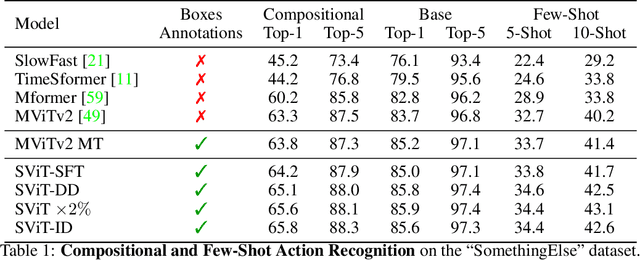
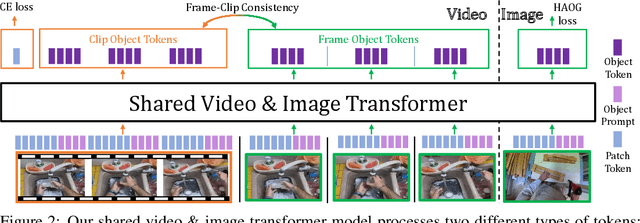
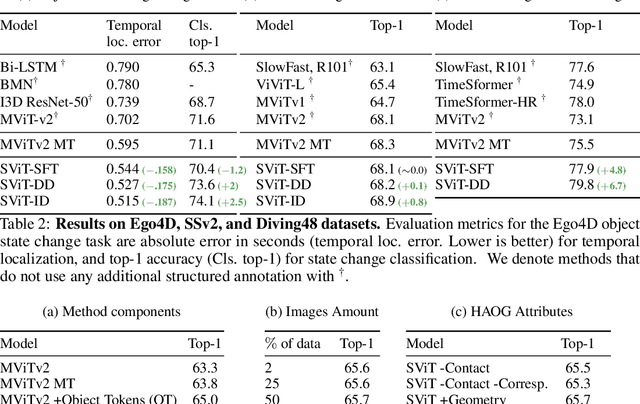
Recent action recognition models have achieved impressive results by integrating objects, their locations and interactions. However, obtaining dense structured annotations for each frame is tedious and time-consuming, making these methods expensive to train and less scalable. At the same time, if a small set of annotated images is available, either within or outside the domain of interest, how could we leverage these for a video downstream task? We propose a learning framework StructureViT (SViT for short), which demonstrates how utilizing the structure of a small number of images only available during training can improve a video model. SViT relies on two key insights. First, as both images and videos contain structured information, we enrich a transformer model with a set of \emph{object tokens} that can be used across images and videos. Second, the scene representations of individual frames in video should "align" with those of still images. This is achieved via a \emph{Frame-Clip Consistency} loss, which ensures the flow of structured information between images and videos. We explore a particular instantiation of scene structure, namely a \emph{Hand-Object Graph}, consisting of hands and objects with their locations as nodes, and physical relations of contact/no-contact as edges. SViT shows strong performance improvements on multiple video understanding tasks and datasets. Furthermore, it won in the Ego4D CVPR'22 Object State Localization challenge. For code and pretrained models, visit the project page at \url{https://eladb3.github.io/SViT/}
Towards Neural Numeric-To-Text Generation From Temporal Personal Health Data
Jul 11, 2022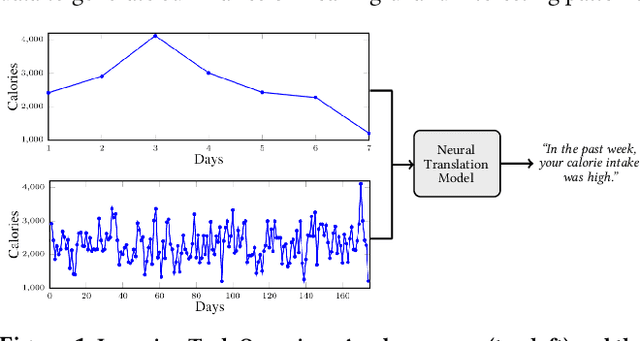
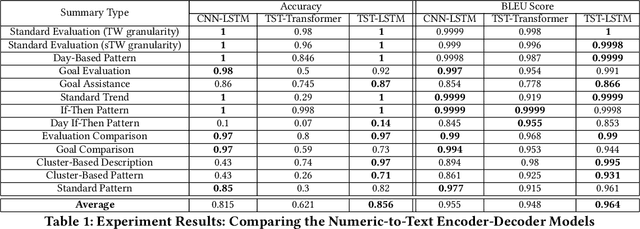
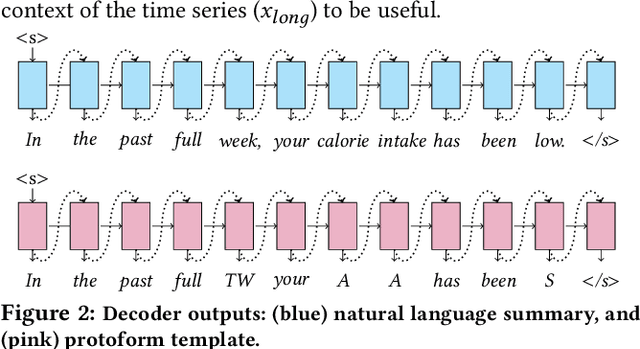
With an increased interest in the production of personal health technologies designed to track user data (e.g., nutrient intake, step counts), there is now more opportunity than ever to surface meaningful behavioral insights to everyday users in the form of natural language. This knowledge can increase their behavioral awareness and allow them to take action to meet their health goals. It can also bridge the gap between the vast collection of personal health data and the summary generation required to describe an individual's behavioral tendencies. Previous work has focused on rule-based time-series data summarization methods designed to generate natural language summaries of interesting patterns found within temporal personal health data. We examine recurrent, convolutional, and Transformer-based encoder-decoder models to automatically generate natural language summaries from numeric temporal personal health data. We showcase the effectiveness of our models on real user health data logged in MyFitnessPal and show that we can automatically generate high-quality natural language summaries. Our work serves as a first step towards the ambitious goal of automatically generating novel and meaningful temporal summaries from personal health data.
Practical Black Box Hamiltonian Learning
Jun 30, 2022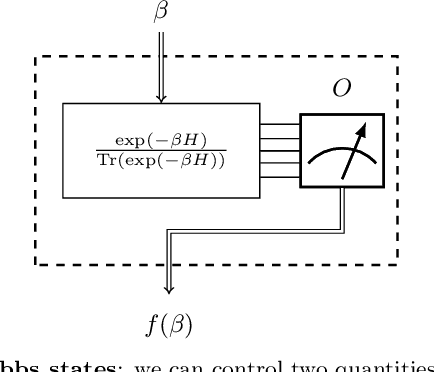

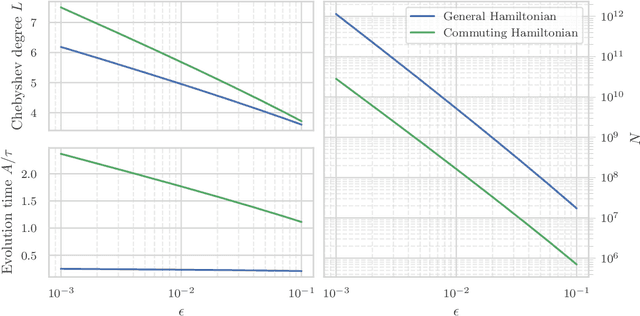
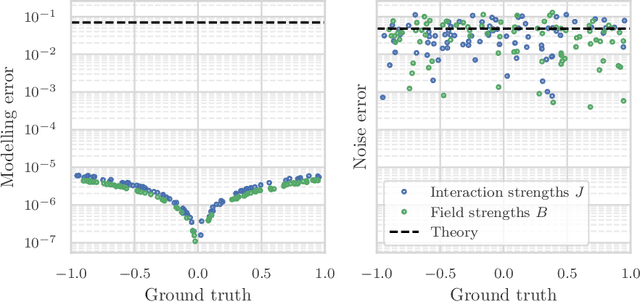
We study the problem of learning the parameters for the Hamiltonian of a quantum many-body system, given limited access to the system. In this work, we build upon recent approaches to Hamiltonian learning via derivative estimation. We propose a protocol that improves the scaling dependence of prior works, particularly with respect to parameters relating to the structure of the Hamiltonian (e.g., its locality $k$). Furthermore, by deriving exact bounds on the performance of our protocol, we are able to provide a precise numerical prescription for theoretically optimal settings of hyperparameters in our learning protocol, such as the maximum evolution time (when learning with unitary dynamics) or minimum temperature (when learning with Gibbs states). Thanks to these improvements, our protocol is practical for large problems: we demonstrate this with a numerical simulation of our protocol on an 80-qubit system.