 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Algorithmic Determination of the Combinatorial Structure of the Linear Regions of ReLU Neural Networks
Jul 15, 2022
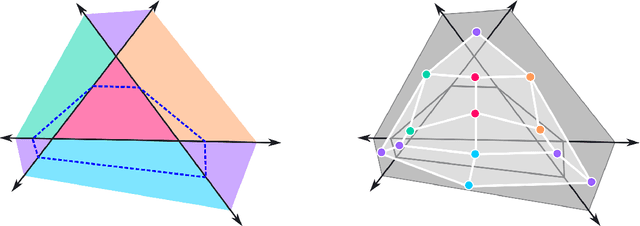

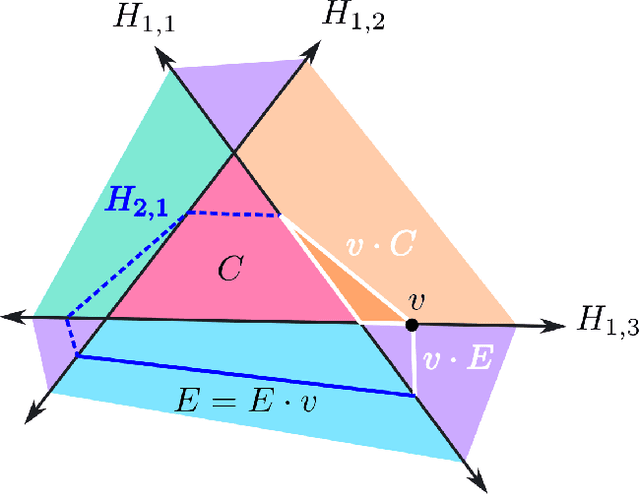
We algorithmically determine the regions and facets of all dimensions of the canonical polyhedral complex, the universal object into which a ReLU network decomposes its input space. We show that the locations of the vertices of the canonical polyhedral complex along with their signs with respect to layer maps determine the full facet structure across all dimensions. We present an algorithm which calculates this full combinatorial structure, making use of our theorems that the dual complex to the canonical polyhedral complex is cubical and it possesses a multiplication compatible with its facet structure. The resulting algorithm is numerically stable, polynomial time in the number of intermediate neurons, and obtains accurate information across all dimensions. This permits us to obtain, for example, the true topology of the decision boundaries of networks with low-dimensional inputs. We run empirics on such networks at initialization, finding that width alone does not increase observed topology, but width in the presence of depth does. Source code for our algorithms is accessible online at https://github.com/mmasden/canonicalpoly.
This is the Way: Differential Bayesian Filtering for Agile Trajectory Synthesis
Jul 15, 2022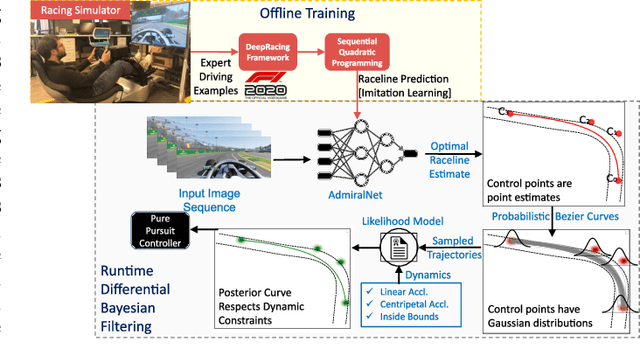
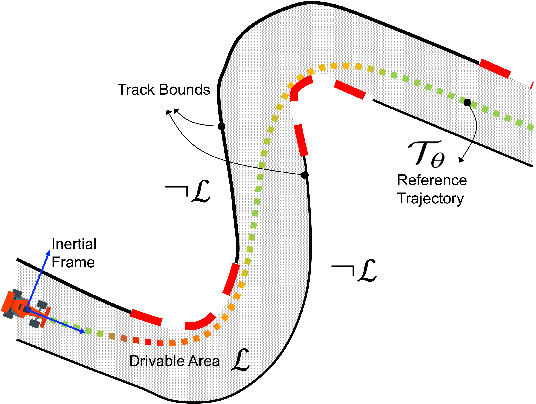
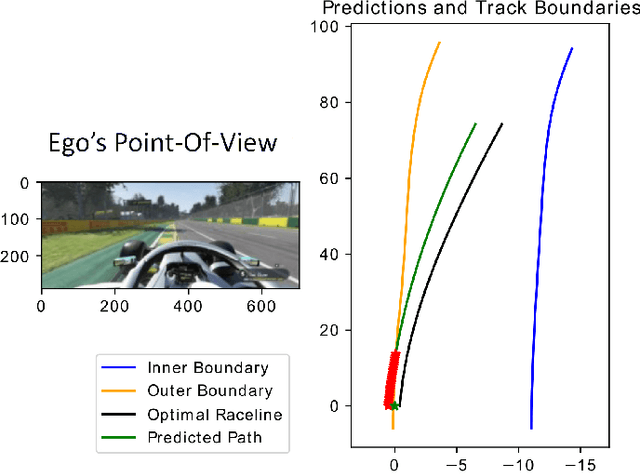
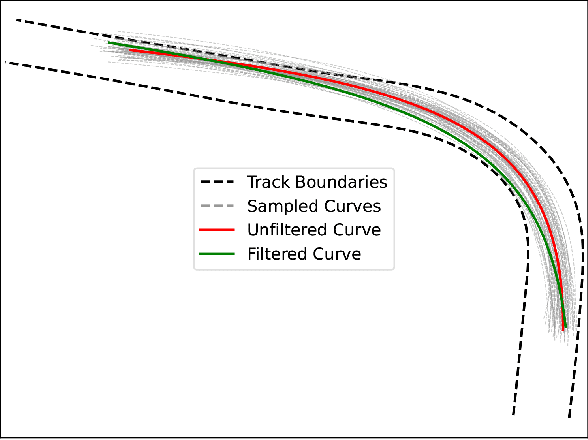
One of the main challenges in autonomous racing is to design algorithms for motion planning at high speed, and across complex racing courses. End-to-end trajectory synthesis has been previously proposed where the trajectory for the ego vehicle is computed based on camera images from the racecar. This is done in a supervised learning setting using behavioral cloning techniques. In this paper, we address the limitations of behavioral cloning methods for trajectory synthesis by introducing Differential Bayesian Filtering (DBF), which uses probabilistic B\'ezier curves as a basis for inferring optimal autonomous racing trajectories based on Bayesian inference. We introduce a trajectory sampling mechanism and combine it with a filtering process which is able to push the car to its physical driving limits. The performance of DBF is evaluated on the DeepRacing Formula One simulation environment and compared with several other trajectory synthesis approaches as well as human driving performance. DBF achieves the fastest lap time, and the fastest speed, by pushing the racecar closer to its limits of control while always remaining inside track bounds.
Real-time Neural Radiance Caching for Path Tracing
Jun 25, 2021

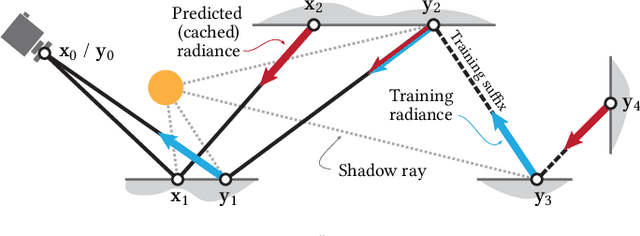
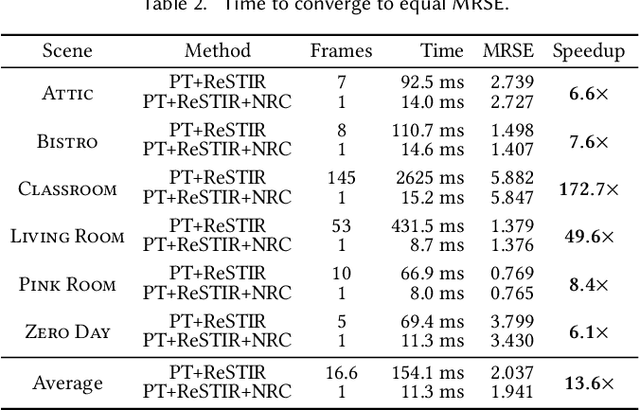
We present a real-time neural radiance caching method for path-traced global illumination. Our system is designed to handle fully dynamic scenes, and makes no assumptions about the lighting, geometry, and materials. The data-driven nature of our approach sidesteps many difficulties of caching algorithms, such as locating, interpolating, and updating cache points. Since pretraining neural networks to handle novel, dynamic scenes is a formidable generalization challenge, we do away with pretraining and instead achieve generalization via adaptation, i.e. we opt for training the radiance cache while rendering. We employ self-training to provide low-noise training targets and simulate infinite-bounce transport by merely iterating few-bounce training updates. The updates and cache queries incur a mild overhead -- about 2.6ms on full HD resolution -- thanks to a streaming implementation of the neural network that fully exploits modern hardware. We demonstrate significant noise reduction at the cost of little induced bias, and report state-of-the-art, real-time performance on a number of challenging scenarios.
VTrackIt: A Synthetic Self-Driving Dataset with Infrastructure and Pooled Vehicle Information
Jul 15, 2022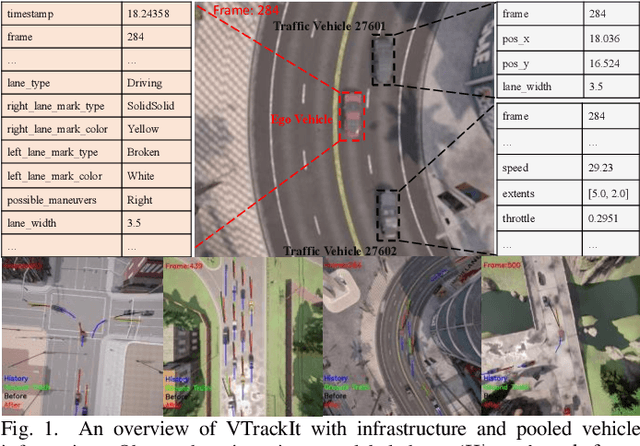
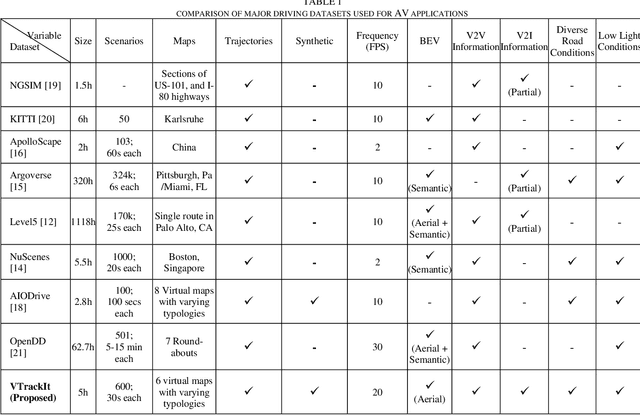
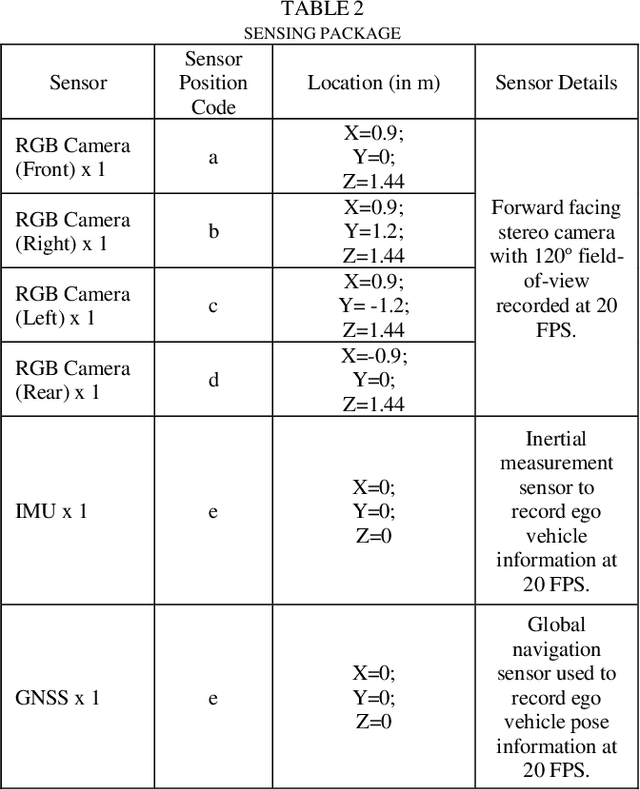
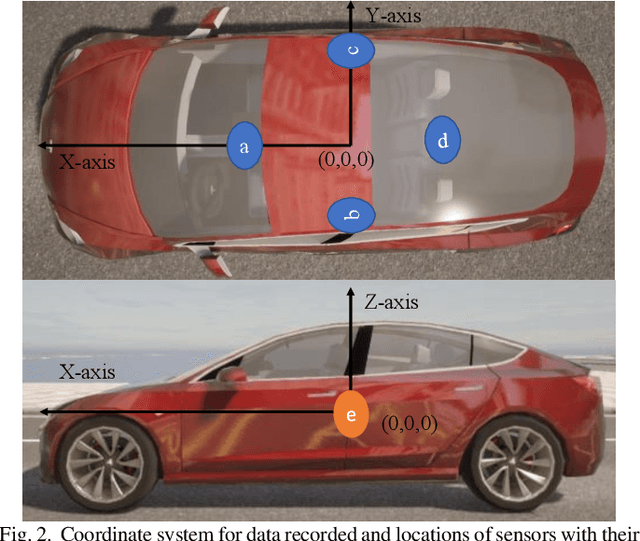
Artificial intelligence solutions for Autonomous Vehicles (AVs) have been developed using publicly available datasets such as Argoverse, ApolloScape, Level5, and NuScenes. One major limitation of these datasets is the absence of infrastructure and/or pooled vehicle information like lane line type, vehicle speed, traffic signs, and intersections. Such information is necessary and not complementary to eliminating high-risk edge cases. The rapid advancements in Vehicle-to-Infrastructure and Vehicle-to-Vehicle technologies show promise that infrastructure and pooled vehicle information will soon be accessible in near real-time. Taking a leap in the future, we introduce the first comprehensive synthetic dataset with intelligent infrastructure and pooled vehicle information for advancing the next generation of AVs, named VTrackIt. We also introduce the first deep learning model (InfraGAN) for trajectory predictions that considers such information. Our experiments with InfraGAN show that the comprehensive information offered by VTrackIt reduces the number of high-risk edge cases. The VTrackIt dataset is available upon request under the Creative Commons CC BY-NC-SA 4.0 license at http://vtrackit.irda.club.
Exploring Techniques for the Analysis of Spontaneous Asynchronicity in MPI-Parallel Applications
May 27, 2022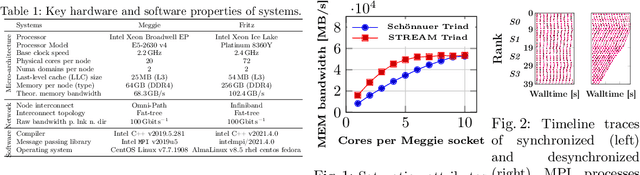
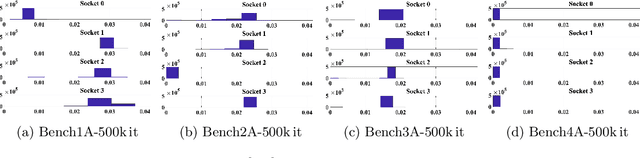
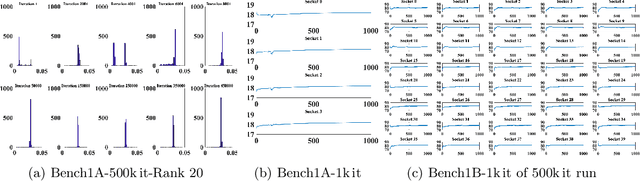
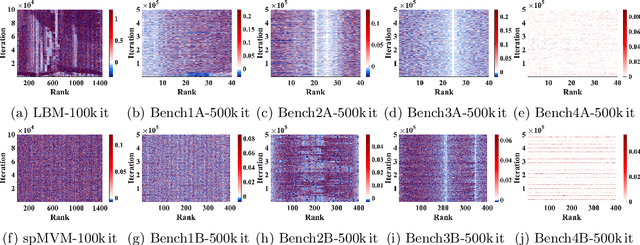
This paper studies the utility of using data analytics and machine learning techniques for identifying, classifying, and characterizing the dynamics of large-scale parallel (MPI) programs. To this end, we run microbenchmarks and realistic proxy applications with the regular compute-communicate structure on two different supercomputing platforms and choose the per-process performance and MPI time per time step as relevant observables. Using principal component analysis, clustering techniques, correlation functions, and a new "phase space plot," we show how desynchronization patterns (or lack thereof) can be readily identified from a data set that is much smaller than a full MPI trace. Our methods also lead the way towards a more general classification of parallel program dynamics.
Automated Dilated Spatio-Temporal Synchronous Graph Modeling for Traffic Prediction
Jul 22, 2022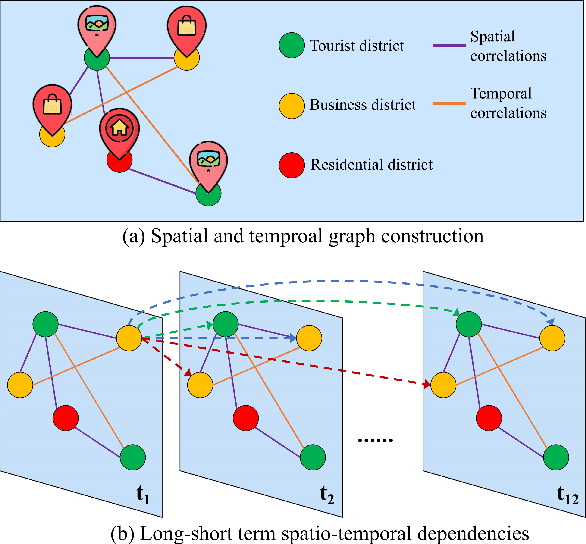

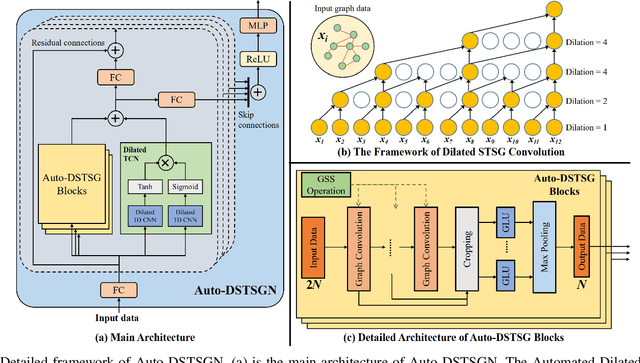
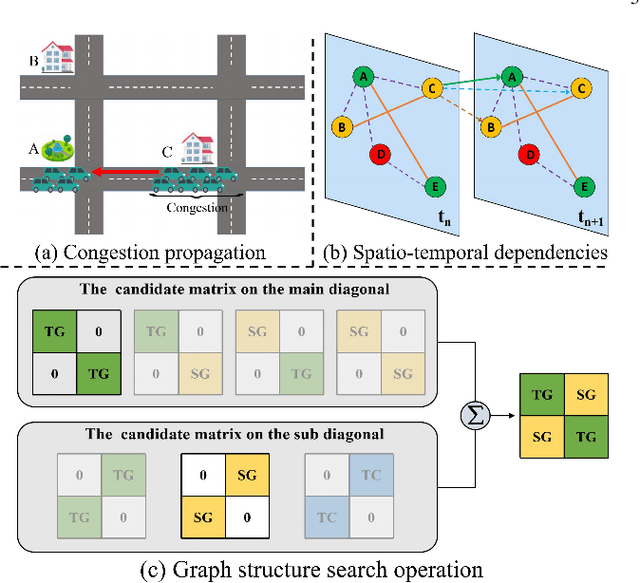
Accurate traffic prediction is a challenging task in intelligent transportation systems because of the complex spatio-temporal dependencies in transportation networks. Many existing works utilize sophisticated temporal modeling approaches to incorporate with graph convolution networks (GCNs) for capturing short-term and long-term spatio-temporal dependencies. However, these separated modules with complicated designs could restrict effectiveness and efficiency of spatio-temporal representation learning. Furthermore, most previous works adopt the fixed graph construction methods to characterize the global spatio-temporal relations, which limits the learning capability of the model for different time periods and even different data scenarios. To overcome these limitations, we propose an automated dilated spatio-temporal synchronous graph network, named Auto-DSTSGN for traffic prediction. Specifically, we design an automated dilated spatio-temporal synchronous graph (Auto-DSTSG) module to capture the short-term and long-term spatio-temporal correlations by stacking deeper layers with dilation factors in an increasing order. Further, we propose a graph structure search approach to automatically construct the spatio-temporal synchronous graph that can adapt to different data scenarios. Extensive experiments on four real-world datasets demonstrate that our model can achieve about 10% improvements compared with the state-of-art methods. Source codes are available at https://github.com/jinguangyin/Auto-DSTSGN.
ProSelfLC: Progressive Self Label Correction Towards A Low-Temperature Entropy State
Jun 30, 2022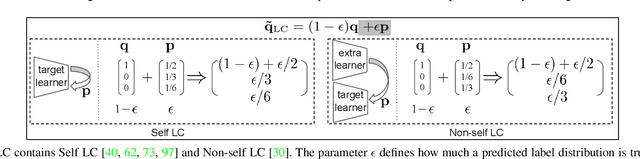

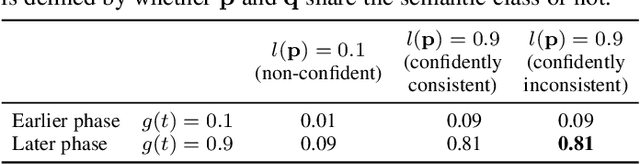
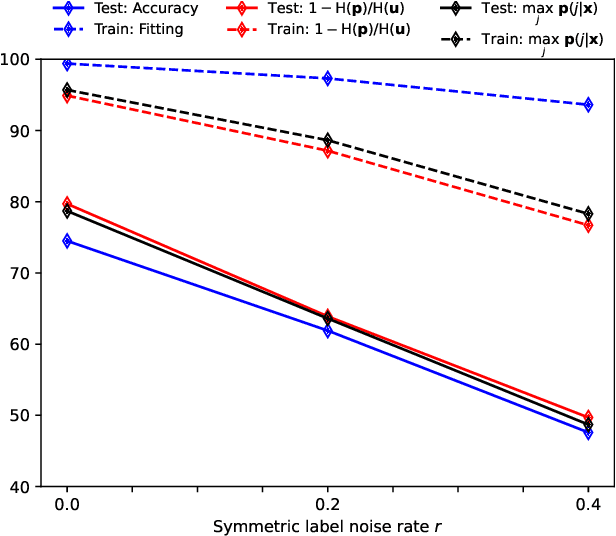
To train robust deep neural networks (DNNs), we systematically study several target modification approaches, which include output regularisation, self and non-self label correction (LC). Three key issues are discovered: (1) Self LC is the most appealing as it exploits its own knowledge and requires no extra models. However, how to automatically decide the trust degree of a learner as training goes is not well answered in the literature. (2) Some methods penalise while the others reward low-entropy predictions, prompting us to ask which one is better. (3) Using the standard training setting, a trained network is of low confidence when severe noise exists, making it hard to leverage its high-entropy self knowledge. To resolve the issue (1), taking two well-accepted propositions--deep neural networks learn meaningful patterns before fitting noise and minimum entropy regularisation principle--we propose a novel end-to-end method named ProSelfLC, which is designed according to learning time and entropy. Specifically, given a data point, we progressively increase trust in its predicted label distribution versus its annotated one if a model has been trained for enough time and the prediction is of low entropy (high confidence). For the issue (2), according to ProSelfLC, we empirically prove that it is better to redefine a meaningful low-entropy status and optimise the learner toward it. This serves as a defence of entropy minimisation. To address the issue (3), we decrease the entropy of self knowledge using a low temperature before exploiting it to correct labels, so that the revised labels redefine a low-entropy target state. We demonstrate the effectiveness of ProSelfLC through extensive experiments in both clean and noisy settings, and on both image and protein datasets. Furthermore, our source code is available at https://github.com/XinshaoAmosWang/ProSelfLC-AT.
AI-aided multiscale modeling of physiologically-significant blood clots
May 25, 2022We have developed an AI-aided multiple time stepping (AI-MTS) algorithm and multiscale modeling framework (AI-MSM) and implemented them on the Summit-like supercomputer, AIMOS. AI-MSM is the first of its kind to integrate multi-physics, including intra-platelet, inter-platelet, and fluid-platelet interactions, into one system. It has simulated a record-setting multiscale blood clotting model of 102 million particles, of which 70 flowing and 180 aggregating platelets, under dissipative particle dynamics to coarse-grained molecular dynamics. By adaptively adjusting timestep sizes to match the characteristic time scales of the underlying dynamics, AI-MTS optimally balances speeds and accuracies of the simulations.
Recipe for Fast Large-scale SVM Training: Polishing, Parallelism, and more RAM!
Jul 03, 2022
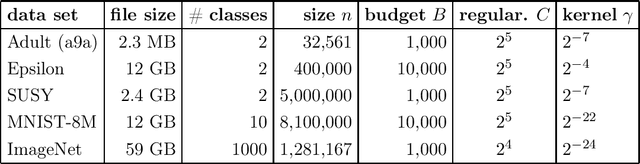
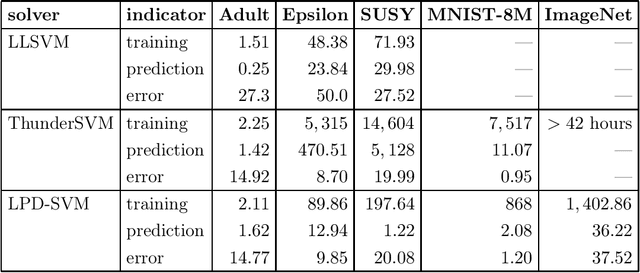
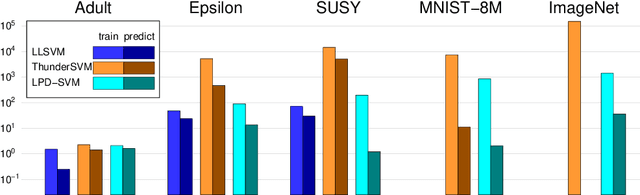
Support vector machines (SVMs) are a standard method in the machine learning toolbox, in particular for tabular data. Non-linear kernel SVMs often deliver highly accurate predictors, however, at the cost of long training times. That problem is aggravated by the exponential growth of data volumes over time. It was tackled in the past mainly by two types of techniques: approximate solvers, and parallel GPU implementations. In this work, we combine both approaches to design an extremely fast dual SVM solver. We fully exploit the capabilities of modern compute servers: many-core architectures, multiple high-end GPUs, and large random access memory. On such a machine, we train a large-margin classifier on the ImageNet data set in 24 minutes.
Power Transformer Fault Diagnosis with Intrinsic Time-scale Decomposition and XGBoost Classifier
Oct 21, 2021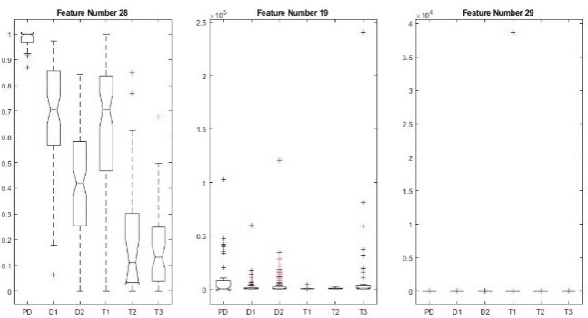
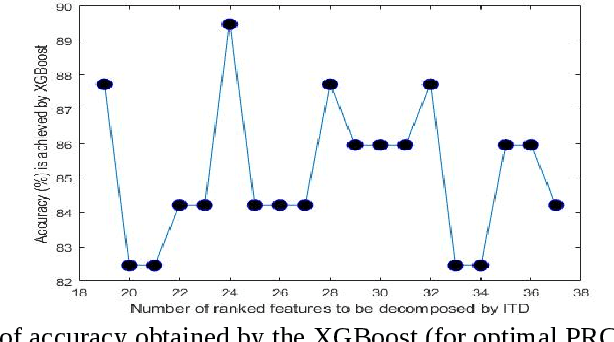
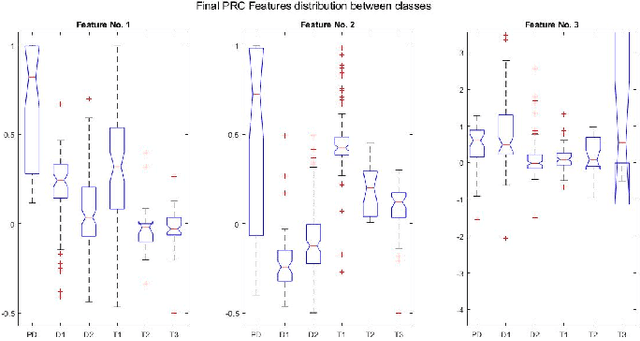
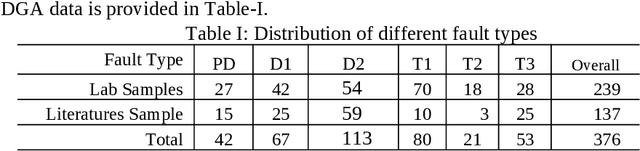
An intrinsic time-scale decomposition (ITD) based method for power transformer fault diagnosis is proposed. Dissolved gas analysis (DGA) parameters are ranked according to their skewness, and then ITD based features extraction is performed. An optimal set of PRC features are determined by an XGBoost classifier. For classification purpose, an XGBoost classifier is used to the optimal PRC features set. The proposed method's performance in classification is studied using publicly available DGA data of 376 power transformers and employing an XGBoost classifier. The Proposed method achieves more than 95% accuracy and high sensitivity and F1-score, better than conventional methods and some recent machine learning-based fault diagnosis approaches. Moreover, it gives better Cohen Kappa and F1-score as compared to the recently introduced EMD-based hierarchical technique for fault diagnosis in power transformers.