 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Curiosity-driven Red-teaming for Large Language Models
Feb 29, 2024
Large language models (LLMs) hold great potential for many natural language applications but risk generating incorrect or toxic content. To probe when an LLM generates unwanted content, the current paradigm is to recruit a \textit{red team} of human testers to design input prompts (i.e., test cases) that elicit undesirable responses from LLMs. However, relying solely on human testers is expensive and time-consuming. Recent works automate red teaming by training a separate red team LLM with reinforcement learning (RL) to generate test cases that maximize the chance of eliciting undesirable responses from the target LLM. However, current RL methods are only able to generate a small number of effective test cases resulting in a low coverage of the span of prompts that elicit undesirable responses from the target LLM. To overcome this limitation, we draw a connection between the problem of increasing the coverage of generated test cases and the well-studied approach of curiosity-driven exploration that optimizes for novelty. Our method of curiosity-driven red teaming (CRT) achieves greater coverage of test cases while mantaining or increasing their effectiveness compared to existing methods. Our method, CRT successfully provokes toxic responses from LLaMA2 model that has been heavily fine-tuned using human preferences to avoid toxic outputs. Code is available at \url{https://github.com/Improbable-AI/curiosity_redteam}
TELEClass: Taxonomy Enrichment and LLM-Enhanced Hierarchical Text Classification with Minimal Supervision
Feb 29, 2024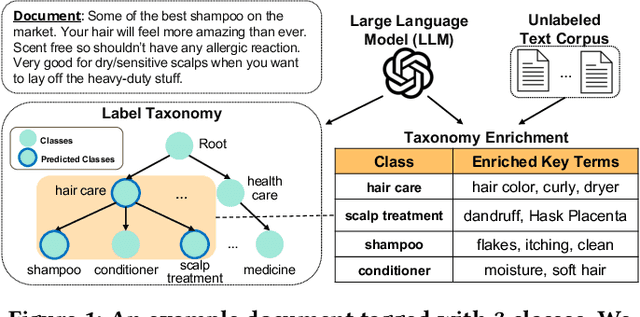
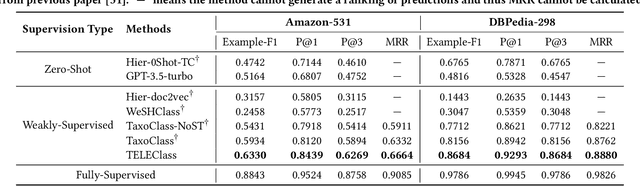
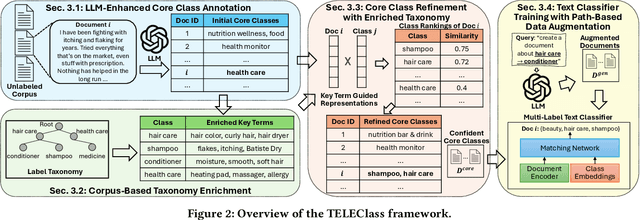

Hierarchical text classification aims to categorize each document into a set of classes in a label taxonomy. Most earlier works focus on fully or semi-supervised methods that require a large amount of human annotated data which is costly and time-consuming to acquire. To alleviate human efforts, in this paper, we work on hierarchical text classification with the minimal amount of supervision: using the sole class name of each node as the only supervision. Recently, large language models (LLM) show competitive performance on various tasks through zero-shot prompting, but this method performs poorly in the hierarchical setting, because it is ineffective to include the large and structured label space in a prompt. On the other hand, previous weakly-supervised hierarchical text classification methods only utilize the raw taxonomy skeleton and ignore the rich information hidden in the text corpus that can serve as additional class-indicative features. To tackle the above challenges, we propose TELEClass, Taxonomy Enrichment and LLM-Enhanced weakly-supervised hierarchical text classification, which (1) automatically enriches the label taxonomy with class-indicative topical terms mined from the corpus to facilitate classifier training and (2) utilizes LLMs for both data annotation and creation tailored for the hierarchical label space. Experiments show that TELEClass can outperform previous weakly-supervised hierarchical text classification methods and LLM-based zero-shot prompting methods on two public datasets.
Active Sensing for Reciprocal MIMO Channels
Feb 29, 2024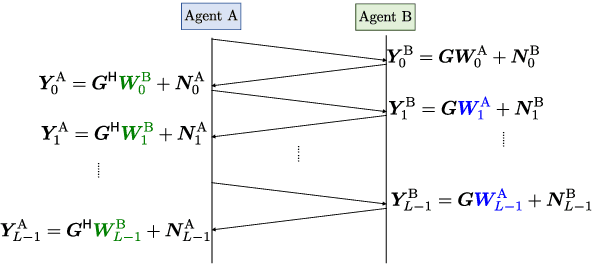
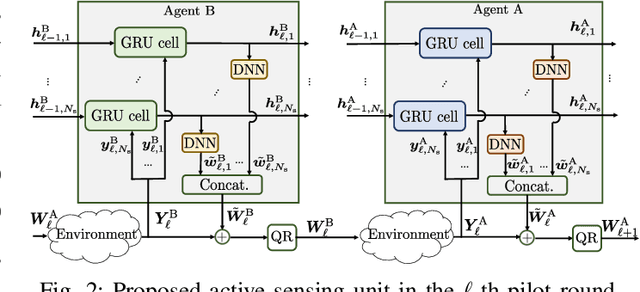
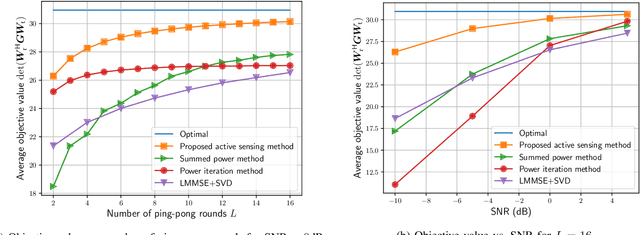
This paper addresses the design of transmit precoder and receive combiner matrices to support $N_{\rm s}$ independent data streams over a time-division duplex (TDD) point-to-point massive multiple-input multiple-output (MIMO) channel with either a fully digital or a hybrid structure. The optimal precoder and combiner design amounts to finding the top-$N_{\rm s}$ singular vectors of the channel matrix, but the explicit estimation of the entire high-dimensional channel would require significant pilot overhead. Alternatively, prior works seek to find the precoding and combining matrices directly by exploiting channel reciprocity and by using the power iteration method, but its performance degrades in the low SNR regime. To tackle this challenging problem, this paper proposes a learning-based active sensing framework, where the transmitter and the receiver send pilots alternately using sensing beamformers that are actively designed as functions of previously received pilots. This is accomplished by using recurrent neural networks to summarize information from the historical observations into hidden state vectors, then using fully connected neural networks to learn the appropriate sensing beamformers in the next pilot stage and finally the transmit precoding and receive combiner matrices for data communications. Simulations demonstrate that the learning-based method outperforms existing approaches significantly and maintains superior performance even in low SNR regimes both in fully digital and hybrid MIMO scenarios.
Lumiere: A Space-Time Diffusion Model for Video Generation
Feb 05, 2024We introduce Lumiere -- a text-to-video diffusion model designed for synthesizing videos that portray realistic, diverse and coherent motion -- a pivotal challenge in video synthesis. To this end, we introduce a Space-Time U-Net architecture that generates the entire temporal duration of the video at once, through a single pass in the model. This is in contrast to existing video models which synthesize distant keyframes followed by temporal super-resolution -- an approach that inherently makes global temporal consistency difficult to achieve. By deploying both spatial and (importantly) temporal down- and up-sampling and leveraging a pre-trained text-to-image diffusion model, our model learns to directly generate a full-frame-rate, low-resolution video by processing it in multiple space-time scales. We demonstrate state-of-the-art text-to-video generation results, and show that our design easily facilitates a wide range of content creation tasks and video editing applications, including image-to-video, video inpainting, and stylized generation.
High-Fidelity Neural Phonetic Posteriorgrams
Feb 27, 2024A phonetic posteriorgram (PPG) is a time-varying categorical distribution over acoustic units of speech (e.g., phonemes). PPGs are a popular representation in speech generation due to their ability to disentangle pronunciation features from speaker identity, allowing accurate reconstruction of pronunciation (e.g., voice conversion) and coarse-grained pronunciation editing (e.g., foreign accent conversion). In this paper, we demonstrably improve the quality of PPGs to produce a state-of-the-art interpretable PPG representation. We train an off-the-shelf speech synthesizer using our PPG representation and show that high-quality PPGs yield independent control over pitch and pronunciation. We further demonstrate novel uses of PPGs, such as an acoustic pronunciation distance and fine-grained pronunciation control.
Graph Feature Preprocessor: Real-time Extraction of Subgraph-based Features from Transaction Graphs
Feb 13, 2024In this paper, we present "Graph Feature Preprocessor", a software library for detecting typical money laundering and fraud patterns in financial transaction graphs in real time. These patterns are used to produce a rich set of transaction features for downstream machine learning training and inference tasks such as money laundering detection. We show that our enriched transaction features dramatically improve the prediction accuracy of gradient-boosting-based machine learning models. Our library exploits multicore parallelism, maintains a dynamic in-memory graph, and efficiently mines subgraph patterns in the incoming transaction stream, which enables it to be operated in a streaming manner. We evaluate our library using highly-imbalanced synthetic anti-money laundering (AML) and real-life Ethereum phishing datasets. In these datasets, the proportion of illicit transactions is very small, which makes the learning process challenging. Our solution, which combines our Graph Feature Preprocessor and gradient-boosting-based machine learning models, is able to detect these illicit transactions with higher minority-class F1 scores than standard graph neural networks. In addition, the end-to-end throughput rate of our solution executed on a multicore CPU outperforms the graph neural network baselines executed on a powerful V100 GPU. Overall, the combination of high accuracy, a high throughput rate, and low latency of our solution demonstrates the practical value of our library in real-world applications. Graph Feature Preprocessor has been integrated into IBM mainframe software products, namely "IBM Cloud Pak for Data on Z" and "AI Toolkit for IBM Z and LinuxONE".
XTSFormer: Cross-Temporal-Scale Transformer for Irregular Time Event Prediction
Feb 03, 2024Event prediction aims to forecast the time and type of a future event based on a historical event sequence. Despite its significance, several challenges exist, including the irregularity of time intervals between consecutive events, the existence of cycles, periodicity, and multi-scale event interactions, as well as the high computational costs for long event sequences. Existing neural temporal point processes (TPPs) methods do not capture the multi-scale nature of event interactions, which is common in many real-world applications such as clinical event data. To address these issues, we propose the cross-temporal-scale transformer (XTSFormer), designed specifically for irregularly timed event data. Our model comprises two vital components: a novel Feature-based Cycle-aware Time Positional Encoding (FCPE) that adeptly captures the cyclical nature of time, and a hierarchical multi-scale temporal attention mechanism. These scales are determined by a bottom-up clustering algorithm. Extensive experiments on several real-world datasets show that our XTSFormer outperforms several baseline methods in prediction performance.
DEYO: DETR with YOLO for End-to-End Object Detection
Feb 26, 2024The training paradigm of DETRs is heavily contingent upon pre-training their backbone on the ImageNet dataset. However, the limited supervisory signals provided by the image classification task and one-to-one matching strategy result in an inadequately pre-trained neck for DETRs. Additionally, the instability of matching in the early stages of training engenders inconsistencies in the optimization objectives of DETRs. To address these issues, we have devised an innovative training methodology termed step-by-step training. Specifically, in the first stage of training, we employ a classic detector, pre-trained with a one-to-many matching strategy, to initialize the backbone and neck of the end-to-end detector. In the second stage of training, we froze the backbone and neck of the end-to-end detector, necessitating the training of the decoder from scratch. Through the application of step-by-step training, we have introduced the first real-time end-to-end object detection model that utilizes a purely convolutional structure encoder, DETR with YOLO (DEYO). Without reliance on any supplementary training data, DEYO surpasses all existing real-time object detectors in both speed and accuracy. Moreover, the comprehensive DEYO series can complete its second-phase training on the COCO dataset using a single 8GB RTX 4060 GPU, significantly reducing the training expenditure. Source code and pre-trained models are available at https://github.com/ouyanghaodong/DEYO.
Decoding-time Realignment of Language Models
Feb 05, 2024Aligning language models with human preferences is crucial for reducing errors and biases in these models. Alignment techniques, such as reinforcement learning from human feedback (RLHF), are typically cast as optimizing a tradeoff between human preference rewards and a proximity regularization term that encourages staying close to the unaligned model. Selecting an appropriate level of regularization is critical: insufficient regularization can lead to reduced model capabilities due to reward hacking, whereas excessive regularization hinders alignment. Traditional methods for finding the optimal regularization level require retraining multiple models with varying regularization strengths. This process, however, is resource-intensive, especially for large models. To address this challenge, we propose decoding-time realignment (DeRa), a simple method to explore and evaluate different regularization strengths in aligned models without retraining. DeRa enables control over the degree of alignment, allowing users to smoothly transition between unaligned and aligned models. It also enhances the efficiency of hyperparameter tuning by enabling the identification of effective regularization strengths using a validation dataset.
Pathformer: Multi-scale transformers with Adaptive Pathways for Time Series Forecasting
Feb 04, 2024Transformer-based models have achieved some success in time series forecasting. Existing methods mainly model time series from limited or fixed scales, making it challenging to capture different characteristics spanning various scales. In this paper, we propose multi-scale transformers with adaptive pathways (Pathformer). The proposed Transformer integrates both temporal resolution and temporal distance for multi-scale modeling. Multi-scale division divides the time series into different temporal resolutions using patches of various sizes. Based on the division of each scale, dual attention is performed over these patches to capture global correlations and local details as temporal dependencies. We further enrich the multi-scale transformer with adaptive pathways, which adaptively adjust the multi-scale modeling process based on the varying temporal dynamics in the input time series, improving the prediction accuracy and generalization of Pathformer. Extensive experiments on eleven real-world datasets demonstrate that Pathformer not only achieves state-of-the-art performance by surpassing all current models but also exhibits stronger generalization abilities under various transfer scenarios.