 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-time Pose Estimation from Images for Multiple Humanoid Robots
Jul 06, 2021

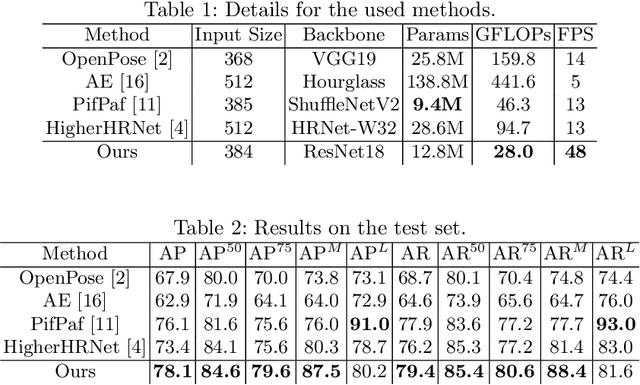
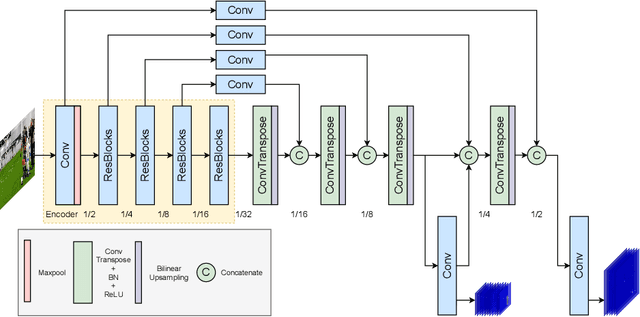
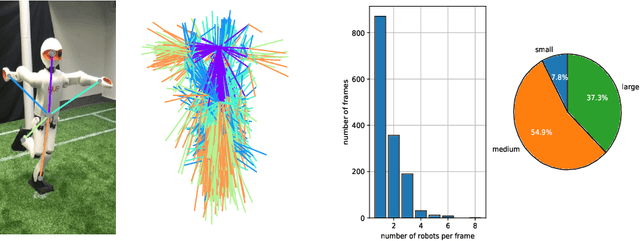
Pose estimation commonly refers to computer vision methods that recognize people's body postures in images or videos. With recent advancements in deep learning, we now have compelling models to tackle the problem in real-time. Since these models are usually designed for human images, one needs to adapt existing models to work on other creatures, including robots. This paper examines different state-of-the-art pose estimation models and proposes a lightweight model that can work in real-time on humanoid robots in the RoboCup Humanoid League environment. Additionally, we present a novel dataset called the HumanoidRobotPose dataset. The results of this work have the potential to enable many advanced behaviors for soccer-playing robots.
Practical Black Box Hamiltonian Learning
Jun 30, 2022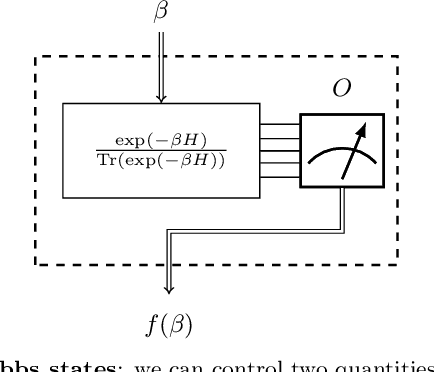

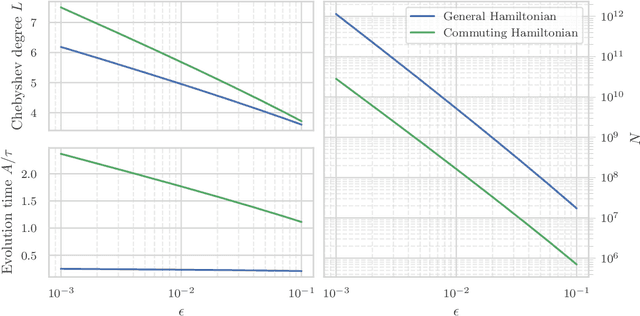
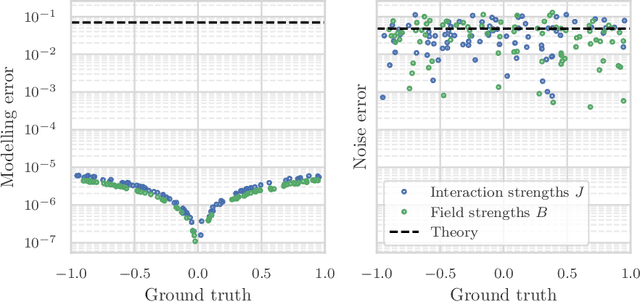
We study the problem of learning the parameters for the Hamiltonian of a quantum many-body system, given limited access to the system. In this work, we build upon recent approaches to Hamiltonian learning via derivative estimation. We propose a protocol that improves the scaling dependence of prior works, particularly with respect to parameters relating to the structure of the Hamiltonian (e.g., its locality $k$). Furthermore, by deriving exact bounds on the performance of our protocol, we are able to provide a precise numerical prescription for theoretically optimal settings of hyperparameters in our learning protocol, such as the maximum evolution time (when learning with unitary dynamics) or minimum temperature (when learning with Gibbs states). Thanks to these improvements, our protocol is practical for large problems: we demonstrate this with a numerical simulation of our protocol on an 80-qubit system.
Deep Time Series Forecasting with Shape and Temporal Criteria
Apr 09, 2021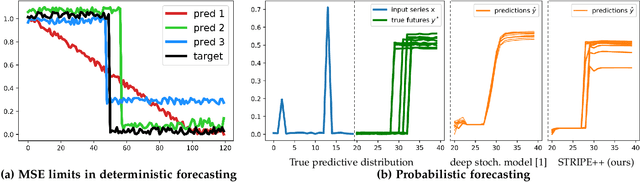
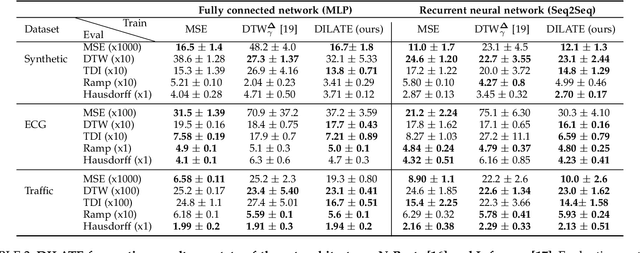
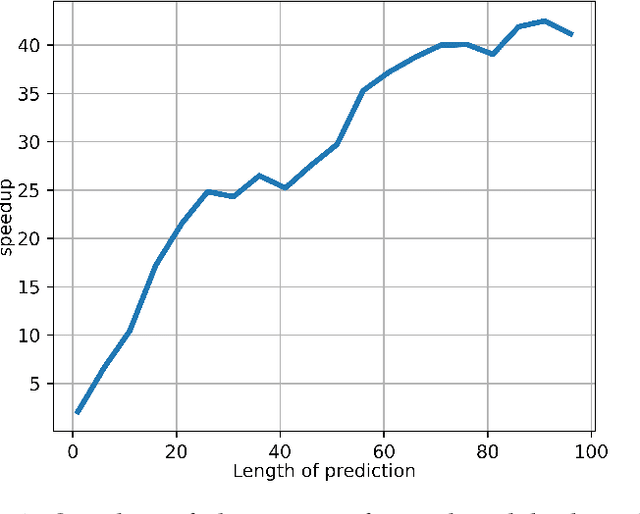
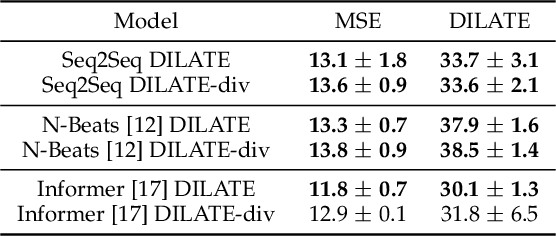
This paper addresses the problem of multi-step time series forecasting for non-stationary signals that can present sudden changes. Current state-of-the-art deep learning forecasting methods, often trained with variants of the MSE, lack the ability to provide sharp predictions in deterministic and probabilistic contexts. To handle these challenges, we propose to incorporate shape and temporal criteria in the training objective of deep models. We define shape and temporal similarities and dissimilarities, based on a smooth relaxation of Dynamic Time Warping (DTW) and Temporal Distortion Index (TDI), that enable to build differentiable loss functions and positive semi-definite (PSD) kernels. With these tools, we introduce DILATE (DIstortion Loss including shApe and TimE), a new objective for deterministic forecasting, that explicitly incorporates two terms supporting precise shape and temporal change detection. For probabilistic forecasting, we introduce STRIPE++ (Shape and Time diverRsIty in Probabilistic forEcasting), a framework for providing a set of sharp and diverse forecasts, where the structured shape and time diversity is enforced with a determinantal point process (DPP) diversity loss. Extensive experiments and ablations studies on synthetic and real-world datasets confirm the benefits of leveraging shape and time features in time series forecasting.
Clustering Left-Censored Multivariate Time-Series
Feb 13, 2021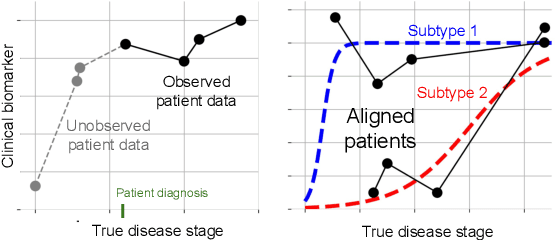
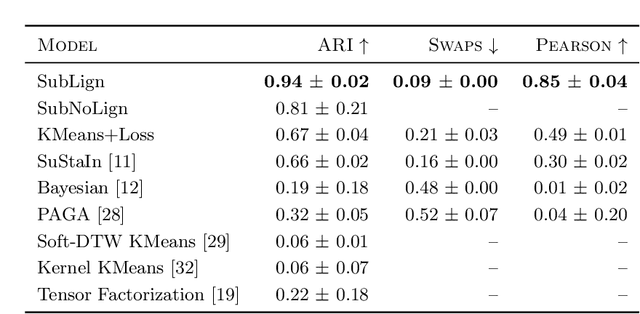
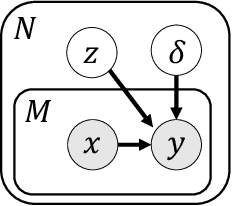
Unsupervised learning seeks to uncover patterns in data. However, different kinds of noise may impede the discovery of useful substructure from real-world time-series data. In this work, we focus on mitigating the interference of left-censorship in the task of clustering. We provide conditions under which clusters and left-censorship may be identified; motivated by this result, we develop a deep generative, continuous-time model of time-series data that clusters while correcting for censorship time. We demonstrate accurate, stable, and interpretable results on synthetic data that outperform several benchmarks. To showcase the utility of our framework on real-world problems, we study how left-censorship can adversely affect the task of disease phenotyping, resulting in the often incorrect assumption that longitudinal patient data are aligned by disease stage. In reality, patients at the time of diagnosis are at different stages of the disease -- both late and early due to differences in when patients seek medical care and such discrepancy can confound unsupervised learning algorithms. On two clinical datasets, our model corrects for this form of censorship and recovers known clinical subtypes.
Mobile MIMO Channel Prediction with ODE-RNN: a Physics-Inspired Adaptive Approach
Jul 08, 2022
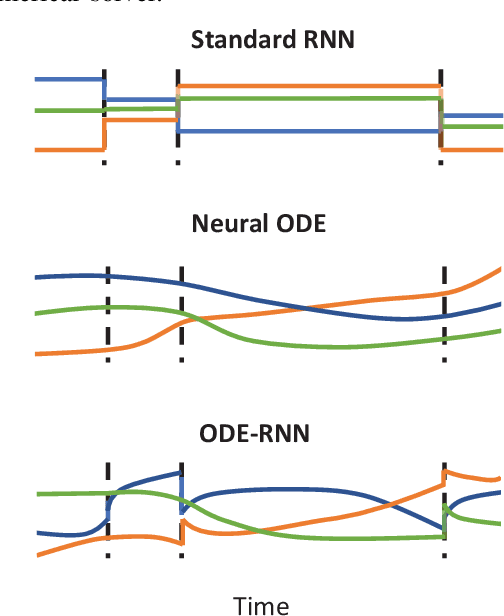
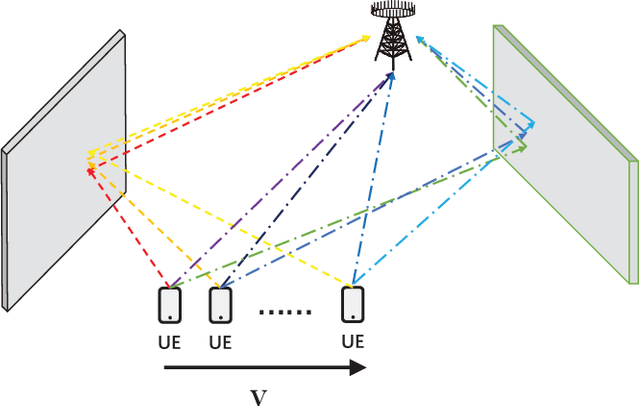
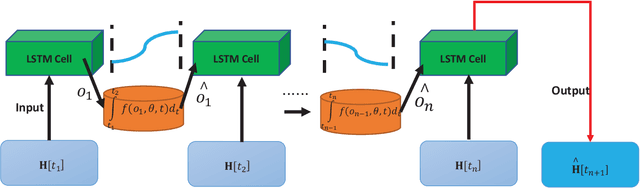
Obtaining accurate channel state information (CSI) is crucial and challenging for multiple-input multiple-output (MIMO) wireless communication systems. Conventional channel estimation method cannot guarantee the accuracy of mobile CSI while requires high signaling overhead. Through exploring the intrinsic correlation among a set of historical CSI instances randomly obtained in a certain communication environment, channel prediction can significantly increase CSI accuracy and save signaling overhead. In this paper, we propose a novel channel prediction method based on ordinary differential equation (ODE)-recurrent neural network (RNN) for accurate and flexible mobile MIMO channel prediction. Differing from existing works using sequential network structures for exploring the numerical correlation between observed data, our proposed method tries to represent the implicit physics process of path responses changing by specially designed continuous learning network with ODE structure. Due to the targeted design of learning network, our proposed method fits the mathematics feature of CSI data better and enjoy higher network interpretability. Experimental results show that the proposed learning approach outperforms existing methods, especially for long time interval of the CSI sequence and large channel measurement error.
Real-World Image Super-Resolution by Exclusionary Dual-Learning
Jun 06, 2022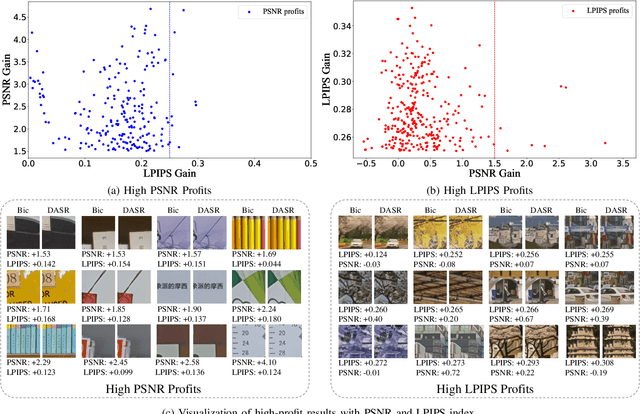

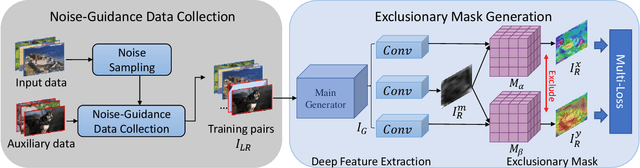
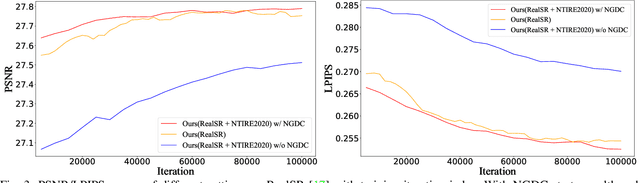
Real-world image super-resolution is a practical image restoration problem that aims to obtain high-quality images from in-the-wild input, has recently received considerable attention with regard to its tremendous application potentials. Although deep learning-based methods have achieved promising restoration quality on real-world image super-resolution datasets, they ignore the relationship between L1- and perceptual- minimization and roughly adopt auxiliary large-scale datasets for pre-training. In this paper, we discuss the image types within a corrupted image and the property of perceptual- and Euclidean- based evaluation protocols. Then we propose a method, Real-World image Super-Resolution by Exclusionary Dual-Learning (RWSR-EDL) to address the feature diversity in perceptual- and L1- based cooperative learning. Moreover, a noise-guidance data collection strategy is developed to address the training time consumption in multiple datasets optimization. When an auxiliary dataset is incorporated, RWSR-EDL achieves promising results and repulses any training time increment by adopting the noise-guidance data collection strategy. Extensive experiments show that RWSR-EDL achieves competitive performance over state-of-the-art methods on four in-the-wild image super-resolution datasets.
CROM: Continuous Reduced-Order Modeling of PDEs Using Implicit Neural Representations
Jun 06, 2022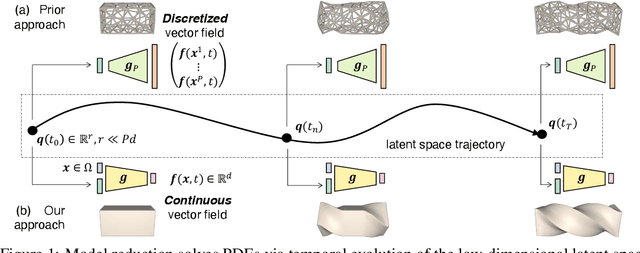
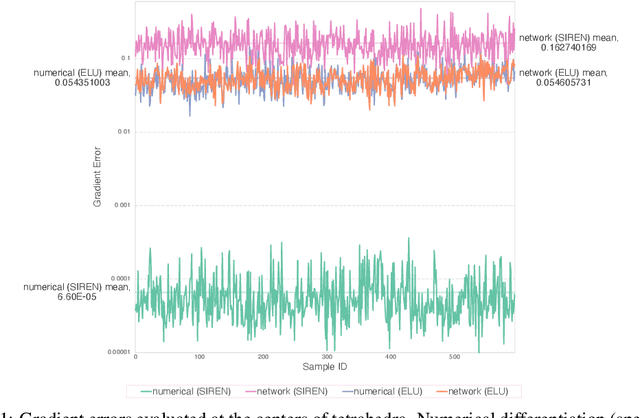
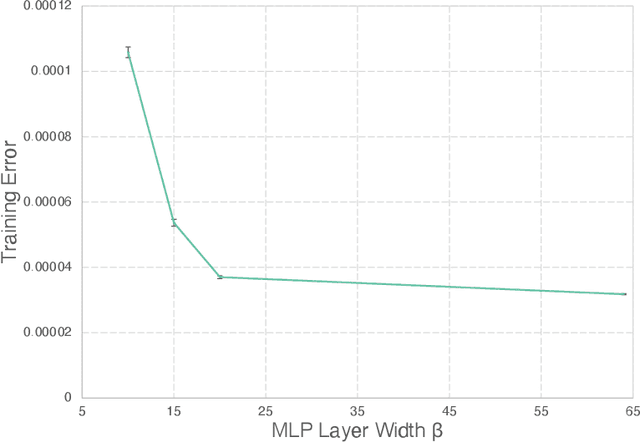

The excessive runtime of high-fidelity partial differential equation (PDE) solvers makes them unsuitable for time-critical applications. We propose to accelerate PDE solvers using reduced-order modeling (ROM). Whereas prior ROM approaches reduce the dimensionality of discretized vector fields, our continuous reduced-order modeling (CROM) approach builds a smooth, low-dimensional manifold of the continuous vector fields themselves, not their discretization. We represent this reduced manifold using neural fields, relying on their continuous and differentiable nature to efficiently solve the PDEs. CROM may train on any and all available numerical solutions of the continuous system, even when they are obtained using diverse methods or discretizations. After the low-dimensional manifolds are built, solving PDEs requires significantly less computational resources. Since CROM is discretization-agnostic, CROM-based PDE solvers may optimally adapt discretization resolution over time to economize computation. We validate our approach on an extensive range of PDEs with training data from voxel grids, meshes, and point clouds. Large-scale experiments demonstrate that our approach obtains speed, memory, and accuracy advantages over prior ROM approaches while gaining 109$\times$ wall-clock speedup over full-order models on CPUs and 89$\times$ speedup on GPUs.
Sampling-free Inference for Ab-Initio Potential Energy Surface Networks
May 30, 2022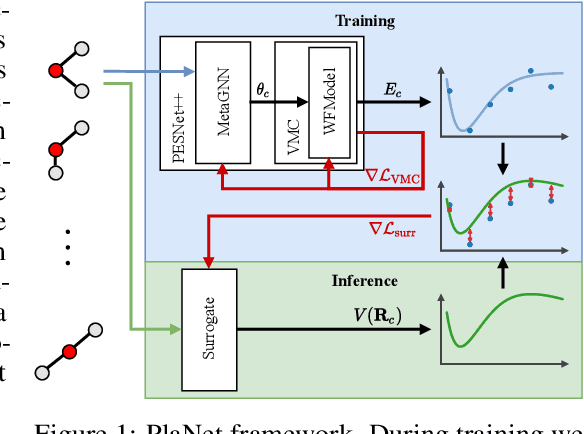

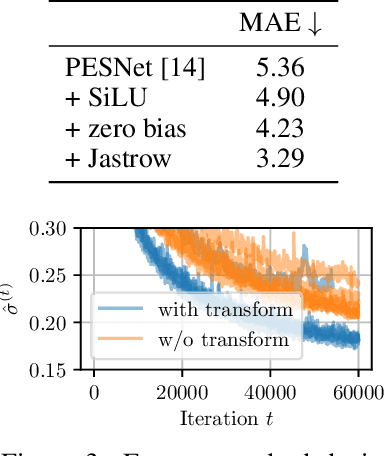
Obtaining the energy of molecular systems typically requires solving the associated Schr\"odinger equation. Unfortunately, analytical solutions only exist for single-electron systems, and accurate approximate solutions are expensive. In recent work, the potential energy surface network (PESNet) has been proposed to reduce training time by solving the Schr\"odinger equation for many geometries simultaneously. While training significantly faster, inference still required numerical integration limiting the evaluation to a few geometries. Here, we address the inference shortcomings by proposing the Potential learning from ab-initio Networks (PlaNet) framework to simultaneously train a surrogate model that avoids expensive Monte-Carlo integration and, thus, reduces inference time from minutes or even hours to milliseconds. In this way, we can accurately model high-resolution multi-dimensional energy surfaces that previously would have been unobtainable via neural wave functions. Finally, we present PESNet++, an architectural improvement to PESNet, that reduces errors by up to 39% and provides new state-of-the-art results for neural wave functions across all systems evaluated.
Detection of Condensed Vehicle Gas Exhaust in LiDAR Point Clouds
Jul 11, 2022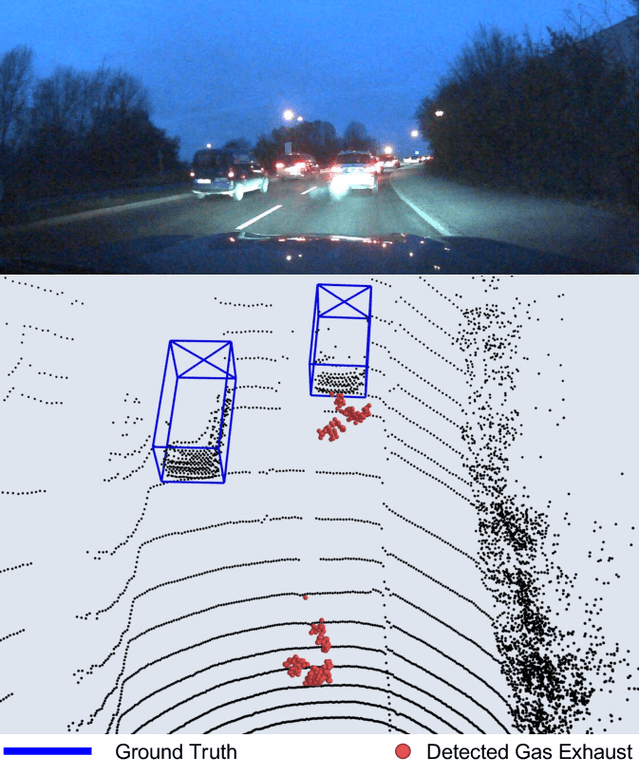
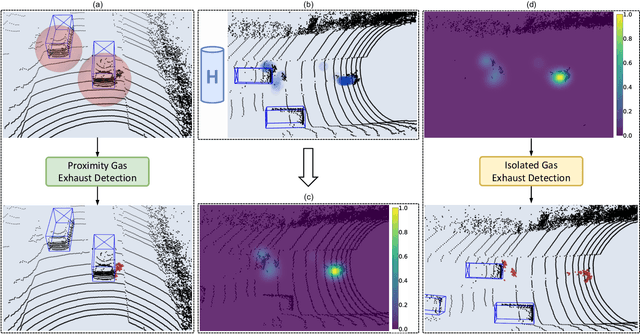
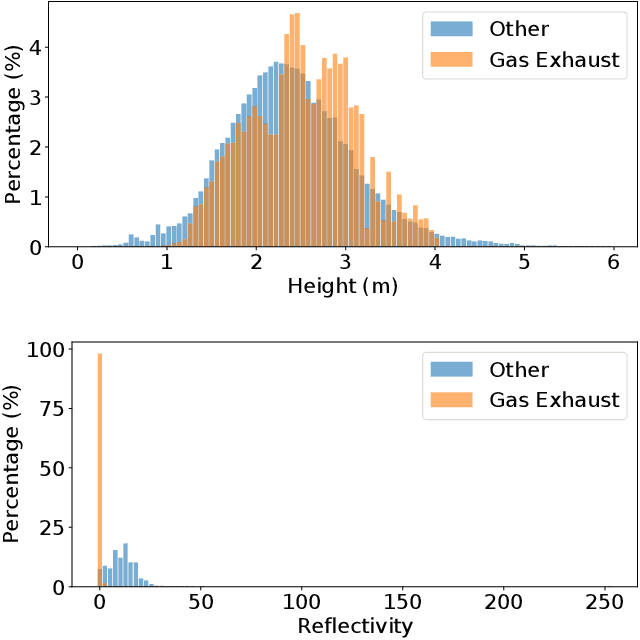
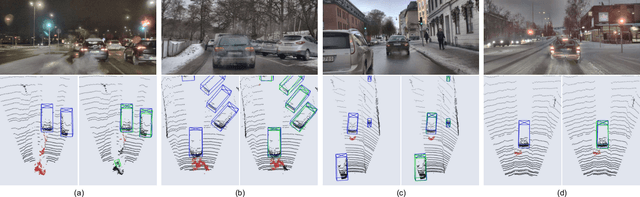
LiDAR sensors used in autonomous driving applications are negatively affected by adverse weather conditions. One common, but understudied effect, is the condensation of vehicle gas exhaust in cold weather. This everyday phenomenon can severely impact the quality of LiDAR measurements, resulting in a less accurate environment perception by creating artifacts like ghost object detections. In the literature, the semantic segmentation of adverse weather effects like rain and fog is achieved using learning-based approaches. However, such methods require large sets of labeled data, which can be extremely expensive and laborious to get. We address this problem by presenting a two-step approach for the detection of condensed vehicle gas exhaust. First, we identify for each vehicle in a scene its emission area and detect gas exhaust if present. Then, isolated clouds are detected by modeling through time the regions of space where gas exhaust is likely to be present. We test our method on real urban data, showing that our approach can reliably detect gas exhaust in different scenarios, making it appealing for offline pre-labeling and online applications such as ghost object detection.
MPC with Learned Residual Dynamics with Application on Omnidirectional MAVs
Jul 04, 2022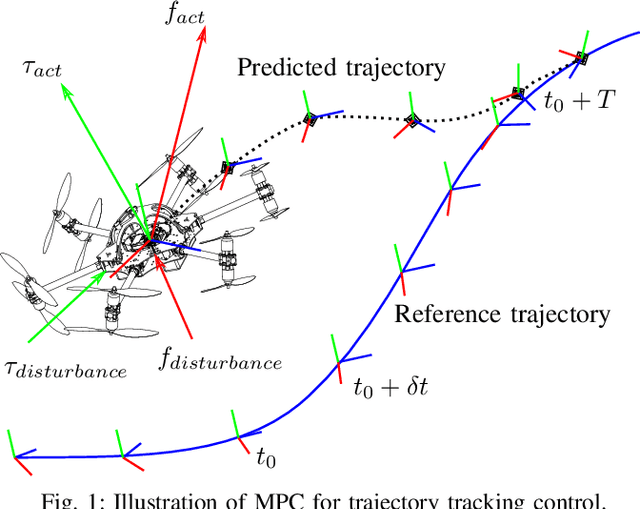
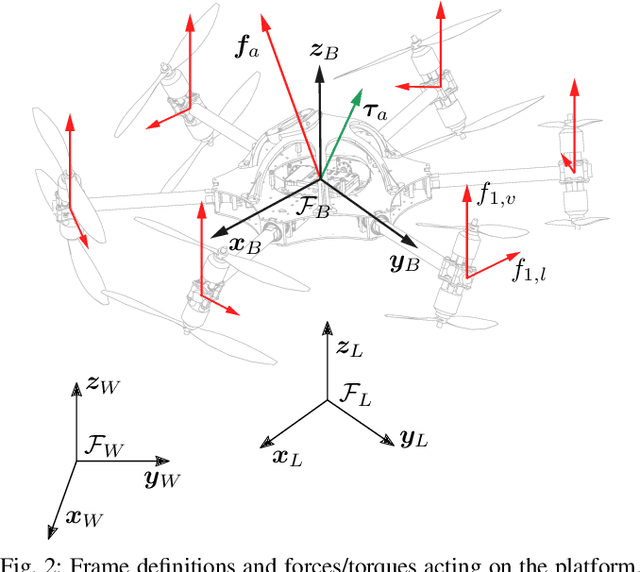
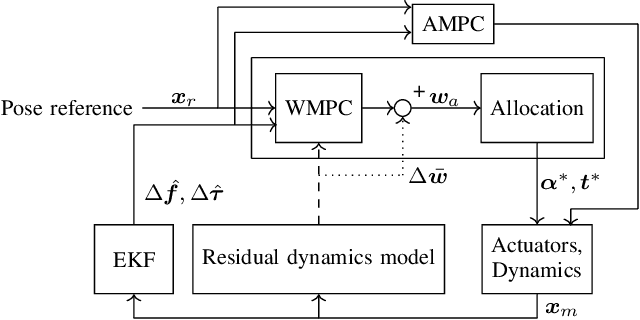
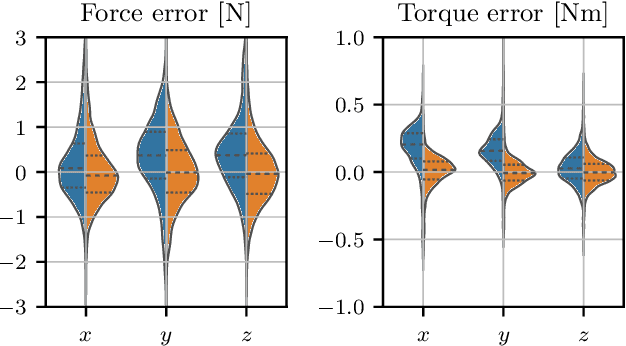
The growing field of aerial manipulation often relies on fully actuated or omnidirectional micro aerial vehicles (OMAVs) which can apply arbitrary forces and torques while in contact with the environment. Control methods are usually based on model-free approaches, separating a high-level wrench controller from an actuator allocation. If necessary, disturbances are rejected by online disturbance observers. However, while being general, this approach often produces sub-optimal control commands and cannot incorporate constraints given by the platform design. We present two model-based approaches to control OMAVs for the task of trajectory tracking while rejecting disturbances. The first one optimizes wrench commands and compensates model errors by a model learned from experimental data. The second one optimizes low-level actuator commands, allowing to exploit an allocation nullspace and to consider constraints given by the actuator hardware. The efficacy and real-time feasibility of both approaches is shown and evaluated in real-world experiments.