 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
KATANA: Simple Post-Training Robustness Using Test Time Augmentations
Sep 16, 2021

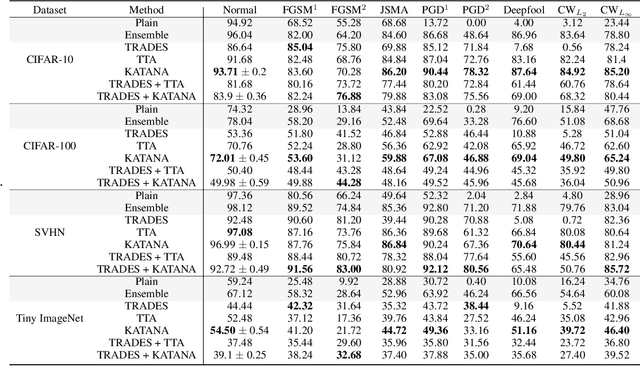

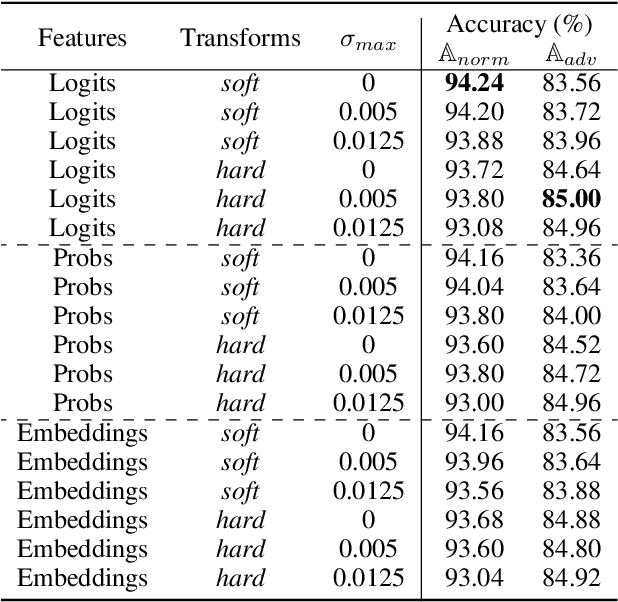
Although Deep Neural Networks (DNNs) achieve excellent performance on many real-world tasks, they are highly vulnerable to adversarial attacks. A leading defense against such attacks is adversarial training, a technique in which a DNN is trained to be robust to adversarial attacks by introducing adversarial noise to its input. This procedure is effective but must be done during the training phase. In this work, we propose a new simple and easy-to-use technique, KATANA, for robustifying an existing pretrained DNN without modifying its weights. For every image, we generate N randomized Test Time Augmentations (TTAs) by applying diverse color, blur, noise, and geometric transforms. Next, we utilize the DNN's logits output to train a simple random forest classifier to predict the real class label. Our strategy achieves state-of-the-art adversarial robustness on diverse attacks with minimal compromise on the natural images' classification. We test KATANA also against two adaptive white-box attacks and it shows excellent results when combined with adversarial training. Code is available in https://github.com/giladcohen/KATANA.
Privacy-Preserving Face Recognition with Learnable Privacy Budgets in Frequency Domain
Jul 19, 2022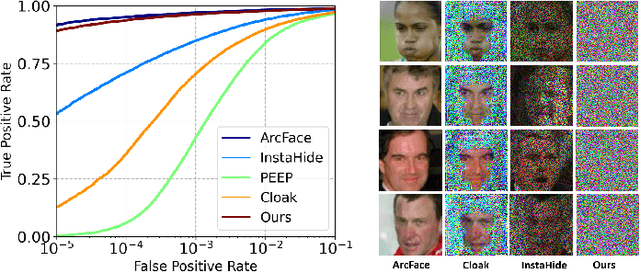

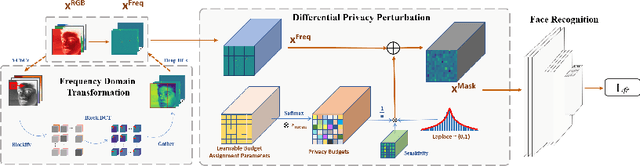
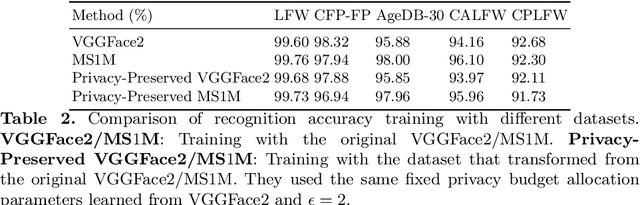
Face recognition technology has been used in many fields due to its high recognition accuracy, including the face unlocking of mobile devices, community access control systems, and city surveillance. As the current high accuracy is guaranteed by very deep network structures, facial images often need to be transmitted to third-party servers with high computational power for inference. However, facial images visually reveal the user's identity information. In this process, both untrusted service providers and malicious users can significantly increase the risk of a personal privacy breach. Current privacy-preserving approaches to face recognition are often accompanied by many side effects, such as a significant increase in inference time or a noticeable decrease in recognition accuracy. This paper proposes a privacy-preserving face recognition method using differential privacy in the frequency domain. Due to the utilization of differential privacy, it offers a guarantee of privacy in theory. Meanwhile, the loss of accuracy is very slight. This method first converts the original image to the frequency domain and removes the direct component termed DC. Then a privacy budget allocation method can be learned based on the loss of the back-end face recognition network within the differential privacy framework. Finally, it adds the corresponding noise to the frequency domain features. Our method performs very well with several classical face recognition test sets according to the extensive experiments.
Routing and Placement of Macros using Deep Reinforcement Learning
May 19, 2022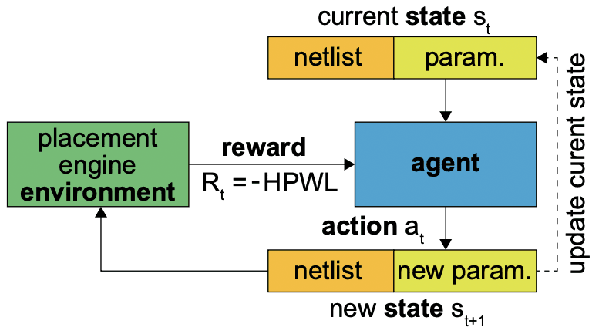
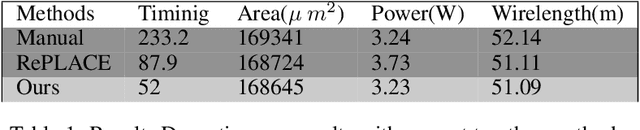
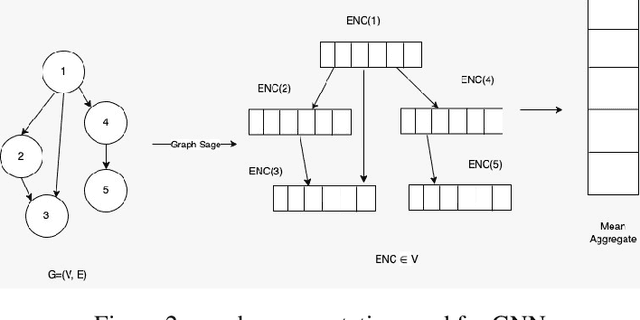
Chip placement has been one of the most time consuming task in any semi conductor area, Due to this negligence, many projects are pushed and chips availability in real markets get delayed. An engineer placing macros on a chip also needs to place it optimally to reduce the three important factors like power, performance and time. Looking at these prior problems we wanted to introduce a new method using Reinforcement Learning where we train the model to place the nodes of a chip netlist onto a chip canvas. We want to build a neural architecture that will accurately reward the agent across a wide variety of input netlist correctly.
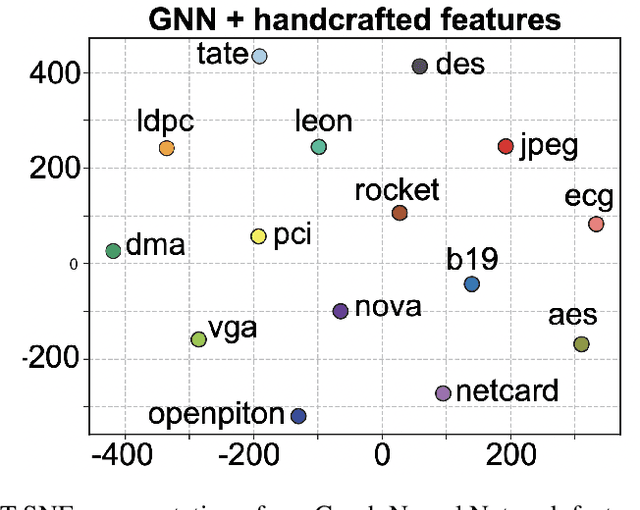
Multiple Kernel Clustering with Dual Noise Minimization
Jul 13, 2022
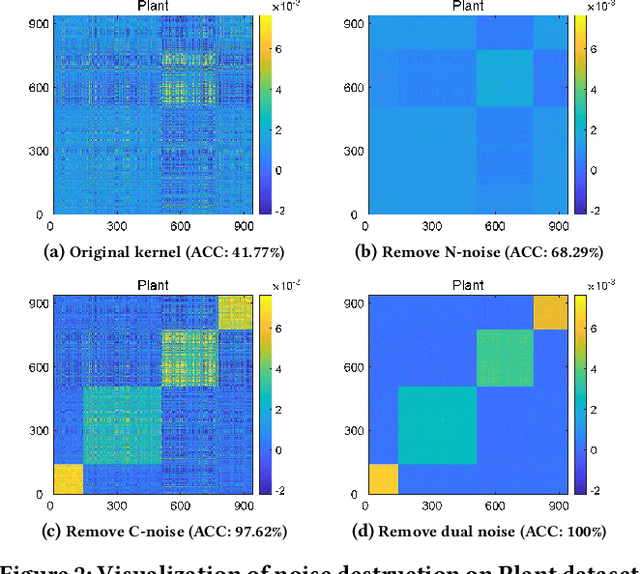
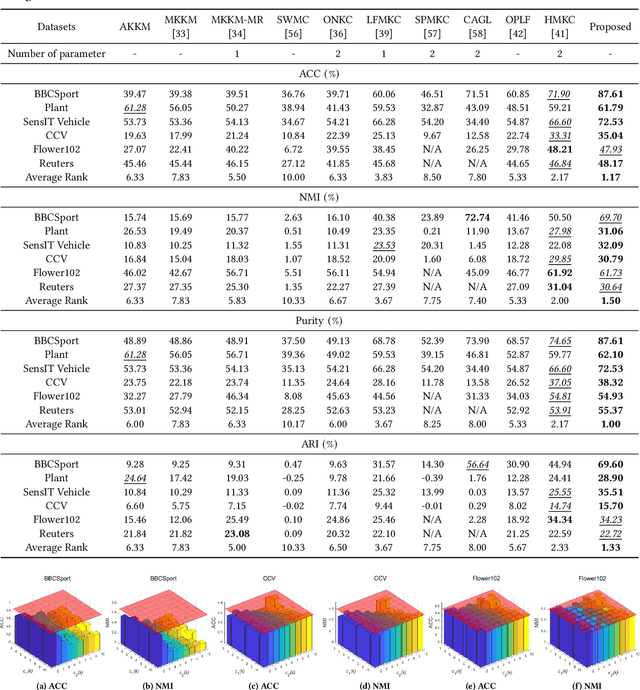
Clustering is a representative unsupervised method widely applied in multi-modal and multi-view scenarios. Multiple kernel clustering (MKC) aims to group data by integrating complementary information from base kernels. As a representative, late fusion MKC first decomposes the kernels into orthogonal partition matrices, then learns a consensus one from them, achieving promising performance recently. However, these methods fail to consider the noise inside the partition matrix, preventing further improvement of clustering performance. We discover that the noise can be disassembled into separable dual parts, i.e. N-noise and C-noise (Null space noise and Column space noise). In this paper, we rigorously define dual noise and propose a novel parameter-free MKC algorithm by minimizing them. To solve the resultant optimization problem, we design an efficient two-step iterative strategy. To our best knowledge, it is the first time to investigate dual noise within the partition in the kernel space. We observe that dual noise will pollute the block diagonal structures and incur the degeneration of clustering performance, and C-noise exhibits stronger destruction than N-noise. Owing to our efficient mechanism to minimize dual noise, the proposed algorithm surpasses the recent methods by large margins.
CLTS-GAN: Color-Lighting-Texture-Specular Reflection Augmentation for Colonoscopy
Jun 29, 2022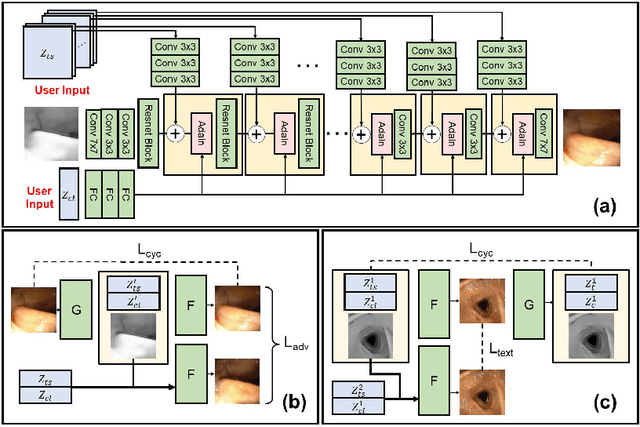


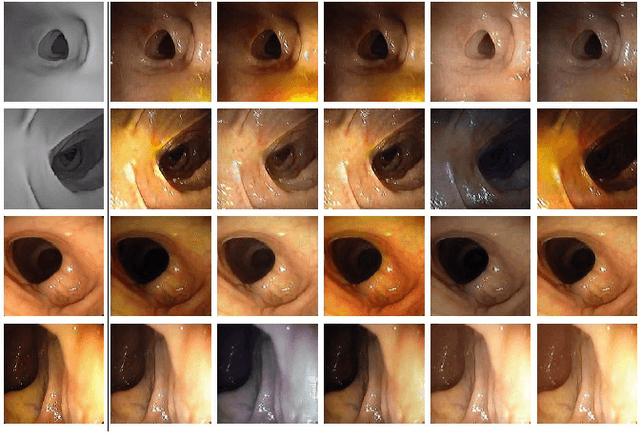
Automated analysis of optical colonoscopy (OC) video frames (to assist endoscopists during OC) is challenging due to variations in color, lighting, texture, and specular reflections. Previous methods either remove some of these variations via preprocessing (making pipelines cumbersome) or add diverse training data with annotations (but expensive and time-consuming). We present CLTS-GAN, a new deep learning model that gives fine control over color, lighting, texture, and specular reflection synthesis for OC video frames. We show that adding these colonoscopy-specific augmentations to the training data can improve state-of-the-art polyp detection/segmentation methods as well as drive next generation of OC simulators for training medical students. The code and pre-trained models for CLTS-GAN are available on Computational Endoscopy Platform GitHub (https://github.com/nadeemlab/CEP).
Position-enhanced and Time-aware Graph Convolutional Network for Sequential Recommendations
Jul 12, 2021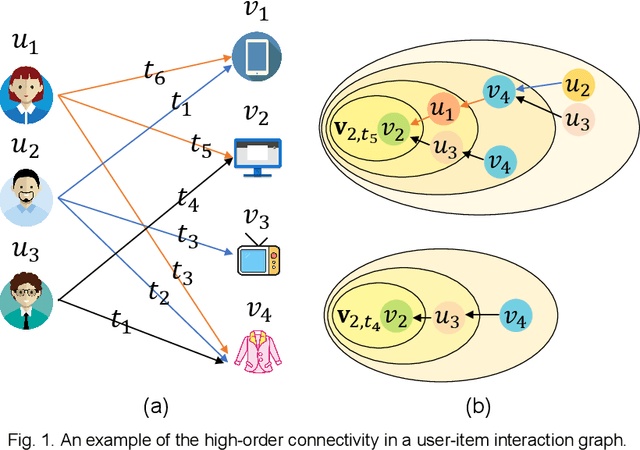

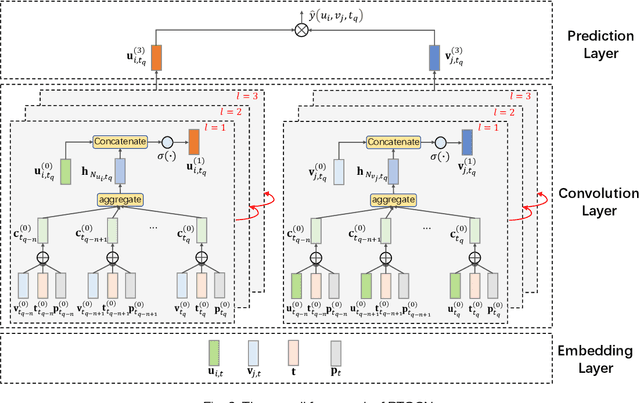

Most of the existing deep learning-based sequential recommendation approaches utilize the recurrent neural network architecture or self-attention to model the sequential patterns and temporal influence among a user's historical behavior and learn the user's preference at a specific time. However, these methods have two main drawbacks. First, they focus on modeling users' dynamic states from a user-centric perspective and always neglect the dynamics of items over time. Second, most of them deal with only the first-order user-item interactions and do not consider the high-order connectivity between users and items, which has recently been proved helpful for the sequential recommendation. To address the above problems, in this article, we attempt to model user-item interactions by a bipartite graph structure and propose a new recommendation approach based on a Position-enhanced and Time-aware Graph Convolutional Network (PTGCN) for the sequential recommendation. PTGCN models the sequential patterns and temporal dynamics between user-item interactions by defining a position-enhanced and time-aware graph convolution operation and learning the dynamic representations of users and items simultaneously on the bipartite graph with a self-attention aggregator. Also, it realizes the high-order connectivity between users and items by stacking multi-layer graph convolutions. To demonstrate the effectiveness of PTGCN, we carried out a comprehensive evaluation of PTGCN on three real-world datasets of different sizes compared with a few competitive baselines. Experimental results indicate that PTGCN outperforms several state-of-the-art models in terms of two commonly-used evaluation metrics for ranking.
Context Unaware Knowledge Distillation for Image Retrieval
Jul 19, 2022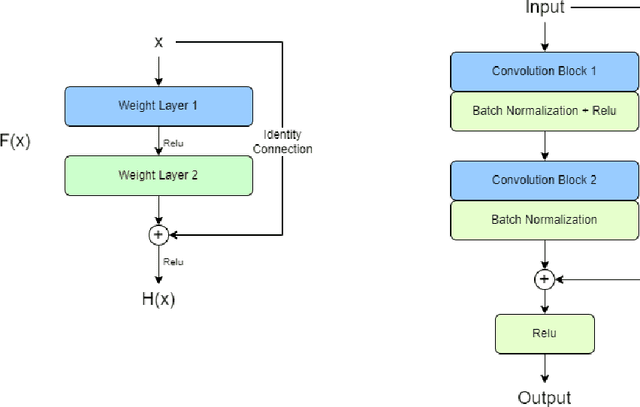
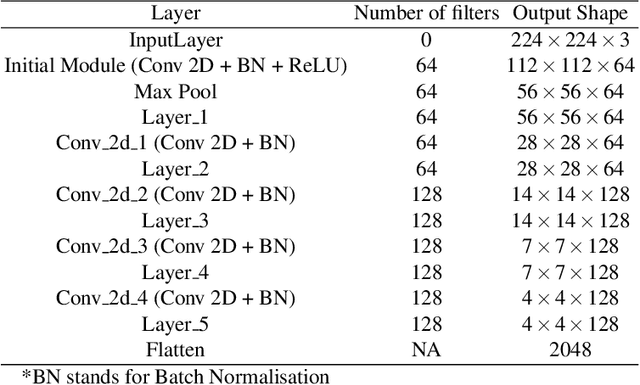

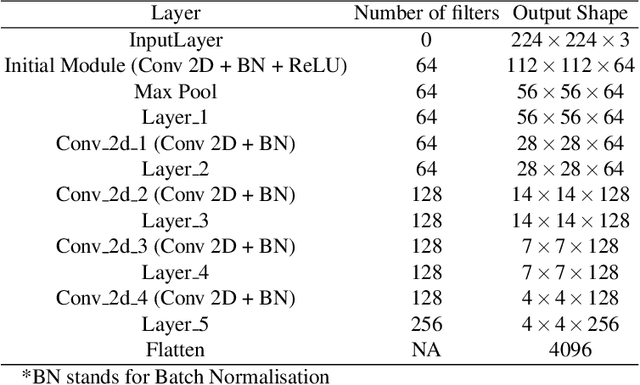
Existing data-dependent hashing methods use large backbone networks with millions of parameters and are computationally complex. Existing knowledge distillation methods use logits and other features of the deep (teacher) model and as knowledge for the compact (student) model, which requires the teacher's network to be fine-tuned on the context in parallel with the student model on the context. Training teacher on the target context requires more time and computational resources. In this paper, we propose context unaware knowledge distillation that uses the knowledge of the teacher model without fine-tuning it on the target context. We also propose a new efficient student model architecture for knowledge distillation. The proposed approach follows a two-step process. The first step involves pre-training the student model with the help of context unaware knowledge distillation from the teacher model. The second step involves fine-tuning the student model on the context of image retrieval. In order to show the efficacy of the proposed approach, we compare the retrieval results, no. of parameters and no. of operations of the student models with the teacher models under different retrieval frameworks, including deep cauchy hashing (DCH) and central similarity quantization (CSQ). The experimental results confirm that the proposed approach provides a promising trade-off between the retrieval results and efficiency. The code used in this paper is released publicly at \url{https://github.com/satoru2001/CUKDFIR}.
Efficient and Scalable Recommendation via Item-Item Graph Partitioning
Jul 13, 2022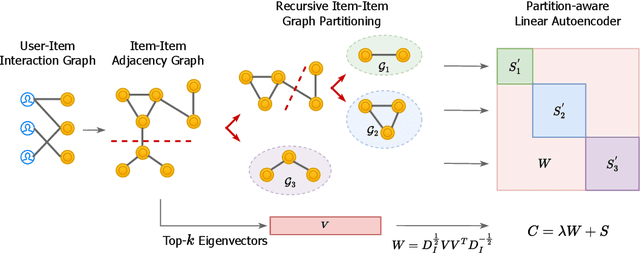
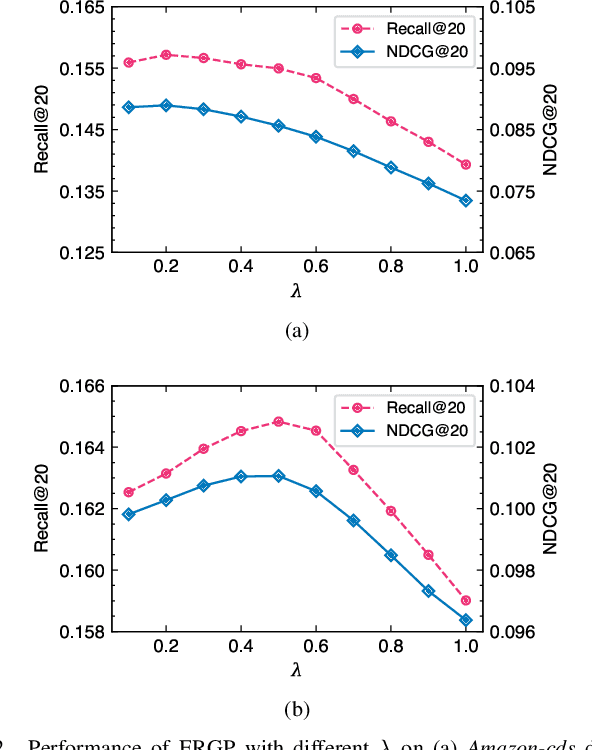
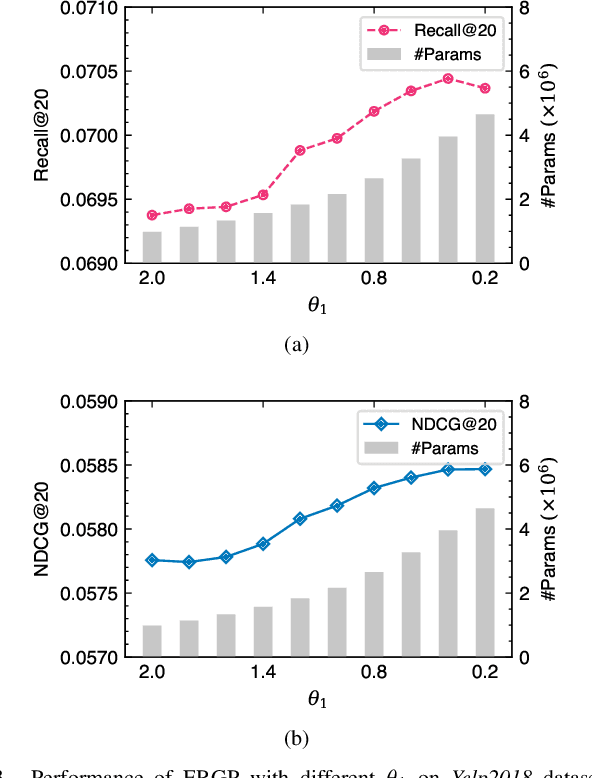
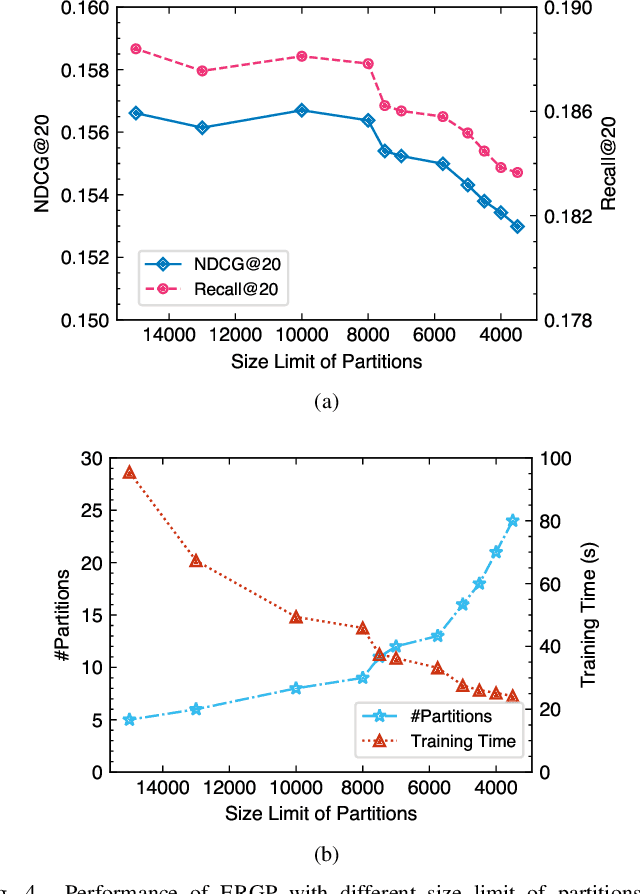
Collaborative filtering (CF) is a widely searched problem in recommender systems. Linear autoencoder is a kind of well-established method for CF, which estimates item-item relations through encoding user-item interactions. Despite the excellent performance of linear autoencoders, the rapidly increasing computational and storage costs caused by the growing number of items limit their scalabilities in large-scale real-world scenarios. Recently, graph-based approaches have achieved success on CF with high scalability, and have been shown to have commonalities with linear autoencoders in user-item interaction modeling. Motivated by this, we propose an efficient and scalable recommendation via item-item graph partitioning (ERGP), aiming to address the limitations of linear autoencoders. In particular, a recursive graph partitioning strategy is proposed to ensure that the item set is divided into several partitions of finite size. Linear autoencoders encode user-item interactions within partitions while preserving global information across the entire item set. This allows ERGP to have guaranteed efficiency and high scalability when the number of items increases. Experiments conducted on 3 public datasets and 3 open benchmarking datasets demonstrate the effectiveness of ERGP, which outperforms state-of-the-art models with lower training time and storage costs.
Time-Travel Rephotography
Dec 22, 2020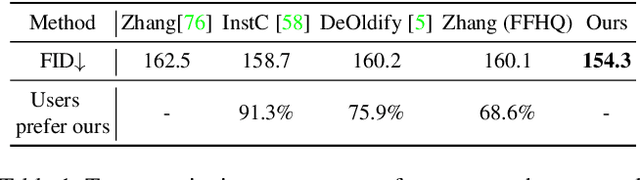
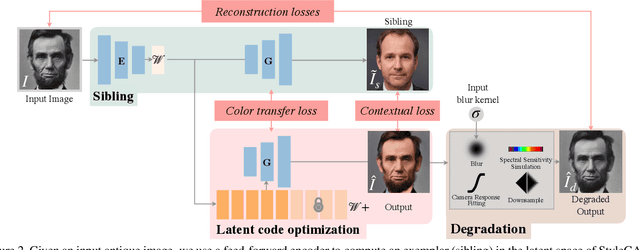


Many historical people are captured only in old, faded, black and white photos, that have been distorted by the limitations of early cameras and the passage of time. This paper simulates traveling back in time with a modern camera to rephotograph famous subjects. Unlike conventional image restoration filters which apply independent operations like denoising, colorization, and superresolution, we leverage the StyleGAN2 framework to project old photos into the space of modern high-resolution photos, achieving all of these effects in a unified framework. A unique challenge with this approach is capturing the identity and pose of the photo's subject and not the many artifacts in low-quality antique photos. Our comparisons to current state-of-the-art restoration filters show significant improvements and compelling results for a variety of important historical people.
Resolution Limits of Non-Adaptive 20 Questions Search for a Moving Target
Jun 14, 2022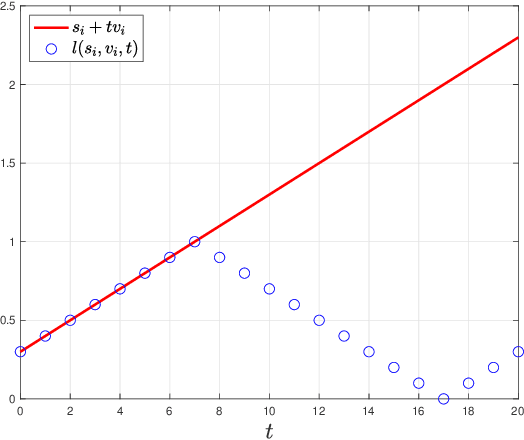
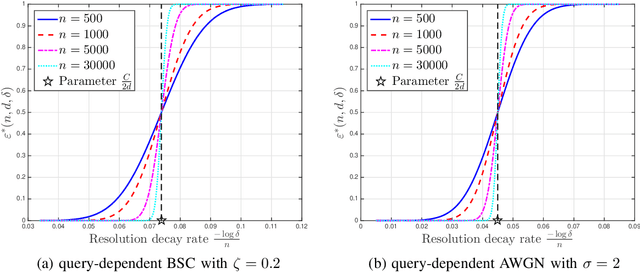
Using the 20 questions estimation framework with query-dependent noise, we study non-adaptive search strategies for a moving target over the unit cube with unknown initial location and velocities under a piecewise constant velocity model. In this search problem, there is an oracle who knows the instantaneous location of the target at any time. Our task is to query the oracle as few times as possible to accurately estimate the location of the target at any specified time. We first study the case where the oracle's answer to each query is corrupted by discrete noise and then generalize our results to the case of additive white Gaussian noise. In our formulation, the performance criterion is the resolution, which is defined as the maximal $L_\infty$ distance between the true locations and estimated locations. We characterize the minimal resolution of an optimal non-adaptive query procedure with a finite number of queries by deriving non-asymptotic and asymptotic bounds. Our bounds are tight in the first-order asymptotic sense when the number of queries satisfies a certain condition and our bounds are tight in the stronger second-order asymptotic sense when the target moves with a constant velocity. To prove our results, we relate the current problem to channel coding, borrow ideas from finite blocklength information theory and construct bounds on the number of possible quantized target trajectories.