 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Policy Gradient and Actor-Critic Learning in Continuous Time and Space: Theory and Algorithms
Nov 22, 2021
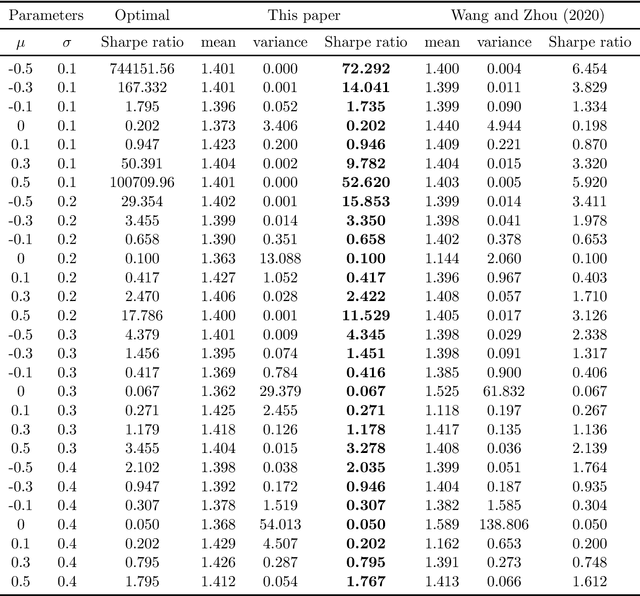
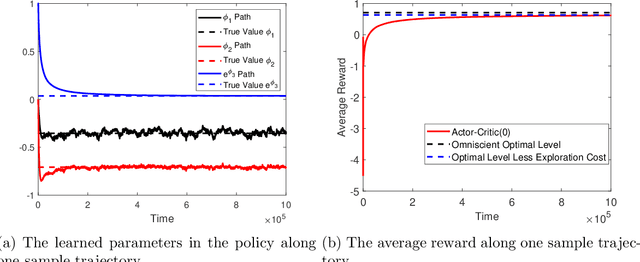
We study policy gradient (PG) for reinforcement learning in continuous time and space under the regularized exploratory formulation developed by Wang et al. (2020). We represent the gradient of the value function with respect to a given parameterized stochastic policy as the expected integration of an auxiliary running reward function that can be evaluated using samples and the current value function. This effectively turns PG into a policy evaluation (PE) problem, enabling us to apply the martingale approach recently developed by Jia and Zhou (2021) for PE to solve our PG problem. Based on this analysis, we propose two types of the actor-critic algorithms for RL, where we learn and update value functions and policies simultaneously and alternatingly. The first type is based directly on the aforementioned representation which involves future trajectories and hence is offline. The second type, designed for online learning, employs the first-order condition of the policy gradient and turns it into martingale orthogonality conditions. These conditions are then incorporated using stochastic approximation when updating policies. Finally, we demonstrate the algorithms by simulations in two concrete examples.
Predictive Maintenance using Machine Learning
May 19, 2022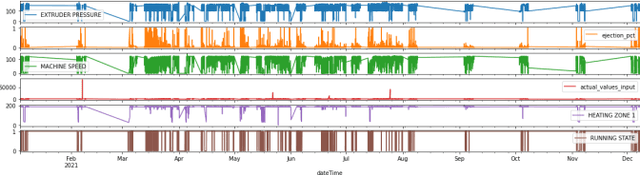
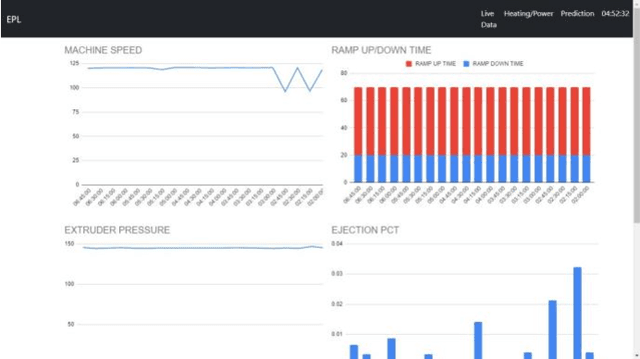
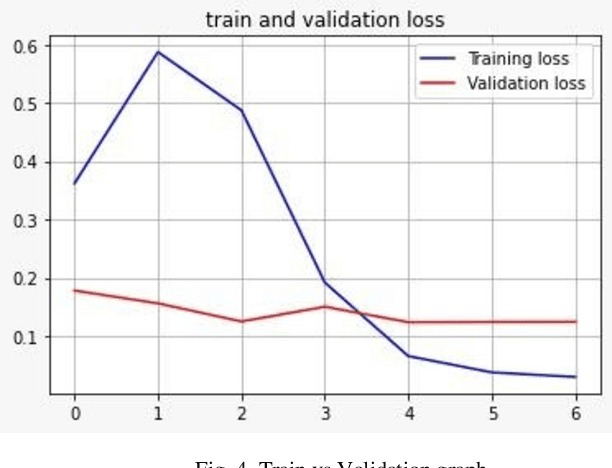
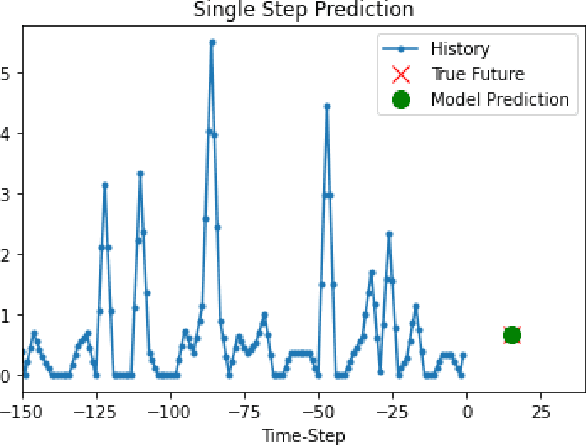
Predictive maintenance (PdM) is a concept, which is implemented to effectively manage maintenance plans of the assets by predicting their failures with data driven techniques. In these scenarios, data is collected over a certain period of time to monitor the state of equipment. The objective is to find some correlations and patterns that can help predict and ultimately prevent failures. Equipment in manufacturing industry are often utilized without a planned maintenance approach. Such practise frequently results in unexpected downtime, owing to certain unexpected failures. In scheduled maintenance, the condition of the manufacturing equipment is checked after fixed time interval and if any fault occurs, the component is replaced to avoid unexpected equipment stoppages. On the flip side, this leads to increase in time for which machine is non-functioning and cost of carrying out the maintenance. The emergence of Industry 4.0 and smart systems have led to increasing emphasis on predictive maintenance (PdM) strategies that can reduce the cost of downtime and increase the availability (utilization rate) of manufacturing equipment. PdM also has the potential to bring about new sustainable practices in manufacturing by fully utilizing the useful lives of components.
NeurAR: Neural Uncertainty for Autonomous 3D Reconstruction
Jul 22, 2022
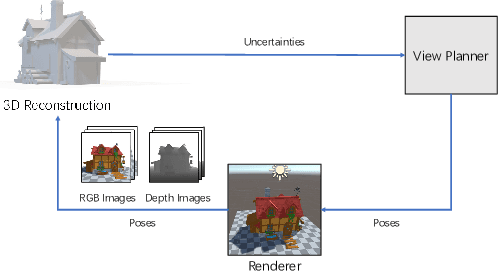
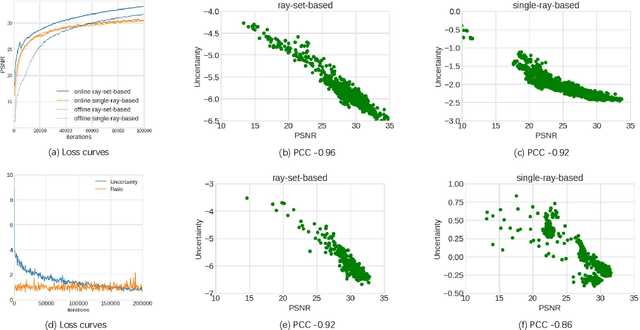

Implicit neural representations have shown compelling results in offline 3D reconstruction and also recently demonstrated the potential for online SLAM systems. However, applying them to autonomous 3D reconstruction, where robots are required to explore a scene and plan a view path for the reconstruction, has not been studied. In this paper, we explore for the first time the possibility of using implicit neural representations for autonomous 3D scene reconstruction by addressing two key challenges: 1) seeking a criterion to measure the quality of the candidate viewpoints for the view planning based on the new representations, and 2) learning the criterion from data that can generalize to different scenes instead of hand-crafting one. For the first challenge, a proxy of Peak Signal-to-Noise Ratio (PSNR) is proposed to quantify a viewpoint quality. The proxy is acquired by treating the color of a spatial point in a scene as a random variable under a Gaussian distribution rather than a deterministic one; the variance of the distribution quantifies the uncertainty of the reconstruction and composes the proxy. For the second challenge, the proxy is optimized jointly with the parameters of an implicit neural network for the scene. With the proposed view quality criterion, we can then apply the new representations to autonomous 3D reconstruction. Our method demonstrates significant improvements on various metrics for the rendered image quality and the geometry quality of the reconstructed 3D models when compared with variants using TSDF or reconstruction without view planning.
Water Surface Patch Classification Using Mixture Augmentation for River Scum Index
Jul 13, 2022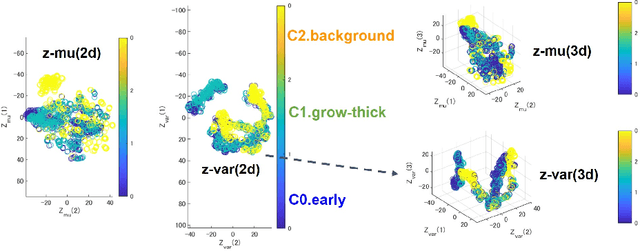
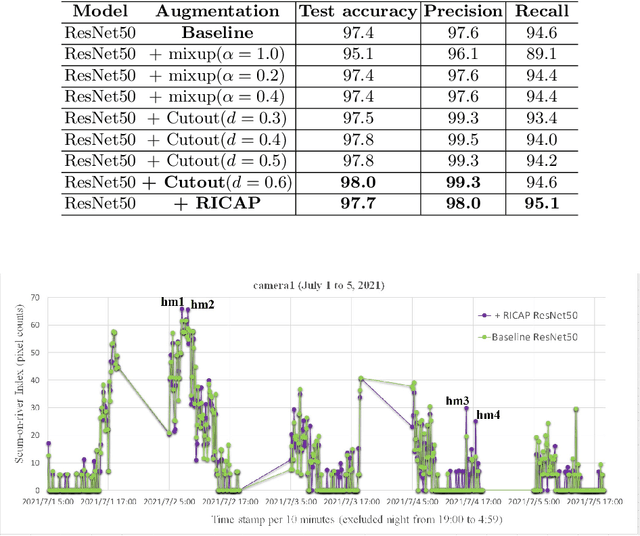
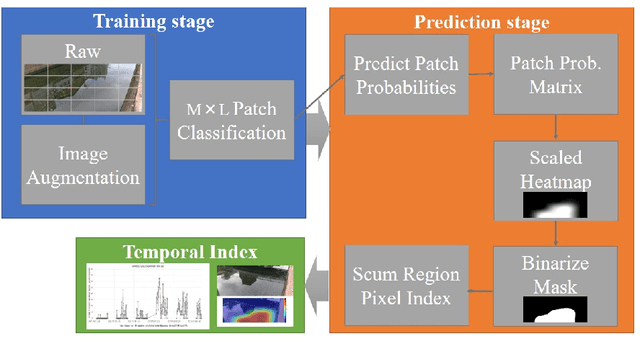

Urban rivers provide a water environment that influences residential living. River surface monitoring has become crucial for making decisions about where to prioritize cleaning and when to automatically start the cleaning treatment. We focus on the organic mud, or "scum" that accumulates on the river's surface and gives it its peculiar odor and external economic effects on the landscape. Because of its feature of a sparsely distributed and unstable pattern of organic shape, automating the monitoring has proved difficult. We propose a patch classification pipeline to detect scum features on the river surface using mixture image augmentation to increase the diversity between the scum floating on the river and the entangled background on the river surface reflected by nearby structures like buildings, bridges, poles, and barriers. Furthermore, we propose a scum index covered on rivers to help monitor worse grade online, collecting floating scum and deciding on chemical treatment policies. Finally, we show how to use our method on a time series dataset with frames every ten minutes recording river scum events over several days. We discuss the value of our pipeline and its experimental findings.
Learning state machines via efficient hashing of future traces
Jul 04, 2022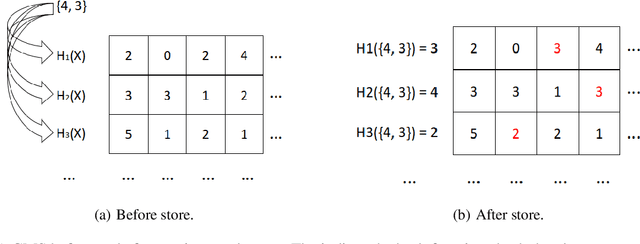

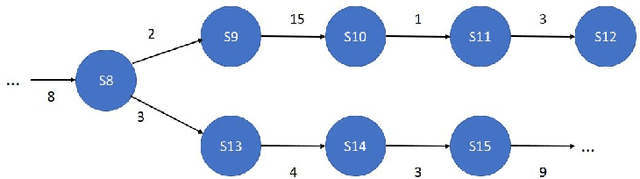
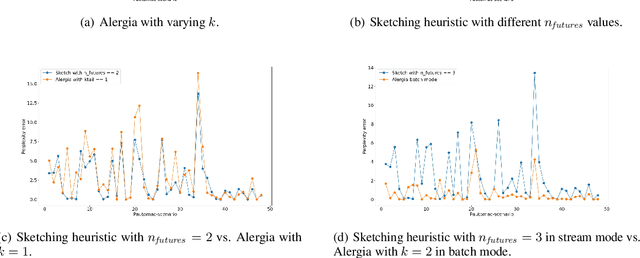
State machines are popular models to model and visualize discrete systems such as software systems, and to represent regular grammars. Most algorithms that passively learn state machines from data assume all the data to be available from the beginning and they load this data into memory. This makes it hard to apply them to continuously streaming data and results in large memory requirements when dealing with large datasets. In this paper we propose a method to learn state machines from data streams using the count-min-sketch data structure to reduce memory requirements. We apply state merging using the well-known red-blue-framework to reduce the search space. We implemented our approach in an established framework for learning state machines, and evaluated it on a well know dataset to provide experimental data, showing the effectiveness of our approach with respect to quality of the results and run-time.
Spectral-Efficiency of Cell-Free Massive MIMO with Multicarrier-Division Duplex
Jun 17, 2022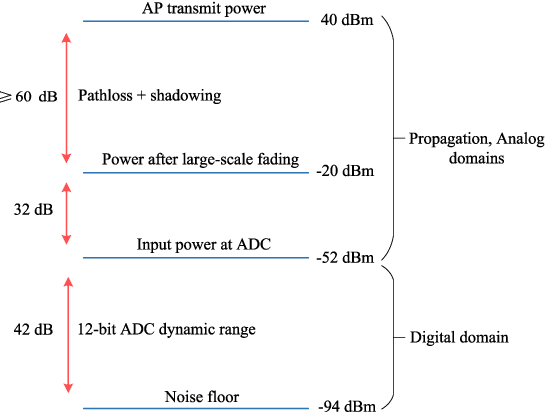
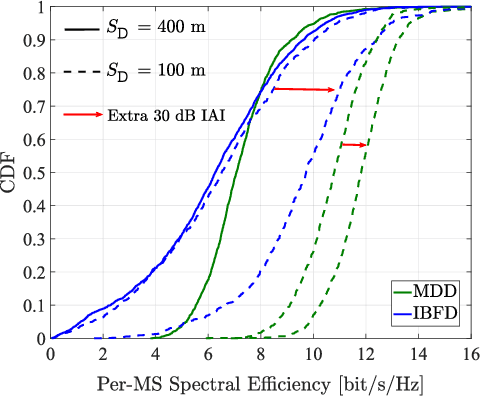
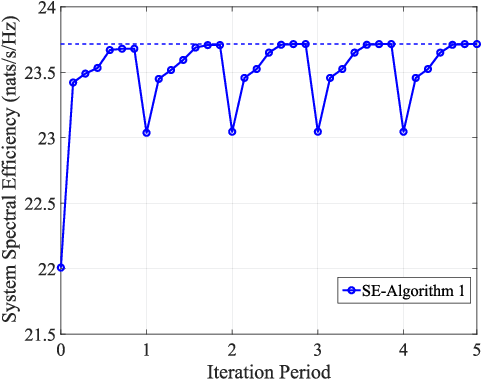
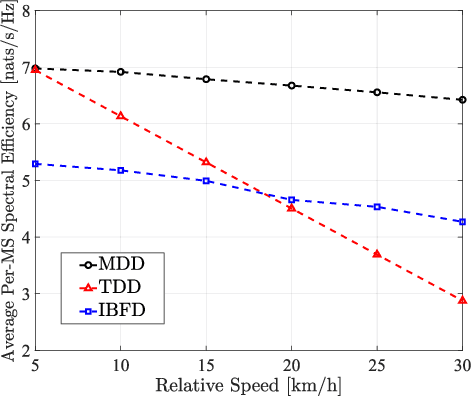
A multicarrier-division duplex (MDD)-based cell-free (CF) scheme, namely MDD-CF, is proposed, which enables downlink (DL) data and uplink (UL) data or pilots to be concurrently transmitted on mutually orthogonal subcarriers in distributed CF massive MIMO (mMIMO) systems. To demonstrate the advantages of MDD-CF, we firstly study the spectral-efficiency (SE) performance in terms of one coherence interval (CT) associated with access point (AP)-selection, power- and subcarrier-allocation. Since the formulated SE optimization is a mixed-integer non-convex problem that is NP-hard to solve, we leverage the inherent association between involved variables to transform it into a continuous-integer convex-concave problem. Then, a quadratic transform (QT)-assisted iterative algorithm is proposed to achieve SE maximization. Next, we extend our study to the case of one radio frame consisting of several CT intervals. In this regard, a novel two-phase CT interval (TPCT) scheme is designed to not only improve the SE in radio frame but also provide consistent data transmissions over fast time-varying channels. Correspondingly, to facilitate the optimization, we propose a two-step iterative algorithm by building the connections between two phases in TPCT through an iteration factor. Simulation results show that, MDD-CF can significantly outperform in-band full duplex (IBFD)-CF due to the efficient interference management. Furthermore, compared with time-division duplex (TDD)-CF, MDD-CF is more robust to high-mobility scenarios and achieves better SE performance.
Controlling the Cascade: Kinematic Planning for N-ball Toss Juggling
Jul 04, 2022
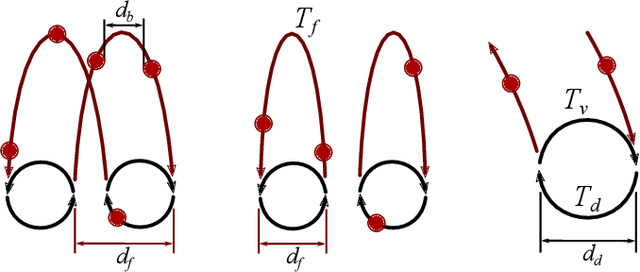
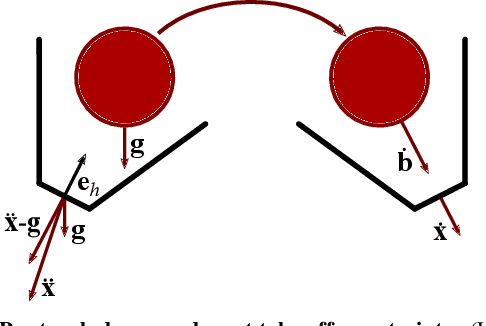
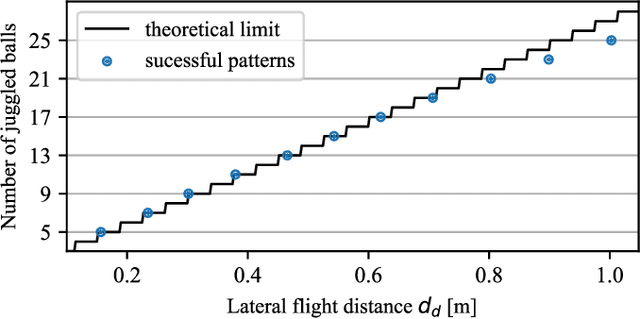
Dynamic movements are ubiquitous in human motor behavior as they tend to be more efficient and can solve a broader range of skill domains than their quasi-static counterparts. For decades, robotic juggling tasks have been among the most frequently studied dynamic manipulation problems since the required dynamic dexterity can be scaled to arbitrarily high difficulty. However, successful approaches have been limited to basic juggling skills, indicating a lack of understanding of the required constraints for dexterous toss juggling. We present a detailed analysis of the toss juggling task, identifying the key challenges and formalizing it as a trajectory optimization problem. Building on our state-of-the-art, real-world toss juggling platform, we reach the theoretical limits of toss juggling in simulation, evaluate a resulting real-time controller in environments of varying difficulty and achieve robust toss juggling of up to 17 balls on two anthropomorphic manipulators.
An Input-Output Feedback Linearization based Exponentially Stable Controller for Multi-UAV Payload Transport
Jul 10, 2022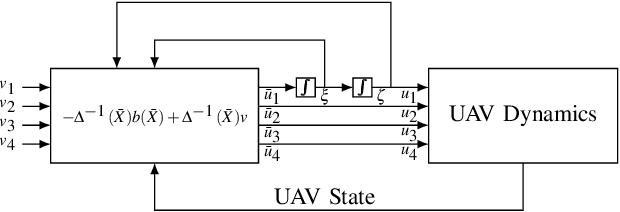
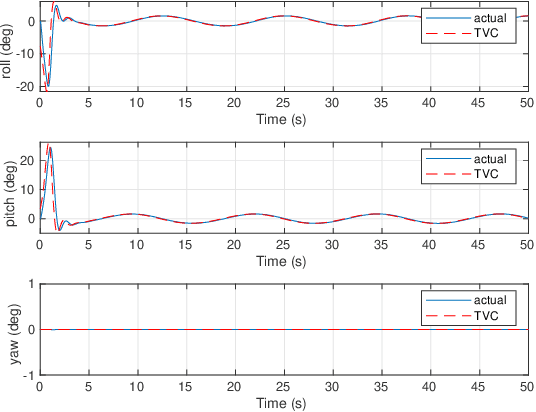
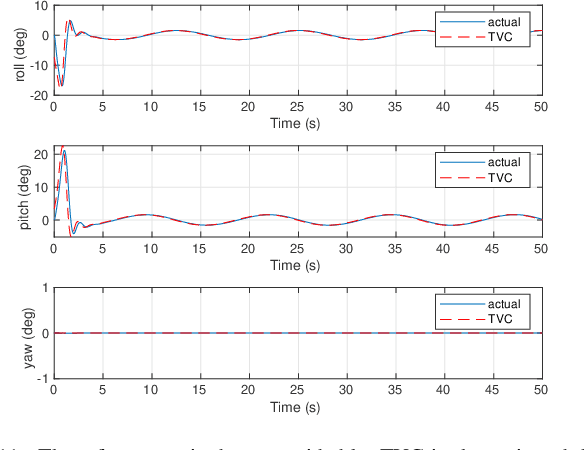
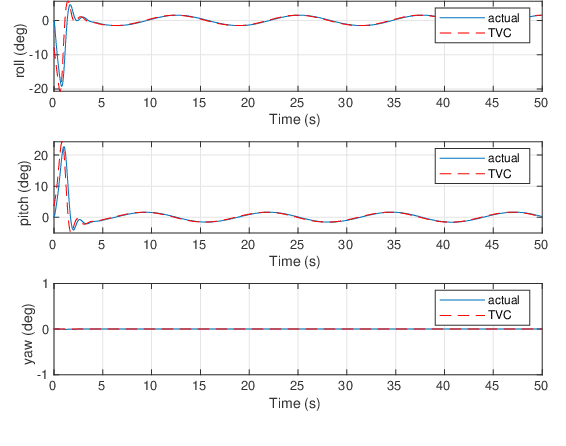
In this paper, an exponentially stable trajectory tracking controller is proposed for multi-UAV payload transport. The multi-UAV payload system has a 2-DOF magnetic spherical joint between the UAVs and the vertical rigid links of the payload frame, so the UAVs can roll or pitch freely. These vertical links are rigidly attached to the payload and cannot move. An input-output feedback linearized model is derived for the complete payload-UAV system along with thrust vectoring control for trajectory tracking of the payload. The theoretical analysis on tracking control laws shows that control law is exponentially stable, thus guaranteeing safe transportation along the desired trajectory. To validate the performance of the proposed control law, the results for a numerical simulation as well as a high-fidelity Gazebo real-time simulation are presented. Next, the robustness of the proposed controller is analyzed against two practical situations: External disturbance on the payload and payload mass uncertainty. The results clearly indicate that the proposed controller is robust and computationally efficient while achieving exponentially stable trajectory tracking.
My View is the Best View: Procedure Learning from Egocentric Videos
Jul 22, 2022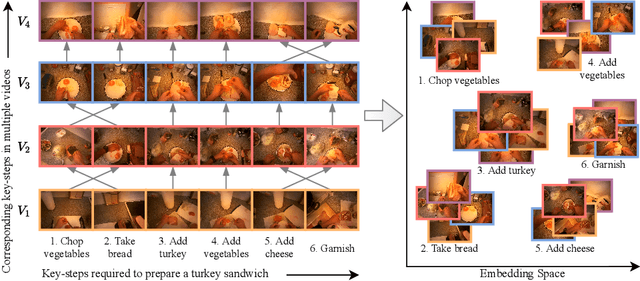


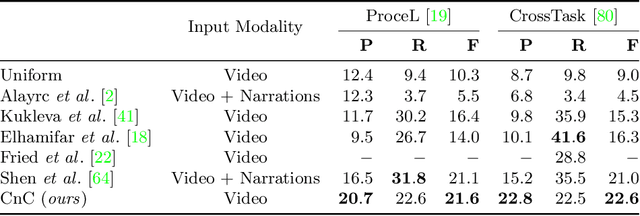
Procedure learning involves identifying the key-steps and determining their logical order to perform a task. Existing approaches commonly use third-person videos for learning the procedure, making the manipulated object small in appearance and often occluded by the actor, leading to significant errors. In contrast, we observe that videos obtained from first-person (egocentric) wearable cameras provide an unobstructed and clear view of the action. However, procedure learning from egocentric videos is challenging because (a) the camera view undergoes extreme changes due to the wearer's head motion, and (b) the presence of unrelated frames due to the unconstrained nature of the videos. Due to this, current state-of-the-art methods' assumptions that the actions occur at approximately the same time and are of the same duration, do not hold. Instead, we propose to use the signal provided by the temporal correspondences between key-steps across videos. To this end, we present a novel self-supervised Correspond and Cut (CnC) framework for procedure learning. CnC identifies and utilizes the temporal correspondences between the key-steps across multiple videos to learn the procedure. Our experiments show that CnC outperforms the state-of-the-art on the benchmark ProceL and CrossTask datasets by 5.2% and 6.3%, respectively. Furthermore, for procedure learning using egocentric videos, we propose the EgoProceL dataset consisting of 62 hours of videos captured by 130 subjects performing 16 tasks. The source code and the dataset are available on the project page https://sid2697.github.io/egoprocel/.
MRF-UNets: Searching UNet with Markov Random Fields
Jul 13, 2022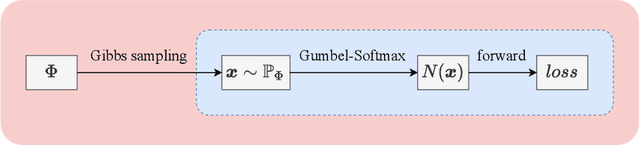
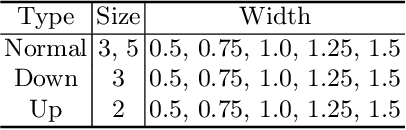
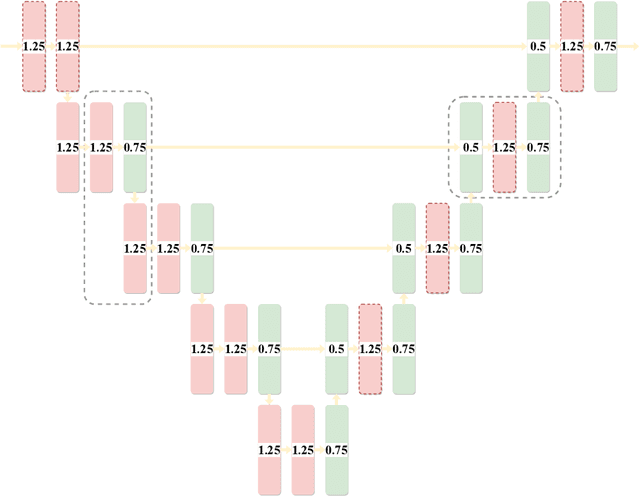
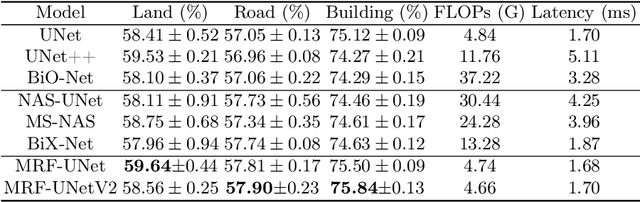
UNet [27] is widely used in semantic segmentation due to its simplicity and effectiveness. However, its manually-designed architecture is applied to a large number of problem settings, either with no architecture optimizations, or with manual tuning, which is time consuming and can be sub-optimal. In this work, firstly, we propose Markov Random Field Neural Architecture Search (MRF-NAS) that extends and improves the recent Adaptive and Optimal Network Width Search (AOWS) method [4] with (i) a more general MRF framework (ii) diverse M-best loopy inference (iii) differentiable parameter learning. This provides the necessary NAS framework to efficiently explore network architectures that induce loopy inference graphs, including loops that arise from skip connections. With UNet as the backbone, we find an architecture, MRF-UNet, that shows several interesting characteristics. Secondly, through the lens of these characteristics, we identify the sub-optimality of the original UNet architecture and further improve our results with MRF-UNetV2. Experiments show that our MRF-UNets significantly outperform several benchmarks on three aerial image datasets and two medical image datasets while maintaining low computational costs. The code is available at: https://github.com/zifuwanggg/MRF-UNets.