 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Temporal Action Detection with Global Segmentation Mask Learning
Jul 14, 2022
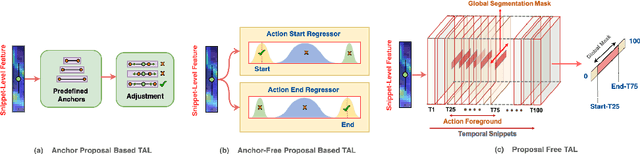
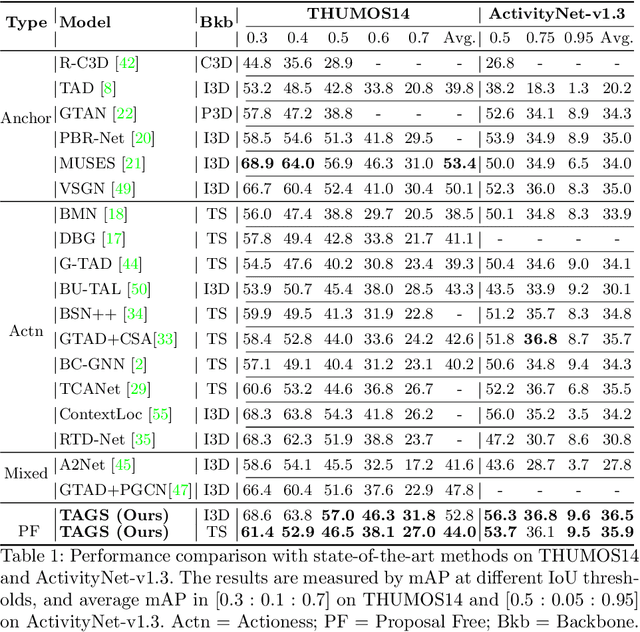
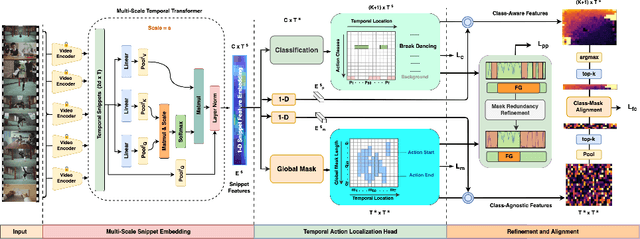
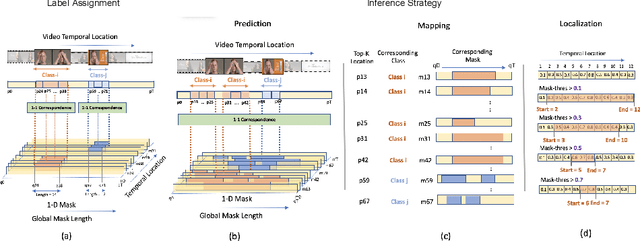
Existing temporal action detection (TAD) methods rely on generating an overwhelmingly large number of proposals per video. This leads to complex model designs due to proposal generation and/or per-proposal action instance evaluation and the resultant high computational cost. In this work, for the first time, we propose a proposal-free Temporal Action detection model with Global Segmentation mask (TAGS). Our core idea is to learn a global segmentation mask of each action instance jointly at the full video length. The TAGS model differs significantly from the conventional proposal-based methods by focusing on global temporal representation learning to directly detect local start and end points of action instances without proposals. Further, by modeling TAD holistically rather than locally at the individual proposal level, TAGS needs a much simpler model architecture with lower computational cost. Extensive experiments show that despite its simpler design, TAGS outperforms existing TAD methods, achieving new state-of-the-art performance on two benchmarks. Importantly, it is ~ 20x faster to train and ~1.6x more efficient for inference. Our PyTorch implementation of TAGS is available at https://github.com/sauradip/TAGS .
Bayesian-based Symbol Detector for Orthogonal Time Frequency Space Modulation Systems
Oct 27, 2021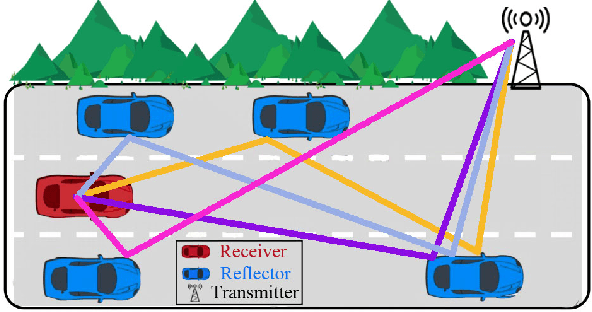
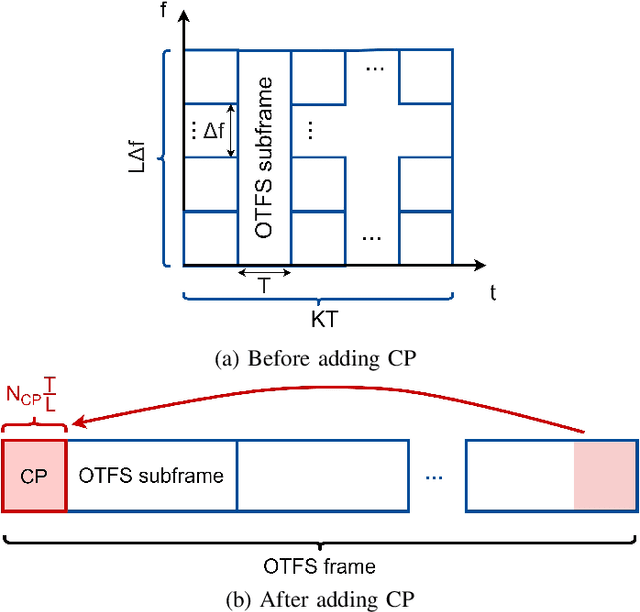

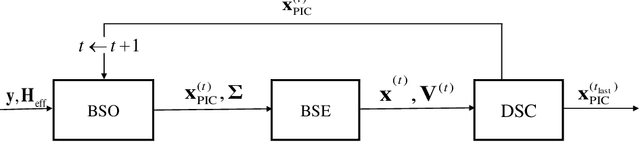
Recently, the orthogonal time frequency space (OTFS) modulation is proposed for 6G wireless system to deal with high Doppler spread. The high Doppler spread happens when the transmitted signal is reflected towards the receiver by fast moving objects (e.g. high speed cars), which causes inter-carrier interference (ICI). Recent state-of-the-art OTFS detectors fail to achieve an acceptable bit-error-rate (BER) performance as the number of mobile reflectors increases which in turn, results in high inter-carrier-interference (ICI). In this paper, we propose a novel detector for OTFS systems, referred to as the Bayesian based parallel interference and decision statistics combining (B-PIC-DSC) OTFS detector that can achieve a high BER performance, under high ICI environments. The B-PIC-DSC OTFS detector employs the PIC and DSC schemes to iteratively cancel the interference, and the Bayesian concept to take the probability measure into the consideration when refining the transmitted symbols. Our simulation results show that in contrast to the state-of-the-art OTFS detectors, the proposed detector is able to achieve a BER of less than $10^{-5}$, when SNR is over $14$ dB, under high ICI environments.
Time Complexity Analysis of Evolutionary Algorithms for 2-Hop (1,2)-Minimum Spanning Tree Problem
Oct 10, 2021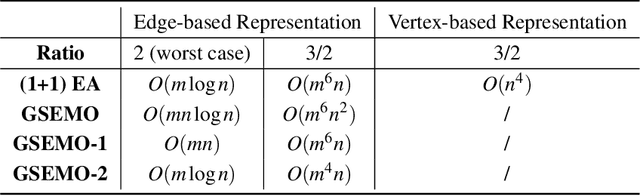

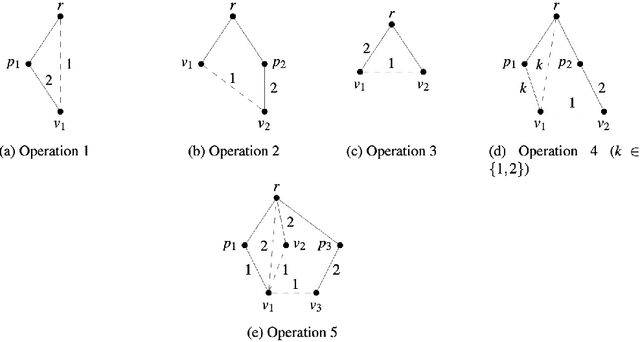
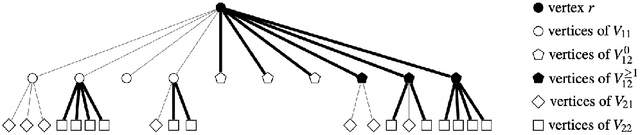
The Minimum Spanning Tree problem (abbr. MSTP) is a well-known combinatorial optimization problem that has been extensively studied by the researchers in the field of evolutionary computing to theoretically analyze the optimization performance of evolutionary algorithms. Within the paper, we consider a constrained version of the problem named 2-Hop (1,2)-Minimum Spanning Tree problem (abbr. 2H-(1,2)-MSTP) in the context of evolutionary algorithms, which has been shown to be NP-hard. Following how evolutionary algorithms are applied to solve the MSTP, we first consider the evolutionary algorithms with search points in edge-based representation adapted to the 2H-(1,2)-MSTP (including the (1+1) EA, Global Simple Evolutionary Multi-Objective Optimizer and its two variants). More specifically, we separately investigate the upper bounds on their expected time (i.e., the expected number of fitness evaluations) to obtain a $\frac{3}{2}$-approximate solution with respect to different fitness functions. Inspired by the special structure of 2-hop spanning trees, we also consider the (1+1) EA with search points in vertex-based representation that seems not so natural for the problem and give an upper bound on its expected time to obtain a $\frac{3}{2}$-approximate solution, which is better than the above mentioned ones.
A Deep Learning-Based GPR Forward Solver for Predicting B-Scans of Subsurface Objects
Jul 13, 2022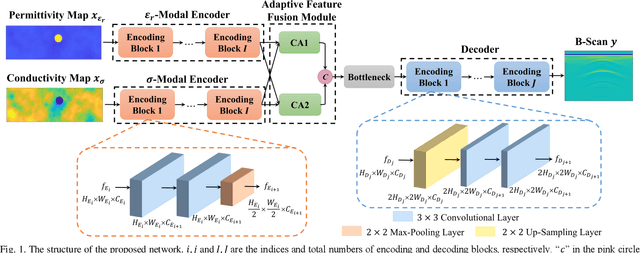
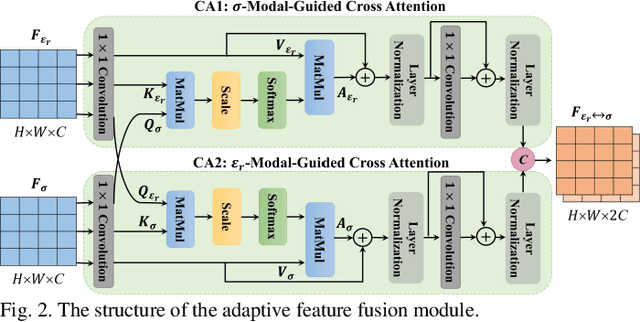
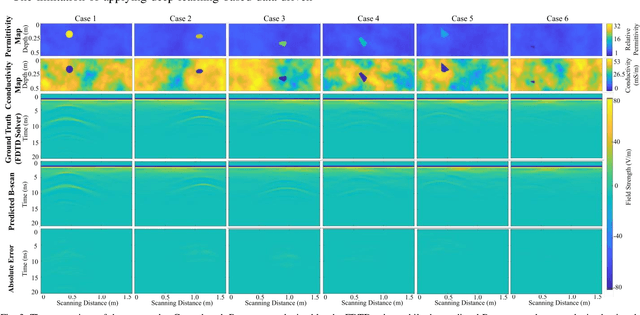
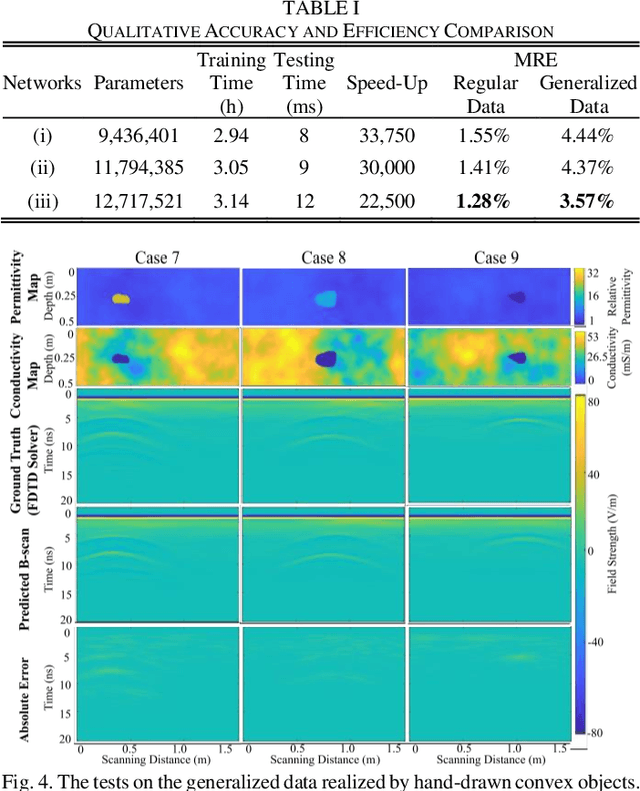
The forward full-wave modeling of ground-penetrating radar (GPR) facilitates the understanding and interpretation of GPR data. Traditional forward solvers require excessive computational resources, especially when their repetitive executions are needed in signal processing and/or machine learning algorithms for GPR data inversion. To alleviate the computational burden, a deep learning-based 2D GPR forward solver is proposed to predict the GPR B-scans of subsurface objects buried in the heterogeneous soil. The proposed solver is constructed as a bimodal encoder-decoder neural network. Two encoders followed by an adaptive feature fusion module are designed to extract informative features from the subsurface permittivity and conductivity maps. The decoder subsequently constructs the B-scans from the fused feature representations. To enhance the network's generalization capability, transfer learning is employed to fine-tune the network for new scenarios vastly different from those in training set. Numerical results show that the proposed solver achieves a mean relative error of 1.28%. For predicting the B-scan of one subsurface object, the proposed solver requires 12 milliseconds, which is 22,500x less than the time required by a classical physics-based solver.
Conformal Prediction Intervals with Temporal Dependence
May 26, 2022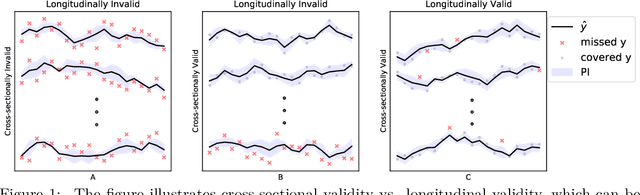


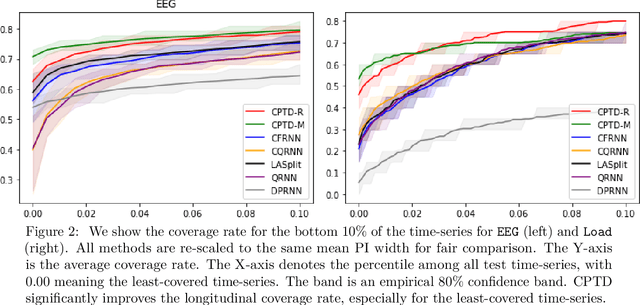
Cross-sectional prediction is common in many domains such as healthcare, including forecasting tasks using electronic health records, where different patients form a cross-section. We focus on the task of constructing valid prediction intervals (PIs) in time-series regression with a cross-section. A prediction interval is considered valid if it covers the true response with (a pre-specified) high probability. We first distinguish between two notions of validity in such a setting: cross-sectional and longitudinal. Cross-sectional validity is concerned with validity across the cross-section of the time series data, while longitudinal validity accounts for the temporal dimension. Coverage guarantees along both these dimensions are ideally desirable; however, we show that distribution-free longitudinal validity is theoretically impossible. Despite this limitation, we propose Conformal Prediction with Temporal Dependence (CPTD), a procedure which is able to maintain strict cross-sectional validity while improving longitudinal coverage. CPTD is post-hoc and light-weight, and can easily be used in conjunction with any prediction model as long as a calibration set is available. We focus on neural networks due to their ability to model complicated data such as diagnosis codes for time-series regression, and perform extensive experimental validation to verify the efficacy of our approach. We find that CPTD outperforms baselines on a variety of datasets by improving longitudinal coverage and often providing more efficient (narrower) PIs.
NeurAR: Neural Uncertainty for Autonomous 3D Reconstruction
Jul 22, 2022
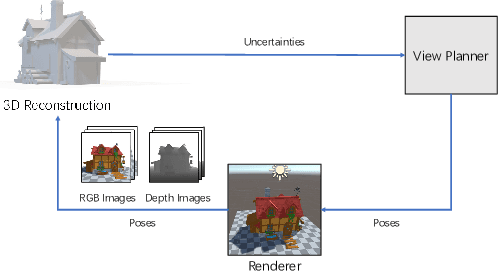
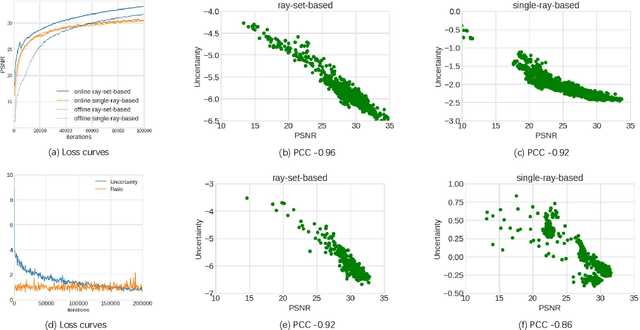

Implicit neural representations have shown compelling results in offline 3D reconstruction and also recently demonstrated the potential for online SLAM systems. However, applying them to autonomous 3D reconstruction, where robots are required to explore a scene and plan a view path for the reconstruction, has not been studied. In this paper, we explore for the first time the possibility of using implicit neural representations for autonomous 3D scene reconstruction by addressing two key challenges: 1) seeking a criterion to measure the quality of the candidate viewpoints for the view planning based on the new representations, and 2) learning the criterion from data that can generalize to different scenes instead of hand-crafting one. For the first challenge, a proxy of Peak Signal-to-Noise Ratio (PSNR) is proposed to quantify a viewpoint quality. The proxy is acquired by treating the color of a spatial point in a scene as a random variable under a Gaussian distribution rather than a deterministic one; the variance of the distribution quantifies the uncertainty of the reconstruction and composes the proxy. For the second challenge, the proxy is optimized jointly with the parameters of an implicit neural network for the scene. With the proposed view quality criterion, we can then apply the new representations to autonomous 3D reconstruction. Our method demonstrates significant improvements on various metrics for the rendered image quality and the geometry quality of the reconstructed 3D models when compared with variants using TSDF or reconstruction without view planning.
PhishSim: Aiding Phishing Website Detection with a Feature-Free Tool
Jul 13, 2022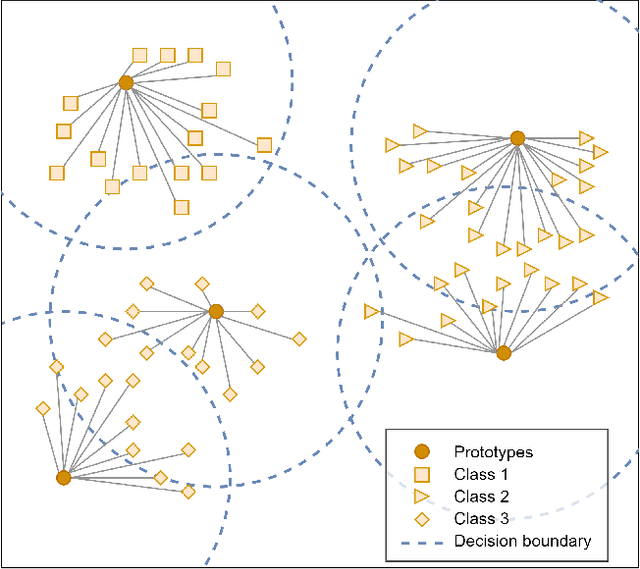

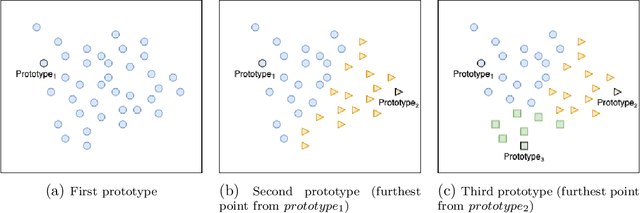
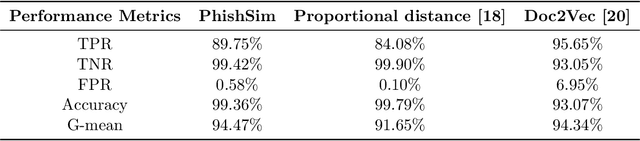
In this paper, we propose a feature-free method for detecting phishing websites using the Normalized Compression Distance (NCD), a parameter-free similarity measure which computes the similarity of two websites by compressing them, thus eliminating the need to perform any feature extraction. It also removes any dependence on a specific set of website features. This method examines the HTML of webpages and computes their similarity with known phishing websites, in order to classify them. We use the Furthest Point First algorithm to perform phishing prototype extractions, in order to select instances that are representative of a cluster of phishing webpages. We also introduce the use of an incremental learning algorithm as a framework for continuous and adaptive detection without extracting new features when concept drift occurs. On a large dataset, our proposed method significantly outperforms previous methods in detecting phishing websites, with an AUC score of 98.68%, a high true positive rate (TPR) of around 90%, while maintaining a low false positive rate (FPR) of 0.58%. Our approach uses prototypes, eliminating the need to retain long term data in the future, and is feasible to deploy in real systems with a processing time of roughly 0.3 seconds.
* 34 pages, 20 figures
Open-Source LiDAR Time Synchronization System by Mimicking GPS-clock
Jul 06, 2021
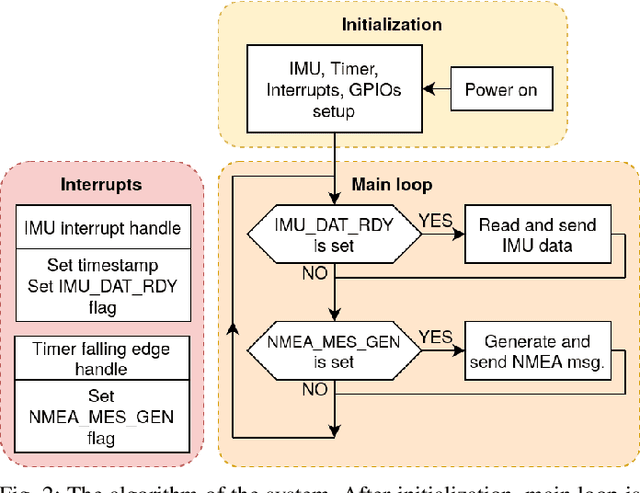
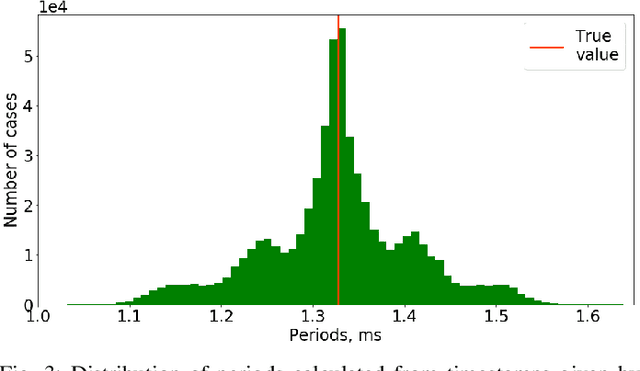
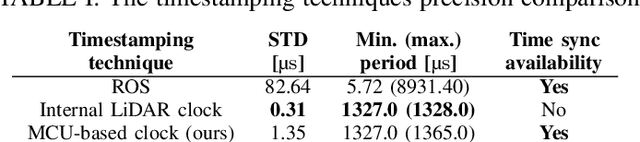
Time synchronization of multiple sensors is one of the main issues when building sensor networks. Data fusion algorithms and their applications, such as LiDAR-IMU Odometry (LIO), rely on precise timestamping. We introduce open-source LiDAR to inertial measurement unit (IMU) hardware time synchronization system, which could be generalized to multiple sensors such as cameras, encoders, other LiDARs, etc. The system mimics a GPS-supplied clock interface by a microcontroller-powered platform and provides 1 microsecond synchronization precision. In addition, we conduct an evaluation of the system precision comparing to other synchronization methods, including timestamping provided by ROS software and LiDAR inner clock, showing clear advantages over both baseline methods.
Multi-Modal Prototype Learning for Interpretable Multivariable Time Series Classification
Jun 17, 2021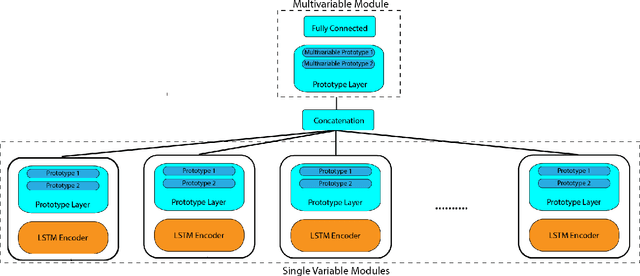
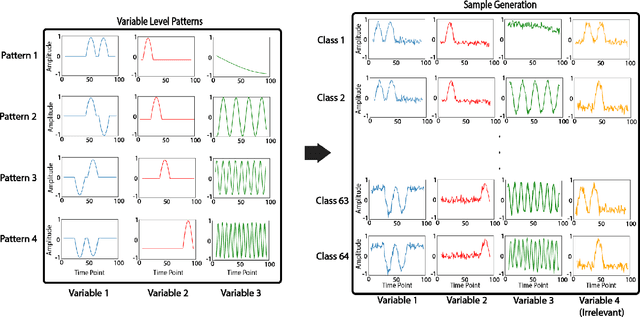
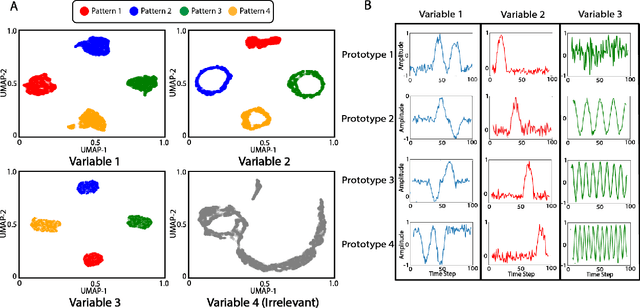
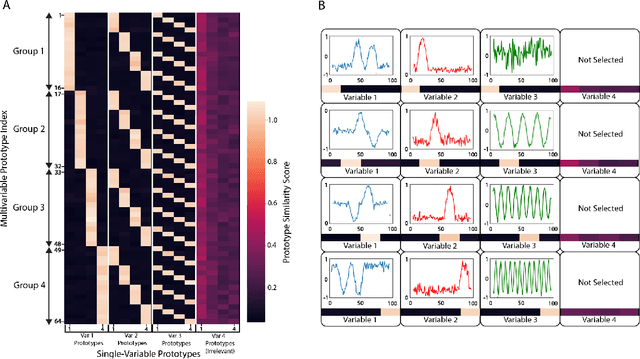
Multivariable time series classification problems are increasing in prevalence and complexity in a variety of domains, such as biology and finance. While deep learning methods are an effective tool for these problems, they often lack interpretability. In this work, we propose a novel modular prototype learning framework for multivariable time series classification. In the first stage of our framework, encoders extract features from each variable independently. Prototype layers identify single-variable prototypes in the resulting feature spaces. The next stage of our framework represents the multivariable time series sample points in terms of their similarity to these single-variable prototypes. This results in an inherently interpretable representation of multivariable patterns, on which prototype learning is applied to extract representative examples i.e. multivariable prototypes. Our framework is thus able to explicitly identify both informative patterns in the individual variables, as well as the relationships between the variables. We validate our framework on a simulated dataset with embedded patterns, as well as a real human activity recognition problem. Our framework attains comparable or superior classification performance to existing time series classification methods on these tasks. On the simulated dataset, we find that our model returns interpretations consistent with the embedded patterns. Moreover, the interpretations learned on the activity recognition dataset align with domain knowledge.
Clustering Left-Censored Multivariate Time-Series
Feb 19, 2021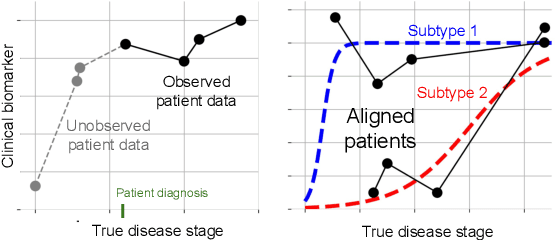
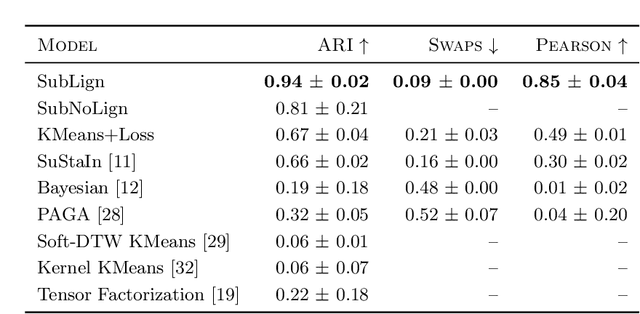
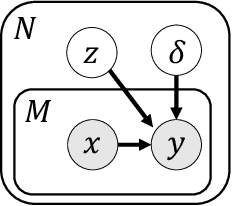
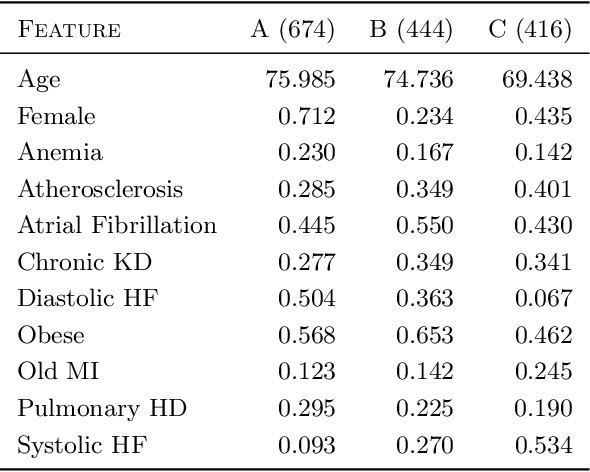
Unsupervised learning seeks to uncover patterns in data. However, different kinds of noise may impede the discovery of useful substructure from real-world time-series data. In this work, we focus on mitigating the interference of left-censorship in the task of clustering. We provide conditions under which clusters and left-censorship may be identified; motivated by this result, we develop a deep generative, continuous-time model of time-series data that clusters while correcting for censorship time. We demonstrate accurate, stable, and interpretable results on synthetic data that outperform several benchmarks. To showcase the utility of our framework on real-world problems, we study how left-censorship can adversely affect the task of disease phenotyping, resulting in the often incorrect assumption that longitudinal patient data are aligned by disease stage. In reality, patients at the time of diagnosis are at different stages of the disease -- both late and early due to differences in when patients seek medical care and such discrepancy can confound unsupervised learning algorithms. On two clinical datasets, our model corrects for this form of censorship and recovers known clinical subtypes.