 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Can Deep Learning Assist Automatic Identification of Layered Pigments From XRF Data?
Jul 26, 2022
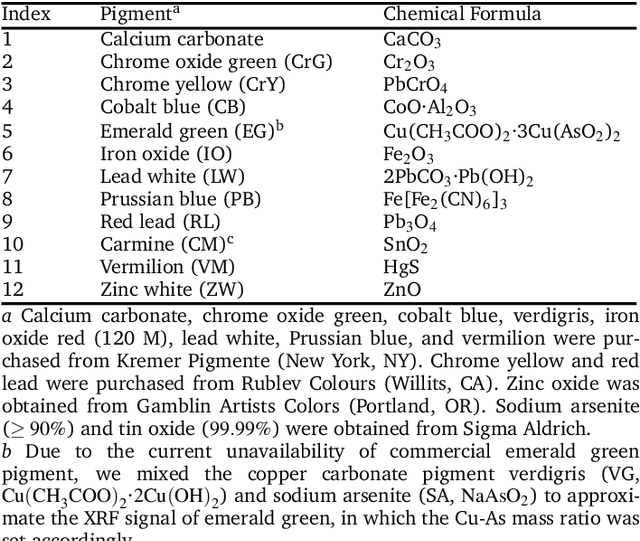
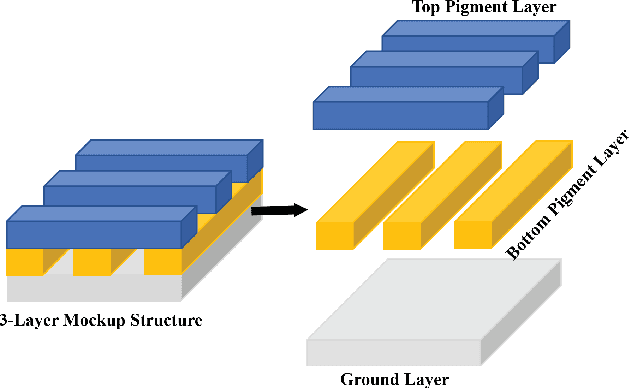
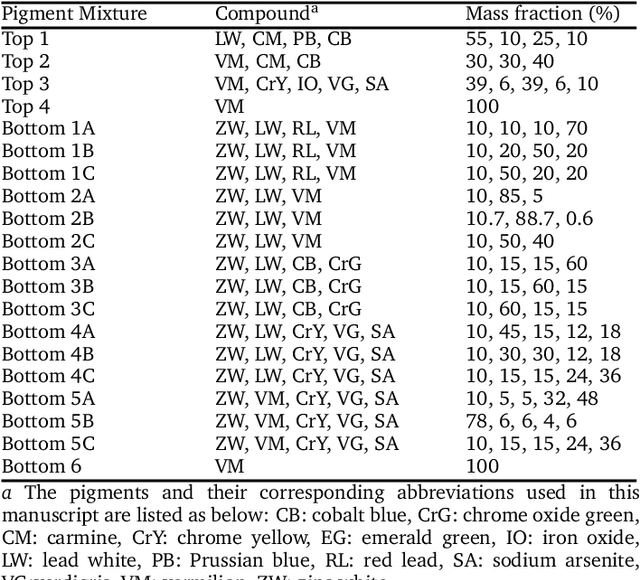
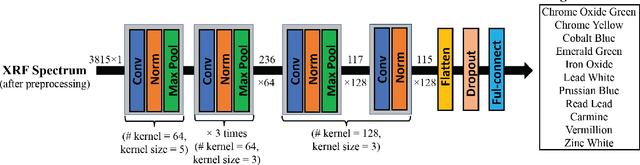
X-ray fluorescence spectroscopy (XRF) plays an important role for elemental analysis in a wide range of scientific fields, especially in cultural heritage. XRF imaging, which uses a raster scan to acquire spectra across artworks, provides the opportunity for spatial analysis of pigment distributions based on their elemental composition. However, conventional XRF-based pigment identification relies on time-consuming elemental mapping by expert interpretations of measured spectra. To reduce the reliance on manual work, recent studies have applied machine learning techniques to cluster similar XRF spectra in data analysis and to identify the most likely pigments. Nevertheless, it is still challenging for automatic pigment identification strategies to directly tackle the complex structure of real paintings, e.g. pigment mixtures and layered pigments. In addition, pixel-wise pigment identification based on XRF imaging remains an obstacle due to the high noise level compared with averaged spectra. Therefore, we developed a deep-learning-based end-to-end pigment identification framework to fully automate the pigment identification process. In particular, it offers high sensitivity to the underlying pigments and to the pigments with a low concentration, therefore enabling satisfying results in mapping the pigments based on single-pixel XRF spectrum. As case studies, we applied our framework to lab-prepared mock-up paintings and two 19th-century paintings: Paul Gauguin's Po\`emes Barbares (1896) that contains layered pigments with an underlying painting, and Paul Cezanne's The Bathers (1899-1904). The pigment identification results demonstrated that our model achieved comparable results to the analysis by elemental mapping, suggesting the generalizability and stability of our model.
Tightening Discretization-based MILP Models for the Pooling Problem using Upper Bounds on Bilinear Terms
Jul 08, 2022
Discretization-based methods have been proposed for solving nonconvex optimization problems with bilinear terms. These methods convert the original nonconvex optimization problems into mixed-integer linear programs (MILPs). Compared to a wide range of studies related to methods to convert nonconvex optimization problems into MILPs, research on tightening the resulting MILP models is limited. In this paper, we present tightening constraints for the discretization-based MILP models for the pooling problem. Specifically, we study tightening constraints derived from upper bounds on bilinear term and exploiting the structures resulting from the discretization. We demonstrate the effectiveness of our constraints, showing computational results for MILP models derived from different formulations for (1) the pooling problem and (2) discretization-based pooling models. Computational results show that our methods reduce the computational time for MILP models on CPLEX 12.10. Finally, we note that while our methods are presented in the context of the pooling problem, they can be extended to address other nonconvex optimization problems with upper bounds on bilinear terms.
Lane-Level Route Planning for Autonomous Vehicles
Jun 06, 2022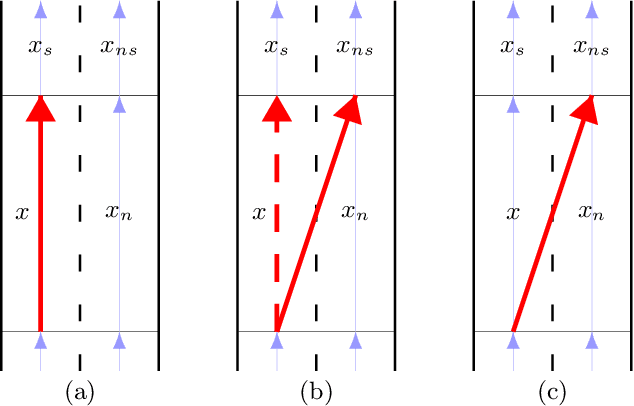
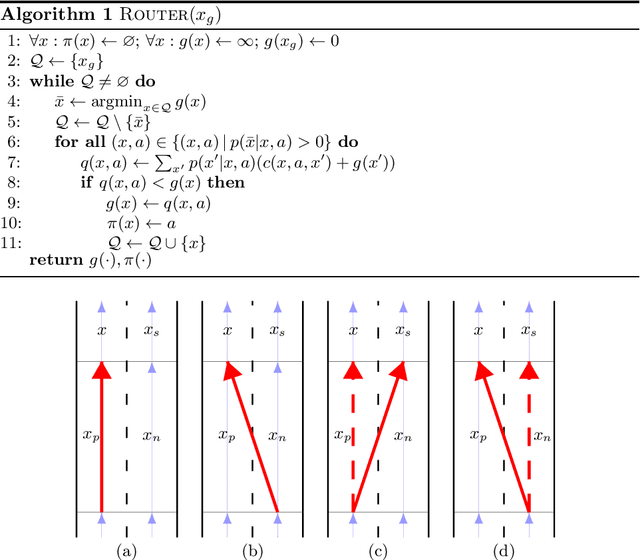
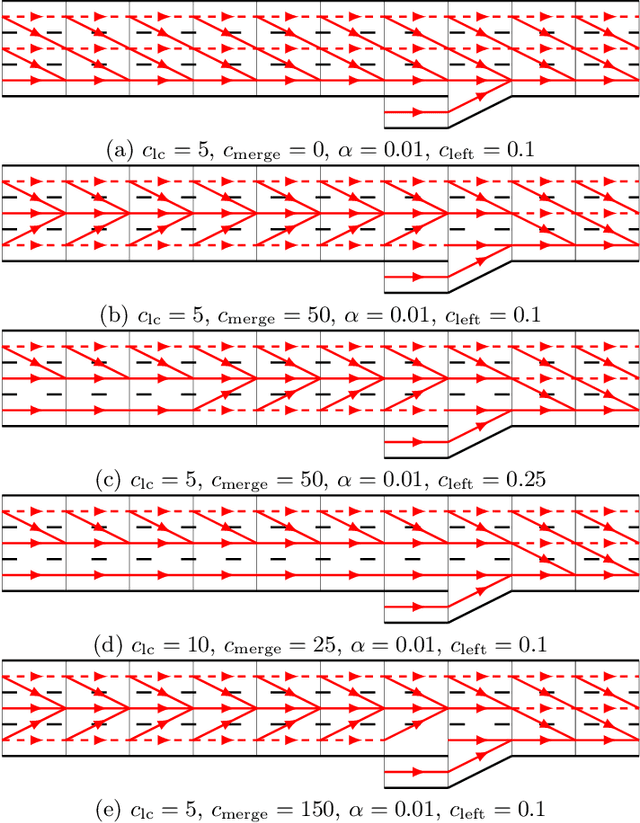
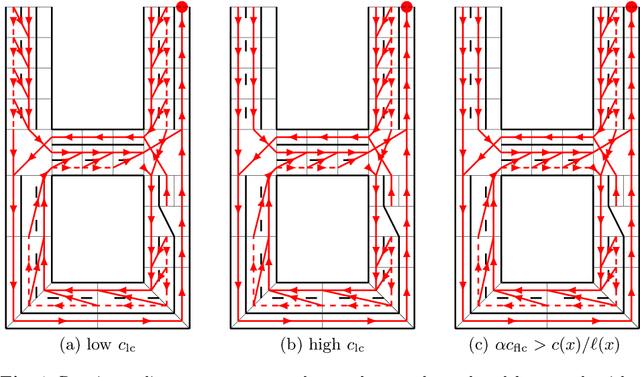
We present an algorithm that, given a representation of a road network in lane-level detail, computes a route that minimizes the expected cost to reach a given destination. In doing so, our algorithm allows us to solve for the complex trade-offs encountered when trying to decide not just which roads to follow, but also when to change between the lanes making up these roads, in order to -- for example -- reduce the likelihood of missing a left exit while not unnecessarily driving in the leftmost lane. This routing problem can naturally be formulated as a Markov Decision Process (MDP), in which lane change actions have stochastic outcomes. However, MDPs are known to be time-consuming to solve in general. In this paper, we show that -- under reasonable assumptions -- we can use a Dijkstra-like approach to solve this stochastic problem, and benefit from its efficient $O(n \log n)$ running time. This enables an autonomous vehicle to exhibit natural lane-selection behavior as it efficiently plans an optimal route to its destination.
Robot-Assisted Drilling on Curved Surfaces with Haptic Guidance under Adaptive Admittance Control
Jul 28, 2022
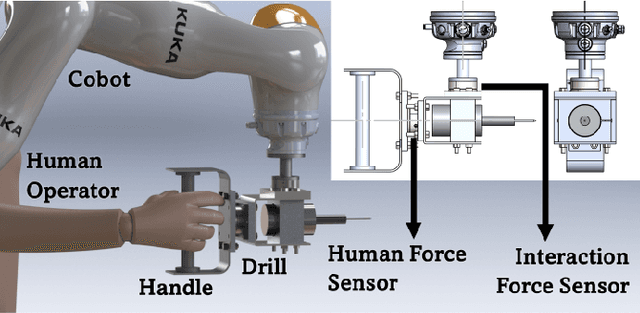
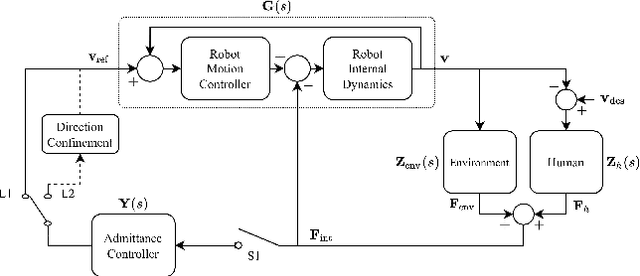
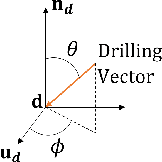
Drilling a hole on a curved surface with a desired angle is prone to failure when done manually, due to the difficulties in drill alignment and also inherent instabilities of the task, potentially causing injury and fatigue to the workers. On the other hand, it can be impractical to fully automate such a task in real manufacturing environments because the parts arriving at an assembly line can have various complex shapes where drill point locations are not easily accessible, making automated path planning difficult. In this work, an adaptive admittance controller with 6 degrees of freedom is developed and deployed on a KUKA LBR iiwa 7 cobot such that the operator is able to manipulate a drill mounted on the robot with one hand comfortably and open holes on a curved surface with haptic guidance of the cobot and visual guidance provided through an AR interface. Real-time adaptation of the admittance damping provides more transparency when driving the robot in free space while ensuring stability during drilling. After the user brings the drill sufficiently close to the drill target and roughly aligns to the desired drilling angle, the haptic guidance module fine tunes the alignment first and then constrains the user movement to the drilling axis only, after which the operator simply pushes the drill into the workpiece with minimal effort. Two sets of experiments were conducted to investigate the potential benefits of the haptic guidance module quantitatively (Experiment I) and also the practical value of the proposed pHRI system for real manufacturing settings based on the subjective opinion of the participants (Experiment II).
Traffic Congestion Prediction Using Machine Learning Techniques
Jun 22, 2022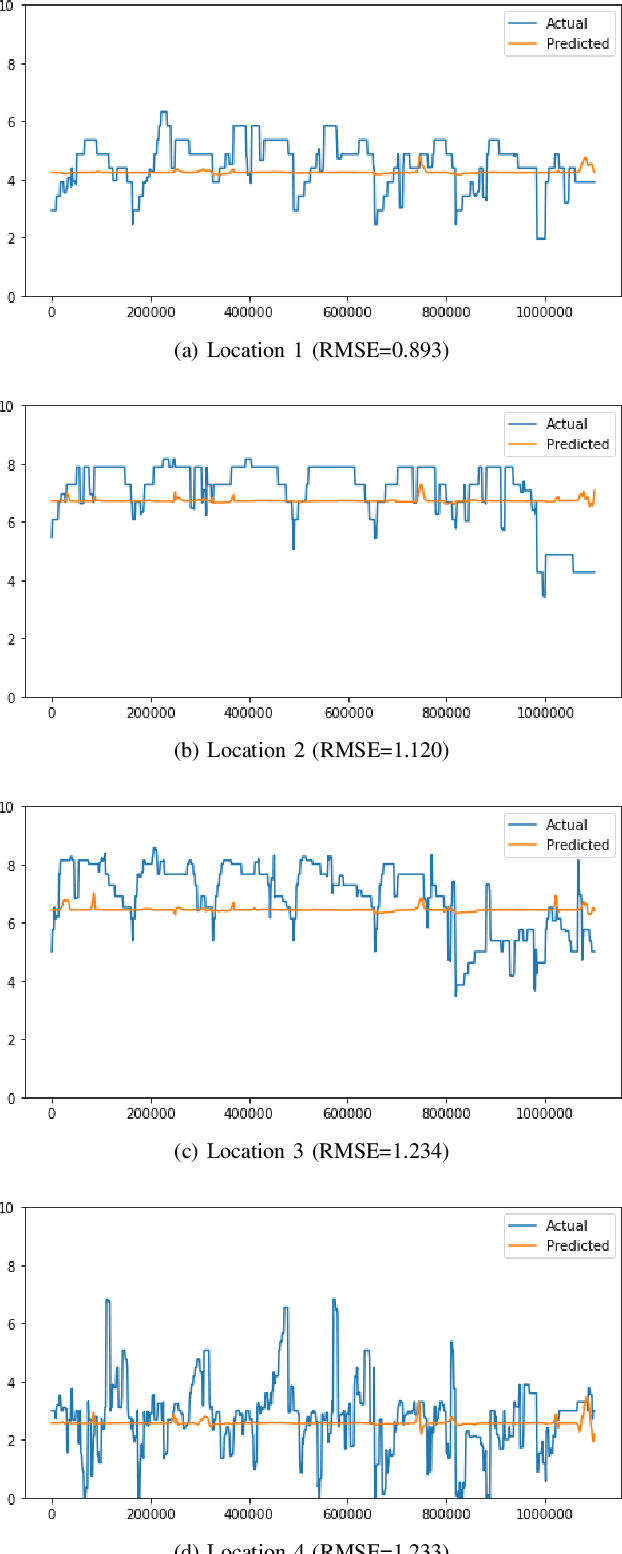
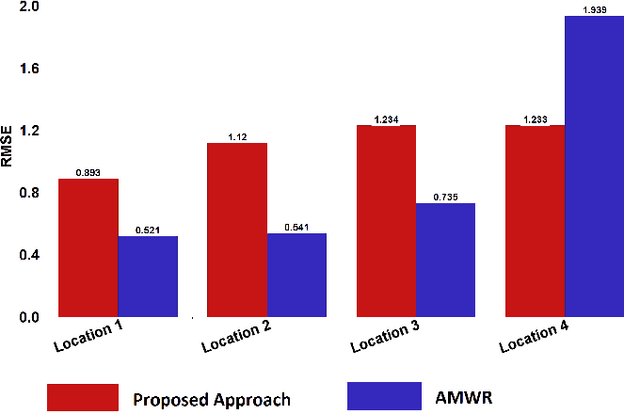
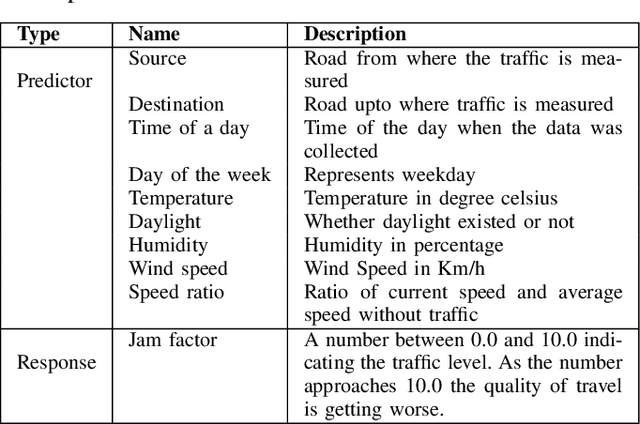
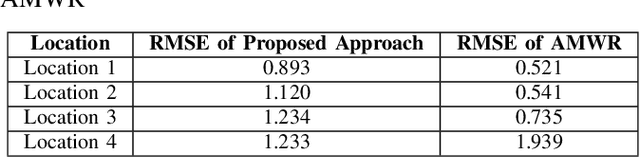
The prediction of traffic congestion can serve a crucial role in making future decisions. Although many studies have been conducted regarding congestion, most of these could not cover all the important factors (e.g., weather conditions). We proposed a prediction model for traffic congestion that can predict congestion based on day, time and several weather data (e.g., temperature, humidity). To evaluate our model, it has been tested against the traffic data of New Delhi. With this model, congestion of a road can be predicted one week ahead with an average RMSE of 1.12. Therefore, this model can be used to take preventive measure beforehand.
FD-GATDR: A Federated-Decentralized-Learning Graph Attention Network for Doctor Recommendation Using EHR
Jul 11, 2022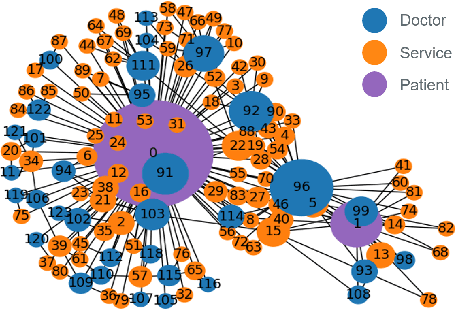
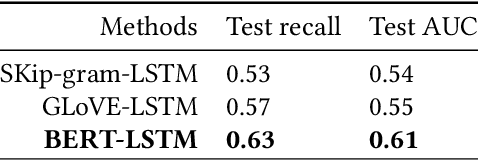
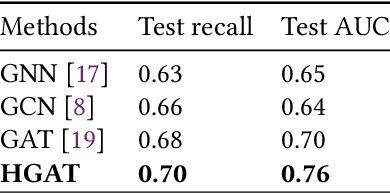
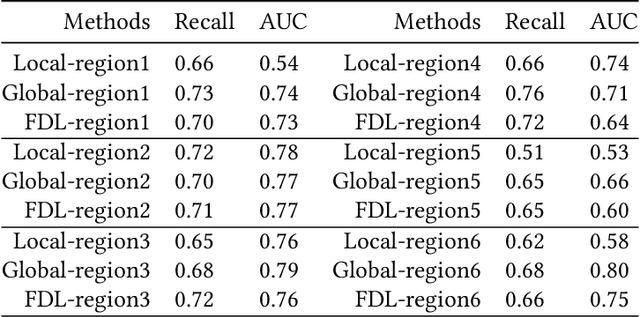
In the past decade, with the development of big data technology, an increasing amount of patient information has been stored as electronic health records (EHRs). Leveraging these data, various doctor recommendation systems have been proposed. Typically, such studies process the EHR data in a flat-structured manner, where each encounter was treated as an unordered set of features. Nevertheless, the heterogeneous structured information such as service sequence stored in claims shall not be ignored. This paper presents a doctor recommendation system with time embedding to reconstruct the potential connections between patients and doctors using heterogeneous graph attention network. Besides, to address the privacy issue of patient data sharing crossing hospitals, a federated decentralized learning method based on a minimization optimization model is also proposed. The graph-based recommendation system has been validated on a EHR dataset. Compared to baseline models, the proposed method improves the AUC by up to 6.2%. And our proposed federated-based algorithm not only yields the fictitious fusion center's performance but also enjoys a convergence rate of O(1/T).
Audio-Visual Segmentation
Jul 11, 2022

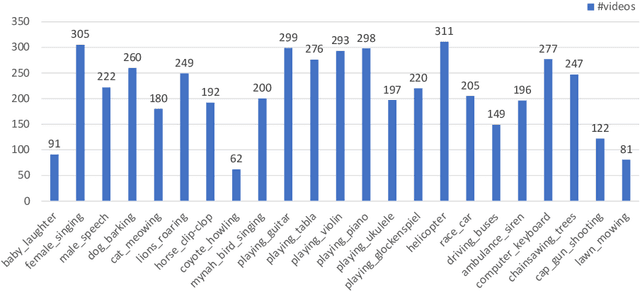
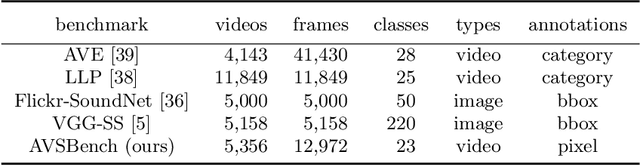
We propose to explore a new problem called audio-visual segmentation (AVS), in which the goal is to output a pixel-level map of the object(s) that produce sound at the time of the image frame. To facilitate this research, we construct the first audio-visual segmentation benchmark (AVSBench), providing pixel-wise annotations for the sounding objects in audible videos. Two settings are studied with this benchmark: 1) semi-supervised audio-visual segmentation with a single sound source and 2) fully-supervised audio-visual segmentation with multiple sound sources. To deal with the AVS problem, we propose a novel method that uses a temporal pixel-wise audio-visual interaction module to inject audio semantics as guidance for the visual segmentation process. We also design a regularization loss to encourage the audio-visual mapping during training. Quantitative and qualitative experiments on the AVSBench compare our approach to several existing methods from related tasks, demonstrating that the proposed method is promising for building a bridge between the audio and pixel-wise visual semantics. Code is available at https://github.com/OpenNLPLab/AVSBench.
Space-Time Finite Element for Sensor Fusion
Jul 19, 2021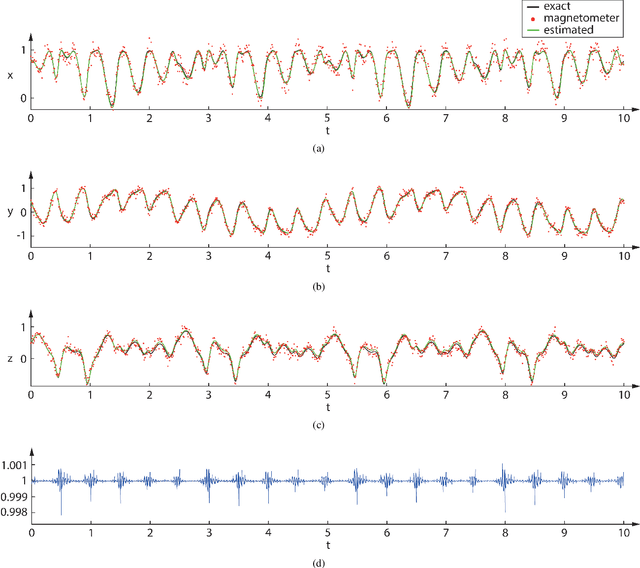
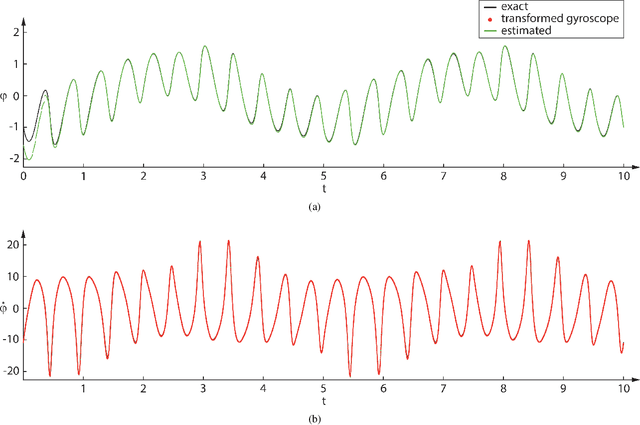
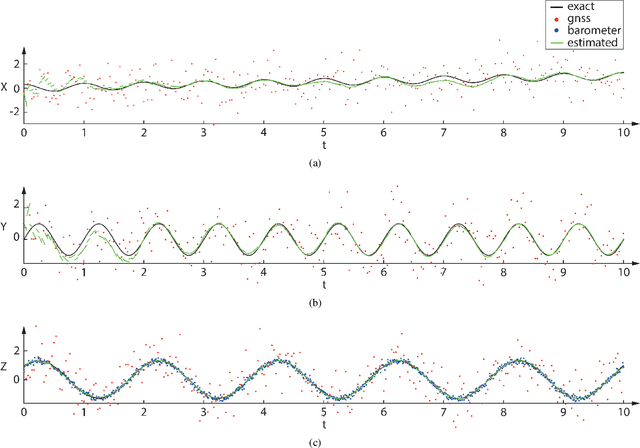
Drones estimate their position and orientation with the help of various sensors. Their data streams, that differ with respect to the sampling rate and standard deviation, need to be fused to get an accurate position and orientation estimate. It is subsequently shown that a nonlinear space-time finite element and static condensation can be used to accomplish this task. This is done, for the sake of clarity, in three stages. The first stage estimates the local magnetic north vector with the help of magnetometers and gyroscopes. The second stage projects the remaining sensor data onto the plane that is orthogonal to the local magnetic north vector and the third stage solves the corresponding two-dimensional problem.
Predictive Neural Speech Coding
Jul 18, 2022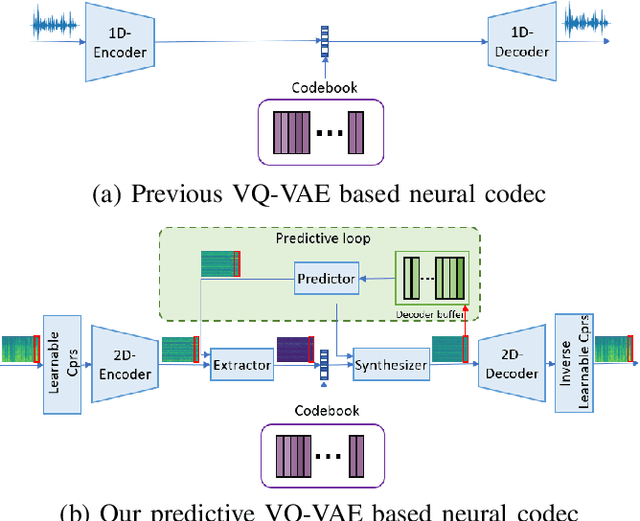
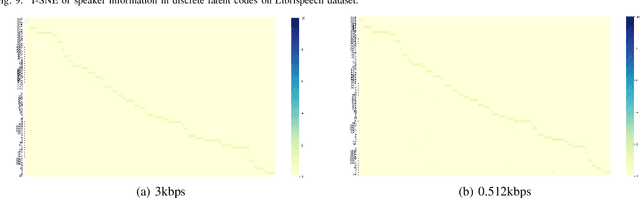
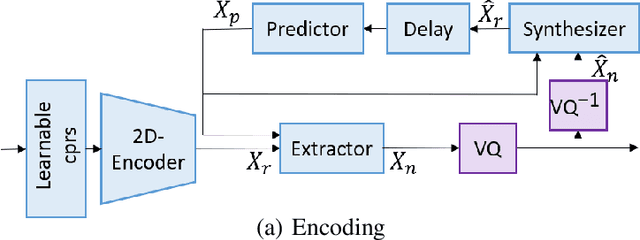
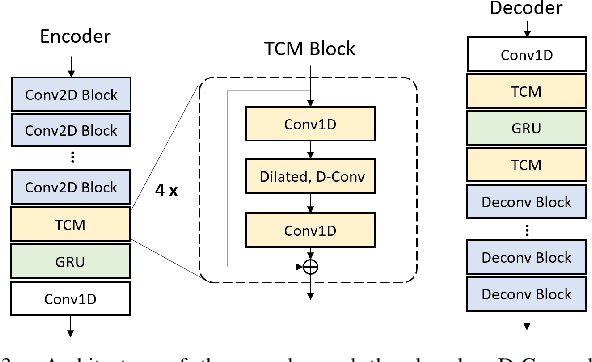
Neural audio/speech coding has shown its capability to deliver a high quality at much lower bitrates than traditional methods recently. However, existing neural audio/speech codecs employ either acoustic features or learned blind features with a convolutional neural network for encoding, by which there are still temporal redundancies inside encoded features. This paper introduces latent-domain predictive coding into the VQ-VAE framework to fully remove such redundancies and proposes the TF-Codec for low-latency neural speech coding in an end-to-end way. Specifically, the extracted features are encoded conditioned on a prediction from past quantized latent frames so that temporal correlations are further removed. What's more, we introduce a learnable compression on the time-frequency input to adaptively adjust the attention paid on main frequencies and details at different bitrates. A differentiable vector quantization scheme based on distance-to-soft mapping and Gumbel-Softmax is proposed to better model the latent distributions with rate constraint. Subjective results on multilingual speech datasets show that with a latency of 40ms, the proposed TF-Codec at 1kbps can achieve a much better quality than Opus 9kbps and TF-Codec at 3kbps outperforms both EVS 9.6kbps and Opus 12kbps. Numerous studies are conducted to show the effectiveness of these techniques.
3D-Aware Video Generation
Jun 29, 2022
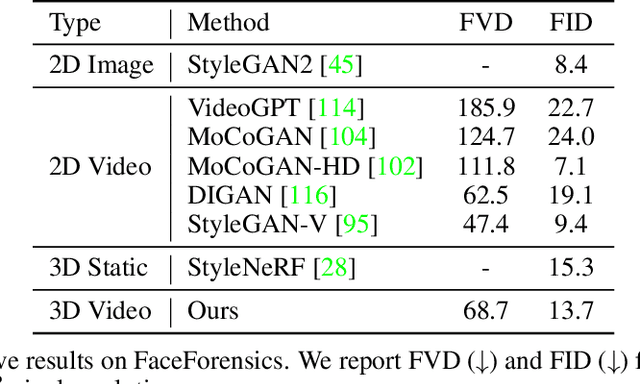
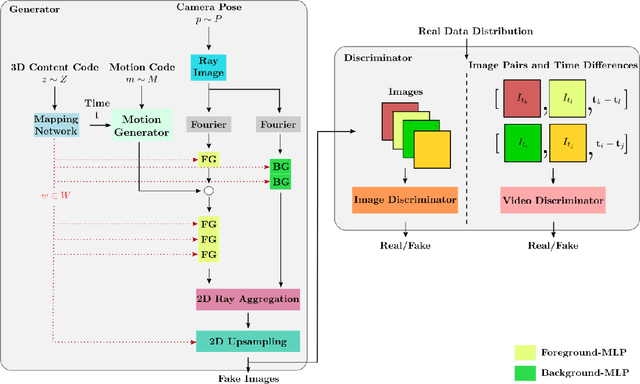

Generative models have emerged as an essential building block for many image synthesis and editing tasks. Recent advances in this field have also enabled high-quality 3D or video content to be generated that exhibits either multi-view or temporal consistency. With our work, we explore 4D generative adversarial networks (GANs) that learn unconditional generation of 3D-aware videos. By combining neural implicit representations with time-aware discriminator, we develop a GAN framework that synthesizes 3D video supervised only with monocular videos. We show that our method learns a rich embedding of decomposable 3D structures and motions that enables new visual effects of spatio-temporal renderings while producing imagery with quality comparable to that of existing 3D or video GANs.