 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Partial Disentanglement via Mechanism Sparsity
Jul 15, 2022
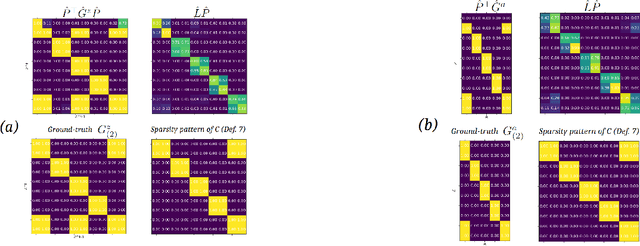

Disentanglement via mechanism sparsity was introduced recently as a principled approach to extract latent factors without supervision when the causal graph relating them in time is sparse, and/or when actions are observed and affect them sparsely. However, this theory applies only to ground-truth graphs satisfying a specific criterion. In this work, we introduce a generalization of this theory which applies to any ground-truth graph and specifies qualitatively how disentangled the learned representation is expected to be, via a new equivalence relation over models we call consistency. This equivalence captures which factors are expected to remain entangled and which are not based on the specific form of the ground-truth graph. We call this weaker form of identifiability partial disentanglement. The graphical criterion that allows complete disentanglement, proposed in an earlier work, can be derived as a special case of our theory. Finally, we enforce graph sparsity with constrained optimization and illustrate our theory and algorithm in simulations.
Efficient Multi-Purpose Cross-Attention Based Image Alignment Block for Edge Devices
Jun 01, 2022

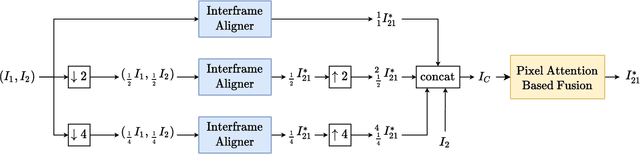
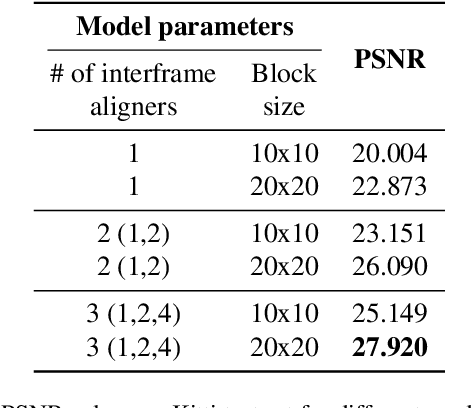
Image alignment, also known as image registration, is a critical block used in many computer vision problems. One of the key factors in alignment is efficiency, as inefficient aligners can cause significant overhead to the overall problem. In the literature, there are some blocks that appear to do the alignment operation, although most do not focus on efficiency. Therefore, an image alignment block which can both work in time and/or space and can work on edge devices would be beneficial for almost all networks dealing with multiple images. Given its wide usage and importance, we propose an efficient, cross-attention-based, multi-purpose image alignment block (XABA) suitable to work within edge devices. Using cross-attention, we exploit the relationships between features extracted from images. To make cross-attention feasible for real-time image alignment problems and handle large motions, we provide a pyramidal block based cross-attention scheme. This also captures local relationships besides reducing memory requirements and number of operations. Efficient XABA models achieve real-time requirements of running above 20 FPS performance on NVIDIA Jetson Xavier with 30W power consumption compared to other powerful computers. Used as a sub-block in a larger network, XABA also improves multi-image super-resolution network performance in comparison to other alignment methods.
ICME 2022 Few-shot LOGO detection top 9 solution
Jun 23, 2022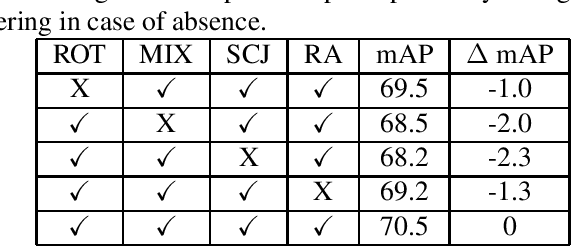
ICME-2022 few-shot logo detection competition is held in May, 2022. Participants are required to develop a single model to detect logos by handling tiny logo instances, similar brands, and adversarial images at the same time, with limited annotations. Our team achieved rank 16 and 11 in the first and second round of the competition respectively, with a final rank of 9th. This technical report summarized our major techniques used in this competitions, and potential improvement.
TPARN: Triple-path Attentive Recurrent Network for Time-domain Multichannel Speech Enhancement
Oct 20, 2021
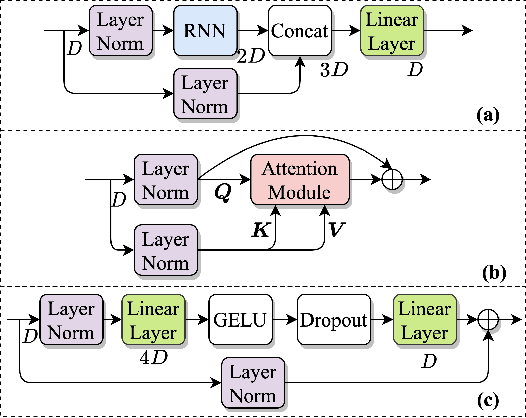
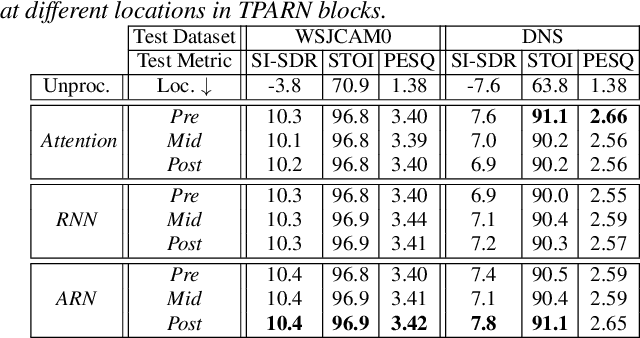
In this work, we propose a new model called triple-path attentive recurrent network (TPARN) for multichannel speech enhancement in the time domain. TPARN extends a single-channel dual-path network to a multichannel network by adding a third path along the spatial dimension. First, TPARN processes speech signals from all channels independently using a dual-path attentive recurrent network (ARN), which is a recurrent neural network (RNN) augmented with self-attention. Next, an ARN is introduced along the spatial dimension for spatial context aggregation. TPARN is designed as a multiple-input and multiple-output architecture to enhance all input channels simultaneously. Experimental results demonstrate the superiority of TPARN over existing state-of-the-art approaches.
Exploring Attention-Aware Network Resource Allocation for Customized Metaverse Services
Jul 31, 2022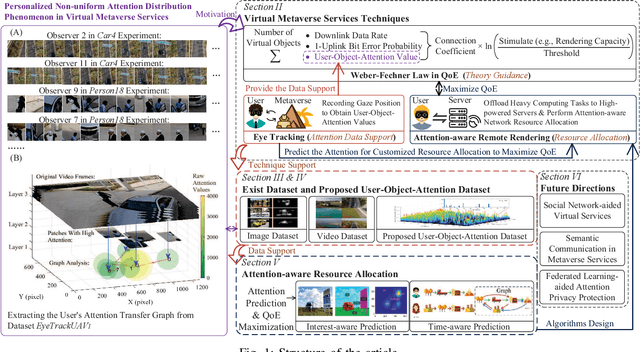
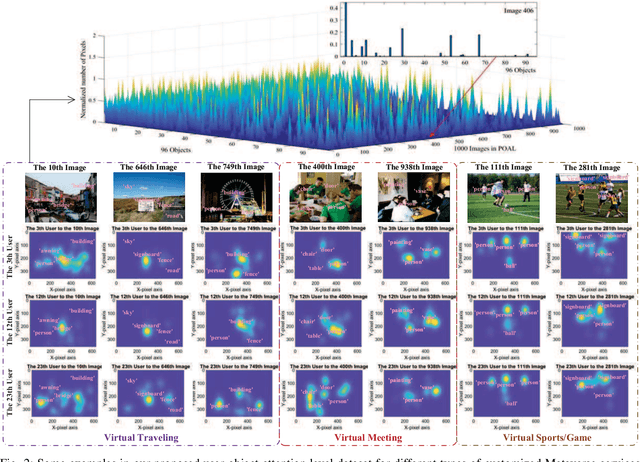
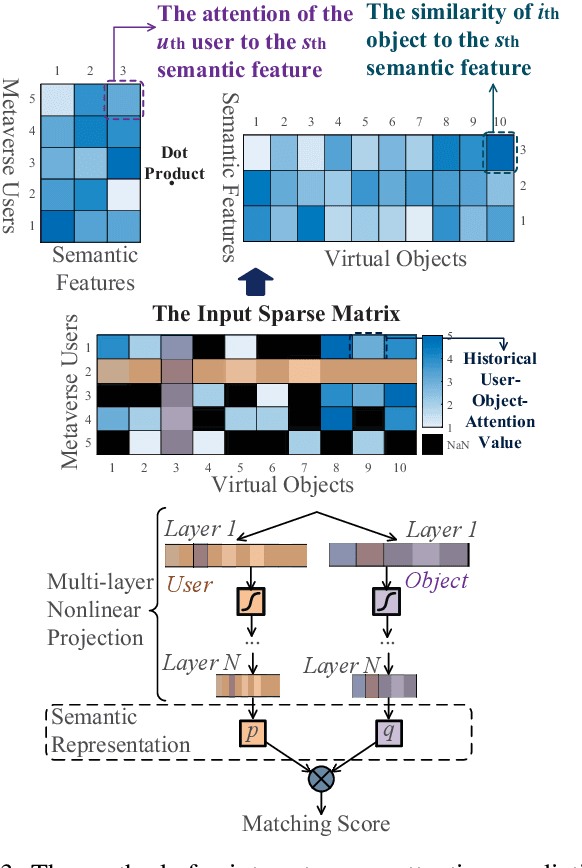
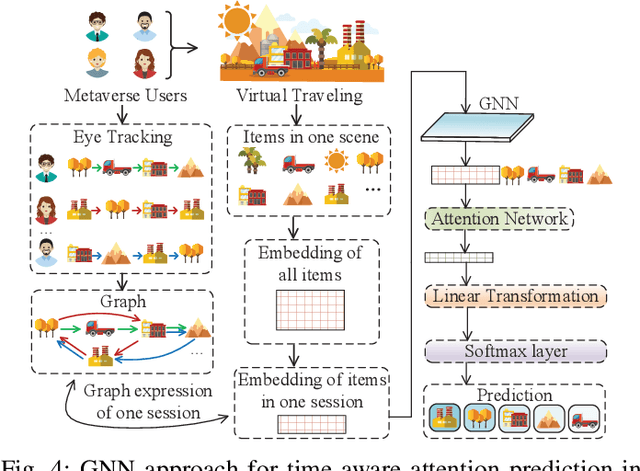
Emerging with the support of computing and communications technologies, Metaverse is expected to bring users unprecedented service experiences. However, the increase in the number of Metaverse users places a heavy demand on network resources, especially for Metaverse services that are based on graphical extended reality and require rendering a plethora of virtual objects. To make efficient use of network resources and improve the Quality-of-Experience (QoE), we design an attention-aware network resource allocation scheme to achieve customized Metaverse services. The aim is to allocate more network resources to virtual objects in which users are more interested. We first discuss several key techniques related to Metaverse services, including QoE analysis, eye-tracking, and remote rendering. We then review existing datasets and propose the user-object-attention level (UOAL) dataset that contains the ground truth attention of 30 users to 96 objects in 1,000 images. A tutorial on how to use UOAL is presented. With the help of UOAL, we propose an attention-aware network resource allocation algorithm that has two steps, i.e., attention prediction and QoE maximization. Specially, we provide an overview of the designs of two types of attention prediction methods, i.e., interest-aware and time-aware prediction. By using the predicted user-object-attention values, network resources such as the rendering capacity of edge devices can be allocated optimally to maximize the QoE. Finally, we propose promising research directions related to Metaverse services.
POET: Training Neural Networks on Tiny Devices with Integrated Rematerialization and Paging
Jul 15, 2022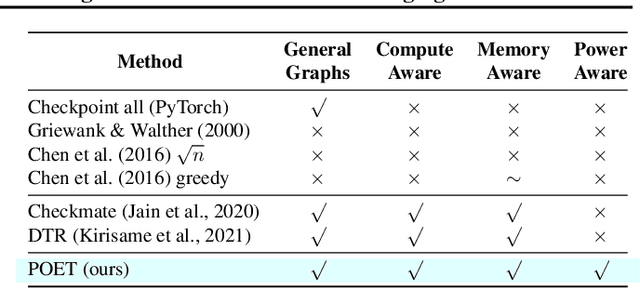
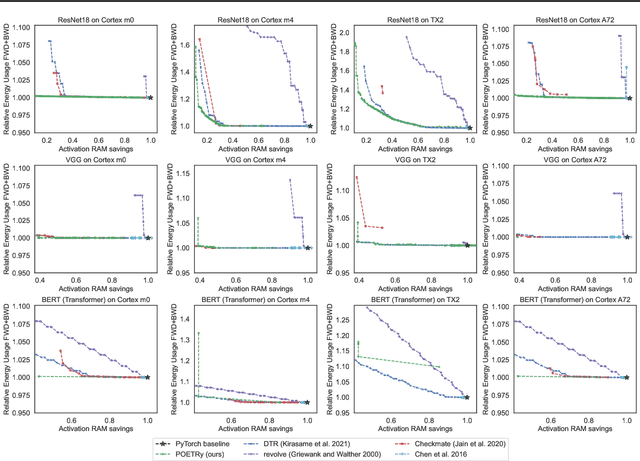
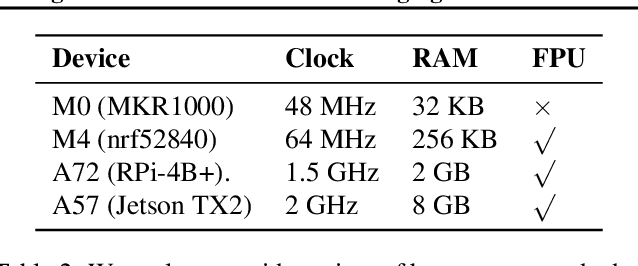
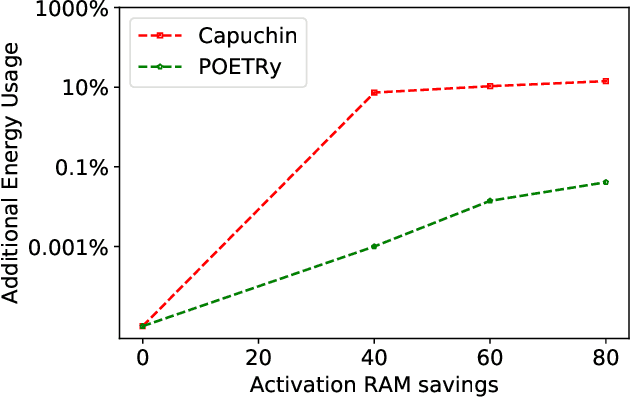
Fine-tuning models on edge devices like mobile phones would enable privacy-preserving personalization over sensitive data. However, edge training has historically been limited to relatively small models with simple architectures because training is both memory and energy intensive. We present POET, an algorithm to enable training large neural networks on memory-scarce battery-operated edge devices. POET jointly optimizes the integrated search search spaces of rematerialization and paging, two algorithms to reduce the memory consumption of backpropagation. Given a memory budget and a run-time constraint, we formulate a mixed-integer linear program (MILP) for energy-optimal training. Our approach enables training significantly larger models on embedded devices while reducing energy consumption while not modifying mathematical correctness of backpropagation. We demonstrate that it is possible to fine-tune both ResNet-18 and BERT within the memory constraints of a Cortex-M class embedded device while outperforming current edge training methods in energy efficiency. POET is an open-source project available at https://github.com/ShishirPatil/poet
Using Neural Networks by Modelling Semi-Active Shock Absorber
Jul 19, 2022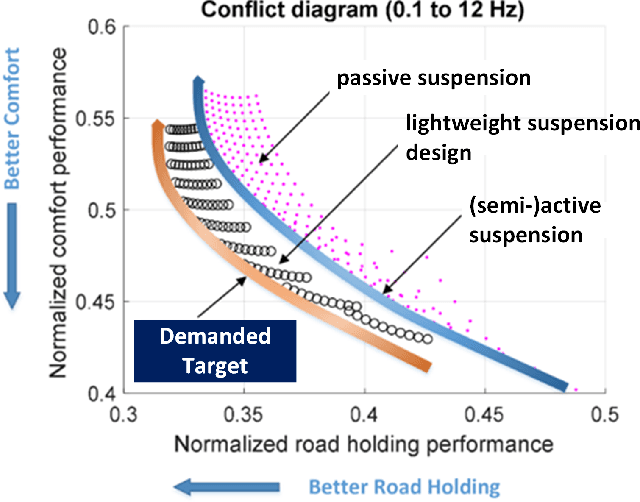
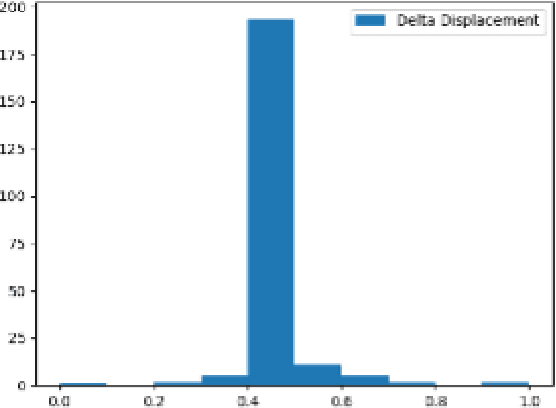
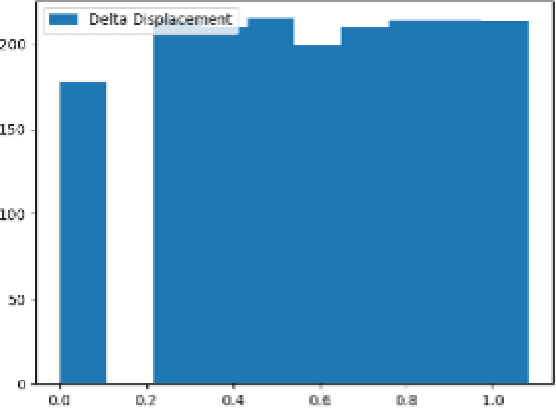
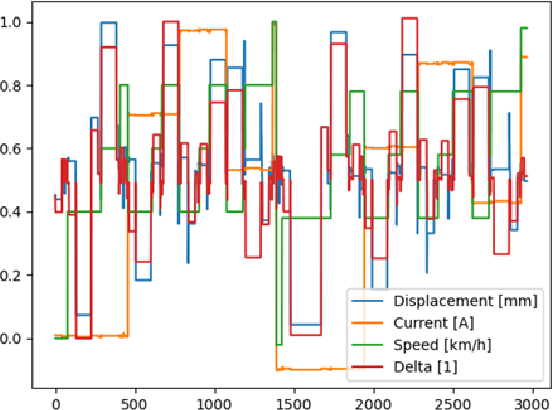
A permanently increasing number of on-board automotive control systems requires new approaches to their digital mapping that improves functionality in terms of adaptability and robustness as well as enables their easier on-line software update. As it can be concluded from many recent studies, various methods applying neural networks (NN) can be good candidates for relevant digital twin (DT) tools in automotive control system design, for example, for controller parameterization and condition monitoring. However, the NN-based DT has strong requirements to an adequate amount of data to be used in training and design. In this regard, the paper presents an approach, which demonstrates how the regression tasks can be efficiently handled by the modeling of a semi-active shock absorber within the DT framework. The approach is based on the adaptation of time series augmentation techniques to the stationary data that increases the variance of the latter. Such a solution gives a background to elaborate further data engineering methods for the data preparation of sophisticated databases.
Learning to Singulate Layers of Cloth using Tactile Feedback
Jul 22, 2022
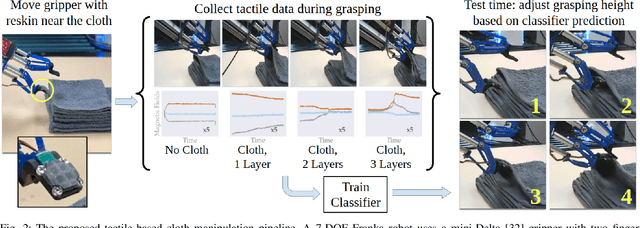


Robotic manipulation of cloth has applications ranging from fabrics manufacturing to handling blankets and laundry. Cloth manipulation is challenging for robots largely due to their high degrees of freedom, complex dynamics, and severe self-occlusions when in folded or crumpled configurations. Prior work on robotic manipulation of cloth relies primarily on vision sensors alone, which may pose challenges for fine-grained manipulation tasks such as grasping a desired number of cloth layers from a stack of cloth. In this paper, we propose to use tactile sensing for cloth manipulation; we attach a tactile sensor (ReSkin) to one of the two fingertips of a Franka robot and train a classifier to determine whether the robot is grasping a specific number of cloth layers. During test-time experiments, the robot uses this classifier as part of its policy to grasp one or two cloth layers using tactile feedback to determine suitable grasping points. Experimental results over 180 physical trials suggest that the proposed method outperforms baselines that do not use tactile feedback and has better generalization to unseen cloth compared to methods that use image classifiers. Code, data, and videos are available at https://sites.google.com/view/reskin-cloth.
Realistic sources, receivers and walls improve the generalisability of virtually-supervised blind acoustic parameter estimators
Jul 19, 2022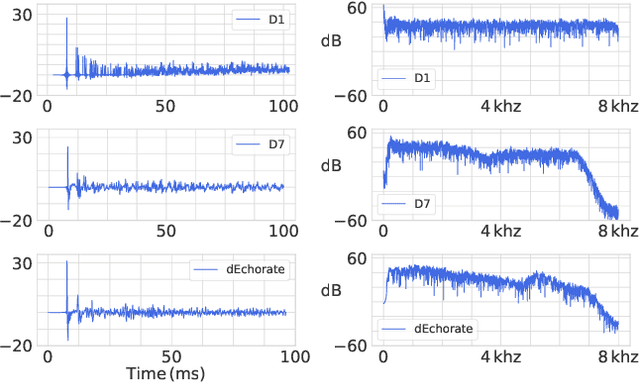

Blind acoustic parameter estimation consists in inferring the acoustic properties of an environment from recordings of unknown sound sources. Recent works in this area have utilized deep neural networks trained either partially or exclusively on simulated data, due to the limited availability of real annotated measurements. In this paper, we study whether a model purely trained using a fast image-source room impulse response simulator can generalize to real data. We present an ablation study on carefully crafted simulated training sets that account for different levels of realism in source, receiver and wall responses. The extent of realism is controlled by the sampling of wall absorption coefficients and by applying measured directivity patterns to microphones and sources. A state-of-the-art model trained on these datasets is evaluated on the task of jointly estimating the room's volume, total surface area, and octave-band reverberation times from multiple, multichannel speech recordings. Results reveal that every added layer of simulation realism at train time significantly improves the estimation of all quantities on real signals.
Neural Laplace: Learning diverse classes of differential equations in the Laplace domain
Jun 14, 2022
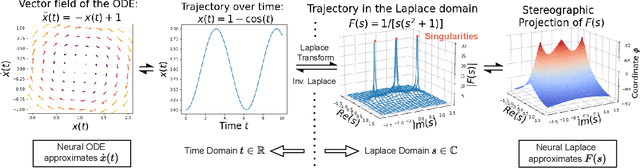
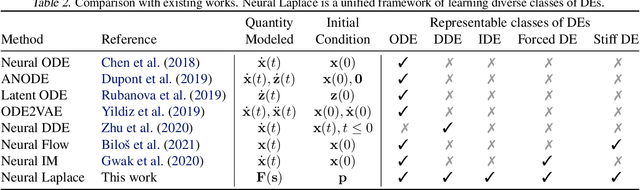
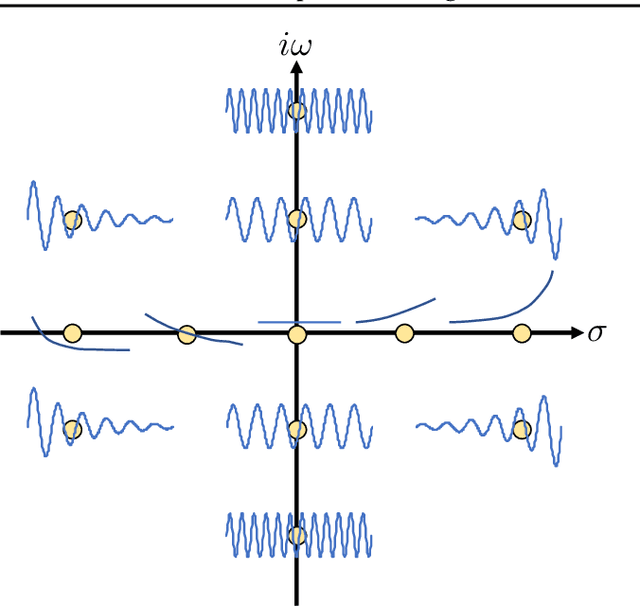
Neural Ordinary Differential Equations model dynamical systems with ODEs learned by neural networks. However, ODEs are fundamentally inadequate to model systems with long-range dependencies or discontinuities, which are common in engineering and biological systems. Broader classes of differential equations (DE) have been proposed as remedies, including delay differential equations and integro-differential equations. Furthermore, Neural ODE suffers from numerical instability when modelling stiff ODEs and ODEs with piecewise forcing functions. In this work, we propose Neural Laplace, a unified framework for learning diverse classes of DEs including all the aforementioned ones. Instead of modelling the dynamics in the time domain, we model it in the Laplace domain, where the history-dependencies and discontinuities in time can be represented as summations of complex exponentials. To make learning more efficient, we use the geometrical stereographic map of a Riemann sphere to induce more smoothness in the Laplace domain. In the experiments, Neural Laplace shows superior performance in modelling and extrapolating the trajectories of diverse classes of DEs, including the ones with complex history dependency and abrupt changes.