 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-time Neural Radiance Caching for Path Tracing
Jun 25, 2021


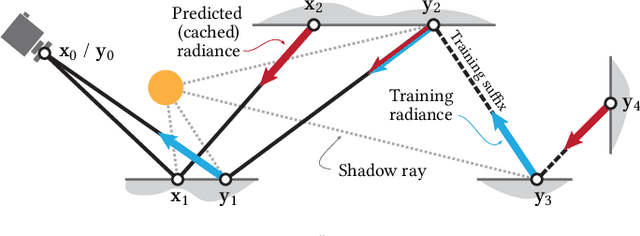
We present a real-time neural radiance caching method for path-traced global illumination. Our system is designed to handle fully dynamic scenes, and makes no assumptions about the lighting, geometry, and materials. The data-driven nature of our approach sidesteps many difficulties of caching algorithms, such as locating, interpolating, and updating cache points. Since pretraining neural networks to handle novel, dynamic scenes is a formidable generalization challenge, we do away with pretraining and instead achieve generalization via adaptation, i.e. we opt for training the radiance cache while rendering. We employ self-training to provide low-noise training targets and simulate infinite-bounce transport by merely iterating few-bounce training updates. The updates and cache queries incur a mild overhead -- about 2.6ms on full HD resolution -- thanks to a streaming implementation of the neural network that fully exploits modern hardware. We demonstrate significant noise reduction at the cost of little induced bias, and report state-of-the-art, real-time performance on a number of challenging scenarios.
Grasping the Arrow of Time from the Singularity: Decoding Micromotion in Low-dimensional Latent Spaces from StyleGAN
Apr 27, 2022
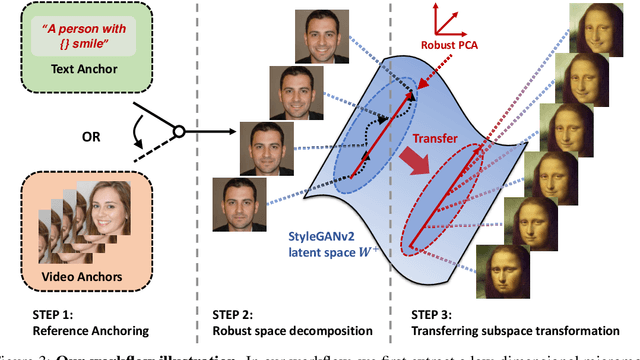


The disentanglement of StyleGAN latent space has paved the way for realistic and controllable image editing, but does StyleGAN know anything about temporal motion, as it was only trained on static images? To study the motion features in the latent space of StyleGAN, in this paper, we hypothesize and demonstrate that a series of meaningful, natural, and versatile small, local movements (referred to as "micromotion", such as expression, head movement, and aging effect) can be represented in low-rank spaces extracted from the latent space of a conventionally pre-trained StyleGAN-v2 model for face generation, with the guidance of proper "anchors" in the form of either short text or video clips. Starting from one target face image, with the editing direction decoded from the low-rank space, its micromotion features can be represented as simple as an affine transformation over its latent feature. Perhaps more surprisingly, such micromotion subspace, even learned from just single target face, can be painlessly transferred to other unseen face images, even those from vastly different domains (such as oil painting, cartoon, and sculpture faces). It demonstrates that the local feature geometry corresponding to one type of micromotion is aligned across different face subjects, and hence that StyleGAN-v2 is indeed "secretly" aware of the subject-disentangled feature variations caused by that micromotion. We present various successful examples of applying our low-dimensional micromotion subspace technique to directly and effortlessly manipulate faces, showing high robustness, low computational overhead, and impressive domain transferability. Our codes are available at https://github.com/wuqiuche/micromotion-StyleGAN.
Mip-NeRF RGB-D: Depth Assisted Fast Neural Radiance Fields
May 19, 2022
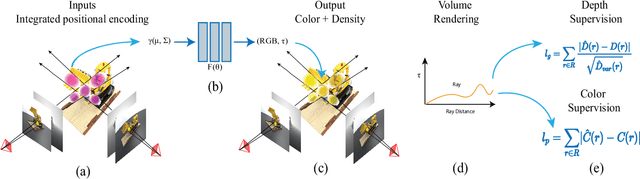
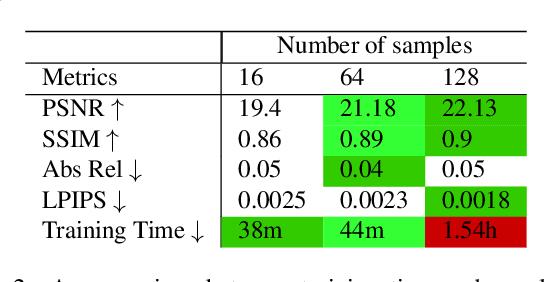
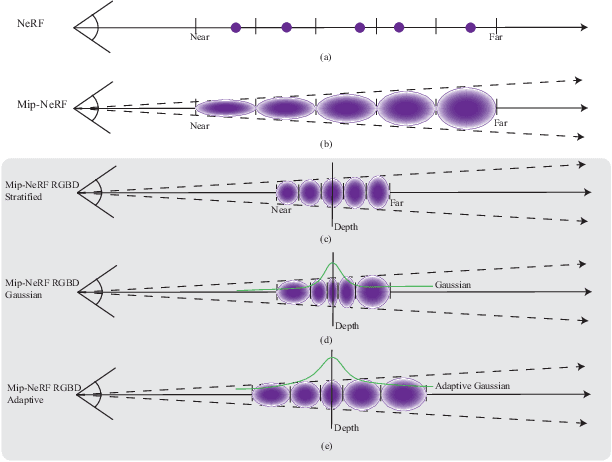
Neural scene representations, such as neural radiance fields (NeRF), are based on training a multilayer perceptron (MLP) using a set of color images with known poses. An increasing number of devices now produce RGB-D information, which has been shown to be very important for a wide range of tasks. Therefore, the aim of this paper is to investigate what improvements can be made to these promising implicit representations by incorporating depth information with the color images. In particular, the recently proposed Mip-NeRF approach, which uses conical frustums instead of rays for volume rendering, allows one to account for the varying area of a pixel with distance from the camera center. The proposed method additionally models depth uncertainty. This allows to address major limitations of NeRF-based approaches including improving the accuracy of geometry, reduced artifacts, faster training time, and shortened prediction time. Experiments are performed on well-known benchmark scenes, and comparisons show improved accuracy in scene geometry and photometric reconstruction, while reducing the training time by 3 - 5 times.
VertXNet: Automatic Segmentation and Identification of Lumbar and Cervical Vertebrae from Spinal X-ray Images
Jul 12, 2022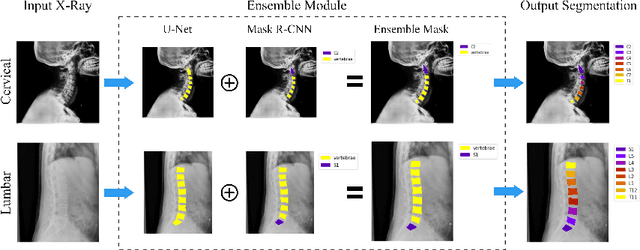
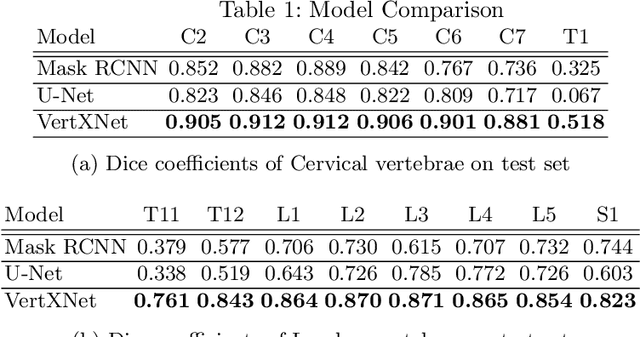
Manual annotation of vertebrae on spinal X-ray imaging is costly and time-consuming due to bone shape complexity and image quality variations. In this study, we address this challenge by proposing an ensemble method called VertXNet, to automatically segment and label vertebrae in X-ray spinal images. VertXNet combines two state-of-the-art segmentation models, namely U-Net and Mask R-CNN to improve vertebrae segmentation. A main feature of VertXNet is to also infer vertebrae labels thanks to its Mask R-CNN component (trained to detect 'reference' vertebrae) on a given spinal X-ray image. VertXNet was evaluated on an in-house dataset of lateral cervical and lumbar X-ray imaging for ankylosing spondylitis (AS) patients. Our results show that VertXNet can accurately label spinal X-rays (mean Dice of 0.9). It can be used to circumvent the lack of annotated vertebrae without requiring human expert review. This step is crucial to investigate clinical associations by solving the lack of segmentation, a common bottleneck for most computational imaging projects.
IMG-NILM: A Deep learning NILM approach using energy heatmaps
Jul 12, 2022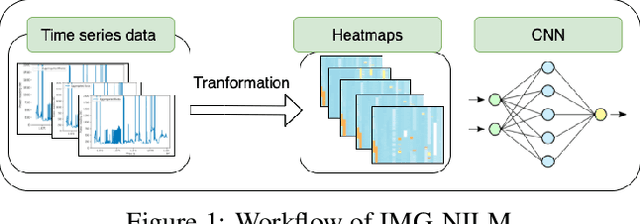
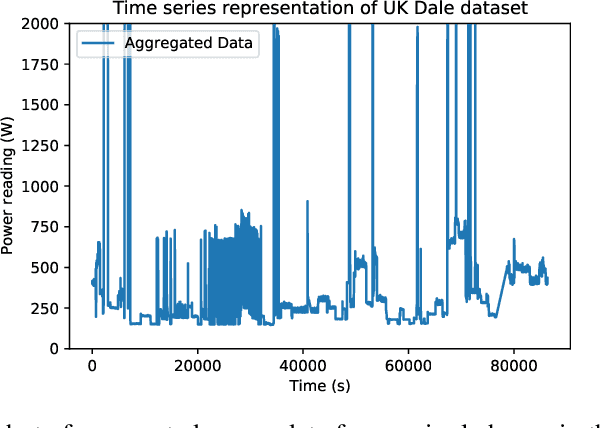
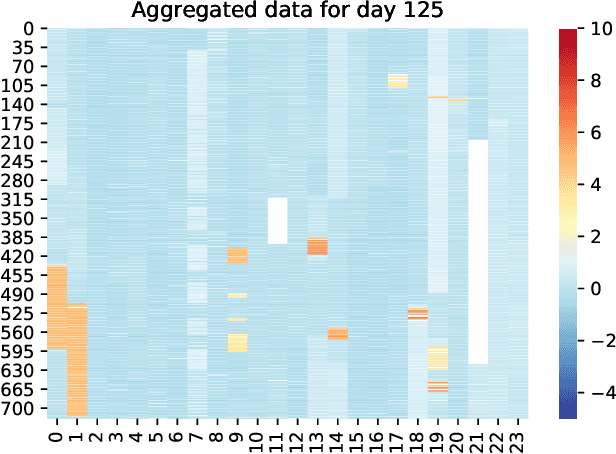
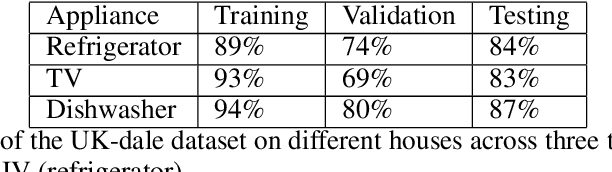
Energy disaggregation estimates appliance-by-appliance electricity consumption from a single meter that measures the whole home's electricity demand. Compared with intrusive load monitoring, NILM (Non-intrusive load monitoring) is low cost, easy to deploy, and flexible. In this paper, we propose a new method, coined IMG-NILM, that utilises convolutional neural networks (CNN) to disaggregate electricity data represented as images. CNN is proven to be efficient with images, hence, instead of the traditional representation of electricity data as time series, data is transformed into heatmaps with higher electricity readings portrayed as 'hotter' colours. The image representation is then used in CNN to detect the signature of an appliance from aggregated data. IMG-NILM is flexible and shows consistent performance in disaggregating various types of appliances; including single and multiple states. It attains a test accuracy of up to 93% on the UK dale dataset within a single house, where a substantial number of appliances are present. In more challenging settings where electricity data is collected from different houses, IMG-NILM attains also a very good average accuracy of 85%.
Designing An Illumination-Aware Network for Deep Image Relighting
Jul 21, 2022
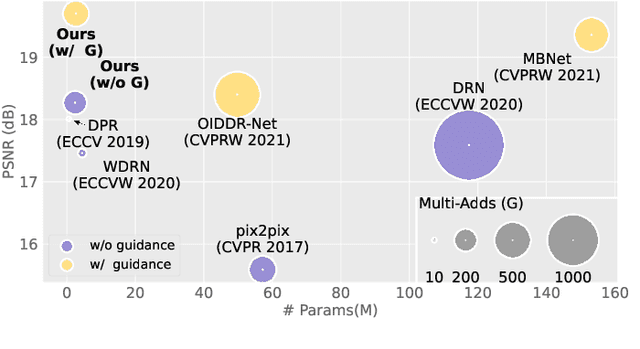


Lighting is a determining factor in photography that affects the style, expression of emotion, and even quality of images. Creating or finding satisfying lighting conditions, in reality, is laborious and time-consuming, so it is of great value to develop a technology to manipulate illumination in an image as post-processing. Although previous works have explored techniques based on the physical viewpoint for relighting images, extensive supervisions and prior knowledge are necessary to generate reasonable images, restricting the generalization ability of these works. In contrast, we take the viewpoint of image-to-image translation and implicitly merge ideas of the conventional physical viewpoint. In this paper, we present an Illumination-Aware Network (IAN) which follows the guidance from hierarchical sampling to progressively relight a scene from a single image with high efficiency. In addition, an Illumination-Aware Residual Block (IARB) is designed to approximate the physical rendering process and to extract precise descriptors of light sources for further manipulations. We also introduce a depth-guided geometry encoder for acquiring valuable geometry- and structure-related representations once the depth information is available. Experimental results show that our proposed method produces better quantitative and qualitative relighting results than previous state-of-the-art methods. The code and models are publicly available on https://github.com/NK-CS-ZZL/IAN.
TransFA: Transformer-based Representation for Face Attribute Evaluation
Jul 12, 2022
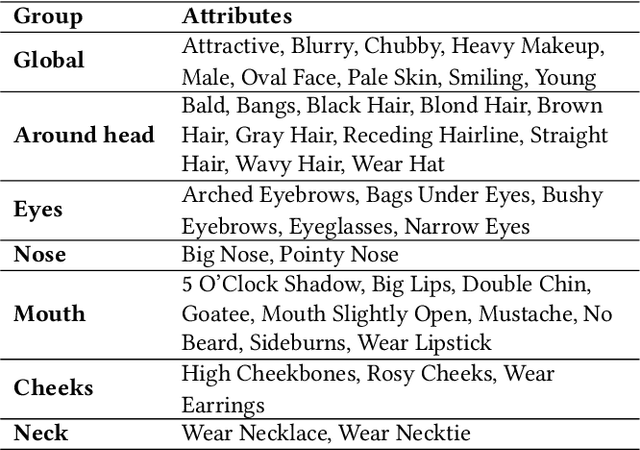
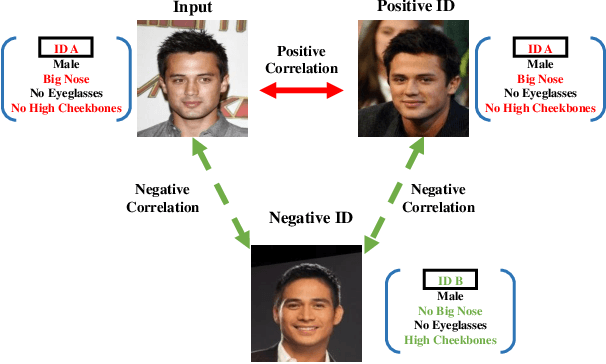
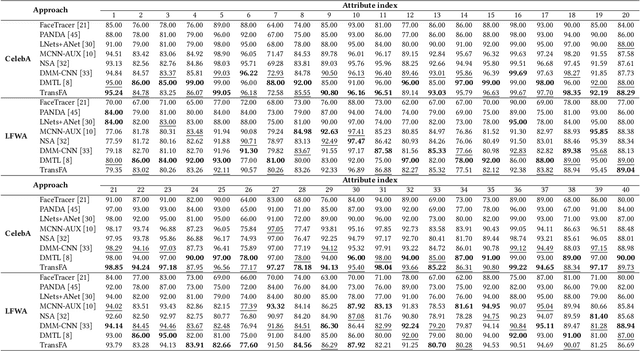
Face attribute evaluation plays an important role in video surveillance and face analysis. Although methods based on convolution neural networks have made great progress, they inevitably only deal with one local neighborhood with convolutions at a time. Besides, existing methods mostly regard face attribute evaluation as the individual multi-label classification task, ignoring the inherent relationship between semantic attributes and face identity information. In this paper, we propose a novel \textbf{trans}former-based representation for \textbf{f}ace \textbf{a}ttribute evaluation method (\textbf{TransFA}), which could effectively enhance the attribute discriminative representation learning in the context of attention mechanism. The multiple branches transformer is employed to explore the inter-correlation between different attributes in similar semantic regions for attribute feature learning. Specially, the hierarchical identity-constraint attribute loss is designed to train the end-to-end architecture, which could further integrate face identity discriminative information to boost performance. Experimental results on multiple face attribute benchmarks demonstrate that the proposed TransFA achieves superior performances compared with state-of-the-art methods.
Support Vector Machines with the Hard-Margin Loss: Optimal Training via Combinatorial Benders' Cuts
Jul 15, 2022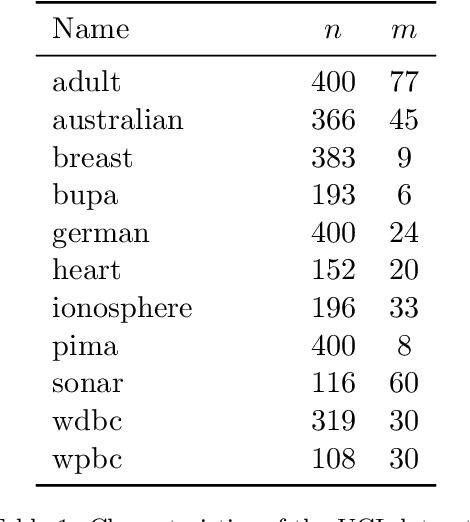
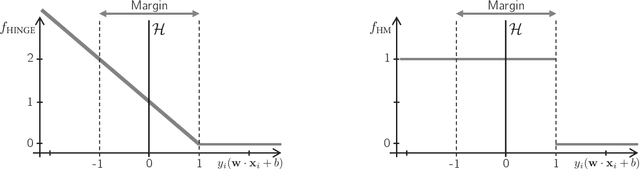

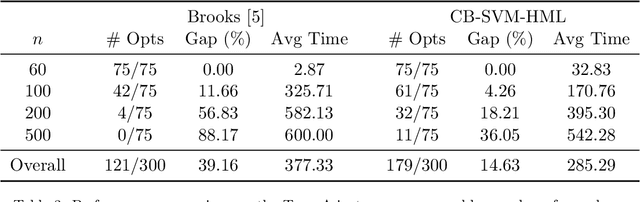
The classical hinge-loss support vector machines (SVMs) model is sensitive to outlier observations due to the unboundedness of its loss function. To circumvent this issue, recent studies have focused on non-convex loss functions, such as the hard-margin loss, which associates a constant penalty to any misclassified or within-margin sample. Applying this loss function yields much-needed robustness for critical applications but it also leads to an NP-hard model that makes training difficult, since current exact optimization algorithms show limited scalability, whereas heuristics are not able to find high-quality solutions consistently. Against this background, we propose new integer programming strategies that significantly improve our ability to train the hard-margin SVM model to global optimality. We introduce an iterative sampling and decomposition approach, in which smaller subproblems are used to separate combinatorial Benders' cuts. Those cuts, used within a branch-and-cut algorithm, permit to converge much more quickly towards a global optimum. Through extensive numerical analyses on classical benchmark data sets, our solution algorithm solves, for the first time, 117 new data sets to optimality and achieves a reduction of 50% in the average optimality gap for the hardest datasets of the benchmark.
Electromagnetic Signal Injection Attacks on Differential Signaling
Jul 31, 2022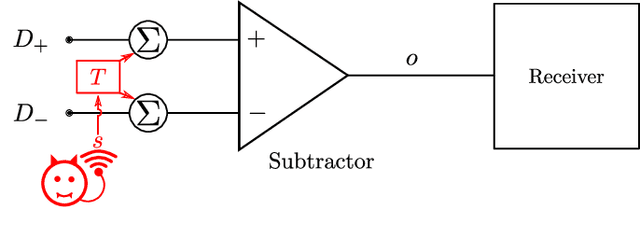
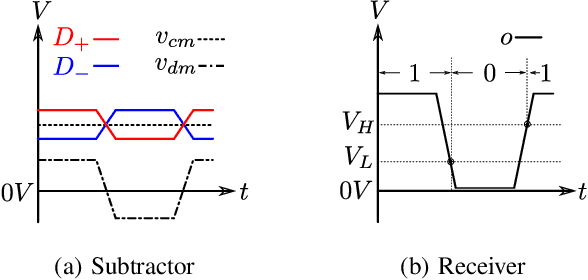
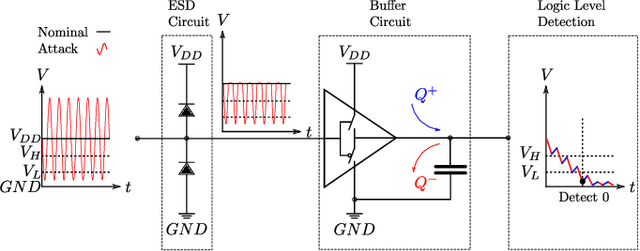
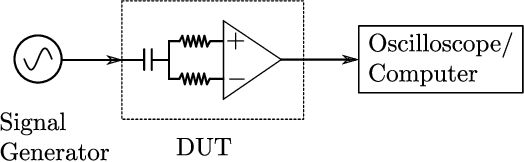
Differential signaling is a method of data transmission that uses two complementary electrical signals to encode information. This allows a receiver to reject any noise by looking at the difference between the two signals, assuming the noise affects both signals in the same way. Many protocols such as USB, Ethernet, and HDMI use differential signaling to achieve a robust communication channel in a noisy environment. This generally works well and has led many to believe that it is infeasible to remotely inject attacking signals into such a differential pair. In this paper we challenge this assumption and show that an adversary can in fact inject malicious signals from a distance, purely using common-mode injection, i.e., injecting into both wires at the same time. We show how this allows an attacker to inject bits or even arbitrary messages into a communication line. Such an attack is a significant threat to many applications, from home security and privacy to automotive systems, critical infrastructure, or implantable medical devices; in which incorrect data or unauthorized control could cause significant damage, or even fatal accidents. We show in detail the principles of how an electromagnetic signal can bypass the noise rejection of differential signaling, and eventually result in incorrect bits in the receiver. We show how an attacker can exploit this to achieve a successful injection of an arbitrary bit, and we analyze the success rate of injecting longer arbitrary messages. We demonstrate the attack on a real system and show that the success rate can reach as high as $90\%$. Finally, we present a case study where we wirelessly inject a message into a Controller Area Network (CAN) bus, which is a differential signaling bus protocol used in many critical applications, including the automotive and aviation sector.
libACA, pyACA, and ACA-Code: Audio Content Analysis in 3 Languages
Jun 30, 2022The three packages libACA, pyACA, and ACA-Code provide reference implementations for basic approaches and algorithms for the analysis of musical audio signals in three different languages: C++, Python, and Matlab. All three packages cover the same algorithms, such as extraction of low level audio features, fundamental frequency estimation, as well as simple approaches to chord recognition, musical key detection, and onset detection. In addition, it implementations of more generic algorithms useful in audio content analysis such as dynamic time warping and the Viterbi algorithm are provided. The three packages thus provide a practical cross-language and cross-platform reference to students and engineers implementing audio analysis algorithms and enable implementation-focused learning of algorithms for audio content analysis and music information retrieval.