 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning to Estimate External Forces of Human Motion in Video
Jul 12, 2022
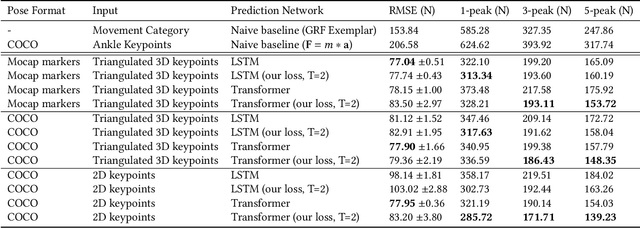


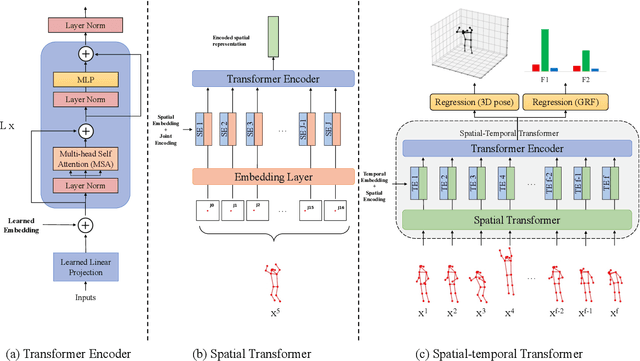
Analyzing sports performance or preventing injuries requires capturing ground reaction forces (GRFs) exerted by the human body during certain movements. Standard practice uses physical markers paired with force plates in a controlled environment, but this is marred by high costs, lengthy implementation time, and variance in repeat experiments; hence, we propose GRF inference from video. While recent work has used LSTMs to estimate GRFs from 2D viewpoints, these can be limited in their modeling and representation capacity. First, we propose using a transformer architecture to tackle the GRF from video task, being the first to do so. Then we introduce a new loss to minimize high impact peaks in regressed curves. We also show that pre-training and multi-task learning on 2D-to-3D human pose estimation improves generalization to unseen motions. And pre-training on this different task provides good initial weights when finetuning on smaller (rarer) GRF datasets. We evaluate on LAAS Parkour and a newly collected ForcePose dataset; we show up to 19% decrease in error compared to prior approaches.
Placing (Historical) Facts on a Timeline: A Classification cum Coref Resolution Approach
Jun 28, 2022
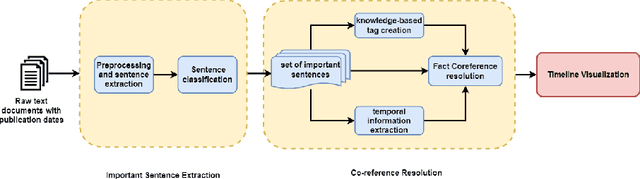
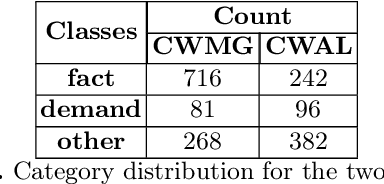
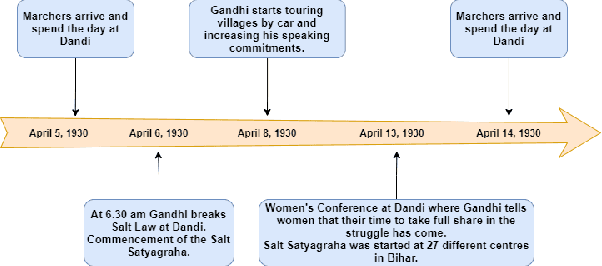
A timeline provides one of the most effective ways to visualize the important historical facts that occurred over a period of time, presenting the insights that may not be so apparent from reading the equivalent information in textual form. By leveraging generative adversarial learning for important sentence classification and by assimilating knowledge based tags for improving the performance of event coreference resolution we introduce a two staged system for event timeline generation from multiple (historical) text documents. We demonstrate our results on two manually annotated historical text documents. Our results can be extremely helpful for historians, in advancing research in history and in understanding the socio-political landscape of a country as reflected in the writings of famous personas.
Characterizing Coherent Integrated Photonic Neural Networks under Imperfections
Jul 22, 2022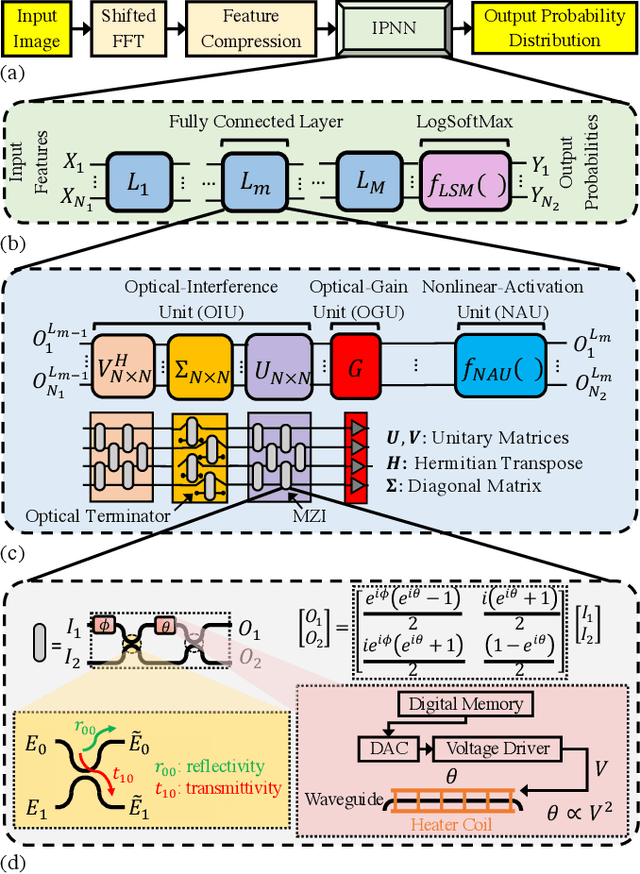
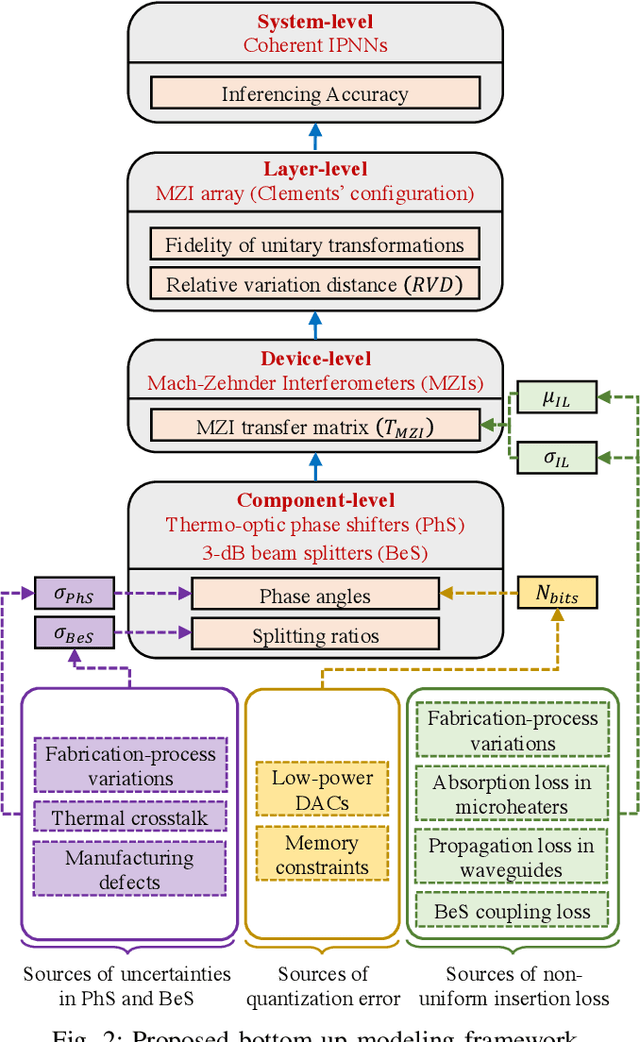
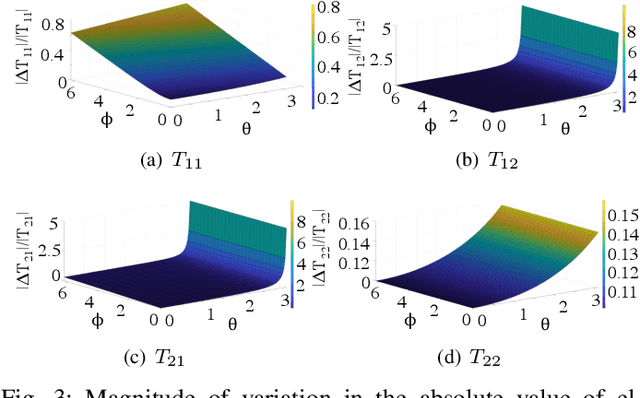
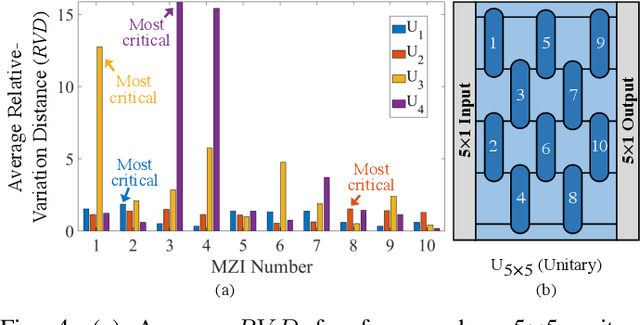
Integrated photonic neural networks (IPNNs) are emerging as promising successors to conventional electronic AI accelerators as they offer substantial improvements in computing speed and energy efficiency. In particular, coherent IPNNs use arrays of Mach-Zehnder interferometers (MZIs) for unitary transformations to perform energy-efficient matrix-vector multiplication. However, the underlying MZI devices in IPNNs are susceptible to uncertainties stemming from optical lithographic variations and thermal crosstalk and can experience imprecisions due to non-uniform MZI insertion loss and quantization errors due to low-precision encoding in the tuned phase angles. In this paper, we, for the first time, systematically characterize the impact of such uncertainties and imprecisions (together referred to as imperfections) in IPNNs using a bottom-up approach. We show that their impact on IPNN accuracy can vary widely based on the tuned parameters (e.g., phase angles) of the affected components, their physical location, and the nature and distribution of the imperfections. To improve reliability measures, we identify critical IPNN building blocks that, under imperfections, can lead to catastrophic degradation in the classification accuracy. We show that under multiple simultaneous imperfections, the IPNN inferencing accuracy can degrade by up to 46%, even when the imperfection parameters are restricted within a small range. Our results also indicate that the inferencing accuracy is sensitive to imperfections affecting the MZIs in the linear layers next to the input layer of the IPNN.
Real-time Neural Radiance Caching for Path Tracing
Jun 25, 2021

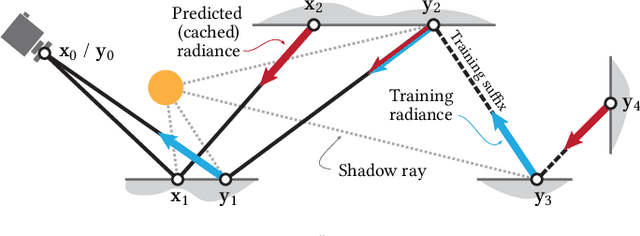
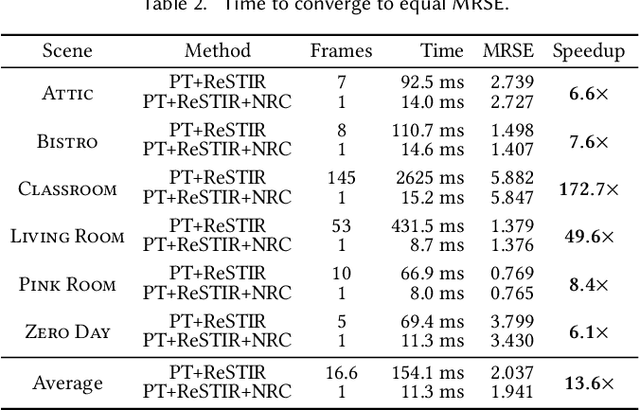
We present a real-time neural radiance caching method for path-traced global illumination. Our system is designed to handle fully dynamic scenes, and makes no assumptions about the lighting, geometry, and materials. The data-driven nature of our approach sidesteps many difficulties of caching algorithms, such as locating, interpolating, and updating cache points. Since pretraining neural networks to handle novel, dynamic scenes is a formidable generalization challenge, we do away with pretraining and instead achieve generalization via adaptation, i.e. we opt for training the radiance cache while rendering. We employ self-training to provide low-noise training targets and simulate infinite-bounce transport by merely iterating few-bounce training updates. The updates and cache queries incur a mild overhead -- about 2.6ms on full HD resolution -- thanks to a streaming implementation of the neural network that fully exploits modern hardware. We demonstrate significant noise reduction at the cost of little induced bias, and report state-of-the-art, real-time performance on a number of challenging scenarios.
Multi-label Classification with High-rank and High-order Label Correlations
Jul 09, 2022
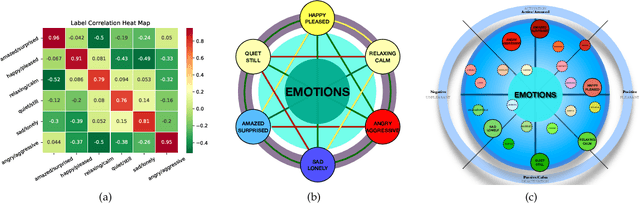

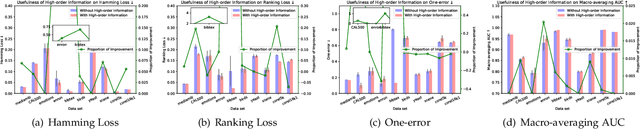
Exploiting label correlations is important to multi-label classification. Previous methods capture the high-order label correlations mainly by transforming the label matrix to a latent label space with low-rank matrix factorization. However, the label matrix is generally a full-rank or approximate full-rank matrix, making the low-rank factorization inappropriate. Besides, in the latent space, the label correlations will become implicit. To this end, we propose a simple yet effective method to depict the high-order label correlations explicitly, and at the same time maintain the high-rank of the label matrix. Moreover, we estimate the label correlations and infer model parameters simultaneously via the local geometric structure of the input to achieve mutual enhancement. Comparative studies over ten benchmark data sets validate the effectiveness of the proposed algorithm in multi-label classification. The exploited high-order label correlations are consistent with common sense empirically. Our code is publicly available at https://github.com/601175936/HOMI.
Yankee Swap: a Fast and Simple Fair Allocation Mechanism for Matroid Rank Valuations
Jun 28, 2022
We study fair allocation of indivisible goods when agents have matroid rank valuations. Our main contribution is a simple algorithm based on the colloquial Yankee Swap procedure that computes provably fair and efficient Lorenz dominating allocations. While there exist polynomial time algorithms to compute such allocations, our proposed method improves on them in two ways. (a) Our approach is easy to understand and does not use complex matroid optimization algorithms as subroutines. (b) Our approach is scalable; it is provably faster than all known algorithms to compute Lorenz dominating allocations. These two properties are key to the adoption of algorithms in any real fair allocation setting; our contribution brings us one step closer to this goal.
Towards a Low-SWaP 1024-beam Digital Array: A 32-beam Sub-system at 5.8 GHz
Jul 19, 2022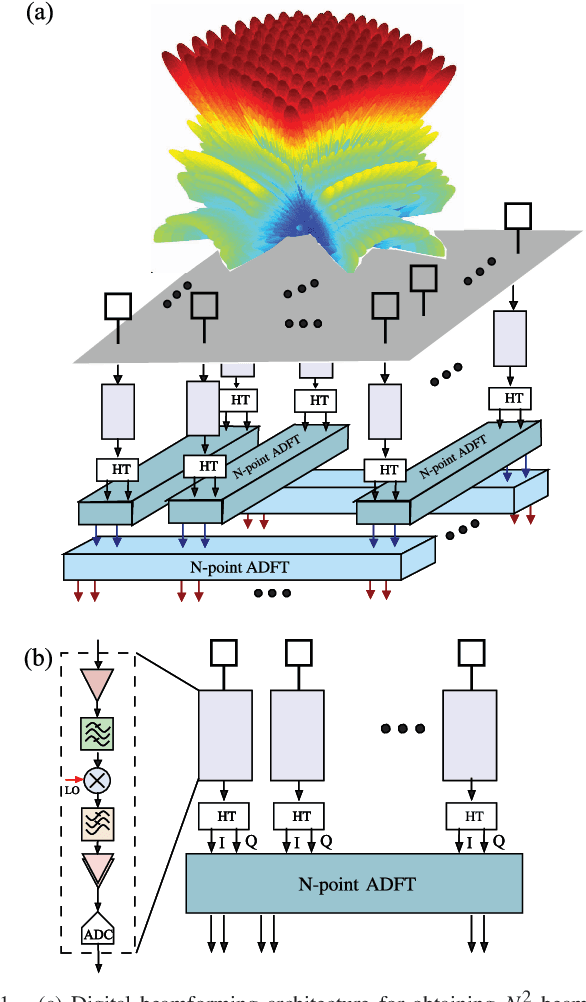
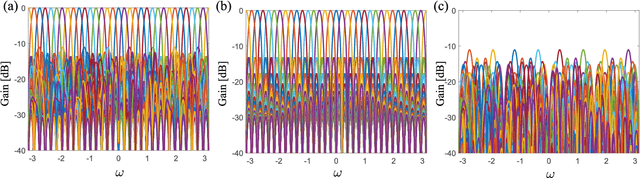
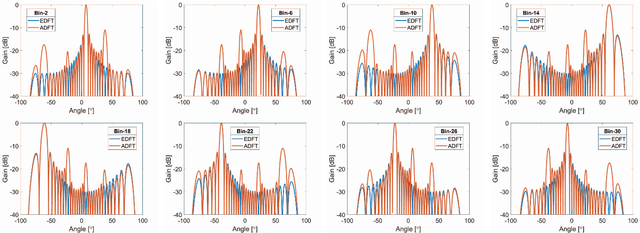
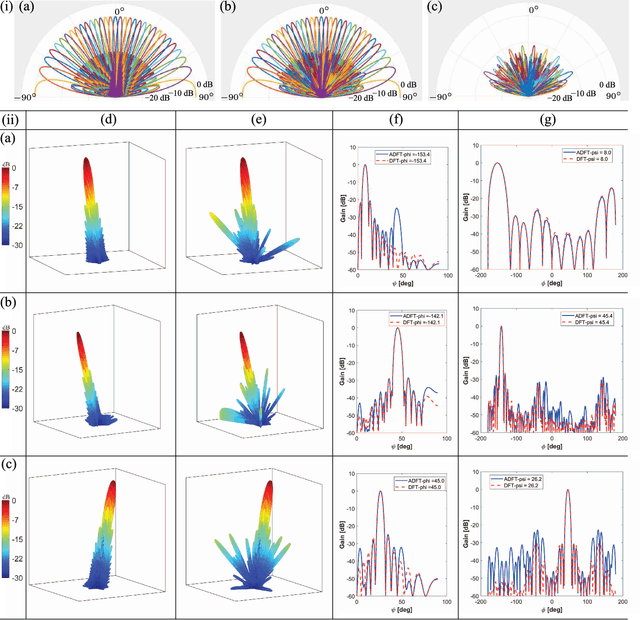
Millimeter wave communications require multibeam beamforming in order to utilize wireless channels that suffer from obstructions, path loss, and multi-path effects. Digital multibeam beamforming has maximum degrees of freedom compared to analog phased arrays. However, circuit complexity and power consumption are important constraints for digital multibeam systems. A low-complexity digital computing architecture is proposed for a multiplication-free 32-point linear transform that approximates multiple simultaneous RF beams similar to a discrete Fourier transform (DFT). Arithmetic complexity due to multiplication is reduced from the FFT complexity of $\mathcal{O}(N\: \log N)$ for DFT realizations, down to zero, thus yielding a 46% and 55% reduction in chip area and dynamic power consumption, respectively, for the $N=32$ case considered. The paper describes the proposed 32-point DFT approximation targeting a 1024-beams using a 2D array, and shows the multiplierless approximation and its mapping to a 32-beam sub-system consisting of 5.8 GHz antennas that can be used for generating 1024 digital beams without multiplications. Real-time beam computation is achieved using a Xilinx FPGA at 120 MHz bandwidth per beam. Theoretical beam performance is compared with measured RF patterns from both a fixed-point FFT as well as the proposed multiplier-free algorithm and are in good agreement.
* 19 pages, 8 figures, 4 tables. This version corrects a typo in the matrix equations from Section 3
Sedentary Behavior Estimation with Hip-worn Accelerometer Data: Segmentation, Classification and Thresholding
Jul 05, 2022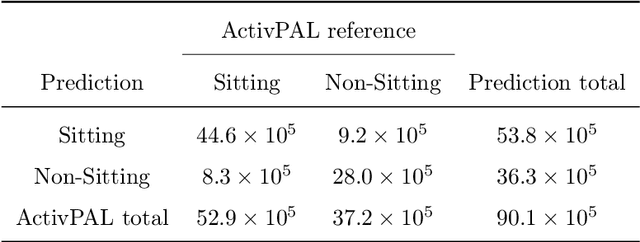
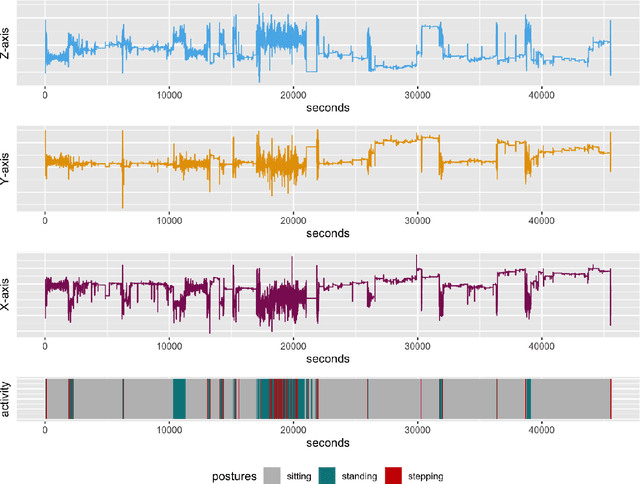
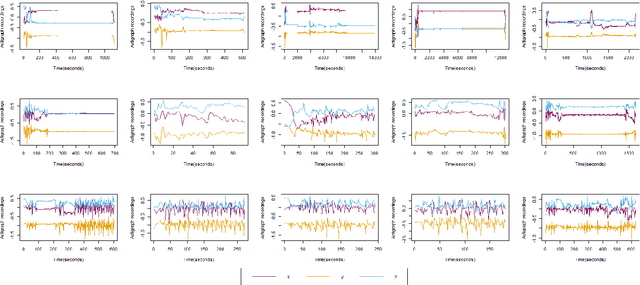
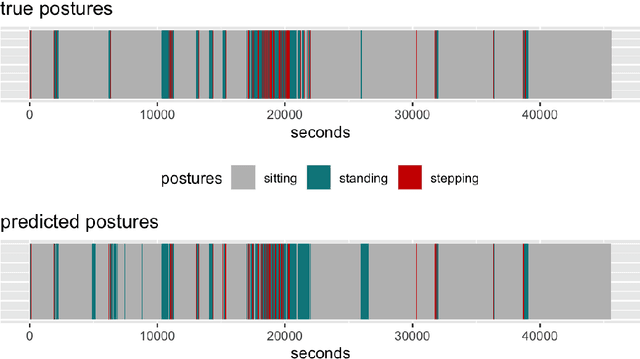
Cohort studies are increasingly using accelerometers for physical activity and sedentary behavior estimation. These devices tend to be less error-prone than self-report, can capture activity throughout the day, and are economical. However, previous methods for estimating sedentary behavior based on hip-worn data are often invalid or suboptimal under free-living situations and subject-to-subject variation. In this paper, we propose a local Markov switching model that takes this situation into account, and introduce a general procedure for posture classification and sedentary behavior analysis that fits the model naturally. Our method features changepoint detection methods in time series and also a two stage classification step that labels data into 3 classes(sitting, standing, stepping). Through a rigorous training-testing paradigm, we showed that our approach achieves > 80% accuracy. In addition, our method is robust and easy to interpret.
Decorrelative Network Architecture for Robust Electrocardiogram Classification
Jul 19, 2022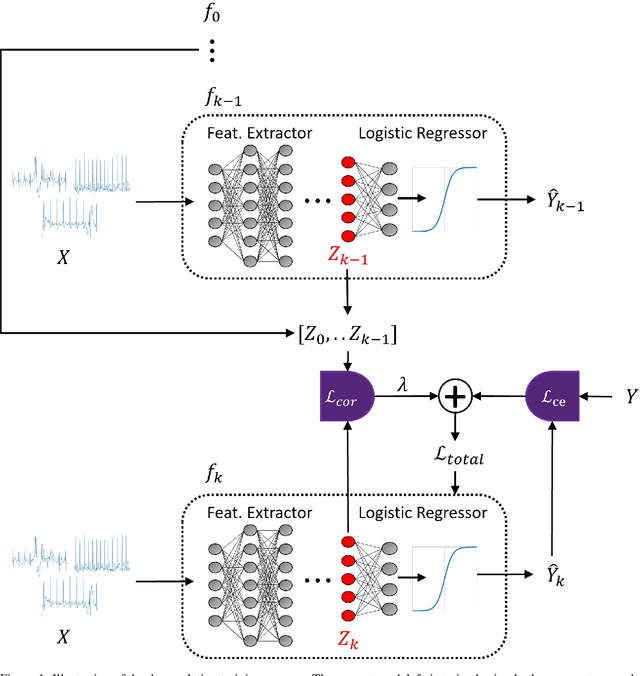
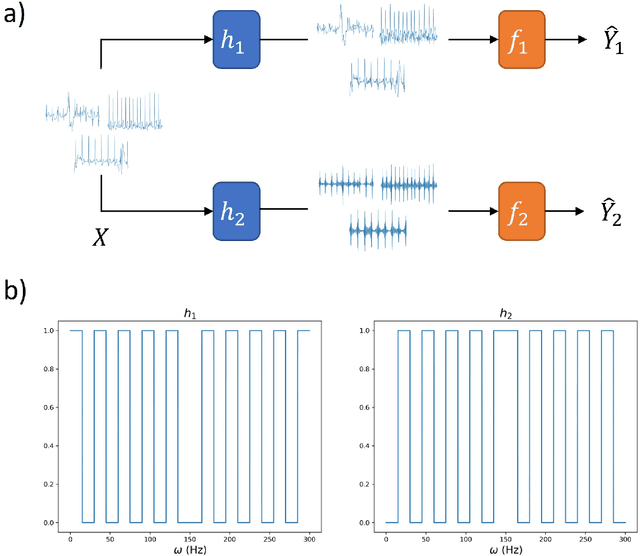
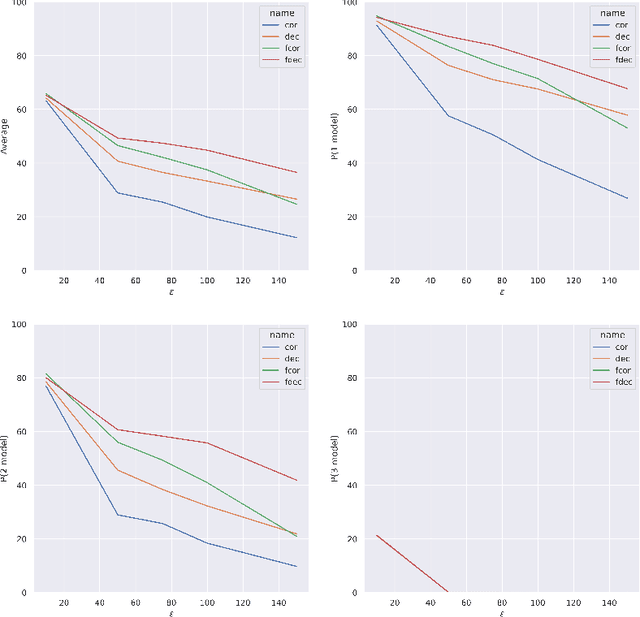
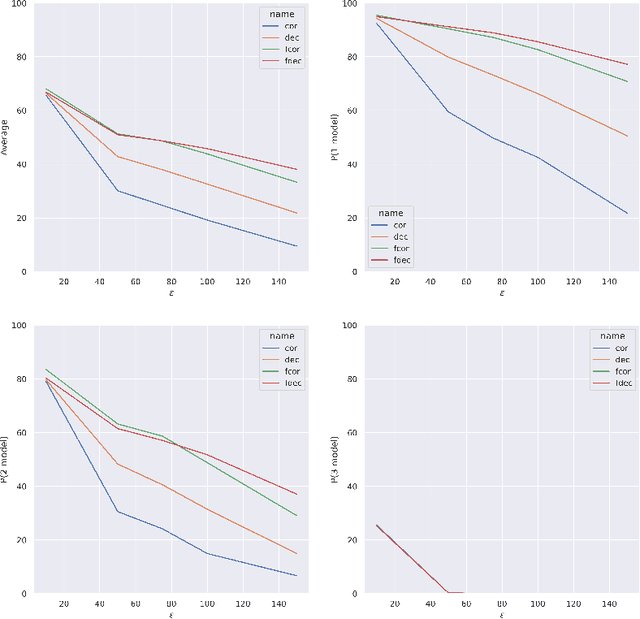
Artificial intelligence has made great progresses in medical data analysis, but the lack of robustness and interpretability has kept these methods from being widely deployed. In particular, data-driven models are vulnerable to adversarial attacks, which are small, targeted perturbations that dramatically degrade model performance. As a recent example, while deep learning has shown impressive performance in electrocardiogram (ECG) classification, Han et al. crafted realistic perturbations that fooled the network 74% of the time [2020]. Current adversarial defense paradigms are computationally intensive and impractical for many high dimensional problems. Previous research indicates that a network vulnerability is related to the features learned during training. We propose a novel approach based on ensemble decorrelation and Fourier partitioning for training parallel network arms into a decorrelated architecture to learn complementary features, significantly reducing the chance of a perturbation fooling all arms of the deep learning model. We test our approach in ECG classification, demonstrating a much-improved 77.2% chance of at least one correct network arm on the strongest adversarial attack tested, in contrast to a 21.7% chance from a comparable ensemble. Our approach does not require expensive optimization with adversarial samples, and thus can be scaled to large problems. These methods can easily be applied to other tasks for improved network robustness.
Human Treelike Tubular Structure Segmentation: A Comprehensive Review and Future Perspectives
Jul 12, 2022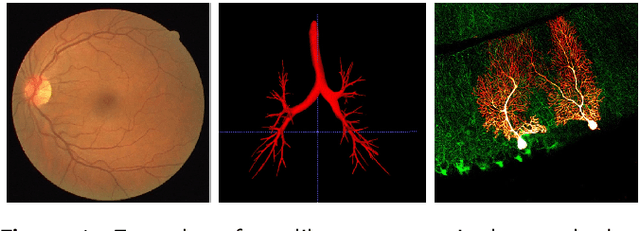
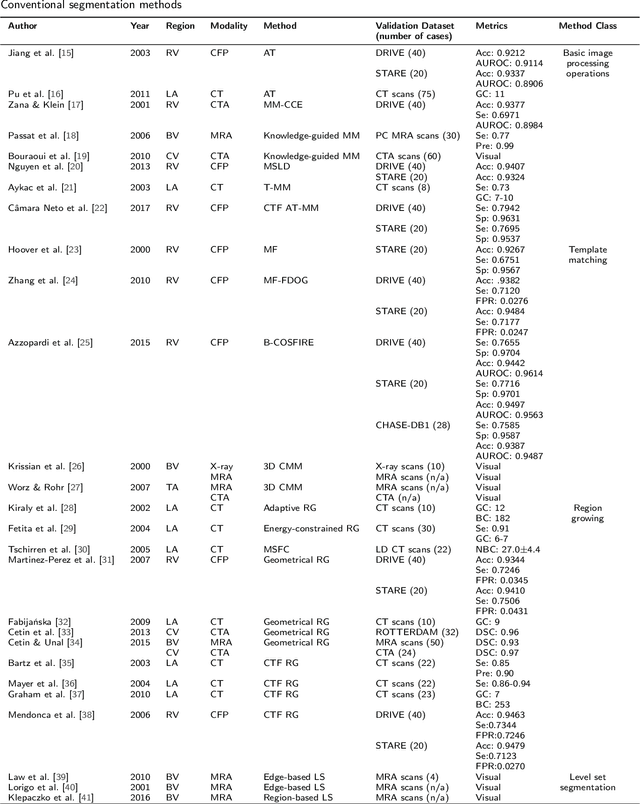
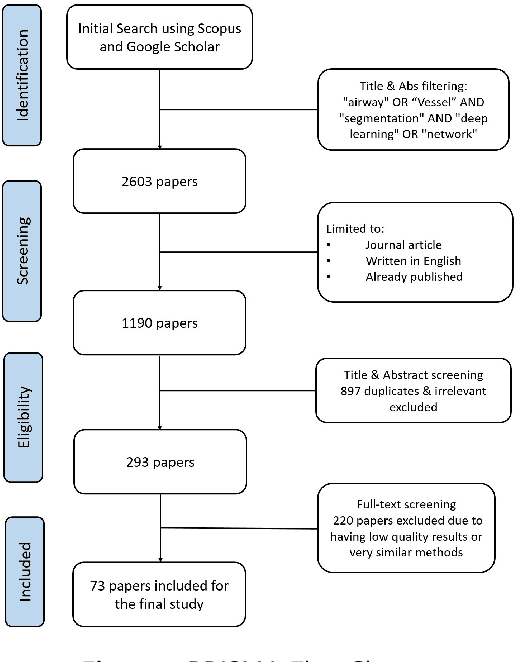
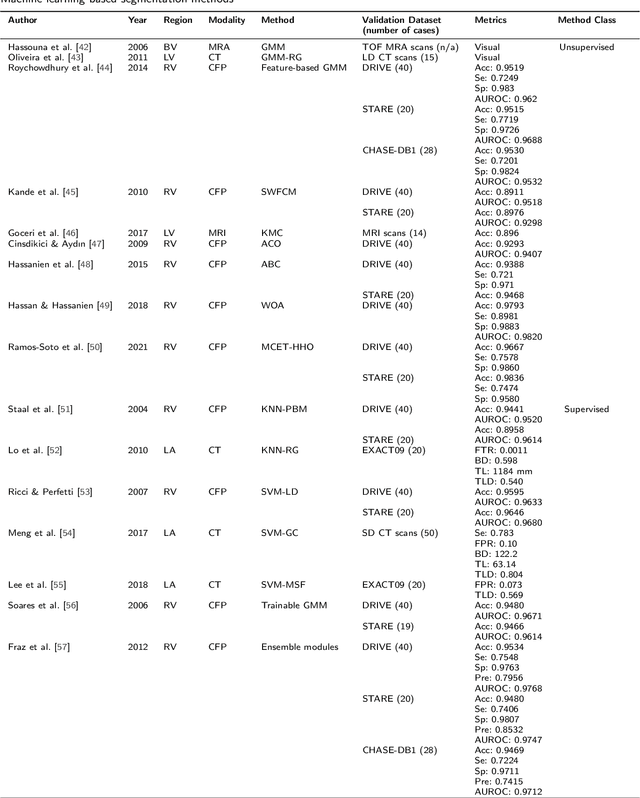
Various structures in human physiology follow a treelike morphology, which often expresses complexity at very fine scales. Examples of such structures are intrathoracic airways, retinal blood vessels, and hepatic blood vessels. Large collections of 2D and 3D images have been made available by medical imaging modalities such as magnetic resonance imaging (MRI), computed tomography (CT), Optical coherence tomography (OCT) and ultrasound in which the spatial arrangement can be observed. Segmentation of these structures in medical imaging is of great importance since the analysis of the structure provides insights into disease diagnosis, treatment planning, and prognosis. Manually labelling extensive data by radiologists is often time-consuming and error-prone. As a result, automated or semi-automated computational models have become a popular research field of medical imaging in the past two decades, and many have been developed to date. In this survey, we aim to provide a comprehensive review of currently publicly available datasets, segmentation algorithms, and evaluation metrics. In addition, current challenges and future research directions are discussed.