 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Trajectory and Resource Optimization for UAV Synthetic Aperture Radar
Jul 12, 2022
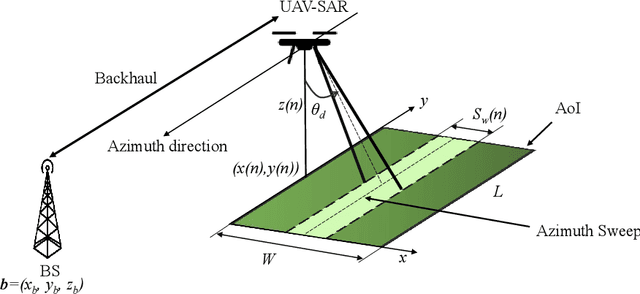
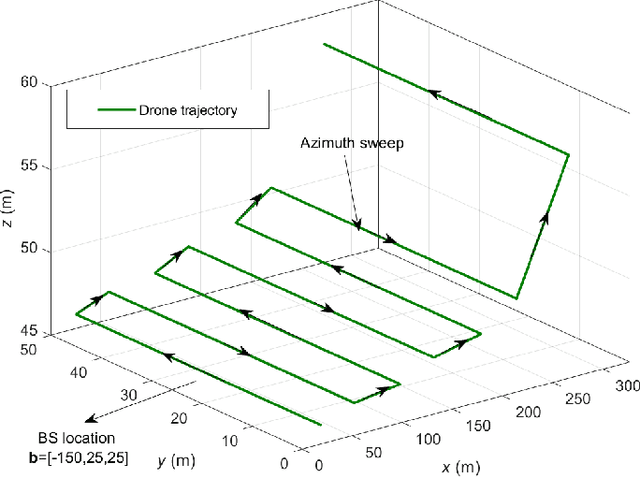
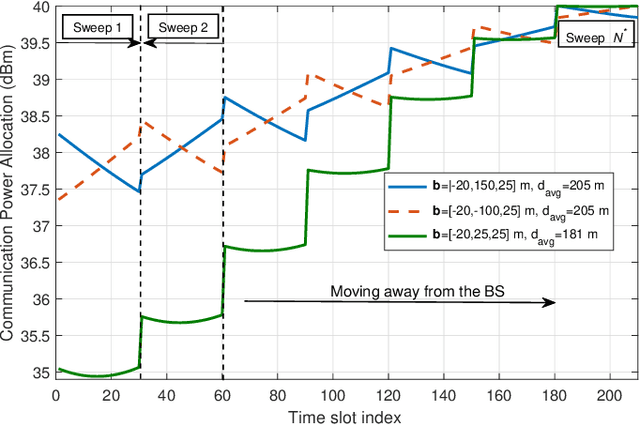
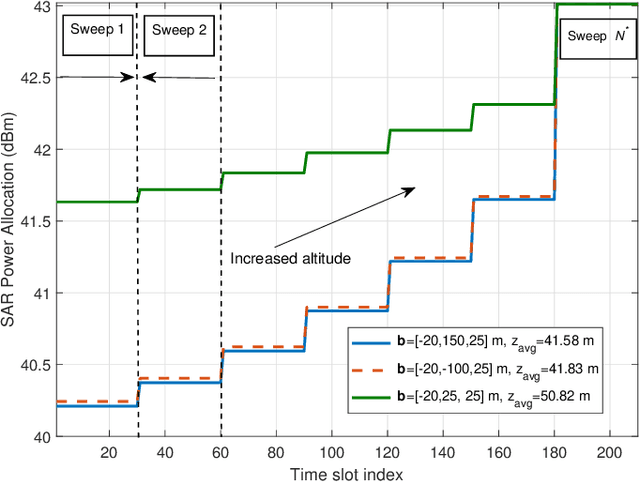
In this paper, we study the trajectory and resource optimization for lightweight rotary-wing unmanned aerial vehicles (UAVs) equipped with a synthetic aperture radar (SAR) system. The UAV's mission is to perform SAR imaging of a given area of interest (AoI). In this setup, real-time communication with a base station (BS) is required to facilitate live mission planning for the drone. For this purpose, a non-convex mixed-integer non-linear program (MINLP) is formulated such that the UAV resources and three-dimensional (3D) trajectory are jointly optimized for maximization of the drone radar ground coverage. We present a low-complexity sub-optimal algorithm based on successive convex approximation (SCA) for solving the problem, and perform a finite search to optimize the total distance traversed by the UAV for maximal coverage. We show that the proposed 3D trajectory planning achieves at least 70% improvement in radar ground coverage compared to benchmark schemes employing constant powers for communication or radar imaging. We also show that positioning the BS near the AoI can significantly improve the radar coverage of the UAV.
Batch-efficient EigenDecomposition for Small and Medium Matrices
Jul 09, 2022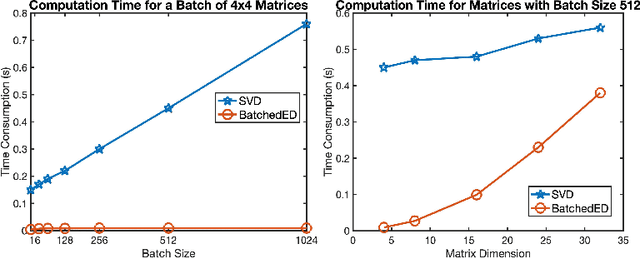

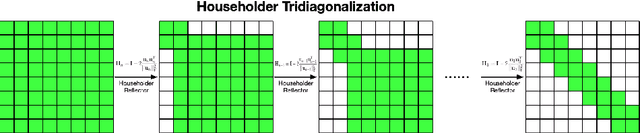
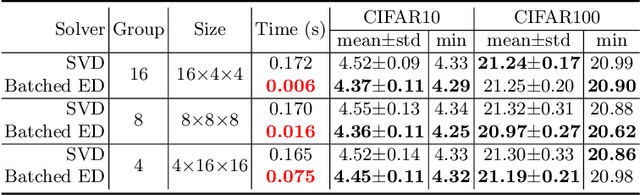
EigenDecomposition (ED) is at the heart of many computer vision algorithms and applications. One crucial bottleneck limiting its usage is the expensive computation cost, particularly for a mini-batch of matrices in the deep neural networks. In this paper, we propose a QR-based ED method dedicated to the application scenarios of computer vision. Our proposed method performs the ED entirely by batched matrix/vector multiplication, which processes all the matrices simultaneously and thus fully utilizes the power of GPUs. Our technique is based on the explicit QR iterations by Givens rotation with double Wilkinson shifts. With several acceleration techniques, the time complexity of QR iterations is reduced from $O{(}n^5{)}$ to $O{(}n^3{)}$. The numerical test shows that for small and medium batched matrices (\emph{e.g.,} $dim{<}32$) our method can be much faster than the Pytorch SVD function. Experimental results on visual recognition and image generation demonstrate that our methods also achieve competitive performances.
Discovering Dynamic Functional Brain Networks via Spatial and Channel-wise Attention
May 31, 2022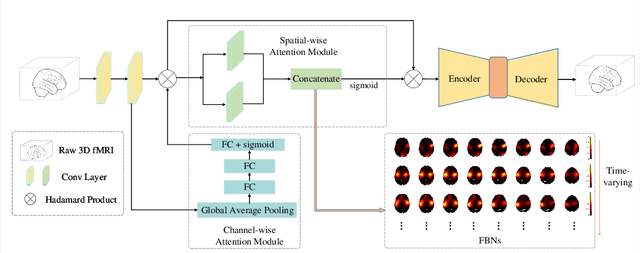
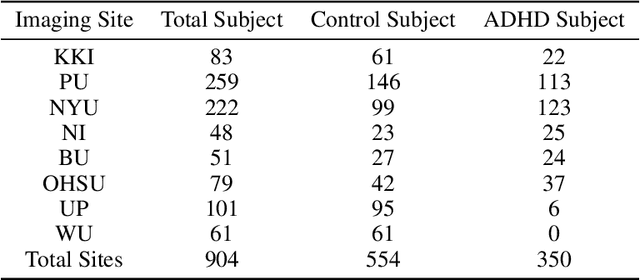


Using deep learning models to recognize functional brain networks (FBNs) in functional magnetic resonance imaging (fMRI) has been attracting increasing interest recently. However, most existing work focuses on detecting static FBNs from entire fMRI signals, such as correlation-based functional connectivity. Sliding-window is a widely used strategy to capture the dynamics of FBNs, but it is still limited in representing intrinsic functional interactive dynamics at each time step. And the number of FBNs usually need to be set manually. More over, due to the complexity of dynamic interactions in brain, traditional linear and shallow models are insufficient in identifying complex and spatially overlapped FBNs across each time step. In this paper, we propose a novel Spatial and Channel-wise Attention Autoencoder (SCAAE) for discovering FBNs dynamically. The core idea of SCAAE is to apply attention mechanism to FBNs construction. Specifically, we designed two attention modules: 1) spatial-wise attention (SA) module to discover FBNs in the spatial domain and 2) a channel-wise attention (CA) module to weigh the channels for selecting the FBNs automatically. We evaluated our approach on ADHD200 dataset and our results indicate that the proposed SCAAE method can effectively recover the dynamic changes of the FBNs at each fMRI time step, without using sliding windows. More importantly, our proposed hybrid attention modules (SA and CA) do not enforce assumptions of linearity and independence as previous methods, and thus provide a novel approach to better understanding dynamic functional brain networks.
Linear Bandit Algorithms with Sublinear Time Complexity
Mar 03, 2021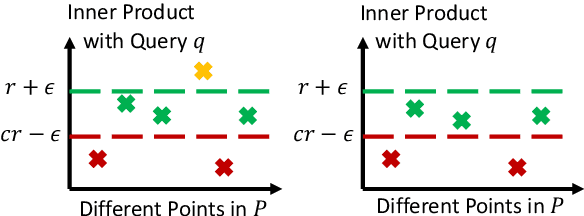
We propose to accelerate existing linear bandit algorithms to achieve per-step time complexity sublinear in the number of arms $K$. The key to sublinear complexity is the realization that the arm selection in many linear bandit algorithms reduces to the maximum inner product search (MIPS) problem. Correspondingly, we propose an algorithm that approximately solves the MIPS problem for a sequence of adaptive queries yielding near-linear preprocessing time complexity and sublinear query time complexity. Using the proposed MIPS solver as a sub-routine, we present two bandit algorithms (one based on UCB, and the other based on TS) that achieve sublinear time complexity. We explicitly characterize the tradeoff between the per-step time complexity and regret, and show that our proposed algorithms can achieve $O(K^{1-\alpha(T)})$ per-step complexity for some $\alpha(T) > 0$ and $\widetilde O(\sqrt{T})$ regret, where $T$ is the time horizon. Further, we present the theoretical limit of the tradeoff, which provides a lower bound for the per-step time complexity. We also discuss other choices of approximate MIPS algorithms and other applications to linear bandit problems.
eCDT: Event Clustering for Simultaneous Feature Detection and Tracking-
Jul 19, 2022

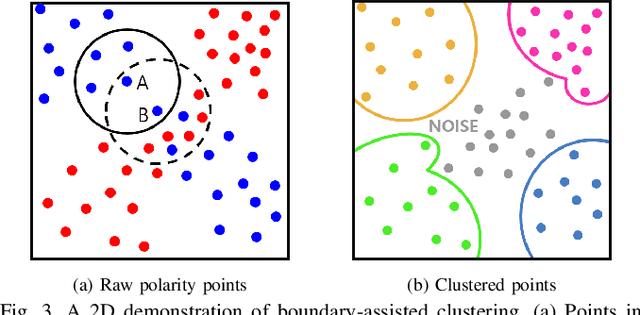

Contrary to other standard cameras, event cameras interpret the world in an entirely different manner; as a collection of asynchronous events. Despite event camera's unique data output, many event feature detection and tracking algorithms have shown significant progress by making detours to frame-based data representations. This paper questions the need to do so and proposes a novel event data-friendly method that achieve simultaneous feature detection and tracking, called event Clustering-based Detection and Tracking (eCDT). Our method employs a novel clustering method, named as k-NN Classifier-based Spatial Clustering and Applications with Noise (KCSCAN), to cluster adjacent polarity events to retrieve event trajectories.With the aid of a Head and Tail Descriptor Matching process, event clusters that reappear in a different polarity are continually tracked, elongating the feature tracks. Thanks to our clustering approach in spatio-temporal space, our method automatically solves feature detection and feature tracking simultaneously. Also, eCDT can extract feature tracks at any frequency with an adjustable time window, which does not corrupt the high temporal resolution of the original event data. Our method achieves 30% better feature tracking ages compared with the state-of-the-art approach while also having a low error approximately equal to it.
SMATE: Semi-Supervised Spatio-Temporal Representation Learning on Multivariate Time Series
Oct 01, 2021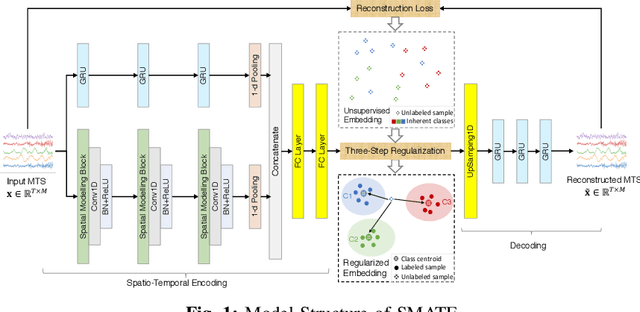
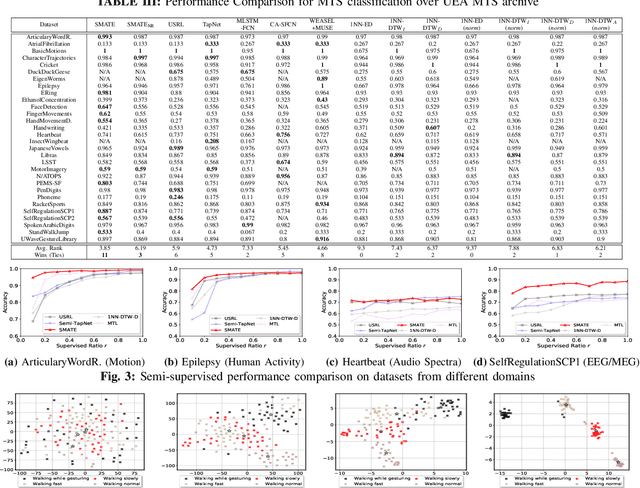
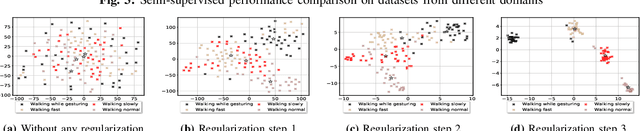
Learning from Multivariate Time Series (MTS) has attracted widespread attention in recent years. In particular, label shortage is a real challenge for the classification task on MTS, considering its complex dimensional and sequential data structure. Unlike self-training and positive unlabeled learning that rely on distance-based classifiers, in this paper, we propose SMATE, a novel semi-supervised model for learning the interpretable Spatio-Temporal representation from weakly labeled MTS. We validate empirically the learned representation on 22 public datasets from the UEA MTS archive. We compare it with 13 state-of-the-art baseline methods for fully supervised tasks and four baselines for semi-supervised tasks. The results show the reliability and efficiency of our proposed method.
Explainable Human-in-the-loop Dynamic Data-Driven Digital Twins
Jul 19, 2022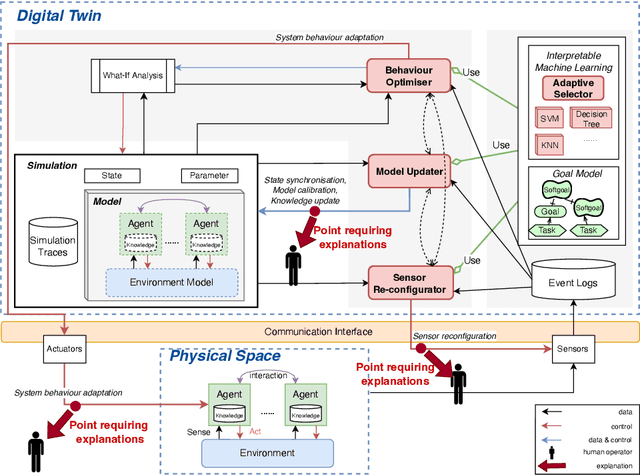
Digital Twins (DT) are essentially Dynamic Data-driven models that serve as real-time symbiotic "virtual replicas" of real-world systems. DT can leverage fundamentals of Dynamic Data-Driven Applications Systems (DDDAS) bidirectional symbiotic sensing feedback loops for its continuous updates. Sensing loops can consequently steer measurement, analysis and reconfiguration aimed at more accurate modelling and analysis in DT. The reconfiguration decisions can be autonomous or interactive, keeping human-in-the-loop. The trustworthiness of these decisions can be hindered by inadequate explainability of the rationale, and utility gained in implementing the decision for the given situation among alternatives. Additionally, different decision-making algorithms and models have varying complexity, quality and can result in different utility gained for the model. The inadequacy of explainability can limit the extent to which humans can evaluate the decisions, often leading to updates which are unfit for the given situation, erroneous, compromising the overall accuracy of the model. The novel contribution of this paper is an approach to harnessing explainability in human-in-the-loop DDDAS and DT systems, leveraging bidirectional symbiotic sensing feedback. The approach utilises interpretable machine learning and goal modelling to explainability, and considers trade-off analysis of utility gained. We use examples from smart warehousing to demonstrate the approach.
Instant Graph Neural Networks for Dynamic Graphs
Jun 03, 2022
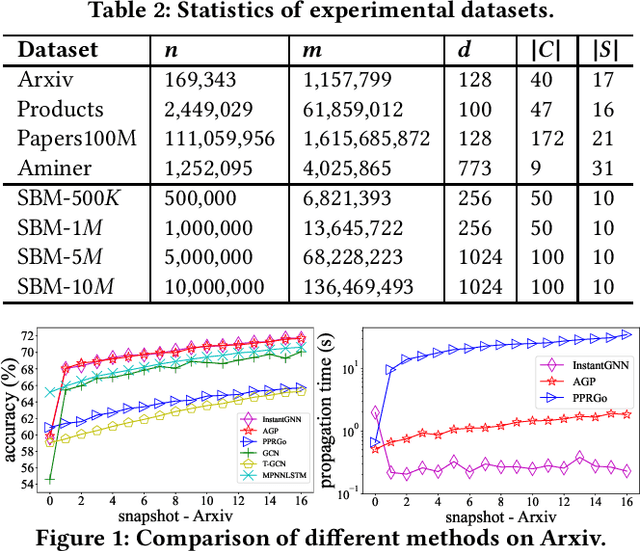
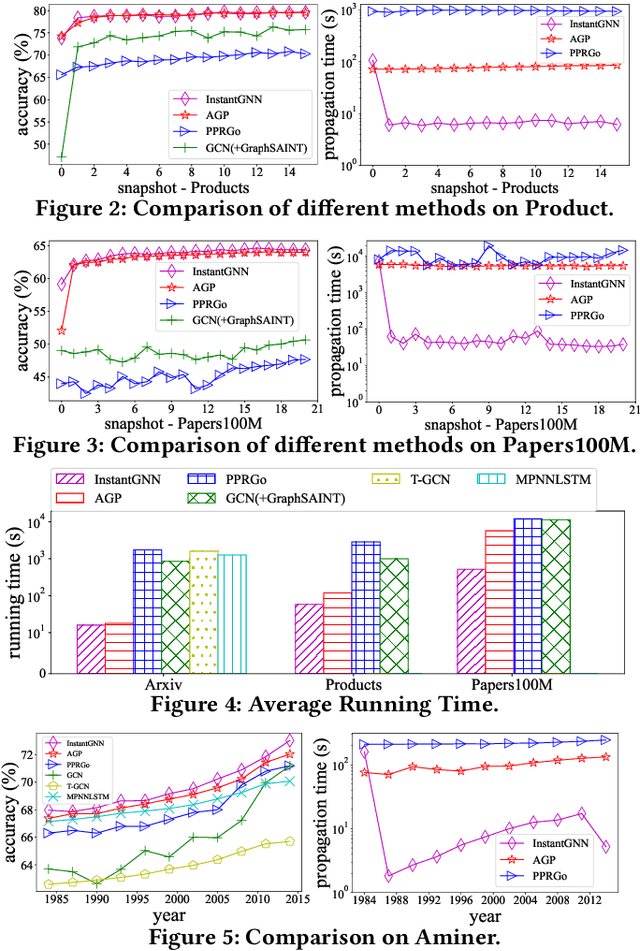
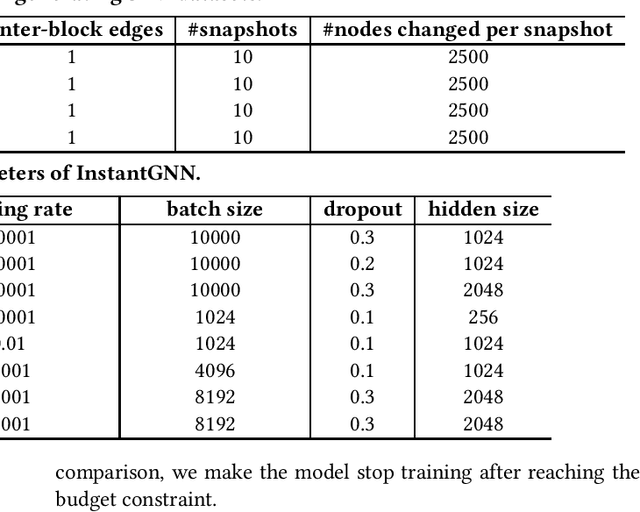
Graph Neural Networks (GNNs) have been widely used for modeling graph-structured data. With the development of numerous GNN variants, recent years have witnessed groundbreaking results in improving the scalability of GNNs to work on static graphs with millions of nodes. However, how to instantly represent continuous changes of large-scale dynamic graphs with GNNs is still an open problem. Existing dynamic GNNs focus on modeling the periodic evolution of graphs, often on a snapshot basis. Such methods suffer from two drawbacks: first, there is a substantial delay for the changes in the graph to be reflected in the graph representations, resulting in losses on the model's accuracy; second, repeatedly calculating the representation matrix on the entire graph in each snapshot is predominantly time-consuming and severely limits the scalability. In this paper, we propose Instant Graph Neural Network (InstantGNN), an incremental computation approach for the graph representation matrix of dynamic graphs. Set to work with dynamic graphs with the edge-arrival model, our method avoids time-consuming, repetitive computations and allows instant updates on the representation and instant predictions. Graphs with dynamic structures and dynamic attributes are both supported. The upper bounds of time complexity of those updates are also provided. Furthermore, our method provides an adaptive training strategy, which guides the model to retrain at moments when it can make the greatest performance gains. We conduct extensive experiments on several real-world and synthetic datasets. Empirical results demonstrate that our model achieves state-of-the-art accuracy while having orders-of-magnitude higher efficiency than existing methods.
Learning to Estimate External Forces of Human Motion in Video
Jul 12, 2022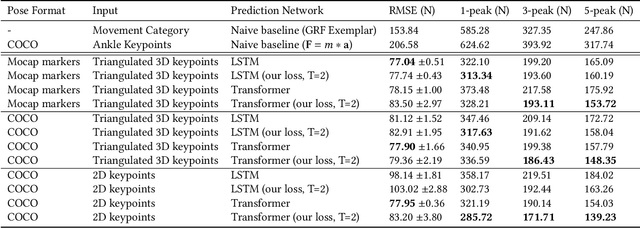


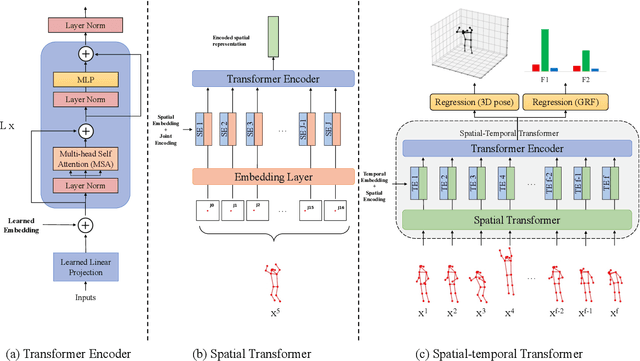
Analyzing sports performance or preventing injuries requires capturing ground reaction forces (GRFs) exerted by the human body during certain movements. Standard practice uses physical markers paired with force plates in a controlled environment, but this is marred by high costs, lengthy implementation time, and variance in repeat experiments; hence, we propose GRF inference from video. While recent work has used LSTMs to estimate GRFs from 2D viewpoints, these can be limited in their modeling and representation capacity. First, we propose using a transformer architecture to tackle the GRF from video task, being the first to do so. Then we introduce a new loss to minimize high impact peaks in regressed curves. We also show that pre-training and multi-task learning on 2D-to-3D human pose estimation improves generalization to unseen motions. And pre-training on this different task provides good initial weights when finetuning on smaller (rarer) GRF datasets. We evaluate on LAAS Parkour and a newly collected ForcePose dataset; we show up to 19% decrease in error compared to prior approaches.
Characterizing Coherent Integrated Photonic Neural Networks under Imperfections
Jul 22, 2022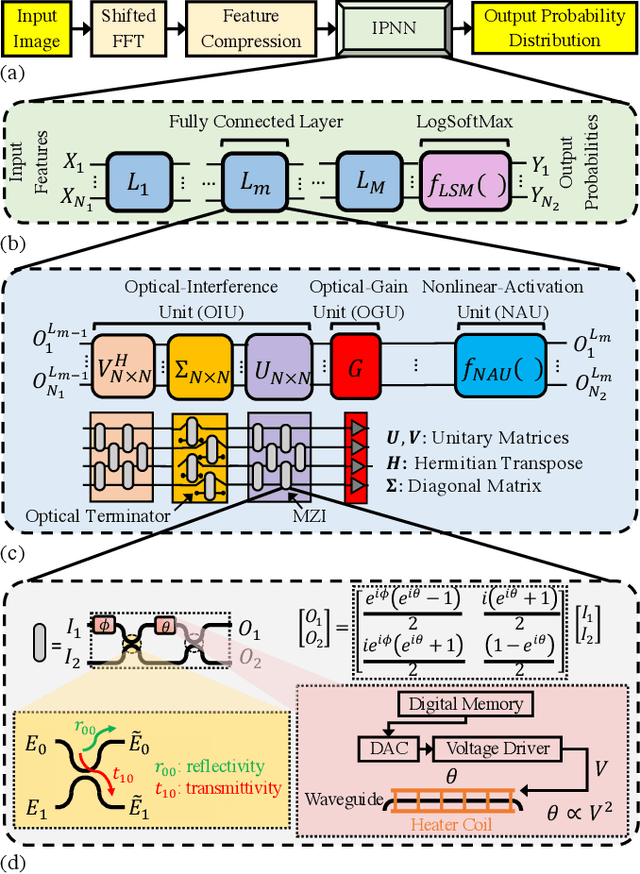
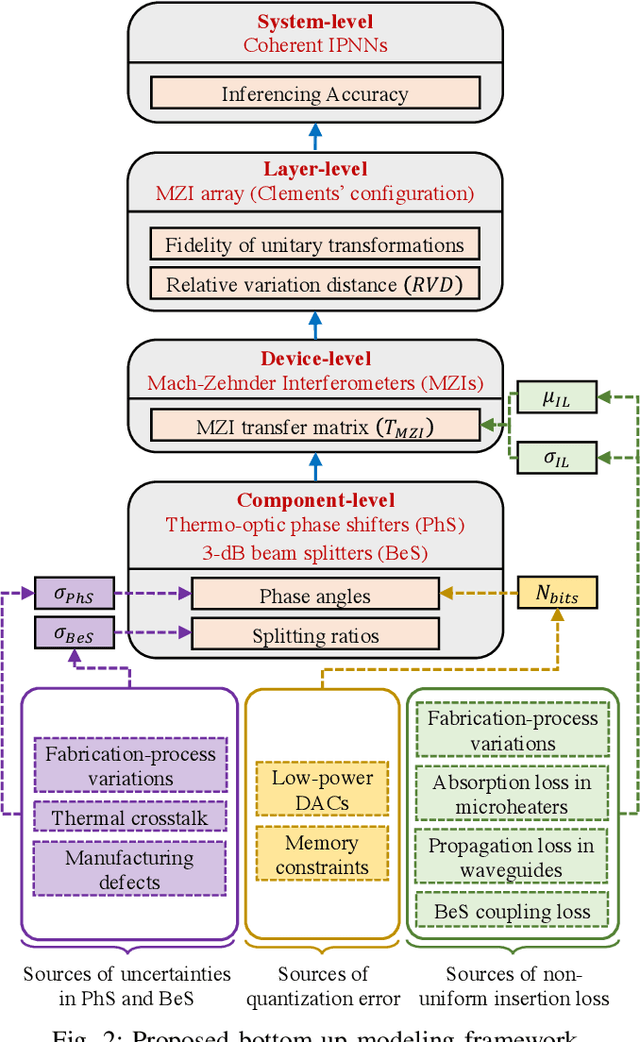
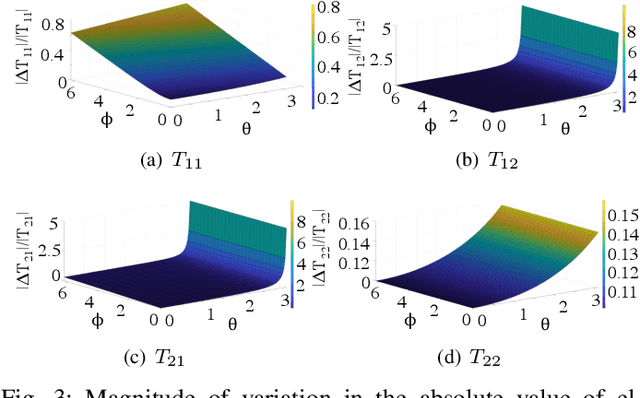
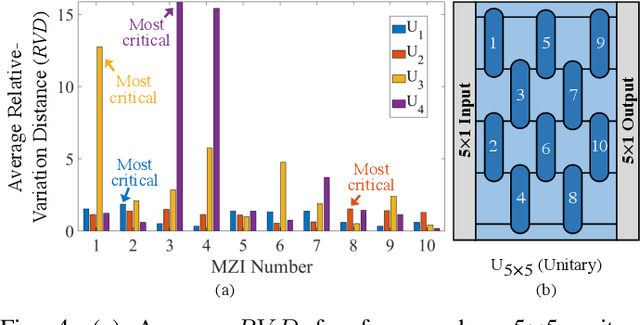
Integrated photonic neural networks (IPNNs) are emerging as promising successors to conventional electronic AI accelerators as they offer substantial improvements in computing speed and energy efficiency. In particular, coherent IPNNs use arrays of Mach-Zehnder interferometers (MZIs) for unitary transformations to perform energy-efficient matrix-vector multiplication. However, the underlying MZI devices in IPNNs are susceptible to uncertainties stemming from optical lithographic variations and thermal crosstalk and can experience imprecisions due to non-uniform MZI insertion loss and quantization errors due to low-precision encoding in the tuned phase angles. In this paper, we, for the first time, systematically characterize the impact of such uncertainties and imprecisions (together referred to as imperfections) in IPNNs using a bottom-up approach. We show that their impact on IPNN accuracy can vary widely based on the tuned parameters (e.g., phase angles) of the affected components, their physical location, and the nature and distribution of the imperfections. To improve reliability measures, we identify critical IPNN building blocks that, under imperfections, can lead to catastrophic degradation in the classification accuracy. We show that under multiple simultaneous imperfections, the IPNN inferencing accuracy can degrade by up to 46%, even when the imperfection parameters are restricted within a small range. Our results also indicate that the inferencing accuracy is sensitive to imperfections affecting the MZIs in the linear layers next to the input layer of the IPNN.