 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-time Neural Radiance Caching for Path Tracing
Jun 23, 2021


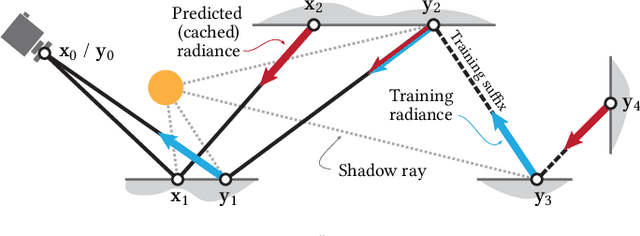
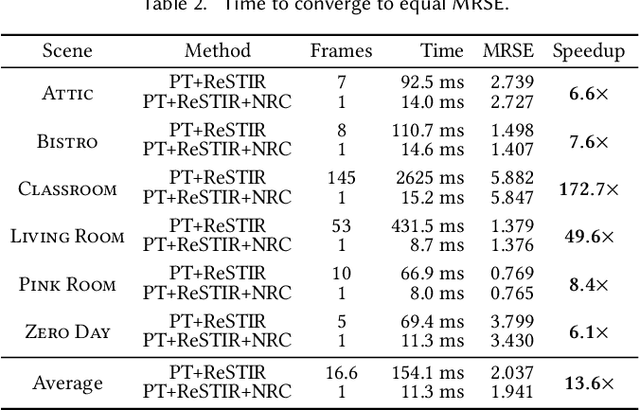
We present a real-time neural radiance caching method for path-traced global illumination. Our system is designed to handle fully dynamic scenes, and makes no assumptions about the lighting, geometry, and materials. The data-driven nature of our approach sidesteps many difficulties of caching algorithms, such as locating, interpolating, and updating cache points. Since pretraining neural networks to handle novel, dynamic scenes is a formidable generalization challenge, we do away with pretraining and instead achieve generalization via adaptation, i.e. we opt for training the radiance cache while rendering. We employ self-training to provide low-noise training targets and simulate infinite-bounce transport by merely iterating few-bounce training updates. The updates and cache queries incur a mild overhead -- about 2.6ms on full HD resolution -- thanks to a streaming implementation of the neural network that fully exploits modern hardware. We demonstrate significant noise reduction at the cost of little induced bias, and report state-of-the-art, real-time performance on a number of challenging scenarios.
Learning reversible symplectic dynamics
Apr 26, 2022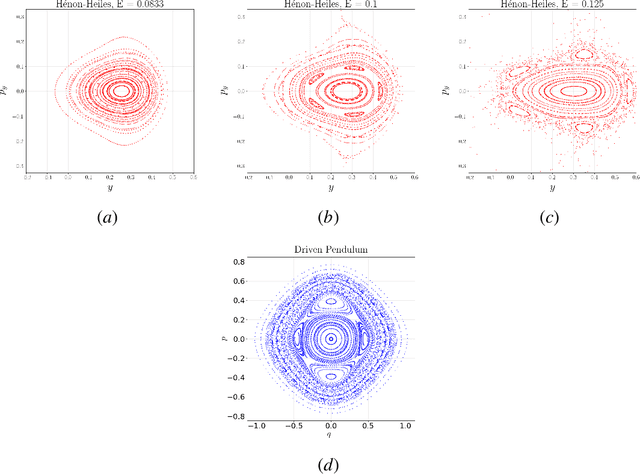
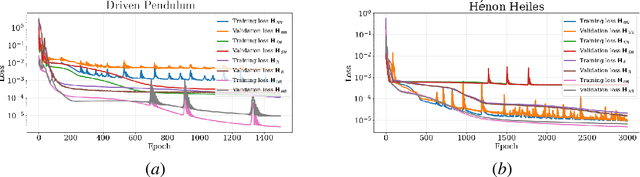
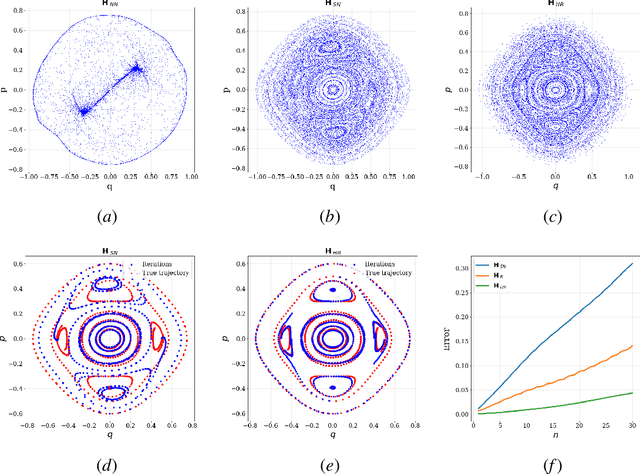
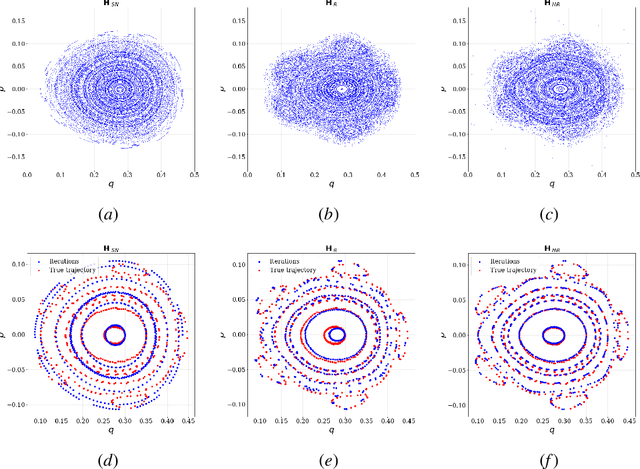
Time-reversal symmetry arises naturally as a structural property in many dynamical systems of interest. While the importance of hard-wiring symmetry is increasingly recognized in machine learning, to date this has eluded time-reversibility. In this paper we propose a new neural network architecture for learning time-reversible dynamical systems from data. We focus in particular on an adaptation to symplectic systems, because of their importance in physics-informed learning.
On the Versatile Uses of Partial Distance Correlation in Deep Learning
Jul 20, 2022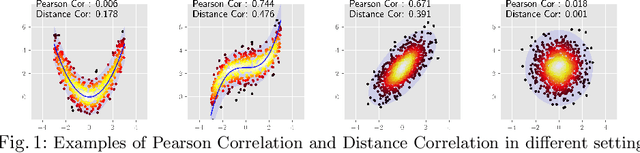
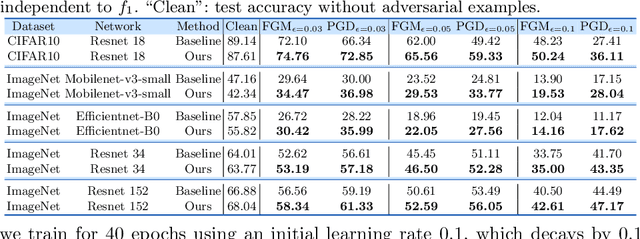
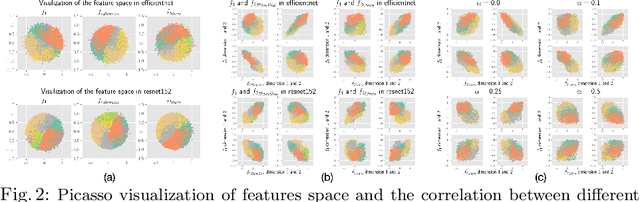
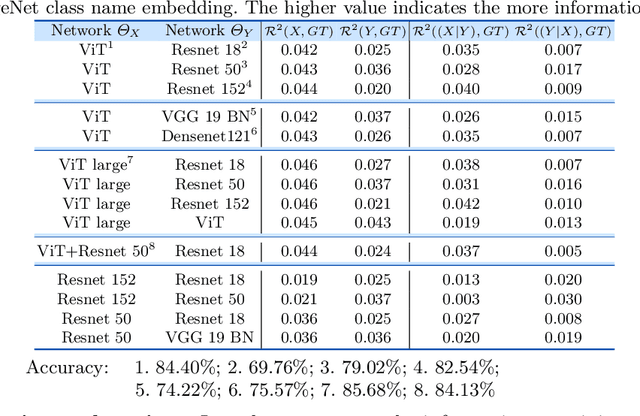
Comparing the functional behavior of neural network models, whether it is a single network over time or two (or more networks) during or post-training, is an essential step in understanding what they are learning (and what they are not), and for identifying strategies for regularization or efficiency improvements. Despite recent progress, e.g., comparing vision transformers to CNNs, systematic comparison of function, especially across different networks, remains difficult and is often carried out layer by layer. Approaches such as canonical correlation analysis (CCA) are applicable in principle, but have been sparingly used so far. In this paper, we revisit a (less widely known) from statistics, called distance correlation (and its partial variant), designed to evaluate correlation between feature spaces of different dimensions. We describe the steps necessary to carry out its deployment for large scale models -- this opens the door to a surprising array of applications ranging from conditioning one deep model w.r.t. another, learning disentangled representations as well as optimizing diverse models that would directly be more robust to adversarial attacks. Our experiments suggest a versatile regularizer (or constraint) with many advantages, which avoids some of the common difficulties one faces in such analyses. Code is at https://github.com/zhenxingjian/Partial_Distance_Correlation.
Deep Learning Based OFDM Channel Estimation Using Frequency-Time Division and Attention Mechanism
Jul 30, 2021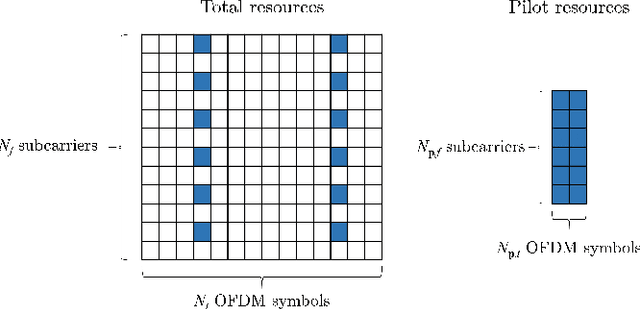
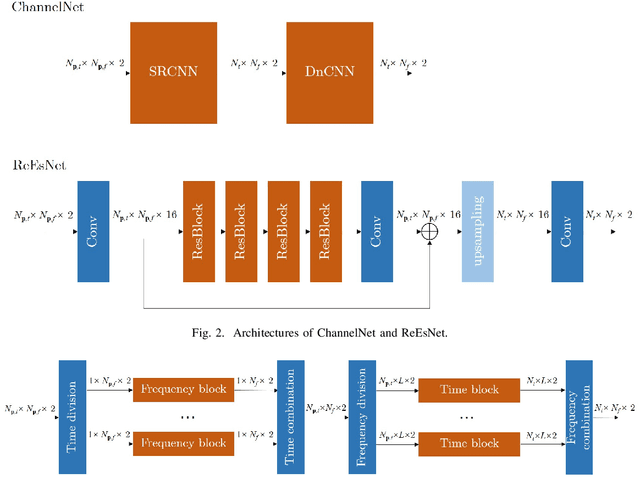
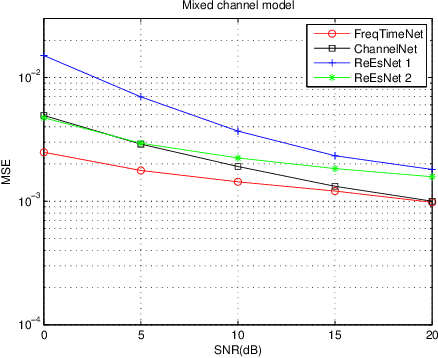
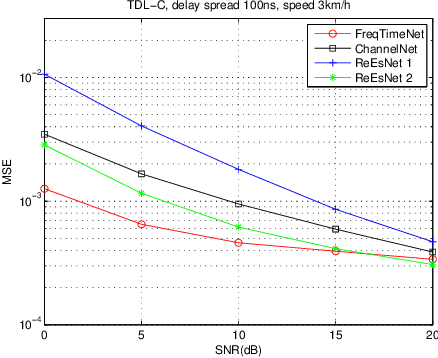
In this paper, we propose a frequency-time division network (FreqTimeNet) to improve the performance of deep learning (DL) based OFDM channel estimation. This FreqTimeNet is designed based on the orthogonality between the frequency domain and the time domain. In FreqTimeNet, the input is processed by parallel frequency blocks and parallel time blocks in sequential. Introducing the attention mechanism to use the SNR information, an attention based FreqTimeNet (AttenFreqTimeNet) is proposed. Using 3rd Generation Partnership Project (3GPP) channel models, the mean square error (MSE) performance of FreqTimeNet and AttenFreqTimeNet under different scenarios is evaluated. A method for constructing mixed training data is proposed, which could address the generalization problem in DL. It is observed that AttenFreqTimeNet outperforms FreqTimeNet, and FreqTimeNet outperforms other DL networks, with acceptable complexity.
Motion-aware Memory Network for Fast Video Salient Object Detection
Aug 01, 2022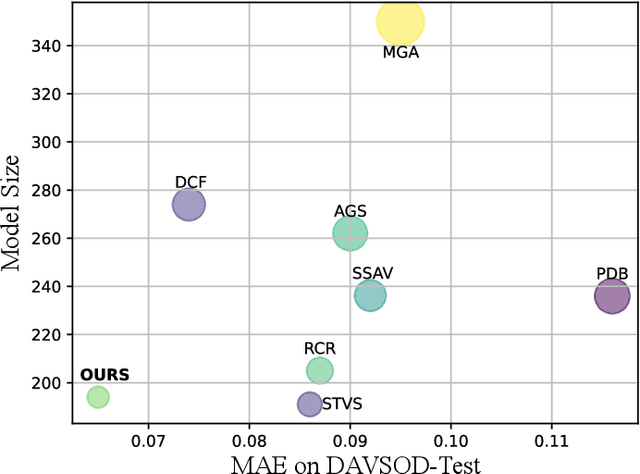

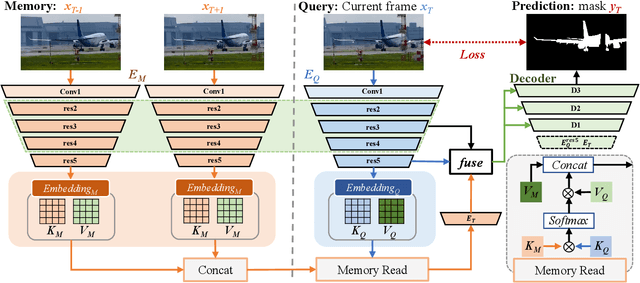
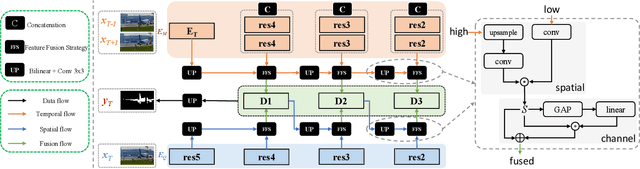
Previous methods based on 3DCNN, convLSTM, or optical flow have achieved great success in video salient object detection (VSOD). However, they still suffer from high computational costs or poor quality of the generated saliency maps. To solve these problems, we design a space-time memory (STM)-based network, which extracts useful temporal information of the current frame from adjacent frames as the temporal branch of VSOD. Furthermore, previous methods only considered single-frame prediction without temporal association. As a result, the model may not focus on the temporal information sufficiently. Thus, we initially introduce object motion prediction between inter-frame into VSOD. Our model follows standard encoder--decoder architecture. In the encoding stage, we generate high-level temporal features by using high-level features from the current and its adjacent frames. This approach is more efficient than the optical flow-based methods. In the decoding stage, we propose an effective fusion strategy for spatial and temporal branches. The semantic information of the high-level features is used to fuse the object details in the low-level features, and then the spatiotemporal features are obtained step by step to reconstruct the saliency maps. Moreover, inspired by the boundary supervision commonly used in image salient object detection (ISOD), we design a motion-aware loss for predicting object boundary motion and simultaneously perform multitask learning for VSOD and object motion prediction, which can further facilitate the model to extract spatiotemporal features accurately and maintain the object integrity. Extensive experiments on several datasets demonstrated the effectiveness of our method and can achieve state-of-the-art metrics on some datasets. The proposed model does not require optical flow or other preprocessing, and can reach a speed of nearly 100 FPS during inference.
ExoSGAN and ExoACGAN: Exoplanet Detection using Adversarial Training Algorithms
Jul 20, 2022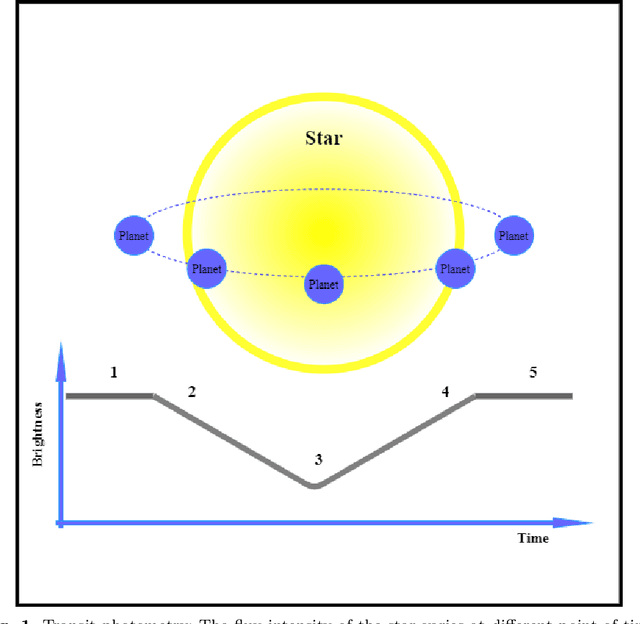
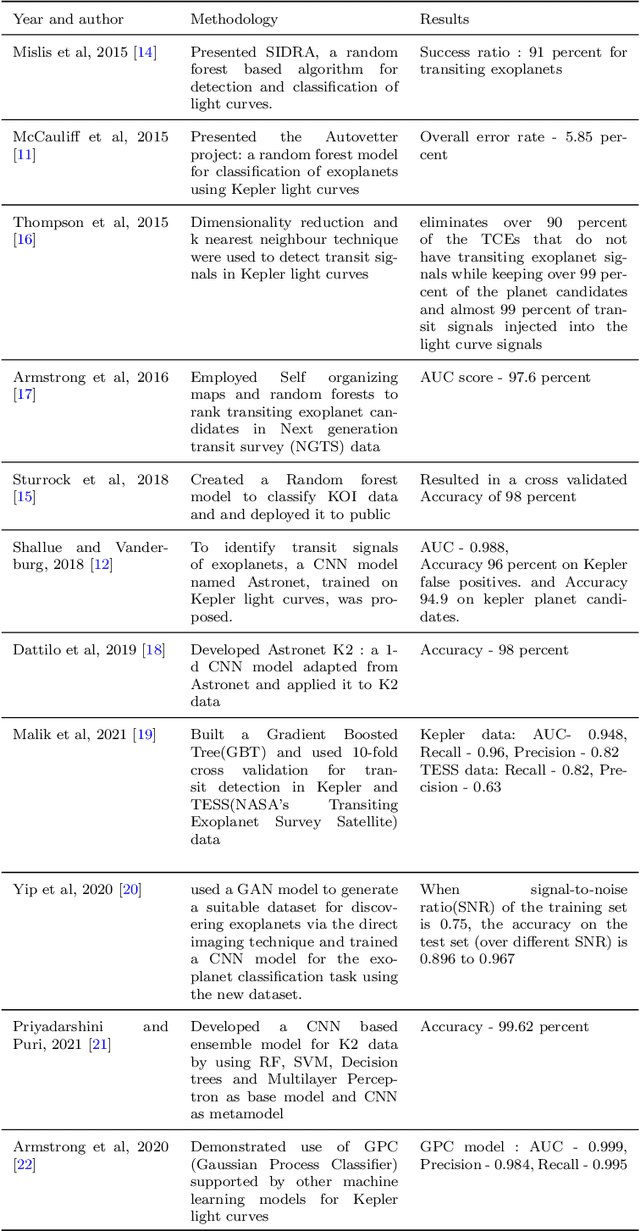
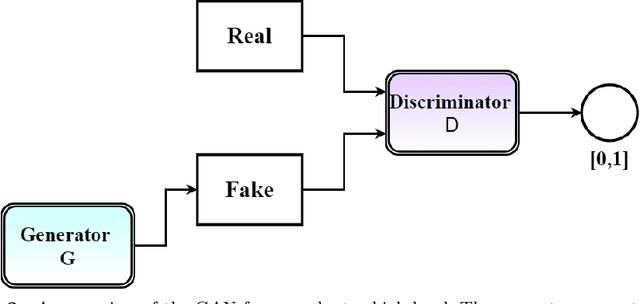
Exoplanet detection opens the door to the discovery of new habitable worlds and helps us understand how planets were formed. With the objective of finding earth-like habitable planets, NASA launched Kepler space telescope and its follow up mission K2. The advancement of observation capabilities has increased the range of fresh data available for research, and manually handling them is both time-consuming and difficult. Machine learning and deep learning techniques can greatly assist in lowering human efforts to process the vast array of data produced by the modern instruments of these exoplanet programs in an economical and unbiased manner. However, care should be taken to detect all the exoplanets precisely while simultaneously minimizing the misclassification of non-exoplanet stars. In this paper, we utilize two variations of generative adversarial networks, namely semi-supervised generative adversarial networks and auxiliary classifier generative adversarial networks, to detect transiting exoplanets in K2 data. We find that the usage of these models can be helpful for the classification of stars with exoplanets. Both of our techniques are able to categorize the light curves with a recall and precision of 1.00 on the test data. Our semi-supervised technique is beneficial to solve the cumbersome task of creating a labeled dataset.
Pseudo-label Guided Cross-video Pixel Contrast for Robotic Surgical Scene Segmentation with Limited Annotations
Jul 20, 2022



Surgical scene segmentation is fundamentally crucial for prompting cognitive assistance in robotic surgery. However, pixel-wise annotating surgical video in a frame-by-frame manner is expensive and time consuming. To greatly reduce the labeling burden, in this work, we study semi-supervised scene segmentation from robotic surgical video, which is practically essential yet rarely explored before. We consider a clinically suitable annotation situation under the equidistant sampling. We then propose PGV-CL, a novel pseudo-label guided cross-video contrast learning method to boost scene segmentation. It effectively leverages unlabeled data for a trusty and global model regularization that produces more discriminative feature representation. Concretely, for trusty representation learning, we propose to incorporate pseudo labels to instruct the pair selection, obtaining more reliable representation pairs for pixel contrast. Moreover, we expand the representation learning space from previous image-level to cross-video, which can capture the global semantics to benefit the learning process. We extensively evaluate our method on a public robotic surgery dataset EndoVis18 and a public cataract dataset CaDIS. Experimental results demonstrate the effectiveness of our method, consistently outperforming the state-of-the-art semi-supervised methods under different labeling ratios, and even surpassing fully supervised training on EndoVis18 with 10.1% labeling.
eCDT: Event Clustering for Simultaneous Feature Detection and Tracking-
Jul 20, 2022

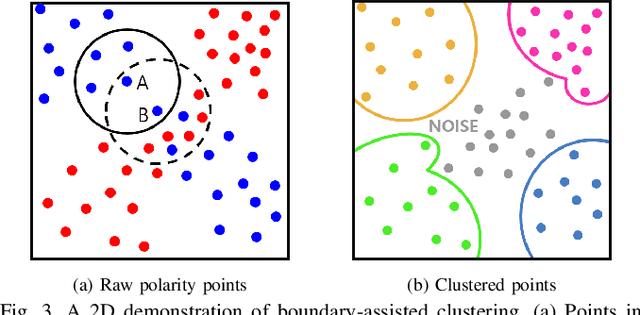

Contrary to other standard cameras, event cameras interpret the world in an entirely different manner; as a collection of asynchronous events. Despite event camera's unique data output, many event feature detection and tracking algorithms have shown significant progress by making detours to frame-based data representations. This paper questions the need to do so and proposes a novel event data-friendly method that achieve simultaneous feature detection and tracking, called event Clustering-based Detection and Tracking (eCDT). Our method employs a novel clustering method, named as k-NN Classifier-based Spatial Clustering and Applications with Noise (KCSCAN), to cluster adjacent polarity events to retrieve event trajectories.With the aid of a Head and Tail Descriptor Matching process, event clusters that reappear in a different polarity are continually tracked, elongating the feature tracks. Thanks to our clustering approach in spatio-temporal space, our method automatically solves feature detection and feature tracking simultaneously. Also, eCDT can extract feature tracks at any frequency with an adjustable time window, which does not corrupt the high temporal resolution of the original event data. Our method achieves 30% better feature tracking ages compared with the state-of-the-art approach while also having a low error approximately equal to it.
Deep Probabilistic Koopman: Long-term time-series forecasting under periodic uncertainties
Jun 10, 2021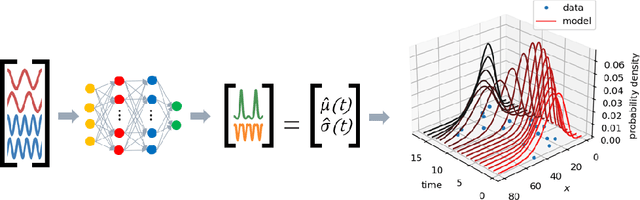
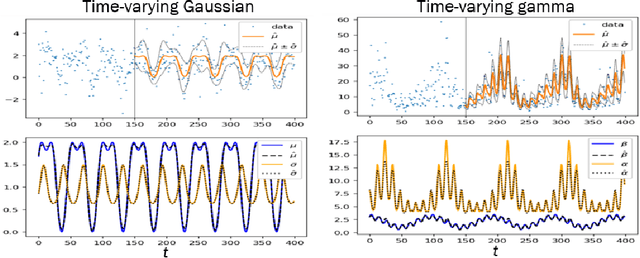
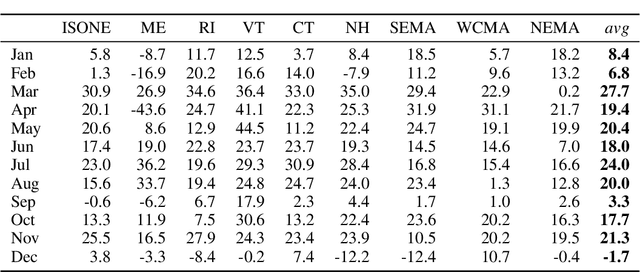
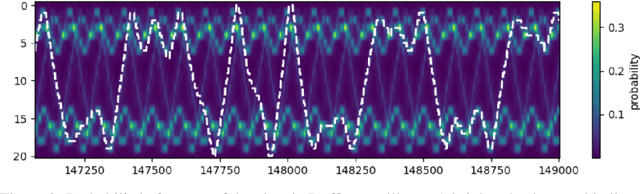
Probabilistic forecasting of complex phenomena is paramount to various scientific disciplines and applications. Despite the generality and importance of the problem, general mathematical techniques that allow for stable long-term forecasts with calibrated uncertainty measures are lacking. For most time series models, the difficulty of obtaining accurate probabilistic future time step predictions increases with the prediction horizon. In this paper, we introduce a surprisingly simple approach that characterizes time-varying distributions and enables reasonably accurate predictions thousands of timesteps into the future. This technique, which we call Deep Probabilistic Koopman (DPK), is based on recent advances in linear Koopman operator theory, and does not require time stepping for future time predictions. Koopman models also tend to have a small parameter footprint (often less than 10,000 parameters). We demonstrate the long-term forecasting performance of these models on a diversity of domains, including electricity demand forecasting, atmospheric chemistry, and neuroscience. For electricity demand modeling, our domain-agnostic technique outperforms all of 177 domain-specific competitors in the most recent Global Energy Forecasting Competition.
Super Vision Transformer
May 26, 2022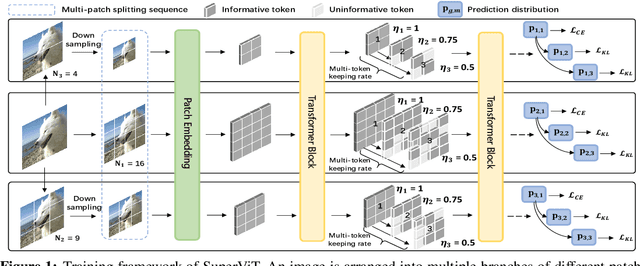
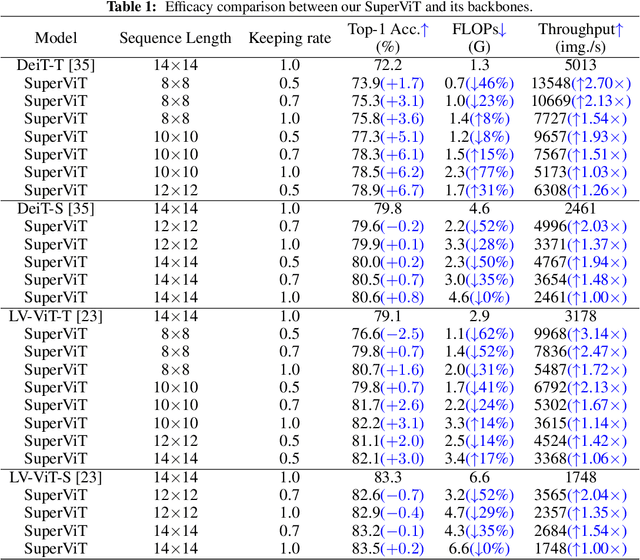
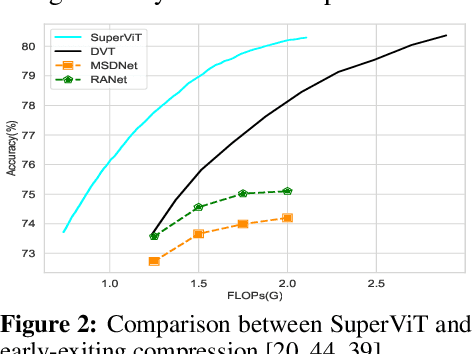
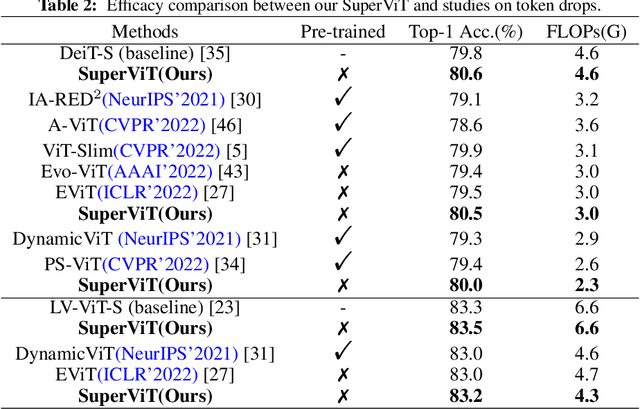
We attempt to reduce the computational costs in vision transformers (ViTs), which increase quadratically in the token number. We present a novel training paradigm that trains only one ViT model at a time, but is capable of providing improved image recognition performance with various computational costs. Here, the trained ViT model, termed super vision transformer (SuperViT), is empowered with the versatile ability to solve incoming patches of multiple sizes as well as preserve informative tokens with multiple keeping rates (the ratio of keeping tokens) to achieve good hardware efficiency for inference, given that the available hardware resources often change from time to time. Experimental results on ImageNet demonstrate that our SuperViT can considerably reduce the computational costs of ViT models with even performance increase. For example, we reduce 2x FLOPs of DeiT-S while increasing the Top-1 accuracy by 0.2% and 0.7% for 1.5x reduction. Also, our SuperViT significantly outperforms existing studies on efficient vision transformers. For example, when consuming the same amount of FLOPs, our SuperViT surpasses the recent state-of-the-art (SoTA) EViT by 1.1% when using DeiT-S as their backbones. The project of this work is made publicly available at https://github.com/lmbxmu/SuperViT.