 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Texture Generation Using Graph Generative Adversarial Network And Differentiable Rendering
Jun 17, 2022
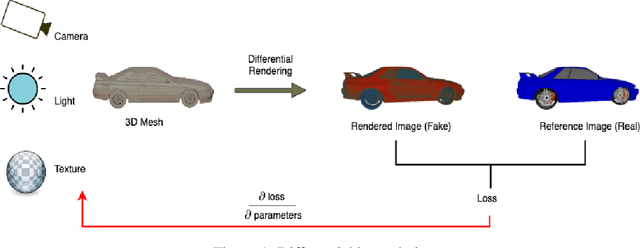
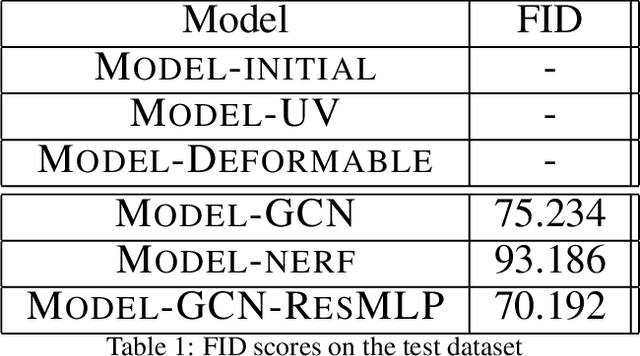
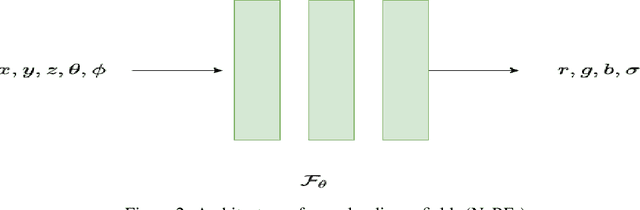
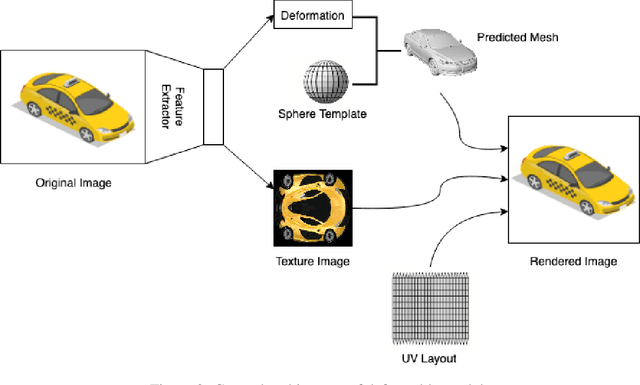
Novel texture synthesis for existing 3D mesh models is an important step towards photo realistic asset generation for existing simulators. But existing methods inherently work in the 2D image space which is the projection of the 3D space from a given camera perspective. These methods take camera angle, 3D model information, lighting information and generate photorealistic 2D image. To generate a photorealistic image from another perspective or lighting, we need to make a computationally expensive forward pass each time we change the parameters. Also, it is hard to generate such images for a simulator that can satisfy the temporal constraints the sequences of images should be similar but only need to change the viewpoint of lighting as desired. The solution can not be directly integrated with existing tools like Blender and Unreal Engine. Manual solution is expensive and time consuming. We thus present a new system called a graph generative adversarial network (GGAN) that can generate textures which can be directly integrated into a given 3D mesh models with tools like Blender and Unreal Engine and can be simulated from any perspective and lighting condition easily.
Bio-inspired Intelligence with Applications to Robotics: A Survey
Jun 17, 2022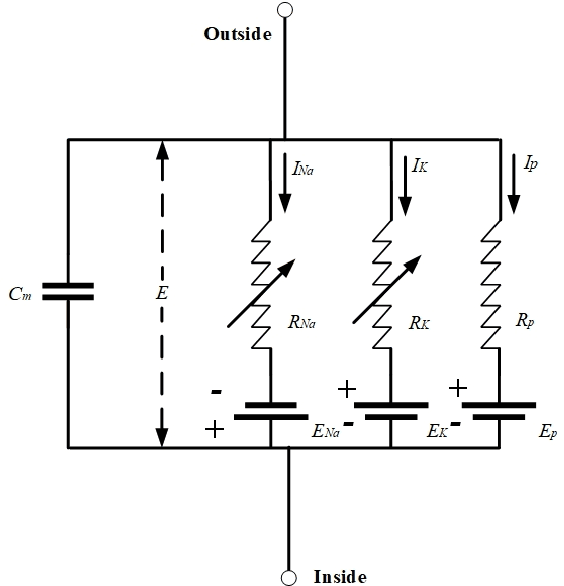
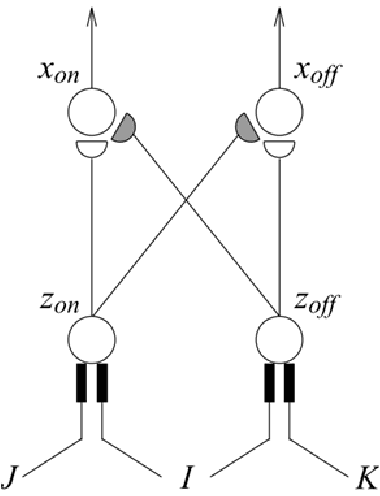
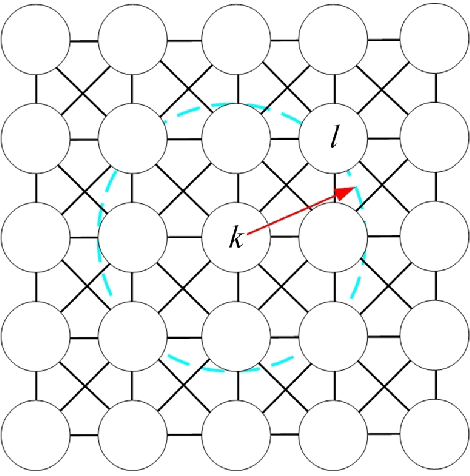
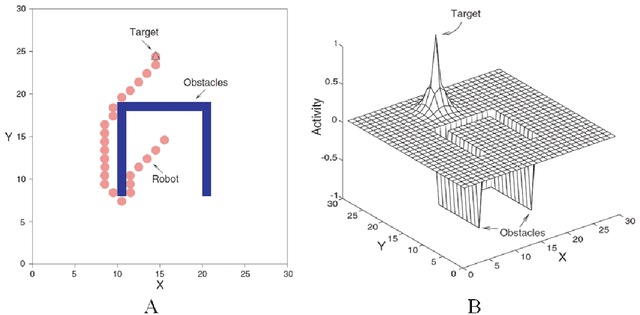
In the past decades, considerable attention has been paid to bio-inspired intelligence and its applications to robotics. This paper provides a comprehensive survey of bio-inspired intelligence, with a focus on neurodynamics approaches, to various robotic applications, particularly to path planning and control of autonomous robotic systems. Firstly, the bio-inspired shunting model and its variants (additive model and gated dipole model) are introduced, and their main characteristics are given in detail. Then, two main neurodynamics applications to real-time path planning and control of various robotic systems are reviewed. A bio-inspired neural network framework, in which neurons are characterized by the neurodynamics models, is discussed for mobile robots, cleaning robots, and underwater robots. The bio-inspired neural network has been widely used in real-time collision-free navigation and cooperation without any learning procedures, global cost functions, and prior knowledge of the dynamic environment. In addition, bio-inspired backstepping controllers for various robotic systems, which are able to eliminate the speed jump when a large initial tracking error occurs, are further discussed. Finally, the current challenges and future research directions are discussed in this paper.
A Novel Multi-Agent Scheduling Mechanism for Adaptation of Production Plans in Case of Supply Chain Disruptions
Jun 23, 2022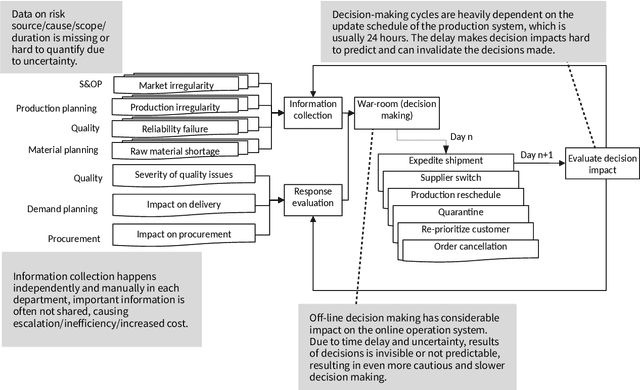
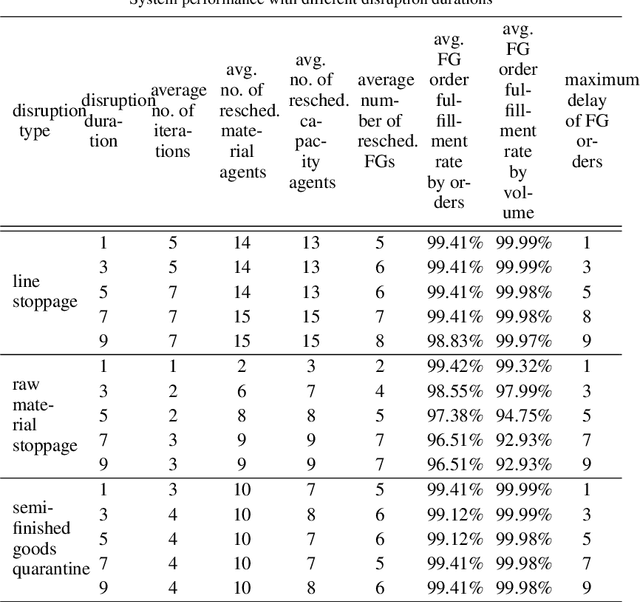
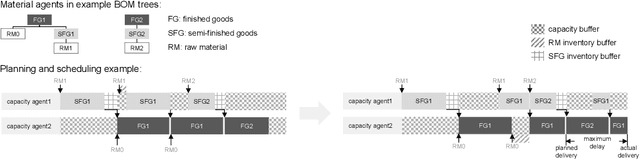
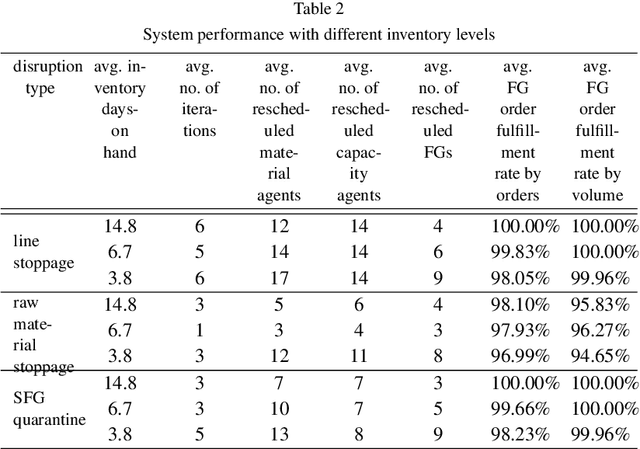
Manufacturing companies typically use sophisticated production planning systems optimizing production steps, often delivering near-optimal solutions. As a downside for delivering a near-optimal schedule, planning systems have high computational demands resulting in hours of computation. Under normal circumstances this is not issue if there is enough buffer time before implementation of the schedule (e.g. at night for the next day). However, in case of unexpected disruptions such as delayed part deliveries or defectively manufactured goods, the planned schedule may become invalid and swift replanning becomes necessary. Such immediate replanning is unsuited for existing optimal planners due to the computational requirements. This paper proposes a novel solution that can effectively and efficiently perform replanning in case of different types of disruptions using an existing plan. The approach is based on the idea to adhere to the existing schedule as much as possible, adapting it based on limited local changes. For that purpose an agent-based scheduling mechanism has been devised, in which agents represent materials and production sites and use local optimization techniques and negotiations to generate an adapted (sufficient, but non-optimal) schedule. The approach has been evaluated using real production data from Huawei, showing that efficient schedules are produced in short time. The system has been implemented as proof of concept and is currently reimplemented and transferred to a production system based on the Jadex agent platform.
Origin of life from a maker's perspective -- focus on protocellular compartments in bottom-up synthetic biology
Jul 14, 2022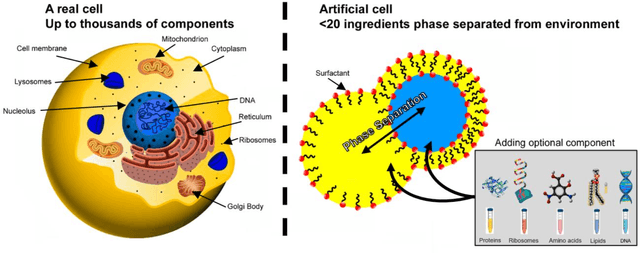

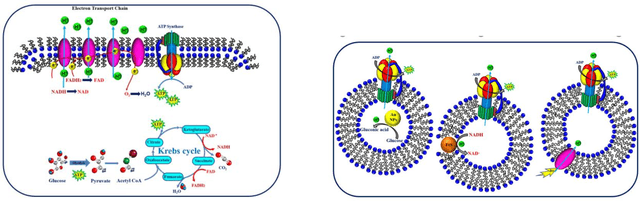
The origin of life is shrouded in mystery, with few surviving clues, obscured by evolutionary competition. Previous reviews have touched on the complementary approaches of top-down and bottom-up synthetic biology to augment our understanding of living systems. Here we point out the synergies between these fields, especially between bottom-up synthetic biology and origin of life research. We explore recent progress made in artificial cell compartmentation in line with the crowded cell, its metabolism, as well as cycles of growth and division, and how those efforts are starting to be combined. Though the complexity of current life is among its most striking characteristics, none of life's essential features require it, and they are unlikely to have emerged thus complex from the beginning. Rather than recovering the one true origin lost in time, current research converges towards reproducing the emergence of minimal life, by teasing out how complexity and evolution may arise from a set of essential components.
Knock Detection in Combustion Engine Time Series Using a Theory-Guided 1D Convolutional Neural Network Approach
Jan 18, 2022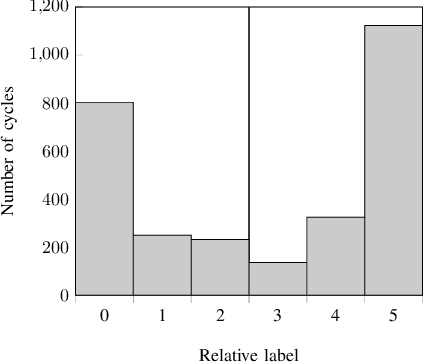
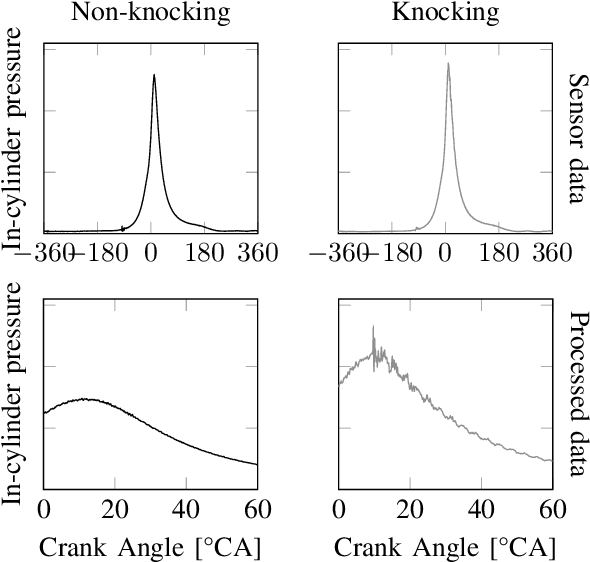

This paper introduces a method for the detection of knock occurrences in an internal combustion engine (ICE) using a 1D convolutional neural network trained on in-cylinder pressure data. The model architecture was based on considerations regarding the expected frequency characteristics of knocking combustion. To aid the feature extraction, all cycles were reduced to 60{\deg} CA long windows, with no further processing applied to the pressure traces. The neural networks were trained exclusively on in-cylinder pressure traces from multiple conditions and labels provided by human experts. The best-performing model architecture achieves an accuracy of above 92% on all test sets in a tenfold cross-validation when distinguishing between knocking and non-knocking cycles. In a multi-class problem where each cycle was labeled by the number of experts who rated it as knocking, 78% of cycles were labeled perfectly, while 90% of cycles were classified at most one class from ground truth. They thus considerably outperform the broadly applied MAPO (Maximum Amplitude of Pressure Oscillation) detection method, as well as other references reconstructed from previous works. Our analysis indicates that the neural network learned physically meaningful features connected to engine-characteristic resonance frequencies, thus verifying the intended theory-guided data science approach. Deeper performance investigation further shows remarkable generalization ability to unseen operating points. In addition, the model proved to classify knocking cycles in unseen engines with increased accuracy of 89% after adapting to their features via training on a small number of exclusively non-knocking cycles. The algorithm takes below 1 ms (on CPU) to classify individual cycles, effectively making it suitable for real-time engine control.
Nature-Inspired Intelligent α-Fair Hybrid Precoding in Multiuser Massive Multiple-Input Multiple-Output Systems
Jul 18, 2022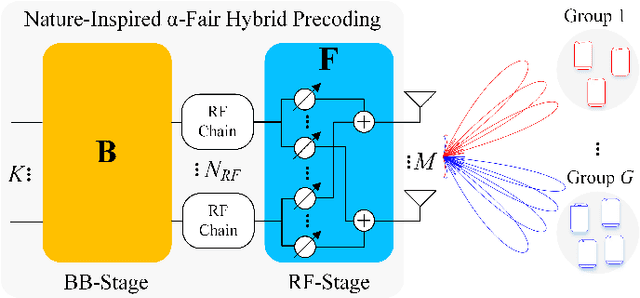
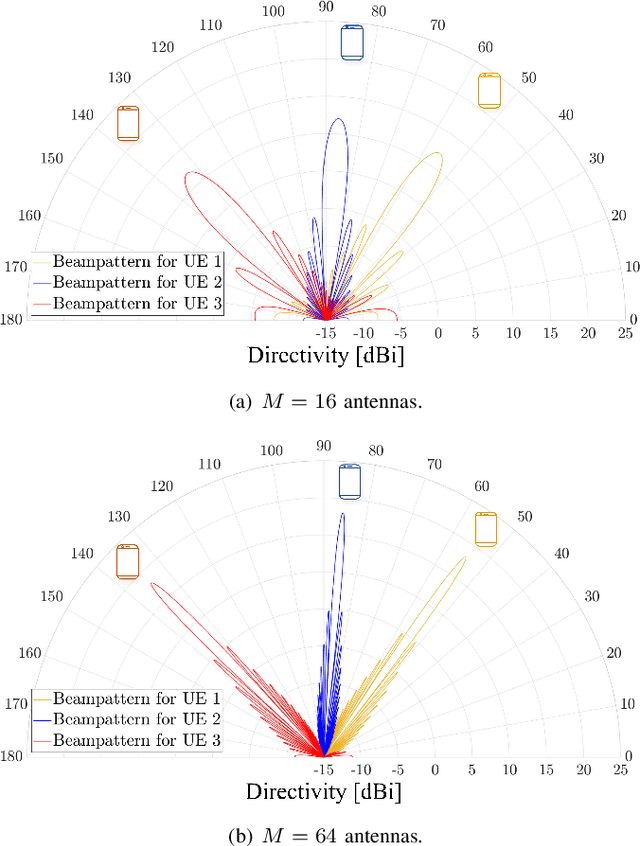
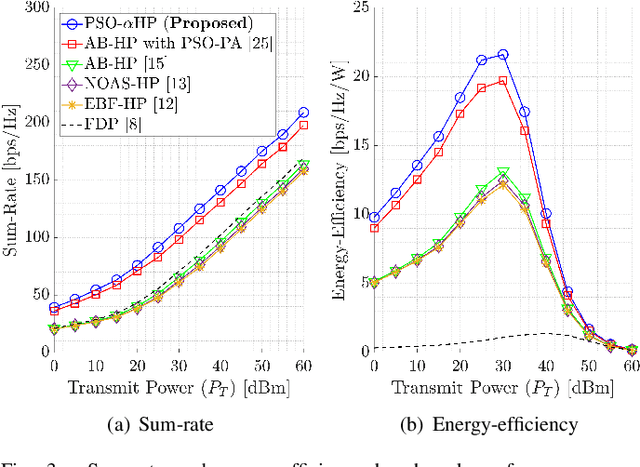
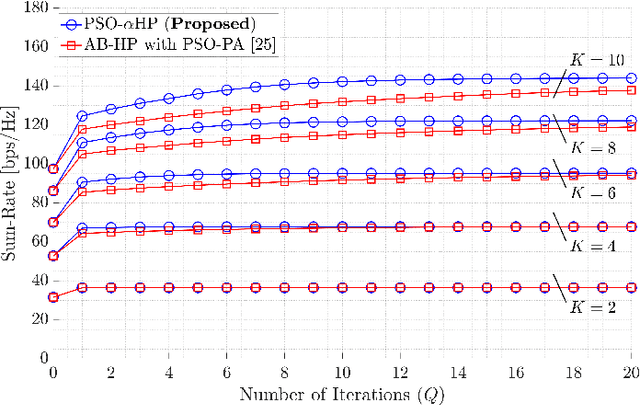
This paper proposes a novel nature-inspired $\alpha$-fair hybrid precoding (NI-$\alpha$HP) technique for millimeter-wave multi-user massive multiple-input multiple-output systems. Unlike the existing HP literature, we propose to apply $\alpha$-fairness for maintaining various fairness expectations (e.g., sum-rate maximization, proportional fairness, max-min fairness, etc.). After developing the analog RF beamformer via slow time-varying angular information, the digital baseband (BB) precoder is designed via the reduced-dimensional effective channel matrix seen from the BB-stage. For the $\alpha$-fairness, we derive the optimal digital BB precoder expression with a set of parameters, where optimizing them is an NP-hard problem. Hence, we efficiently optimize the parameters in the digital BB precoder via five nature-inspired intelligent algorithms. Numerical results present that when the sum-rate maximization is the target, the proposed NI-$\alpha$HP technique greatly improves the sum-rate capacity and energy-efficiency performance compared to other benchmarks. Moreover, NI-$\alpha$HP supports different fairness expectations and reduces the rate gap among UEs by varying the fairness level ($\alpha$).
On the Learnability of Physical Concepts: Can a Neural Network Understand What's Real?
Aug 04, 2022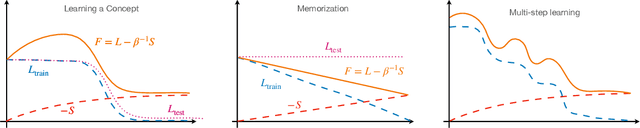
We revisit the classic signal-to-symbol barrier in light of the remarkable ability of deep neural networks to generate realistic synthetic data. DeepFakes and spoofing highlight the feebleness of the link between physical reality and its abstract representation, whether learned by a digital computer or a biological agent. Starting from a widely applicable definition of abstract concept, we show that standard feed-forward architectures cannot capture but trivial concepts, regardless of the number of weights and the amount of training data, despite being extremely effective classifiers. On the other hand, architectures that incorporate recursion can represent a significantly larger class of concepts, but may still be unable to learn them from a finite dataset. We qualitatively describe the class of concepts that can be "understood" by modern architectures trained with variants of stochastic gradient descent, using a (free energy) Lagrangian to measure information complexity. Even if a concept has been understood, however, a network has no means of communicating its understanding to an external agent, except through continuous interaction and validation. We then characterize physical objects as abstract concepts and use the previous analysis to show that physical objects can be encoded by finite architectures. However, to understand physical concepts, sensors must provide persistently exciting observations, for which the ability to control the data acquisition process is essential (active perception). The importance of control depends on the modality, benefiting visual more than acoustic or chemical perception. Finally, we conclude that binding physical entities to digital identities is possible in finite time with finite resources, solving in principle the signal-to-symbol barrier problem, but we highlight the need for continuous validation.
Research Trends and Applications of Data Augmentation Algorithms
Jul 18, 2022

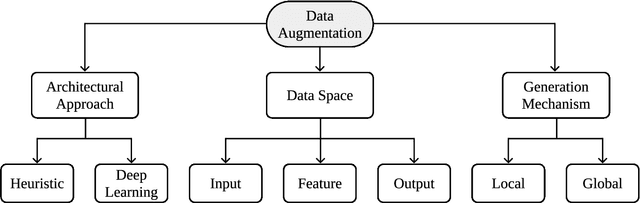
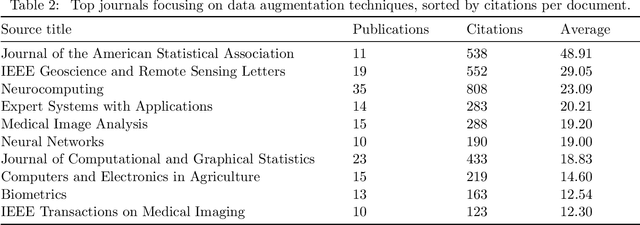
In the Machine Learning research community, there is a consensus regarding the relationship between model complexity and the required amount of data and computation power. In real world applications, these computational requirements are not always available, motivating research on regularization methods. In addition, current and past research have shown that simpler classification algorithms can reach state-of-the-art performance on computer vision tasks given a robust method to artificially augment the training dataset. Because of this, data augmentation techniques became a popular research topic in recent years. However, existing data augmentation methods are generally less transferable than other regularization methods. In this paper we identify the main areas of application of data augmentation algorithms, the types of algorithms used, significant research trends, their progression over time and research gaps in data augmentation literature. To do this, the related literature was collected through the Scopus database. Its analysis was done following network science, text mining and exploratory analysis approaches. We expect readers to understand the potential of data augmentation, as well as identify future research directions and open questions within data augmentation research.
Lightweight and Progressively-Scalable Networks for Semantic Segmentation
Jul 27, 2022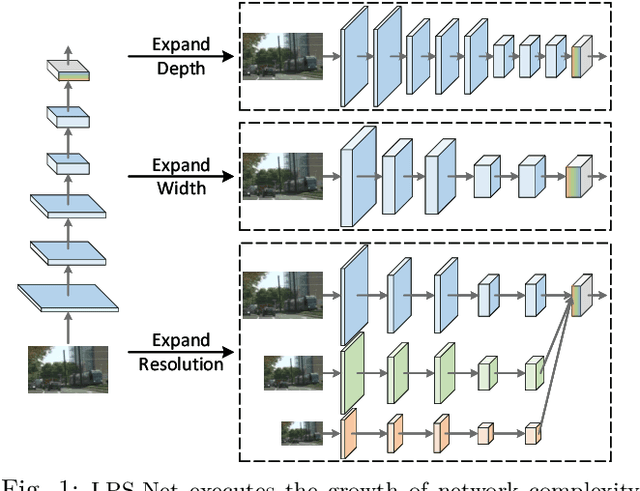

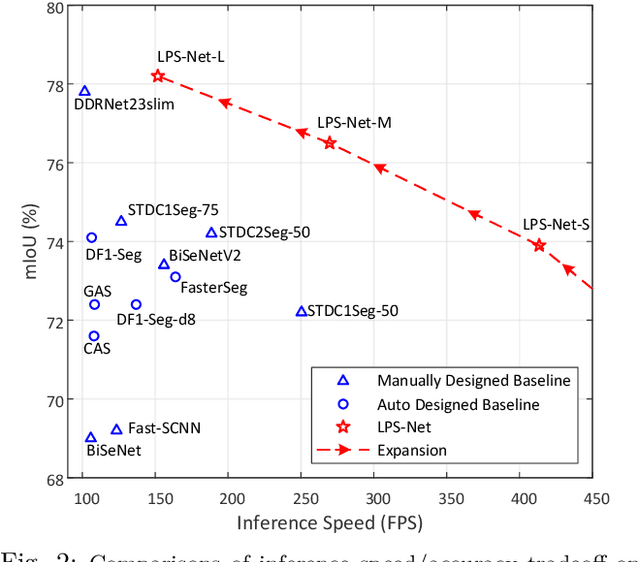
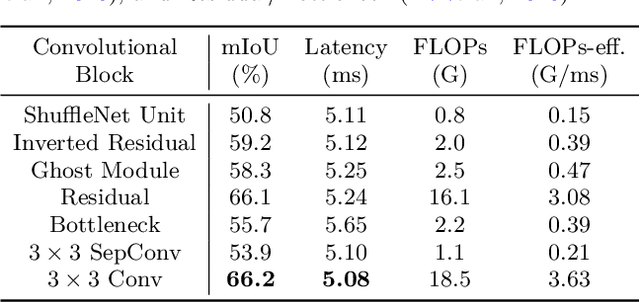
Multi-scale learning frameworks have been regarded as a capable class of models to boost semantic segmentation. The problem nevertheless is not trivial especially for the real-world deployments, which often demand high efficiency in inference latency. In this paper, we thoroughly analyze the design of convolutional blocks (the type of convolutions and the number of channels in convolutions), and the ways of interactions across multiple scales, all from lightweight standpoint for semantic segmentation. With such in-depth comparisons, we conclude three principles, and accordingly devise Lightweight and Progressively-Scalable Networks (LPS-Net) that novelly expands the network complexity in a greedy manner. Technically, LPS-Net first capitalizes on the principles to build a tiny network. Then, LPS-Net progressively scales the tiny network to larger ones by expanding a single dimension (the number of convolutional blocks, the number of channels, or the input resolution) at one time to meet the best speed/accuracy tradeoff. Extensive experiments conducted on three datasets consistently demonstrate the superiority of LPS-Net over several efficient semantic segmentation methods. More remarkably, our LPS-Net achieves 73.4% mIoU on Cityscapes test set, with the speed of 413.5FPS on an NVIDIA GTX 1080Ti, leading to a performance improvement by 1.5% and a 65% speed-up against the state-of-the-art STDC. Code is available at \url{https://github.com/YihengZhang-CV/LPS-Net}.
Neural Pixel Composition: 3D-4D View Synthesis from Multi-Views
Jul 21, 2022
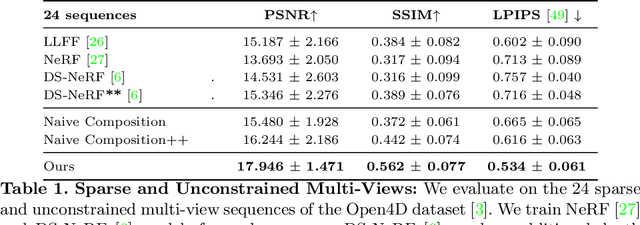
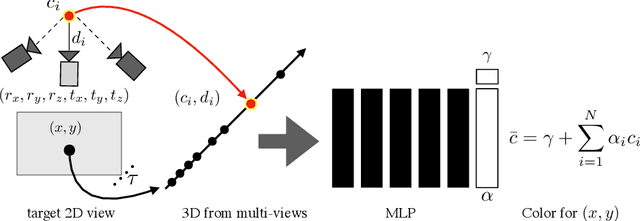
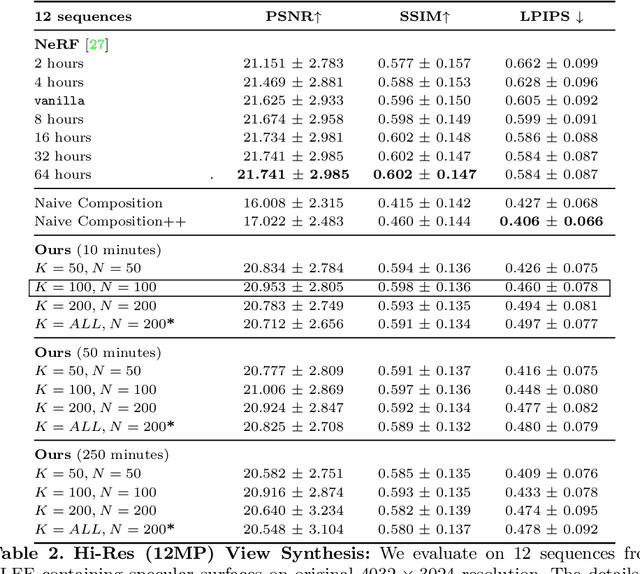
We present Neural Pixel Composition (NPC), a novel approach for continuous 3D-4D view synthesis given only a discrete set of multi-view observations as input. Existing state-of-the-art approaches require dense multi-view supervision and an extensive computational budget. The proposed formulation reliably operates on sparse and wide-baseline multi-view imagery and can be trained efficiently within a few seconds to 10 minutes for hi-res (12MP) content, i.e., 200-400X faster convergence than existing methods. Crucial to our approach are two core novelties: 1) a representation of a pixel that contains color and depth information accumulated from multi-views for a particular location and time along a line of sight, and 2) a multi-layer perceptron (MLP) that enables the composition of this rich information provided for a pixel location to obtain the final color output. We experiment with a large variety of multi-view sequences, compare to existing approaches, and achieve better results in diverse and challenging settings. Finally, our approach enables dense 3D reconstruction from sparse multi-views, where COLMAP, a state-of-the-art 3D reconstruction approach, struggles.