 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
MToFNet: Object Anti-Spoofing with Mobile Time-of-Flight Data
Oct 06, 2021
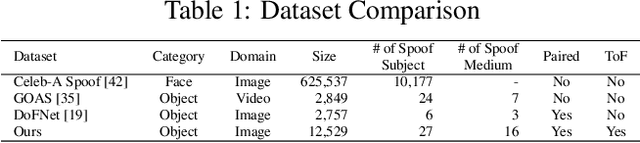
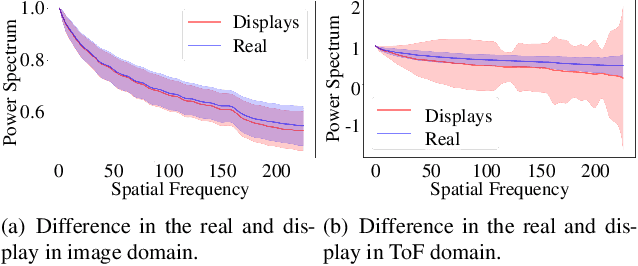

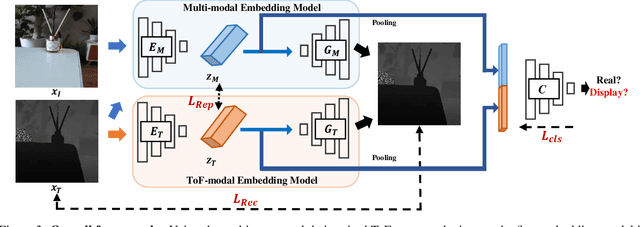
In online markets, sellers can maliciously recapture others' images on display screens to utilize as spoof images, which can be challenging to distinguish in human eyes. To prevent such harm, we propose an anti-spoofing method using the paired rgb images and depth maps provided by the mobile camera with a Time-of-Fight sensor. When images are recaptured on display screens, various patterns differing by the screens as known as the moir\'e patterns can be also captured in spoof images. These patterns lead the anti-spoofing model to be overfitted and unable to detect spoof images recaptured on unseen media. To avoid the issue, we build a novel representation model composed of two embedding models, which can be trained without considering the recaptured images. Also, we newly introduce mToF dataset, the largest and most diverse object anti-spoofing dataset, and the first to utilize ToF data. Experimental results confirm that our model achieves robust generalization even across unseen domains.
Accelerating Magnetic Resonance Parametric Mapping Using Simultaneously Spatial Patch-based and Parametric Group-based Low-rank Tensors (SMART)
Jul 17, 2022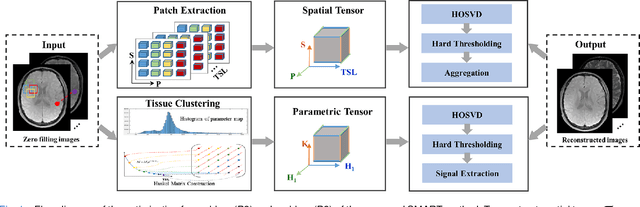
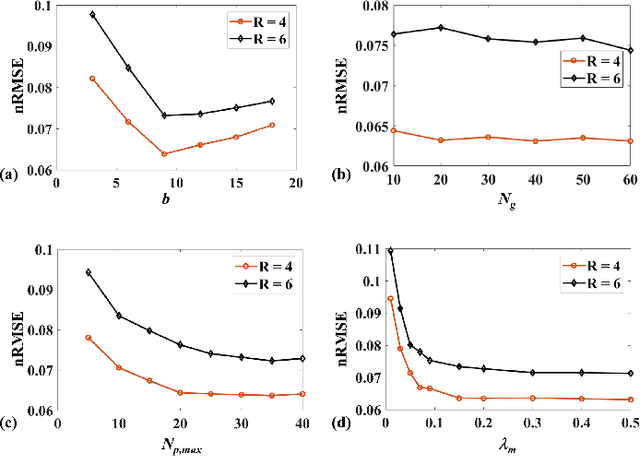
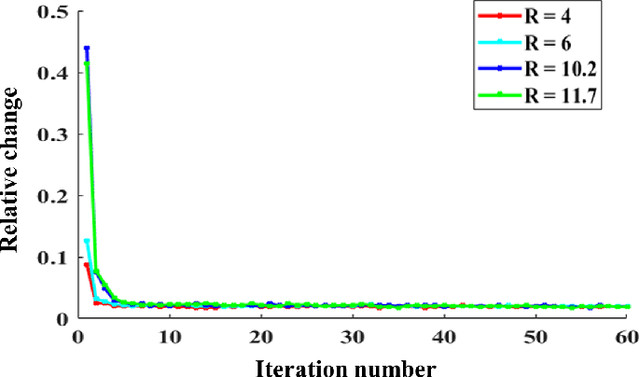
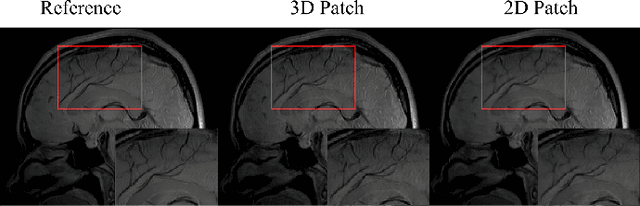
Quantitative magnetic resonance (MR) parametric mapping is a promising approach for characterizing intrinsic tissue-dependent information. However, long scan time significantly hinders its widespread applications. Recently, low-rank tensor has been employed and demonstrated good performance in accelerating MR parametricmapping. In this study, we propose a novel method that uses spatial patch-based and parametric group-based low rank tensors simultaneously (SMART) to reconstruct images from highly undersampled k-space data. The spatial patch-based low-rank tensor exploits the high local and nonlocal redundancies and similarities between the contrast images in parametric mapping. The parametric group based low-rank tensor, which integrates similar exponential behavior of the image signals, is jointly used to enforce the multidimensional low-rankness in the reconstruction process. In vivo brain datasets were used to demonstrate the validity of the proposed method. Experimental results have demonstrated that the proposed method achieves 11.7-fold and 13.21-fold accelerations in two-dimensional and three-dimensional acquisitions, respectively, with more accurate reconstructed images and maps than several state-of-the-art methods. Prospective reconstruction results further demonstrate the capability of the SMART method in accelerating MR quantitative imaging.
DarkSLAM: GAN-assisted Visual SLAM for Reliable Operation in Low-light Conditions
Jun 05, 2022
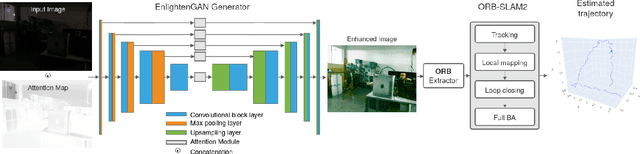


Existing visual SLAM approaches are sensitive to illumination, with their precision drastically falling in dark conditions due to feature extractor limitations. The algorithms currently used to overcome this issue are not able to provide reliable results due to poor performance and noisiness, and the localization quality in dark conditions is still insufficient for practical use. In this paper, we present a novel SLAM method capable of working in low light using Generative Adversarial Network (GAN) preprocessing module to enhance the light conditions on input images, thus improving the localization robustness. The proposed algorithm was evaluated on a custom indoor dataset consisting of 14 sequences with varying illumination levels and ground truth data collected using a motion capture system. According to the experimental results, the reliability of the proposed approach remains high even in extremely low light conditions, providing 25.1% tracking time on darkest sequences, whereas existing approaches achieve tracking only 0.6% of the sequence time.
Multi-UAV Planning for Cooperative Wildfire Coverage and Tracking with Quality-of-Service Guarantees
Jun 21, 2022In recent years, teams of robot and Unmanned Aerial Vehicles (UAVs) have been commissioned by researchers to enable accurate, online wildfire coverage and tracking. While the majority of prior work focuses on the coordination and control of such multi-robot systems, to date, these UAV teams have not been given the ability to reason about a fire's track (i.e., location and propagation dynamics) to provide performance guarantee over a time horizon. Motivated by the problem of aerial wildfire monitoring, we propose a predictive framework which enables cooperation in multi-UAV teams towards collaborative field coverage and fire tracking with probabilistic performance guarantee. Our approach enables UAVs to infer the latent fire propagation dynamics for time-extended coordination in safety-critical conditions. We derive a set of novel, analytical temporal, and tracking-error bounds to enable the UAV-team to distribute their limited resources and cover the entire fire area according to the case-specific estimated states and provide a probabilistic performance guarantee. Our results are not limited to the aerial wildfire monitoring case-study and are generally applicable to problems, such as search-and-rescue, target tracking and border patrol. We evaluate our approach in simulation and provide demonstrations of the proposed framework on a physical multi-robot testbed to account for real robot dynamics and restrictions. Our quantitative evaluations validate the performance of our method accumulating 7.5x and 9.0x smaller tracking-error than state-of-the-art model-based and reinforcement learning benchmarks, respectively.
Motion-aware Memory Network for Fast Video Salient Object Detection
Aug 01, 2022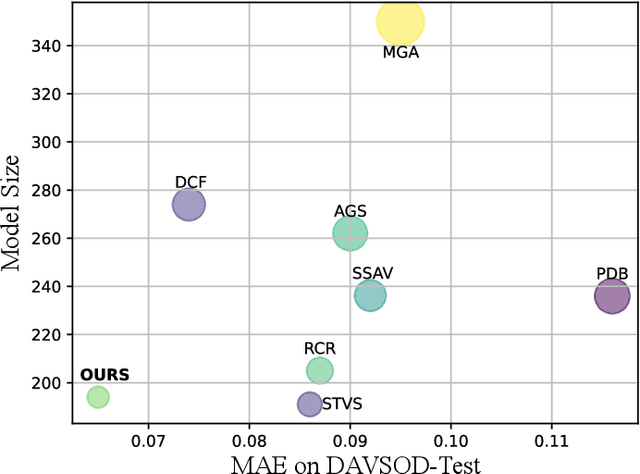

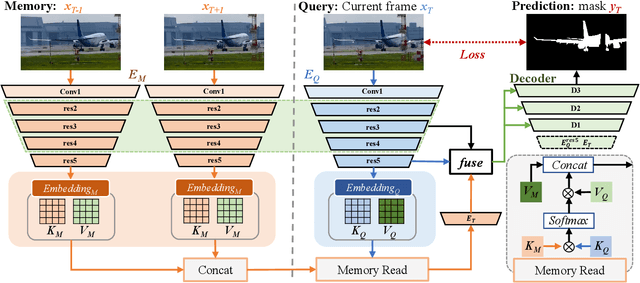
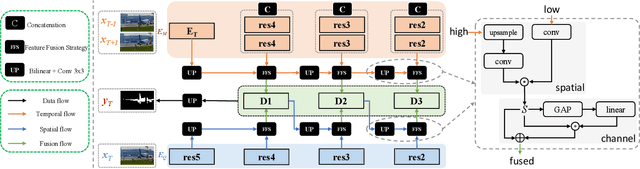
Previous methods based on 3DCNN, convLSTM, or optical flow have achieved great success in video salient object detection (VSOD). However, they still suffer from high computational costs or poor quality of the generated saliency maps. To solve these problems, we design a space-time memory (STM)-based network, which extracts useful temporal information of the current frame from adjacent frames as the temporal branch of VSOD. Furthermore, previous methods only considered single-frame prediction without temporal association. As a result, the model may not focus on the temporal information sufficiently. Thus, we initially introduce object motion prediction between inter-frame into VSOD. Our model follows standard encoder--decoder architecture. In the encoding stage, we generate high-level temporal features by using high-level features from the current and its adjacent frames. This approach is more efficient than the optical flow-based methods. In the decoding stage, we propose an effective fusion strategy for spatial and temporal branches. The semantic information of the high-level features is used to fuse the object details in the low-level features, and then the spatiotemporal features are obtained step by step to reconstruct the saliency maps. Moreover, inspired by the boundary supervision commonly used in image salient object detection (ISOD), we design a motion-aware loss for predicting object boundary motion and simultaneously perform multitask learning for VSOD and object motion prediction, which can further facilitate the model to extract spatiotemporal features accurately and maintain the object integrity. Extensive experiments on several datasets demonstrated the effectiveness of our method and can achieve state-of-the-art metrics on some datasets. The proposed model does not require optical flow or other preprocessing, and can reach a speed of nearly 100 FPS during inference.
SECLEDS: Sequence Clustering in Evolving Data Streams via Multiple Medoids and Medoid Voting
Jun 24, 2022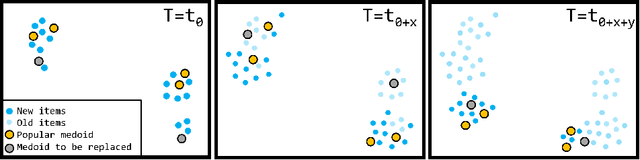

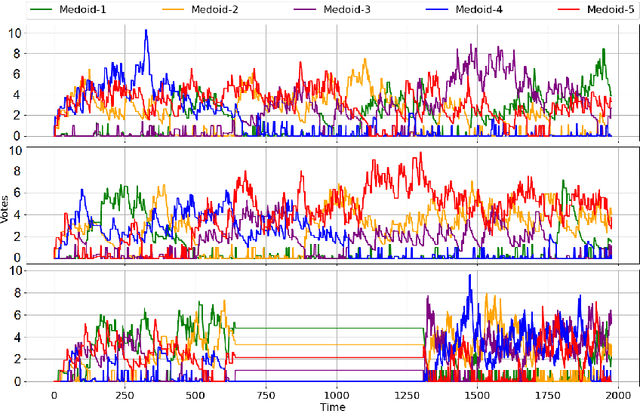
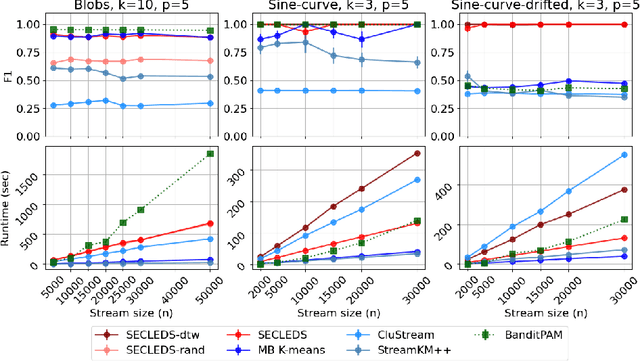
Sequence clustering in a streaming environment is challenging because it is computationally expensive, and the sequences may evolve over time. K-medoids or Partitioning Around Medoids (PAM) is commonly used to cluster sequences since it supports alignment-based distances, and the k-centers being actual data items helps with cluster interpretability. However, offline k-medoids has no support for concept drift, while also being prohibitively expensive for clustering data streams. We therefore propose SECLEDS, a streaming variant of the k-medoids algorithm with constant memory footprint. SECLEDS has two unique properties: i) it uses multiple medoids per cluster, producing stable high-quality clusters, and ii) it handles concept drift using an intuitive Medoid Voting scheme for approximating cluster distances. Unlike existing adaptive algorithms that create new clusters for new concepts, SECLEDS follows a fundamentally different approach, where the clusters themselves evolve with an evolving stream. Using real and synthetic datasets, we empirically demonstrate that SECLEDS produces high-quality clusters regardless of drift, stream size, data dimensionality, and number of clusters. We compare against three popular stream and batch clustering algorithms. The state-of-the-art BanditPAM is used as an offline benchmark. SECLEDS achieves comparable F1 score to BanditPAM while reducing the number of required distance computations by 83.7%. Importantly, SECLEDS outperforms all baselines by 138.7% when the stream contains drift. We also cluster real network traffic, and provide evidence that SECLEDS can support network bandwidths of up to 1.08 Gbps while using the (expensive) dynamic time warping distance.
Finite-Time Error Analysis of Asynchronous Q-Learning with Discrete-Time Switching System Models
Feb 22, 2021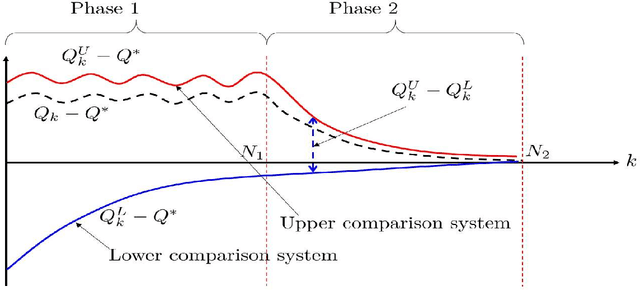
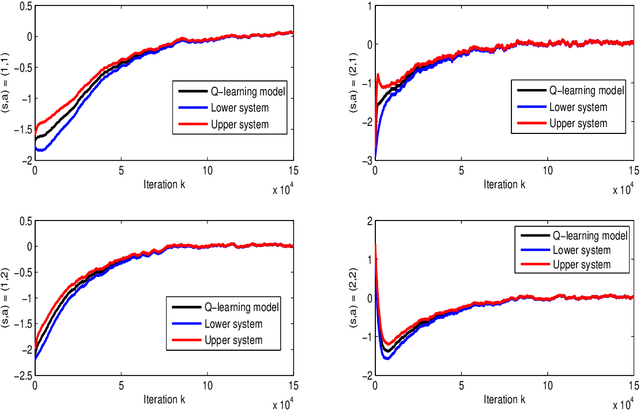
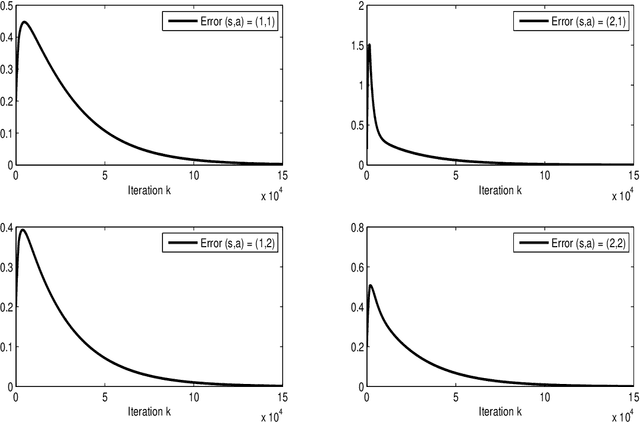
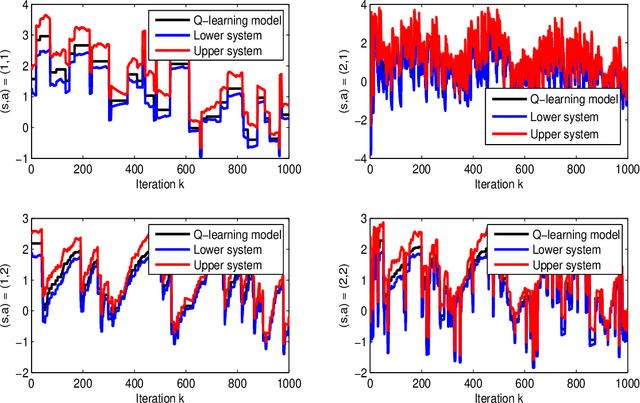
This paper develops a novel framework to analyze the convergence of Q-learning algorithm by using its connections to dynamical systems. We prove that asynchronous Q-learning with a constant step-size can be naturally formulated as discrete-time stochastic switched linear systems. Moreover, the evolution of the Q-learning estimation error is over- and underestimated by trajectories of two dynamical systems. Based on the schemes, a new finite-time analysis of the Q-learning is given with a finite-time error bound. It offers novel intuitive insights on analysis of Q-learning mainly based on control theoretic frameworks. By filling the gap between both domains in a synergistic way, this approach can potentially facilitate further progress in each field.
Survival Kernets: Scalable and Interpretable Deep Kernel Survival Analysis with an Accuracy Guarantee
Jun 21, 2022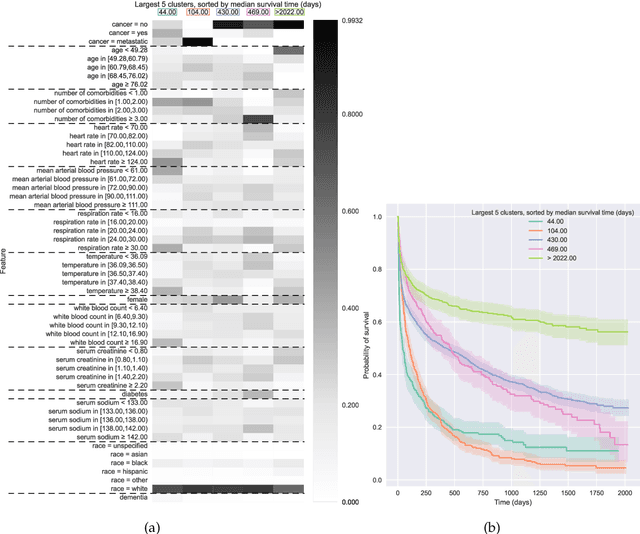
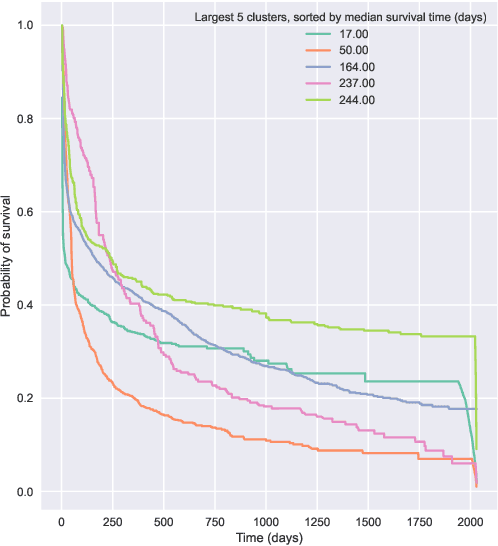
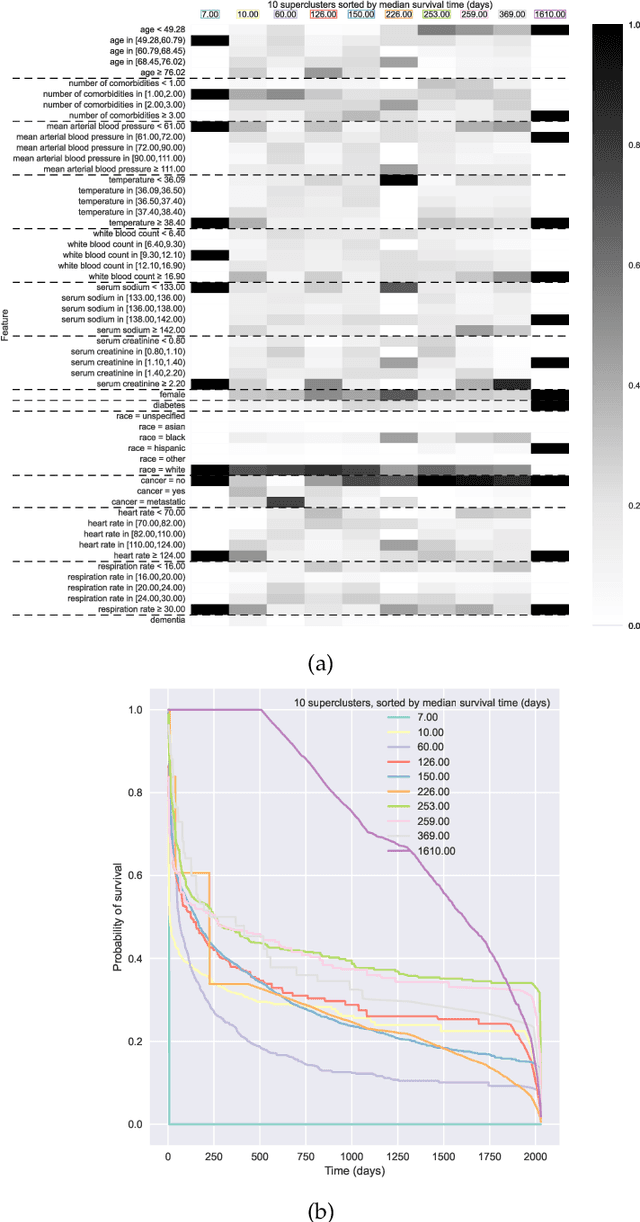
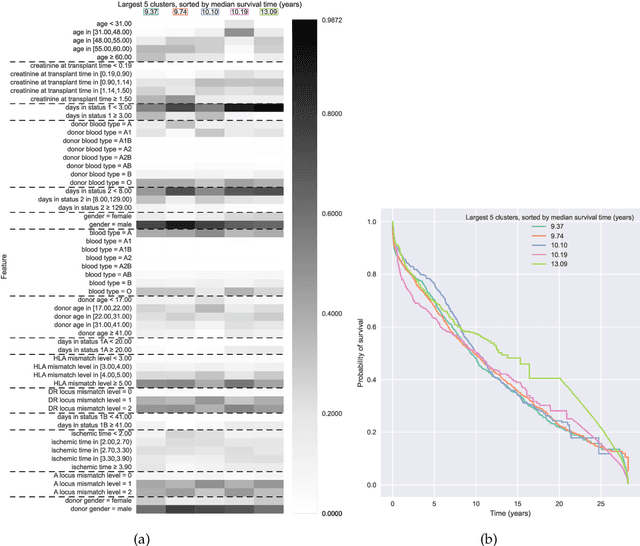
Kernel survival analysis models estimate individual survival distributions with the help of a kernel function, which measures the similarity between any two data points. Such a kernel function can be learned using deep kernel survival models. In this paper, we present a new deep kernel survival model called a survival kernet, which scales to large datasets in a manner that is amenable to model interpretation and also theoretical analysis. Specifically, the training data are partitioned into clusters based on a recently developed training set compression scheme for classification and regression called kernel netting that we extend to the survival analysis setting. At test-time, each data point is represented as a weighted combination of these clusters, and each such cluster can be visualized. For a special case of survival kernets, we establish a finite-sample error bound on predicted survival distributions that is, up to a log factor, optimal. Whereas scalability at test time is achieved using the aforementioned kernel netting compression strategy, scalability during training is achieved by a warm-start procedure based on tree ensembles such as XGBoost and a heuristic approach to accelerating neural architecture search. On three standard survival analysis datasets of varying sizes (up to roughly 3 million data points), we show that survival kernets are highly competitive with the best of baselines tested in terms of concordance index. Our code is available at: https://github.com/georgehc/survival-kernets
On the Versatile Uses of Partial Distance Correlation in Deep Learning
Jul 20, 2022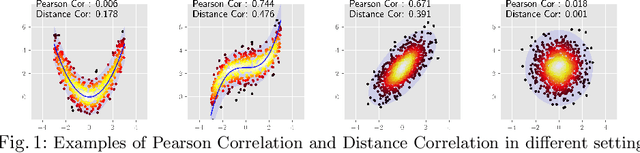
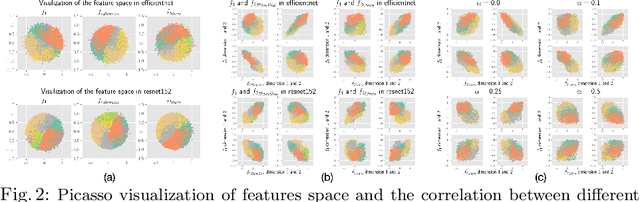
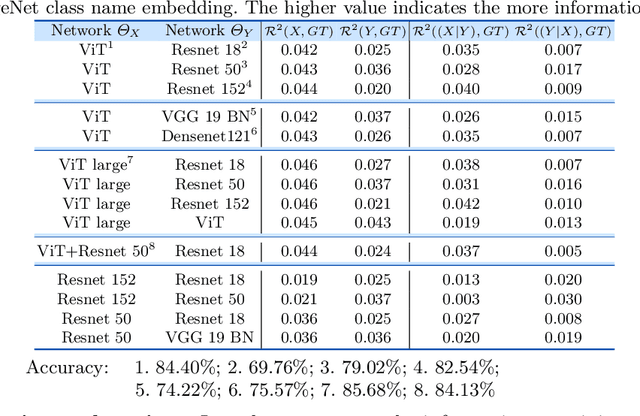
Comparing the functional behavior of neural network models, whether it is a single network over time or two (or more networks) during or post-training, is an essential step in understanding what they are learning (and what they are not), and for identifying strategies for regularization or efficiency improvements. Despite recent progress, e.g., comparing vision transformers to CNNs, systematic comparison of function, especially across different networks, remains difficult and is often carried out layer by layer. Approaches such as canonical correlation analysis (CCA) are applicable in principle, but have been sparingly used so far. In this paper, we revisit a (less widely known) from statistics, called distance correlation (and its partial variant), designed to evaluate correlation between feature spaces of different dimensions. We describe the steps necessary to carry out its deployment for large scale models -- this opens the door to a surprising array of applications ranging from conditioning one deep model w.r.t. another, learning disentangled representations as well as optimizing diverse models that would directly be more robust to adversarial attacks. Our experiments suggest a versatile regularizer (or constraint) with many advantages, which avoids some of the common difficulties one faces in such analyses. Code is at https://github.com/zhenxingjian/Partial_Distance_Correlation.
SMATE: Semi-Supervised Spatio-Temporal Representation Learning on Multivariate Time Series
Oct 01, 2021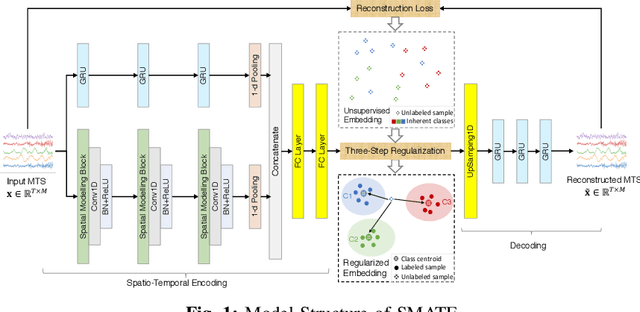
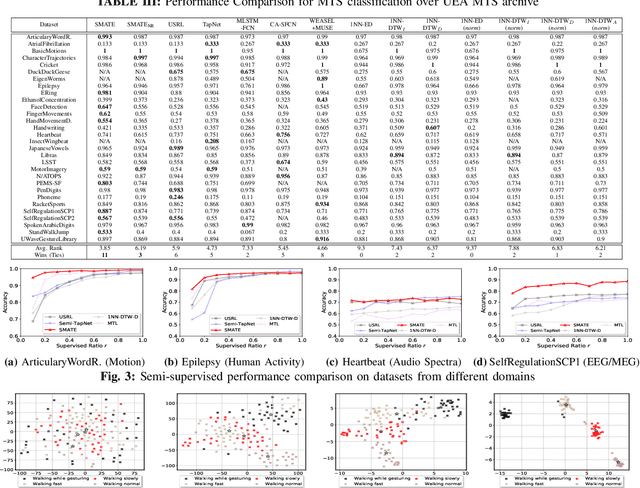
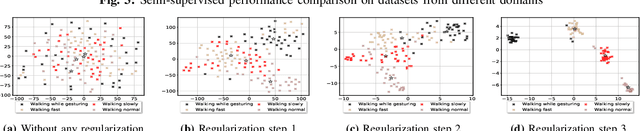
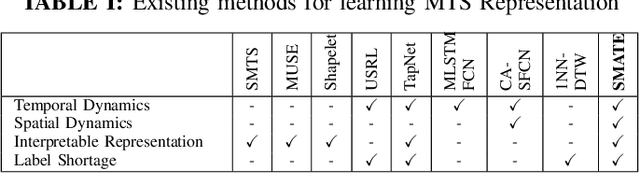
Learning from Multivariate Time Series (MTS) has attracted widespread attention in recent years. In particular, label shortage is a real challenge for the classification task on MTS, considering its complex dimensional and sequential data structure. Unlike self-training and positive unlabeled learning that rely on distance-based classifiers, in this paper, we propose SMATE, a novel semi-supervised model for learning the interpretable Spatio-Temporal representation from weakly labeled MTS. We validate empirically the learned representation on 22 public datasets from the UEA MTS archive. We compare it with 13 state-of-the-art baseline methods for fully supervised tasks and four baselines for semi-supervised tasks. The results show the reliability and efficiency of our proposed method.