 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
You Only Need One Detector: Unified Object Detector for Different Modalities based on Vision Transformers
Jul 03, 2022



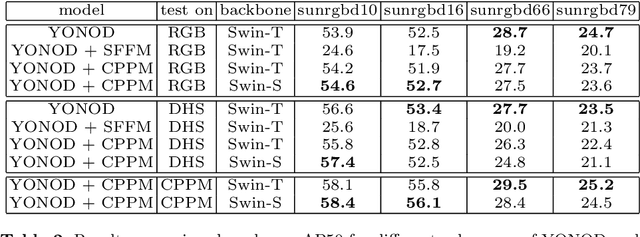
Most systems use different models for different modalities, such as one model for processing RGB images and one for depth images. Meanwhile, some recent works discovered that an identical model for one modality can be used for another modality with the help of cross modality transfer learning. In this article, we further find out that by using a vision transformer together with cross/inter modality transfer learning, a unified detector can achieve better performances when using different modalities as inputs. The unified model is useful as we don't need to maintain separate models or weights for robotics, hence, it is more efficient. One application scenario of our unified system for robotics can be: without any model architecture and model weights updating, robotics can switch smoothly on using RGB camera or both RGB and Depth Sensor during the day time and Depth sensor during the night time . Experiments on SUN RGB-D dataset show: Our unified model is not only efficient, but also has a similar or better performance in terms of mAP50 based on SUNRGBD16 category: compare with the RGB only one, ours is slightly worse (52.3 $\to$ 51.9). compare with the point cloud only one, we have similar performance (52.7 $\to$ 52.8); When using the novel inter modality mixing method proposed in this work, our model can achieve a significantly better performance with 3.1 (52.7 $\to$ 55.8) absolute improvement comparing with the previous best result. Code (including training/inference logs and model checkpoints) is available: \url{https://github.com/liketheflower/YONOD.git}
A complex network approach to time series analysis with application in diagnosis of neuromuscular disorders
Aug 16, 2021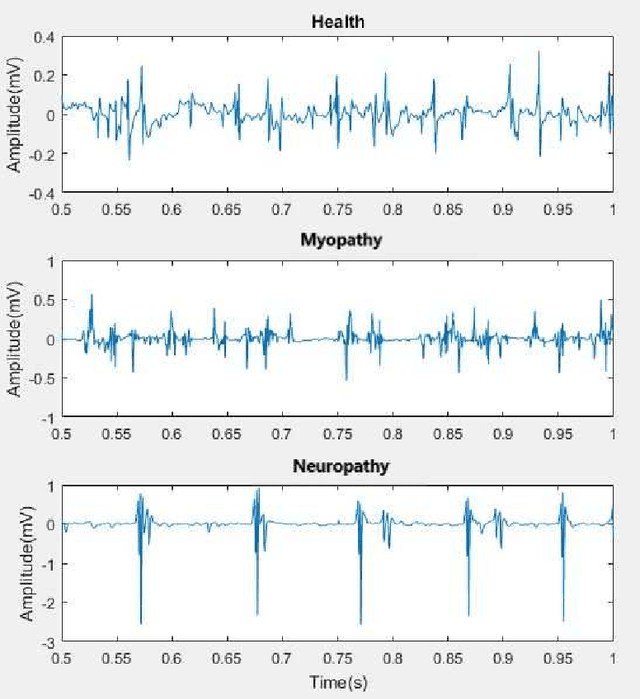
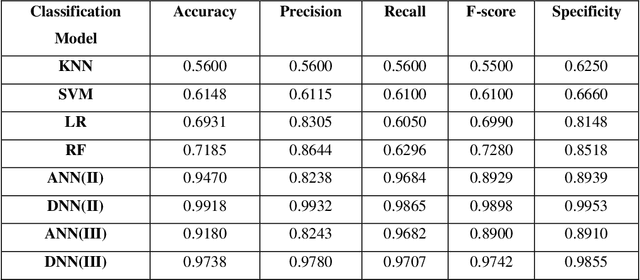
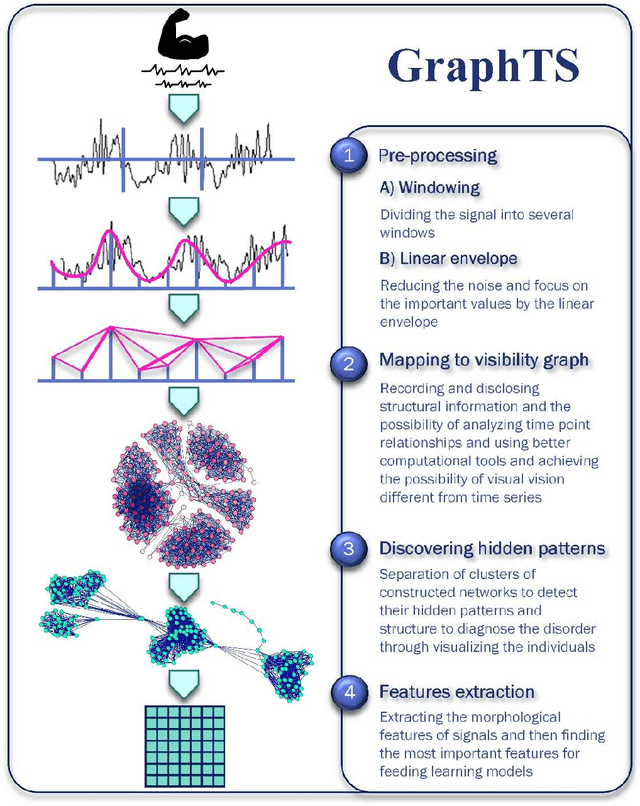
Electromyography (EMG) refers to a biomedical signal indicating neuromuscular activity and muscle morphology. Experts accurately diagnose neuromuscular disorders using this time series. Modern data analysis techniques have recently led to introducing novel approaches for mapping time series data to graphs and complex networks with applications in diverse fields, including medicine. The resulting networks develop a completely different visual acuity that can be used to complement physician findings of time series. This can lead to a more enriched analysis, reduced error, more accurate diagnosis of the disease, and increased accuracy and speed of the treatment process. The mapping process may cause the loss of essential data from the time series and not retain all the time series features. As a result, achieving an approach that can provide a good representation of the time series while maintaining essential features is crucial. This paper proposes a new approach to network development named GraphTS to overcome the limited accuracy of existing methods through EMG time series using the visibility graph method. For this purpose, EMG signals are pre-processed and mapped to a complex network by a standard visibility graph algorithm. The resulting networks can differentiate between healthy and patient samples. In the next step, the properties of the developed networks are given in the form of a feature matrix as input to classifiers after extracting optimal features. Performance evaluation of the proposed approach with deep neural network shows 99.30% accuracy for training data and 99.18% for test data. Therefore, in addition to enriched network representation and covering the features of time series for healthy, myopathy, and neuropathy EMG, the proposed technique improves accuracy, precision, recall, and F-score.
Survival Kernets: Scalable and Interpretable Deep Kernel Survival Analysis with an Accuracy Guarantee
Jun 30, 2022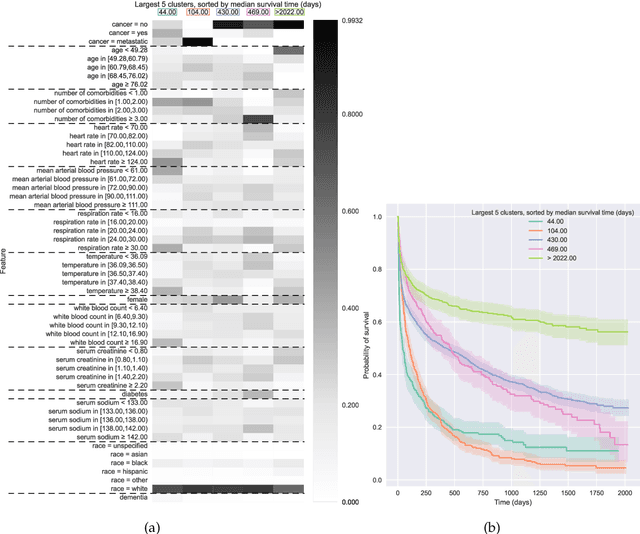
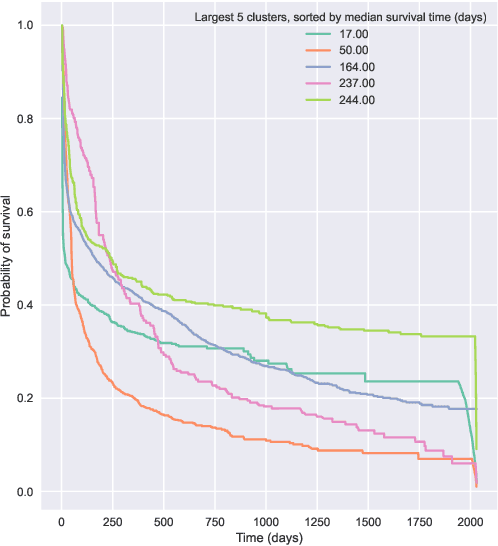
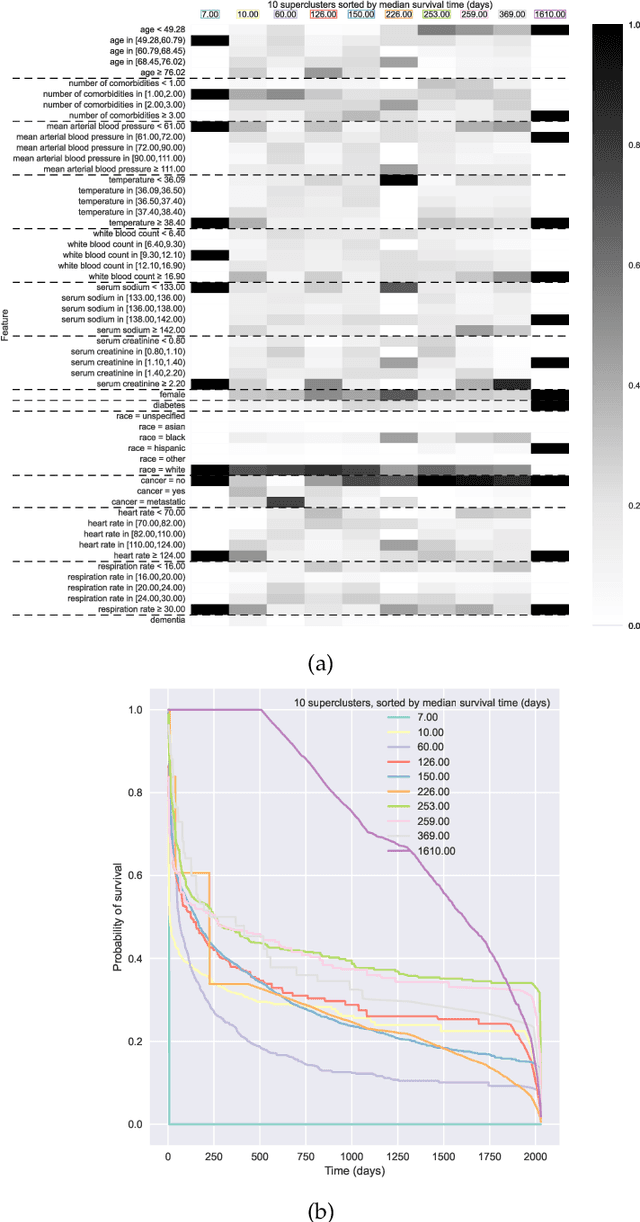
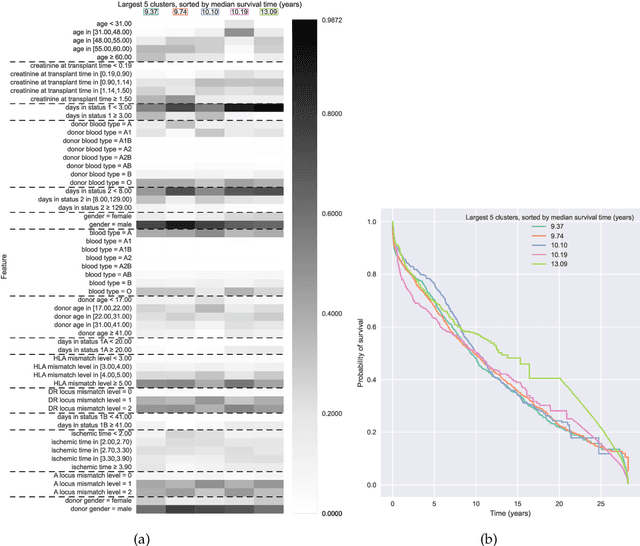
Kernel survival analysis models estimate individual survival distributions with the help of a kernel function, which measures the similarity between any two data points. Such a kernel function can be learned using deep kernel survival models. In this paper, we present a new deep kernel survival model called a survival kernet, which scales to large datasets in a manner that is amenable to model interpretation and also theoretical analysis. Specifically, the training data are partitioned into clusters based on a recently developed training set compression scheme for classification and regression called kernel netting that we extend to the survival analysis setting. At test-time, each data point is represented as a weighted combination of these clusters, and each such cluster can be visualized. For a special case of survival kernets, we establish a finite-sample error bound on predicted survival distributions that is, up to a log factor, optimal. Whereas scalability at test time is achieved using the aforementioned kernel netting compression strategy, scalability during training is achieved by a warm-start procedure based on tree ensembles such as XGBoost and a heuristic approach to accelerating neural architecture search. On three standard survival analysis datasets of varying sizes (up to roughly 3 million data points), we show that survival kernets are highly competitive with the best of baselines tested in terms of concordance index. Our code is available at: https://github.com/georgehc/survival-kernets
GPU-accelerated SIFT-aided source identification of stabilized videos
Jul 29, 2022

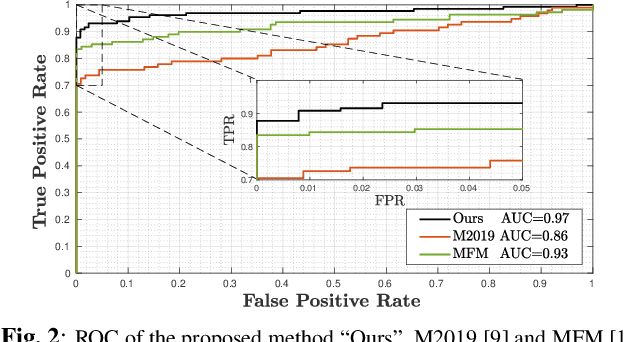
Video stabilization is an in-camera processing commonly applied by modern acquisition devices. While significantly improving the visual quality of the resulting videos, it has been shown that such operation typically hinders the forensic analysis of video signals. In fact, the correct identification of the acquisition source usually based on Photo Response non-Uniformity (PRNU) is subject to the estimation of the transformation applied to each frame in the stabilization phase. A number of techniques have been proposed for dealing with this problem, which however typically suffer from a high computational burden due to the grid search in the space of inversion parameters. Our work attempts to alleviate these shortcomings by exploiting the parallelization capabilities of Graphics Processing Units (GPUs), typically used for deep learning applications, in the framework of stabilised frames inversion. Moreover, we propose to exploit SIFT features {to estimate the camera momentum and} %to identify less stabilized temporal segments, thus enabling a more accurate identification analysis, and to efficiently initialize the frame-wise parameter search of consecutive frames. Experiments on a consolidated benchmark dataset confirm the effectiveness of the proposed approach in reducing the required computational time and improving the source identification accuracy. {The code is available at \url{https://github.com/AMontiB/GPU-PRNU-SIFT}}.
Graph Property Prediction on Open Graph Benchmark: A Winning Solution by Graph Neural Architecture Search
Jul 13, 2022

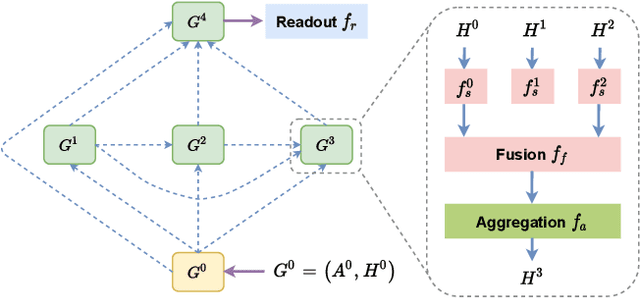
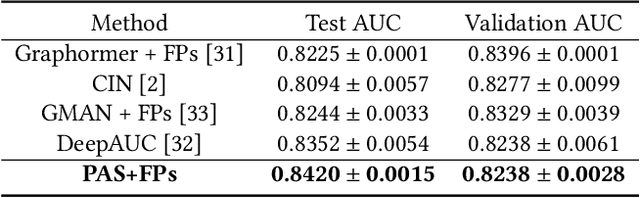
Aiming at two molecular graph datasets and one protein association subgraph dataset in OGB graph classification task, we design a graph neural network framework for graph classification task by introducing PAS(Pooling Architecture Search). At the same time, we improve it based on the GNN topology design method F2GNN to further design the feature selection and fusion strategies, so as to further improve the performance of the model in the graph property prediction task while overcoming the over smoothing problem of deep GNN training. Finally, a performance breakthrough is achieved on these three datasets, which is significantly better than other methods with fixed aggregate function. It is proved that the NAS method has high generalization ability for multiple tasks and the advantage of our method in processing graph property prediction tasks.
Fairness Based Energy-Efficient 3D Path Planning of a Portable Access Point: A Deep Reinforcement Learning Approach
Aug 10, 2022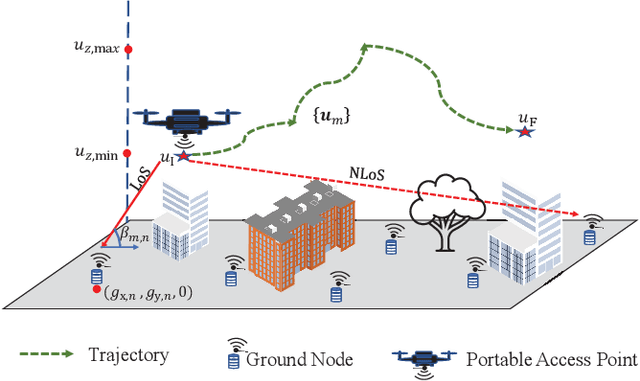
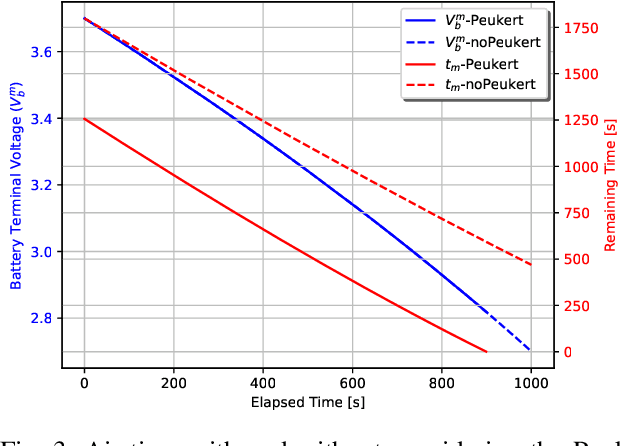
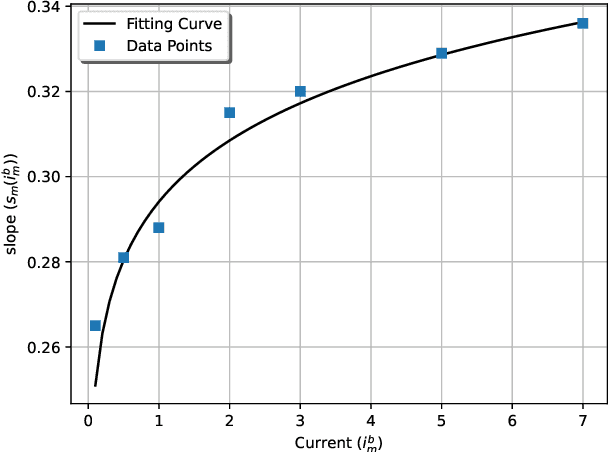
In this work, we optimize the 3D trajectory of an unmanned aerial vehicle (UAV)-based portable access point (PAP) that provides wireless services to a set of ground nodes (GNs). Moreover, as per the Peukert effect, we consider pragmatic non-linear battery discharge for the battery of the UAV. Thus, we formulate the problem in a novel manner that represents the maximization of a fairness-based energy efficiency metric and is named fair energy efficiency (FEE). The FEE metric defines a system that lays importance on both the per-user service fairness and the energy efficiency of the PAP. The formulated problem takes the form of a non-convex problem with non-tractable constraints. To obtain a solution, we represent the problem as a Markov Decision Process (MDP) with continuous state and action spaces. Considering the complexity of the solution space, we use the twin delayed deep deterministic policy gradient (TD3) actor-critic deep reinforcement learning (DRL) framework to learn a policy that maximizes the FEE of the system. We perform two types of RL training to exhibit the effectiveness of our approach: the first (offline) approach keeps the positions of the GNs the same throughout the training phase; the second approach generalizes the learned policy to any arrangement of GNs by changing the positions of GNs after each training episode. Numerical evaluations show that neglecting the Peukert effect overestimates the air-time of the PAP and can be addressed by optimally selecting the PAP's flying speed. Moreover, the user fairness, energy efficiency, and hence the FEE value of the system can be improved by efficiently moving the PAP above the GNs. As such, we notice massive FEE improvements over baseline scenarios of up to 88.31%, 272.34%, and 318.13% for suburban, urban, and dense urban environments, respectively.
Test-time Collective Prediction
Jun 22, 2021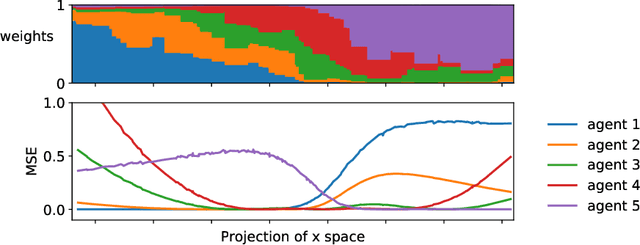
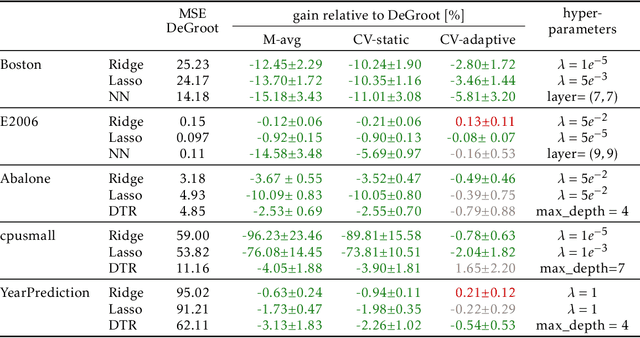
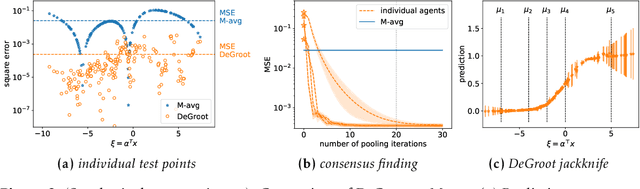
An increasingly common setting in machine learning involves multiple parties, each with their own data, who want to jointly make predictions on future test points. Agents wish to benefit from the collective expertise of the full set of agents to make better predictions than they would individually, but may not be willing to release their data or model parameters. In this work, we explore a decentralized mechanism to make collective predictions at test time, leveraging each agent's pre-trained model without relying on external validation, model retraining, or data pooling. Our approach takes inspiration from the literature in social science on human consensus-making. We analyze our mechanism theoretically, showing that it converges to inverse meansquared-error (MSE) weighting in the large-sample limit. To compute error bars on the collective predictions we propose a decentralized Jackknife procedure that evaluates the sensitivity of our mechanism to a single agent's prediction. Empirically, we demonstrate that our scheme effectively combines models with differing quality across the input space. The proposed consensus prediction achieves significant gains over classical model averaging, and even outperforms weighted averaging schemes that have access to additional validation data.
A Real-time Junk Food Recognition System based on Machine Learning
Mar 22, 2022



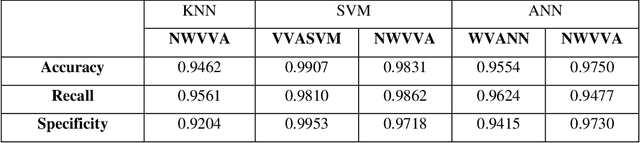
$ $As a result of bad eating habits, humanity may be destroyed. People are constantly on the lookout for tasty foods, with junk foods being the most common source. As a consequence, our eating patterns are shifting, and we're gravitating toward junk food more than ever, which is bad for our health and increases our risk of acquiring health problems. Machine learning principles are applied in every aspect of our lives, and one of them is object recognition via image processing. However, because foods vary in nature, this procedure is crucial, and traditional methods like ANN, SVM, KNN, PLS etc., will result in a low accuracy rate. All of these issues were defeated by the Deep Neural Network. In this work, we created a fresh dataset of 10,000 data points from 20 junk food classifications to try to recognize junk foods. All of the data in the data set was gathered using the Google search engine, which is thought to be one-of-a-kind in every way. The goal was achieved using Convolution Neural Network (CNN) technology, which is well-known for image processing. We achieved a 98.05\% accuracy rate throughout the research, which was satisfactory. In addition, we conducted a test based on a real-life event, and the outcome was extraordinary. Our goal is to advance this research to the next level, so that it may be applied to a future study. Our ultimate goal is to create a system that would encourage people to avoid eating junk food and to be health-conscious. \keywords{ Machine Learning \and junk food \and object detection \and YOLOv3 \and custom food dataset.}
Multi-Object Tracking and Segmentation with a Space-Time Memory Network
Oct 21, 2021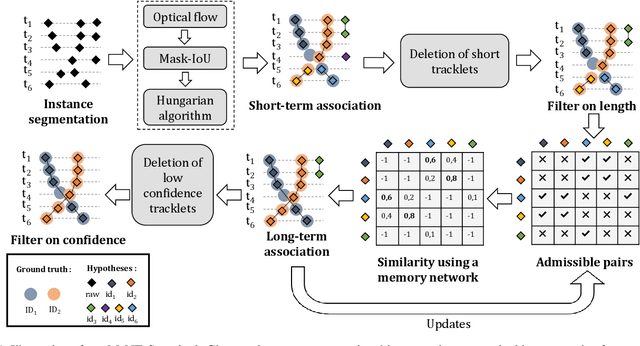
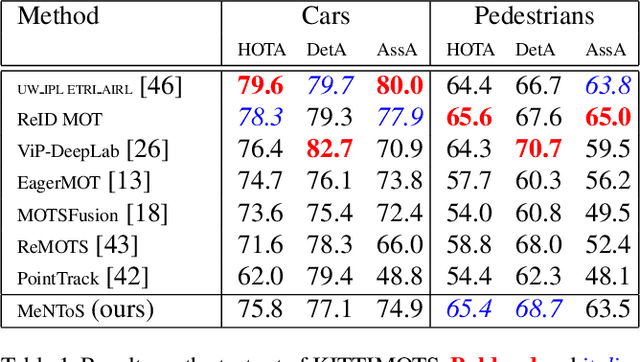
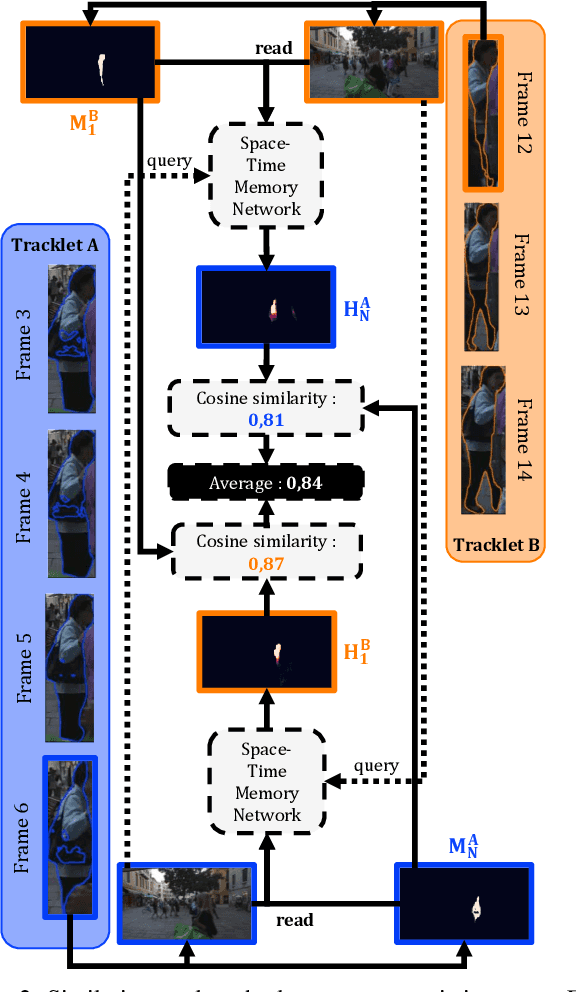
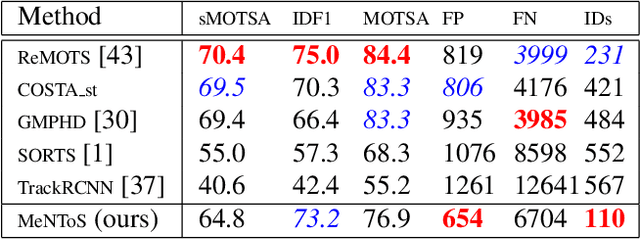
We propose a method for multi-object tracking and segmentation that does not require fine-tuning or per benchmark hyper-parameter selection. The proposed tracker, MeNToS, addresses particularly the data association problem. Indeed, the recently introduced HOTA metric, which has a better alignment with the human visual assessment by evenly balancing detections and associations quality, has shown that improvements are still needed for data association. After creating tracklets using instance segmentation and optical flow, the proposed method relies on a space-time memory network developed for one-shot video object segmentation to improve the association of tracklets with temporal gaps. We evaluated our tracker on KITTIMOTS and MOTSChallenge and show the benefit of our data association strategy with the HOTA metric. The project page is \url{www.mehdimiah.com/mentos+}.
Explaining Dynamic Graph Neural Networks via Relevance Back-propagation
Jul 22, 2022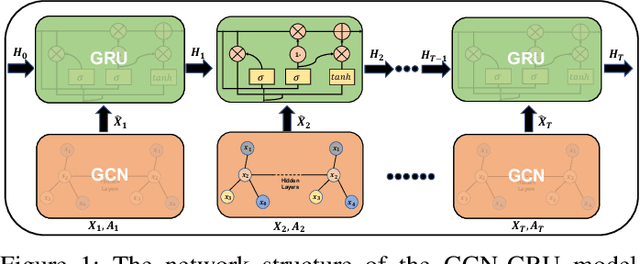
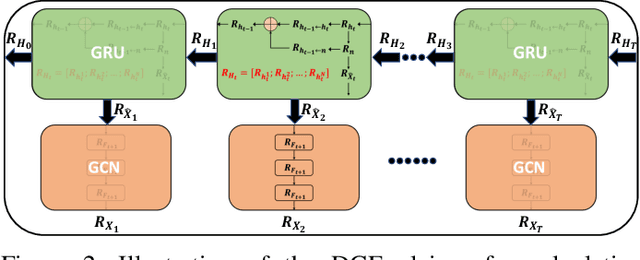
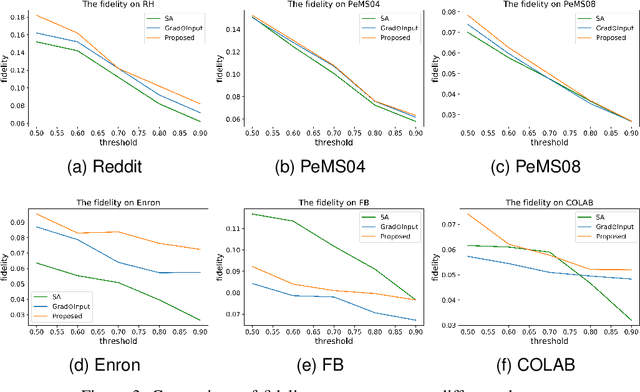
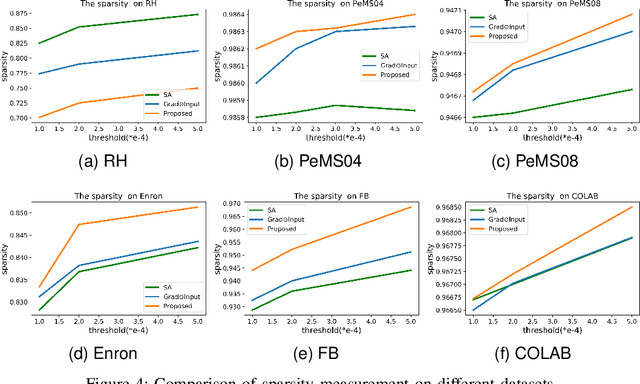
Graph Neural Networks (GNNs) have shown remarkable effectiveness in capturing abundant information in graph-structured data. However, the black-box nature of GNNs hinders users from understanding and trusting the models, thus leading to difficulties in their applications. While recent years witness the prosperity of the studies on explaining GNNs, most of them focus on static graphs, leaving the explanation of dynamic GNNs nearly unexplored. It is challenging to explain dynamic GNNs, due to their unique characteristic of time-varying graph structures. Directly using existing models designed for static graphs on dynamic graphs is not feasible because they ignore temporal dependencies among the snapshots. In this work, we propose DGExplainer to provide reliable explanation on dynamic GNNs. DGExplainer redistributes the output activation score of a dynamic GNN to the relevances of the neurons of its previous layer, which iterates until the relevance scores of the input neuron are obtained. We conduct quantitative and qualitative experiments on real-world datasets to demonstrate the effectiveness of the proposed framework for identifying important nodes for link prediction and node regression for dynamic GNNs.