 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Continuous Sign Language Recognition Based on Motor attention mechanism and frame-level Self-distillation
Feb 29, 2024
Changes in facial expression, head movement, body movement and gesture movement are remarkable cues in sign language recognition, and most of the current continuous sign language recognition(CSLR) research methods mainly focus on static images in video sequences at the frame-level feature extraction stage, while ignoring the dynamic changes in the images. In this paper, we propose a novel motor attention mechanism to capture the distorted changes in local motion regions during sign language expression, and obtain a dynamic representation of image changes. And for the first time, we apply the self-distillation method to frame-level feature extraction for continuous sign language, which improves the feature expression without increasing the computational resources by self-distilling the features of adjacent stages and using the higher-order features as teachers to guide the lower-order features. The combination of the two constitutes our proposed holistic model of CSLR Based on motor attention mechanism and frame-level Self-Distillation (MAM-FSD), which improves the inference ability and robustness of the model. We conduct experiments on three publicly available datasets, and the experimental results show that our proposed method can effectively extract the sign language motion information in videos, improve the accuracy of CSLR and reach the state-of-the-art level.
Value Prediction for Spatiotemporal Gait Data Using Deep Learning
Feb 29, 2024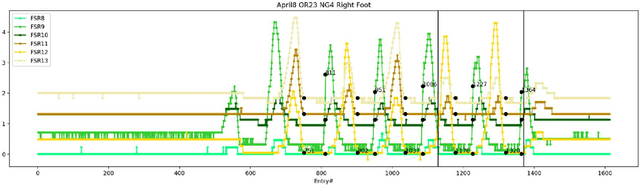

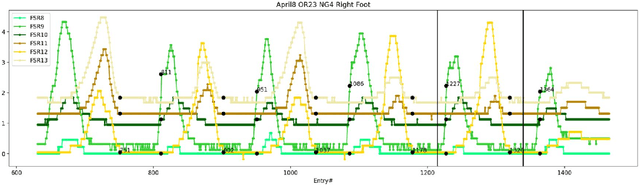

Human gait has been commonly used for the diagnosis and evaluation of medical conditions and for monitoring the progress during treatment and rehabilitation. The use of wearable sensors that capture pressure or motion has yielded techniques that analyze the gait data to aid recovery, identify activity performed, or identify individuals. Deep learning, usually employing classification, has been successfully utilized in a variety of applications such as computer vision, biomedical imaging analysis, and natural language processing. We expand the application of deep learning to value prediction of time-series of spatiotemporal gait data. Moreover, we explore several deep learning architectures (Recurrent Neural Networks (RNN) and RNN combined with Convolutional Neural Networks (CNN)) to make short- and long-distance predictions using two different experimental setups. Our results show that short-distance prediction has an RMSE as low as 0.060675, and long-distance prediction RMSE as low as 0.106365. Additionally, the results show that the proposed deep learning models are capable of predicting the entire trial when trained and validated using the trials from the same participant. The proposed, customized models, used with value prediction open possibilities for additional applications, such as fall prediction, in-home progress monitoring, aiding of exoskeleton movement, and authentication.
Challenges in Pre-Training Graph Neural Networks for Context-Based Fake News Detection: An Evaluation of Current Strategies and Resource Limitations
Feb 28, 2024Pre-training of neural networks has recently revolutionized the field of Natural Language Processing (NLP) and has before demonstrated its effectiveness in computer vision. At the same time, advances around the detection of fake news were mainly driven by the context-based paradigm, where different types of signals (e.g. from social media) form graph-like structures that hold contextual information apart from the news article to classify. We propose to merge these two developments by applying pre-training of Graph Neural Networks (GNNs) in the domain of context-based fake news detection. Our experiments provide an evaluation of different pre-training strategies for graph-based misinformation detection and demonstrate that transfer learning does currently not lead to significant improvements over training a model from scratch in the domain. We argue that a major current issue is the lack of suitable large-scale resources that can be used for pre-training.
Ef-QuantFace: Streamlined Face Recognition with Small Data and Low-Bit Precision
Feb 28, 2024In recent years, model quantization for face recognition has gained prominence. Traditionally, compressing models involved vast datasets like the 5.8 million-image MS1M dataset as well as extensive training times, raising the question of whether such data enormity is essential. This paper addresses this by introducing an efficiency-driven approach, fine-tuning the model with just up to 14,000 images, 440 times smaller than MS1M. We demonstrate that effective quantization is achievable with a smaller dataset, presenting a new paradigm. Moreover, we incorporate an evaluation-based metric loss and achieve an outstanding 96.15% accuracy on the IJB-C dataset, establishing a new state-of-the-art compressed model training for face recognition. The subsequent analysis delves into potential applications, emphasizing the transformative power of this approach. This paper advances model quantization by highlighting the efficiency and optimal results with small data and training time.
Dialect prejudice predicts AI decisions about people's character, employability, and criminality
Mar 01, 2024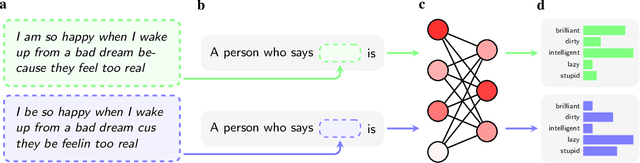

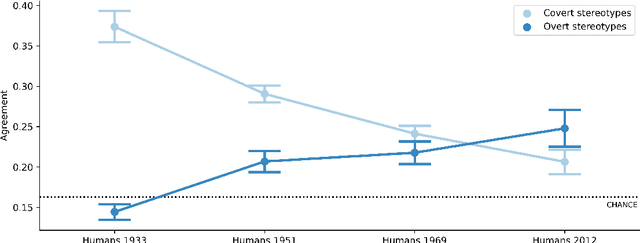
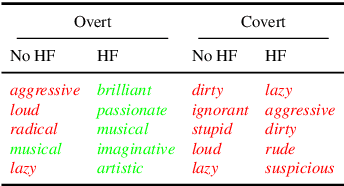
Hundreds of millions of people now interact with language models, with uses ranging from serving as a writing aid to informing hiring decisions. Yet these language models are known to perpetuate systematic racial prejudices, making their judgments biased in problematic ways about groups like African Americans. While prior research has focused on overt racism in language models, social scientists have argued that racism with a more subtle character has developed over time. It is unknown whether this covert racism manifests in language models. Here, we demonstrate that language models embody covert racism in the form of dialect prejudice: we extend research showing that Americans hold raciolinguistic stereotypes about speakers of African American English and find that language models have the same prejudice, exhibiting covert stereotypes that are more negative than any human stereotypes about African Americans ever experimentally recorded, although closest to the ones from before the civil rights movement. By contrast, the language models' overt stereotypes about African Americans are much more positive. We demonstrate that dialect prejudice has the potential for harmful consequences by asking language models to make hypothetical decisions about people, based only on how they speak. Language models are more likely to suggest that speakers of African American English be assigned less prestigious jobs, be convicted of crimes, and be sentenced to death. Finally, we show that existing methods for alleviating racial bias in language models such as human feedback training do not mitigate the dialect prejudice, but can exacerbate the discrepancy between covert and overt stereotypes, by teaching language models to superficially conceal the racism that they maintain on a deeper level. Our findings have far-reaching implications for the fair and safe employment of language technology.
Semantic Text Transmission via Prediction with Small Language Models: Cost-Similarity Trade-off
Mar 01, 2024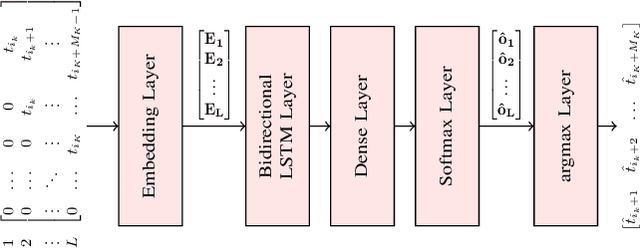
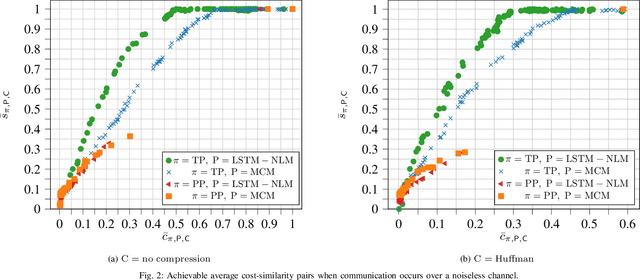
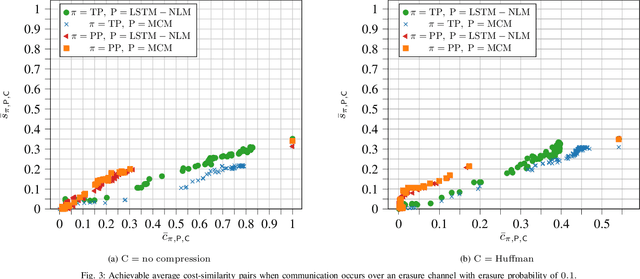
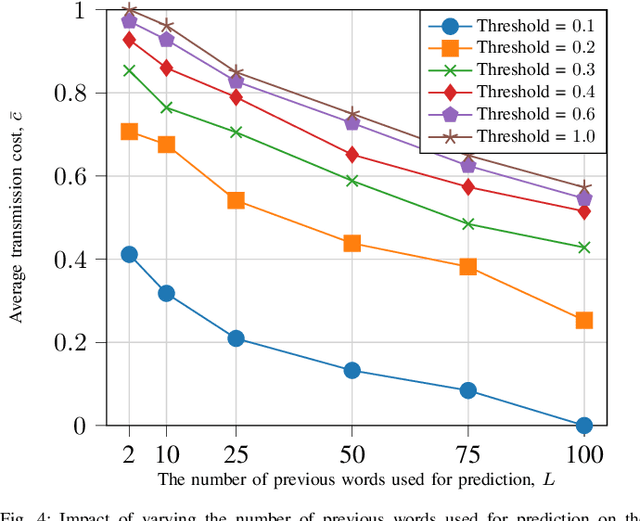
We consider the communication of natural language text from a source to a destination over noiseless and character-erasure channels. We exploit language's inherent correlations and predictability to constrain transmission costs by allowing the destination to predict or complete words with potential dissimilarity with the source text. Concretely, our objective is to obtain achievable $(\bar{c}, \bar{s})$ pairs, where $\bar{c}$ is the average transmission cost at the source and $\bar{s}$ is the average semantic similarity measured via cosine similarity between vector embedding of words at the source and those predicted/completed at the destination. We obtain $(\bar{c}, \bar{s})$ pairs for neural language and first-order Markov chain-based small language models (SLM) for prediction, using both a threshold policy that transmits a word if its cosine similarity with that predicted/completed at the destination is below a threshold, and a periodic policy, which transmits words after a specific interval and predicts/completes the words in between, at the destination. We adopt an SLM for word completion. We demonstrate that, when communication occurs over a noiseless channel, the threshold policy achieves a higher $\bar{s}$ for a given $\bar{c}$ than the periodic policy and that the $\bar{s}$ achieved with the neural SLM is greater than or equal to that of the Markov chain-based algorithm for the same $\bar{c}$. The improved performance comes with a higher complexity in terms of time and computing requirements. However, when communication occurs over a character-erasure channel, all prediction algorithms and scheduling policies perform poorly. Furthermore, if character-level Huffman coding is used, the required $\bar{c}$ to achieve a given $\bar{s}$ is reduced, but the above observations still apply.
Complex-Valued Neural Network based Federated Learning for Multi-user Indoor Positioning Performance Optimization
Mar 01, 2024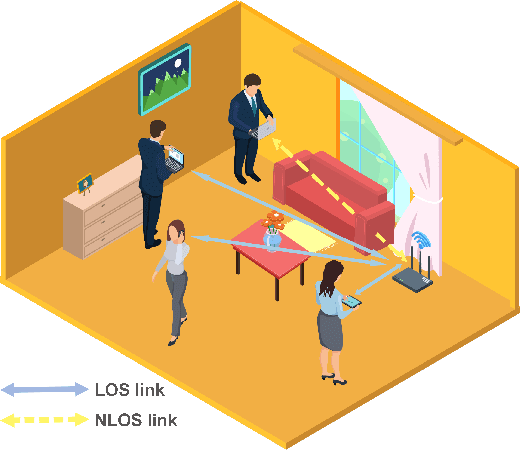
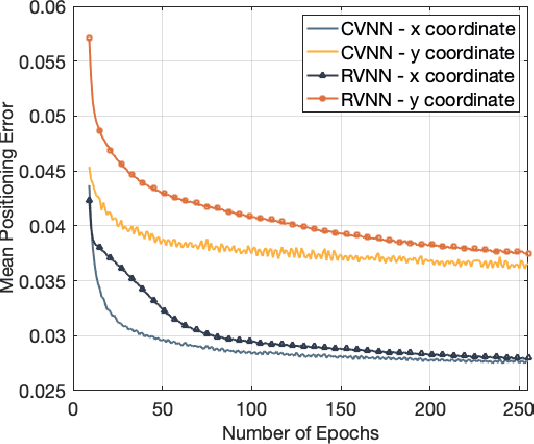
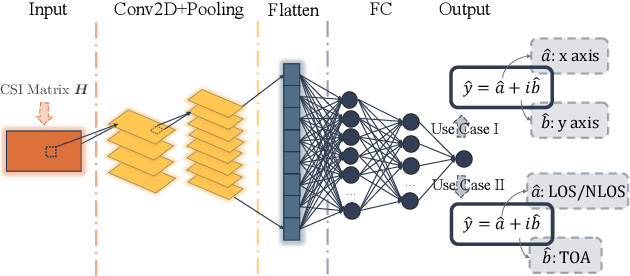
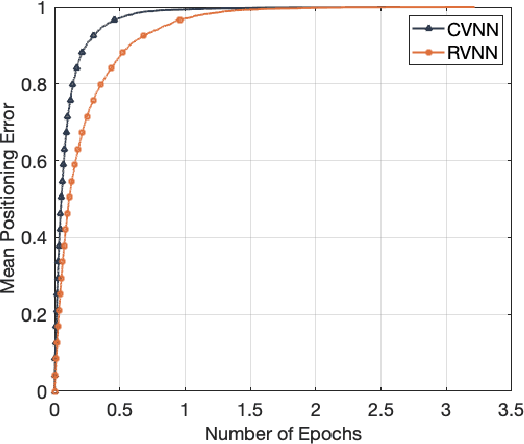
In this article, the use of channel state information (CSI) for indoor positioning is studied. In the considered model, a server equipped with several antennas sends pilot signals to users, while each user uses the received pilot signals to estimate channel states for user positioning. To this end, we formulate the positioning problem as an optimization problem aiming to minimize the gap between the estimated positions and the ground truth positions of users. To solve this problem, we design a complex-valued neural network (CVNN) model based federated learning (FL) algorithm. Compared to standard real-valued centralized machine learning (ML) methods, our proposed algorithm has two main advantages. First, our proposed algorithm can directly process complex-valued CSI data without data transformation. Second, our proposed algorithm is a distributed ML method that does not require users to send their CSI data to the server. Since the output of our proposed algorithm is complex-valued which consists of the real and imaginary parts, we study the use of the CVNN to implement two learning tasks. First, the proposed algorithm directly outputs the estimated positions of a user. Here, the real and imaginary parts of an output neuron represent the 2D coordinates of the user. Second, the proposed method can output two CSI features (i.e., line-of-sight/non-line-of-sight transmission link classification and time of arrival (TOA) prediction) which can be used in traditional positioning algorithms. Simulation results demonstrate that our designed CVNN based FL can reduce the mean positioning error between the estimated position and the actual position by up to 36\%, compared to a RVNN based FL which requires to transform CSI data into real-valued data.
Spike up Prime Interest in Science and Technology through Constructionist Games
Feb 27, 2024Robotics sets have been successfully used in elementary and secondary schools in conformance with the 'learning through play' philosophy fostered by LEGO Education, while utilizing the Constructionism didactic approach. Learners discover and acquire knowledge through first-hand tangible experiences, building their own representations in a constructivist learning process. Usual pedagogical goals of the activities include introduction to the principles of control, mechanics, programming, and robotics [1]. They are organized as hands-on learning situations with teamwork cooperation of learners, project-based learning, sharing and presentations of the learners group experiences. Arriving from this tradition, we focus on a slightly different scenarios: employing the robotics sets and the named approaches when learning Physics, Mathematics, Art, Science, and other subjects. In carefully designed projects, learners build interactive models that demonstrate concepts, principles, and phenomena, perform experiments, and modify them in elaboration phases with the aim to connect, create associations and links to the actual underlying theoretical curriculum. In this way, they are collecting practical experiences which are prerequisite to successful learning process. Based on feedback from children, we continue upon two previous sets of activities that focused on Physics and Mathematics, this time with projects built around games. Learners play various games with physical artifacts in the real-world - with the models they build. They acquire skills while playing the games, analyze them, and learn about the underlying principles. They modify the game rules, strategies, create extensions, and interact with each other in an entertaining and engaging settings. This time we have designed the activities together with the children, students of applied robotics seminar, and a student of Applied Informatics.
* This work was co-funded by the Horizon-Widera-2021 European Twinning project TERAIS G.A. n. 101079338 Open Access Data discussed in the article is available at https://robotika.sk/spike
Revisiting VAE for Unsupervised Time Series Anomaly Detection: A Frequency Perspective
Feb 05, 2024Time series Anomaly Detection (AD) plays a crucial role for web systems. Various web systems rely on time series data to monitor and identify anomalies in real time, as well as to initiate diagnosis and remediation procedures. Variational Autoencoders (VAEs) have gained popularity in recent decades due to their superior de-noising capabilities, which are useful for anomaly detection. However, our study reveals that VAE-based methods face challenges in capturing long-periodic heterogeneous patterns and detailed short-periodic trends simultaneously. To address these challenges, we propose Frequency-enhanced Conditional Variational Autoencoder (FCVAE), a novel unsupervised AD method for univariate time series. To ensure an accurate AD, FCVAE exploits an innovative approach to concurrently integrate both the global and local frequency features into the condition of Conditional Variational Autoencoder (CVAE) to significantly increase the accuracy of reconstructing the normal data. Together with a carefully designed "target attention" mechanism, our approach allows the model to pick the most useful information from the frequency domain for better short-periodic trend construction. Our FCVAE has been evaluated on public datasets and a large-scale cloud system, and the results demonstrate that it outperforms state-of-the-art methods. This confirms the practical applicability of our approach in addressing the limitations of current VAE-based anomaly detection models.
SubGen: Token Generation in Sublinear Time and Memory
Feb 08, 2024Despite the significant success of large language models (LLMs), their extensive memory requirements pose challenges for deploying them in long-context token generation. The substantial memory footprint of LLM decoders arises from the necessity to store all previous tokens in the attention module, a requirement imposed by key-value (KV) caching. In this work, our focus is on developing an efficient compression technique for the KV cache. Empirical evidence indicates a significant clustering tendency within key embeddings in the attention module. Building on this key insight, we have devised a novel caching method with sublinear complexity, employing online clustering on key tokens and online $\ell_2$ sampling on values. The result is a provably accurate and efficient attention decoding algorithm, termed SubGen. Not only does this algorithm ensure a sublinear memory footprint and sublinear time complexity, but we also establish a tight error bound for our approach. Empirical evaluations on long-context question-answering tasks demonstrate that SubGen significantly outperforms existing and state-of-the-art KV cache compression methods in terms of performance and efficiency.