 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Distortion-Corrected Image Reconstruction with Deep Learning on an MRI-Linac
May 23, 2022
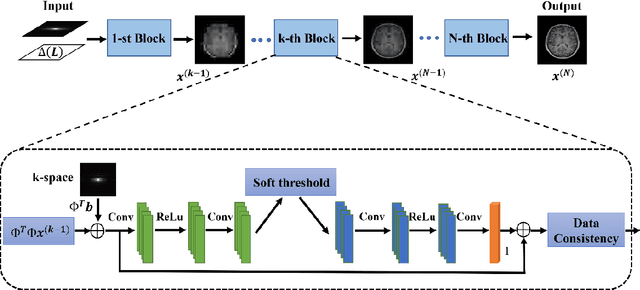

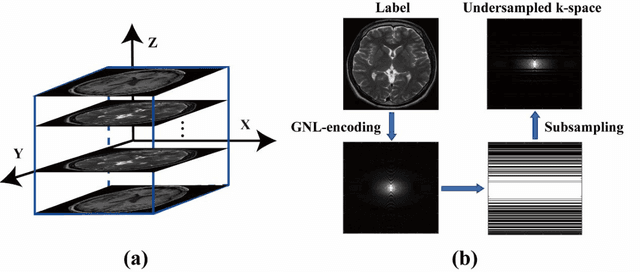
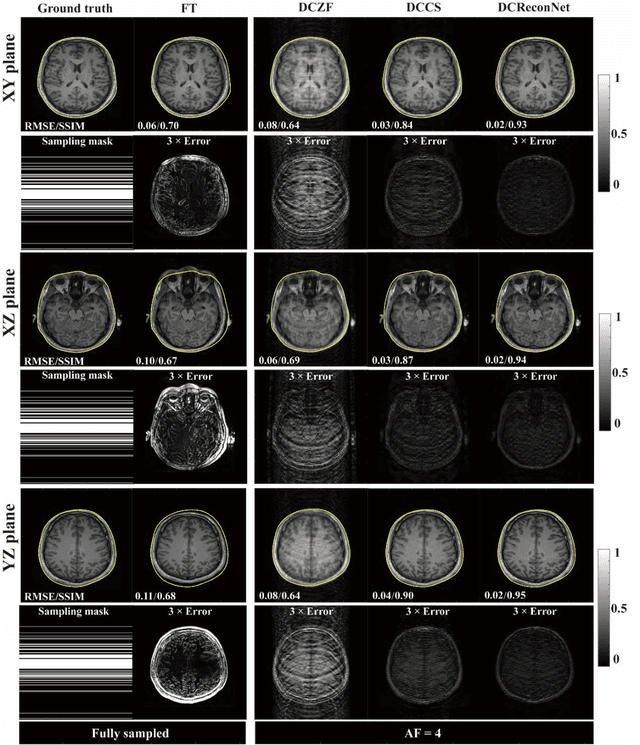
Magnetic resonance imaging (MRI) is increasingly utilized for image-guided radiotherapy due to its outstanding soft-tissue contrast and lack of ionizing radiation. However, geometric distortions caused by gradient nonlinearity (GNL) limit anatomical accuracy, potentially compromising the quality of tumour treatments. In addition, slow MR acquisition and reconstruction limit the potential for real-time image guidance. Here, we demonstrate a deep learning-based method that rapidly reconstructs distortion-corrected images from raw k-space data for real-time MR-guided radiotherapy applications. We leverage recent advances in interpretable unrolling networks to develop a Distortion-Corrected Reconstruction Network (DCReconNet) that applies convolutional neural networks (CNNs) to learn effective regularizations and nonuniform fast Fourier transforms for GNL-encoding. DCReconNet was trained on a public MR brain dataset from eleven healthy volunteers for fully sampled and accelerated techniques including parallel imaging (PI) and compressed sensing (CS). The performance of DCReconNet was tested on phantom and volunteer brain data acquired on a 1.0T MRI-Linac. The DCReconNet, CS- and PI-based reconstructed image quality was measured by structural similarity (SSIM) and root-mean-squared error (RMSE) for numerical comparisons. The computation time for each method was also reported. Phantom and volunteer results demonstrated that DCReconNet better preserves image structure when compared to CS- and PI-based reconstruction methods. DCReconNet resulted in highest SSIM (0.95 median value) and lowest RMSE (<0.04) on simulated brain images with four times acceleration. DCReconNet is over 100-times faster than iterative, regularized reconstruction methods. DCReconNet provides fast and geometrically accurate image reconstruction and has potential for real-time MRI-guided radiotherapy applications.
Unsupervised Deep Anomaly Detection for Multi-Sensor Time-Series Signals
Jul 27, 2021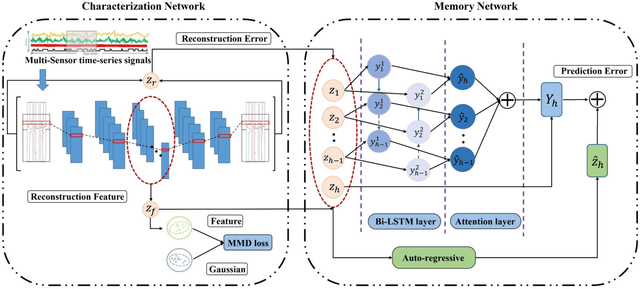

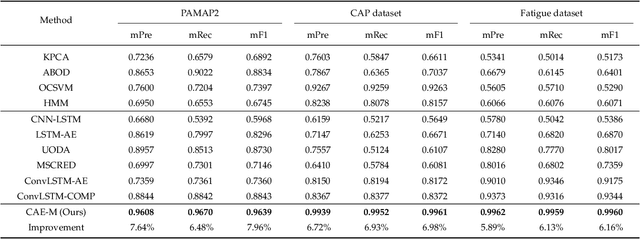
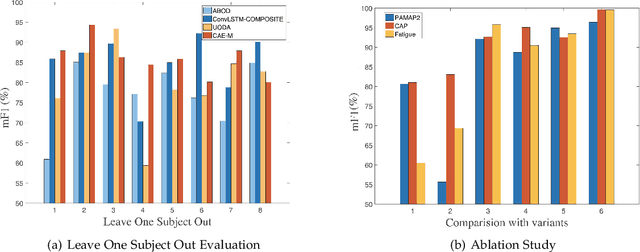
Nowadays, multi-sensor technologies are applied in many fields, e.g., Health Care (HC), Human Activity Recognition (HAR), and Industrial Control System (ICS). These sensors can generate a substantial amount of multivariate time-series data. Unsupervised anomaly detection on multi-sensor time-series data has been proven critical in machine learning researches. The key challenge is to discover generalized normal patterns by capturing spatial-temporal correlation in multi-sensor data. Beyond this challenge, the noisy data is often intertwined with the training data, which is likely to mislead the model by making it hard to distinguish between the normal, abnormal, and noisy data. Few of previous researches can jointly address these two challenges. In this paper, we propose a novel deep learning-based anomaly detection algorithm called Deep Convolutional Autoencoding Memory network (CAE-M). We first build a Deep Convolutional Autoencoder to characterize spatial dependence of multi-sensor data with a Maximum Mean Discrepancy (MMD) to better distinguish between the noisy, normal, and abnormal data. Then, we construct a Memory Network consisting of linear (Autoregressive Model) and non-linear predictions (Bidirectional LSTM with Attention) to capture temporal dependence from time-series data. Finally, CAE-M jointly optimizes these two subnetworks. We empirically compare the proposed approach with several state-of-the-art anomaly detection methods on HAR and HC datasets. Experimental results demonstrate that our proposed model outperforms these existing methods.
STT: Soft Template Tuning for Few-Shot Adaptation
Jul 18, 2022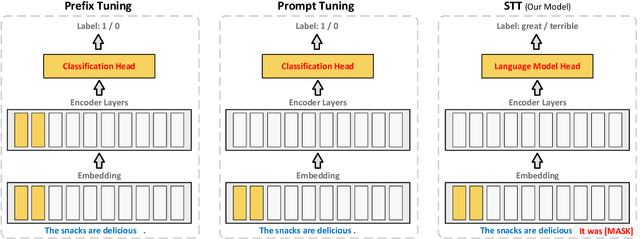
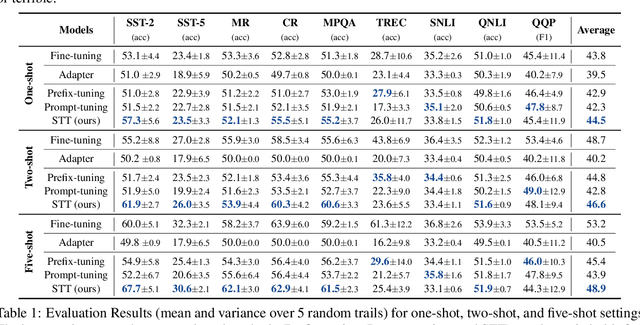
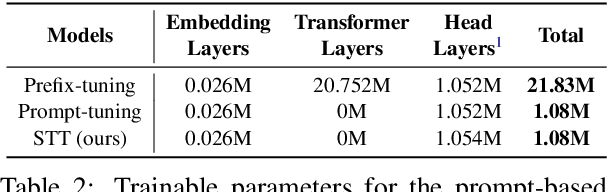
Prompt tuning has been an extremely effective tool to adapt a pre-trained model to downstream tasks. However, standard prompt-based methods mainly consider the case of sufficient data of downstream tasks. It is still unclear whether the advantage can be transferred to the few-shot regime, where only limited data are available for each downstream task. Although some works have demonstrated the potential of prompt-tuning under the few-shot setting, the main stream methods via searching discrete prompts or tuning soft prompts with limited data are still very challenging. Through extensive empirical studies, we find that there is still a gap between prompt tuning and fully fine-tuning for few-shot learning. To bridge the gap, we propose a new prompt-tuning framework, called Soft Template Tuning (STT). STT combines manual and auto prompts, and treats downstream classification tasks as a masked language modeling task. Comprehensive evaluation on different settings suggests STT can close the gap between fine-tuning and prompt-based methods without introducing additional parameters. Significantly, it can even outperform the time- and resource-consuming fine-tuning method on sentiment classification tasks.
Moving Stuff Around: A study on efficiency of moving documents into memory for Neural IR models
May 17, 2022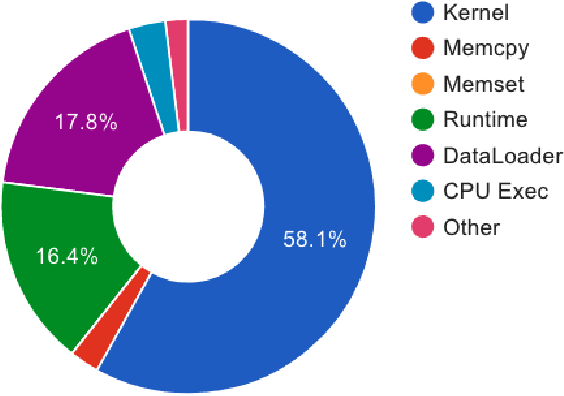



When training neural rankers using Large Language Models, it's expected that a practitioner would make use of multiple GPUs to accelerate the training time. By using more devices, deep learning frameworks, like PyTorch, allow the user to drastically increase the available VRAM pool, making larger batches possible when training, therefore shrinking training time. At the same time, one of the most critical processes, that is generally overlooked when running data-hungry models, is how data is managed between disk, main memory and VRAM. Most open source research implementations overlook this memory hierarchy, and instead resort to loading all documents from disk to main memory and then allowing the framework (e.g., PyTorch) to handle moving data into VRAM. Therefore, with the increasing sizes of datasets dedicated to IR research, a natural question arises: s this the optimal solution for optimizing training time? We here study how three different popular approaches to handling documents for IR datasets behave and how they scale with multiple GPUs. Namely, loading documents directly into memory, reading documents directly from text files with a lookup table and using a library for handling IR datasets (ir_datasets) differ, both in performance (i.e. samples processed per second) and memory footprint. We show that, when using the most popular libraries for neural ranker research (i.e. PyTorch and Hugging Face's Transformers), the practice of loading all documents into main memory is not always the fastest option and is not feasible for setups with more than a couple GPUs. Meanwhile, a good implementation of data streaming from disk can be faster, while being considerably more scalable. We also show how popular techniques for improving loading times, like memory pining, multiple workers, and RAMDISK usage, can reduce the training time further with minor memory overhead.
ARShoe: Real-Time Augmented Reality Shoe Try-on System on Smartphones
Aug 24, 2021
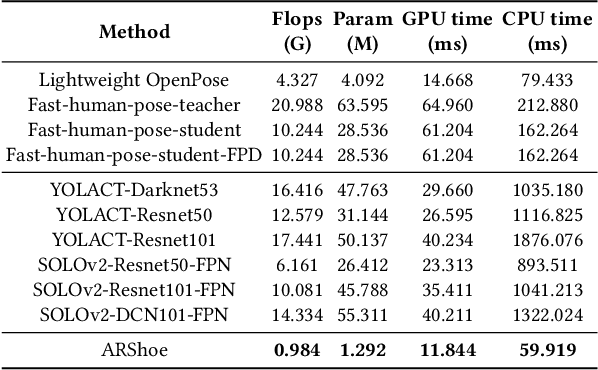
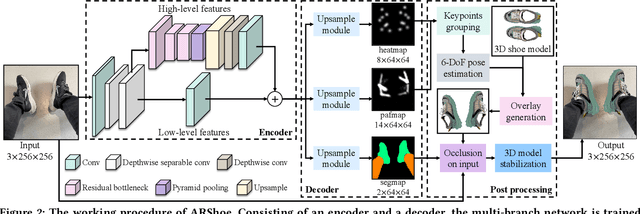
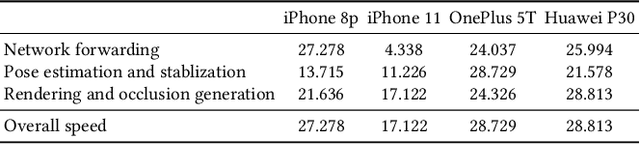
Virtual try-on technology enables users to try various fashion items using augmented reality and provides a convenient online shopping experience. However, most previous works focus on the virtual try-on for clothes while neglecting that for shoes, which is also a promising task. To this concern, this work proposes a real-time augmented reality virtual shoe try-on system for smartphones, namely ARShoe. Specifically, ARShoe adopts a novel multi-branch network to realize pose estimation and segmentation simultaneously. A solution to generate realistic 3D shoe model occlusion during the try-on process is presented. To achieve a smooth and stable try-on effect, this work further develop a novel stabilization method. Moreover, for training and evaluation, we construct the very first large-scale foot benchmark with multiple virtual shoe try-on task-related labels annotated. Exhaustive experiments on our newly constructed benchmark demonstrate the satisfying performance of ARShoe. Practical tests on common smartphones validate the real-time performance and stabilization of the proposed approach.
On-Demand Redundancy Grouping: Selectable Soft-Error Tolerance for a Multicore Cluster
May 25, 2022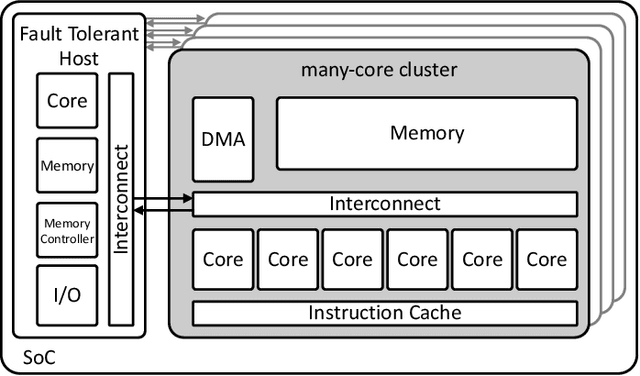
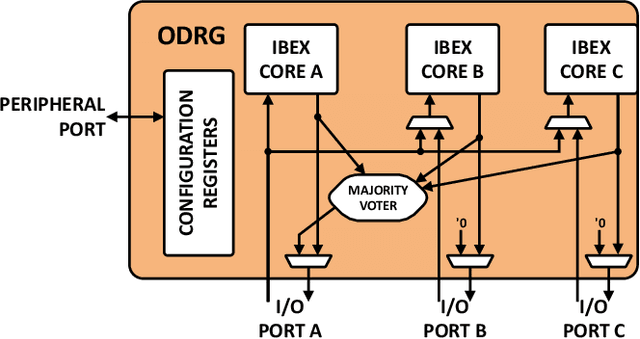
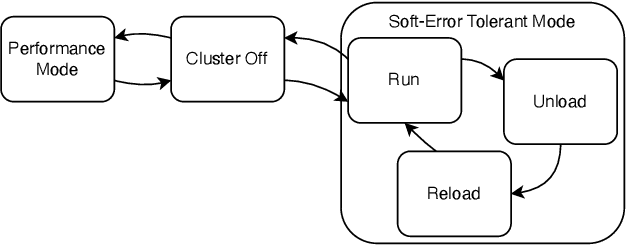
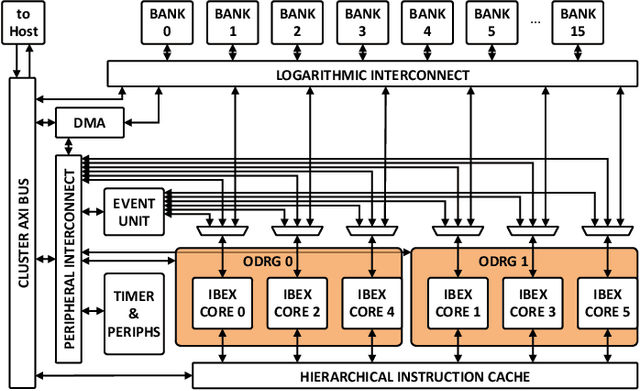
With the shrinking of technology nodes and the use of parallel processor clusters in hostile and critical environments, such as space, run-time faults caused by radiation are a serious cross-cutting concern, also impacting architectural design. This paper introduces an architectural approach to run-time configurable soft-error tolerance at the core level, augmenting a six-core open-source RISC-V cluster with a novel On-Demand Redundancy Grouping (ODRG) scheme. ODRG allows the cluster to operate either as two fault-tolerant cores, or six individual cores for high-performance, with limited overhead to switch between these modes during run-time. The ODRG unit adds less than 11% of a core's area for a three-core group, or a total of 1% of the cluster area, and shows negligible timing increase, which compares favorably to a commercial state-of-the-art implementation, and is 2.5$\times$ faster in fault recovery re-synchronization. Furthermore, unlike other implementations, when redundancy is not necessary, the ODRG approach allows the redundant cores to be used for independent computation, allowing up to 2.96$\times$ increase in performance for selected applications.
Comprehensive Reactive Safety: No Need For A Trajectory If You Have A Strategy
Jul 11, 2022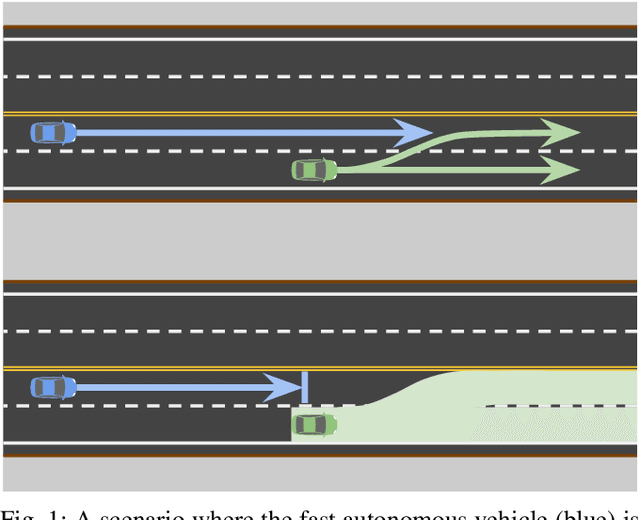
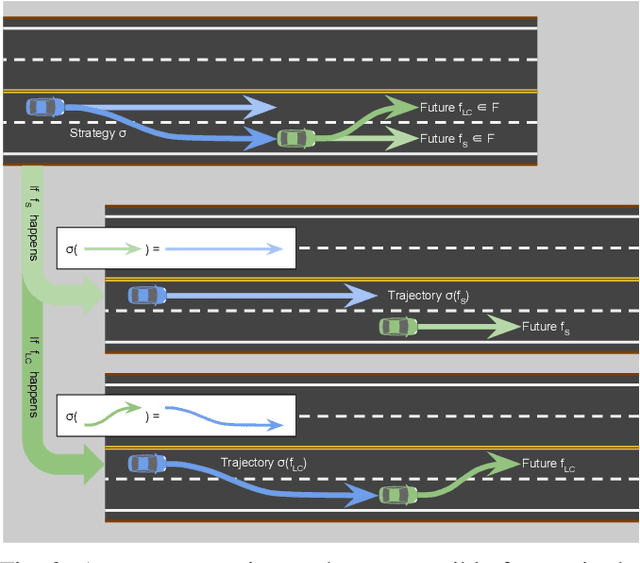
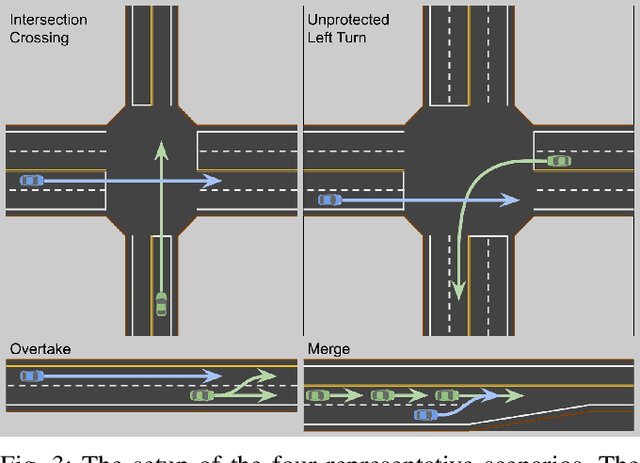

Safety guarantees in motion planning for autonomous driving typically involve certifying the trajectory to be collision-free under any motion of the uncontrollable participants in the environment, such as the human-driven vehicles on the road. As a result they usually employ a conservative bound on the behavior of such participants, such as reachability analysis. We point out that planning trajectories to rigorously avoid the entirety of the reachable regions is unnecessary and too restrictive, because observing the environment in the future will allow us to prune away most of them; disregarding this ability to react to future updates could prohibit solutions to scenarios that are easily navigated by human drivers. We propose to account for the autonomous vehicle's reactions to future environment changes by a novel safety framework, Comprehensive Reactive Safety. Validated in simulations in several urban driving scenarios such as unprotected left turns and lane merging, the resulting planning algorithm called Reactive ILQR demonstrates strong negotiation capabilities and better safety at the same time.
Infant movement classification through pressure distribution analysis -- added value for research and clinical implementation
Jul 26, 2022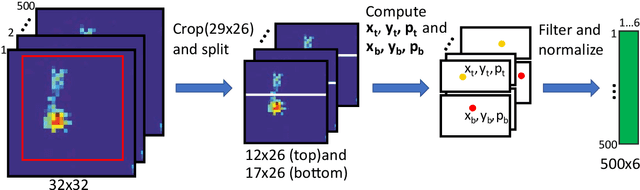
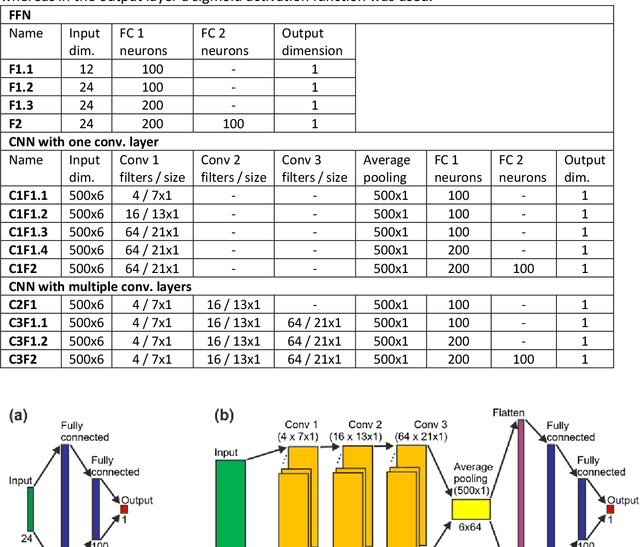
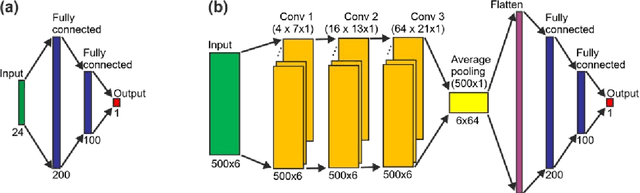
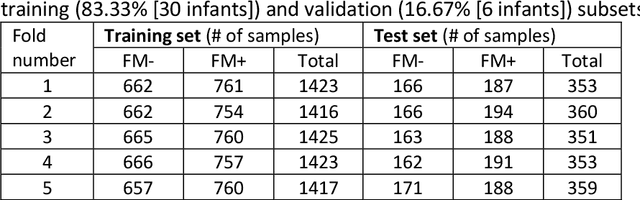
In recent years, numerous automated approaches complementing the human Prechtl's general movements assessment (GMA) were developed. Most approaches utilised RGB or RGB-D cameras to obtain motion data, while a few employed accelerometers or inertial measurement units. In this paper, within a prospective longitudinal infant cohort study applying a multimodal approach for movement tracking and analyses, we examined for the first time the performance of pressure sensors for classifying an infant general movements pattern, the fidgety movements. We developed an algorithm to encode movements with pressure data from a 32x32 grid mat with 1024 sensors. Multiple neural network architectures were investigated to distinguish presence vs. absence of the fidgety movements, including the feed-forward networks (FFNs) with manually defined statistical features and the convolutional neural networks (CNNs) with learned features. The CNN with multiple convolutional layers and learned features outperformed the FFN with manually defined statistical features, with classification accuracy of $81.4\%$ and $75.6\%$, respectively. We compared the pros and cons of the pressure sensing approach to the video-based and inertial motion senor-based approaches for analysing infant movements. The non-intrusive, extremely easy-to-use pressure sensing approach has great potential for efficient large-scaled movement data acquisition across cites and for application in busy daily clinical routines for evaluating infant neuromotor functions. The pressure sensors can be combined with other sensor modalities to enhance infant movement analyses in research and practice, as proposed in our multimodal sensor fusion model.
Dynamic Complementarity Conditions and Whole-Body Trajectory Optimization for Humanoid Robot Locomotion
Jul 07, 2022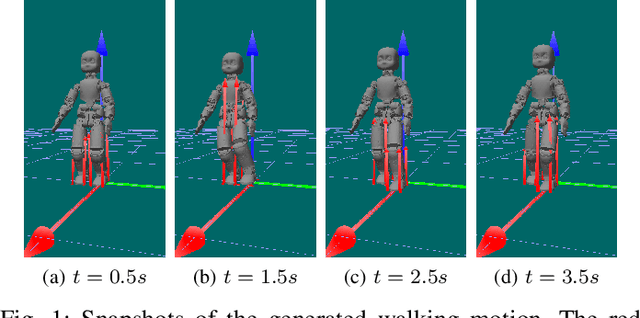
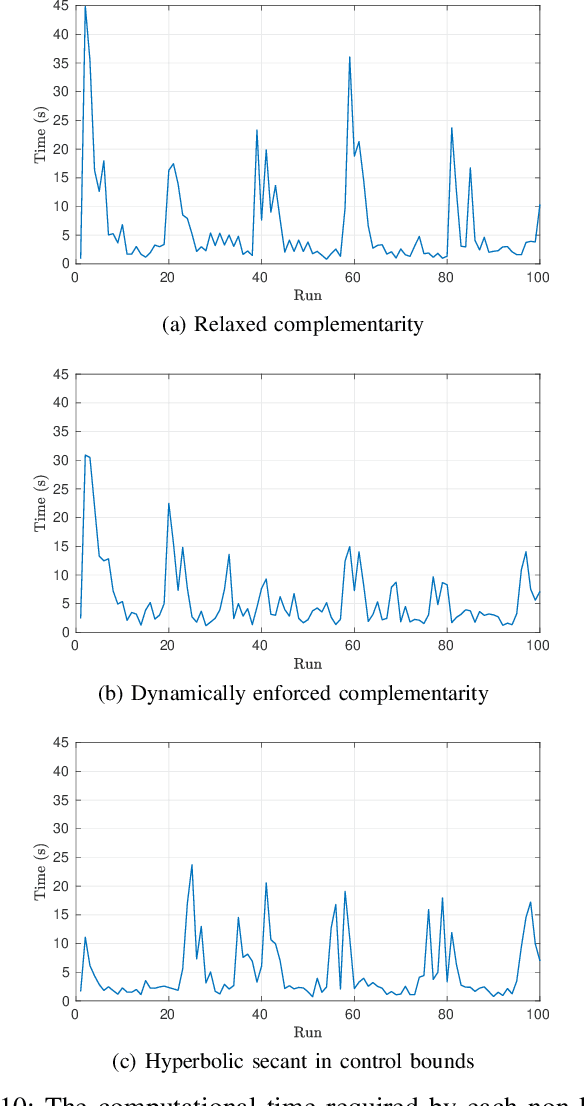
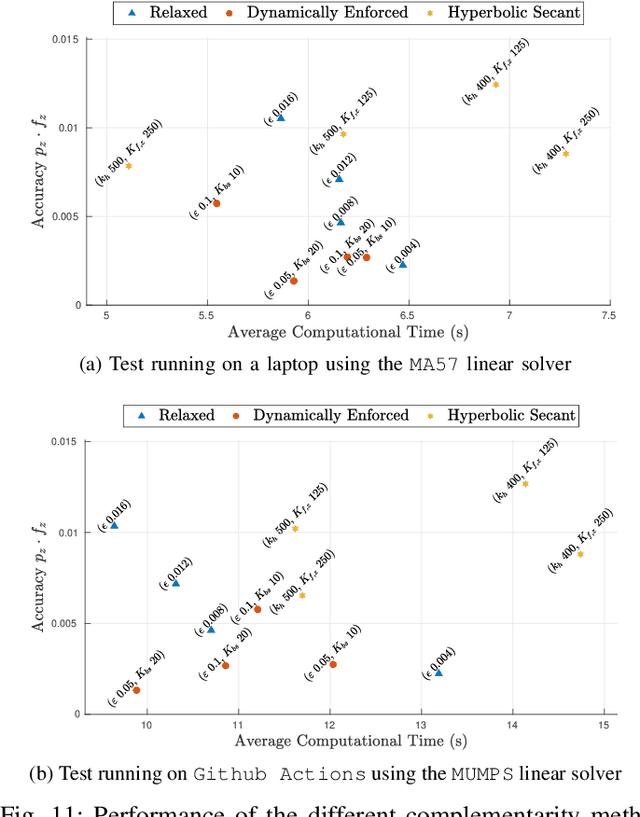
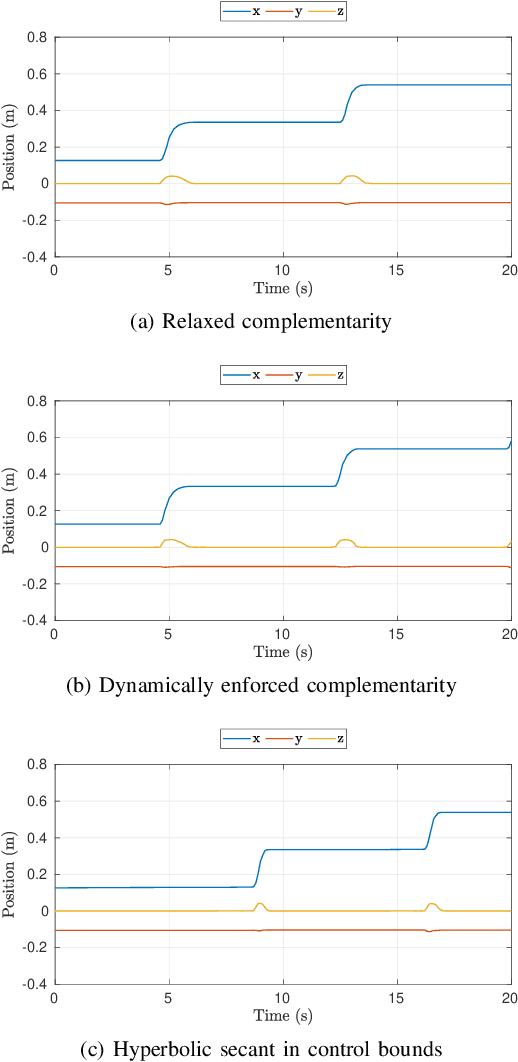
The paper presents a planner to generate walking trajectories by using the centroidal dynamics and the full kinematics of a humanoid robot. The interaction between the robot and the walking surface is modeled explicitly via new conditions, the \emph{Dynamical Complementarity Constraints}. The approach does not require a predefined contact sequence and generates the footsteps automatically. We characterize the robot control objective via a set of tasks, and we address it by solving an optimal control problem. We show that it is possible to achieve walking motions automatically by specifying a minimal set of references, such as a constant desired center of mass velocity and a reference point on the ground. Furthermore, we analyze how the contact modelling choices affect the computational time. We validate the approach by generating and testing walking trajectories for the humanoid robot iCub.
Solving Learn-to-Race Autonomous Racing Challenge by Planning in Latent Space
Jul 05, 2022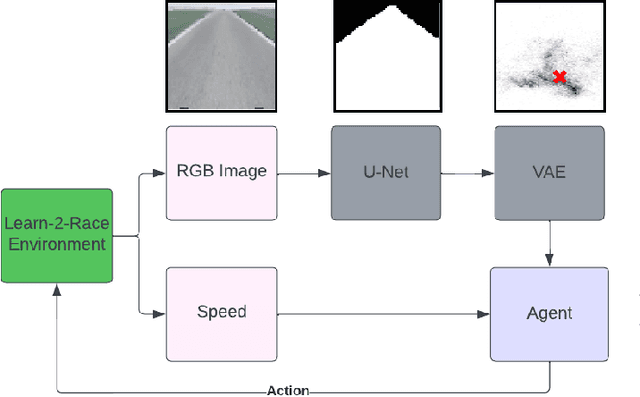
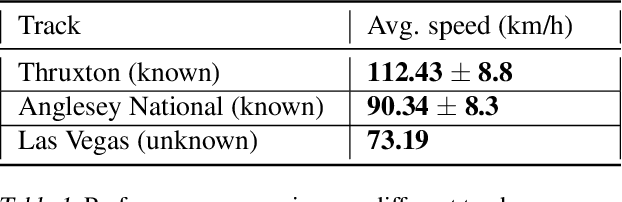

Learn-to-Race Autonomous Racing Virtual Challenge hosted on www<dot>aicrowd<dot>com platform consisted of two tracks: Single and Multi Camera. Our UniTeam team was among the final winners in the Single Camera track. The agent is required to pass the previously unknown F1-style track in the minimum time with the least amount of off-road driving violations. In our approach, we used the U-Net architecture for road segmentation, variational autocoder for encoding a road binary mask, and a nearest-neighbor search strategy that selects the best action for a given state. Our agent achieved an average speed of 105 km/h on stage 1 (known track) and 73 km/h on stage 2 (unknown track) without any off-road driving violations. Here we present our solution and results.