 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Interpretable Time-series Representation Learning With Multi-Level Disentanglement
May 17, 2021
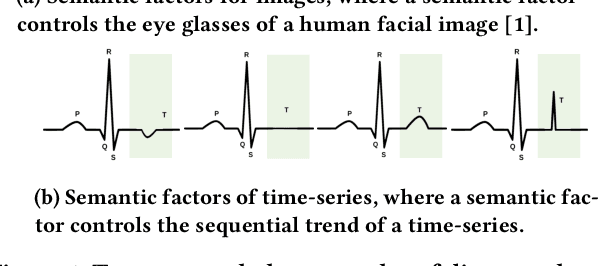
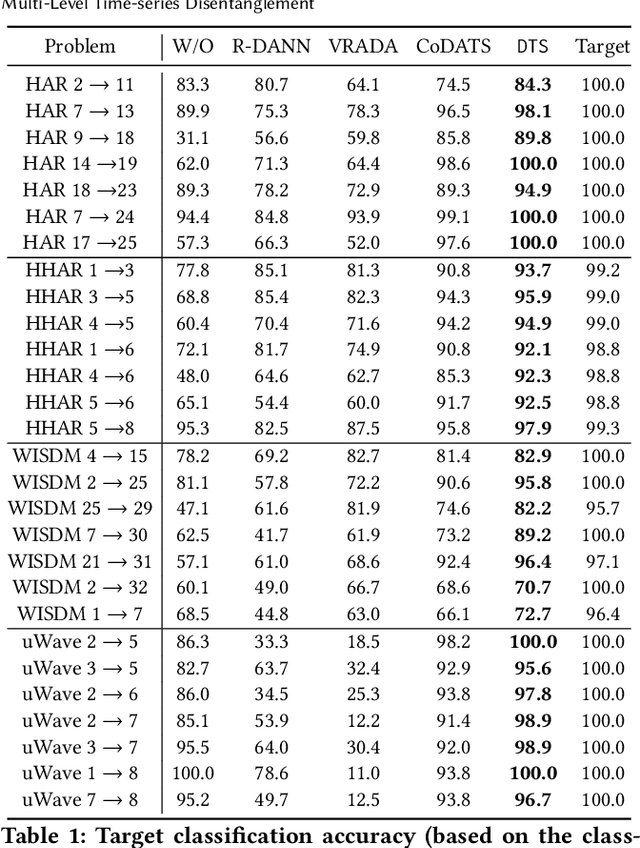
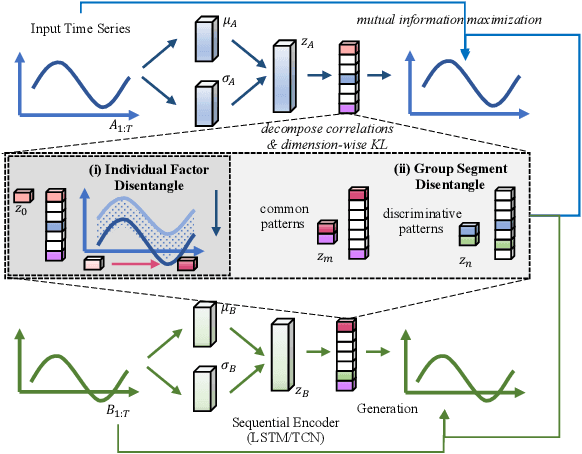
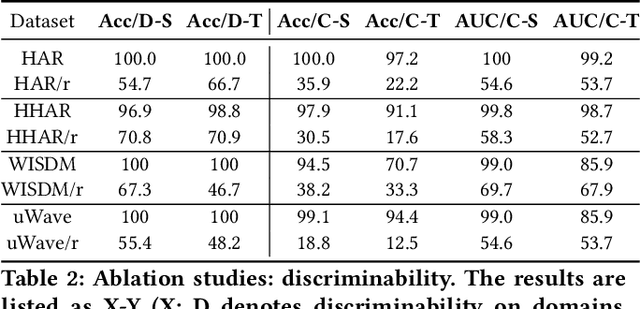
Time-series representation learning is a fundamental task for time-series analysis. While significant progress has been made to achieve accurate representations for downstream applications, the learned representations often lack interpretability and do not expose semantic meanings. Different from previous efforts on the entangled feature space, we aim to extract the semantic-rich temporal correlations in the latent interpretable factorized representation of the data. Motivated by the success of disentangled representation learning in computer vision, we study the possibility of learning semantic-rich time-series representations, which remains unexplored due to three main challenges: 1) sequential data structure introduces complex temporal correlations and makes the latent representations hard to interpret, 2) sequential models suffer from KL vanishing problem, and 3) interpretable semantic concepts for time-series often rely on multiple factors instead of individuals. To bridge the gap, we propose Disentangle Time Series (DTS), a novel disentanglement enhancement framework for sequential data. Specifically, to generate hierarchical semantic concepts as the interpretable and disentangled representation of time-series, DTS introduces multi-level disentanglement strategies by covering both individual latent factors and group semantic segments. We further theoretically show how to alleviate the KL vanishing problem: DTS introduces a mutual information maximization term, while preserving a heavier penalty on the total correlation and the dimension-wise KL to keep the disentanglement property. Experimental results on various real-world benchmark datasets demonstrate that the representations learned by DTS achieve superior performance in downstream applications, with high interpretability of semantic concepts.
ProSelfLC: Progressive Self Label Correction Towards A Low-Temperature Entropy State
Jun 30, 2022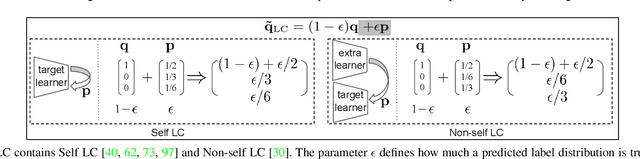

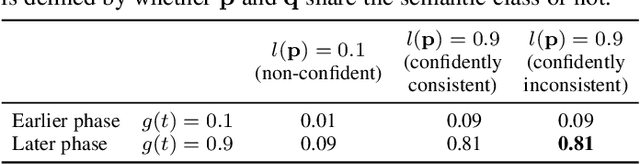
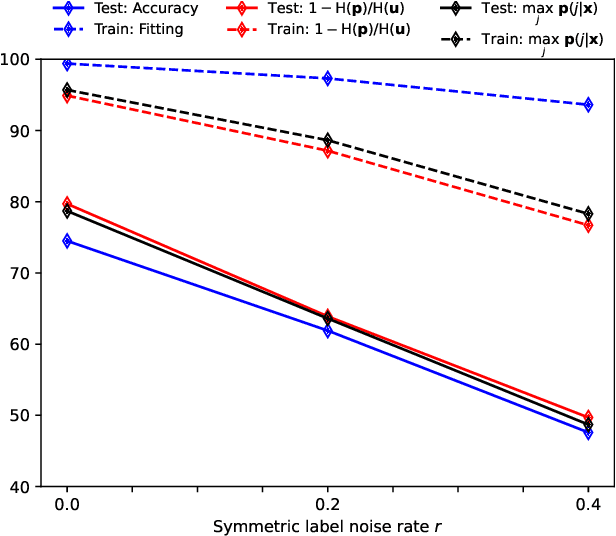
To train robust deep neural networks (DNNs), we systematically study several target modification approaches, which include output regularisation, self and non-self label correction (LC). Three key issues are discovered: (1) Self LC is the most appealing as it exploits its own knowledge and requires no extra models. However, how to automatically decide the trust degree of a learner as training goes is not well answered in the literature. (2) Some methods penalise while the others reward low-entropy predictions, prompting us to ask which one is better. (3) Using the standard training setting, a trained network is of low confidence when severe noise exists, making it hard to leverage its high-entropy self knowledge. To resolve the issue (1), taking two well-accepted propositions--deep neural networks learn meaningful patterns before fitting noise and minimum entropy regularisation principle--we propose a novel end-to-end method named ProSelfLC, which is designed according to learning time and entropy. Specifically, given a data point, we progressively increase trust in its predicted label distribution versus its annotated one if a model has been trained for enough time and the prediction is of low entropy (high confidence). For the issue (2), according to ProSelfLC, we empirically prove that it is better to redefine a meaningful low-entropy status and optimise the learner toward it. This serves as a defence of entropy minimisation. To address the issue (3), we decrease the entropy of self knowledge using a low temperature before exploiting it to correct labels, so that the revised labels redefine a low-entropy target state. We demonstrate the effectiveness of ProSelfLC through extensive experiments in both clean and noisy settings, and on both image and protein datasets. Furthermore, our source code is available at https://github.com/XinshaoAmosWang/ProSelfLC-AT.
Dynamic mean field programming
Jun 10, 2022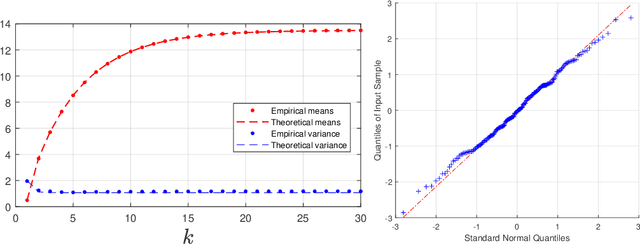
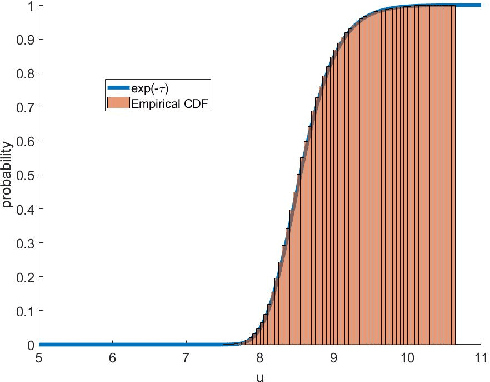
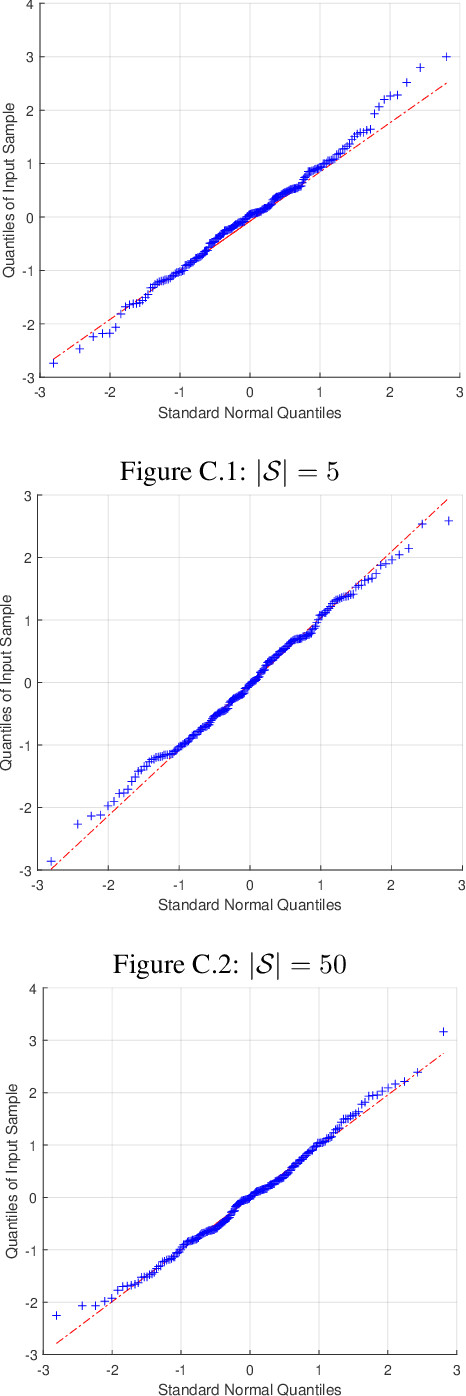
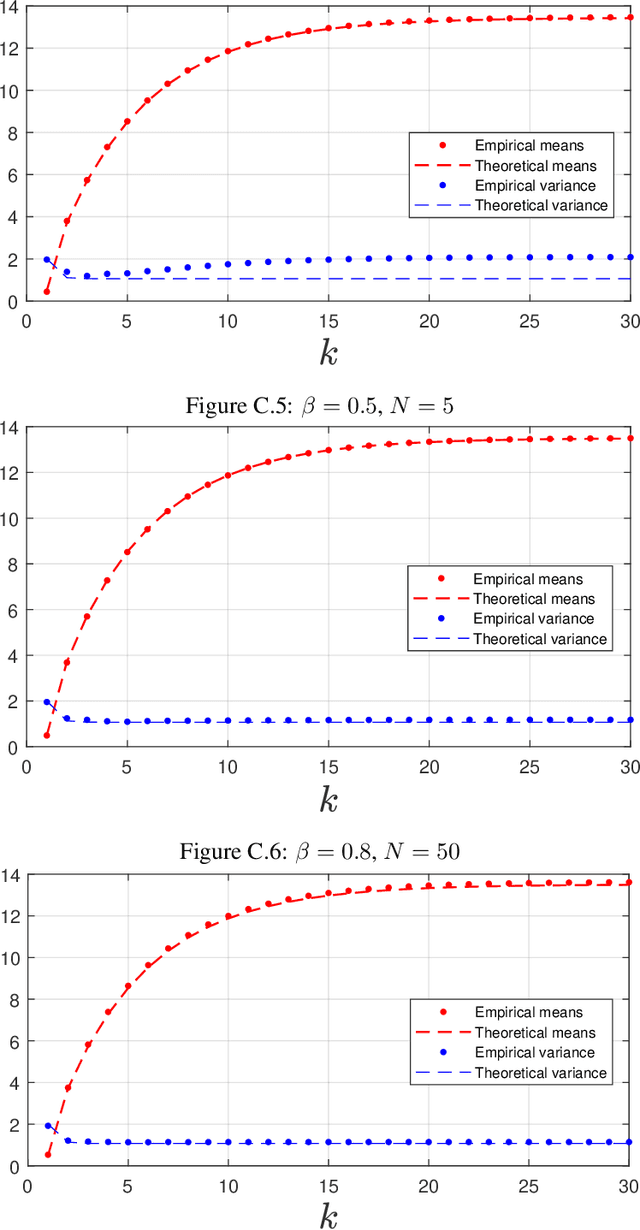
A dynamic mean field theory is developed for model based Bayesian reinforcement learning in the large state space limit. In an analogy with the statistical physics of disordered systems, the transition probabilities are interpreted as couplings, and value functions as deterministic spins, and thus the sampled transition probabilities are considered to be quenched random variables. The results reveal that, under standard assumptions, the posterior over Q-values is asymptotically independent and Gaussian across state-action pairs, for infinite horizon problems. The finite horizon case exhibits the same behaviour for all state-actions pairs at each time but has an additional correlation across time, for each state-action pair. The results also hold for policy evaluation. The Gaussian statistics can be computed from a set of coupled mean field equations derived from the Bellman equation, which we call dynamic mean field programming (DMFP). For Q-value iteration, approximate equations are obtained by appealing to extreme value theory, and closed form expressions are found in the independent and identically distributed case. The Lyapunov stability of these closed form equations is studied.
Context-sensitive neocortical neurons transform the effectiveness and efficiency of neural information processing
Jul 15, 2022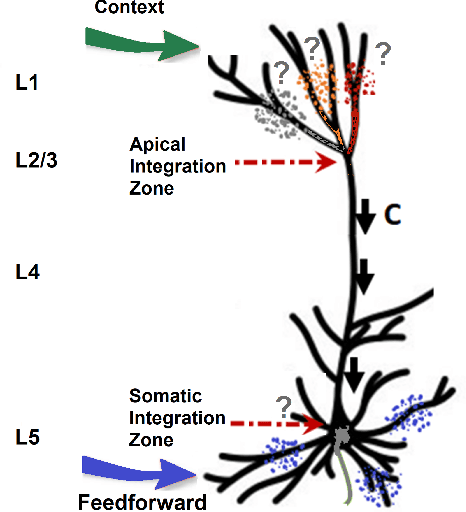
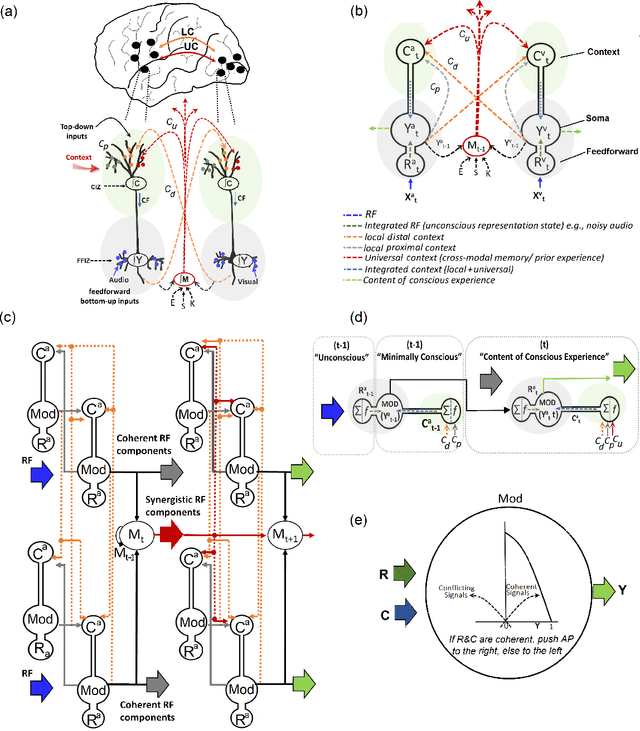
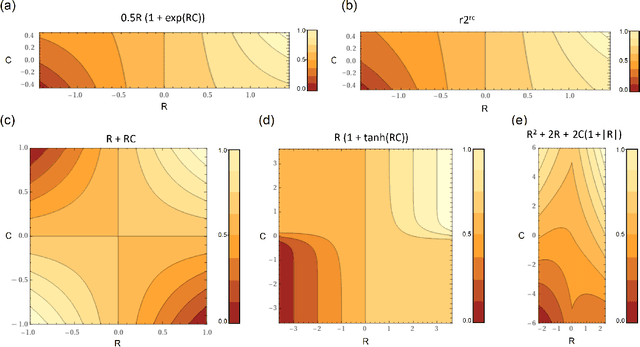
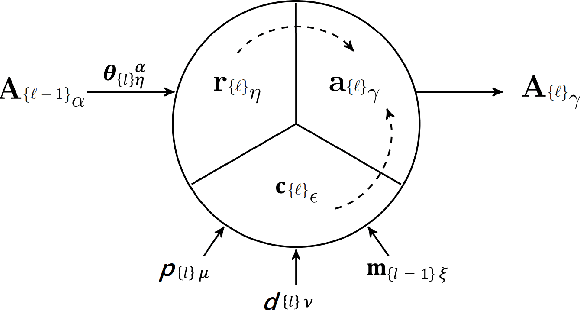
There is ample neurobiological evidence that context-sensitive neocortical neurons use their apical inputs as context to amplify the transmission of coherent feedforward (FF) inputs. However, it has not been demonstrated until now how this known mechanism can provide useful neural computation. Here we show for the first time that the processing and learning capabilities of this form of neural information processing are well-matched to the abilities of mammalian neocortex. Specifically, we show that a network composed of such local processors restricts the transmission of conflicting information to higher levels and greatly reduces the amount of activity required to process large amounts of heterogeneous real-world data e.g., when processing audiovisual speech, these local processors use seen lip movements to selectively amplify FF transmission of the auditory information that those movements generate and vice versa. As this mechanism is shown to be far more effective and efficient than the best available forms of deep neural nets, it offers a step-change in understanding the brain's mysterious energy-saving mechanism and inspires advances in designing enhanced forms of biologically plausible machine learning algorithms.
Semantic Novelty Detection via Relational Reasoning
Jul 18, 2022
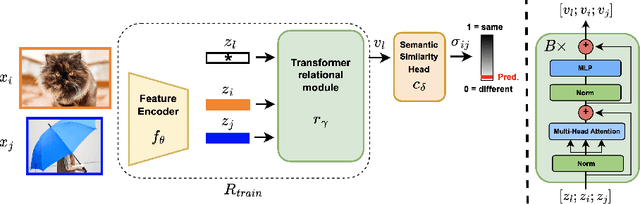
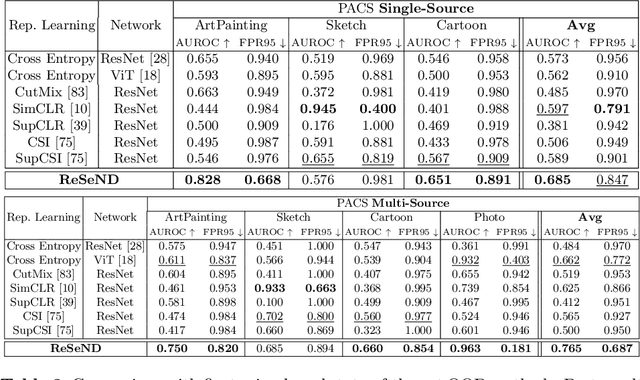
Semantic novelty detection aims at discovering unknown categories in the test data. This task is particularly relevant in safety-critical applications, such as autonomous driving or healthcare, where it is crucial to recognize unknown objects at deployment time and issue a warning to the user accordingly. Despite the impressive advancements of deep learning research, existing models still need a finetuning stage on the known categories in order to recognize the unknown ones. This could be prohibitive when privacy rules limit data access, or in case of strict memory and computational constraints (e.g. edge computing). We claim that a tailored representation learning strategy may be the right solution for effective and efficient semantic novelty detection. Besides extensively testing state-of-the-art approaches for this task, we propose a novel representation learning paradigm based on relational reasoning. It focuses on learning how to measure semantic similarity rather than recognizing known categories. Our experiments show that this knowledge is directly transferable to a wide range of scenarios, and it can be exploited as a plug-and-play module to convert closed-set recognition models into reliable open-set ones.
Recipe for Fast Large-scale SVM Training: Polishing, Parallelism, and more RAM!
Jul 03, 2022
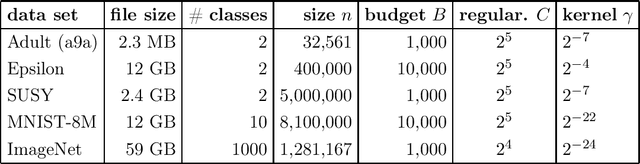
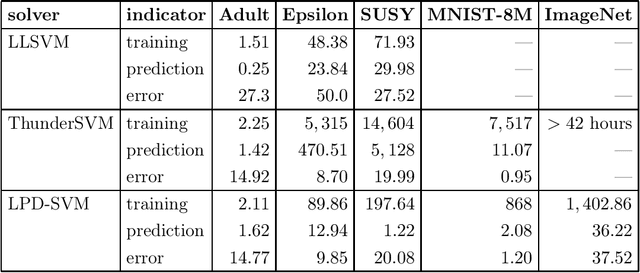
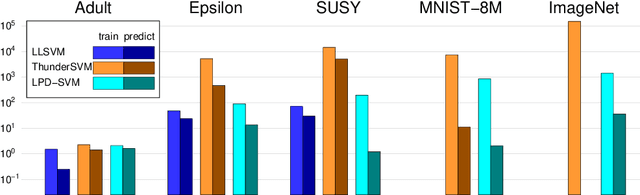
Support vector machines (SVMs) are a standard method in the machine learning toolbox, in particular for tabular data. Non-linear kernel SVMs often deliver highly accurate predictors, however, at the cost of long training times. That problem is aggravated by the exponential growth of data volumes over time. It was tackled in the past mainly by two types of techniques: approximate solvers, and parallel GPU implementations. In this work, we combine both approaches to design an extremely fast dual SVM solver. We fully exploit the capabilities of modern compute servers: many-core architectures, multiple high-end GPUs, and large random access memory. On such a machine, we train a large-margin classifier on the ImageNet data set in 24 minutes.
Distortion-Corrected Image Reconstruction with Deep Learning on an MRI-Linac
May 23, 2022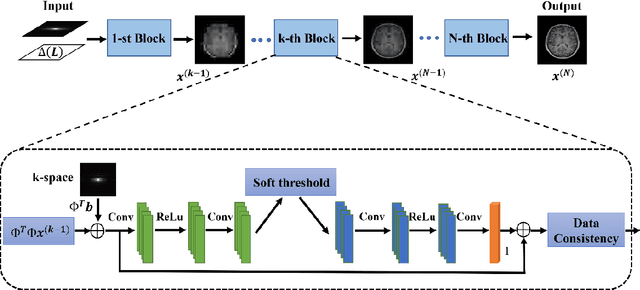

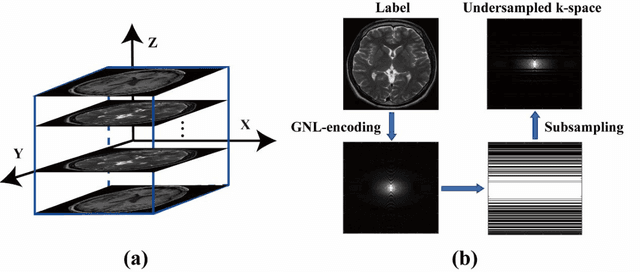
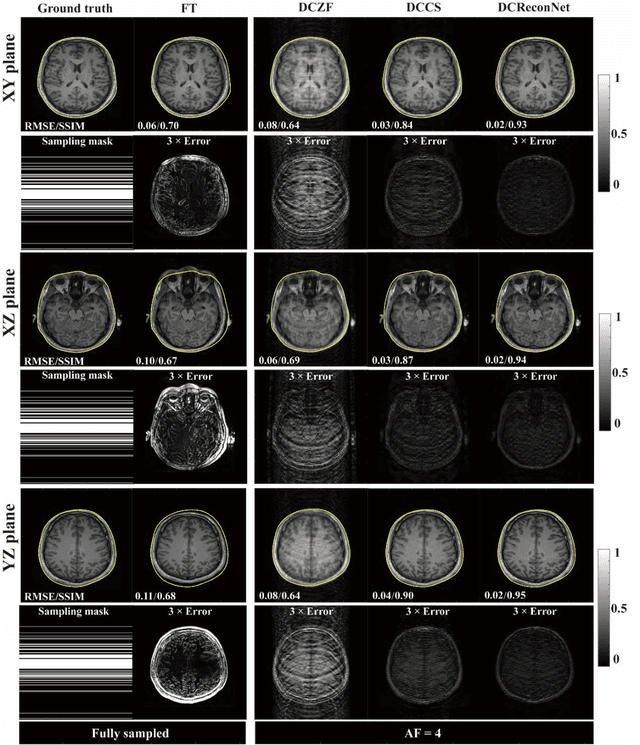
Magnetic resonance imaging (MRI) is increasingly utilized for image-guided radiotherapy due to its outstanding soft-tissue contrast and lack of ionizing radiation. However, geometric distortions caused by gradient nonlinearity (GNL) limit anatomical accuracy, potentially compromising the quality of tumour treatments. In addition, slow MR acquisition and reconstruction limit the potential for real-time image guidance. Here, we demonstrate a deep learning-based method that rapidly reconstructs distortion-corrected images from raw k-space data for real-time MR-guided radiotherapy applications. We leverage recent advances in interpretable unrolling networks to develop a Distortion-Corrected Reconstruction Network (DCReconNet) that applies convolutional neural networks (CNNs) to learn effective regularizations and nonuniform fast Fourier transforms for GNL-encoding. DCReconNet was trained on a public MR brain dataset from eleven healthy volunteers for fully sampled and accelerated techniques including parallel imaging (PI) and compressed sensing (CS). The performance of DCReconNet was tested on phantom and volunteer brain data acquired on a 1.0T MRI-Linac. The DCReconNet, CS- and PI-based reconstructed image quality was measured by structural similarity (SSIM) and root-mean-squared error (RMSE) for numerical comparisons. The computation time for each method was also reported. Phantom and volunteer results demonstrated that DCReconNet better preserves image structure when compared to CS- and PI-based reconstruction methods. DCReconNet resulted in highest SSIM (0.95 median value) and lowest RMSE (<0.04) on simulated brain images with four times acceleration. DCReconNet is over 100-times faster than iterative, regularized reconstruction methods. DCReconNet provides fast and geometrically accurate image reconstruction and has potential for real-time MRI-guided radiotherapy applications.
Lightweight Automated Feature Monitoring for Data Streams
Jul 18, 2022
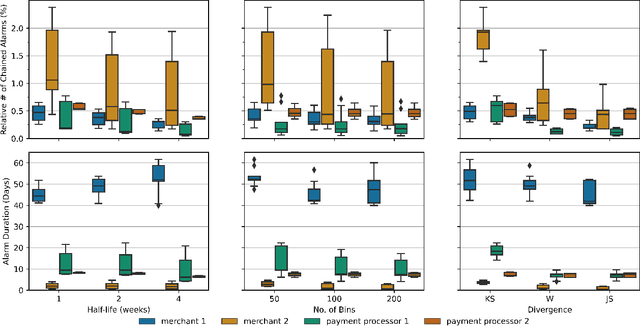
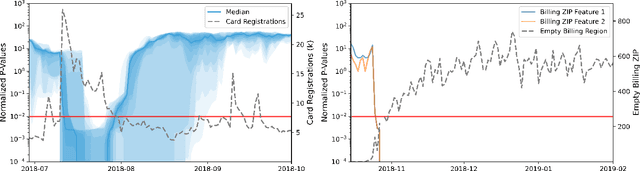
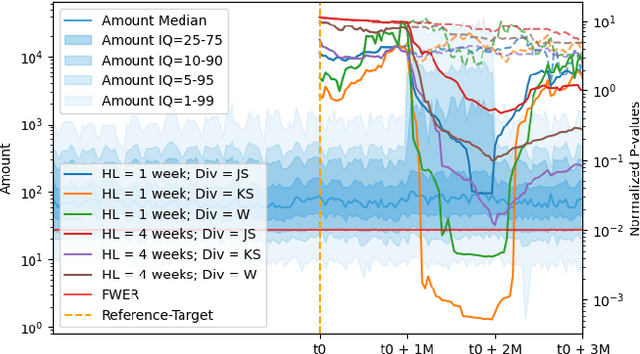
Monitoring the behavior of automated real-time stream processing systems has become one of the most relevant problems in real world applications. Such systems have grown in complexity relying heavily on high dimensional input data, and data hungry Machine Learning (ML) algorithms. We propose a flexible system, Feature Monitoring (FM), that detects data drifts in such data sets, with a small and constant memory footprint and a small computational cost in streaming applications. The method is based on a multi-variate statistical test and is data driven by design (full reference distributions are estimated from the data). It monitors all features that are used by the system, while providing an interpretable features ranking whenever an alarm occurs (to aid in root cause analysis). The computational and memory lightness of the system results from the use of Exponential Moving Histograms. In our experimental study, we analyze the system's behavior with its parameters and, more importantly, show examples where it detects problems that are not directly related to a single feature. This illustrates how FM eliminates the need to add custom signals to detect specific types of problems and that monitoring the available space of features is often enough.
Moving Stuff Around: A study on efficiency of moving documents into memory for Neural IR models
May 17, 2022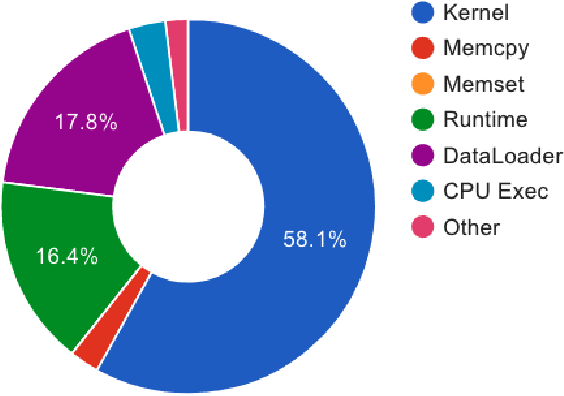



When training neural rankers using Large Language Models, it's expected that a practitioner would make use of multiple GPUs to accelerate the training time. By using more devices, deep learning frameworks, like PyTorch, allow the user to drastically increase the available VRAM pool, making larger batches possible when training, therefore shrinking training time. At the same time, one of the most critical processes, that is generally overlooked when running data-hungry models, is how data is managed between disk, main memory and VRAM. Most open source research implementations overlook this memory hierarchy, and instead resort to loading all documents from disk to main memory and then allowing the framework (e.g., PyTorch) to handle moving data into VRAM. Therefore, with the increasing sizes of datasets dedicated to IR research, a natural question arises: s this the optimal solution for optimizing training time? We here study how three different popular approaches to handling documents for IR datasets behave and how they scale with multiple GPUs. Namely, loading documents directly into memory, reading documents directly from text files with a lookup table and using a library for handling IR datasets (ir_datasets) differ, both in performance (i.e. samples processed per second) and memory footprint. We show that, when using the most popular libraries for neural ranker research (i.e. PyTorch and Hugging Face's Transformers), the practice of loading all documents into main memory is not always the fastest option and is not feasible for setups with more than a couple GPUs. Meanwhile, a good implementation of data streaming from disk can be faster, while being considerably more scalable. We also show how popular techniques for improving loading times, like memory pining, multiple workers, and RAMDISK usage, can reduce the training time further with minor memory overhead.
Compatible deep neural network framework with financial time series data, including data preprocessor, neural network model and trading strategy
May 11, 2022
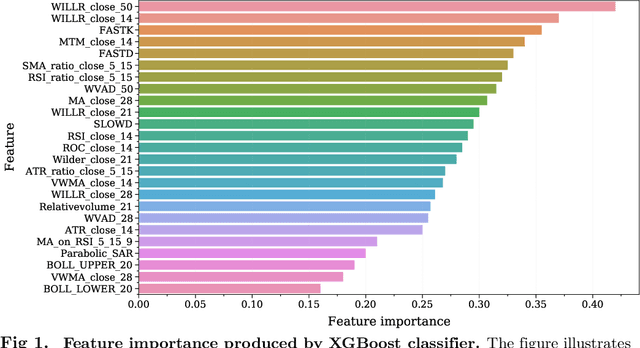
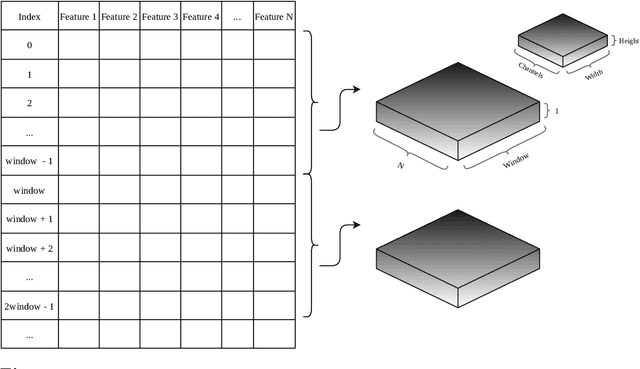
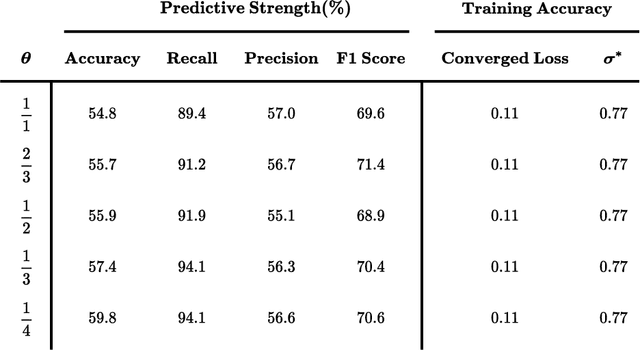
Experience has shown that trading in stock and cryptocurrency markets has the potential to be highly profitable. In this light, considerable effort has been recently devoted to investigate how to apply machine learning and deep learning to interpret and predict market behavior. This research introduces a new deep neural network architecture and a novel idea of how to prepare financial data before feeding them to the model. In the data preparation part, the first step is to generate many features using technical indicators and then apply the XGBoost model for feature engineering. Splitting data into three categories and using separate autoencoders, we extract high-level mixed features at the second step. This data preprocessing is introduced to predict price movements. Regarding modeling, different convolutional layers, an long short-term memory unit, and several fully-connected layers have been designed to perform binary classification. This research also introduces a trading strategy to exploit the trained model outputs. Three different datasets are used to evaluate this method, where results indicate that this framework can provide us with profitable and robust predictions.