 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Shrinking the Semantic Gap: Spatial Pooling of Local Moment Invariants for Copy-Move Forgery Detection
Jul 19, 2022
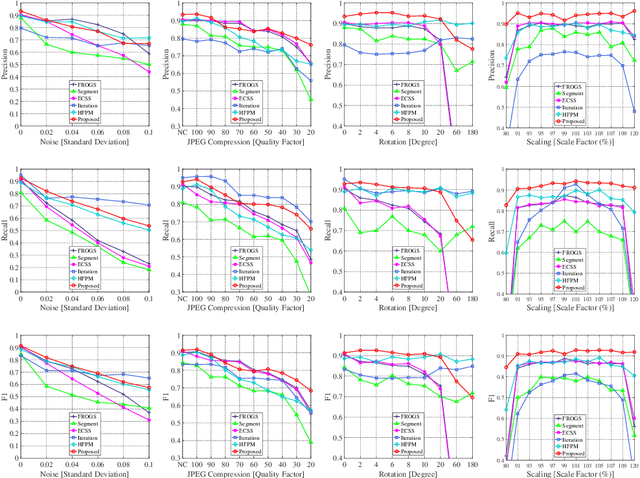
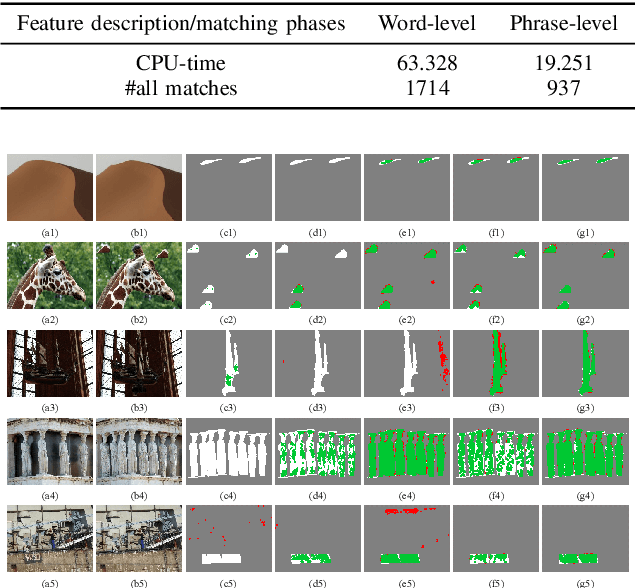

Copy-move forgery is a manipulation of copying and pasting specific patches from and to an image, with potentially illegal or unethical uses. Recent advances in the forensic methods for copy-move forgery have shown increasing success in detection accuracy and robustness. However, for images with high self-similarity or strong signal corruption, the existing algorithms often exhibit inefficient processes and unreliable results. This is mainly due to the inherent semantic gap between low-level visual representation and high-level semantic concept. In this paper, we present a very first study of trying to mitigate the semantic gap problem in copy-move forgery detection, with spatial pooling of local moment invariants for midlevel image representation. Our detection method expands the traditional works on two aspects: 1) we introduce the bag-of-visual-words model into this field for the first time, may meaning a new perspective of forensic study; 2) we propose a word-to-phrase feature description and matching pipeline, covering the spatial structure and visual saliency information of digital images. Extensive experimental results show the superior performance of our framework over state-of-the-art algorithms in overcoming the related problems caused by the semantic gap.
Networked Drones for Industrial Emergency Events
Aug 01, 2022
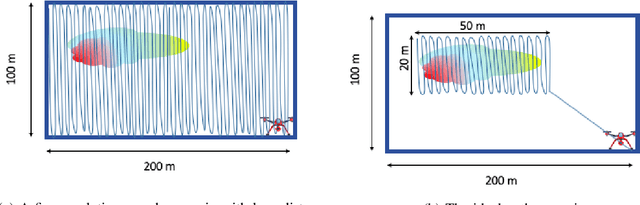
Uncontrolled emissions of gases from industrial accidents and disasters result in huge loss of life and property. Such extreme events require a quick and reliable survey of the site for effective rescue strategy planning. To achieve these goals, a network of unmanned aerial vehicles can be deployed that survey the affected region and identify safe and danger zones. Although single UAV-based systems for gas sensing applications are well-studied in literature, research on the deployment of a UAV network for such applications, which is more robust and fault tolerant, is still in infancy. The objective of this project is to design a system that can be deployed in emergency situations to provide a quick survey and identification of safe and dangerous zones in a given region that contains a toxic plume without making any assumptions about plume location. We focus on an end-to-end solution and formulate a two-phase strategy that can not only guarantee detection/acquisition of plume but also its characterization with high spatial resolution. To guarantee coverage of the region with a certain spatial resolution, we set up a vehicle routing problem. To overcome the limitations imposed by limited range of sensors and drone resources, we estimate the concentration map by using Gaussian kernel extrapolation. Finally, we evaluate the suggested framework in simulations. Our results suggest that this two-phase strategy not only gives better error performance but is also more efficient in terms of mission time. Moreover, the comparison between 2-phase random search and 2-phase uniform coverage suggest that the latter is better for single drone systems whereas for multiple drones the former gives reasonable performance at low computational cost.
Edge-Aided Sensor Data Sharing in Vehicular Communication Networks
Jun 17, 2022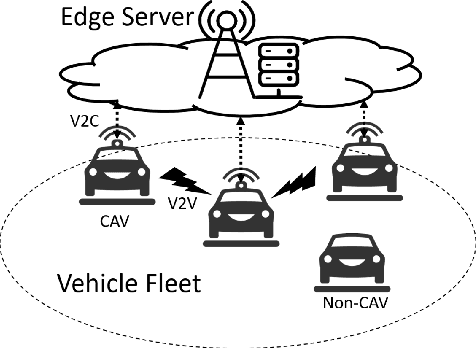
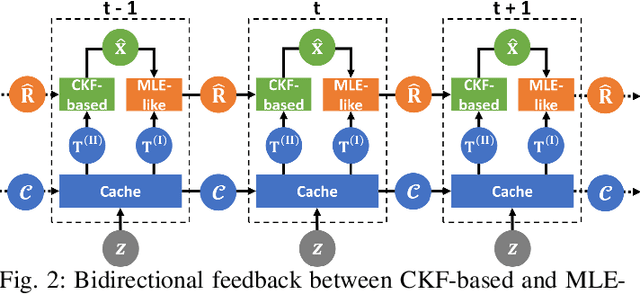
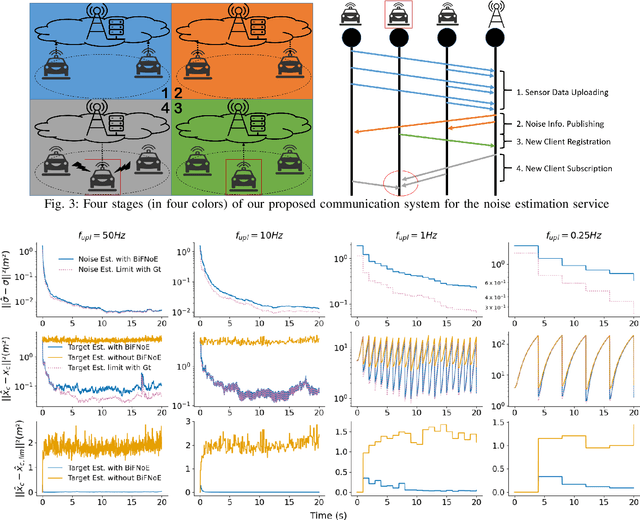
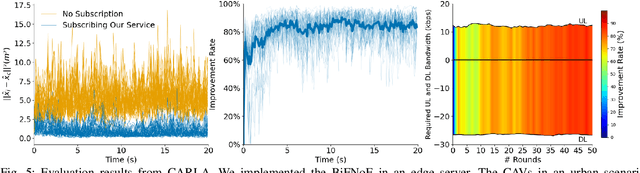
Sensor data sharing in vehicular networks can significantly improve the range and accuracy of environmental perception for connected automated vehicles. Different concepts and schemes for dissemination and fusion of sensor data have been developed. It is common to these schemes that measurement errors of the sensors impair the perception quality and can result in road traffic accidents. Specifically, when the measurement error from the sensors (also referred as measurement noise) is unknown and time varying, the performance of the data fusion process is restricted, which represents a major challenge in the calibration of sensors. In this paper, we consider sensor data sharing and fusion in a vehicular network with both, vehicle-to-infrastructure and vehicle-to-vehicle communication. We propose a method, named Bidirectional Feedback Noise Estimation (BiFNoE), in which an edge server collects and caches sensor measurement data from vehicles. The edge estimates the noise and the targets alternately in double dynamic sliding time windows and enhances the distributed cooperative environment sensing at each vehicle with low communication costs. We evaluate the proposed algorithm and data dissemination strategy in an application scenario by simulation and show that the perception accuracy is on average improved by around 80 % with only 12 kbps uplink and 28 kbps downlink bandwidth.
Convergence Theory of Generalized Distributed Subgradient Method with Random Quantization
Jul 22, 2022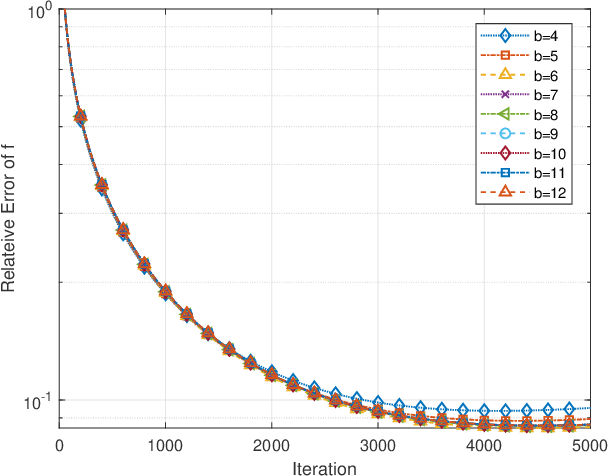
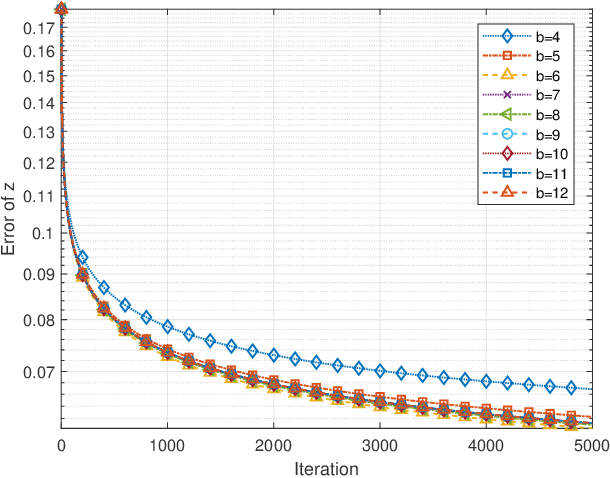
The distributed subgradient method (DSG) is a widely discussed algorithm to cope with large-scale distributed optimization problems in the arising machine learning applications. Most exisiting works on DSG focus on ideal communication between the cooperative agents such that the shared information between agents is exact and perfect. This assumption, however, could lead to potential privacy concerns and is not feasible when the wireless transmission links are not of good quality. To overcome the challenge, a common approach is to quantize the data locally before transmission, which avoids exposure of raw data and significantly reduces the size of data. Compared with perfect data, quantization poses fundamental challenges on loss of data accuracy, which further impacts the convergence of the algorithms. To settle the problem, we propose a generalized distributed subgradient method with random quantization, which can be intepreted as a two time-scale stochastic approximation method. We provide comprehensive results on the convergence of the algorithm and derive upper bounds on the convergence rates in terms of the quantization bit, stepsizes and the number of network agents. Our results extend the existing results, where only special cases are considered and general conclusions for the convergence rates are missing. Finally, numerical simulations are conducted on linear regression problems to support our theoretical results.
Spatio-temporal prediction in video coding by spatially refined motion compensation
Jul 08, 2022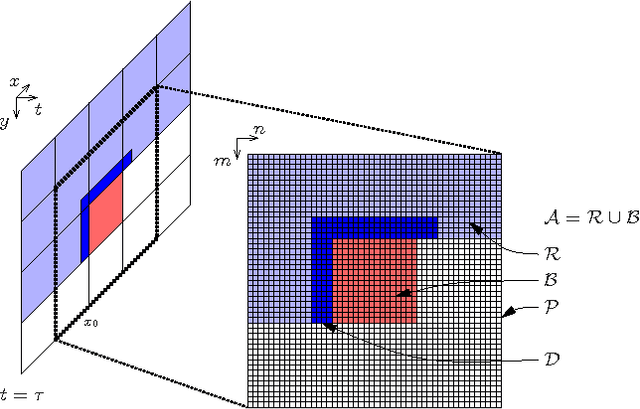
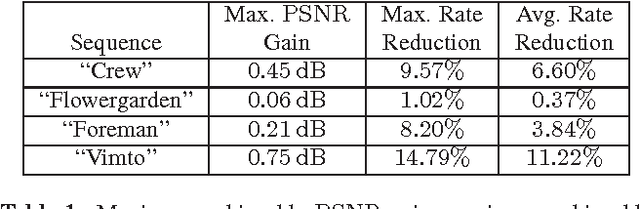
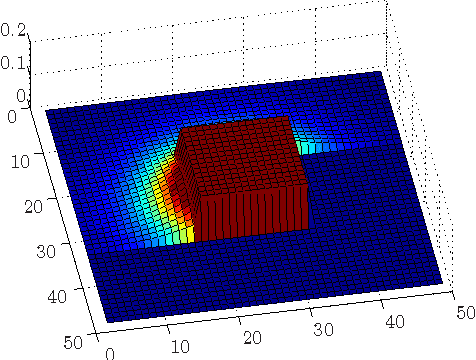
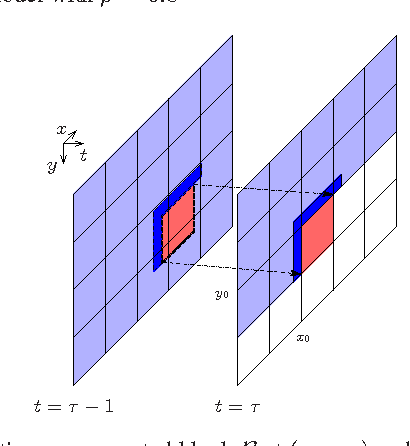
The purpose of this contribution is to introduce a new method of signal prediction in video coding. Unlike most existent prediction methods that either use temporal or use spatial correlations to generate the prediction signal, the proposed method uses spatial and temporal correlations at the same time. The spatio-temporal prediction is obtained by first performing motion compensation for a macroblock, followed by a refinement step that pays attention to the correlations between the macroblock and its surroundings. At the decoder, the refinement step can be performed in the same manner, thus no additional side information has to be transmitted. Implementation of the spatial refinement step into the H.264/AVC video codec leads to reduction in data rate of up to nearly 15% and increase in PSNR of up to 0.75 dB, compared to pure motion compensated prediction.
Segment-level Metric Learning for Few-shot Bioacoustic Event Detection
Jul 15, 2022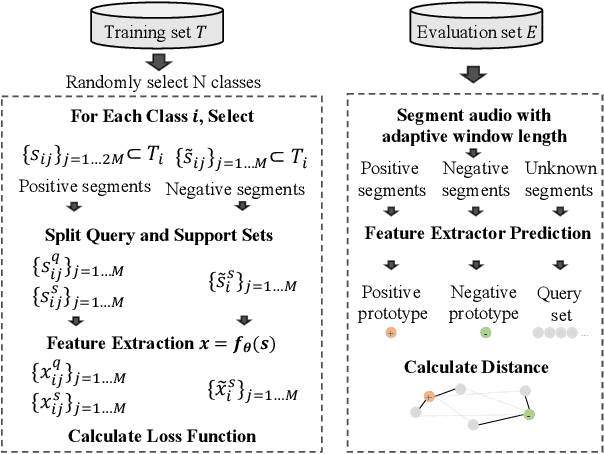
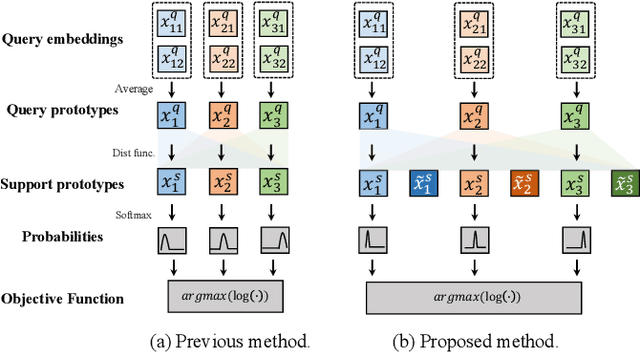
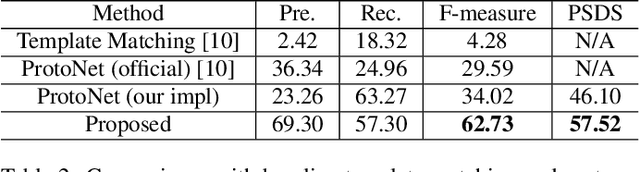
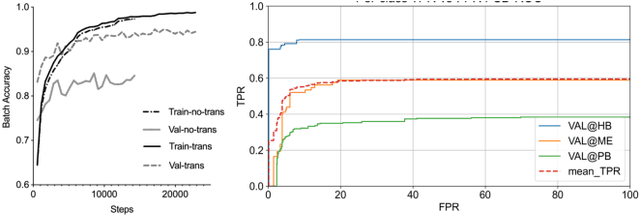
Few-shot bioacoustic event detection is a task that detects the occurrence time of a novel sound given a few examples. Previous methods employ metric learning to build a latent space with the labeled part of different sound classes, also known as positive events. In this study, we propose a segment-level few-shot learning framework that utilizes both the positive and negative events during model optimization. Training with negative events, which are larger in volume than positive events, can increase the generalization ability of the model. In addition, we use transductive inference on the validation set during training for better adaptation to novel classes. We conduct ablation studies on our proposed method with different setups on input features, training data, and hyper-parameters. Our final system achieves an F-measure of 62.73 on the DCASE 2022 challenge task 5 (DCASE2022-T5) validation set, outperforming the performance of the baseline prototypical network 34.02 by a large margin. Using the proposed method, our submitted system ranks 2nd in DCASE2022-T5. The code of this paper is fully open-sourced at https://github.com/haoheliu/DCASE_2022_Task_5.
Robot Trajectory Adaptation to Optimise the Trade-off between Human Cognitive Ergonomics and Workplace Productivity in Collaborative Tasks
Jul 08, 2022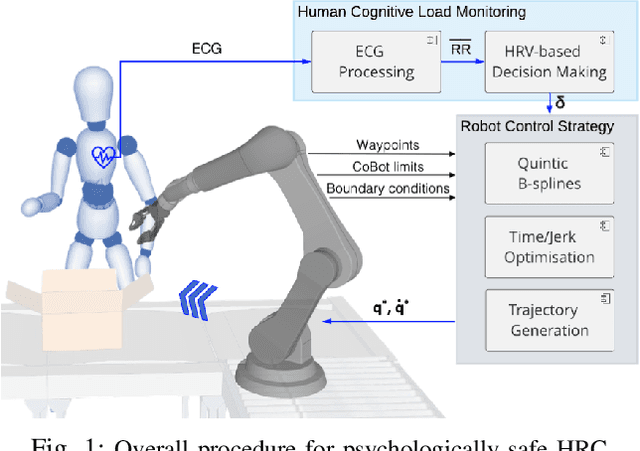
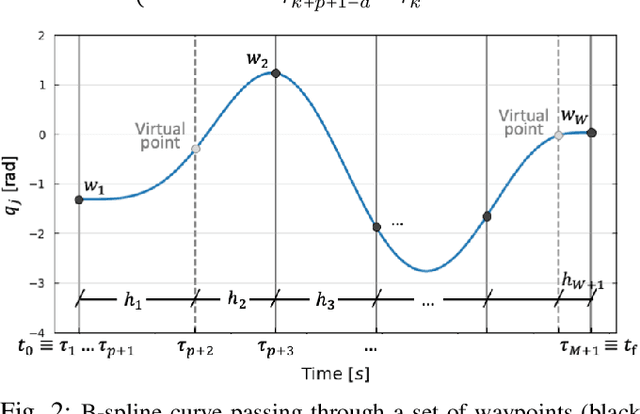
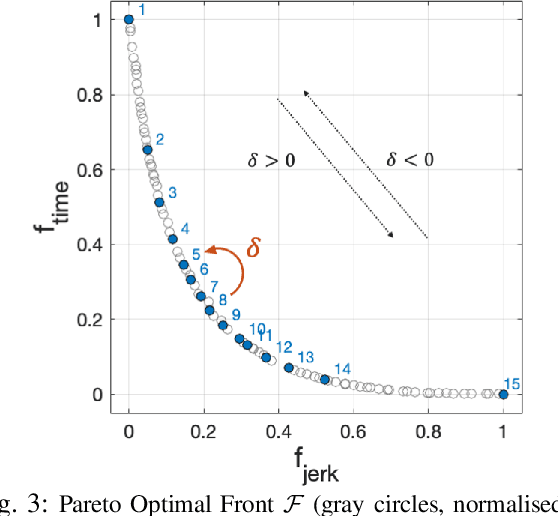

In hybrid industrial environments, workers' comfort and positive perception of safety are essential requirements for successful acceptance and usage of collaborative robots. This paper proposes a novel human-robot interaction framework in which the robot behaviour is adapted online according to the operator's cognitive workload and stress. The method exploits the generation of B-spline trajectories in the joint space and formulation of a multi-objective optimisation problem to online adjust the total execution time and smoothness of the robot trajectories. The former ensures human efficiency and productivity of the workplace, while the latter contributes to safeguarding the user's comfort and cognitive ergonomics. The performance of the proposed framework was evaluated in a typical industrial task. Results demonstrated its capability to enhance the productivity of the human-robot dyad while mitigating the cognitive workload induced in the worker.
Learning Continuous Grasping Function with a Dexterous Hand from Human Demonstrations
Jul 12, 2022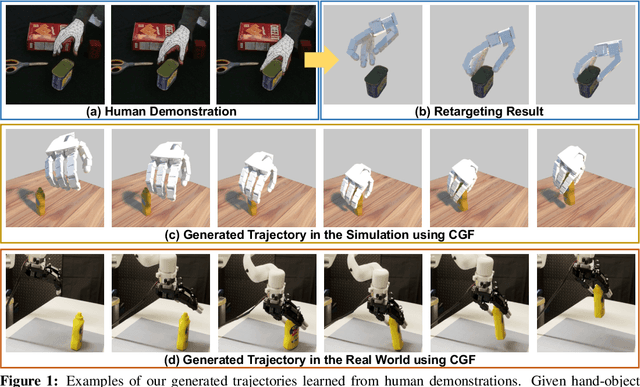

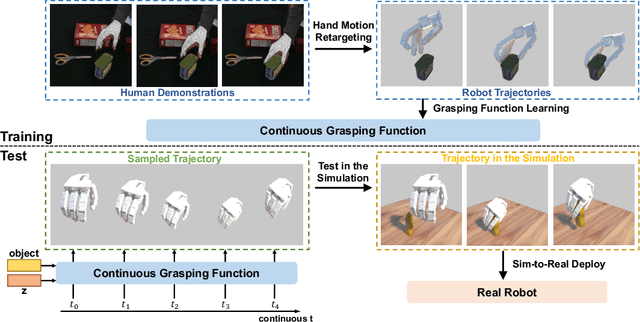
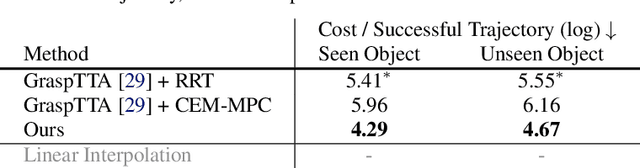
We propose to learn to generate grasping motion for manipulation with a dexterous hand using implicit functions. With continuous time inputs, the model can generate a continuous and smooth grasping plan. We name the proposed model Continuous Grasping Function (CGF). CGF is learned via generative modeling with a Conditional Variational Autoencoder using 3D human demonstrations. We will first convert the large-scale human-object interaction trajectories to robot demonstrations via motion retargeting, and then use these demonstrations to train CGF. During inference, we perform sampling with CGF to generate different grasping plans in the simulator and select the successful ones to transfer to the real robot. By training on diverse human data, our CGF allows generalization to manipulate multiple objects. Compared to previous planning algorithms, CGF is more efficient and achieves significant improvement on success rate when transferred to grasping with the real Allegro Hand. Our project page is at https://jianglongye.com/cgf .
Spatiotemporal motion planning with combinatorial reasoning for autonomous driving
Jul 10, 2022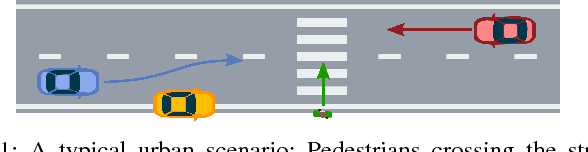
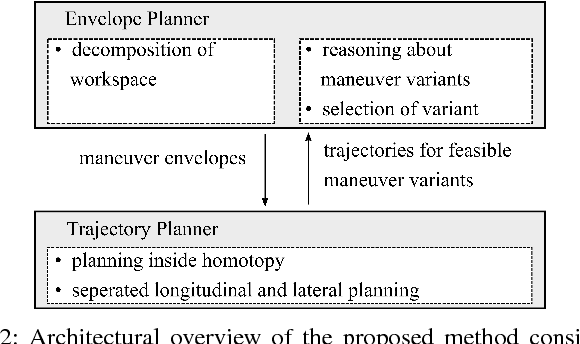
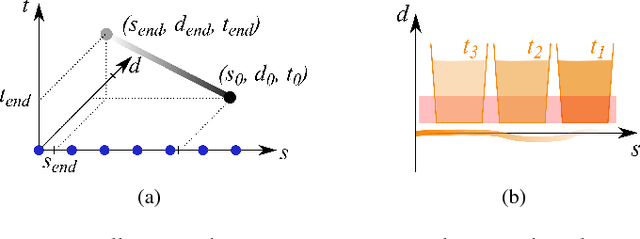
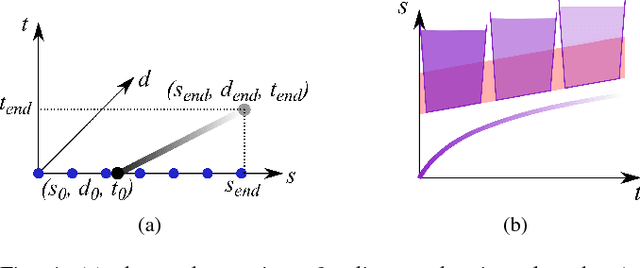
Motion planning for urban environments with numerous moving agents can be viewed as a combinatorial problem. With passing an obstacle before, after, right or left, there are multiple options an autonomous vehicle could choose to execute. These combinatorial aspects need to be taken into account in the planning framework. We address this problem by proposing a novel planning approach that combines trajectory planning and maneuver reasoning. We define a classification for dynamic obstacles along a reference curve that allows us to extract tactical decision sequences. We separate longitudinal and lateral movement to speed up the optimization-based trajectory planning. To map the set of obtained trajectories to maneuver variants, we define a semantic language to describe them. This allows us to choose an optimal trajectory while also ensuring maneuver consistency over time. We demonstrate the capabilities of our approach for a scenario that is still widely considered to be challenging.
Finite-Time Error Analysis of Asynchronous Q-Learning with Discrete-Time Switching System Models
Feb 22, 2021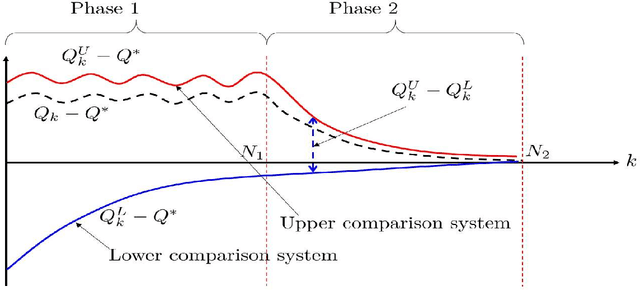
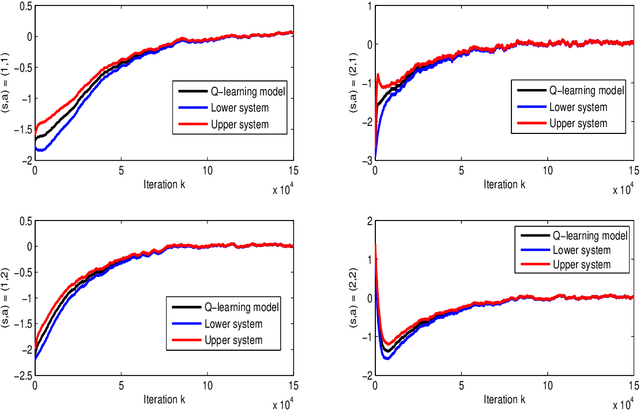
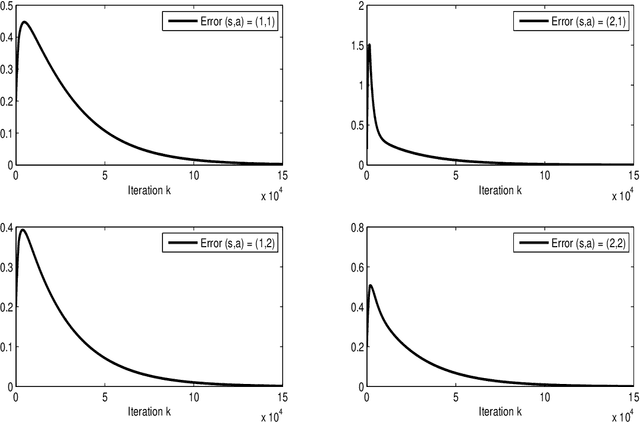
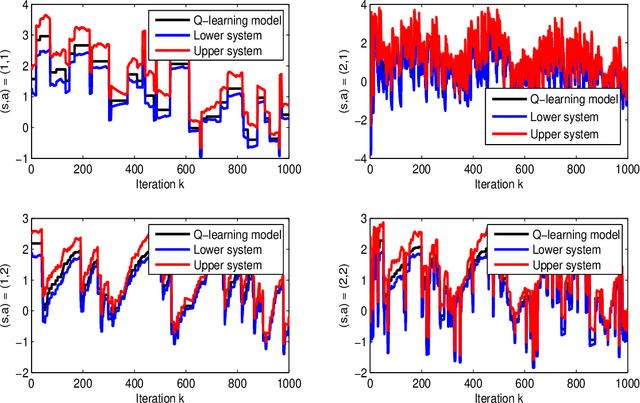
This paper develops a novel framework to analyze the convergence of Q-learning algorithm by using its connections to dynamical systems. We prove that asynchronous Q-learning with a constant step-size can be naturally formulated as discrete-time stochastic switched linear systems. Moreover, the evolution of the Q-learning estimation error is over- and underestimated by trajectories of two dynamical systems. Based on the schemes, a new finite-time analysis of the Q-learning is given with a finite-time error bound. It offers novel intuitive insights on analysis of Q-learning mainly based on control theoretic frameworks. By filling the gap between both domains in a synergistic way, this approach can potentially facilitate further progress in each field.