 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
From Tensor Network Quantum States to Tensorial Recurrent Neural Networks
Jun 24, 2022
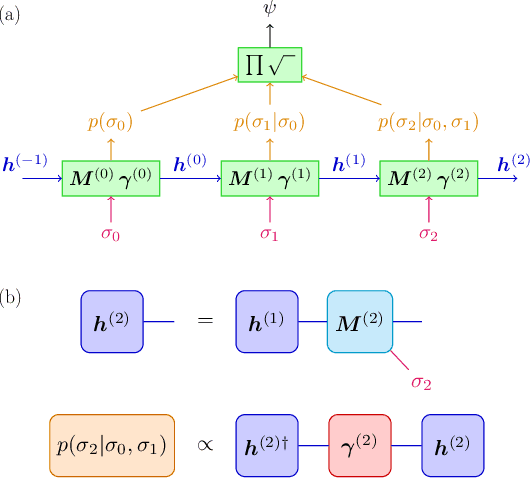
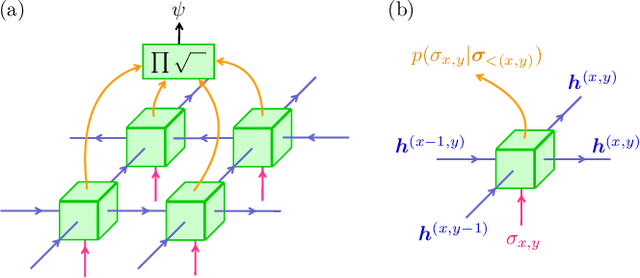
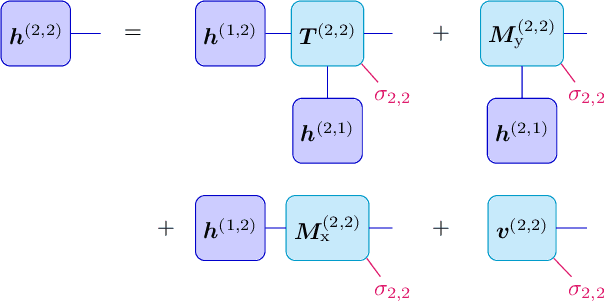
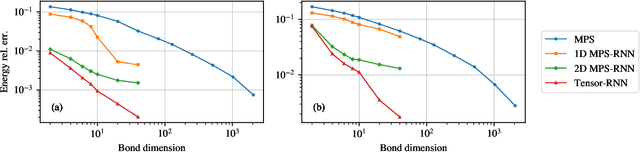
We show that any matrix product state (MPS) can be exactly represented by a recurrent neural network (RNN) with a linear memory update. We generalize this RNN architecture to 2D lattices using a multilinear memory update. It supports perfect sampling and wave function evaluation in polynomial time, and can represent an area law of entanglement entropy. Numerical evidence shows that it can encode the wave function using a bond dimension lower by orders of magnitude when compared to MPS, with an accuracy that can be systematically improved by increasing the bond dimension.
Is More Data All You Need? A Causal Exploration
Jun 06, 2022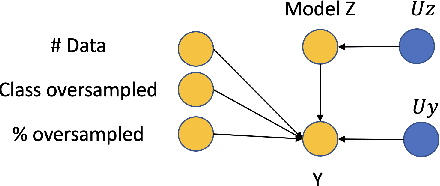

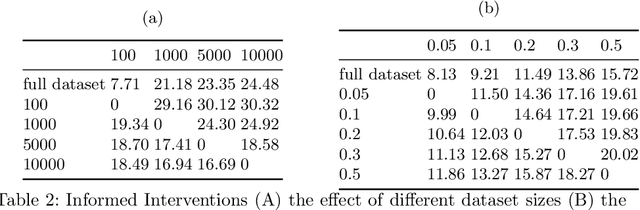
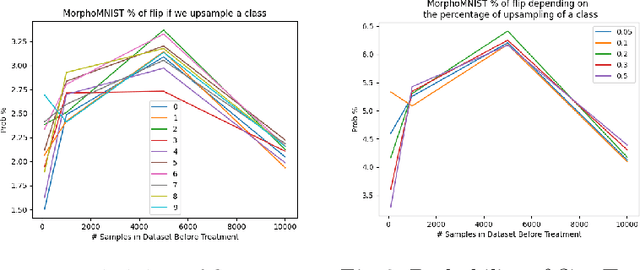
Curating a large scale medical imaging dataset for machine learning applications is both time consuming and expensive. Balancing the workload between model development, data collection and annotations is difficult for machine learning practitioners, especially under time constraints. Causal analysis is often used in medicine and economics to gain insights about the effects of actions and policies. In this paper we explore the effect of dataset interventions on the output of image classification models. Through a causal approach we investigate the effects of the quantity and type of data we need to incorporate in a dataset to achieve better performance for specific subtasks. The main goal of this paper is to highlight the potential of causal analysis as a tool for resource optimization for developing medical imaging ML applications. We explore this concept with a synthetic dataset and an exemplary use-case for Diabetic Retinopathy image analysis.
NEC: Speaker Selective Cancellation via Neural Enhanced Ultrasound Shadowing
Jul 12, 2022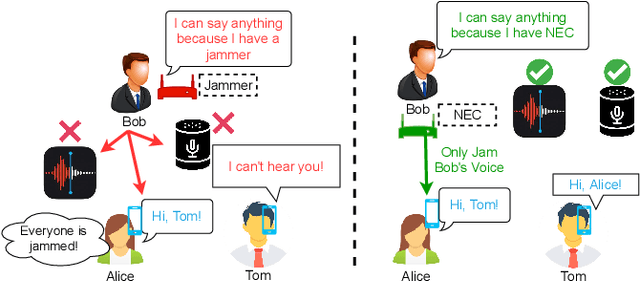


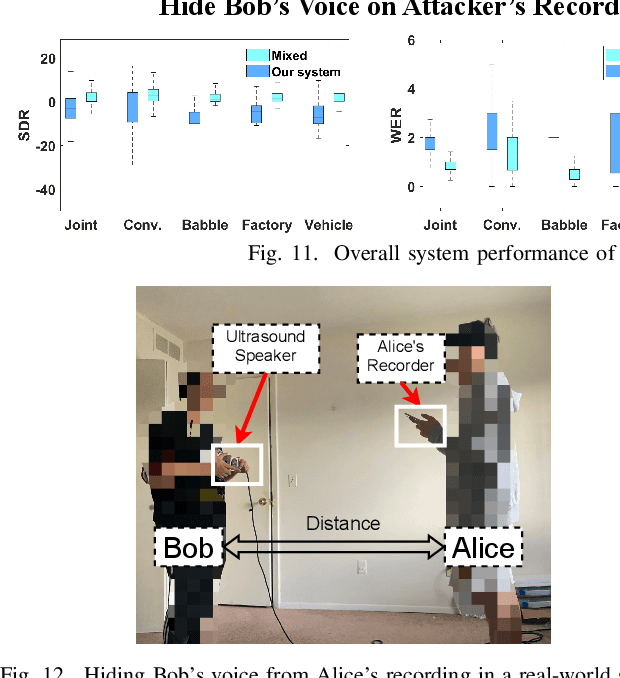
In this paper, we propose NEC (Neural Enhanced Cancellation), a defense mechanism, which prevents unauthorized microphones from capturing a target speaker's voice. Compared with the existing scrambling-based audio cancellation approaches, NEC can selectively remove a target speaker's voice from a mixed speech without causing interference to others. Specifically, for a target speaker, we design a Deep Neural Network (DNN) model to extract high-level speaker-specific but utterance-independent vocal features from his/her reference audios. When the microphone is recording, the DNN generates a shadow sound to cancel the target voice in real-time. Moreover, we modulate the audible shadow sound onto an ultrasound frequency, making it inaudible for humans. By leveraging the non-linearity of the microphone circuit, the microphone can accurately decode the shadow sound for target voice cancellation. We implement and evaluate NEC comprehensively with 8 smartphone microphones in different settings. The results show that NEC effectively mutes the target speaker at a microphone without interfering with other users' normal conversations.
A new hope for network model generalization
Jul 12, 2022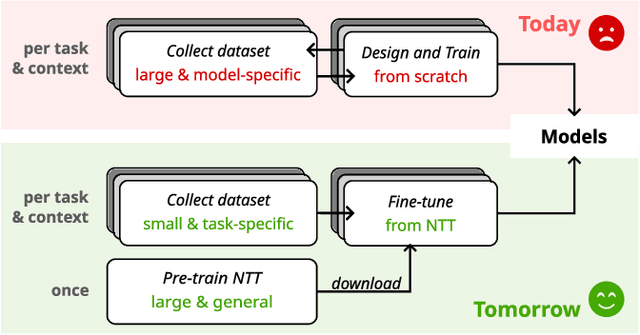
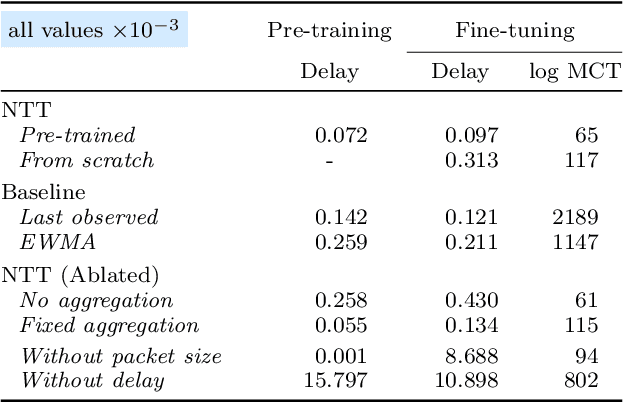
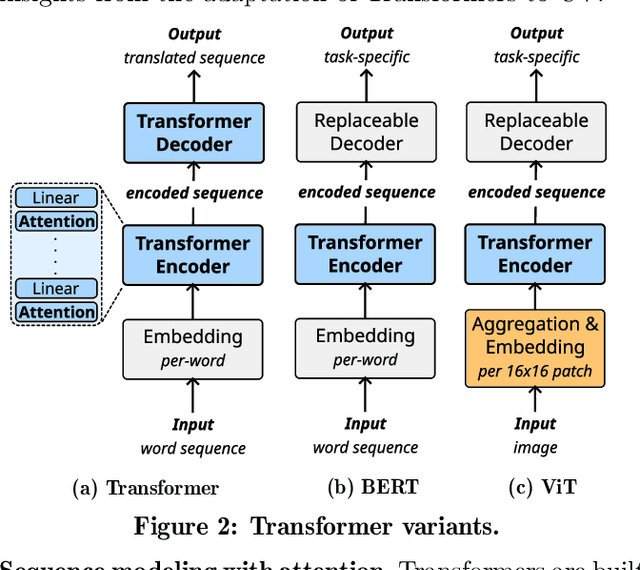
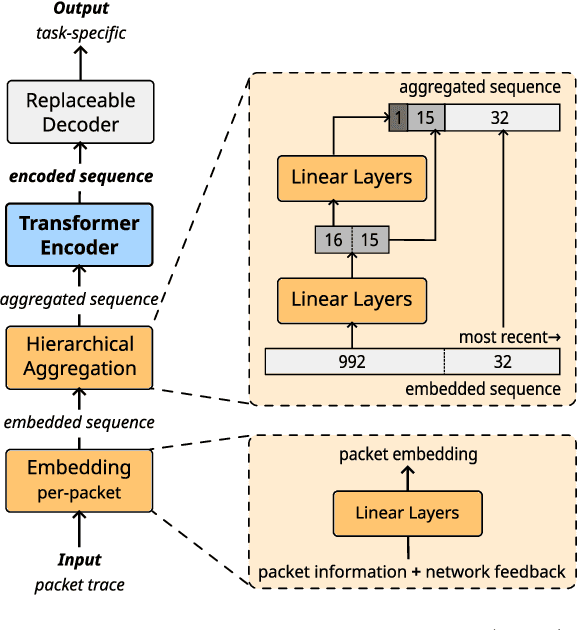
Generalizing machine learning (ML) models for network traffic dynamics tends to be considered a lost cause. Hence, for every new task, we often resolve to design new models and train them on model-specific datasets collected, whenever possible, in an environment mimicking the model's deployment. This approach essentially gives up on generalization. Yet, an ML architecture called_Transformer_ has enabled previously unimaginable generalization in other domains. Nowadays, one can download a model pre-trained on massive datasets and only fine-tune it for a specific task and context with comparatively little time and data. These fine-tuned models are now state-of-the-art for many benchmarks. We believe this progress could translate to networking and propose a Network Traffic Transformer (NTT), a transformer adapted to learn network dynamics from packet traces. Our initial results are promising: NTT seems able to generalize to new prediction tasks and contexts. This study suggests there is still hope for generalization, though it calls for a lot of future research.
End-to-end deep learning for directly estimating grape yield from ground-based imagery
Aug 04, 2022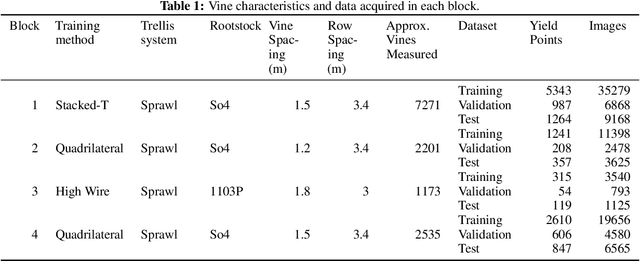
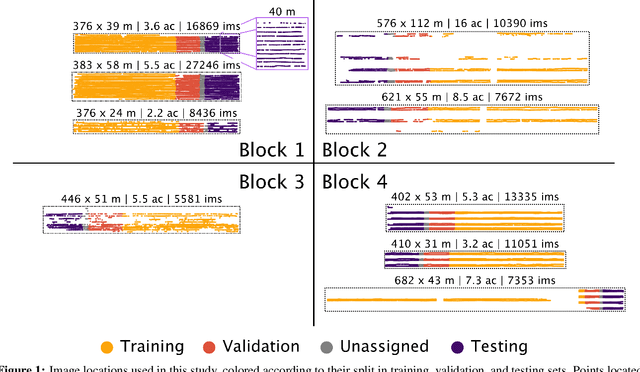
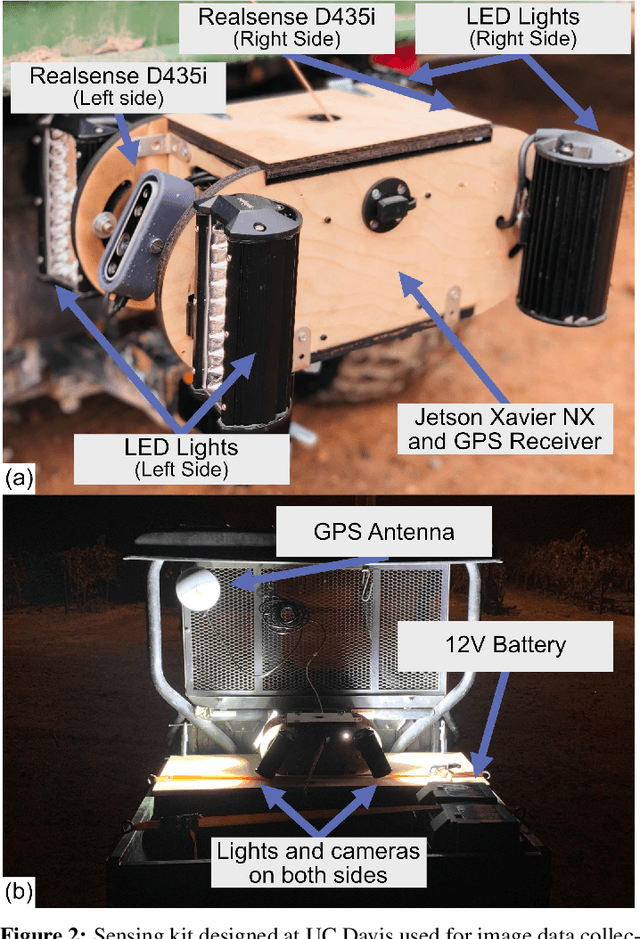
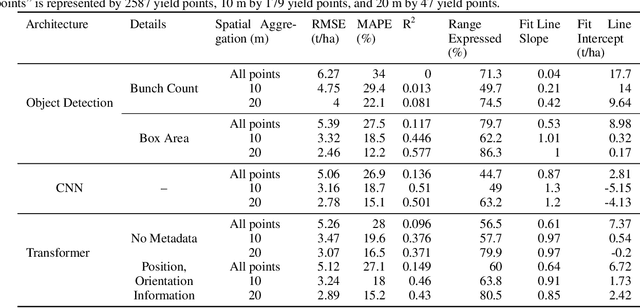
Yield estimation is a powerful tool in vineyard management, as it allows growers to fine-tune practices to optimize yield and quality. However, yield estimation is currently performed using manual sampling, which is time-consuming and imprecise. This study demonstrates the application of proximal imaging combined with deep learning for yield estimation in vineyards. Continuous data collection using a vehicle-mounted sensing kit combined with collection of ground truth yield data at harvest using a commercial yield monitor allowed for the generation of a large dataset of 23,581 yield points and 107,933 images. Moreover, this study was conducted in a mechanically managed commercial vineyard, representing a challenging environment for image analysis but a common set of conditions in the California Central Valley. Three model architectures were tested: object detection, CNN regression, and transformer models. The object detection model was trained on hand-labeled images to localize grape bunches, and either bunch count or pixel area was summed to correlate with grape yield. Conversely, regression models were trained end-to-end to predict grape yield from image data without the need for hand labeling. Results demonstrated that both a transformer as well as the object detection model with pixel area processing performed comparably, with a mean absolute percent error of 18% and 18.5%, respectively on a representative holdout dataset. Saliency mapping was used to demonstrate the attention of the CNN model was localized near the predicted location of grape bunches, as well as on the top of the grapevine canopy. Overall, the study showed the applicability of proximal imaging and deep learning for prediction of grapevine yield on a large scale. Additionally, the end-to-end modeling approach was able to perform comparably to the object detection approach while eliminating the need for hand-labeling.
Resilient Navigation and Path Planning System for High-speed Autonomous Race Car
Jul 25, 2022
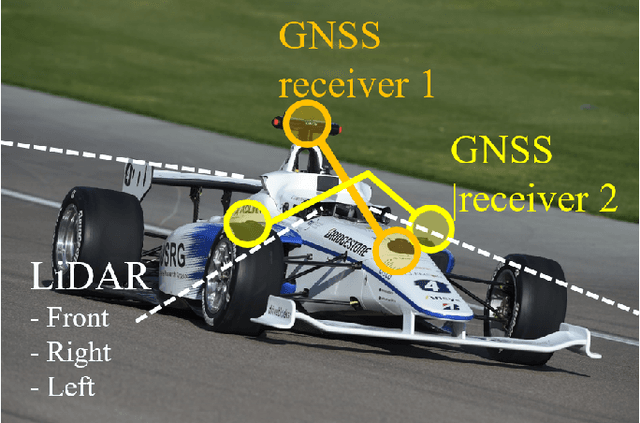
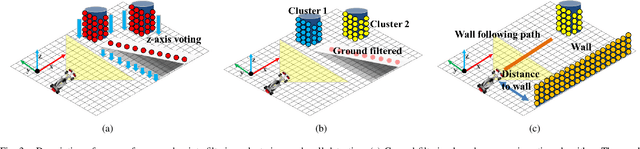
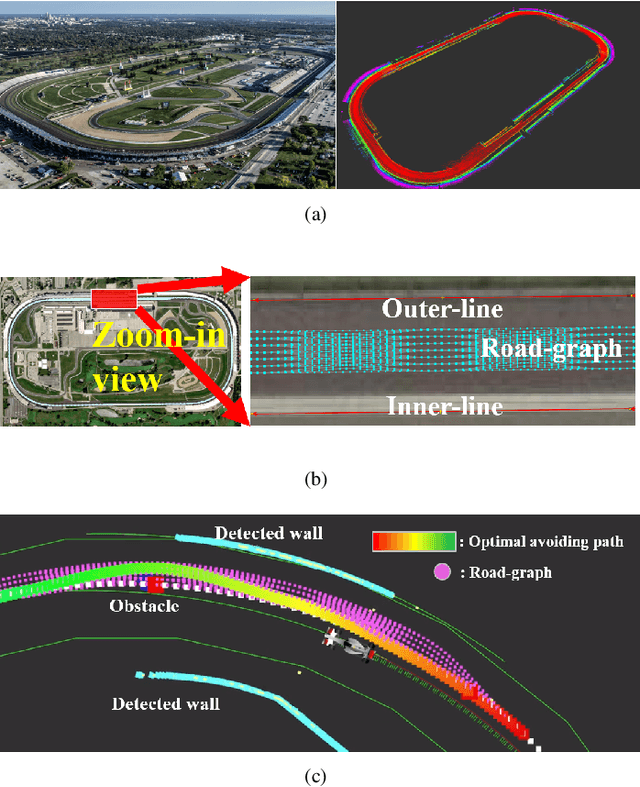
This paper describes resilient navigation and planning algorithm for high-speed autonomous race, Indy Autonomous Challenge (IAC). The IAC is a competition with full-scale autonomous race car that can drive up to 290 km/h(180mph). Due to its high-speed and heavy vibration of the race car, GPS/INS system is prone to be degraded. These degraded GPS measurements can cause a critical localization error leading to a serious crashing accidents. To this end, we propose a robust navigation system to implement multi-sensor fusion Kalman filter. In this study, we present how to identify the degradation of measurement based on probabilistic approaches. Based on this approach, we could compute optimal measurement values for Kalman filter correction step. At the same time, we present the other resilient navigation system so that race car can follow the race track in fatal localization failure situations. In addition, this paper also covers the optimal path planning algorithm for obstacle avoidance. To take account for original optimal racing line, obstacles, vehicle dynamics, we propose a road-graph-based path planning algorithm to guarantee our race car drives in-bounded conditions. In the experiments, we will evaluate our designed localization system can handle the degraded data, and sometimes prevent serious crashing accidents while high-speed driving. In addition, we will describe how we successfully completed the obstacle avoidance challenge.
American == White in Multimodal Language-and-Image AI
Jul 01, 2022
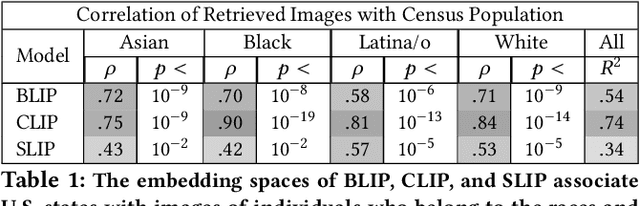
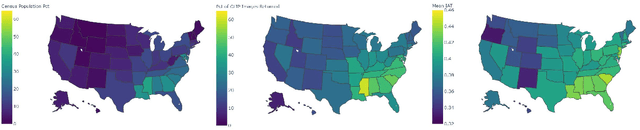
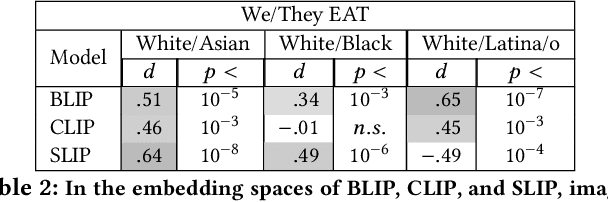
Three state-of-the-art language-and-image AI models, CLIP, SLIP, and BLIP, are evaluated for evidence of a bias previously observed in social and experimental psychology: equating American identity with being White. Embedding association tests (EATs) using standardized images of self-identified Asian, Black, Latina/o, and White individuals from the Chicago Face Database (CFD) reveal that White individuals are more associated with collective in-group words than are Asian, Black, or Latina/o individuals. In assessments of three core aspects of American identity reported by social psychologists, single-category EATs reveal that images of White individuals are more associated with patriotism and with being born in America, but that, consistent with prior findings in psychology, White individuals are associated with being less likely to treat people of all races and backgrounds equally. Three downstream machine learning tasks demonstrate biases associating American with White. In a visual question answering task using BLIP, 97% of White individuals are identified as American, compared to only 3% of Asian individuals. When asked in what state the individual depicted lives in, the model responds China 53% of the time for Asian individuals, but always with an American state for White individuals. In an image captioning task, BLIP remarks upon the race of Asian individuals as much as 36% of the time, but never remarks upon race for White individuals. Finally, provided with an initialization image from the CFD and the text "an American person," a synthetic image generator (VQGAN) using the text-based guidance of CLIP lightens the skin tone of individuals of all races (by 35% for Black individuals, based on pixel brightness). The results indicate that biases equating American identity with being White are learned by language-and-image AI, and propagate to downstream applications of such models.
Discrete-Convex-Analysis-Based Framework for Warm-Starting Algorithms with Predictions
May 20, 2022

Augmenting algorithms with learned predictions is a promising approach for going beyond worst-case bounds. Dinitz, Im, Lavastida, Moseley, and Vassilvitskii~(2021) have demonstrated that a warm start with learned dual solutions can improve the time complexity of the Hungarian method for weighted perfect bipartite matching. We extend and improve their framework in a principled manner via \textit{discrete convex analysis} (DCA), a discrete analog of convex analysis. We show the usefulness of our DCA-based framework by applying it to weighted perfect bipartite matching, weighted matroid intersection, and discrete energy minimization for computer vision. Our DCA-based framework yields time complexity bounds that depend on the $\ell_\infty$-distance from a predicted solution to an optimal solution, which has two advantages relative to the previous $\ell_1$-distance-dependent bounds: time complexity bounds are smaller, and learning of predictions is more sample efficient. We also discuss whether to learn primal or dual solutions from the DCA perspective.
Seeing 3D Objects in a Single Image via Self-Supervised Static-Dynamic Disentanglement
Jul 22, 2022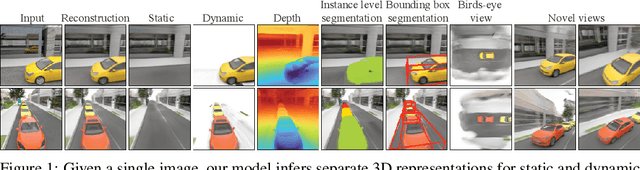
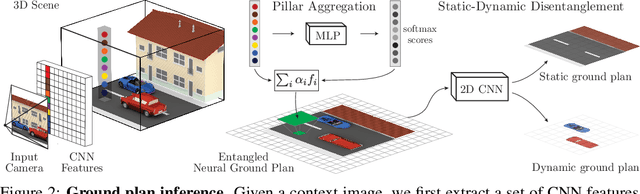
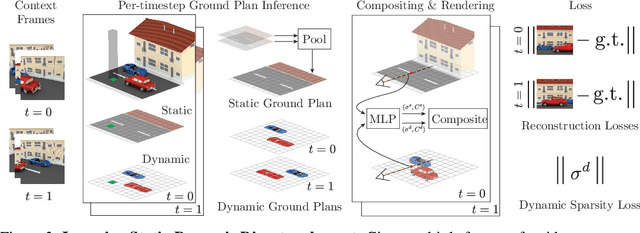

Human perception reliably identifies movable and immovable parts of 3D scenes, and completes the 3D structure of objects and background from incomplete observations. We learn this skill not via labeled examples, but simply by observing objects move. In this work, we propose an approach that observes unlabeled multi-view videos at training time and learns to map a single image observation of a complex scene, such as a street with cars, to a 3D neural scene representation that is disentangled into movable and immovable parts while plausibly completing its 3D structure. We separately parameterize movable and immovable scene parts via 2D neural ground plans. These ground plans are 2D grids of features aligned with the ground plane that can be locally decoded into 3D neural radiance fields. Our model is trained self-supervised via neural rendering. We demonstrate that the structure inherent to our disentangled 3D representation enables a variety of downstream tasks in street-scale 3D scenes using simple heuristics, such as extraction of object-centric 3D representations, novel view synthesis, instance segmentation, and 3D bounding box prediction, highlighting its value as a backbone for data-efficient 3D scene understanding models. This disentanglement further enables scene editing via object manipulation such as deletion, insertion, and rigid-body motion.
Seasonal Encoder-Decoder Architecture for Forecasting
Jul 08, 2022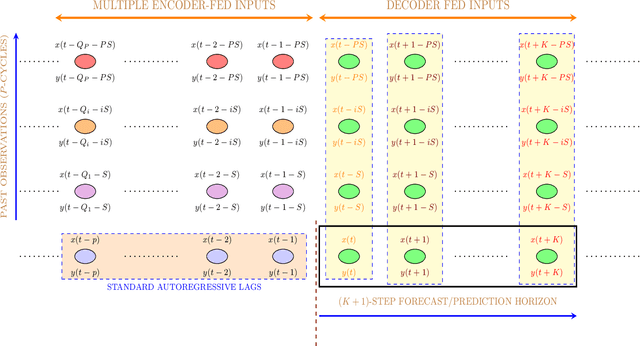
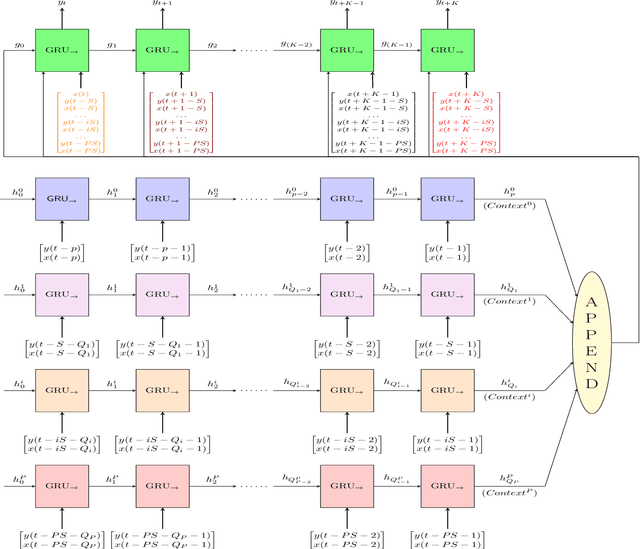
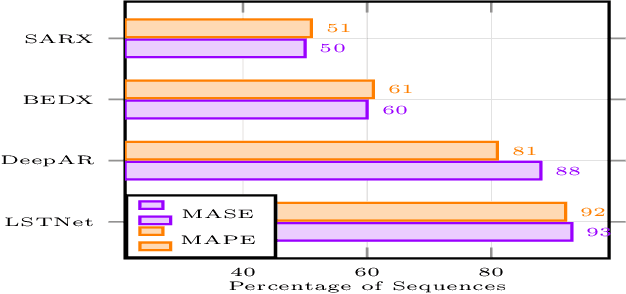
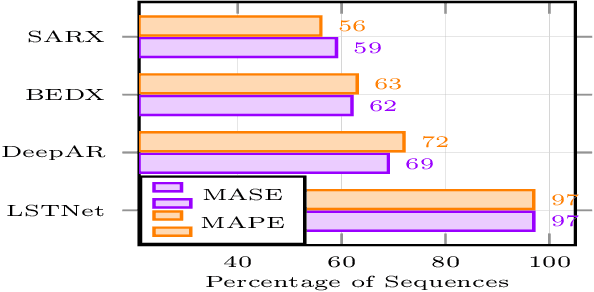
Deep learning (DL) in general and Recurrent neural networks (RNNs) in particular have seen high success levels in sequence based applications. This paper pertains to RNNs for time series modelling and forecasting. We propose a novel RNN architecture capturing (stochastic) seasonal correlations intelligently while capable of accurate multi-step forecasting. It is motivated from the well-known encoder-decoder (ED) architecture and multiplicative seasonal auto-regressive model. It incorporates multi-step (multi-target) learning even in the presence (or absence) of exogenous inputs. It can be employed on single or multiple sequence data. For the multiple sequence case, we also propose a novel greedy recursive procedure to build (one or more) predictive models across sequences when per-sequence data is less. We demonstrate via extensive experiments the utility of our proposed architecture both in single sequence and multiple sequence scenarios.