 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning to Accelerate Partial Differential Equations via Latent Global Evolution
Jun 15, 2022
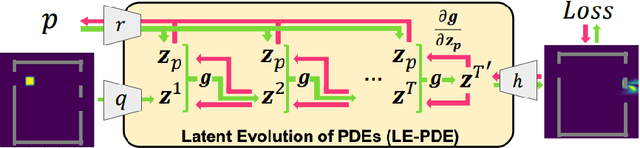
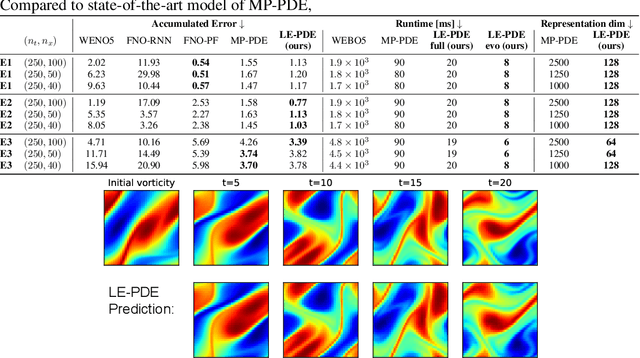
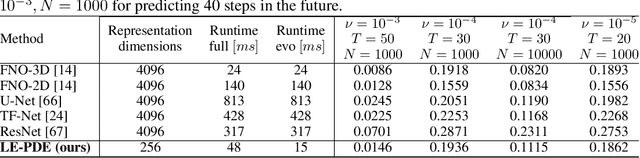

Simulating the time evolution of Partial Differential Equations (PDEs) of large-scale systems is crucial in many scientific and engineering domains such as fluid dynamics, weather forecasting and their inverse optimization problems. However, both classical solvers and recent deep learning-based surrogate models are typically extremely computationally intensive, because of their local evolution: they need to update the state of each discretized cell at each time step during inference. Here we develop Latent Evolution of PDEs (LE-PDE), a simple, fast and scalable method to accelerate the simulation and inverse optimization of PDEs. LE-PDE learns a compact, global representation of the system and efficiently evolves it fully in the latent space with learned latent evolution models. LE-PDE achieves speed-up by having a much smaller latent dimension to update during long rollout as compared to updating in the input space. We introduce new learning objectives to effectively learn such latent dynamics to ensure long-term stability. We further introduce techniques for speeding-up inverse optimization of boundary conditions for PDEs via backpropagation through time in latent space, and an annealing technique to address the non-differentiability and sparse interaction of boundary conditions. We test our method in a 1D benchmark of nonlinear PDEs, 2D Navier-Stokes flows into turbulent phase and an inverse optimization of boundary conditions in 2D Navier-Stokes flow. Compared to state-of-the-art deep learning-based surrogate models and other strong baselines, we demonstrate up to 128x reduction in the dimensions to update, and up to 15x improvement in speed, while achieving competitive accuracy.
Learning Large-scale Subsurface Simulations with a Hybrid Graph Network Simulator
Jun 15, 2022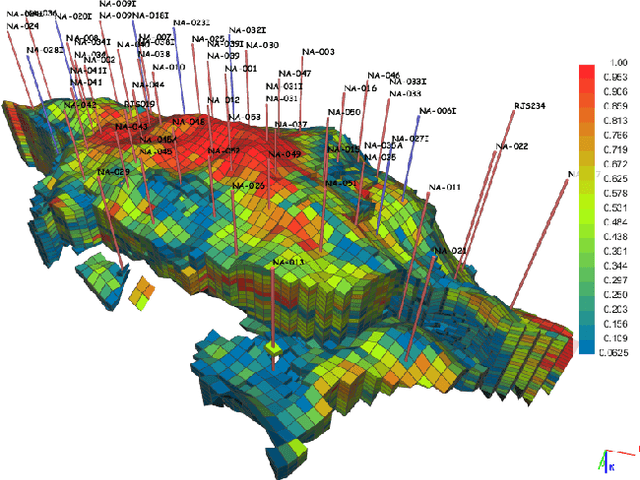
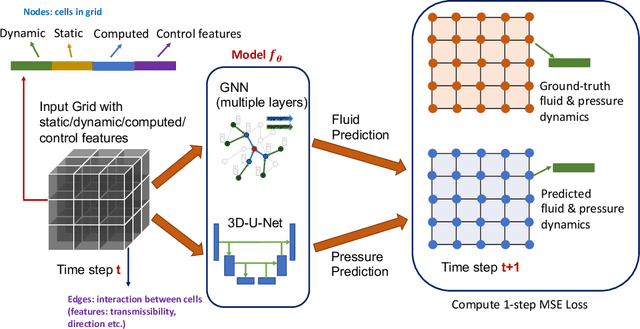
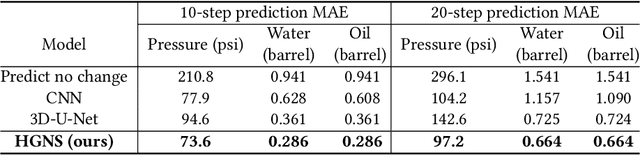
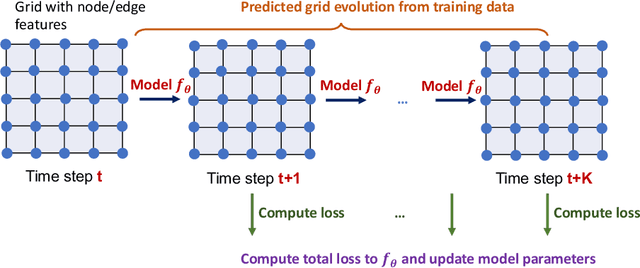
Subsurface simulations use computational models to predict the flow of fluids (e.g., oil, water, gas) through porous media. These simulations are pivotal in industrial applications such as petroleum production, where fast and accurate models are needed for high-stake decision making, for example, for well placement optimization and field development planning. Classical finite difference numerical simulators require massive computational resources to model large-scale real-world reservoirs. Alternatively, streamline simulators and data-driven surrogate models are computationally more efficient by relying on approximate physics models, however they are insufficient to model complex reservoir dynamics at scale. Here we introduce Hybrid Graph Network Simulator (HGNS), which is a data-driven surrogate model for learning reservoir simulations of 3D subsurface fluid flows. To model complex reservoir dynamics at both local and global scale, HGNS consists of a subsurface graph neural network (SGNN) to model the evolution of fluid flows, and a 3D-U-Net to model the evolution of pressure. HGNS is able to scale to grids with millions of cells per time step, two orders of magnitude higher than previous surrogate models, and can accurately predict the fluid flow for tens of time steps (years into the future). Using an industry-standard subsurface flow dataset (SPE-10) with 1.1 million cells, we demonstrate that HGNS is able to reduce the inference time up to 18 times compared to standard subsurface simulators, and that it outperforms other learning-based models by reducing long-term prediction errors by up to 21%.
Continuous-Time Model-Based Reinforcement Learning
Feb 10, 2021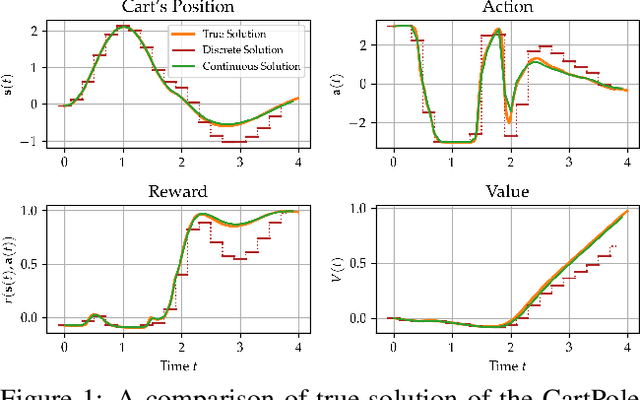


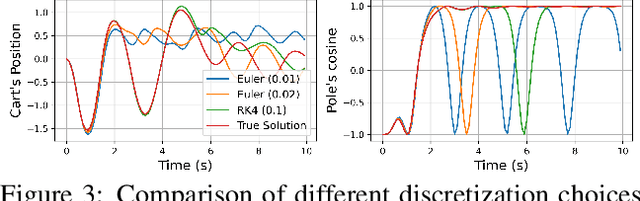
Model-based reinforcement learning (MBRL) approaches rely on discrete-time state transition models whereas physical systems and the vast majority of control tasks operate in continuous-time. To avoid time-discretization approximation of the underlying process, we propose a continuous-time MBRL framework based on a novel actor-critic method. Our approach also infers the unknown state evolution differentials with Bayesian neural ordinary differential equations (ODE) to account for epistemic uncertainty. We implement and test our method on a new ODE-RL suite that explicitly solves continuous-time control systems. Our experiments illustrate that the model is robust against irregular and noisy data, is sample-efficient, and can solve control problems which pose challenges to discrete-time MBRL methods.
Detecting Deepfake by Creating Spatio-Temporal Regularity Disruption
Jul 21, 2022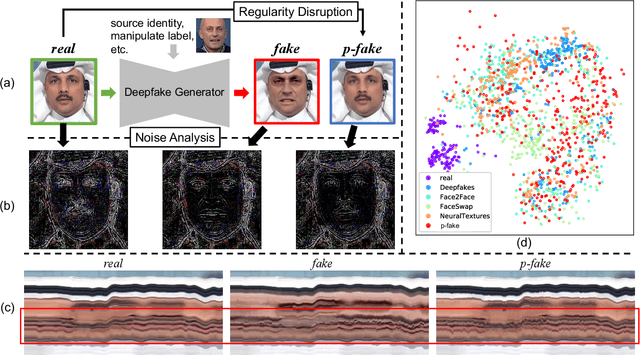
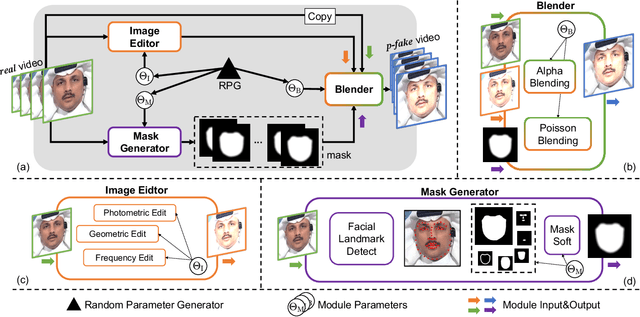
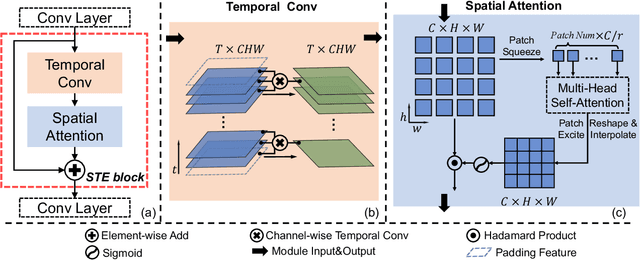
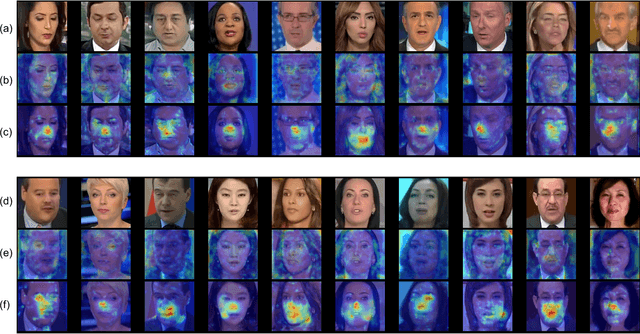
Despite encouraging progress in deepfake detection, generalization to unseen forgery types remains a significant challenge due to the limited forgery clues explored during training. In contrast, we notice a common phenomenon in deepfake: fake video creation inevitably disrupts the statistical regularity in original videos. Inspired by this observation, we propose to boost the generalization of deepfake detection by distinguishing the "regularity disruption" that does not appear in real videos. Specifically, by carefully examining the spatial and temporal properties, we propose to disrupt a real video through a Pseudo-fake Generator and create a wide range of pseudo-fake videos for training. Such practice allows us to achieve deepfake detection without using fake videos and improves the generalization ability in a simple and efficient manner. To jointly capture the spatial and temporal disruptions, we propose a Spatio-Temporal Enhancement block to learn the regularity disruption across space and time on our self-created videos. Through comprehensive experiments, our method exhibits excellent performance on several datasets.
Structure PLP-SLAM: Efficient Sparse Mapping and Localization using Point, Line and Plane for Monocular, RGB-D and Stereo Cameras
Jul 19, 2022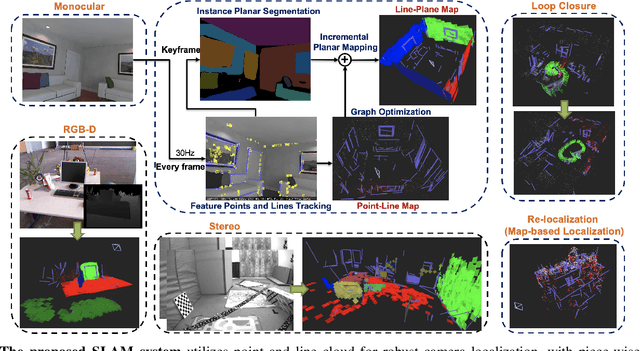
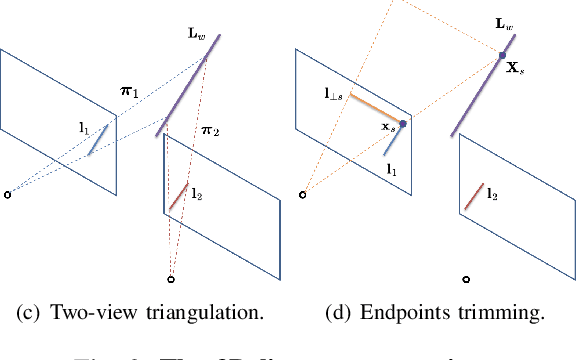
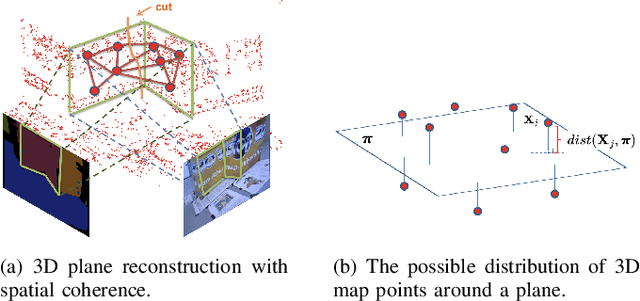

This paper demonstrates a visual SLAM system that utilizes point and line cloud for robust camera localization, simultaneously, with an embedded piece-wise planar reconstruction (PPR) module which in all provides a structural map. To build a scale consistent map in parallel with tracking, such as employing a single camera brings the challenge of reconstructing geometric primitives with scale ambiguity, and further introduces the difficulty in graph optimization of bundle adjustment (BA). We address these problems by proposing several run-time optimizations on the reconstructed lines and planes. The system is then extended with depth and stereo sensors based on the design of the monocular framework. The results show that our proposed SLAM tightly incorporates the semantic features to boost both frontend tracking as well as backend optimization. We evaluate our system exhaustively on various datasets, and open-source our code for the community (https://github.com/PeterFWS/Structure-PLP-SLAM).
Ad2Attack: Adaptive Adversarial Attack on Real-Time UAV Tracking
Mar 03, 2022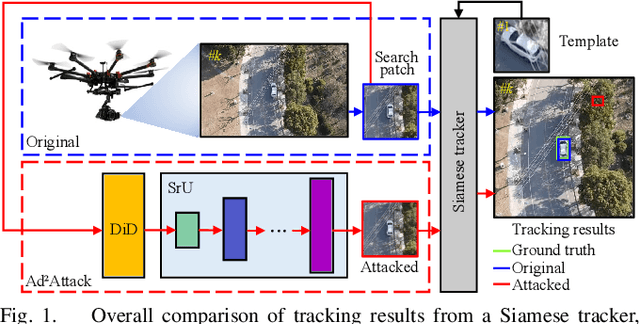
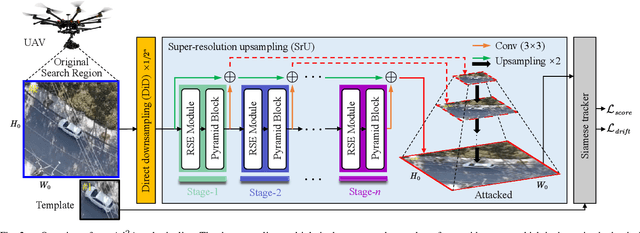
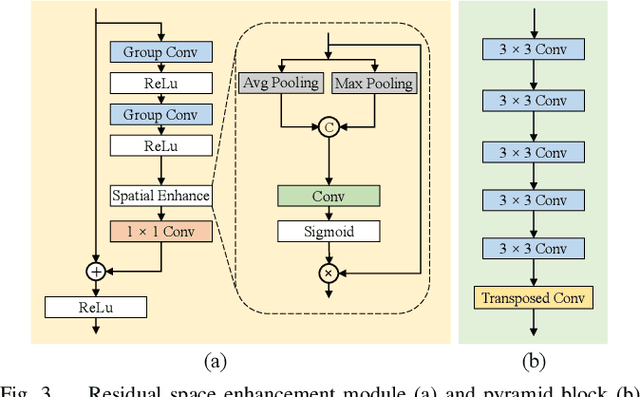
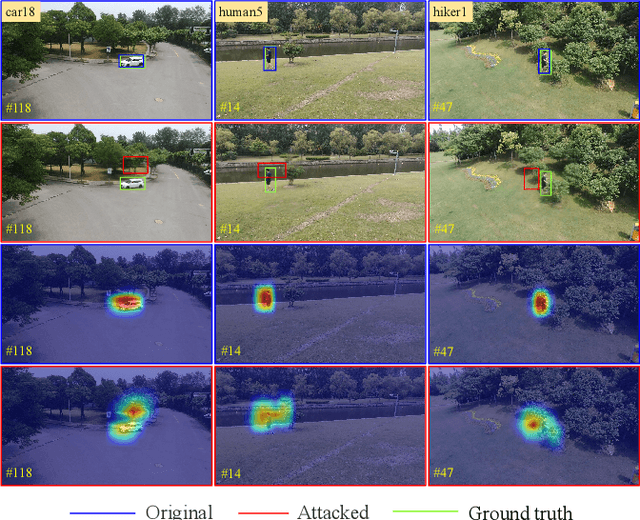
Visual tracking is adopted to extensive unmanned aerial vehicle (UAV)-related applications, which leads to a highly demanding requirement on the robustness of UAV trackers. However, adding imperceptible perturbations can easily fool the tracker and cause tracking failures. This risk is often overlooked and rarely researched at present. Therefore, to help increase awareness of the potential risk and the robustness of UAV tracking, this work proposes a novel adaptive adversarial attack approach, i.e., Ad$^2$Attack, against UAV object tracking. Specifically, adversarial examples are generated online during the resampling of the search patch image, which leads trackers to lose the target in the following frames. Ad$^2$Attack is composed of a direct downsampling module and a super-resolution upsampling module with adaptive stages. A novel optimization function is proposed for balancing the imperceptibility and efficiency of the attack. Comprehensive experiments on several well-known benchmarks and real-world conditions show the effectiveness of our attack method, which dramatically reduces the performance of the most advanced Siamese trackers.
Auto Machine Learning for Medical Image Analysis by Unifying the Search on Data Augmentation and Neural Architecture
Jul 21, 2022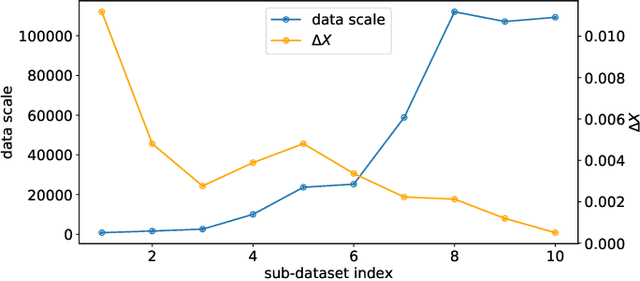
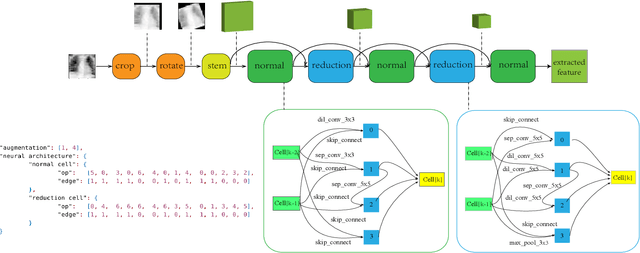
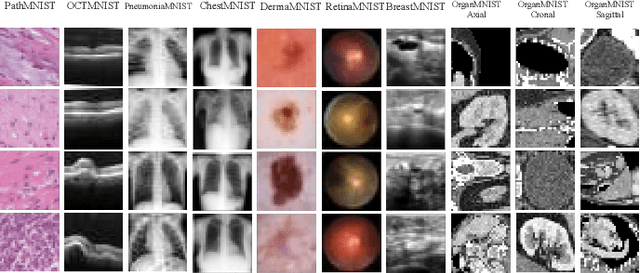
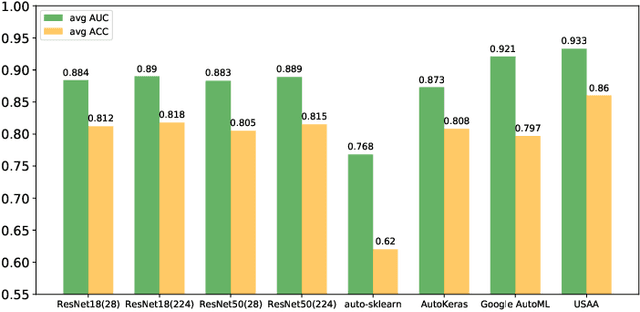
Automated data augmentation, which aims at engineering augmentation policy automatically, recently draw a growing research interest. Many previous auto-augmentation methods utilized a Density Matching strategy by evaluating policies in terms of the test-time augmentation performance. In this paper, we theoretically and empirically demonstrated the inconsistency between the train and validation set of small-scale medical image datasets, referred to as in-domain sampling bias. Next, we demonstrated that the in-domain sampling bias might cause the inefficiency of Density Matching. To address the problem, an improved augmentation search strategy, named Augmented Density Matching, was proposed by randomly sampling policies from a prior distribution for training. Moreover, an efficient automatical machine learning(AutoML) algorithm was proposed by unifying the search on data augmentation and neural architecture. Experimental results indicated that the proposed methods outperformed state-of-the-art approaches on MedMNIST, a pioneering benchmark designed for AutoML in medical image analysis.
Zero-Shot AutoML with Pretrained Models
Jun 16, 2022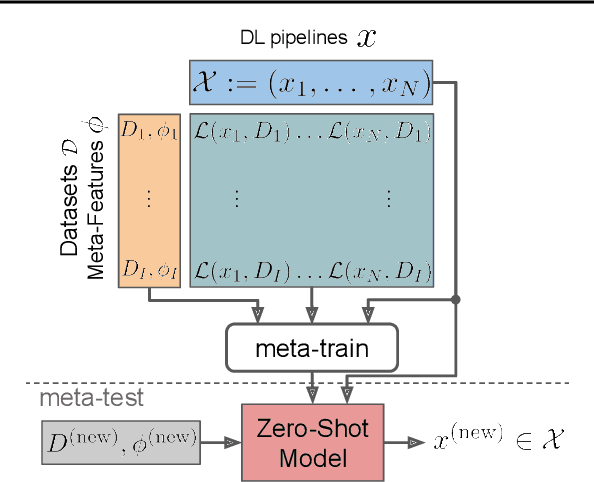
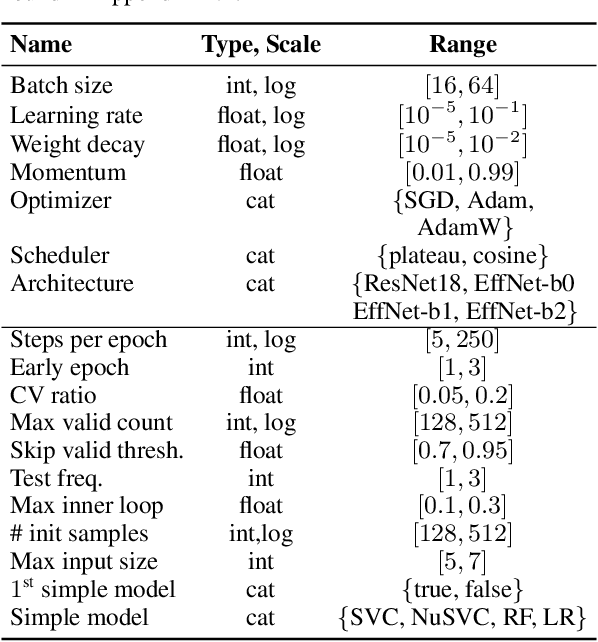
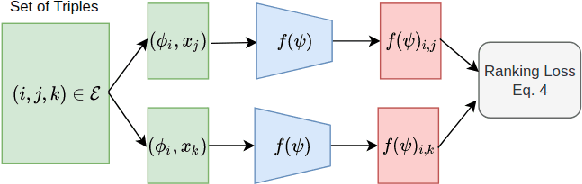

Given a new dataset D and a low compute budget, how should we choose a pre-trained model to fine-tune to D, and set the fine-tuning hyperparameters without risking overfitting, particularly if D is small? Here, we extend automated machine learning (AutoML) to best make these choices. Our domain-independent meta-learning approach learns a zero-shot surrogate model which, at test time, allows to select the right deep learning (DL) pipeline (including the pre-trained model and fine-tuning hyperparameters) for a new dataset D given only trivial meta-features describing D such as image resolution or the number of classes. To train this zero-shot model, we collect performance data for many DL pipelines on a large collection of datasets and meta-train on this data to minimize a pairwise ranking objective. We evaluate our approach under the strict time limit of the vision track of the ChaLearn AutoDL challenge benchmark, clearly outperforming all challenge contenders.
Multi-channel target speech enhancement based on ERB-scaled spatial coherence features
Jul 17, 2022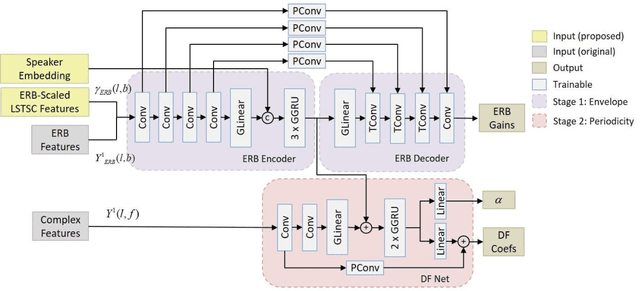
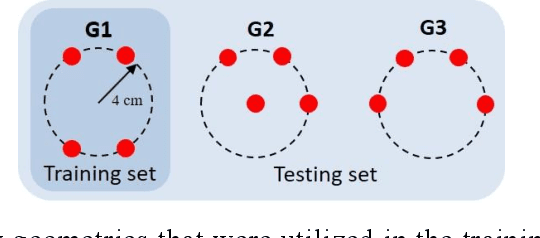
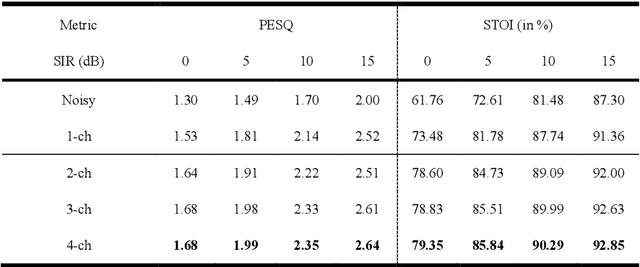
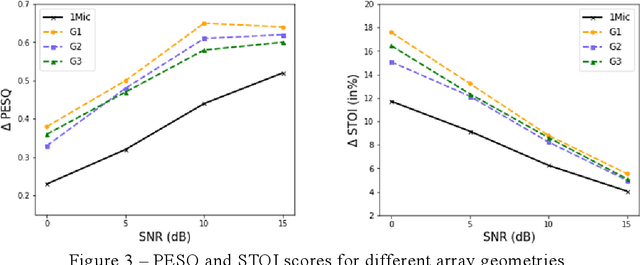
Recently, speech enhancement technologies that are based on deep learning have received considerable research attention. If the spatial information in microphone signals is exploited, microphone arrays can be advantageous under some adverse acoustic conditions compared with single-microphone systems. However, multichannel speech enhancement is often performed in the short-time Fourier transform (STFT) domain, which renders the enhancement approach computationally expensive. To remedy this problem, we propose a novel equivalent rectangular bandwidth (ERB)-scaled spatial coherence feature that is dependent on the target speaker activity between two ERB bands. Experiments conducted using a four-microphone array in a reverberant environment, which involved speech interference, demonstrated the efficacy of the proposed system. This study also demonstrated that a network that was trained with the ERB-scaled spatial feature was robust against variations in the geometry and number of the microphones in the array.
Sepsis Prediction with Temporal Convolutional Networks
May 31, 2022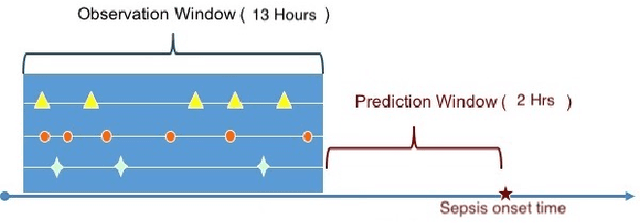

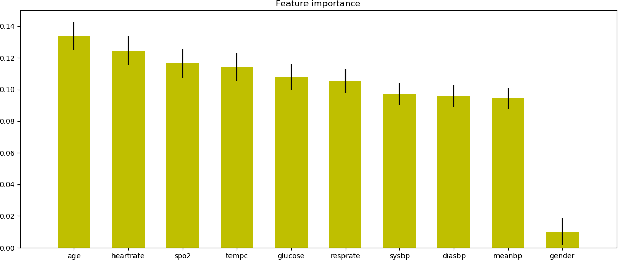
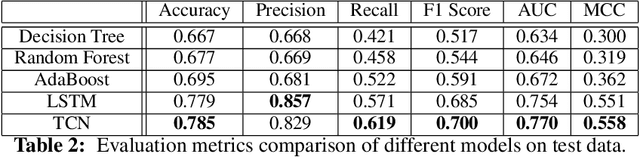
We design and implement a temporal convolutional network model to predict sepsis onset. Our model is trained on data extracted from MIMIC III database, based on a retrospective analysis of patients admitted to intensive care unit who did not fall under the definition of sepsis at the time of admission. Benchmarked with several machine learning models, our model is superior on this binary classification task, demonstrates the prediction power of convolutional networks for temporal patterns, also shows the significant impact of having longer look back time on sepsis prediction.