 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Rectifying Mono-Label Boolean Classifiers
Jun 17, 2022
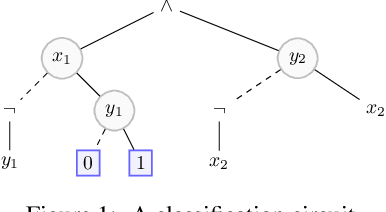

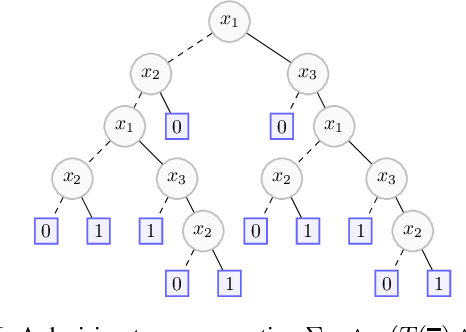
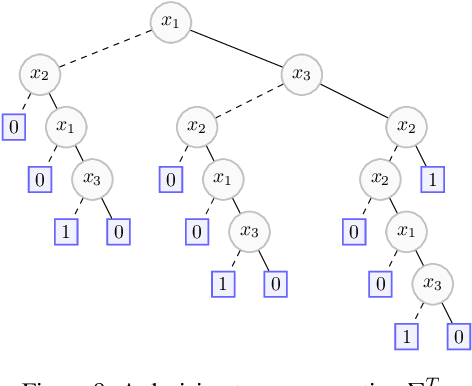
We elaborate on the notion of rectification of a Boolean classifier $\Sigma$. Given $\Sigma$ and some background knowledge $T$, postulates characterizing the way $\Sigma$ must be changed into a new classifier $\Sigma \star T$ that complies with $T$ have already been presented. We focus here on the specific case of mono-label Boolean classifiers, i.e., there is a single target concept and any instance is classified either as positive (an element of the concept), or as negative (an element of the complementary concept). In this specific case, our main contribution is twofold: (1) we show that there is a unique rectification operator $\star$ satisfying the postulates, and (2) when $\Sigma$ and $T$ are Boolean circuits, we show how a classification circuit equivalent to $\Sigma \star T$ can be computed in time linear in the size of $\Sigma$ and $T$; when $\Sigma$ and $T$ are decision trees, a decision tree equivalent to $\Sigma \star T$ can be computed in time polynomial in the size of $\Sigma$ and $T$.
Large-scale matrix optimization based multi microgrid topology design with a constrained differential evolution algorithm
Jul 18, 2022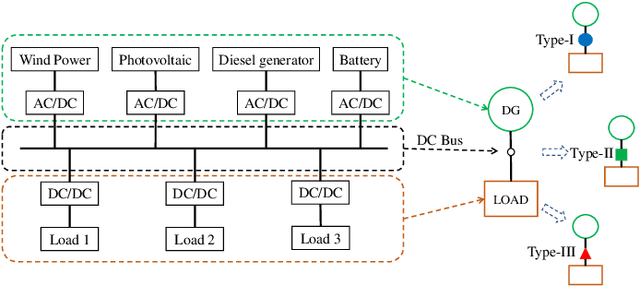
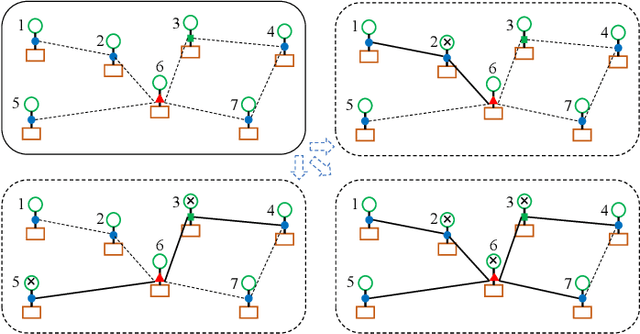
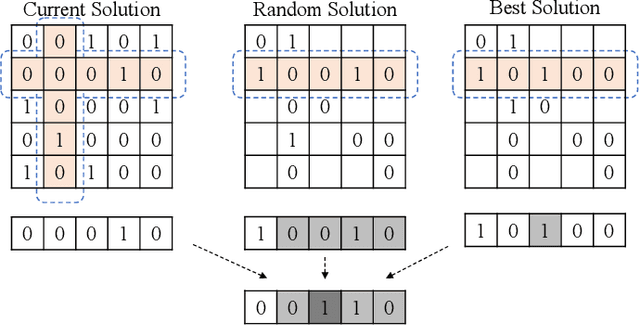
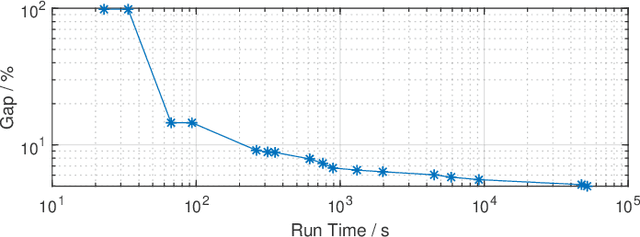
Binary matrix optimization commonly arise in the real world, e.g., multi-microgrid network structure design problem (MGNSDP), which is to minimize the total length of the power supply line under certain constraints. Finding the global optimal solution for these problems faces a great challenge since such problems could be large-scale, sparse and multimodal. Traditional linear programming is time-consuming and cannot solve nonlinear problems. To address this issue, a novel improved feasibility rule based differential evolution algorithm, termed LBMDE, is proposed. To be specific, a general heuristic solution initialization method is first proposed to generate high-quality solutions. Then, a binary-matrix-based DE operator is introduced to produce offspring. To deal with the constraints, we proposed an improved feasibility rule based environmental selection strategy. The performance and searching behaviors of LBMDE are examined by a set of benchmark problems.
Characterization of Real-time Haptic Feedback from Multimodal Neural Network-based Force Estimates during Teleoperation
Sep 23, 2021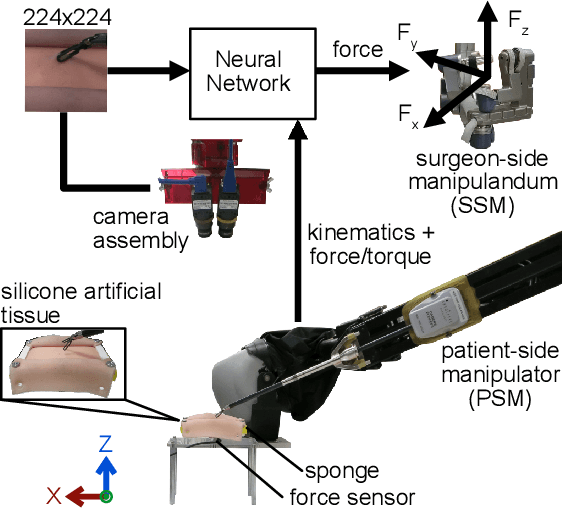
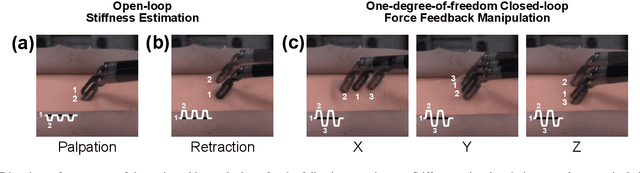
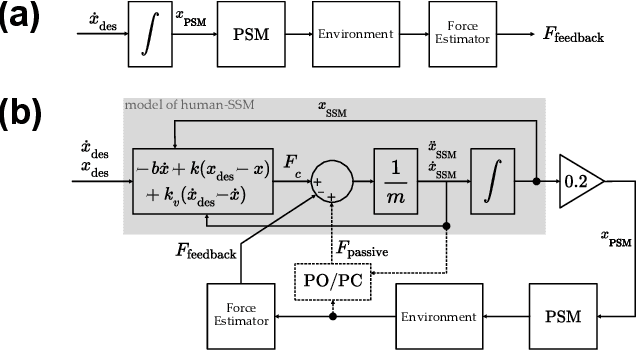
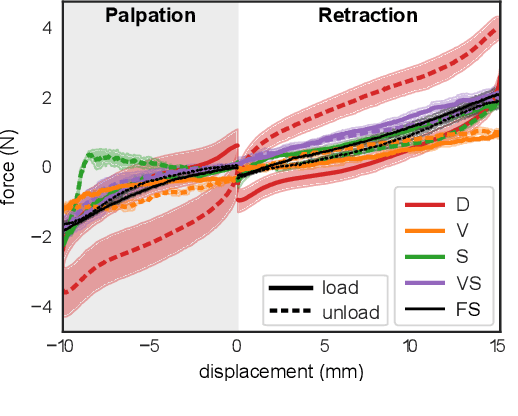
Force estimation using neural networks is a promising approach to enable haptic feedback in minimally invasive surgical robots without end-effector force sensors. Various network architectures have been proposed, but none have been tested in real-time with surgical-like manipulations. Thus, questions remain about the real-time transparency and stability of force feedback from neural network-based force estimates. We characterize the real-time impedance transparency and stability of force feedback rendered on a da Vinci Research Kit teleoperated surgical robot using neural networks with vision-only, state-only, or state and vision inputs. Networks were trained on an existing dataset of teleoperated manipulations without force feedback. We measured real-time transparency without rendered force feedback by commanding the patient-side robot to perform vertical retractions and palpations on artificial silicone tissue. To measure stability and transparency during teleoperation with force feedback to the operator, we modeled a one-degree-of-freedom human and surgeon-side manipulandum that moved the patient-side robot to perform manipulations. We found that the multimodal vision and state network displayed more transparent impedance than single-modality networks under no force feedback. State-based networks displayed instabilities during manipulation with force feedback. This instability was reduced in the multimodal network when refit with additional data collected during teleoperation with force feedback.
The Harvard USPTO Patent Dataset: A Large-Scale, Well-Structured, and Multi-Purpose Corpus of Patent Applications
Jul 08, 2022


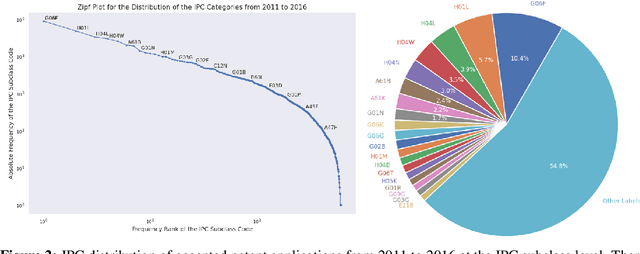
Innovation is a major driver of economic and social development, and information about many kinds of innovation is embedded in semi-structured data from patents and patent applications. Although the impact and novelty of innovations expressed in patent data are difficult to measure through traditional means, ML offers a promising set of techniques for evaluating novelty, summarizing contributions, and embedding semantics. In this paper, we introduce the Harvard USPTO Patent Dataset (HUPD), a large-scale, well-structured, and multi-purpose corpus of English-language patent applications filed to the United States Patent and Trademark Office (USPTO) between 2004 and 2018. With more than 4.5 million patent documents, HUPD is two to three times larger than comparable corpora. Unlike previously proposed patent datasets in NLP, HUPD contains the inventor-submitted versions of patent applications--not the final versions of granted patents--thereby allowing us to study patentability at the time of filing using NLP methods for the first time. It is also novel in its inclusion of rich structured metadata alongside the text of patent filings: By providing each application's metadata along with all of its text fields, the dataset enables researchers to perform new sets of NLP tasks that leverage variation in structured covariates. As a case study on the types of research HUPD makes possible, we introduce a new task to the NLP community--namely, binary classification of patent decisions. We additionally show the structured metadata provided in the dataset enables us to conduct explicit studies of concept shifts for this task. Finally, we demonstrate how HUPD can be used for three additional tasks: multi-class classification of patent subject areas, language modeling, and summarization.
Delayed Feedback in Generalised Linear Bandits Revisited
Jul 25, 2022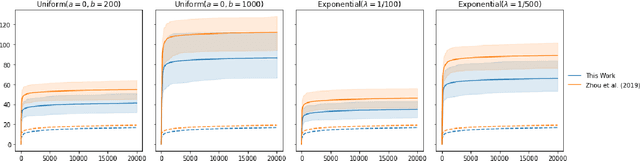
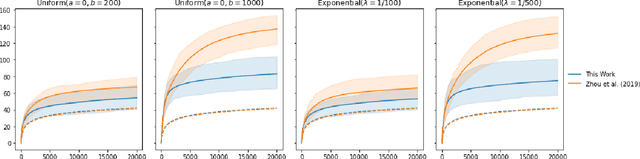
The stochastic generalised linear bandit is a well-understood model for sequential decision-making problems, with many algorithms achieving near-optimal regret guarantees under immediate feedback. However, in many real world settings, the requirement that the reward is observed immediately is not applicable. In this setting, standard algorithms are no longer theoretically understood. We study the phenomenon of delayed rewards in a theoretical manner by introducing a delay between selecting an action and receiving the reward. Subsequently, we show that an algorithm based on the optimistic principle improves on existing approaches for this setting by eliminating the need for prior knowledge of the delay distribution and relaxing assumptions on the decision set and the delays. This also leads to improving the regret guarantees from $ \widetilde O(\sqrt{dT}\sqrt{d + \mathbb{E}[\tau]})$ to $ \widetilde O(d\sqrt{T} + d^{3/2}\mathbb{E}[\tau])$, where $\mathbb{E}[\tau]$ denotes the expected delay, $d$ is the dimension and $T$ the time horizon and we have suppressed logarithmic terms. We verify our theoretical results through experiments on simulated data.
Amazon SageMaker Model Monitor: A System for Real-Time Insights into Deployed Machine Learning Models
Dec 13, 2021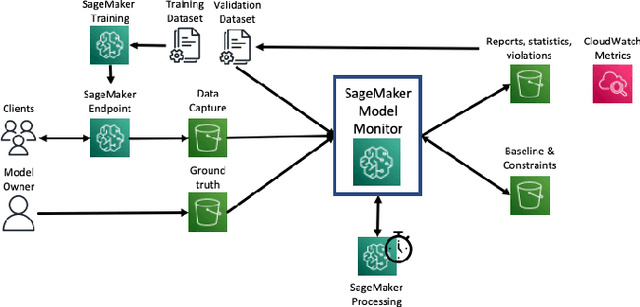
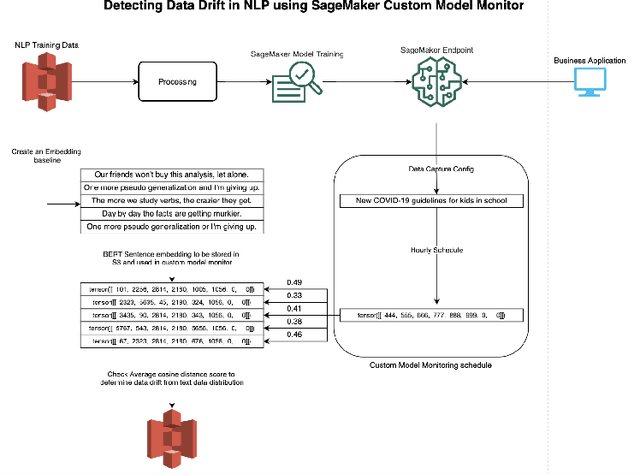
With the increasing adoption of machine learning (ML) models and systems in high-stakes settings across different industries, guaranteeing a model's performance after deployment has become crucial. Monitoring models in production is a critical aspect of ensuring their continued performance and reliability. We present Amazon SageMaker Model Monitor, a fully managed service that continuously monitors the quality of machine learning models hosted on Amazon SageMaker. Our system automatically detects data, concept, bias, and feature attribution drift in models in real-time and provides alerts so that model owners can take corrective actions and thereby maintain high quality models. We describe the key requirements obtained from customers, system design and architecture, and methodology for detecting different types of drift. Further, we provide quantitative evaluations followed by use cases, insights, and lessons learned from more than 1.5 years of production deployment.
Forecasting Question Answering over Temporal Knowledge Graphs
Aug 12, 2022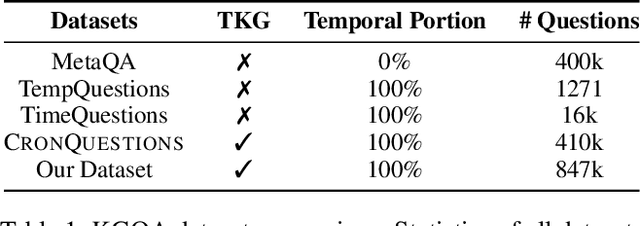

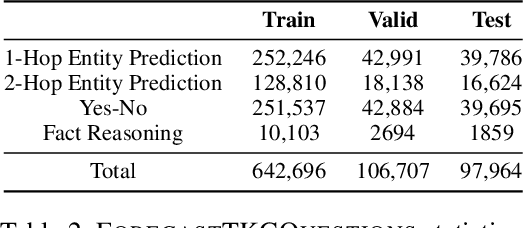
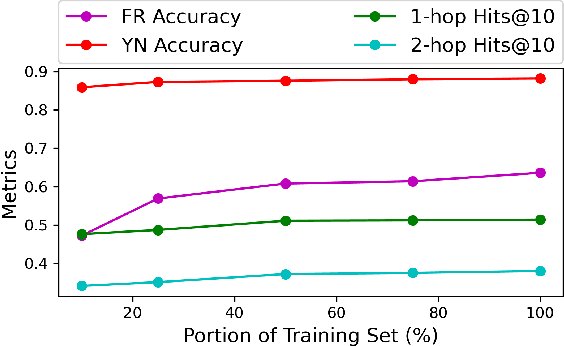
Question answering over temporal knowledge graphs (TKGQA) has recently found increasing interest. TKGQA requires temporal reasoning techniques to extract the relevant information from temporal knowledge bases. The only existing TKGQA dataset, i.e., CronQuestions, consists of temporal questions based on the facts from a fixed time period, where a temporal knowledge graph (TKG) spanning the same period can be fully used for answer inference, allowing the TKGQA models to use even the future knowledge to answer the questions based on the past facts. In real-world scenarios, however, it is also common that given the knowledge until now, we wish the TKGQA systems to answer the questions asking about the future. As humans constantly seek plans for the future, building TKGQA systems for answering such forecasting questions is important. Nevertheless, this has still been unexplored in previous research. In this paper, we propose a novel task: forecasting question answering over temporal knowledge graphs. We also propose a large-scale TKGQA benchmark dataset, i.e., ForecastTKGQuestions, for this task. It includes three types of questions, i.e., entity prediction, yes-no, and fact reasoning questions. For every forecasting question in our dataset, QA models can only have access to the TKG information before the timestamp annotated in the given question for answer inference. We find that the state-of-the-art TKGQA methods perform poorly on forecasting questions, and they are unable to answer yes-no questions and fact reasoning questions. To this end, we propose ForecastTKGQA, a TKGQA model that employs a TKG forecasting module for future inference, to answer all three types of questions. Experimental results show that ForecastTKGQA outperforms recent TKGQA methods on the entity prediction questions, and it also shows great effectiveness in answering the other two types of questions.
Learning Citywide Patterns of Life from Trajectory Monitoring
Jun 30, 2022



The recent proliferation of real-world human mobility datasets has catalyzed geospatial and transportation research in trajectory prediction, demand forecasting, travel time estimation, and anomaly detection. However, these datasets also enable, more broadly, a descriptive analysis of intricate systems of human mobility. We formally define patterns of life analysis as a natural, explainable extension of online unsupervised anomaly detection, where we not only monitor a data stream for anomalies but also explicitly extract normal patterns over time. To learn patterns of life, we adapt Grow When Required (GWR) episodic memory from research in computational biology and neurorobotics to a new domain of geospatial analysis. This biologically-inspired neural network, related to self-organizing maps (SOM), constructs a set of "memories" or prototype traffic patterns incrementally as it iterates over the GPS stream. It then compares each new observation to its prior experiences, inducing an online, unsupervised clustering and anomaly detection on the data. We mine patterns-of-interest from the Porto taxi dataset, including both major public holidays and newly-discovered transportation anomalies, such as festivals and concerts which, to our knowledge, have not been previously acknowledged or reported in prior work. We anticipate that the capability to incrementally learn normal and abnormal road transportation behavior will be useful in many domains, including smart cities, autonomous vehicles, and urban planning and management.
Continuous-Time Model-Based Reinforcement Learning
Feb 10, 2021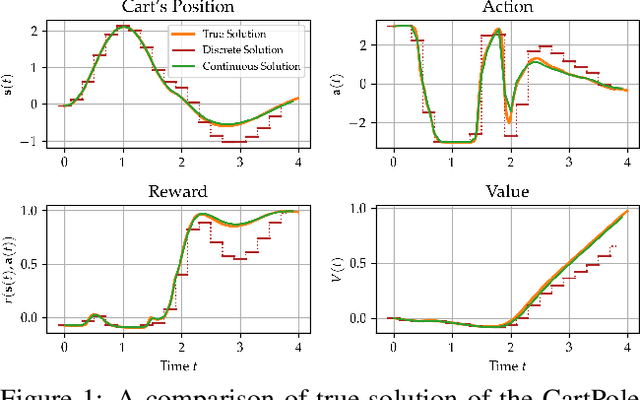


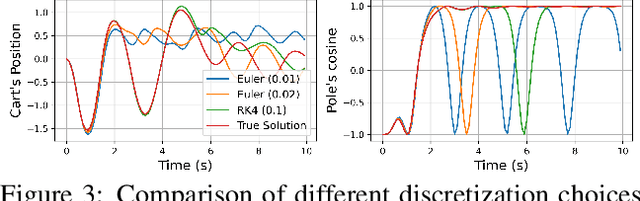
Model-based reinforcement learning (MBRL) approaches rely on discrete-time state transition models whereas physical systems and the vast majority of control tasks operate in continuous-time. To avoid time-discretization approximation of the underlying process, we propose a continuous-time MBRL framework based on a novel actor-critic method. Our approach also infers the unknown state evolution differentials with Bayesian neural ordinary differential equations (ODE) to account for epistemic uncertainty. We implement and test our method on a new ODE-RL suite that explicitly solves continuous-time control systems. Our experiments illustrate that the model is robust against irregular and noisy data, is sample-efficient, and can solve control problems which pose challenges to discrete-time MBRL methods.
Landslide Detection in Real-Time Social Media Image Streams
Oct 03, 2021

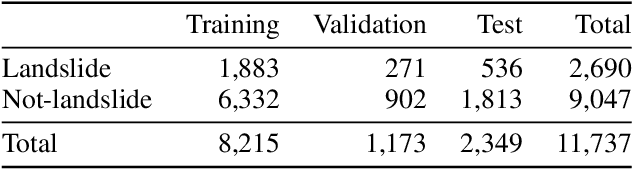
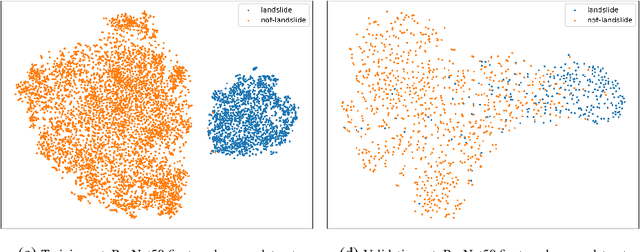
Lack of global data inventories obstructs scientific modeling of and response to landslide hazards which are oftentimes deadly and costly. To remedy this limitation, new approaches suggest solutions based on citizen science that requires active participation. However, as a non-traditional data source, social media has been increasingly used in many disaster response and management studies in recent years. Inspired by this trend, we propose to capitalize on social media data to mine landslide-related information automatically with the help of artificial intelligence (AI) techniques. Specifically, we develop a state-of-the-art computer vision model to detect landslides in social media image streams in real time. To that end, we create a large landslide image dataset labeled by experts and conduct extensive model training experiments. The experimental results indicate that the proposed model can be deployed in an online fashion to support global landslide susceptibility maps and emergency response.