 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Accumulative Poisoning Attacks on Real-time Data
Jun 18, 2021
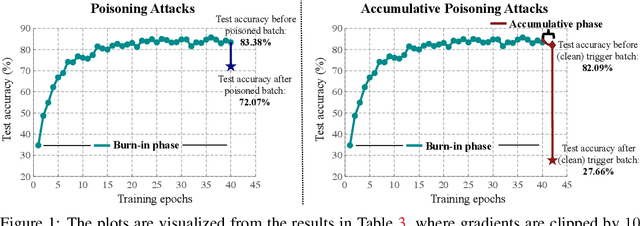
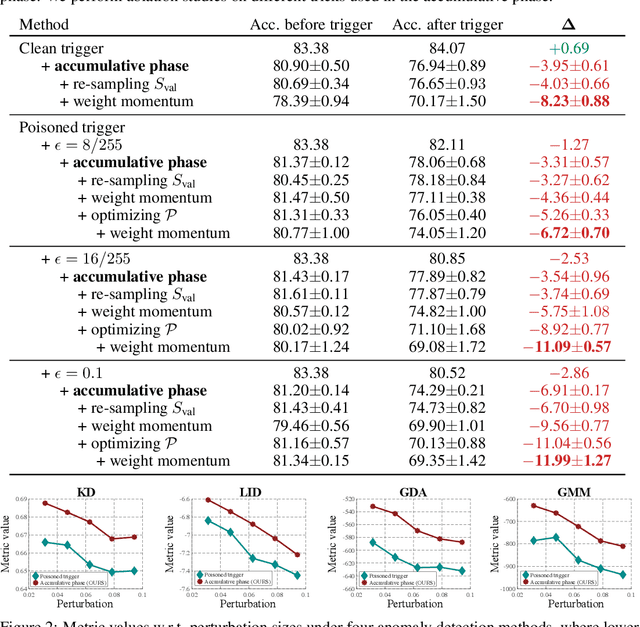
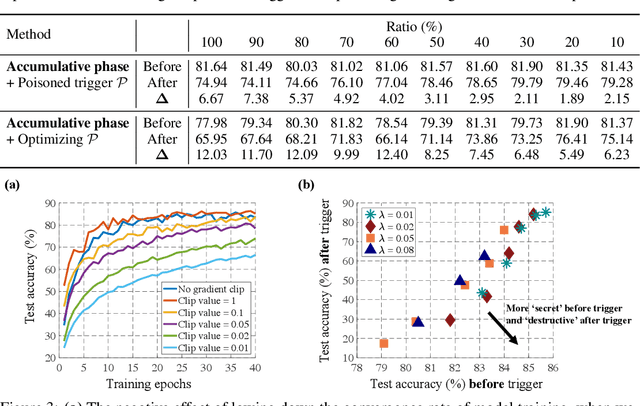
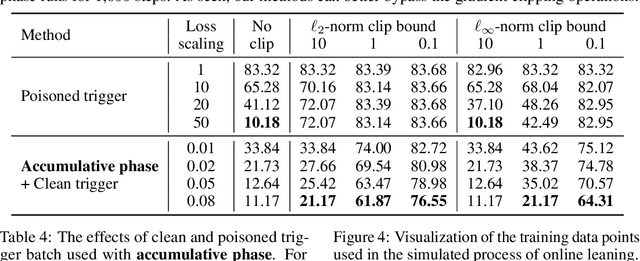
Collecting training data from untrusted sources exposes machine learning services to poisoning adversaries, who maliciously manipulate training data to degrade the model accuracy. When trained on offline datasets, poisoning adversaries have to inject the poisoned data in advance before training, and the order of feeding these poisoned batches into the model is stochastic. In contrast, practical systems are more usually trained/fine-tuned on sequentially captured real-time data, in which case poisoning adversaries could dynamically poison each data batch according to the current model state. In this paper, we focus on the real-time settings and propose a new attacking strategy, which affiliates an accumulative phase with poisoning attacks to secretly (i.e., without affecting accuracy) magnify the destructive effect of a (poisoned) trigger batch. By mimicking online learning and federated learning on CIFAR-10, we show that the model accuracy will significantly drop by a single update step on the trigger batch after the accumulative phase. Our work validates that a well-designed but straightforward attacking strategy can dramatically amplify the poisoning effects, with no need to explore complex techniques.
Machine Learning Enhances Algorithms for Quantifying Non-Equilibrium Dynamics in Correlation Spectroscopy Experiments to Reach Frame-Rate-Limited Time Resolution
Jan 17, 2022Analysis of X-ray Photon Correlation Spectroscopy (XPCS) data for non-equilibrium dynamics often requires manual binning of age regions of an intensity-intensity correlation function. This leads to a loss of temporal resolution and accumulation of systematic error for the parameters quantifying the dynamics, especially in cases with considerable noise. Moreover, the experiments with high data collection rates create the need for automated online analysis, where manual binning is not possible. Here, we integrate a denoising autoencoder model into algorithms for analysis of non-equilibrium two-time intensity-intensity correlation functions. The model can be applied to an input of an arbitrary size. Noise reduction allows to extract the parameters that characterize the sample dynamics with temporal resolution limited only by frame rates. Not only does it improve the quantitative usage of the data, but it also creates the potential for automating the analytical workflow. Various approaches for uncertainty quantification and extension of the model for anomalies detection are discussed.
Texture Generation Using Graph Generative Adversarial Network And Differentiable Rendering
Jun 17, 2022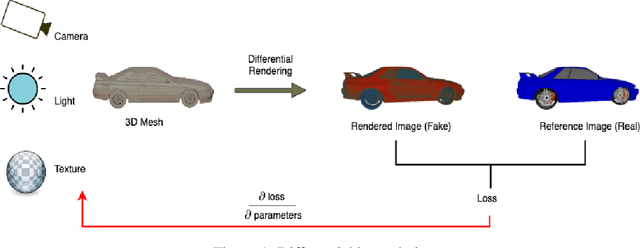
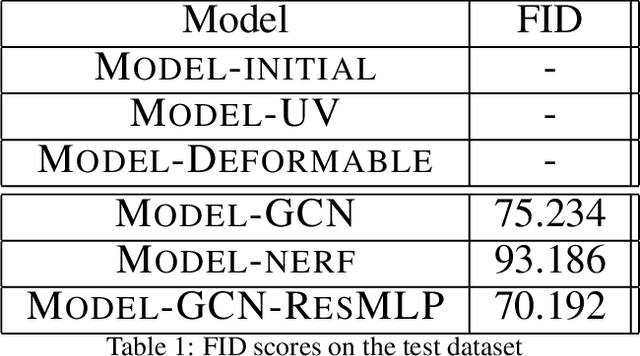
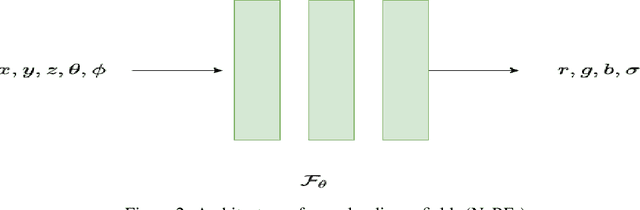
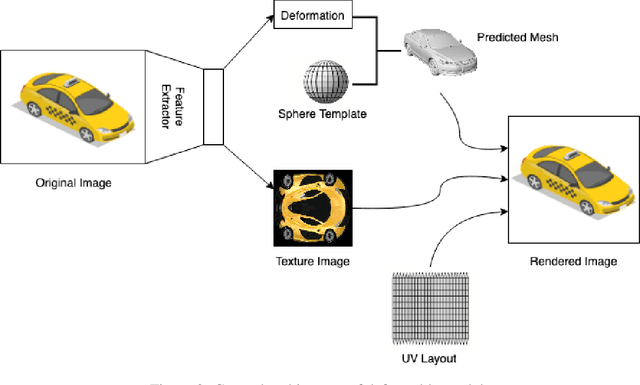
Novel texture synthesis for existing 3D mesh models is an important step towards photo realistic asset generation for existing simulators. But existing methods inherently work in the 2D image space which is the projection of the 3D space from a given camera perspective. These methods take camera angle, 3D model information, lighting information and generate photorealistic 2D image. To generate a photorealistic image from another perspective or lighting, we need to make a computationally expensive forward pass each time we change the parameters. Also, it is hard to generate such images for a simulator that can satisfy the temporal constraints the sequences of images should be similar but only need to change the viewpoint of lighting as desired. The solution can not be directly integrated with existing tools like Blender and Unreal Engine. Manual solution is expensive and time consuming. We thus present a new system called a graph generative adversarial network (GGAN) that can generate textures which can be directly integrated into a given 3D mesh models with tools like Blender and Unreal Engine and can be simulated from any perspective and lighting condition easily.
A Relative Church-Turing-Deutsch Thesis from Special Relativity and Undecidability
Jun 13, 2022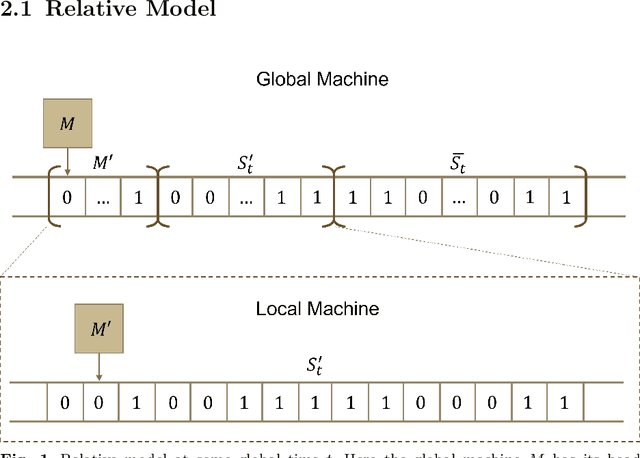
Beginning with Turing's seminal work in 1950, artificial intelligence proposes that consciousness can be simulated by a Turing machine. This implies a potential theory of everything where the universe is a simulation on a computer, which begs the question of whether we can prove we exist in a simulation. In this work, we construct a relative model of computation where a computable \textit{local} machine is simulated by a \textit{global}, classical Turing machine. We show that the problem of the local machine computing \textbf{simulation properties} of its global simulator is undecidable in the same sense as the Halting problem. Then, we show that computing the time, space, or error accumulated by the global simulator are simulation properties and therefore are undecidable. These simulation properties give rise to special relativistic effects in the relative model which we use to construct a relative Church-Turing-Deutsch thesis where a global, classical Turing machine computes quantum mechanics for a local machine with the same constant-time local computational complexity as experienced in our universe.
Bio-inspired Intelligence with Applications to Robotics: A Survey
Jun 17, 2022
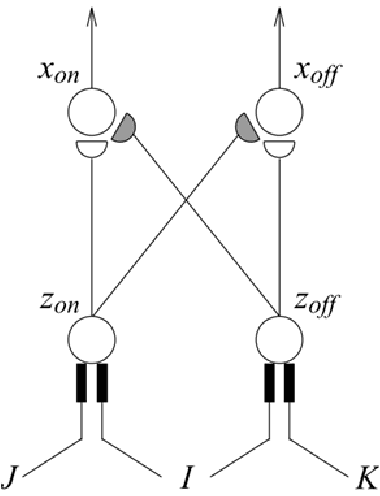
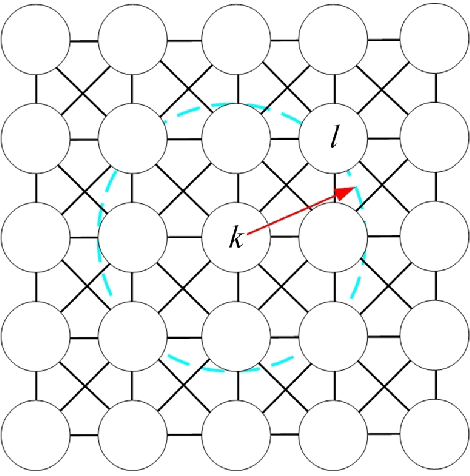
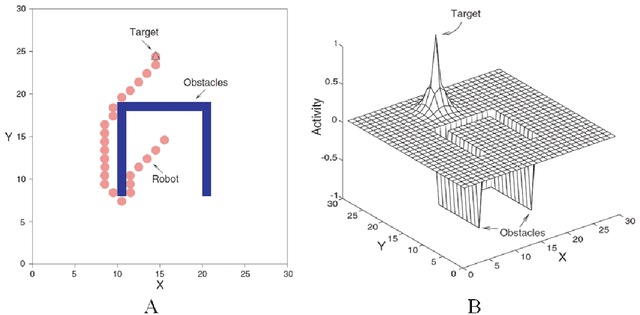
In the past decades, considerable attention has been paid to bio-inspired intelligence and its applications to robotics. This paper provides a comprehensive survey of bio-inspired intelligence, with a focus on neurodynamics approaches, to various robotic applications, particularly to path planning and control of autonomous robotic systems. Firstly, the bio-inspired shunting model and its variants (additive model and gated dipole model) are introduced, and their main characteristics are given in detail. Then, two main neurodynamics applications to real-time path planning and control of various robotic systems are reviewed. A bio-inspired neural network framework, in which neurons are characterized by the neurodynamics models, is discussed for mobile robots, cleaning robots, and underwater robots. The bio-inspired neural network has been widely used in real-time collision-free navigation and cooperation without any learning procedures, global cost functions, and prior knowledge of the dynamic environment. In addition, bio-inspired backstepping controllers for various robotic systems, which are able to eliminate the speed jump when a large initial tracking error occurs, are further discussed. Finally, the current challenges and future research directions are discussed in this paper.
Retention time trajectory matching for target compound peak identification in chromatographic analysis
Jul 16, 2021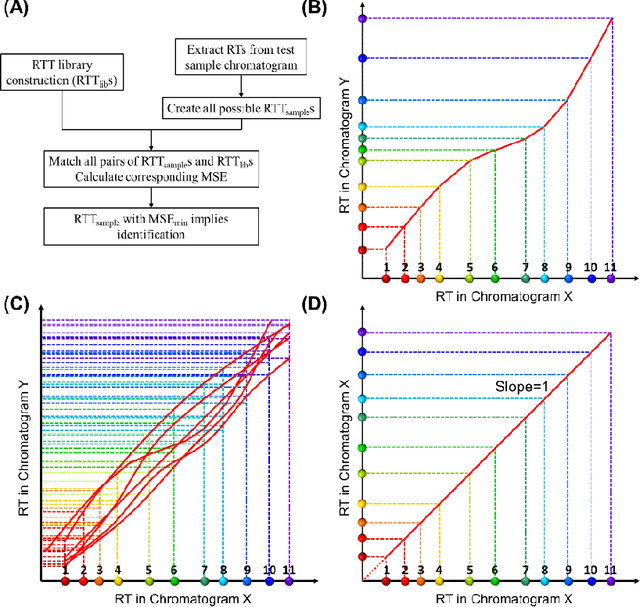
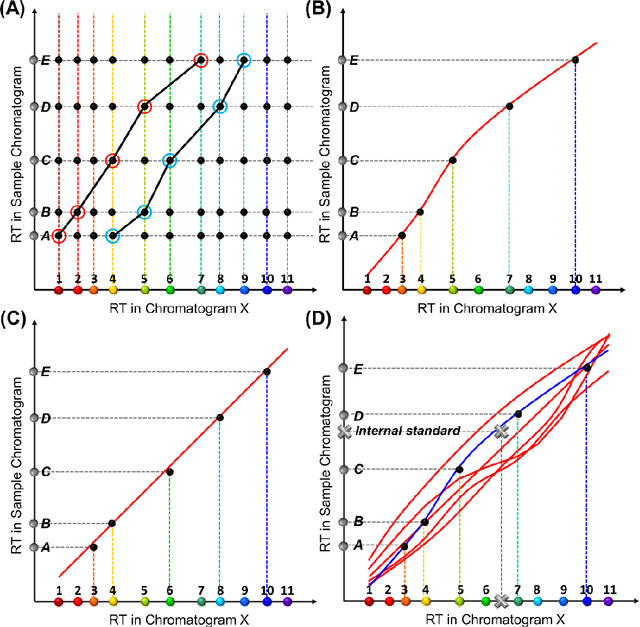
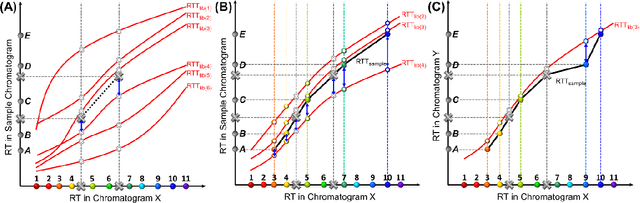
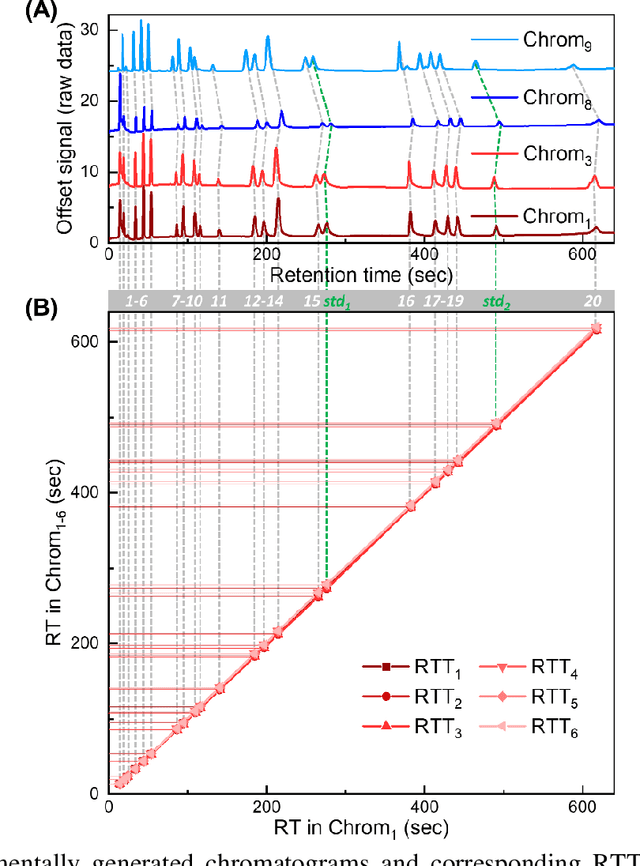
Retention time drift caused by fluctuations in physical factors such as temperature ramping rate and carrier gas flow rate is ubiquitous in chromatographic measurements. Proper peak identification and alignment across different chromatograms is critical prior to any subsequent analysis. This work introduces a peak identification method called retention time trajectory (RTT) matching, which uses chromatographic retention times as the only input and identifies peaks associated with any subset of a predefined set of target compounds. RTT matching is also capable of reporting interferents. An RTT is a 2-dimensional (2D) curve formed uniquely by the retention times of the chromatographic peaks. The RTTs obtained from the chromatogram of a test sample and of pre-characterized library are matched and statistically compared. The best matched pair implies identification. Unlike most existing peak alignment methods, no mathematical warping or transformations are involved. Based on the experimentally characterized RTT, an RTT hybridization method is developed to rapidly generate more RTTs without performing actual time-consuming chromatographic measurements. This enables successful identification even for chromatograms with serious retention time drift. Experimentally obtained gas chromatograms and publicly available fruit metabolomics liquid chromatograms are used to generate over two trillions of tests that validate the proposed method, demonstrating real-time peak/interferent identification.
TPARN: Triple-path Attentive Recurrent Network for Time-domain Multichannel Speech Enhancement
Oct 20, 2021
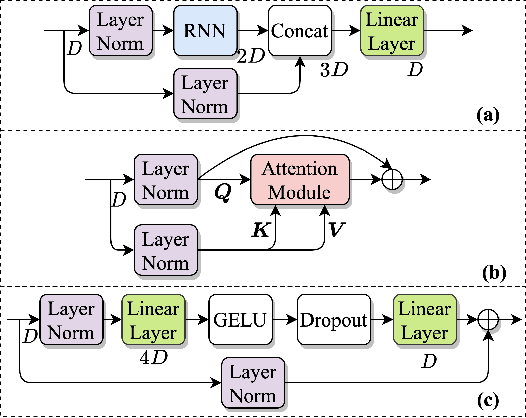
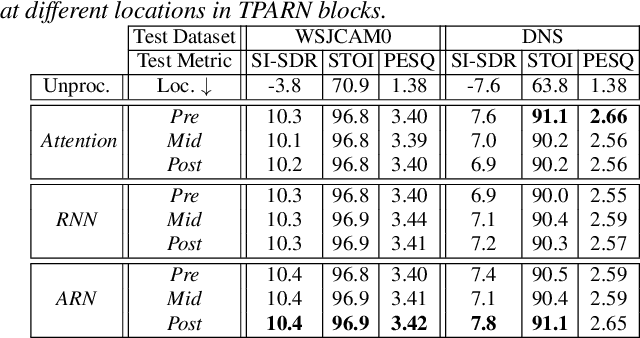
In this work, we propose a new model called triple-path attentive recurrent network (TPARN) for multichannel speech enhancement in the time domain. TPARN extends a single-channel dual-path network to a multichannel network by adding a third path along the spatial dimension. First, TPARN processes speech signals from all channels independently using a dual-path attentive recurrent network (ARN), which is a recurrent neural network (RNN) augmented with self-attention. Next, an ARN is introduced along the spatial dimension for spatial context aggregation. TPARN is designed as a multiple-input and multiple-output architecture to enhance all input channels simultaneously. Experimental results demonstrate the superiority of TPARN over existing state-of-the-art approaches.
Origin of life from a maker's perspective -- focus on protocellular compartments in bottom-up synthetic biology
Jul 14, 2022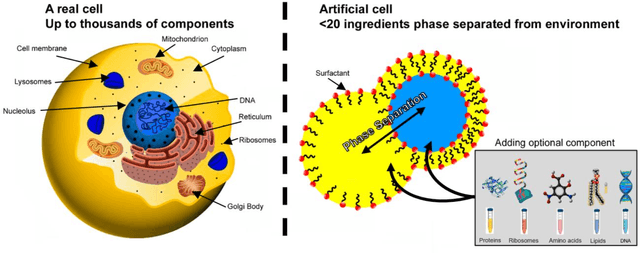

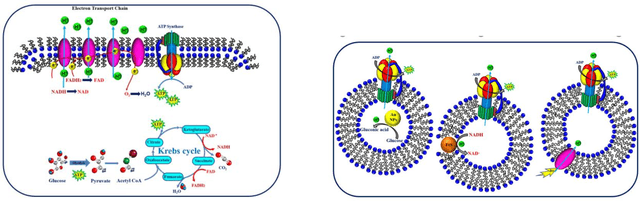
The origin of life is shrouded in mystery, with few surviving clues, obscured by evolutionary competition. Previous reviews have touched on the complementary approaches of top-down and bottom-up synthetic biology to augment our understanding of living systems. Here we point out the synergies between these fields, especially between bottom-up synthetic biology and origin of life research. We explore recent progress made in artificial cell compartmentation in line with the crowded cell, its metabolism, as well as cycles of growth and division, and how those efforts are starting to be combined. Though the complexity of current life is among its most striking characteristics, none of life's essential features require it, and they are unlikely to have emerged thus complex from the beginning. Rather than recovering the one true origin lost in time, current research converges towards reproducing the emergence of minimal life, by teasing out how complexity and evolution may arise from a set of essential components.
A Novel Multi-Agent Scheduling Mechanism for Adaptation of Production Plans in Case of Supply Chain Disruptions
Jun 23, 2022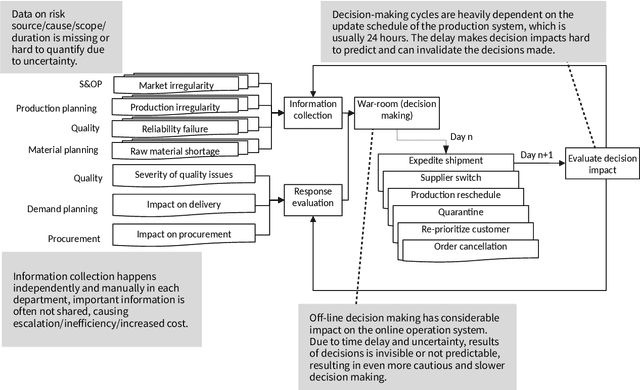
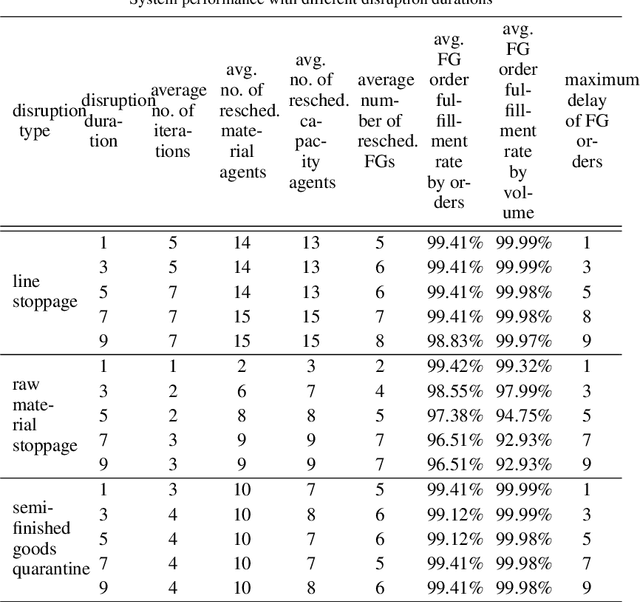
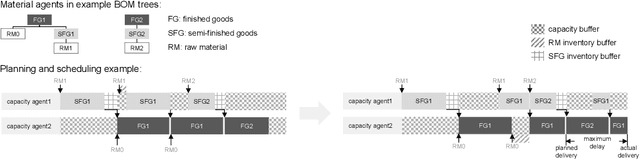
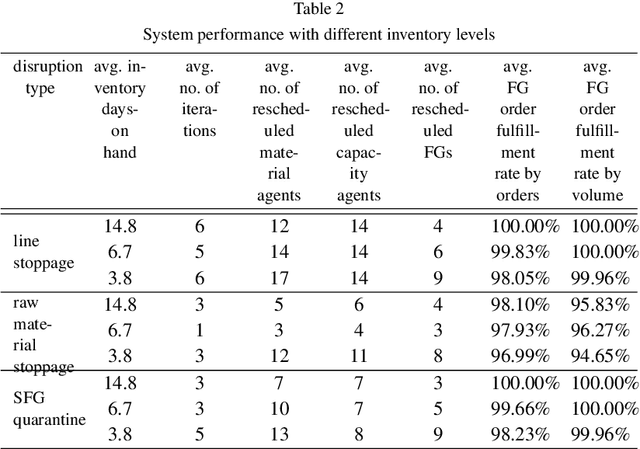
Manufacturing companies typically use sophisticated production planning systems optimizing production steps, often delivering near-optimal solutions. As a downside for delivering a near-optimal schedule, planning systems have high computational demands resulting in hours of computation. Under normal circumstances this is not issue if there is enough buffer time before implementation of the schedule (e.g. at night for the next day). However, in case of unexpected disruptions such as delayed part deliveries or defectively manufactured goods, the planned schedule may become invalid and swift replanning becomes necessary. Such immediate replanning is unsuited for existing optimal planners due to the computational requirements. This paper proposes a novel solution that can effectively and efficiently perform replanning in case of different types of disruptions using an existing plan. The approach is based on the idea to adhere to the existing schedule as much as possible, adapting it based on limited local changes. For that purpose an agent-based scheduling mechanism has been devised, in which agents represent materials and production sites and use local optimization techniques and negotiations to generate an adapted (sufficient, but non-optimal) schedule. The approach has been evaluated using real production data from Huawei, showing that efficient schedules are produced in short time. The system has been implemented as proof of concept and is currently reimplemented and transferred to a production system based on the Jadex agent platform.
On the Learnability of Physical Concepts: Can a Neural Network Understand What's Real?
Aug 04, 2022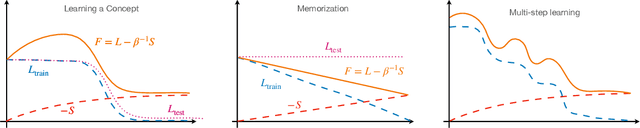
We revisit the classic signal-to-symbol barrier in light of the remarkable ability of deep neural networks to generate realistic synthetic data. DeepFakes and spoofing highlight the feebleness of the link between physical reality and its abstract representation, whether learned by a digital computer or a biological agent. Starting from a widely applicable definition of abstract concept, we show that standard feed-forward architectures cannot capture but trivial concepts, regardless of the number of weights and the amount of training data, despite being extremely effective classifiers. On the other hand, architectures that incorporate recursion can represent a significantly larger class of concepts, but may still be unable to learn them from a finite dataset. We qualitatively describe the class of concepts that can be "understood" by modern architectures trained with variants of stochastic gradient descent, using a (free energy) Lagrangian to measure information complexity. Even if a concept has been understood, however, a network has no means of communicating its understanding to an external agent, except through continuous interaction and validation. We then characterize physical objects as abstract concepts and use the previous analysis to show that physical objects can be encoded by finite architectures. However, to understand physical concepts, sensors must provide persistently exciting observations, for which the ability to control the data acquisition process is essential (active perception). The importance of control depends on the modality, benefiting visual more than acoustic or chemical perception. Finally, we conclude that binding physical entities to digital identities is possible in finite time with finite resources, solving in principle the signal-to-symbol barrier problem, but we highlight the need for continuous validation.