 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Neural-Sim: Learning to Generate Training Data with NeRF
Jul 22, 2022
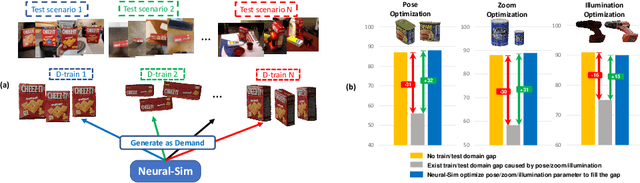
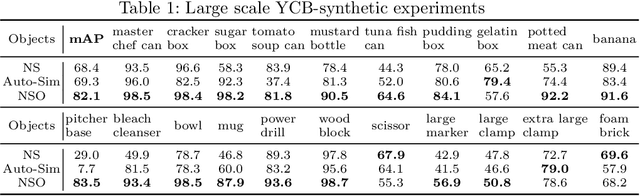

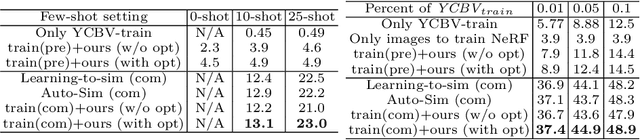
Training computer vision models usually requires collecting and labeling vast amounts of imagery under a diverse set of scene configurations and properties. This process is incredibly time-consuming, and it is challenging to ensure that the captured data distribution maps well to the target domain of an application scenario. Recently, synthetic data has emerged as a way to address both of these issues. However, existing approaches either require human experts to manually tune each scene property or use automatic methods that provide little to no control; this requires rendering large amounts of random data variations, which is slow and is often suboptimal for the target domain. We present the first fully differentiable synthetic data pipeline that uses Neural Radiance Fields (NeRFs) in a closed-loop with a target application's loss function. Our approach generates data on-demand, with no human labor, to maximize accuracy for a target task. We illustrate the effectiveness of our method on synthetic and real-world object detection tasks. We also introduce a new "YCB-in-the-Wild" dataset and benchmark that provides a test scenario for object detection with varied poses in real-world environments.
Time-Aware Q-Networks: Resolving Temporal Irregularity for Deep Reinforcement Learning
May 06, 2021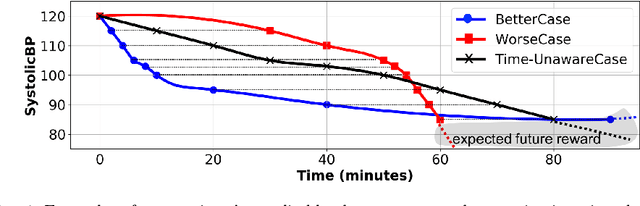
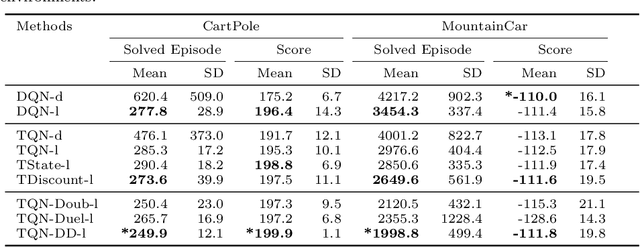
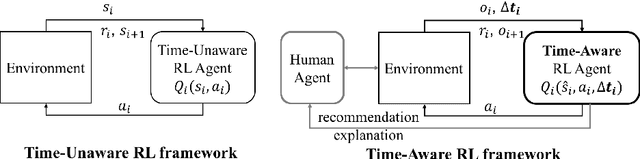
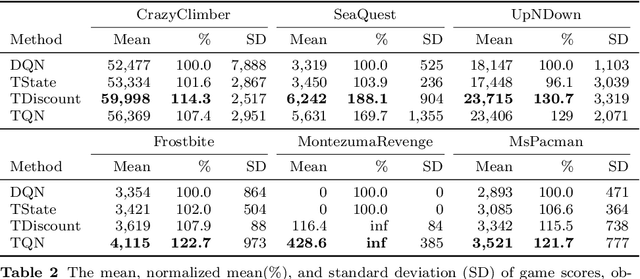
Deep Reinforcement Learning (DRL) has shown outstanding performance on inducing effective action policies that maximize expected long-term return on many complex tasks. Much of DRL work has been focused on sequences of events with discrete time steps and ignores the irregular time intervals between consecutive events. Given that in many real-world domains, data often consists of temporal sequences with irregular time intervals, and it is important to consider the time intervals between temporal events to capture latent progressive patterns of states. In this work, we present a general Time-Aware RL framework: Time-aware Q-Networks (TQN), which takes into account physical time intervals within a deep RL framework. TQN deals with time irregularity from two aspects: 1) elapsed time in the past and an expected next observation time for time-aware state approximation, and 2) action time window for the future for time-aware discounting of rewards. Experimental results show that by capturing the underlying structures in the sequences with time irregularities from both aspects, TQNs significantly outperform DQN in four types of contexts with irregular time intervals. More specifically, our results show that in classic RL tasks such as CartPole and MountainCar and Atari benchmark with randomly segmented time intervals, time-aware discounting alone is more important while in the real-world tasks such as nuclear reactor operation and septic patient treatment with intrinsic time intervals, both time-aware state and time-aware discounting are crucial. Moreover, to improve the agent's learning capacity, we explored three boosting methods: Double networks, Dueling networks, and Prioritized Experience Replay, and our results show that for the two real-world tasks, combining all three boosting methods with TQN is especially effective.
CuDi: Curve Distillation for Efficient and Controllable Exposure Adjustment
Jul 28, 2022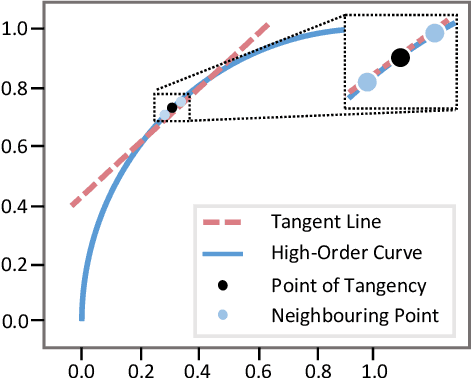


We present Curve Distillation, CuDi, for efficient and controllable exposure adjustment without the requirement of paired or unpaired data during training. Our method inherits the zero-reference learning and curve-based framework from an effective low-light image enhancement method, Zero-DCE, with further speed up in its inference speed, reduction in its model size, and extension to controllable exposure adjustment. The improved inference speed and lightweight model are achieved through novel curve distillation that approximates the time-consuming iterative operation in the conventional curve-based framework by high-order curve's tangent line. The controllable exposure adjustment is made possible with a new self-supervised spatial exposure control loss that constrains the exposure levels of different spatial regions of the output to be close to the brightness distribution of an exposure map serving as an input condition. Different from most existing methods that can only correct either underexposed or overexposed photos, our approach corrects both underexposed and overexposed photos with a single model. Notably, our approach can additionally adjust the exposure levels of a photo globally or locally with the guidance of an input condition exposure map, which can be pre-defined or manually set in the inference stage. Through extensive experiments, we show that our method is appealing for its fast, robust, and flexible performance, outperforming state-of-the-art methods in real scenes. Project page: https://li-chongyi.github.io/CuDi_files/.
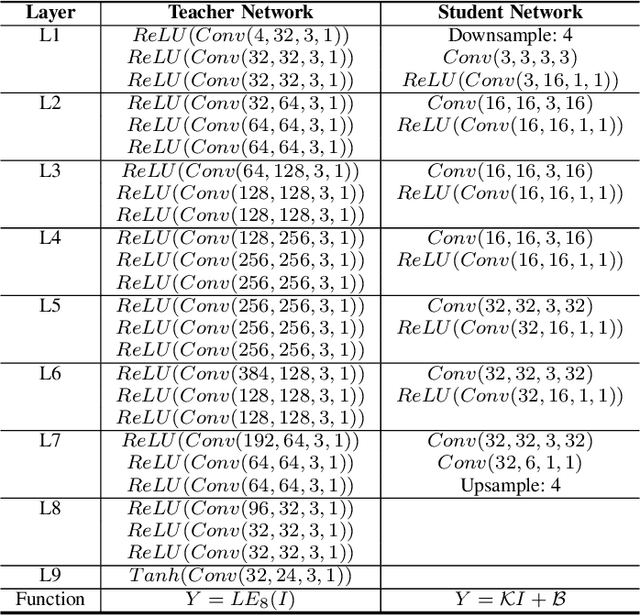
Live Stream Temporally Embedded 3D Human Body Pose and Shape Estimation
Jul 25, 2022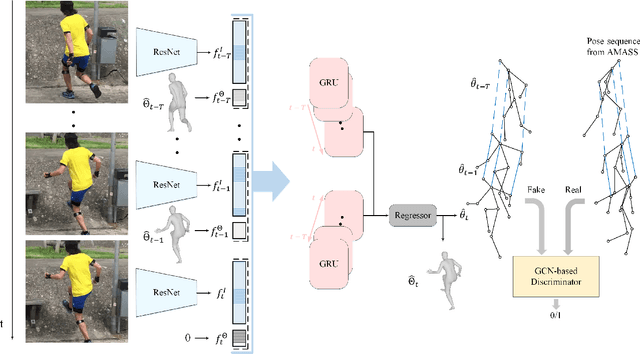

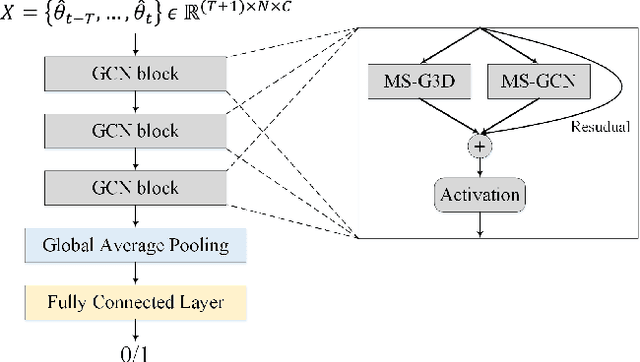
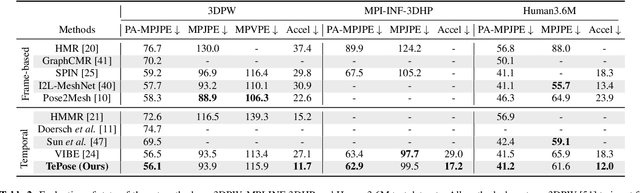
3D Human body pose and shape estimation within a temporal sequence can be quite critical for understanding human behavior. Despite the significant progress in human pose estimation in the recent years, which are often based on single images or videos, human motion estimation on live stream videos is still a rarely-touched area considering its special requirements for real-time output and temporal consistency. To address this problem, we present a temporally embedded 3D human body pose and shape estimation (TePose) method to improve the accuracy and temporal consistency of pose estimation in live stream videos. TePose uses previous predictions as a bridge to feedback the error for better estimation in the current frame and to learn the correspondence between data frames and predictions in the history. A multi-scale spatio-temporal graph convolutional network is presented as the motion discriminator for adversarial training using datasets without any 3D labeling. We propose a sequential data loading strategy to meet the special start-to-end data processing requirement of live stream. We demonstrate the importance of each proposed module with extensive experiments. The results show the effectiveness of TePose on widely-used human pose benchmarks with state-of-the-art performance.
Semi-supervised Predictive Clustering Trees for (Hierarchical) Multi-label Classification
Jul 19, 2022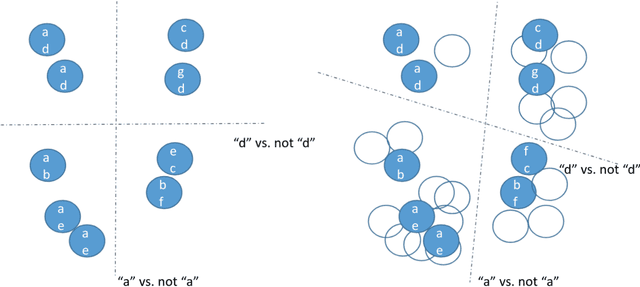

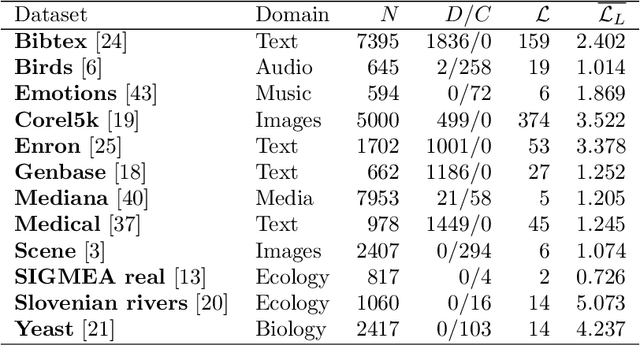
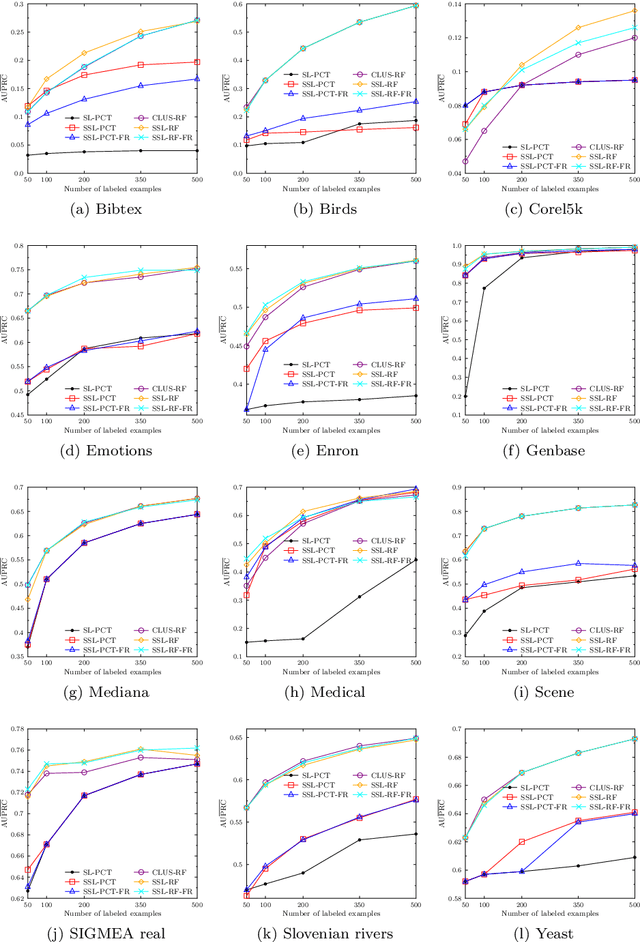
Semi-supervised learning (SSL) is a common approach to learning predictive models using not only labeled examples, but also unlabeled examples. While SSL for the simple tasks of classification and regression has received a lot of attention from the research community, this is not properly investigated for complex prediction tasks with structurally dependent variables. This is the case of multi-label classification and hierarchical multi-label classification tasks, which may require additional information, possibly coming from the underlying distribution in the descriptive space provided by unlabeled examples, to better face the challenging task of predicting simultaneously multiple class labels. In this paper, we investigate this aspect and propose a (hierarchical) multi-label classification method based on semi-supervised learning of predictive clustering trees. We also extend the method towards ensemble learning and propose a method based on the random forest approach. Extensive experimental evaluation conducted on 23 datasets shows significant advantages of the proposed method and its extension with respect to their supervised counterparts. Moreover, the method preserves interpretability and reduces the time complexity of classical tree-based models.
A Novel Meta-predictor based Algorithm for Testing VLSI Circuits
Jul 22, 2022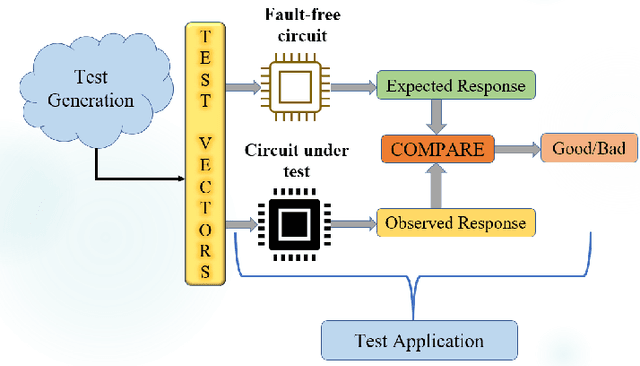
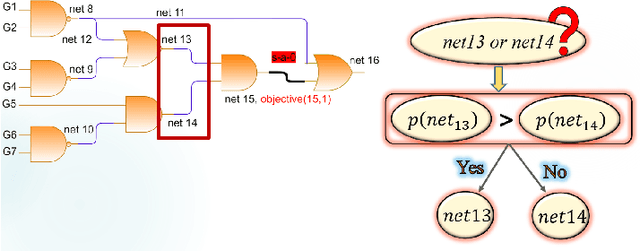
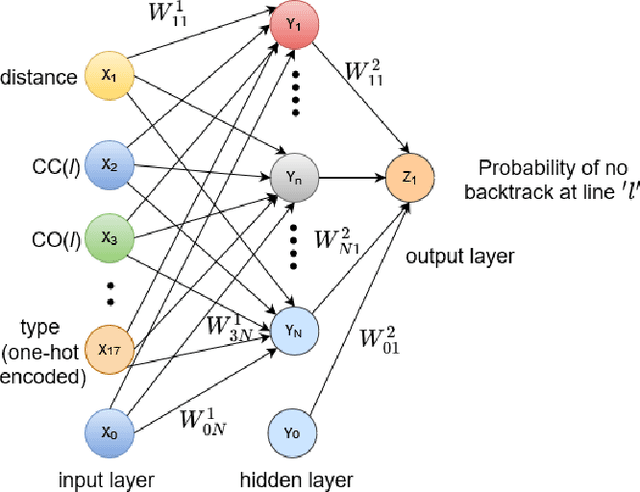
Testing of integrated circuits (IC) is a highly expensive process but also the most important one in determining the defect level of an IC. Manufacturing defects in the IC are modeled using stuck-at-fault models. Stuck-at-fault models cover most of the physical faults that occur during the manufacturing process. With decreasing feature sizes due to the advancement of semiconductor technology, the defects are also getting smaller in size. Tests for these hard-to-detect defects are generated using deterministic test generation (DTG) algorithms. Our work aims at reducing the cost of Path Oriented Decision Making: PODEM (a DTG algorithm) without compromising the test quality. We trained a meta predictor to choose the best model given the circuit and the target net. This ensemble chooses the best probability prediction model with a 95% accuracy. This leads to a reduced number of backtracking decisions and much better performance of PODEM in terms of its CPU time. We show that our ML- guided PODEM algorithm with a meta predictor outperforms the baseline PODEM by 34% and other state-of-the-art ML-guided algorithms by at least 15% for ISCAS85 benchmark circuits.
Exploring Attention-Aware Network Resource Allocation for Customized Metaverse Services
Jul 31, 2022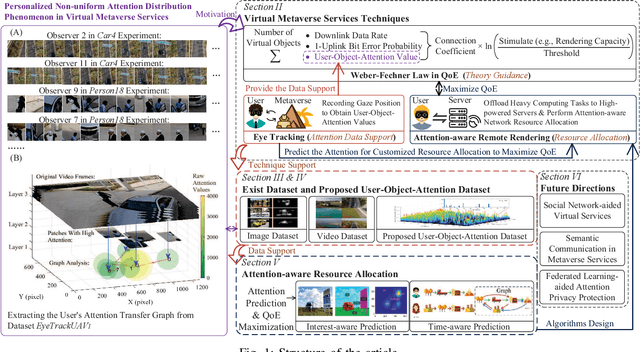
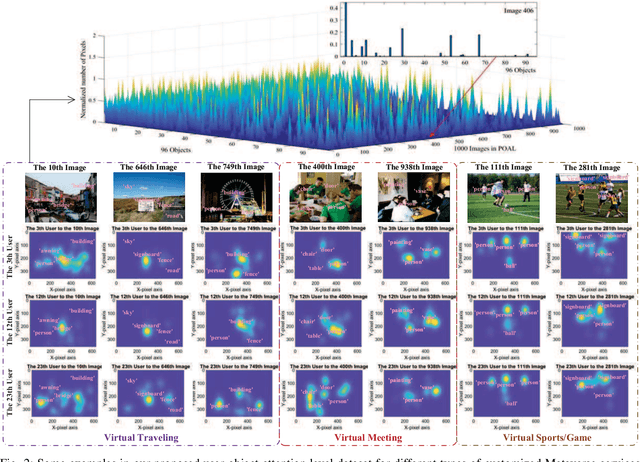
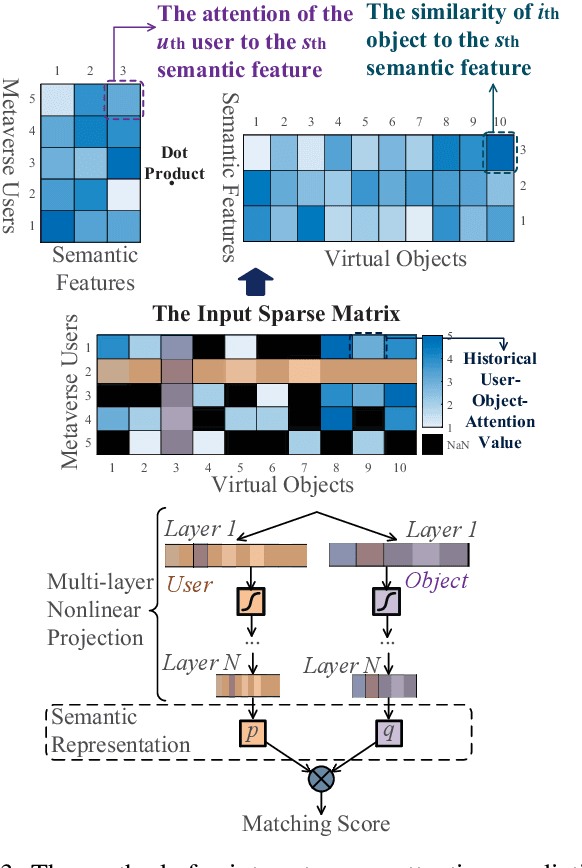
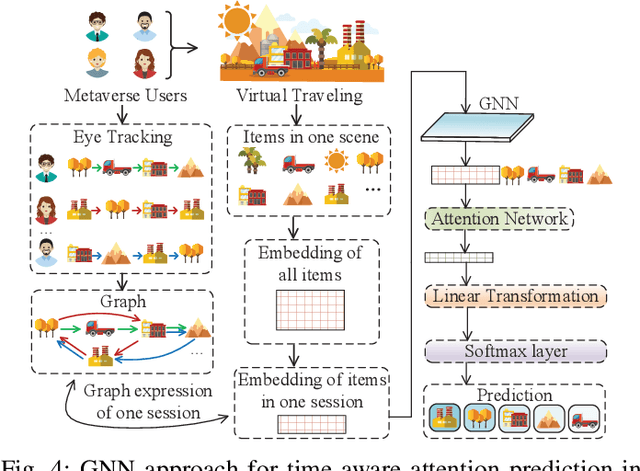
Emerging with the support of computing and communications technologies, Metaverse is expected to bring users unprecedented service experiences. However, the increase in the number of Metaverse users places a heavy demand on network resources, especially for Metaverse services that are based on graphical extended reality and require rendering a plethora of virtual objects. To make efficient use of network resources and improve the Quality-of-Experience (QoE), we design an attention-aware network resource allocation scheme to achieve customized Metaverse services. The aim is to allocate more network resources to virtual objects in which users are more interested. We first discuss several key techniques related to Metaverse services, including QoE analysis, eye-tracking, and remote rendering. We then review existing datasets and propose the user-object-attention level (UOAL) dataset that contains the ground truth attention of 30 users to 96 objects in 1,000 images. A tutorial on how to use UOAL is presented. With the help of UOAL, we propose an attention-aware network resource allocation algorithm that has two steps, i.e., attention prediction and QoE maximization. Specially, we provide an overview of the designs of two types of attention prediction methods, i.e., interest-aware and time-aware prediction. By using the predicted user-object-attention values, network resources such as the rendering capacity of edge devices can be allocated optimally to maximize the QoE. Finally, we propose promising research directions related to Metaverse services.
Partial Disentanglement via Mechanism Sparsity
Jul 15, 2022

Disentanglement via mechanism sparsity was introduced recently as a principled approach to extract latent factors without supervision when the causal graph relating them in time is sparse, and/or when actions are observed and affect them sparsely. However, this theory applies only to ground-truth graphs satisfying a specific criterion. In this work, we introduce a generalization of this theory which applies to any ground-truth graph and specifies qualitatively how disentangled the learned representation is expected to be, via a new equivalence relation over models we call consistency. This equivalence captures which factors are expected to remain entangled and which are not based on the specific form of the ground-truth graph. We call this weaker form of identifiability partial disentanglement. The graphical criterion that allows complete disentanglement, proposed in an earlier work, can be derived as a special case of our theory. Finally, we enforce graph sparsity with constrained optimization and illustrate our theory and algorithm in simulations.
ABCinML: Anticipatory Bias Correction in Machine Learning Applications
Jun 14, 2022
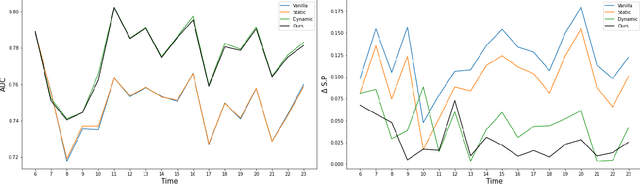

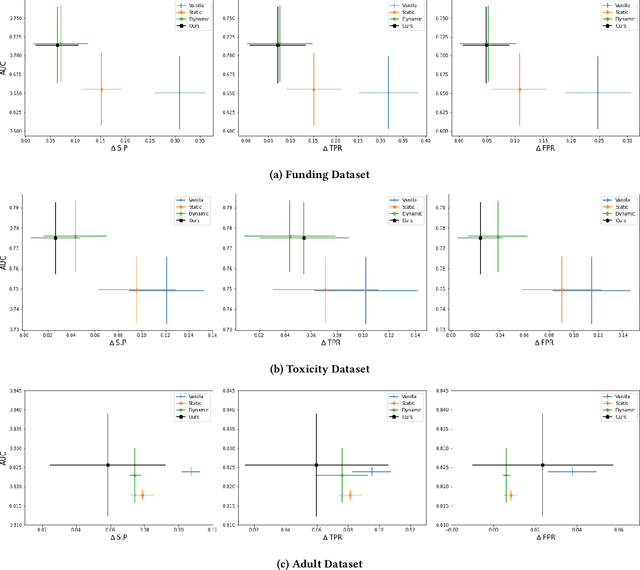
The idealization of a static machine-learned model, trained once and deployed forever, is not practical. As input distributions change over time, the model will not only lose accuracy, any constraints to reduce bias against a protected class may fail to work as intended. Thus, researchers have begun to explore ways to maintain algorithmic fairness over time. One line of work focuses on dynamic learning: retraining after each batch, and the other on robust learning which tries to make algorithms robust against all possible future changes. Dynamic learning seeks to reduce biases soon after they have occurred and robust learning often yields (overly) conservative models. We propose an anticipatory dynamic learning approach for correcting the algorithm to mitigate bias before it occurs. Specifically, we make use of anticipations regarding the relative distributions of population subgroups (e.g., relative ratios of male and female applicants) in the next cycle to identify the right parameters for an importance weighing fairness approach. Results from experiments over multiple real-world datasets suggest that this approach has promise for anticipatory bias correction.
Learning to Singulate Layers of Cloth using Tactile Feedback
Jul 22, 2022
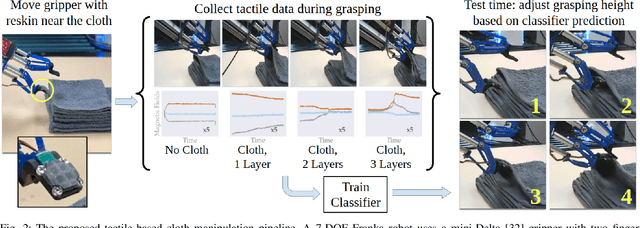


Robotic manipulation of cloth has applications ranging from fabrics manufacturing to handling blankets and laundry. Cloth manipulation is challenging for robots largely due to their high degrees of freedom, complex dynamics, and severe self-occlusions when in folded or crumpled configurations. Prior work on robotic manipulation of cloth relies primarily on vision sensors alone, which may pose challenges for fine-grained manipulation tasks such as grasping a desired number of cloth layers from a stack of cloth. In this paper, we propose to use tactile sensing for cloth manipulation; we attach a tactile sensor (ReSkin) to one of the two fingertips of a Franka robot and train a classifier to determine whether the robot is grasping a specific number of cloth layers. During test-time experiments, the robot uses this classifier as part of its policy to grasp one or two cloth layers using tactile feedback to determine suitable grasping points. Experimental results over 180 physical trials suggest that the proposed method outperforms baselines that do not use tactile feedback and has better generalization to unseen cloth compared to methods that use image classifiers. Code, data, and videos are available at https://sites.google.com/view/reskin-cloth.