 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Online Modeling and Control of Soft Multi-fingered Grippers via Koopman Operator Theory
Jun 21, 2022



Soft grippers are gaining momentum across applications due to their flexibility and dexterity. However, the infinite-dimensionality and non-linearity associated with soft robots challenge modeling and closed-loop control of soft grippers to perform grasping tasks. To solve this problem, data-driven methods have been proposed. Most data-driven methods rely on intensive model learning in simulation or offline, and as such it may be hard to generalize across different settings not explicitly trained upon and in physical robot testing where online control is required. In this paper, we propose an online modeling and control algorithm that utilizes Koopman operator theory to update an estimated model of the underlying dynamics at each time step in real-time. The learned and continuously updated models are then embedded into an online Model Predictive Control (MPC) structure and deployed onto soft multi-fingered robotic grippers. To evaluate the performance, the prediction accuracy of our approach is first compared against other model-extraction methods among different datasets. Next, the online modeling and control algorithm is tested experimentally with a soft 3-fingered gripper grasping objects of various shapes and weights unknown to the controller initially. Results indicate a high success ratio in grasping different objects using the proposed method. Sample trials can be viewed at https://youtu.be/i2hCMX7zSKQ.
Live Stream Temporally Embedded 3D Human Body Pose and Shape Estimation
Jul 25, 2022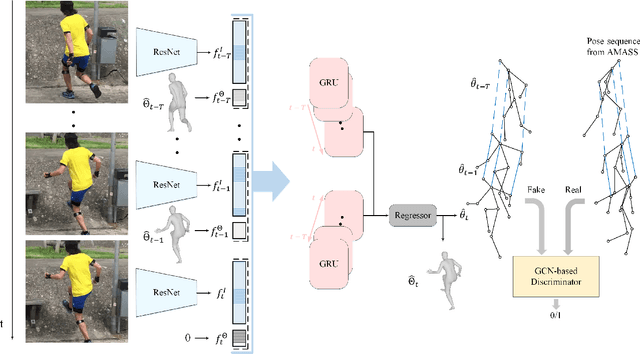

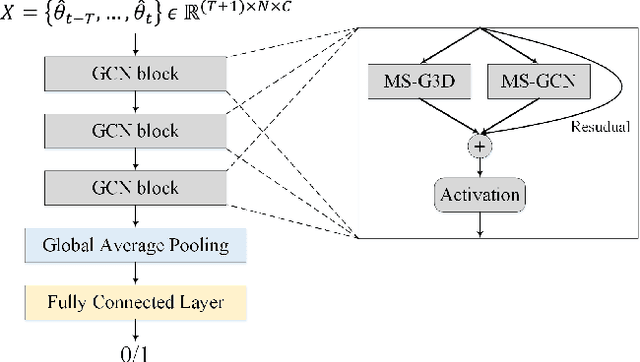
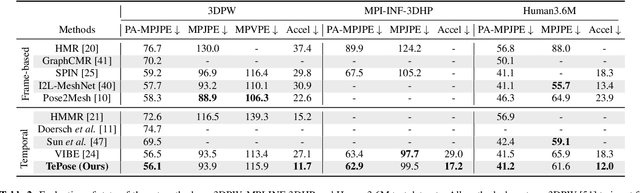
3D Human body pose and shape estimation within a temporal sequence can be quite critical for understanding human behavior. Despite the significant progress in human pose estimation in the recent years, which are often based on single images or videos, human motion estimation on live stream videos is still a rarely-touched area considering its special requirements for real-time output and temporal consistency. To address this problem, we present a temporally embedded 3D human body pose and shape estimation (TePose) method to improve the accuracy and temporal consistency of pose estimation in live stream videos. TePose uses previous predictions as a bridge to feedback the error for better estimation in the current frame and to learn the correspondence between data frames and predictions in the history. A multi-scale spatio-temporal graph convolutional network is presented as the motion discriminator for adversarial training using datasets without any 3D labeling. We propose a sequential data loading strategy to meet the special start-to-end data processing requirement of live stream. We demonstrate the importance of each proposed module with extensive experiments. The results show the effectiveness of TePose on widely-used human pose benchmarks with state-of-the-art performance.
Exploring Attention-Aware Network Resource Allocation for Customized Metaverse Services
Jul 31, 2022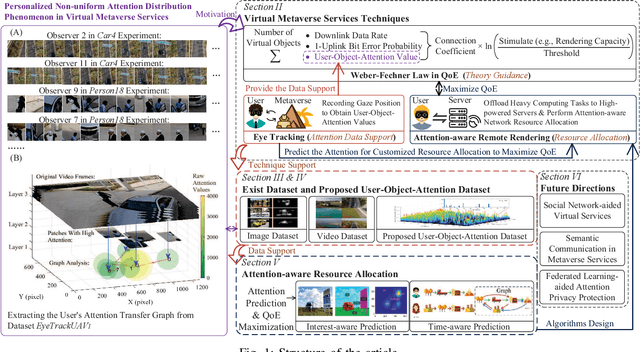
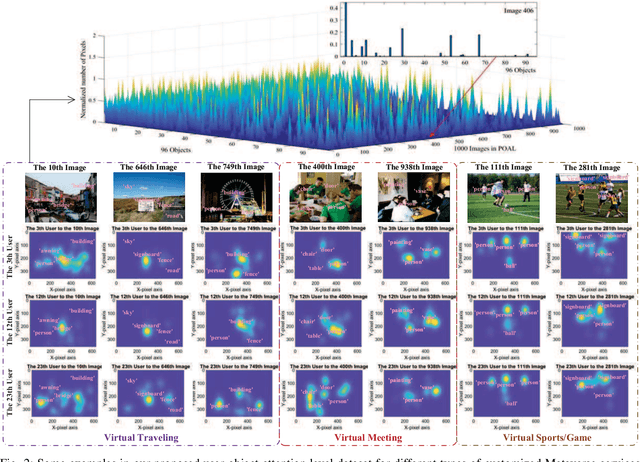
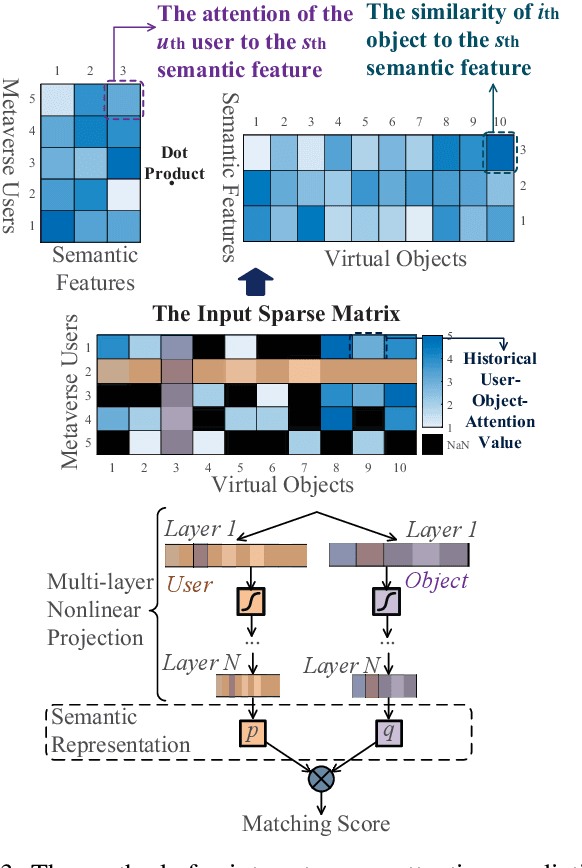
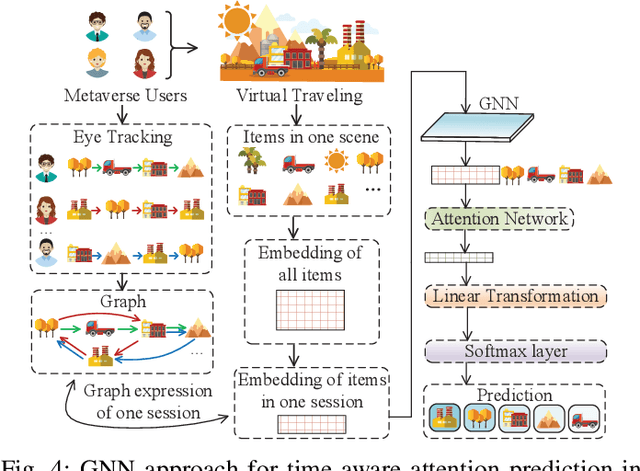
Emerging with the support of computing and communications technologies, Metaverse is expected to bring users unprecedented service experiences. However, the increase in the number of Metaverse users places a heavy demand on network resources, especially for Metaverse services that are based on graphical extended reality and require rendering a plethora of virtual objects. To make efficient use of network resources and improve the Quality-of-Experience (QoE), we design an attention-aware network resource allocation scheme to achieve customized Metaverse services. The aim is to allocate more network resources to virtual objects in which users are more interested. We first discuss several key techniques related to Metaverse services, including QoE analysis, eye-tracking, and remote rendering. We then review existing datasets and propose the user-object-attention level (UOAL) dataset that contains the ground truth attention of 30 users to 96 objects in 1,000 images. A tutorial on how to use UOAL is presented. With the help of UOAL, we propose an attention-aware network resource allocation algorithm that has two steps, i.e., attention prediction and QoE maximization. Specially, we provide an overview of the designs of two types of attention prediction methods, i.e., interest-aware and time-aware prediction. By using the predicted user-object-attention values, network resources such as the rendering capacity of edge devices can be allocated optimally to maximize the QoE. Finally, we propose promising research directions related to Metaverse services.
A Novel Meta-predictor based Algorithm for Testing VLSI Circuits
Jul 22, 2022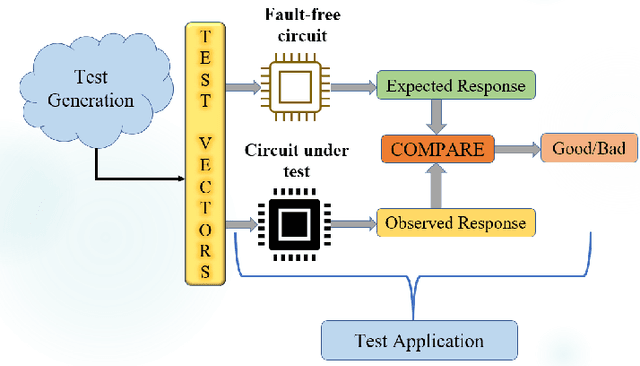
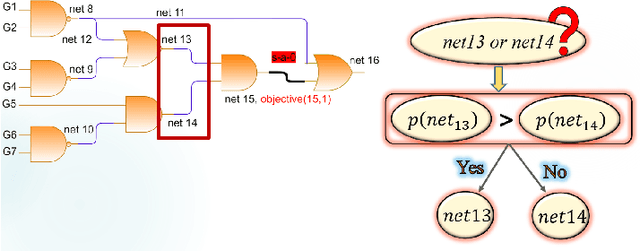
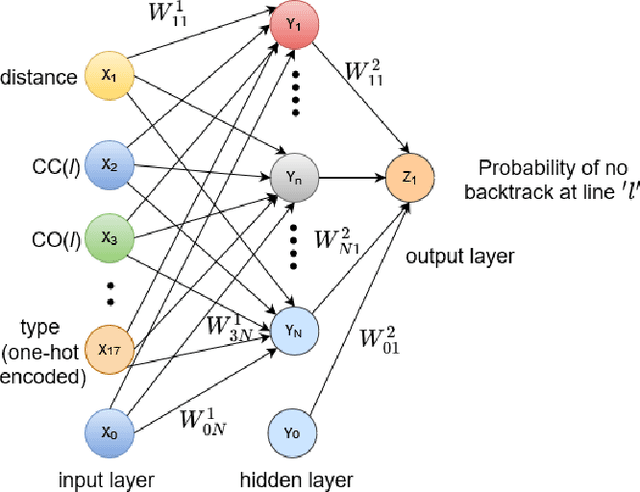
Testing of integrated circuits (IC) is a highly expensive process but also the most important one in determining the defect level of an IC. Manufacturing defects in the IC are modeled using stuck-at-fault models. Stuck-at-fault models cover most of the physical faults that occur during the manufacturing process. With decreasing feature sizes due to the advancement of semiconductor technology, the defects are also getting smaller in size. Tests for these hard-to-detect defects are generated using deterministic test generation (DTG) algorithms. Our work aims at reducing the cost of Path Oriented Decision Making: PODEM (a DTG algorithm) without compromising the test quality. We trained a meta predictor to choose the best model given the circuit and the target net. This ensemble chooses the best probability prediction model with a 95% accuracy. This leads to a reduced number of backtracking decisions and much better performance of PODEM in terms of its CPU time. We show that our ML- guided PODEM algorithm with a meta predictor outperforms the baseline PODEM by 34% and other state-of-the-art ML-guided algorithms by at least 15% for ISCAS85 benchmark circuits.
Semi-supervised Predictive Clustering Trees for (Hierarchical) Multi-label Classification
Jul 19, 2022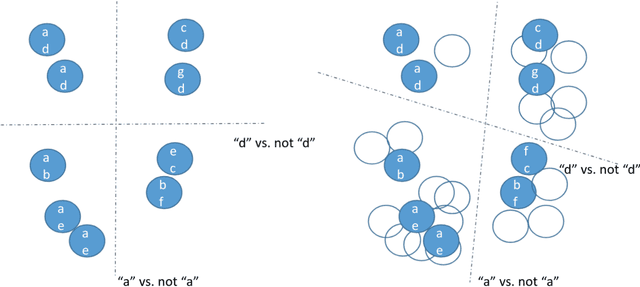

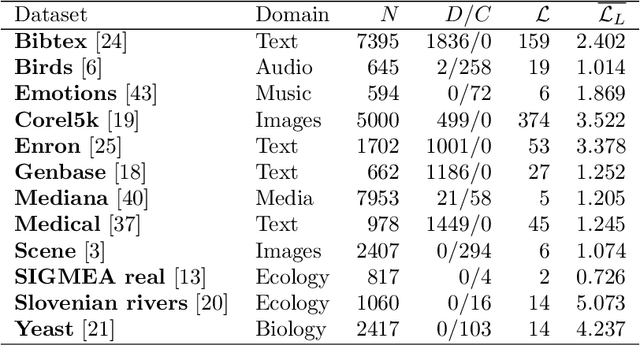
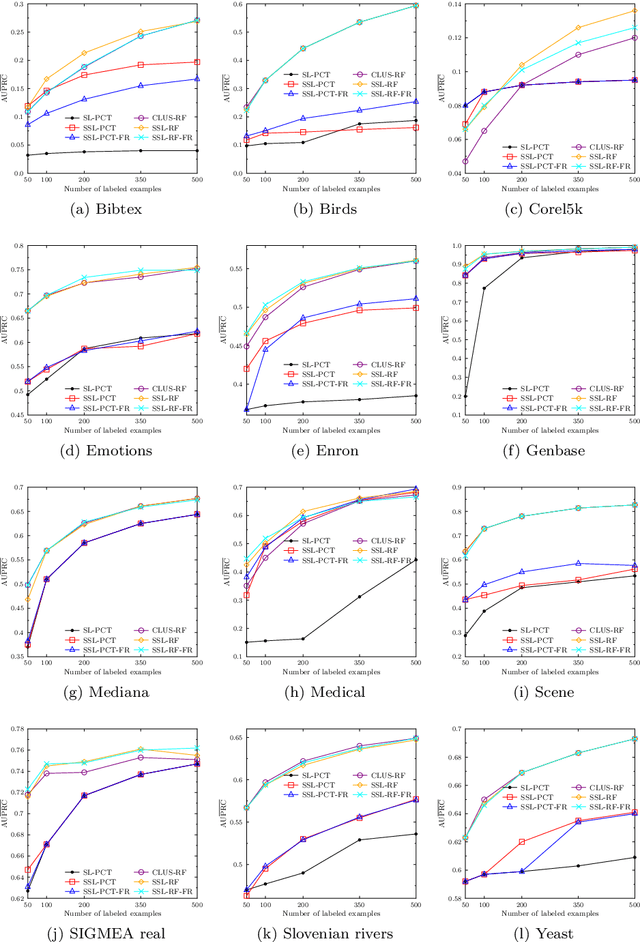
Semi-supervised learning (SSL) is a common approach to learning predictive models using not only labeled examples, but also unlabeled examples. While SSL for the simple tasks of classification and regression has received a lot of attention from the research community, this is not properly investigated for complex prediction tasks with structurally dependent variables. This is the case of multi-label classification and hierarchical multi-label classification tasks, which may require additional information, possibly coming from the underlying distribution in the descriptive space provided by unlabeled examples, to better face the challenging task of predicting simultaneously multiple class labels. In this paper, we investigate this aspect and propose a (hierarchical) multi-label classification method based on semi-supervised learning of predictive clustering trees. We also extend the method towards ensemble learning and propose a method based on the random forest approach. Extensive experimental evaluation conducted on 23 datasets shows significant advantages of the proposed method and its extension with respect to their supervised counterparts. Moreover, the method preserves interpretability and reduces the time complexity of classical tree-based models.
Learning to Singulate Layers of Cloth using Tactile Feedback
Jul 22, 2022
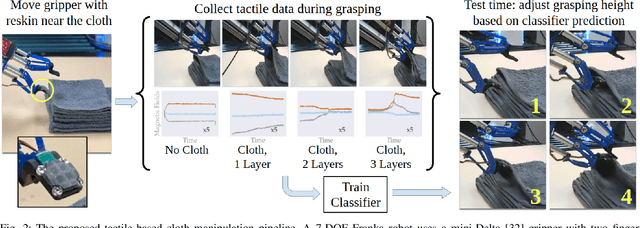


Robotic manipulation of cloth has applications ranging from fabrics manufacturing to handling blankets and laundry. Cloth manipulation is challenging for robots largely due to their high degrees of freedom, complex dynamics, and severe self-occlusions when in folded or crumpled configurations. Prior work on robotic manipulation of cloth relies primarily on vision sensors alone, which may pose challenges for fine-grained manipulation tasks such as grasping a desired number of cloth layers from a stack of cloth. In this paper, we propose to use tactile sensing for cloth manipulation; we attach a tactile sensor (ReSkin) to one of the two fingertips of a Franka robot and train a classifier to determine whether the robot is grasping a specific number of cloth layers. During test-time experiments, the robot uses this classifier as part of its policy to grasp one or two cloth layers using tactile feedback to determine suitable grasping points. Experimental results over 180 physical trials suggest that the proposed method outperforms baselines that do not use tactile feedback and has better generalization to unseen cloth compared to methods that use image classifiers. Code, data, and videos are available at https://sites.google.com/view/reskin-cloth.
Analyzing the impact of feature selection on the accuracy of heart disease prediction
Jun 07, 2022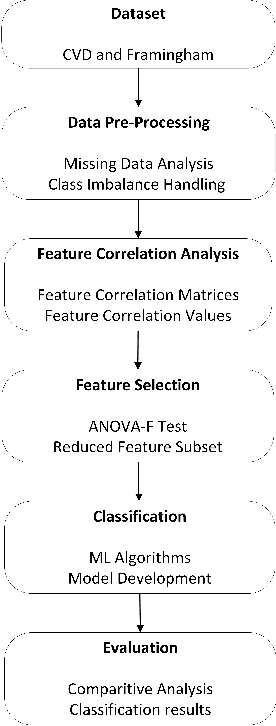
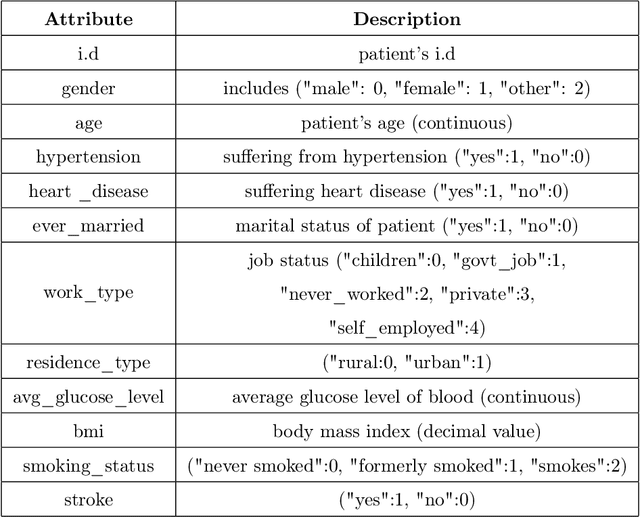
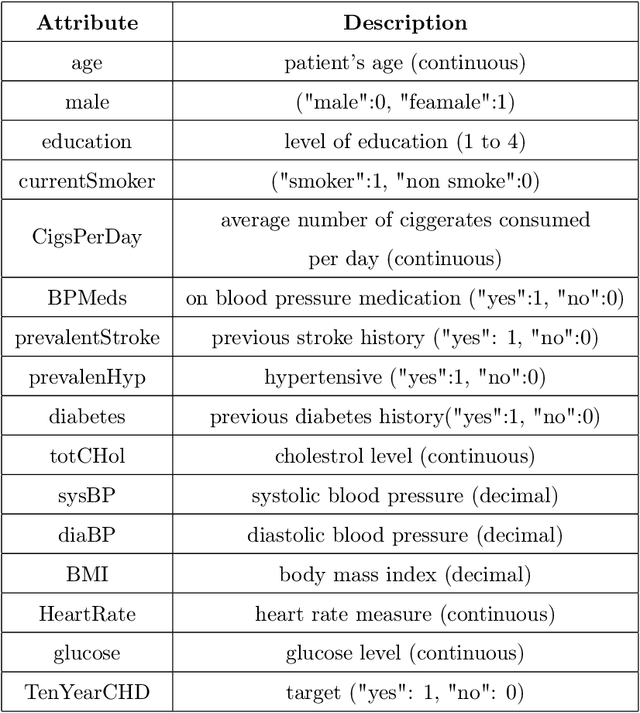

Heart Disease has become one of the most serious diseases that has a significant impact on human life. It has emerged as one of the leading causes of mortality among the people across the globe during the last decade. In order to prevent patients from further damage, an accurate diagnosis of heart disease on time is an essential factor. Recently we have seen the usage of non-invasive medical procedures, such as artificial intelligence-based techniques in the field of medical. Specially machine learning employs several algorithms and techniques that are widely used and are highly useful in accurately diagnosing the heart disease with less amount of time. However, the prediction of heart disease is not an easy task. The increasing size of medical datasets has made it a complicated task for practitioners to understand the complex feature relations and make disease predictions. Accordingly, the aim of this research is to identify the most important risk-factors from a highly dimensional dataset which helps in the accurate classification of heart disease with less complications. For a broader analysis, we have used two heart disease datasets with various medical features. The classification results of the benchmarked models proved that there is a high impact of relevant features on the classification accuracy. Even with a reduced number of features, the performance of the classification models improved significantly with a reduced training time as compared with models trained on full feature set.
Stable Parallel Training of Wasserstein Conditional Generative Adversarial Neural Networks
Jul 25, 2022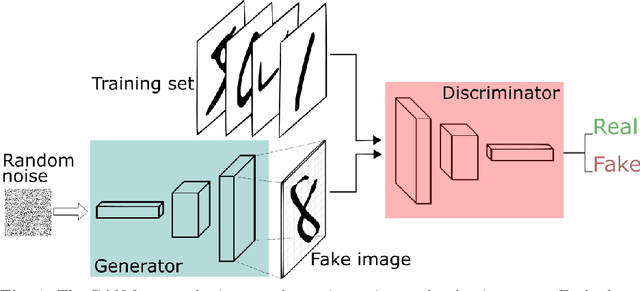
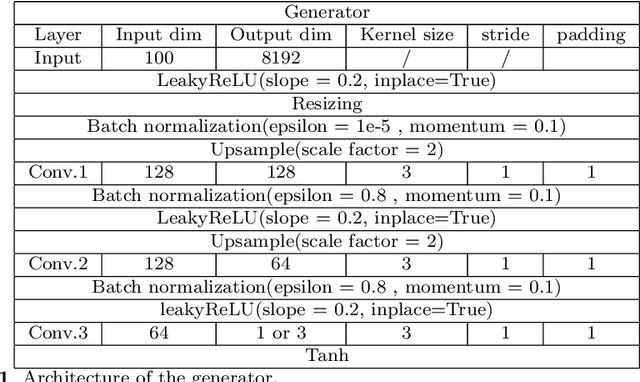
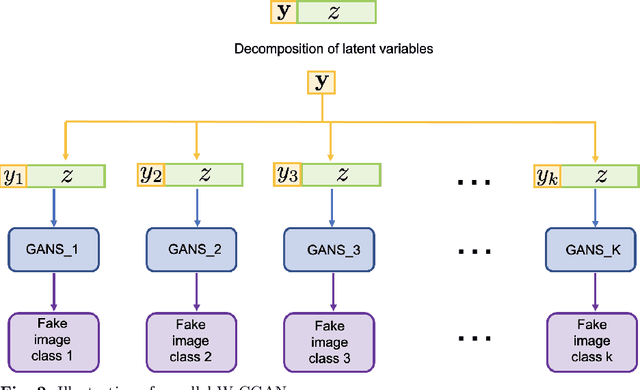
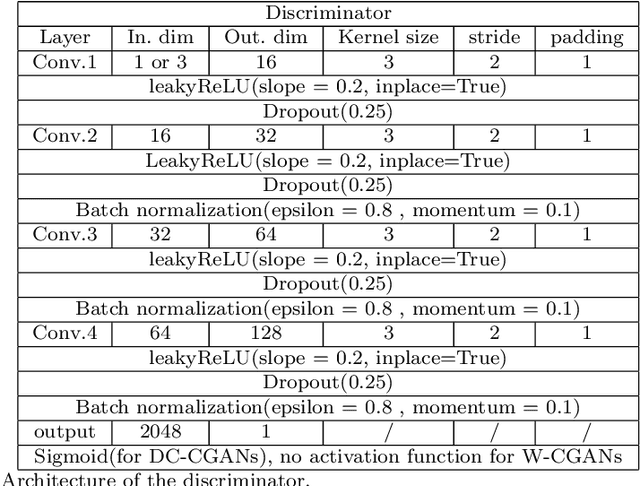
We propose a stable, parallel approach to train Wasserstein Conditional Generative Adversarial Neural Networks (W-CGANs) under the constraint of a fixed computational budget. Differently from previous distributed GANs training techniques, our approach avoids inter-process communications, reduces the risk of mode collapse and enhances scalability by using multiple generators, each one of them concurrently trained on a single data label. The use of the Wasserstein metric also reduces the risk of cycling by stabilizing the training of each generator. We illustrate the approach on the CIFAR10, CIFAR100, and ImageNet1k datasets, three standard benchmark image datasets, maintaining the original resolution of the images for each dataset. Performance is assessed in terms of scalability and final accuracy within a limited fixed computational time and computational resources. To measure accuracy, we use the inception score, the Frechet inception distance, and image quality. An improvement in inception score and Frechet inception distance is shown in comparison to previous results obtained by performing the parallel approach on deep convolutional conditional generative adversarial neural networks (DC-CGANs) as well as an improvement of image quality of the new images created by the GANs approach. Weak scaling is attained on both datasets using up to 2,000 NVIDIA V100 GPUs on the OLCF supercomputer Summit.
CoNLoCNN: Exploiting Correlation and Non-Uniform Quantization for Energy-Efficient Low-precision Deep Convolutional Neural Networks
Jul 31, 2022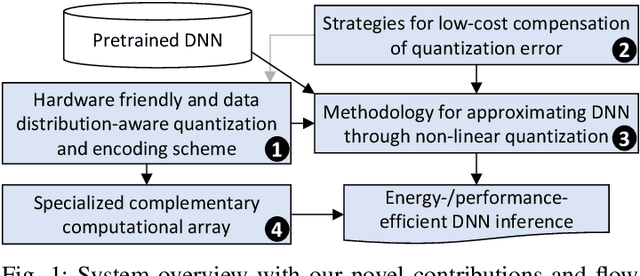
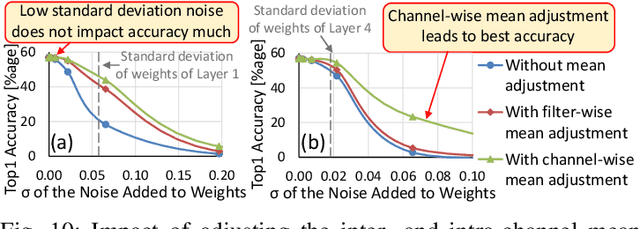


In today's era of smart cyber-physical systems, Deep Neural Networks (DNNs) have become ubiquitous due to their state-of-the-art performance in complex real-world applications. The high computational complexity of these networks, which translates to increased energy consumption, is the foremost obstacle towards deploying large DNNs in resource-constrained systems. Fixed-Point (FP) implementations achieved through post-training quantization are commonly used to curtail the energy consumption of these networks. However, the uniform quantization intervals in FP restrict the bit-width of data structures to large values due to the need to represent most of the numbers with sufficient resolution and avoid high quantization errors. In this paper, we leverage the key insight that (in most of the scenarios) DNN weights and activations are mostly concentrated near zero and only a few of them have large magnitudes. We propose CoNLoCNN, a framework to enable energy-efficient low-precision deep convolutional neural network inference by exploiting: (1) non-uniform quantization of weights enabling simplification of complex multiplication operations; and (2) correlation between activation values enabling partial compensation of quantization errors at low cost without any run-time overheads. To significantly benefit from non-uniform quantization, we also propose a novel data representation format, Encoded Low-Precision Binary Signed Digit, to compress the bit-width of weights while ensuring direct use of the encoded weight for processing using a novel multiply-and-accumulate (MAC) unit design.
Partial Disentanglement via Mechanism Sparsity
Jul 15, 2022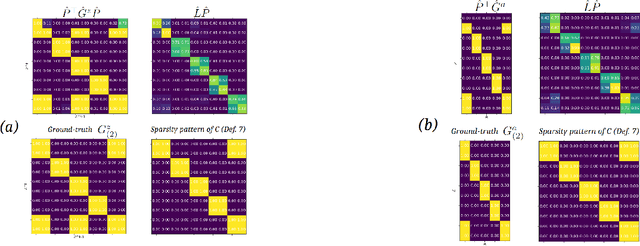

Disentanglement via mechanism sparsity was introduced recently as a principled approach to extract latent factors without supervision when the causal graph relating them in time is sparse, and/or when actions are observed and affect them sparsely. However, this theory applies only to ground-truth graphs satisfying a specific criterion. In this work, we introduce a generalization of this theory which applies to any ground-truth graph and specifies qualitatively how disentangled the learned representation is expected to be, via a new equivalence relation over models we call consistency. This equivalence captures which factors are expected to remain entangled and which are not based on the specific form of the ground-truth graph. We call this weaker form of identifiability partial disentanglement. The graphical criterion that allows complete disentanglement, proposed in an earlier work, can be derived as a special case of our theory. Finally, we enforce graph sparsity with constrained optimization and illustrate our theory and algorithm in simulations.