 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards Realistic Statistical Channel Models For Positioning: Evaluating the Impact of Early Clusters
Jul 16, 2022




Physical effects such as reflection, refraction, and diffraction cause a radio signal to arrive from a transmitter to a receiver in multiple replicas that have different amplitude and rotation. Bandwidth-limited signals, such as positioning reference signals, have a limited time resolution. In reality, the signal is often reflected in the close vicinity of a transmitter and receiver, which causes the displacement of the observed peak from the true peak expected according to the line of sight (LOS) geometry between the transmitter and receiver. In this paper, we show that the existing channel model specified for performance evaluation within 3GPP fails to model the above phenomena. As a result, the simulation results deviate significantly from the measured values. Based on our measurement and simulation results, we propose a model for incorporating the signal reflection by obstacles in the vicinity of transmitter or receiver, so that the outcome of the model corresponds to the measurement made in such scenario.
Activation Template Matching Loss for Explainable Face Recognition
Jul 05, 2022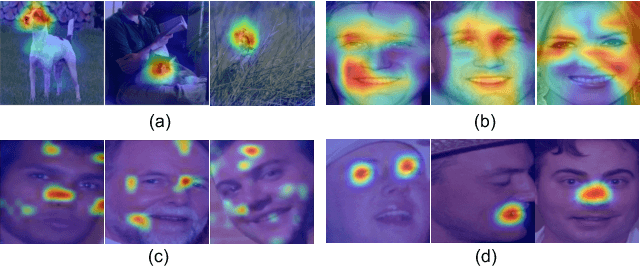
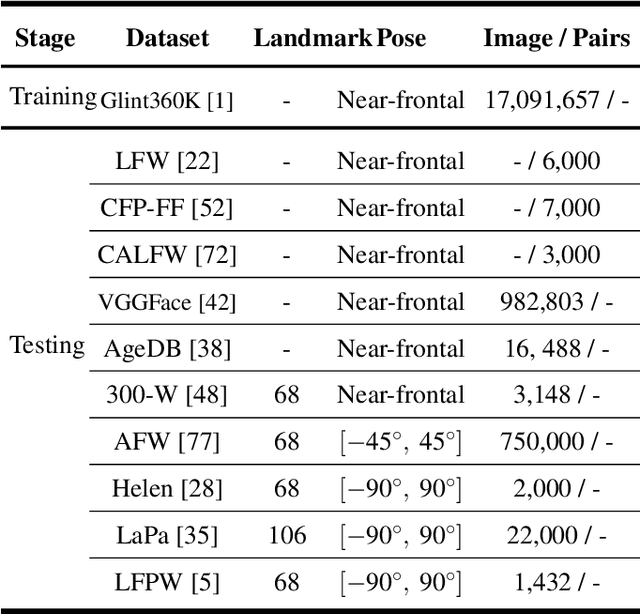
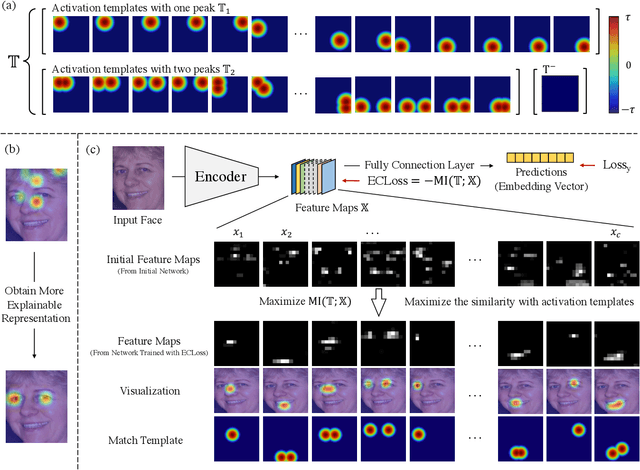
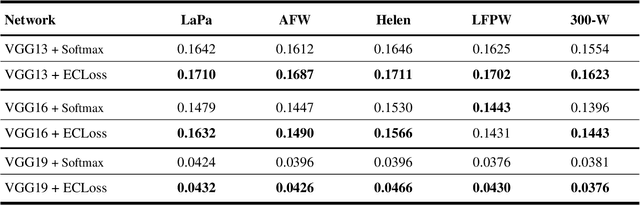
Can we construct an explainable face recognition network able to learn a facial part-based feature like eyes, nose, mouth and so forth, without any manual annotation or additionalsion datasets? In this paper, we propose a generic Explainable Channel Loss (ECLoss) to construct an explainable face recognition network. The explainable network trained with ECLoss can easily learn the facial part-based representation on the target convolutional layer, where an individual channel can detect a certain face part. Our experiments on dozens of datasets show that ECLoss achieves superior explainability metrics, and at the same time improves the performance of face verification without face alignment. In addition, our visualization results also illustrate the effectiveness of the proposed ECLoss.
Bounding generalization error with input compression: An empirical study with infinite-width networks
Jul 19, 2022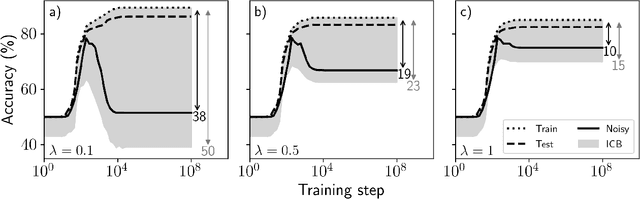

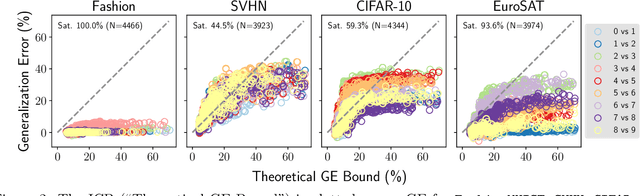
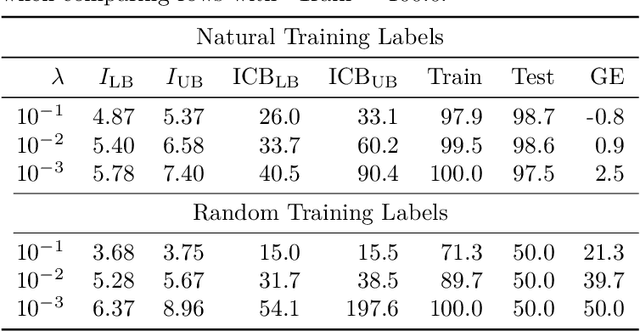
Estimating the Generalization Error (GE) of Deep Neural Networks (DNNs) is an important task that often relies on availability of held-out data. The ability to better predict GE based on a single training set may yield overarching DNN design principles to reduce a reliance on trial-and-error, along with other performance assessment advantages. In search of a quantity relevant to GE, we investigate the Mutual Information (MI) between the input and final layer representations, using the infinite-width DNN limit to bound MI. An existing input compression-based GE bound is used to link MI and GE. To the best of our knowledge, this represents the first empirical study of this bound. In our attempt to empirically falsify the theoretical bound, we find that it is often tight for best-performing models. Furthermore, it detects randomization of training labels in many cases, reflects test-time perturbation robustness, and works well given only few training samples. These results are promising given that input compression is broadly applicable where MI can be estimated with confidence.
Neural-Sim: Learning to Generate Training Data with NeRF
Jul 22, 2022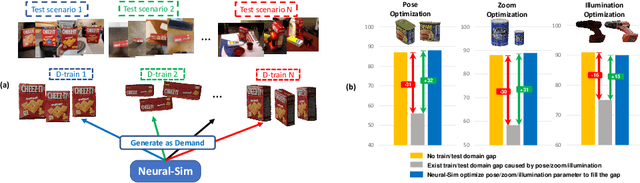
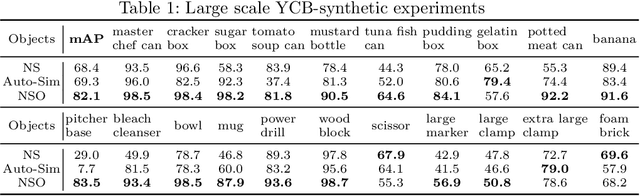

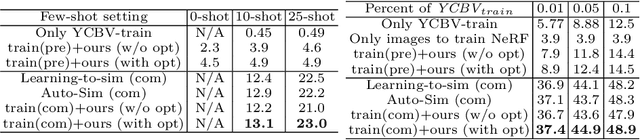
Training computer vision models usually requires collecting and labeling vast amounts of imagery under a diverse set of scene configurations and properties. This process is incredibly time-consuming, and it is challenging to ensure that the captured data distribution maps well to the target domain of an application scenario. Recently, synthetic data has emerged as a way to address both of these issues. However, existing approaches either require human experts to manually tune each scene property or use automatic methods that provide little to no control; this requires rendering large amounts of random data variations, which is slow and is often suboptimal for the target domain. We present the first fully differentiable synthetic data pipeline that uses Neural Radiance Fields (NeRFs) in a closed-loop with a target application's loss function. Our approach generates data on-demand, with no human labor, to maximize accuracy for a target task. We illustrate the effectiveness of our method on synthetic and real-world object detection tasks. We also introduce a new "YCB-in-the-Wild" dataset and benchmark that provides a test scenario for object detection with varied poses in real-world environments.
CuDi: Curve Distillation for Efficient and Controllable Exposure Adjustment
Jul 28, 2022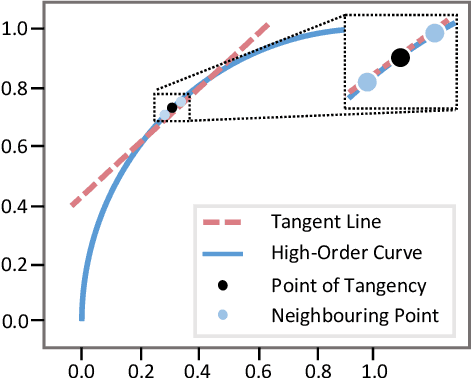
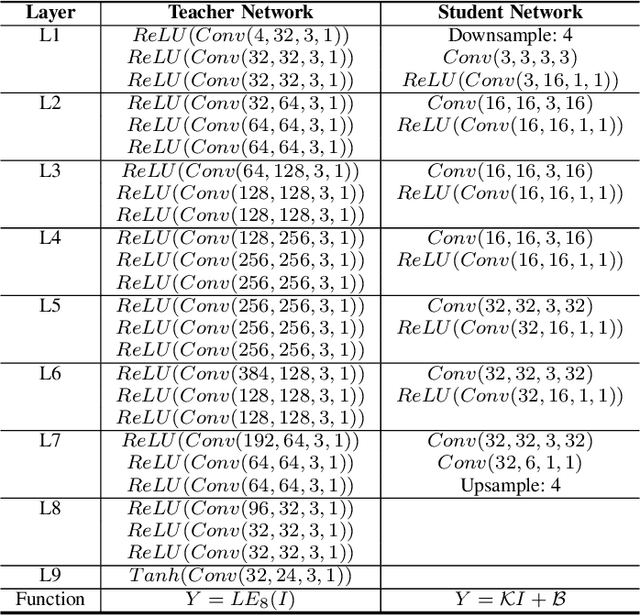


We present Curve Distillation, CuDi, for efficient and controllable exposure adjustment without the requirement of paired or unpaired data during training. Our method inherits the zero-reference learning and curve-based framework from an effective low-light image enhancement method, Zero-DCE, with further speed up in its inference speed, reduction in its model size, and extension to controllable exposure adjustment. The improved inference speed and lightweight model are achieved through novel curve distillation that approximates the time-consuming iterative operation in the conventional curve-based framework by high-order curve's tangent line. The controllable exposure adjustment is made possible with a new self-supervised spatial exposure control loss that constrains the exposure levels of different spatial regions of the output to be close to the brightness distribution of an exposure map serving as an input condition. Different from most existing methods that can only correct either underexposed or overexposed photos, our approach corrects both underexposed and overexposed photos with a single model. Notably, our approach can additionally adjust the exposure levels of a photo globally or locally with the guidance of an input condition exposure map, which can be pre-defined or manually set in the inference stage. Through extensive experiments, we show that our method is appealing for its fast, robust, and flexible performance, outperforming state-of-the-art methods in real scenes. Project page: https://li-chongyi.github.io/CuDi_files/.
Online Modeling and Control of Soft Multi-fingered Grippers via Koopman Operator Theory
Jun 21, 2022


Soft grippers are gaining momentum across applications due to their flexibility and dexterity. However, the infinite-dimensionality and non-linearity associated with soft robots challenge modeling and closed-loop control of soft grippers to perform grasping tasks. To solve this problem, data-driven methods have been proposed. Most data-driven methods rely on intensive model learning in simulation or offline, and as such it may be hard to generalize across different settings not explicitly trained upon and in physical robot testing where online control is required. In this paper, we propose an online modeling and control algorithm that utilizes Koopman operator theory to update an estimated model of the underlying dynamics at each time step in real-time. The learned and continuously updated models are then embedded into an online Model Predictive Control (MPC) structure and deployed onto soft multi-fingered robotic grippers. To evaluate the performance, the prediction accuracy of our approach is first compared against other model-extraction methods among different datasets. Next, the online modeling and control algorithm is tested experimentally with a soft 3-fingered gripper grasping objects of various shapes and weights unknown to the controller initially. Results indicate a high success ratio in grasping different objects using the proposed method. Sample trials can be viewed at https://youtu.be/i2hCMX7zSKQ.
Test-time Collective Prediction
Jun 22, 2021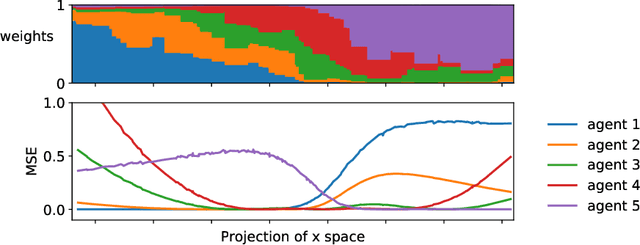
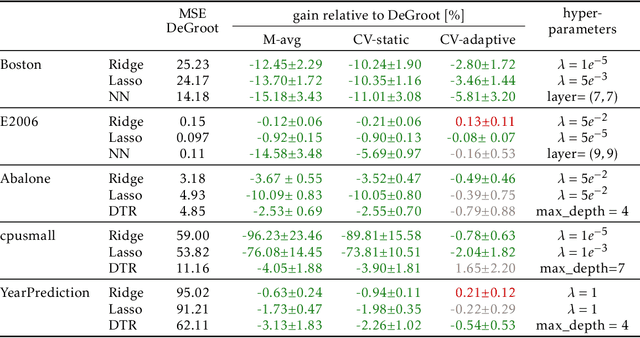
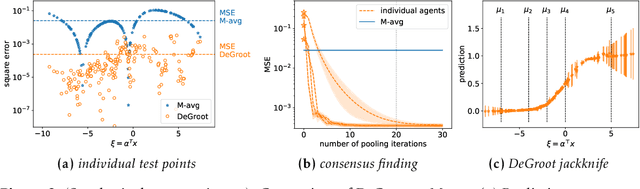
An increasingly common setting in machine learning involves multiple parties, each with their own data, who want to jointly make predictions on future test points. Agents wish to benefit from the collective expertise of the full set of agents to make better predictions than they would individually, but may not be willing to release their data or model parameters. In this work, we explore a decentralized mechanism to make collective predictions at test time, leveraging each agent's pre-trained model without relying on external validation, model retraining, or data pooling. Our approach takes inspiration from the literature in social science on human consensus-making. We analyze our mechanism theoretically, showing that it converges to inverse meansquared-error (MSE) weighting in the large-sample limit. To compute error bars on the collective predictions we propose a decentralized Jackknife procedure that evaluates the sensitivity of our mechanism to a single agent's prediction. Empirically, we demonstrate that our scheme effectively combines models with differing quality across the input space. The proposed consensus prediction achieves significant gains over classical model averaging, and even outperforms weighted averaging schemes that have access to additional validation data.
Live Stream Temporally Embedded 3D Human Body Pose and Shape Estimation
Jul 25, 2022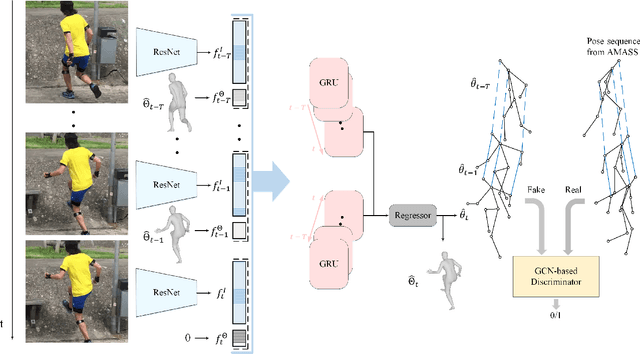

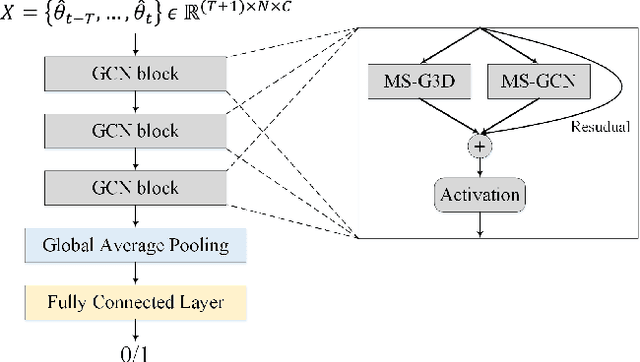
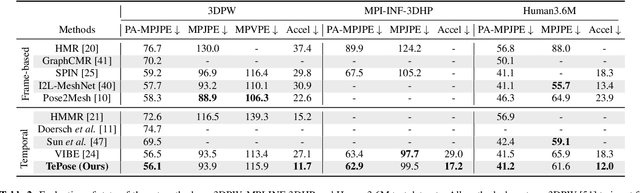
3D Human body pose and shape estimation within a temporal sequence can be quite critical for understanding human behavior. Despite the significant progress in human pose estimation in the recent years, which are often based on single images or videos, human motion estimation on live stream videos is still a rarely-touched area considering its special requirements for real-time output and temporal consistency. To address this problem, we present a temporally embedded 3D human body pose and shape estimation (TePose) method to improve the accuracy and temporal consistency of pose estimation in live stream videos. TePose uses previous predictions as a bridge to feedback the error for better estimation in the current frame and to learn the correspondence between data frames and predictions in the history. A multi-scale spatio-temporal graph convolutional network is presented as the motion discriminator for adversarial training using datasets without any 3D labeling. We propose a sequential data loading strategy to meet the special start-to-end data processing requirement of live stream. We demonstrate the importance of each proposed module with extensive experiments. The results show the effectiveness of TePose on widely-used human pose benchmarks with state-of-the-art performance.
Exploring Attention-Aware Network Resource Allocation for Customized Metaverse Services
Jul 31, 2022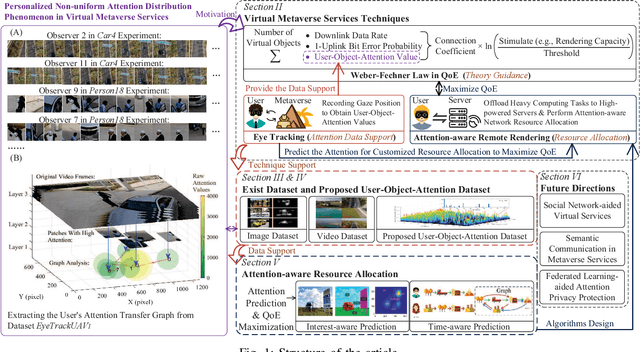
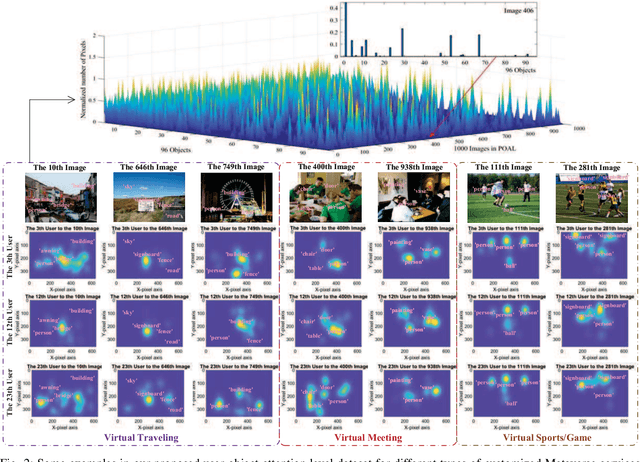
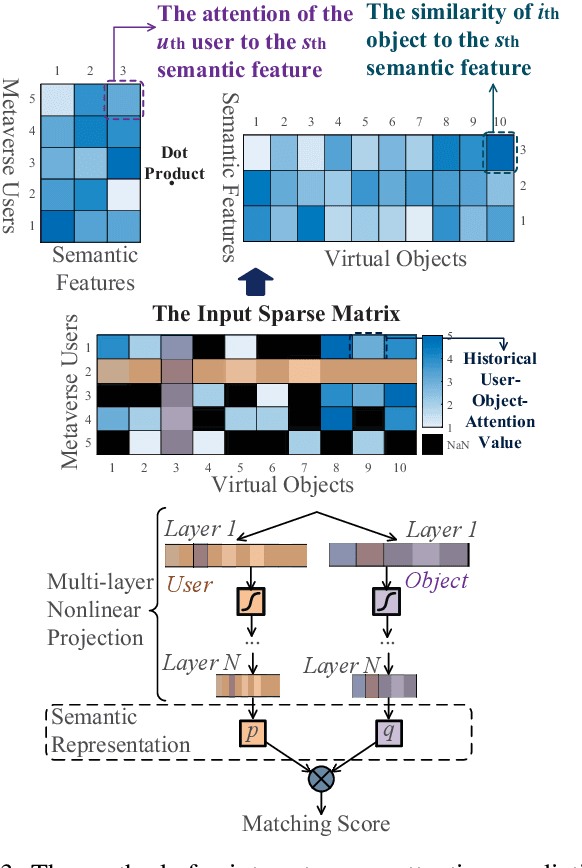
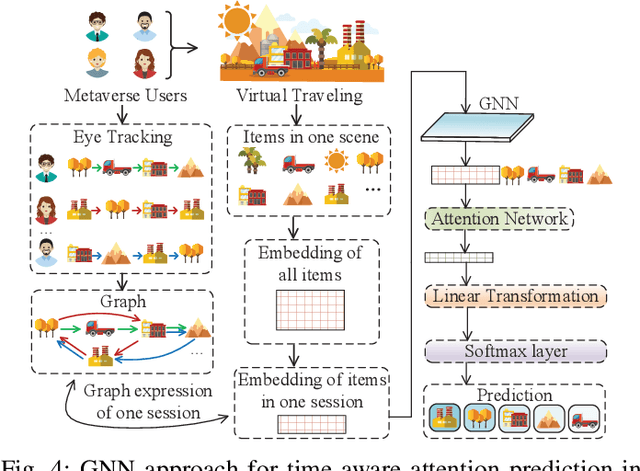
Emerging with the support of computing and communications technologies, Metaverse is expected to bring users unprecedented service experiences. However, the increase in the number of Metaverse users places a heavy demand on network resources, especially for Metaverse services that are based on graphical extended reality and require rendering a plethora of virtual objects. To make efficient use of network resources and improve the Quality-of-Experience (QoE), we design an attention-aware network resource allocation scheme to achieve customized Metaverse services. The aim is to allocate more network resources to virtual objects in which users are more interested. We first discuss several key techniques related to Metaverse services, including QoE analysis, eye-tracking, and remote rendering. We then review existing datasets and propose the user-object-attention level (UOAL) dataset that contains the ground truth attention of 30 users to 96 objects in 1,000 images. A tutorial on how to use UOAL is presented. With the help of UOAL, we propose an attention-aware network resource allocation algorithm that has two steps, i.e., attention prediction and QoE maximization. Specially, we provide an overview of the designs of two types of attention prediction methods, i.e., interest-aware and time-aware prediction. By using the predicted user-object-attention values, network resources such as the rendering capacity of edge devices can be allocated optimally to maximize the QoE. Finally, we propose promising research directions related to Metaverse services.
A Novel Meta-predictor based Algorithm for Testing VLSI Circuits
Jul 22, 2022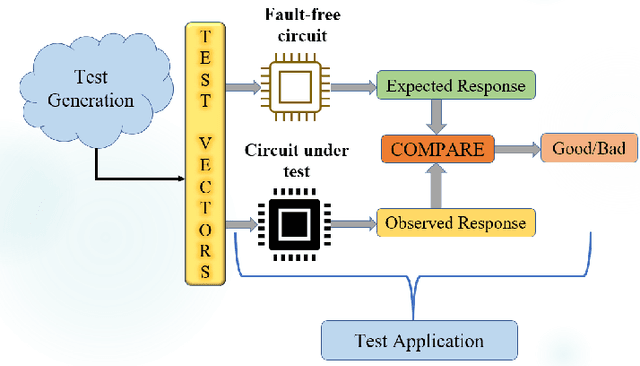
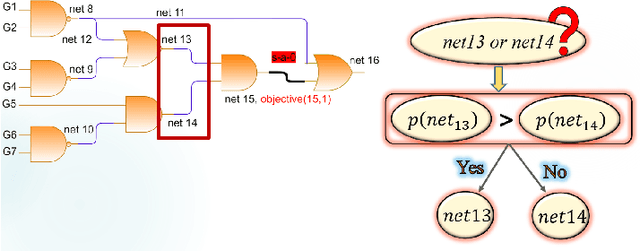
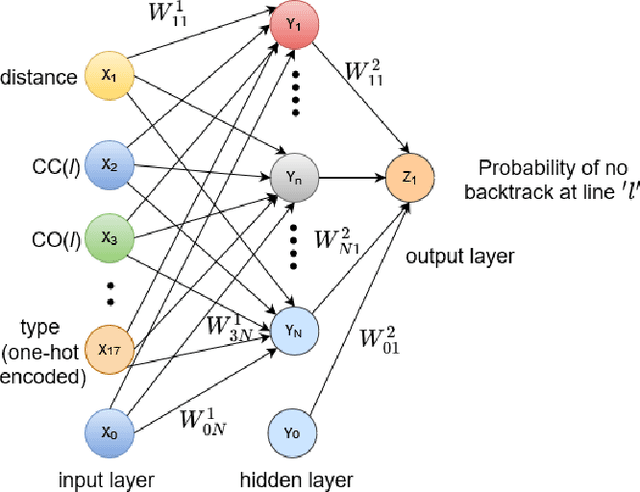
Testing of integrated circuits (IC) is a highly expensive process but also the most important one in determining the defect level of an IC. Manufacturing defects in the IC are modeled using stuck-at-fault models. Stuck-at-fault models cover most of the physical faults that occur during the manufacturing process. With decreasing feature sizes due to the advancement of semiconductor technology, the defects are also getting smaller in size. Tests for these hard-to-detect defects are generated using deterministic test generation (DTG) algorithms. Our work aims at reducing the cost of Path Oriented Decision Making: PODEM (a DTG algorithm) without compromising the test quality. We trained a meta predictor to choose the best model given the circuit and the target net. This ensemble chooses the best probability prediction model with a 95% accuracy. This leads to a reduced number of backtracking decisions and much better performance of PODEM in terms of its CPU time. We show that our ML- guided PODEM algorithm with a meta predictor outperforms the baseline PODEM by 34% and other state-of-the-art ML-guided algorithms by at least 15% for ISCAS85 benchmark circuits.