 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning to Order for Inventory Systems with Lost Sales and Uncertain Supplies
Jul 10, 2022
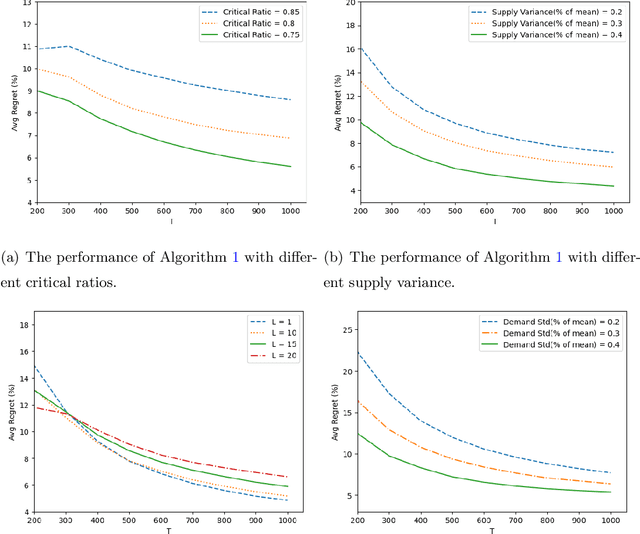
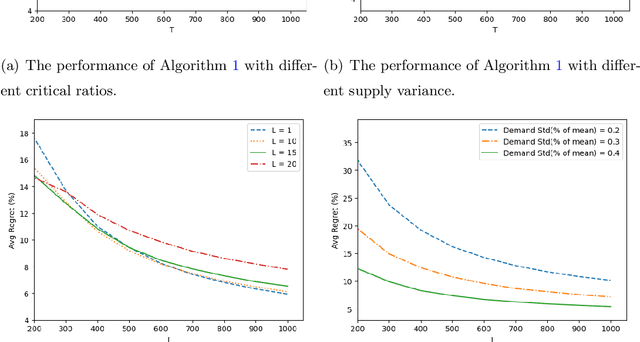
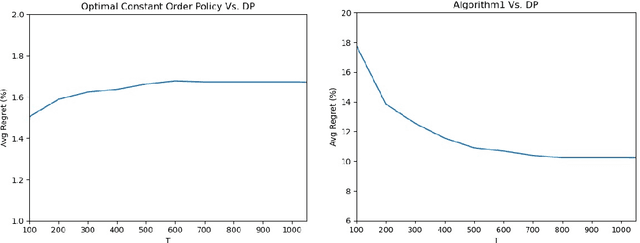
We consider a stochastic lost-sales inventory control system with a lead time $L$ over a planning horizon $T$. Supply is uncertain, and is a function of the order quantity (due to random yield/capacity, etc). We aim to minimize the $T$-period cost, a problem that is known to be computationally intractable even under known distributions of demand and supply. In this paper, we assume that both the demand and supply distributions are unknown and develop a computationally efficient online learning algorithm. We show that our algorithm achieves a regret (i.e. the performance gap between the cost of our algorithm and that of an optimal policy over $T$ periods) of $O(L+\sqrt{T})$ when $L\geq\log(T)$. We do so by 1) showing our algorithm cost is higher by at most $O(L+\sqrt{T})$ for any $L\geq 0$ compared to an optimal constant-order policy under complete information (a well-known and widely-used algorithm) and 2) leveraging its known performance guarantee from the existing literature. To the best of our knowledge, a finite-sample $O(\sqrt{T})$ (and polynomial in $L$) regret bound when benchmarked against an optimal policy is not known before in the online inventory control literature. A key challenge in this learning problem is that both demand and supply data can be censored; hence only truncated values are observable. We circumvent this challenge by showing that the data generated under an order quantity $q^2$ allows us to simulate the performance of not only $q^2$ but also $q^1$ for all $q^1<q^2$, a key observation to obtain sufficient information even under data censoring. By establishing a high probability coupling argument, we are able to evaluate and compare the performance of different order policies at their steady state within a finite time horizon. Since the problem lacks convexity, we develop an active elimination method that adaptively rules out suboptimal solutions.
PI-ARS: Accelerating Evolution-Learned Visual-Locomotion with Predictive Information Representations
Jul 27, 2022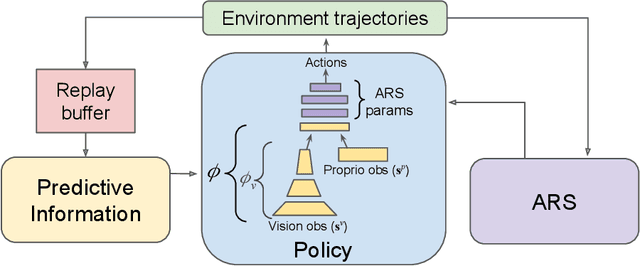

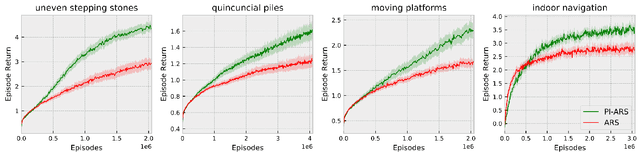

Evolution Strategy (ES) algorithms have shown promising results in training complex robotic control policies due to their massive parallelism capability, simple implementation, effective parameter-space exploration, and fast training time. However, a key limitation of ES is its scalability to large capacity models, including modern neural network architectures. In this work, we develop Predictive Information Augmented Random Search (PI-ARS) to mitigate this limitation by leveraging recent advancements in representation learning to reduce the parameter search space for ES. Namely, PI-ARS combines a gradient-based representation learning technique, Predictive Information (PI), with a gradient-free ES algorithm, Augmented Random Search (ARS), to train policies that can process complex robot sensory inputs and handle highly nonlinear robot dynamics. We evaluate PI-ARS on a set of challenging visual-locomotion tasks where a quadruped robot needs to walk on uneven stepping stones, quincuncial piles, and moving platforms, as well as to complete an indoor navigation task. Across all tasks, PI-ARS demonstrates significantly better learning efficiency and performance compared to the ARS baseline. We further validate our algorithm by demonstrating that the learned policies can successfully transfer to a real quadruped robot, for example, achieving a 100% success rate on the real-world stepping stone environment, dramatically improving prior results achieving 40% success.
Real-Time Mapping of Tissue Properties for Magnetic Resonance Fingerprinting
Jul 16, 2021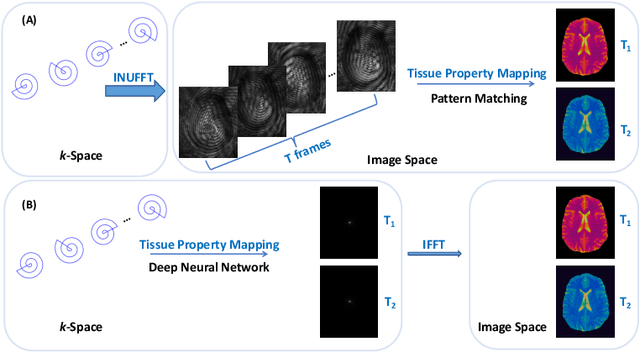
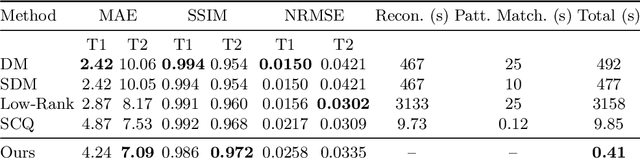
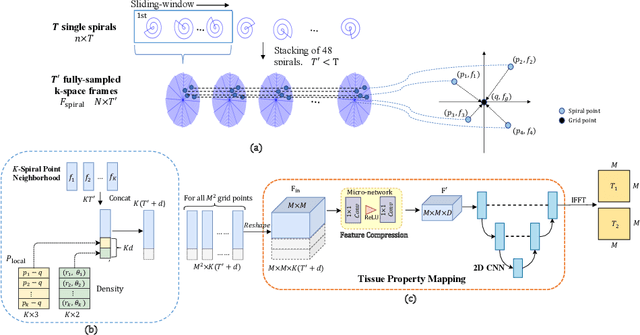

Magnetic resonance Fingerprinting (MRF) is a relatively new multi-parametric quantitative imaging method that involves a two-step process: (i) reconstructing a series of time frames from highly-undersampled non-Cartesian spiral k-space data and (ii) pattern matching using the time frames to infer tissue properties (e.g., T1 and T2 relaxation times). In this paper, we introduce a novel end-to-end deep learning framework to seamlessly map the tissue properties directly from spiral k-space MRF data, thereby avoiding time-consuming processing such as the nonuniform fast Fourier transform (NUFFT) and the dictionary-based Fingerprint matching. Our method directly consumes the non-Cartesian k- space data, performs adaptive density compensation, and predicts multiple tissue property maps in one forward pass. Experiments on both 2D and 3D MRF data demonstrate that quantification accuracy comparable to state-of-the-art methods can be accomplished within 0.5 second, which is 1100 to 7700 times faster than the original MRF framework. The proposed method is thus promising for facilitating the adoption of MRF in clinical settings.
Real-time X-ray Phase-contrast Imaging Using SPINNet -- A Speckle-based Phase-contrast Imaging Neural Network
Jan 18, 2022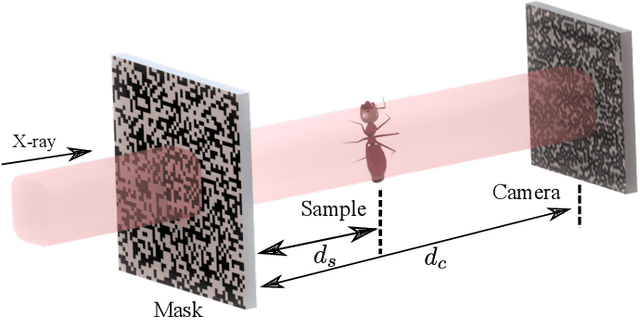
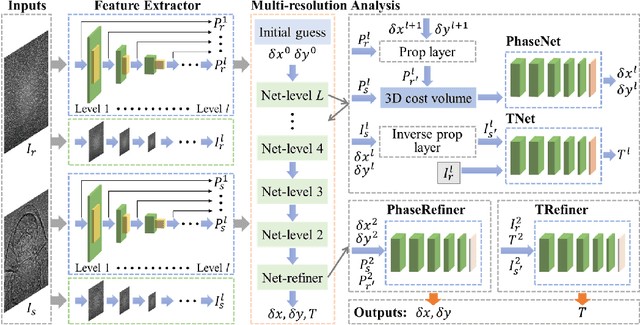
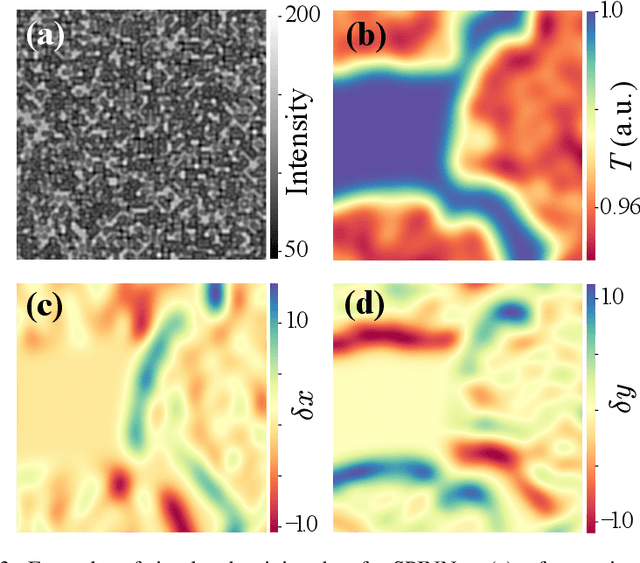
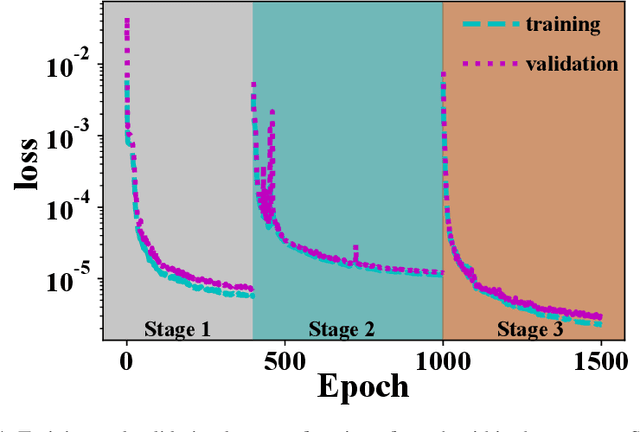
X-ray phase-contrast imaging has become indispensable for visualizing samples with low absorption contrast. In this regard, speckle-based techniques have shown significant advantages in spatial resolution, phase sensitivity, and implementation flexibility compared with traditional methods. However, their computational cost has hindered their wider adoption. By exploiting the power of deep learning, we developed a new speckle-based phase-contrast imaging neural network (SPINNet) that boosts the phase retrieval speed by at least two orders of magnitude compared to existing methods. To achieve this performance, we combined SPINNet with a novel coded-mask-based technique, an enhanced version of the speckle-based method. Using this scheme, we demonstrate a simultaneous reconstruction of absorption and phase images on the order of 100 ms, where a traditional correlation-based analysis would take several minutes even with a cluster. In addition to significant improvement in speed, our experimental results show that the imaging resolution and phase retrieval quality of SPINNet outperform existing single-shot speckle-based methods. Furthermore, we successfully demonstrate its application in 3D X-ray phase-contrast tomography. Our result shows that SPINNet could enable many applications requiring high-resolution and fast data acquisition and processing, such as in-situ and in-operando 2D and 3D phase-contrast imaging and real-time at-wavelength metrology and wavefront sensing.
SatMAE: Pre-training Transformers for Temporal and Multi-Spectral Satellite Imagery
Jul 17, 2022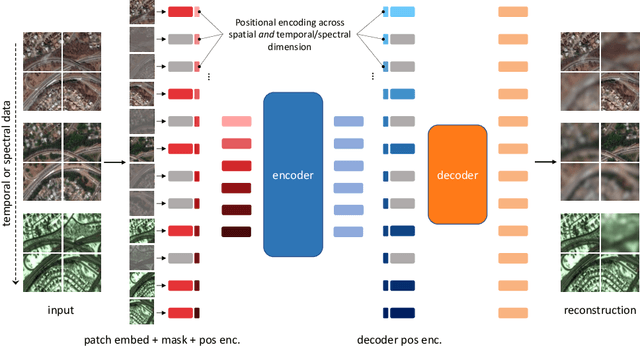

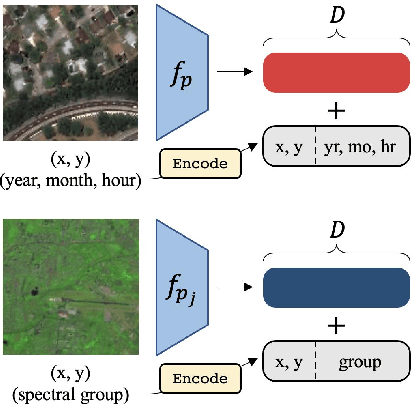
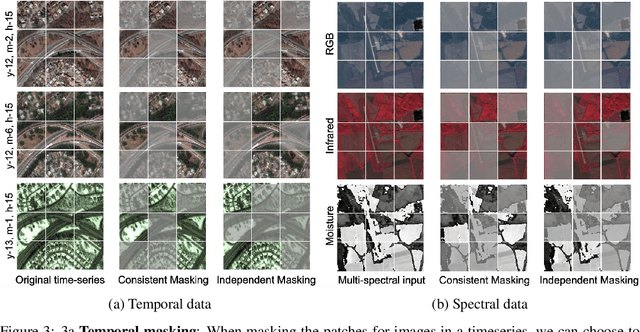
Unsupervised pre-training methods for large vision models have shown to enhance performance on downstream supervised tasks. Developing similar techniques for satellite imagery presents significant opportunities as unlabelled data is plentiful and the inherent temporal and multi-spectral structure provides avenues to further improve existing pre-training strategies. In this paper, we present SatMAE, a pre-training framework for temporal or multi-spectral satellite imagery based on Masked Autoencoder (MAE). To leverage temporal information, we include a temporal embedding along with independently masking image patches across time. In addition, we demonstrate that encoding multi-spectral data as groups of bands with distinct spectral positional encodings is beneficial. Our approach yields strong improvements over previous state-of-the-art techniques, both in terms of supervised learning performance on benchmark datasets (up to $\uparrow$ 7\%), and transfer learning performance on downstream remote sensing tasks, including land cover classification (up to $\uparrow$ 14\%) and semantic segmentation.
Analysis of Kinetic Models for Label Switching and Stochastic Gradient Descent
Jul 01, 2022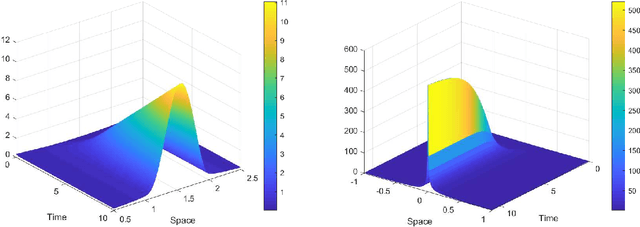
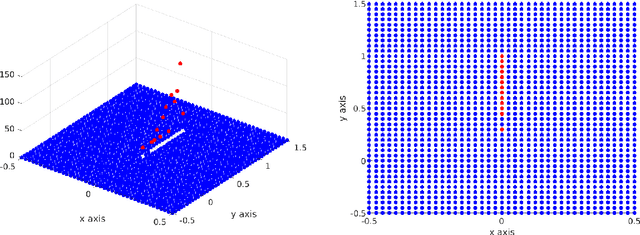
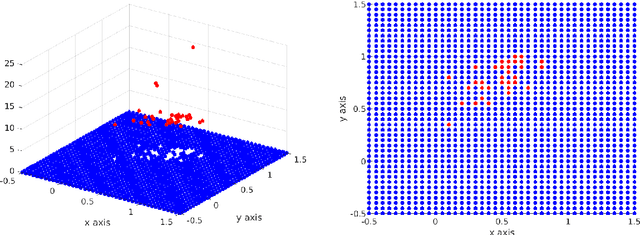
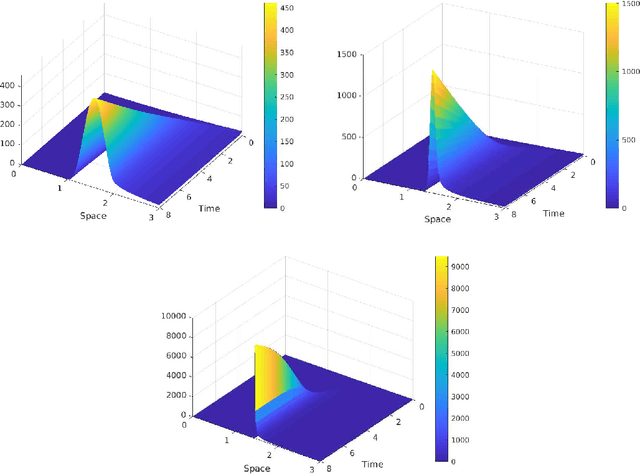
In this paper we provide a novel approach to the analysis of kinetic models for label switching, which are used for particle systems that can randomly switch between gradient flows in different energy landscapes. Besides problems in biology and physics, we also demonstrate that stochastic gradient descent, the most popular technique in machine learning, can be understood in this setting, when considering a time-continuous variant. Our analysis is focusing on the case of evolution in a collection of external potentials, for which we provide analytical and numerical results about the evolution as well as the stationary problem.
A New Algorithm for Discrete-Time Parameter Estimation
Mar 30, 2021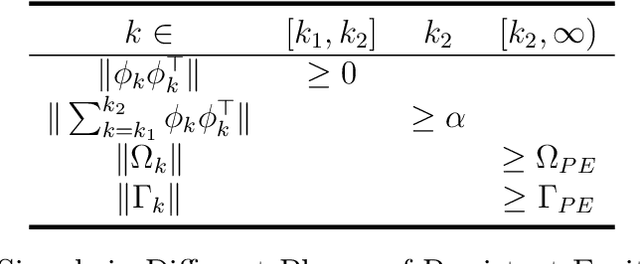
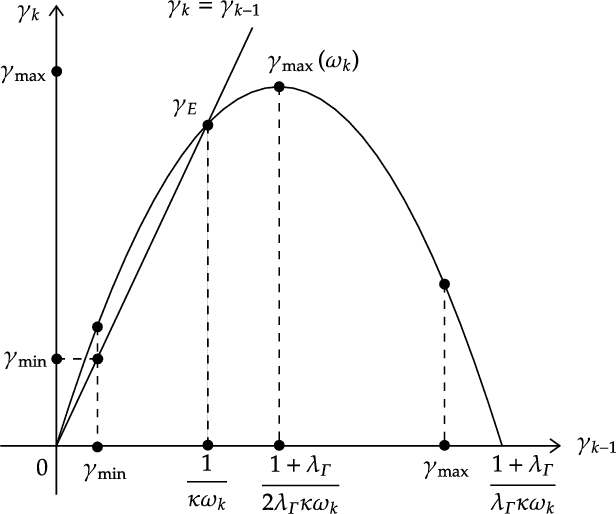
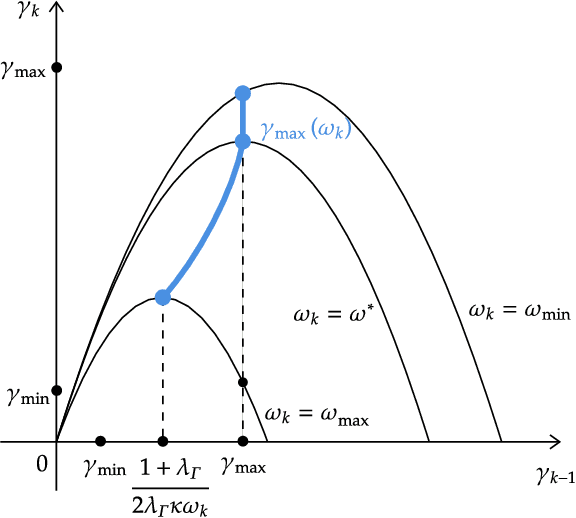
We propose a new discrete-time adaptive algorithm for parameter estimation of a class of time-varying plants. The main contribution is the inclusion of a time-varying gain matrix in the adjustment of the parameter estimates. We show that in the presence of time-varying unknown parameters, the parameter estimation error converges uniformly to a compact set under conditions of persistent excitation, with the size of the compact set proportional to the time-variation of the unknown parameters. Under conditions of finite excitation, the convergence is asymptotic and non-uniform.
Design of secure and robust cognitive system for malware detection
Aug 03, 2022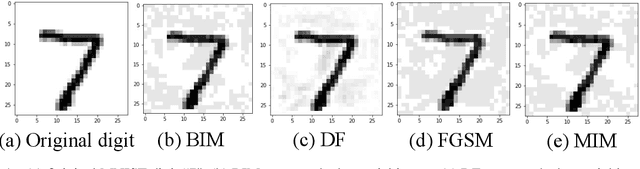

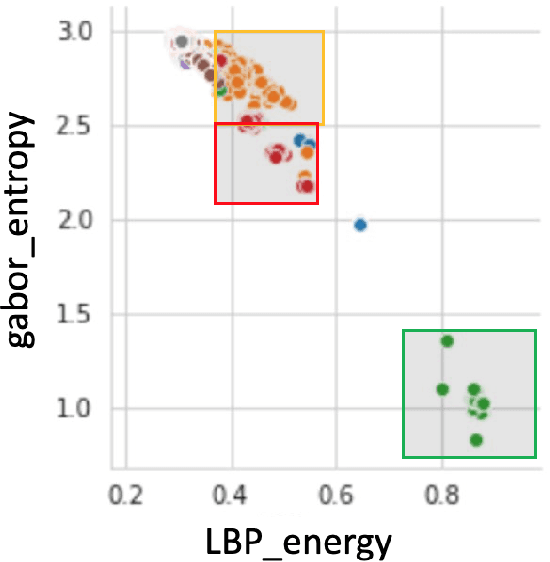

Machine learning based malware detection techniques rely on grayscale images of malware and tends to classify malware based on the distribution of textures in graycale images. Albeit the advancement and promising results shown by machine learning techniques, attackers can exploit the vulnerabilities by generating adversarial samples. Adversarial samples are generated by intelligently crafting and adding perturbations to the input samples. There exists majority of the software based adversarial attacks and defenses. To defend against the adversaries, the existing malware detection based on machine learning and grayscale images needs a preprocessing for the adversarial data. This can cause an additional overhead and can prolong the real-time malware detection. So, as an alternative to this, we explore RRAM (Resistive Random Access Memory) based defense against adversaries. Therefore, the aim of this thesis is to address the above mentioned critical system security issues. The above mentioned challenges are addressed by demonstrating proposed techniques to design a secure and robust cognitive system. First, a novel technique to detect stealthy malware is proposed. The technique uses malware binary images and then extract different features from the same and then employ different ML-classifiers on the dataset thus obtained. Results demonstrate that this technique is successful in differentiating classes of malware based on the features extracted. Secondly, I demonstrate the effects of adversarial attacks on a reconfigurable RRAM-neuromorphic architecture with different learning algorithms and device characteristics. I also propose an integrated solution for mitigating the effects of the adversarial attack using the reconfigurable RRAM architecture.
Unsupervised Deep Anomaly Detection for Multi-Sensor Time-Series Signals
Aug 02, 2021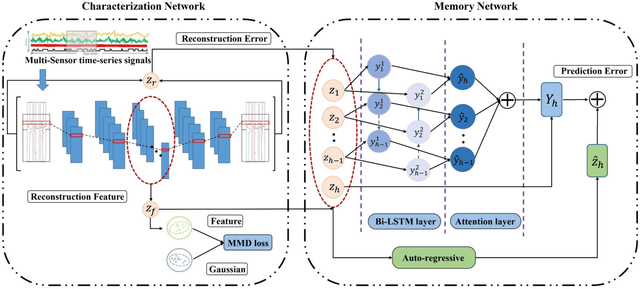

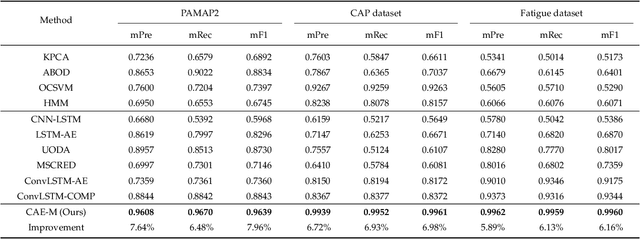
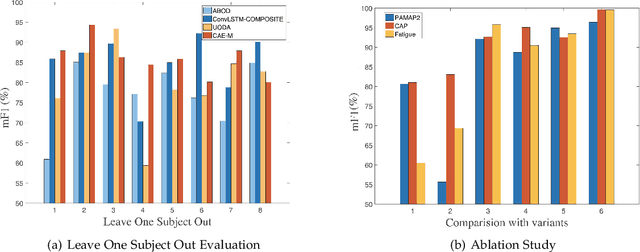
Nowadays, multi-sensor technologies are applied in many fields, e.g., Health Care (HC), Human Activity Recognition (HAR), and Industrial Control System (ICS). These sensors can generate a substantial amount of multivariate time-series data. Unsupervised anomaly detection on multi-sensor time-series data has been proven critical in machine learning researches. The key challenge is to discover generalized normal patterns by capturing spatial-temporal correlation in multi-sensor data. Beyond this challenge, the noisy data is often intertwined with the training data, which is likely to mislead the model by making it hard to distinguish between the normal, abnormal, and noisy data. Few of previous researches can jointly address these two challenges. In this paper, we propose a novel deep learning-based anomaly detection algorithm called Deep Convolutional Autoencoding Memory network (CAE-M). We first build a Deep Convolutional Autoencoder to characterize spatial dependence of multi-sensor data with a Maximum Mean Discrepancy (MMD) to better distinguish between the noisy, normal, and abnormal data. Then, we construct a Memory Network consisting of linear (Autoregressive Model) and non-linear predictions (Bidirectional LSTM with Attention) to capture temporal dependence from time-series data. Finally, CAE-M jointly optimizes these two subnetworks. We empirically compare the proposed approach with several state-of-the-art anomaly detection methods on HAR and HC datasets. Experimental results demonstrate that our proposed model outperforms these existing methods.
Vers la compréhension automatique de la parole bout-en-bout à moindre effort
Jul 01, 2022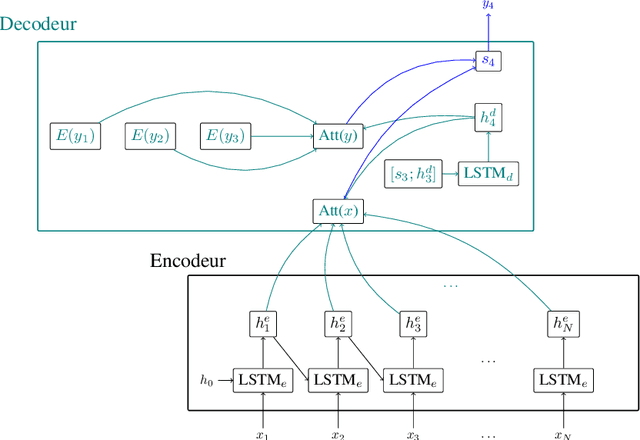
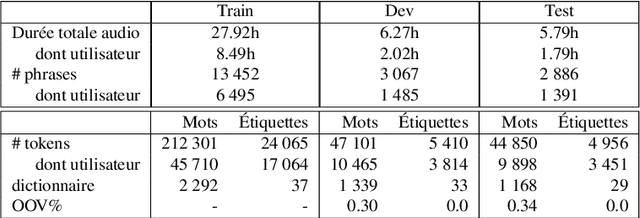
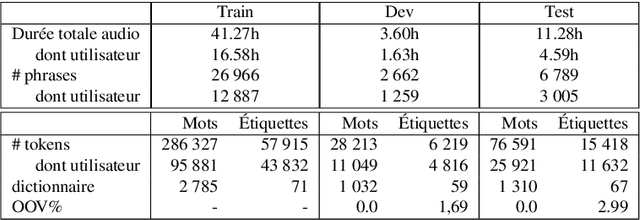
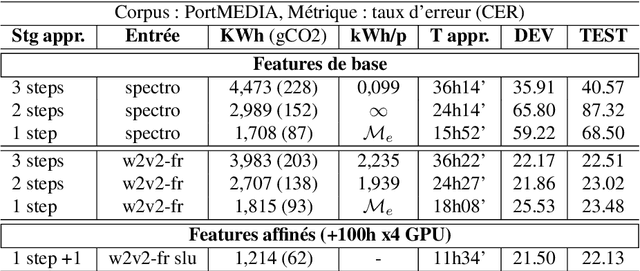
Recent advances in spoken language understanding benefited from Self-Supervised models trained on large speech corpora. For French, the LeBenchmark project has made such models available and has led to impressive progress on several tasks including spoken language understanding. These advances have a non-negligible cost in terms of computation time and energy consumption. In this paper, we compare several learning strategies aiming at reducing such cost while keeping competitive performances. The experiments are performed on the MEDIA corpus, and show that it is possible to reduce the learning cost while maintaining state-of-the-art performances.