 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Analysis of Kinetic Models for Label Switching and Stochastic Gradient Descent
Jul 01, 2022
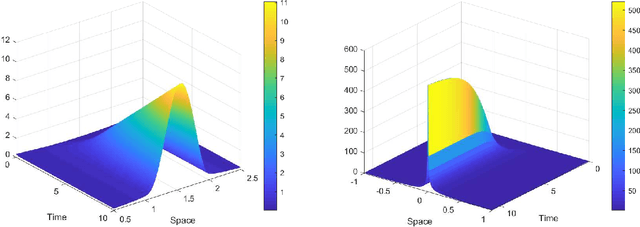
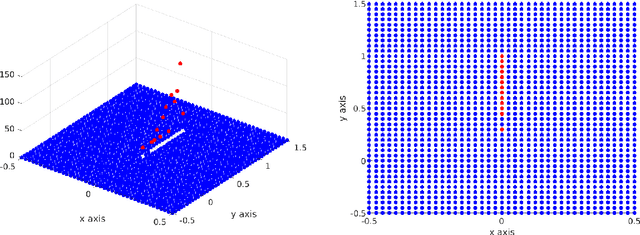
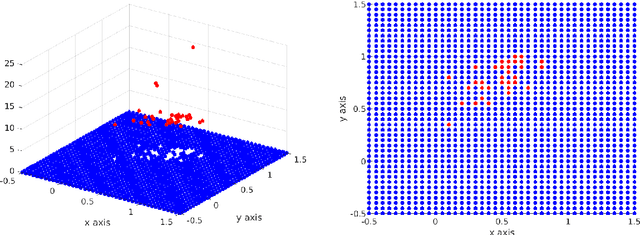
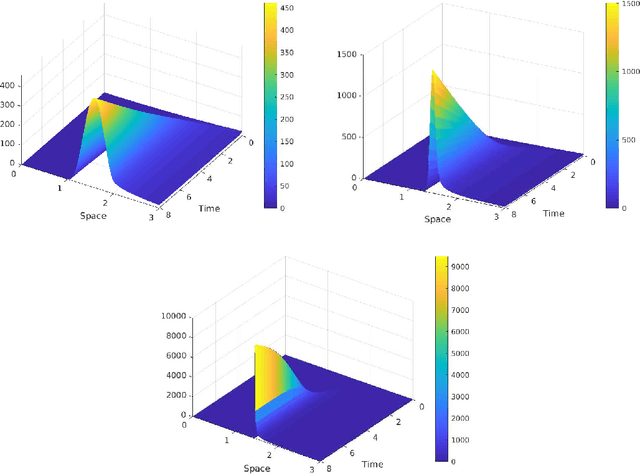
In this paper we provide a novel approach to the analysis of kinetic models for label switching, which are used for particle systems that can randomly switch between gradient flows in different energy landscapes. Besides problems in biology and physics, we also demonstrate that stochastic gradient descent, the most popular technique in machine learning, can be understood in this setting, when considering a time-continuous variant. Our analysis is focusing on the case of evolution in a collection of external potentials, for which we provide analytical and numerical results about the evolution as well as the stationary problem.
Ensembles of Randomized NNs for Pattern-based Time Series Forecasting
Jul 08, 2021
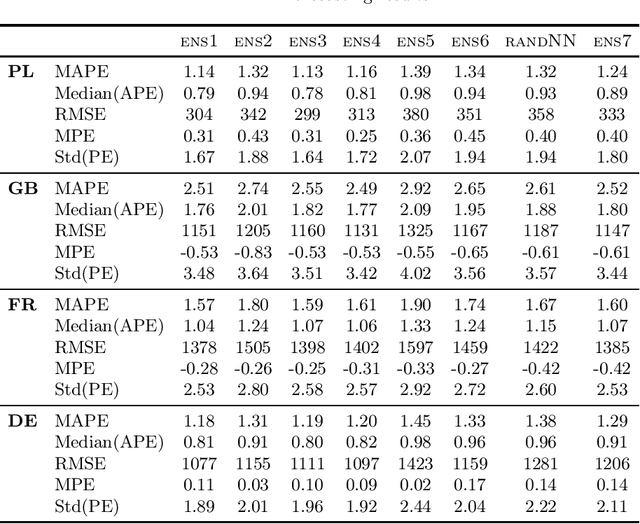
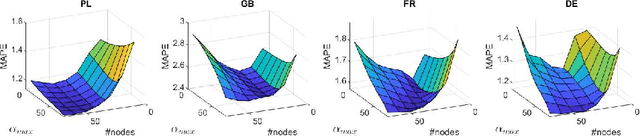
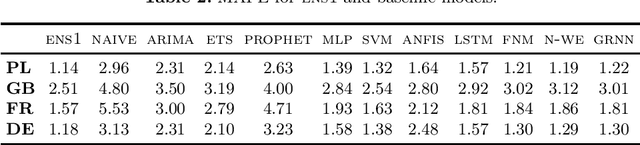
In this work, we propose an ensemble forecasting approach based on randomized neural networks. Improved randomized learning streamlines the fitting abilities of individual learners by generating network parameters in accordance with the data and target function features. A pattern-based representation of time series makes the proposed approach suitable for forecasting time series with multiple seasonality. We propose six strategies for controlling the diversity of ensemble members. Case studies conducted on four real-world forecasting problems verified the effectiveness and superior performance of the proposed ensemble forecasting approach. It outperformed statistical models as well as state-of-the-art machine learning models in terms of forecasting accuracy. The proposed approach has several advantages: fast and easy training, simple architecture, ease of implementation, high accuracy and the ability to deal with nonstationarity and multiple seasonality in time series.
Probability Paths and the Structure of Predictions over Time
Jun 11, 2021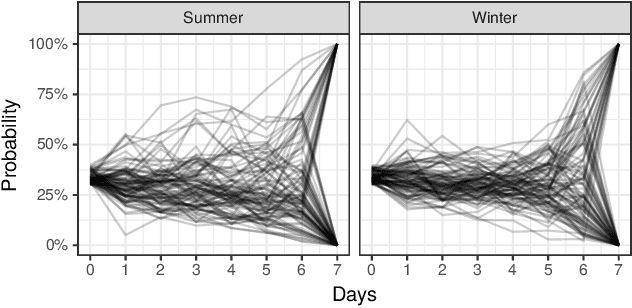
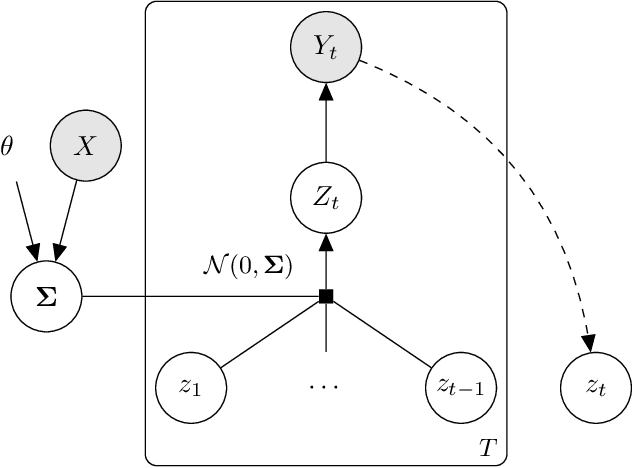
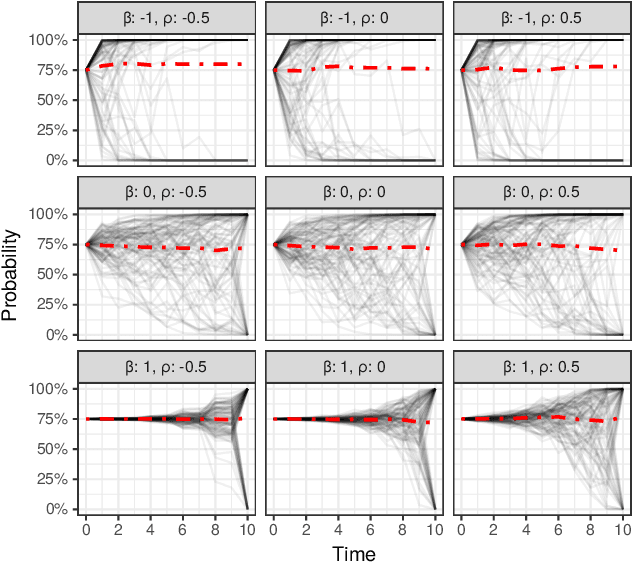
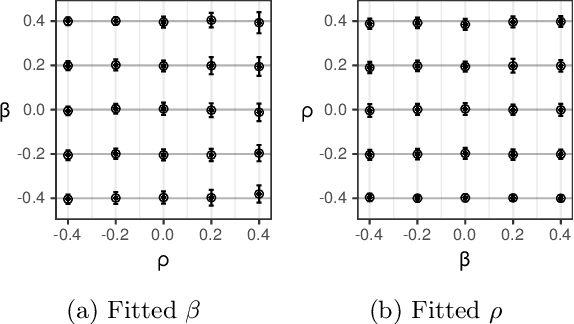
In settings ranging from weather forecasts to political prognostications to financial projections, probability estimates of future binary outcomes often evolve over time. For example, the estimated likelihood of rain on a specific day changes by the hour as new information becomes available. Given a collection of such probability paths, we introduce a Bayesian framework -- which we call the Gaussian latent information martingale, or GLIM -- for modeling the structure of dynamic predictions over time. Suppose, for example, that the likelihood of rain in a week is 50%, and consider two hypothetical scenarios. In the first, one expects the forecast is equally likely to become either 25% or 75% tomorrow; in the second, one expects the forecast to stay constant for the next several days. A time-sensitive decision-maker might select a course of action immediately in the latter scenario, but may postpone their decision in the former, knowing that new information is imminent. We model these trajectories by assuming predictions update according to a latent process of information flow, which is inferred from historical data. In contrast to general methods for time series analysis, this approach preserves the martingale structure of probability paths and better quantifies future uncertainties around probability paths. We show that GLIM outperforms three popular baseline methods, producing better estimated posterior probability path distributions measured by three different metrics. By elucidating the dynamic structure of predictions over time, we hope to help individuals make more informed choices.
Vers la compréhension automatique de la parole bout-en-bout à moindre effort
Jul 01, 2022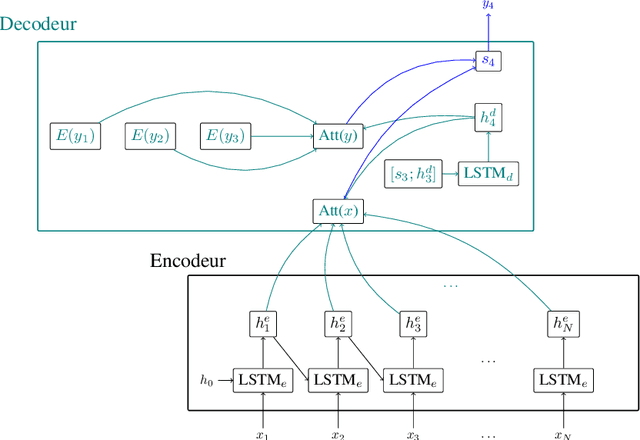
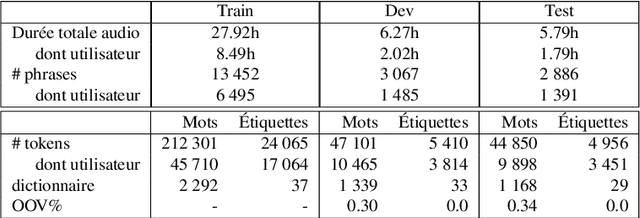
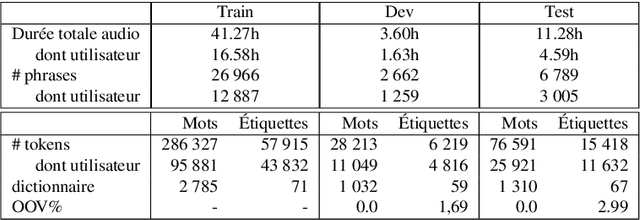
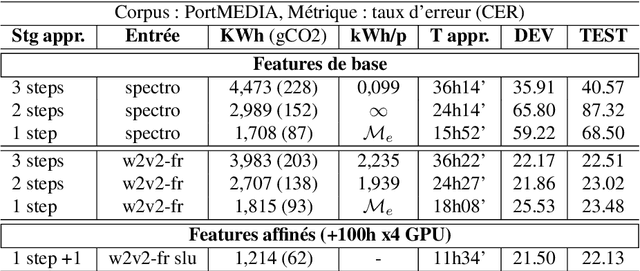
Recent advances in spoken language understanding benefited from Self-Supervised models trained on large speech corpora. For French, the LeBenchmark project has made such models available and has led to impressive progress on several tasks including spoken language understanding. These advances have a non-negligible cost in terms of computation time and energy consumption. In this paper, we compare several learning strategies aiming at reducing such cost while keeping competitive performances. The experiments are performed on the MEDIA corpus, and show that it is possible to reduce the learning cost while maintaining state-of-the-art performances.
Employing Feature Selection Algorithms to Determine the Immune State of Mice with Rheumatoid Arthritis
Jul 12, 2022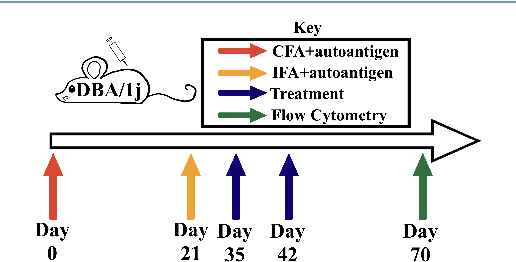
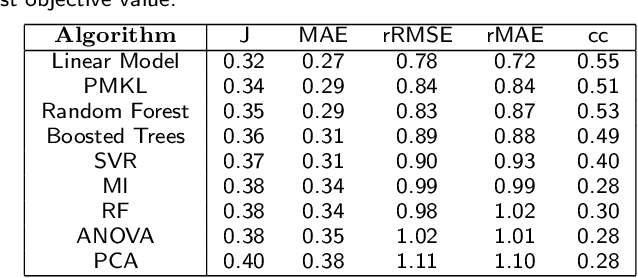
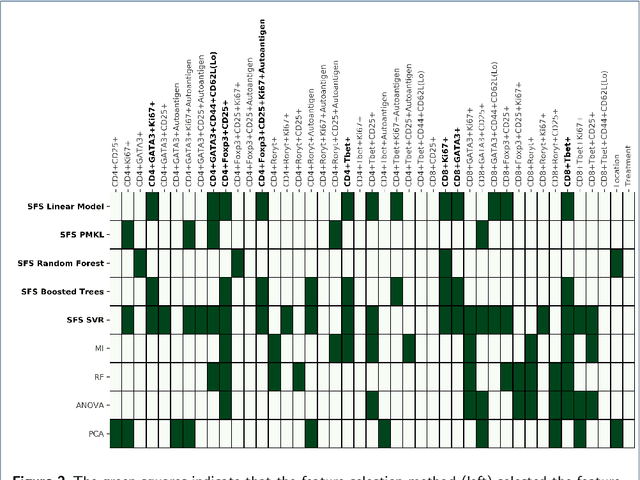
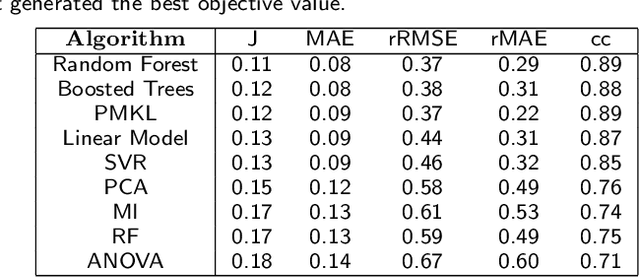
The immune response is a dynamic process by which the body determines whether an antigen is self or nonself. The state of this dynamic process is defined by the relative balance and population of inflammatory and regulatory actors which comprise this decision making process. The goal of immunotherapy as applied to, e.g. Rheumatoid Arthritis (RA), then, is to bias the immune state in favor of the regulatory actors - thereby shutting down autoimmune pathways in the response. While there are several known approaches to immunotherapy, the effectiveness of the therapy will depend on how this intervention alters the evolution of this state. Unfortunately, this process is determined not only by the dynamics of the process, but the state of the system at the time of intervention - a state which is difficult if not impossible to determine prior to application of the therapy.
Real-time multimodal image registration with partial intraoperative point-set data
Sep 20, 2021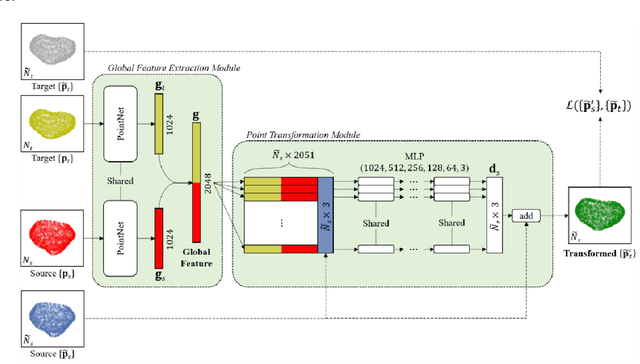


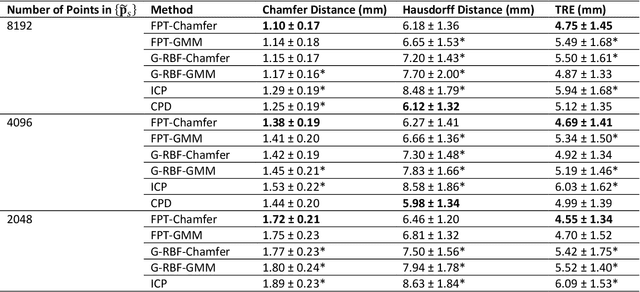
We present Free Point Transformer (FPT) - a deep neural network architecture for non-rigid point-set registration. Consisting of two modules, a global feature extraction module and a point transformation module, FPT does not assume explicit constraints based on point vicinity, thereby overcoming a common requirement of previous learning-based point-set registration methods. FPT is designed to accept unordered and unstructured point-sets with a variable number of points and uses a "model-free" approach without heuristic constraints. Training FPT is flexible and involves minimizing an intuitive unsupervised loss function, but supervised, semi-supervised, and partially- or weakly-supervised training are also supported. This flexibility makes FPT amenable to multimodal image registration problems where the ground-truth deformations are difficult or impossible to measure. In this paper, we demonstrate the application of FPT to non-rigid registration of prostate magnetic resonance (MR) imaging and sparsely-sampled transrectal ultrasound (TRUS) images. The registration errors were 4.71 mm and 4.81 mm for complete TRUS imaging and sparsely-sampled TRUS imaging, respectively. The results indicate superior accuracy to the alternative rigid and non-rigid registration algorithms tested and substantially lower computation time. The rapid inference possible with FPT makes it particularly suitable for applications where real-time registration is beneficial.
Efficient One Pass Self-distillation with Zipf's Label Smoothing
Jul 26, 2022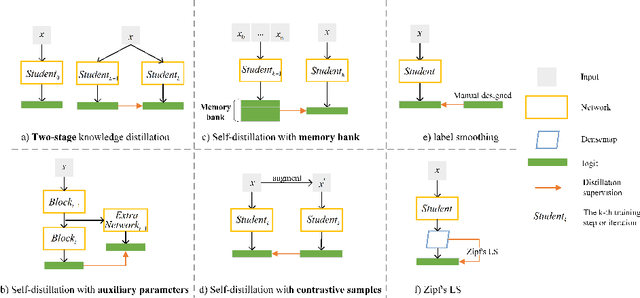
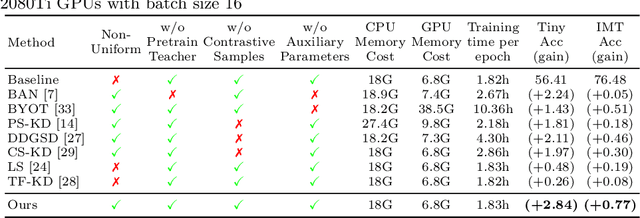
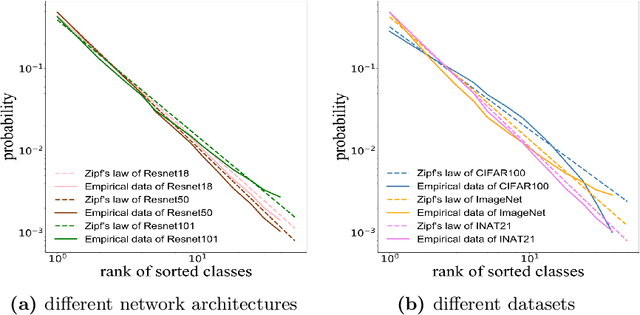
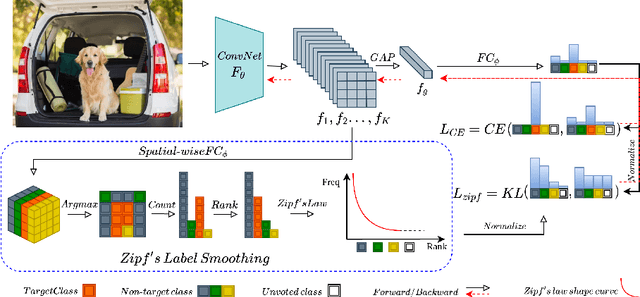
Self-distillation exploits non-uniform soft supervision from itself during training and improves performance without any runtime cost. However, the overhead during training is often overlooked, and yet reducing time and memory overhead during training is increasingly important in the giant models' era. This paper proposes an efficient self-distillation method named Zipf's Label Smoothing (Zipf's LS), which uses the on-the-fly prediction of a network to generate soft supervision that conforms to Zipf distribution without using any contrastive samples or auxiliary parameters. Our idea comes from an empirical observation that when the network is duly trained the output values of a network's final softmax layer, after sorting by the magnitude and averaged across samples, should follow a distribution reminiscent to Zipf's Law in the word frequency statistics of natural languages. By enforcing this property on the sample level and throughout the whole training period, we find that the prediction accuracy can be greatly improved. Using ResNet50 on the INAT21 fine-grained classification dataset, our technique achieves +3.61% accuracy gain compared to the vanilla baseline, and 0.88% more gain against the previous label smoothing or self-distillation strategies. The implementation is publicly available at https://github.com/megvii-research/zipfls.
Hardware-aware Real-time Myocardial Segmentation Quality Control in Contrast Echocardiography
Sep 14, 2021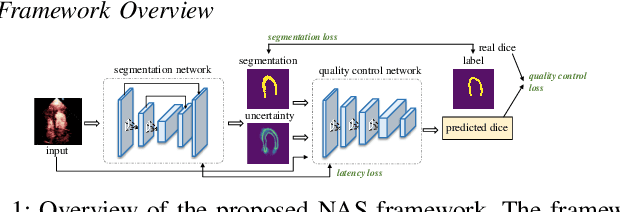
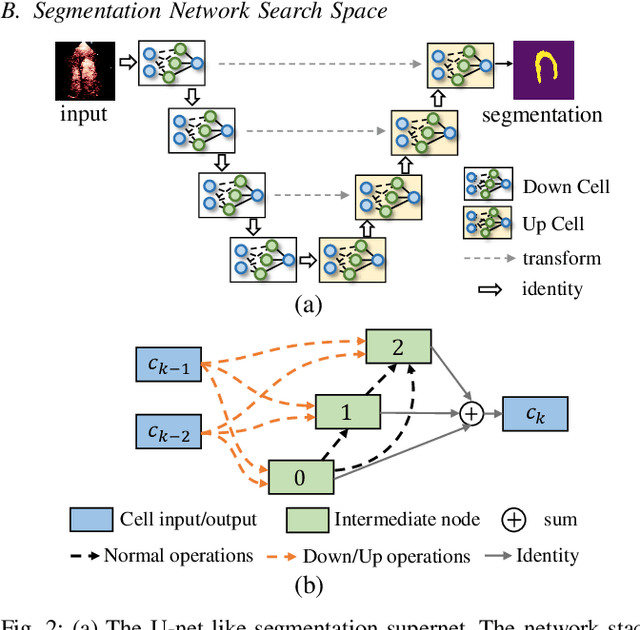
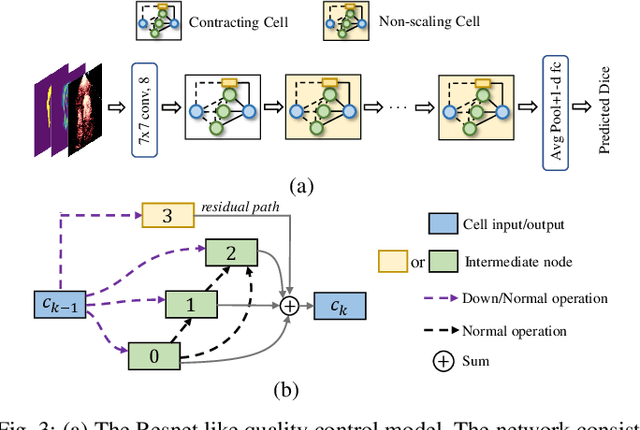
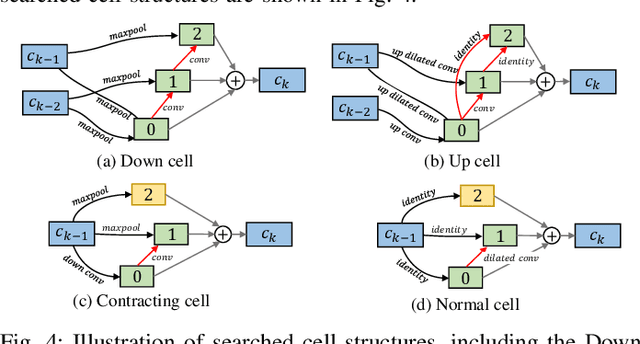
Automatic myocardial segmentation of contrast echocardiography has shown great potential in the quantification of myocardial perfusion parameters. Segmentation quality control is an important step to ensure the accuracy of segmentation results for quality research as well as its clinical application. Usually, the segmentation quality control happens after the data acquisition. At the data acquisition time, the operator could not know the quality of the segmentation results. On-the-fly segmentation quality control could help the operator to adjust the ultrasound probe or retake data if the quality is unsatisfied, which can greatly reduce the effort of time-consuming manual correction. However, it is infeasible to deploy state-of-the-art DNN-based models because the segmentation module and quality control module must fit in the limited hardware resource on the ultrasound machine while satisfying strict latency constraints. In this paper, we propose a hardware-aware neural architecture search framework for automatic myocardial segmentation and quality control of contrast echocardiography. We explicitly incorporate the hardware latency as a regularization term into the loss function during training. The proposed method searches the best neural network architecture for the segmentation module and quality prediction module with strict latency.
How to Spend Your Robot Time: Bridging Kickstarting and Offline Reinforcement Learning for Vision-based Robotic Manipulation
May 06, 2022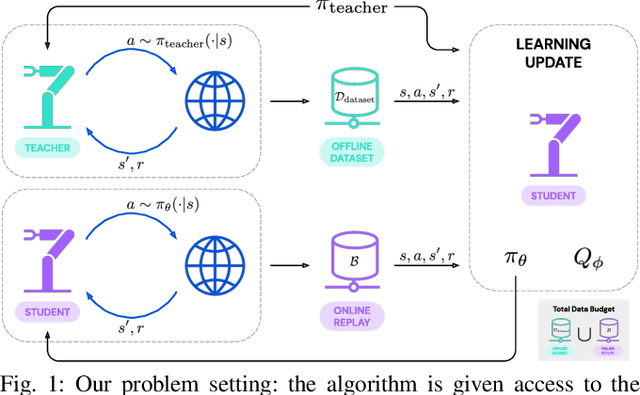

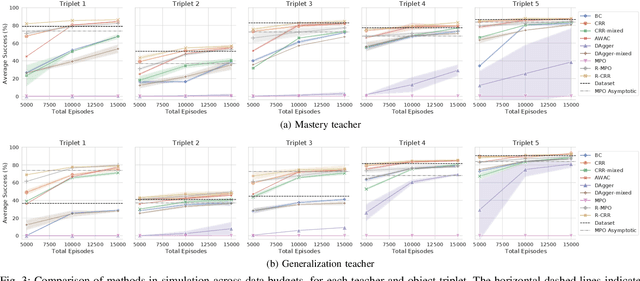
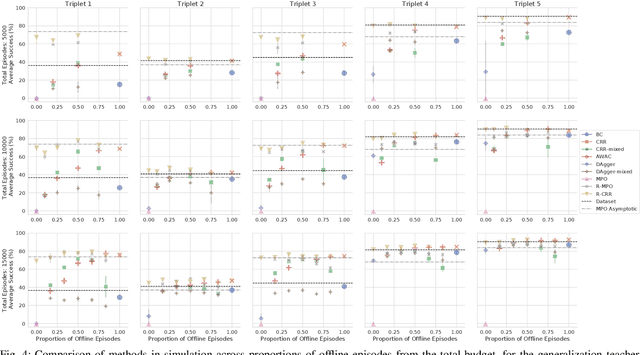
Reinforcement learning (RL) has been shown to be effective at learning control from experience. However, RL typically requires a large amount of online interaction with the environment. This limits its applicability to real-world settings, such as in robotics, where such interaction is expensive. In this work we investigate ways to minimize online interactions in a target task, by reusing a suboptimal policy we might have access to, for example from training on related prior tasks, or in simulation. To this end, we develop two RL algorithms that can speed up training by using not only the action distributions of teacher policies, but also data collected by such policies on the task at hand. We conduct a thorough experimental study of how to use suboptimal teachers on a challenging robotic manipulation benchmark on vision-based stacking with diverse objects. We compare our methods to offline, online, offline-to-online, and kickstarting RL algorithms. By doing so, we find that training on data from both the teacher and student, enables the best performance for limited data budgets. We examine how to best allocate a limited data budget -- on the target task -- between the teacher and the student policy, and report experiments using varying budgets, two teachers with different degrees of suboptimality, and five stacking tasks that require a diverse set of behaviors. Our analysis, both in simulation and in the real world, shows that our approach is the best across data budgets, while standard offline RL from teacher rollouts is surprisingly effective when enough data is given.
Real-Time Gait Phase and Task Estimation for Controlling a Powered Ankle Exoskeleton on Extremely Uneven Terrain
May 06, 2022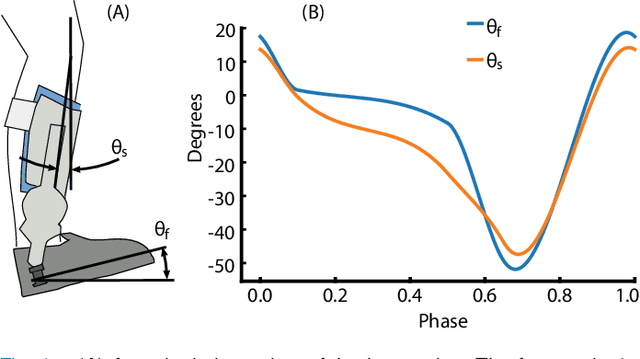
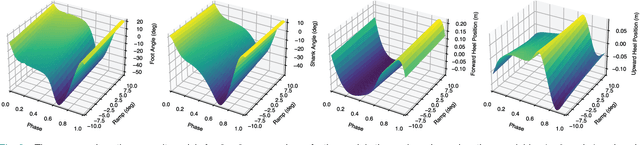
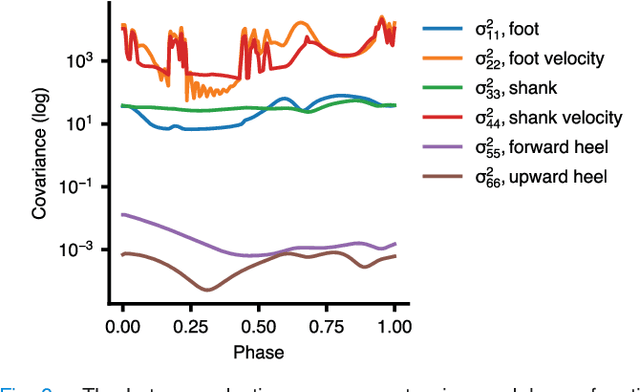
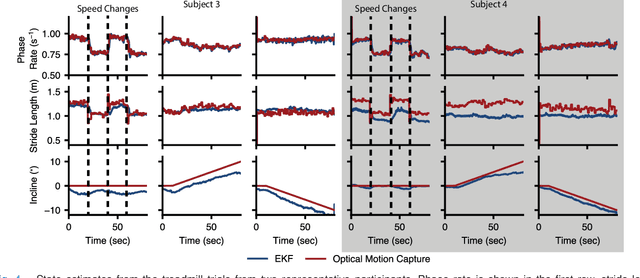
Positive biomechanical outcomes have been reported with lower-limb exoskeletons in laboratory settings, but these devices have difficulty delivering appropriate assistance in synchrony with human gait as the task or rate of phase progression change in real-world environments. This paper presents a torque controller for an ankle exoskeleton that uses state estimation with a data-driven kinematic model to continuously estimate the phase, phase rate, stride length, and ramp parameters during locomotion. The controller applies torque assistance based on the estimated phase and adapts the torque profile based on the estimated task variables to match human torques observed in a multi-activity database of 10 able-bodied subjects. We demonstrate in silico that the controller yields phase estimates that are more accurate than state of the art, while also estimating task variables with comparable accuracy to recent machine learning approaches. The controller implemented in an ankle exoskeleton successfully adapts its assistance in response to changing phase and task variables, both during controlled treadmill trials (6 able-bodied subjects) and a real-world stress test with extremely uneven terrain.