 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
The Surface Edge Explorer (SEE): A measurement-direct approach to next best view planning
Jul 27, 2022

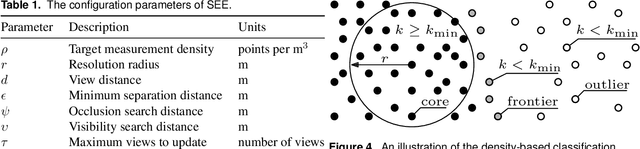

High-quality observations of the real world are crucial for a variety of applications, including producing 3D printed replicas of small-scale scenes and conducting inspections of large-scale infrastructure. These 3D observations are commonly obtained by combining multiple sensor measurements from different views. Guiding the selection of suitable views is known as the Next Best View (NBV) planning problem. Most NBV approaches reason about measurements using rigid data structures (e.g., surface meshes or voxel grids). This simplifies next best view selection but can be computationally expensive, reduces real-world fidelity, and couples the selection of a next best view with the final data processing. This paper presents the Surface Edge Explorer (SEE), a NBV approach that selects new observations directly from previous sensor measurements without requiring rigid data structures. SEE uses measurement density to propose next best views that increase coverage of insufficiently observed surfaces while avoiding potential occlusions. Statistical results from simulated experiments show that SEE can attain better surface coverage in less computational time and sensor travel distance than evaluated volumetric approaches on both small- and large-scale scenes. Real-world experiments demonstrate SEE autonomously observing a deer statue using a 3D sensor affixed to a robotic arm.
Solving the vehicle routing problem with deep reinforcement learning
Jul 30, 2022
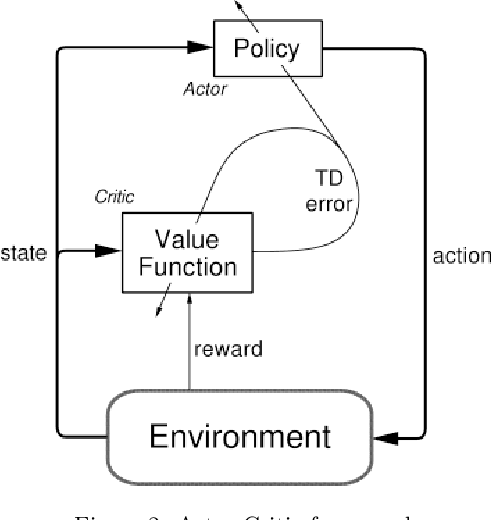
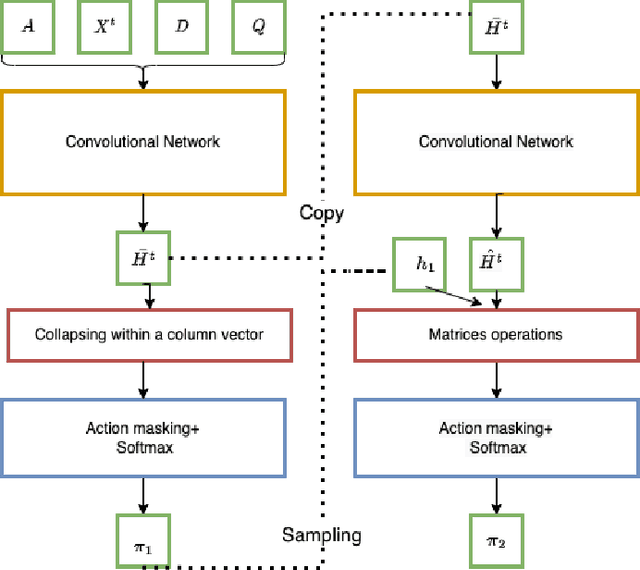
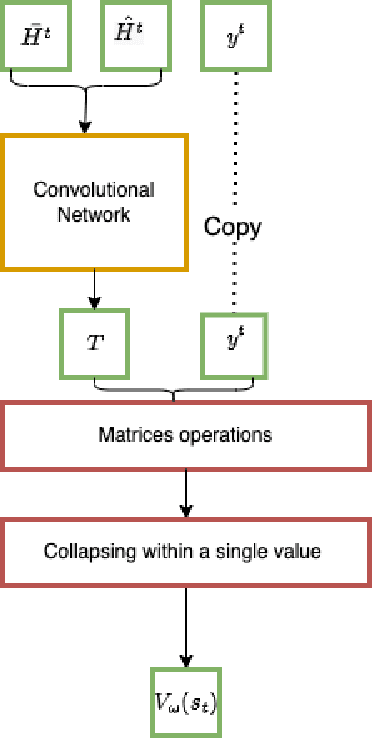
Recently, the applications of the methodologies of Reinforcement Learning (RL) to NP-Hard Combinatorial optimization problems have become a popular topic. This is essentially due to the nature of the traditional combinatorial algorithms, often based on a trial-and-error process. RL aims at automating this process. At this regard, this paper focuses on the application of RL for the Vehicle Routing Problem (VRP), a famous combinatorial problem that belongs to the class of NP-Hard problems. In this work, first, the problem is modeled as a Markov Decision Process (MDP) and then the PPO method (which belongs to the Actor-Critic class of Reinforcement learning methods) is applied. In a second phase, the neural architecture behind the Actor and Critic has been established, choosing to adopt a neural architecture based on the Convolutional neural networks, both for the Actor and the Critic. This choice resulted in effectively addressing problems of different sizes. Experiments performed on a wide range of instances show that the algorithm has good generalization capabilities and can reach good solutions in a short time. Comparisons between the algorithm proposed and the state-of-the-art solver OR-TOOLS show that the latter still outperforms the Reinforcement learning algorithm. However, there are future research perspectives, that aim to upgrade the current performance of the algorithm proposed.
Unsupervised Semantic Segmentation with Self-supervised Object-centric Representations
Jul 11, 2022

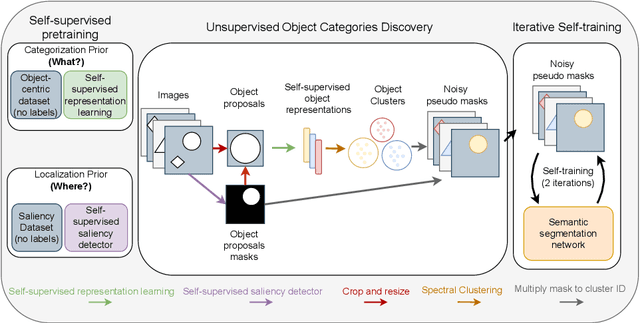
In this paper, we show that recent advances in self-supervised feature learning enable unsupervised object discovery and semantic segmentation with a performance that matches the state of the field on supervised semantic segmentation 10 years ago. We propose a methodology based on unsupervised saliency masks and self-supervised feature clustering to kickstart object discovery followed by training a semantic segmentation network on pseudo-labels to bootstrap the system on images with multiple objects. We present results on PASCAL VOC that go far beyond the current state of the art (47.3 mIoU), and we report for the first time results on MS COCO for the whole set of 81 classes: our method discovers 34 categories with more than $20\%$ IoU, while obtaining an average IoU of 19.6 for all 81 categories.
Towards the Neuroevolution of Low-level Artificial General Intelligence
Jul 27, 2022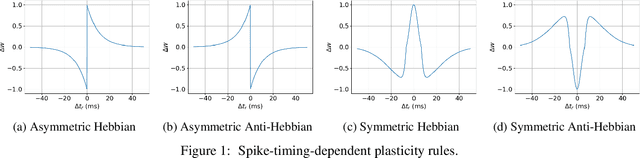
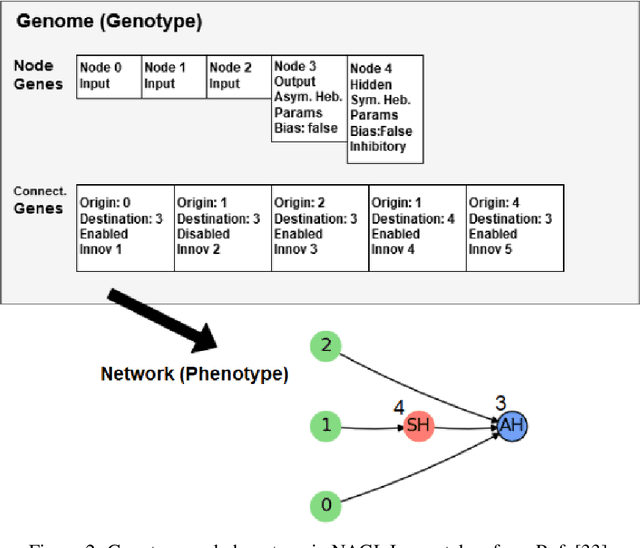
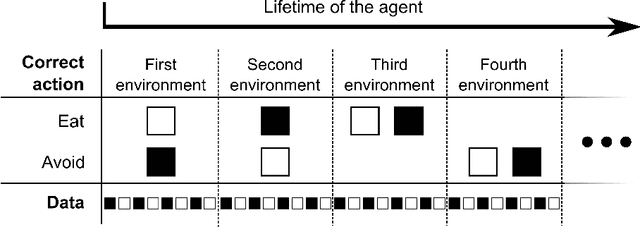
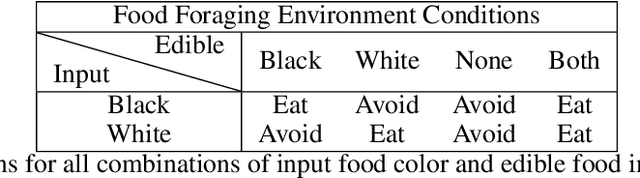
In this work, we argue that the search for Artificial General Intelligence (AGI) should start from a much lower level than human-level intelligence. The circumstances of intelligent behavior in nature resulted from an organism interacting with its surrounding environment, which could change over time and exert pressure on the organism to allow for learning of new behaviors or environment models. Our hypothesis is that learning occurs through interpreting sensory feedback when an agent acts in an environment. For that to happen, a body and a reactive environment are needed. We evaluate a method to evolve a biologically-inspired artificial neural network that learns from environment reactions named Neuroevolution of Artificial General Intelligence (NAGI), a framework for low-level AGI. This method allows the evolutionary complexification of a randomly-initialized spiking neural network with adaptive synapses, which controls agents instantiated in mutable environments. Such a configuration allows us to benchmark the adaptivity and generality of the controllers. The chosen tasks in the mutable environments are food foraging, emulation of logic gates, and cart-pole balancing. The three tasks are successfully solved with rather small network topologies and therefore it opens up the possibility of experimenting with more complex tasks and scenarios where curriculum learning is beneficial.
An Accurate and Explainable Deep Learning System Improves Interobserver Agreement in the Interpretation of Chest Radiograph
Aug 06, 2022Recent artificial intelligence (AI) algorithms have achieved radiologist-level performance on various medical classification tasks. However, only a few studies addressed the localization of abnormal findings from CXR scans, which is essential in explaining the image-level classification to radiologists. We introduce in this paper an explainable deep learning system called VinDr-CXR that can classify a CXR scan into multiple thoracic diseases and, at the same time, localize most types of critical findings on the image. VinDr-CXR was trained on 51,485 CXR scans with radiologist-provided bounding box annotations. It demonstrated a comparable performance to experienced radiologists in classifying 6 common thoracic diseases on a retrospective validation set of 3,000 CXR scans, with a mean area under the receiver operating characteristic curve (AUROC) of 0.967 (95% confidence interval [CI]: 0.958-0.975). The VinDr-CXR was also externally validated in independent patient cohorts and showed its robustness. For the localization task with 14 types of lesions, our free-response receiver operating characteristic (FROC) analysis showed that the VinDr-CXR achieved a sensitivity of 80.2% at the rate of 1.0 false-positive lesion identified per scan. A prospective study was also conducted to measure the clinical impact of the VinDr-CXR in assisting six experienced radiologists. The results indicated that the proposed system, when used as a diagnosis supporting tool, significantly improved the agreement between radiologists themselves with an increase of 1.5% in mean Fleiss' Kappa. We also observed that, after the radiologists consulted VinDr-CXR's suggestions, the agreement between each of them and the system was remarkably increased by 3.3% in mean Cohen's Kappa.
Abstracting Sketches through Simple Primitives
Jul 27, 2022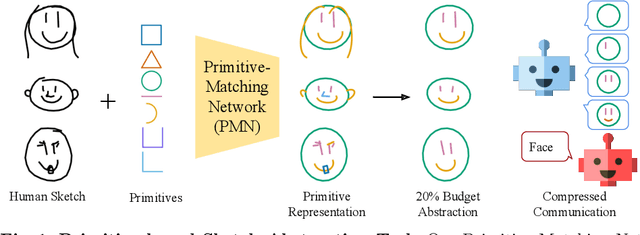
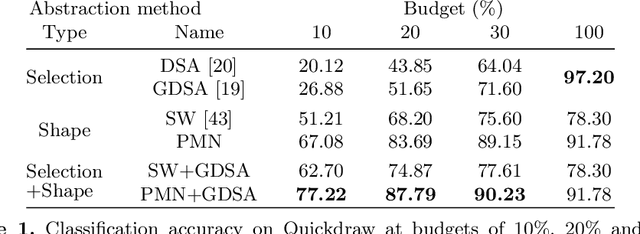

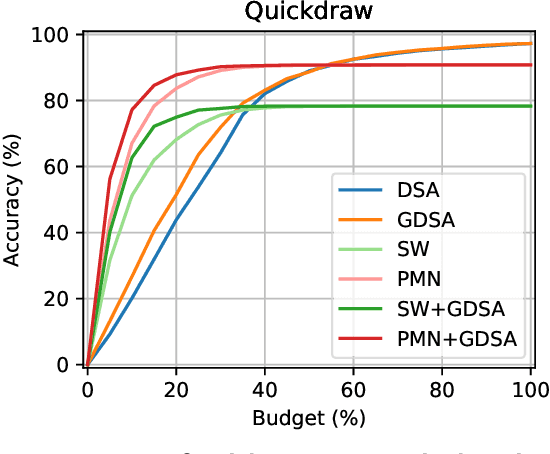
Humans show high-level of abstraction capabilities in games that require quickly communicating object information. They decompose the message content into multiple parts and communicate them in an interpretable protocol. Toward equipping machines with such capabilities, we propose the Primitive-based Sketch Abstraction task where the goal is to represent sketches using a fixed set of drawing primitives under the influence of a budget. To solve this task, our Primitive-Matching Network (PMN), learns interpretable abstractions of a sketch in a self supervised manner. Specifically, PMN maps each stroke of a sketch to its most similar primitive in a given set, predicting an affine transformation that aligns the selected primitive to the target stroke. We learn this stroke-to-primitive mapping end-to-end with a distance-transform loss that is minimal when the original sketch is precisely reconstructed with the predicted primitives. Our PMN abstraction empirically achieves the highest performance on sketch recognition and sketch-based image retrieval given a communication budget, while at the same time being highly interpretable. This opens up new possibilities for sketch analysis, such as comparing sketches by extracting the most relevant primitives that define an object category. Code is available at https://github.com/ExplainableML/sketch-primitives.
WordSig: QR streams enabling platform-independent self-identification that's impossible to deepfake
Jul 15, 2022

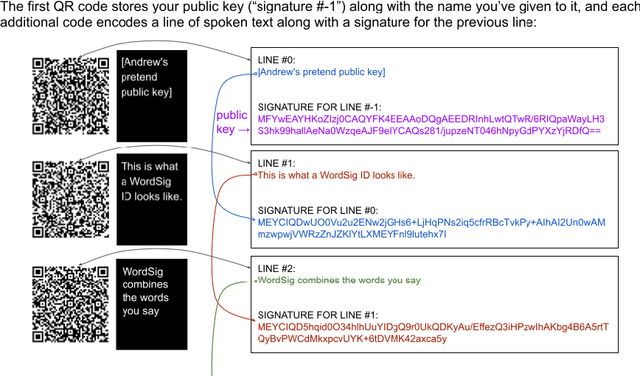
Deepfakes can degrade the fabric of society by limiting our ability to trust video content from leaders, authorities, and even friends. Cryptographically secure digital signatures may be used by video streaming platforms to endorse content, but these signatures are applied by the content distributor rather than the participants in the video. We introduce WordSig, a simple protocol allowing video participants to digitally sign the words they speak using a stream of QR codes, and allowing viewers to verify the consistency of signatures across videos. This allows establishing a trusted connection between the viewer and the participant that is not mediated by the content distributor. Given the widespread adoption of QR codes for distributing hyperlinks and vaccination records, and the increasing prevalence of celebrity deepfakes, 2022 or later may be a good time for public figures to begin using and promoting QR-based self-authentication tools.
Evolutionary Robust Clustering Over Time for Temporal Data
Jun 14, 2021
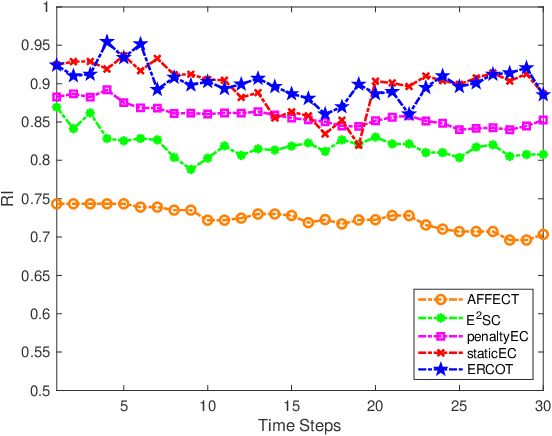


In many clustering scenes, data samples' attribute values change over time. For such data, we are often interested in obtaining a partition for each time step and tracking the dynamic change of partitions. Normally, a smooth change is assumed for data to have a temporal smooth nature. Existing algorithms consider the temporal smoothness as an a priori preference and bias the search towards the preferred direction. This a priori manner leads to a risk of converging to an unexpected region because it is not always the case that a reasonable preference can be elicited given the little prior knowledge about the data. To address this issue, this paper proposes a new clustering framework called evolutionary robust clustering over time. One significant innovation of the proposed framework is processing the temporal smoothness in an a posteriori manner, which avoids unexpected convergence that occurs in existing algorithms. Furthermore, the proposed framework automatically tunes the weight of smoothness without data's affinity matrix and predefined parameters, which holds better applicability and scalability. The effectiveness and efficiency of the proposed framework are confirmed by comparing with state-of-the-art algorithms on both synthetic and real datasets.
A Local Optimization Framework for Multi-Objective Ergodic Search
Jul 06, 2022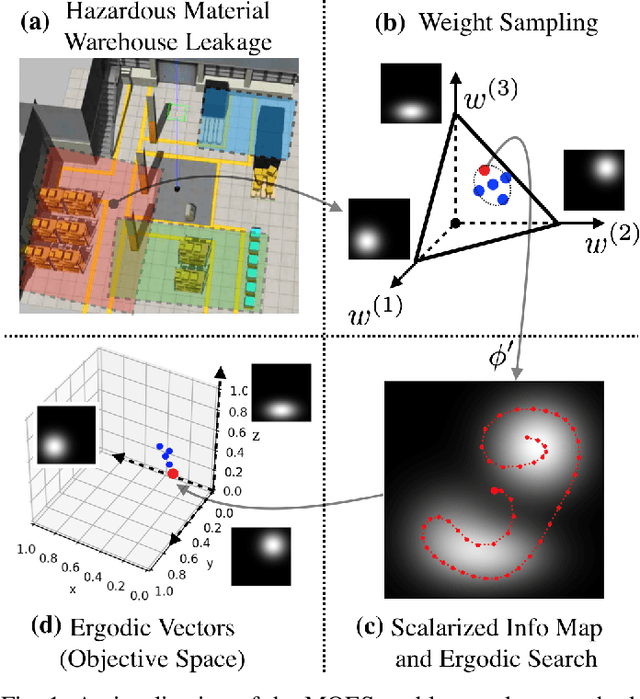
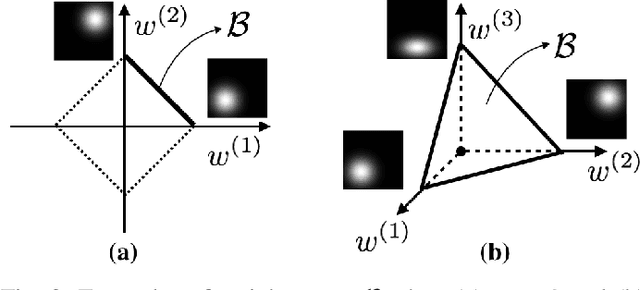
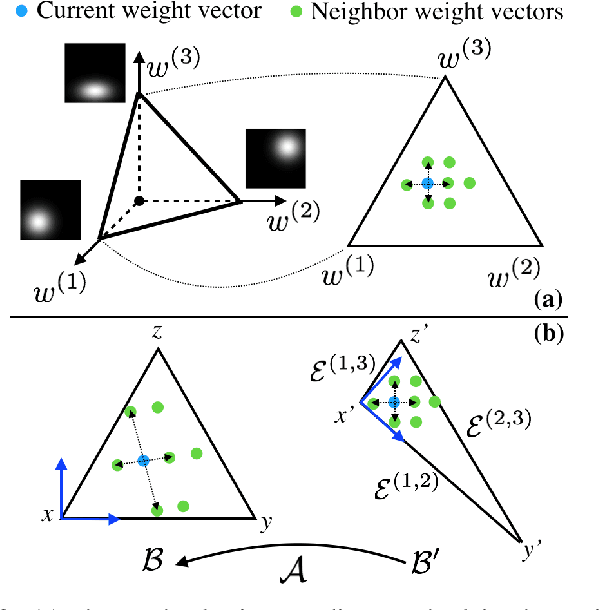
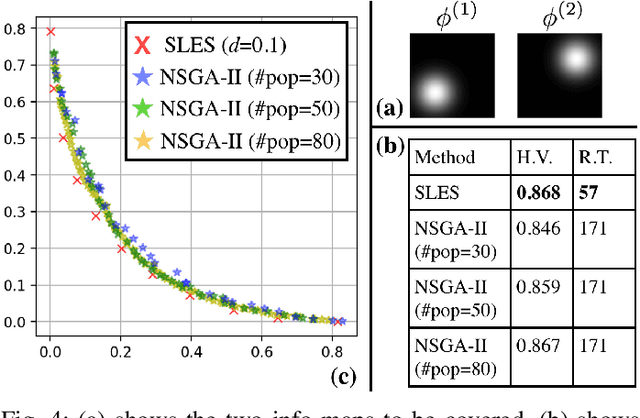
Robots have the potential to perform search for a variety of applications under different scenarios. Our work is motivated by humanitarian assistant and disaster relief (HADR) where often it is critical to find signs of life in the presence of conflicting criteria, objectives, and information. We believe ergodic search can provide a framework for exploiting available information as well as exploring for new information for applications such as HADR, especially when time is of the essence. Ergodic search algorithms plan trajectories such that the time spent in a region is proportional to the amount of information in that region, and is able to naturally balance exploitation (myopically searching high-information areas) and exploration (visiting all locations in the search space for new information). Existing ergodic search algorithms, as well as other information-based approaches, typically consider search using only a single information map. However, in many scenarios, the use of multiple information maps that encode different types of relevant information is common. Ergodic search methods currently do not possess the ability for simultaneous nor do they have a way to balance which information gets priority. This leads us to formulate a Multi-Objective Ergodic Search (MOES) problem, which aims at finding the so-called Pareto-optimal solutions, for the purpose of providing human decision makers various solutions that trade off between conflicting criteria. To efficiently solve MOES, we develop a framework called Sequential Local Ergodic Search (SLES) that converts a MOES problem into a "weight space coverage" problem. It leverages the recent advances in ergodic search methods as well as the idea of local optimization to efficiently approximate the Pareto-optimal front. Our numerical results show that SLES runs distinctly faster than the baseline methods.
MAGIC: Microlensing Analysis Guided by Intelligent Computation
Jun 16, 2022
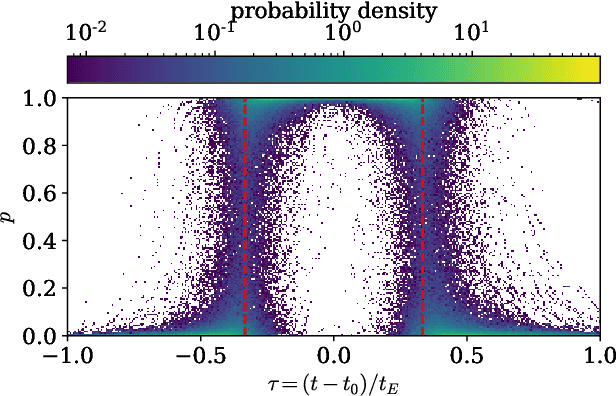

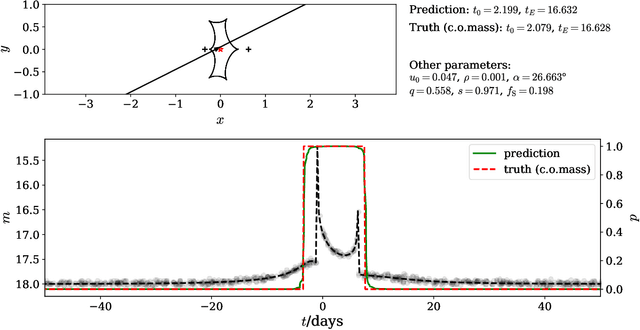
The modeling of binary microlensing light curves via the standard sampling-based method can be challenging, because of the time-consuming light curve computation and the pathological likelihood landscape in the high-dimensional parameter space. In this work, we present MAGIC, which is a machine learning framework to efficiently and accurately infer the microlensing parameters of binary events with realistic data quality. In MAGIC, binary microlensing parameters are divided into two groups and inferred separately with different neural networks. The key feature of MAGIC is the introduction of neural controlled differential equation, which provides the capability to handle light curves with irregular sampling and large data gaps. Based on simulated light curves, we show that MAGIC can achieve fractional uncertainties of a few percent on the binary mass ratio and separation. We also test MAGIC on a real microlensing event. MAGIC is able to locate the degenerate solutions even when large data gaps are introduced. As irregular samplings are common in astronomical surveys, our method also has implications to other studies that involve time series.