 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient Video Deblurring Guided by Motion Magnitude
Jul 27, 2022
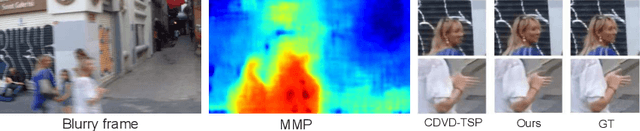

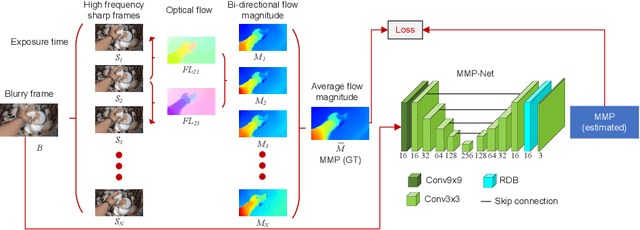
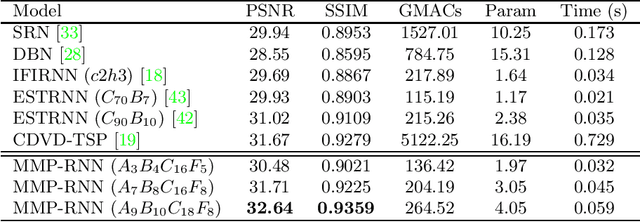
Video deblurring is a highly under-constrained problem due to the spatially and temporally varying blur. An intuitive approach for video deblurring includes two steps: a) detecting the blurry region in the current frame; b) utilizing the information from clear regions in adjacent frames for current frame deblurring. To realize this process, our idea is to detect the pixel-wise blur level of each frame and combine it with video deblurring. To this end, we propose a novel framework that utilizes the motion magnitude prior (MMP) as guidance for efficient deep video deblurring. Specifically, as the pixel movement along its trajectory during the exposure time is positively correlated to the level of motion blur, we first use the average magnitude of optical flow from the high-frequency sharp frames to generate the synthetic blurry frames and their corresponding pixel-wise motion magnitude maps. We then build a dataset including the blurry frame and MMP pairs. The MMP is then learned by a compact CNN by regression. The MMP consists of both spatial and temporal blur level information, which can be further integrated into an efficient recurrent neural network (RNN) for video deblurring. We conduct intensive experiments to validate the effectiveness of the proposed methods on the public datasets.
Region Aware Video Object Segmentation with Deep Motion Modeling
Jul 21, 2022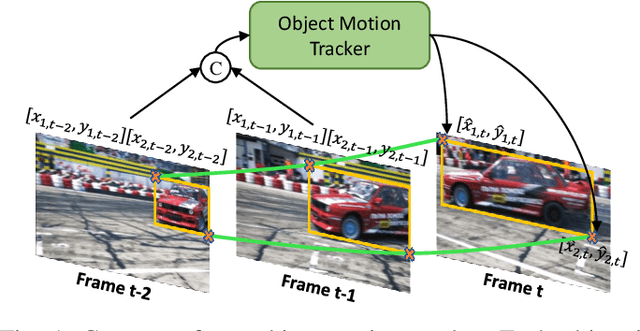
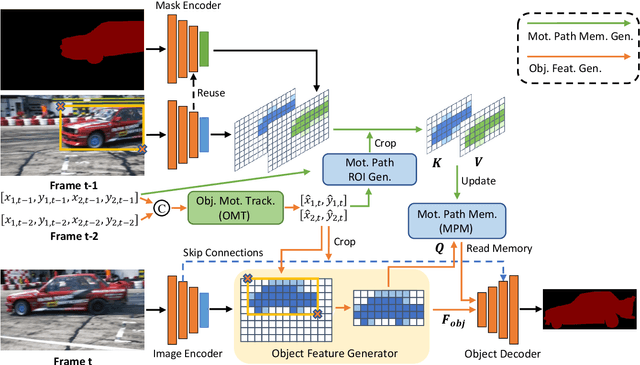

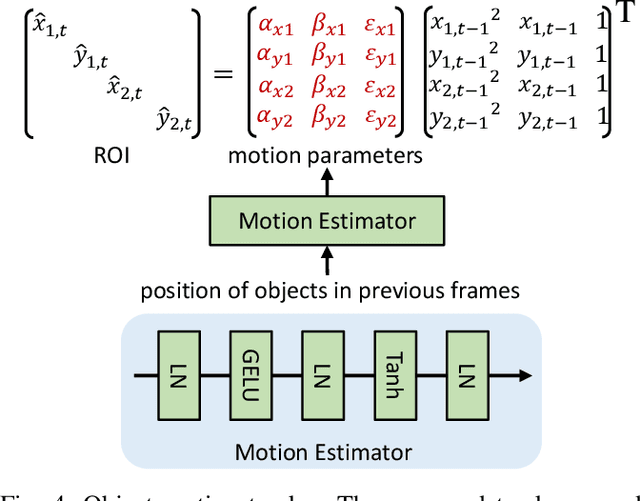
Current semi-supervised video object segmentation (VOS) methods usually leverage the entire features of one frame to predict object masks and update memory. This introduces significant redundant computations. To reduce redundancy, we present a Region Aware Video Object Segmentation (RAVOS) approach that predicts regions of interest (ROIs) for efficient object segmentation and memory storage. RAVOS includes a fast object motion tracker to predict their ROIs in the next frame. For efficient segmentation, object features are extracted according to the ROIs, and an object decoder is designed for object-level segmentation. For efficient memory storage, we propose motion path memory to filter out redundant context by memorizing the features within the motion path of objects between two frames. Besides RAVOS, we also propose a large-scale dataset, dubbed OVOS, to benchmark the performance of VOS models under occlusions. Evaluation on DAVIS and YouTube-VOS benchmarks and our new OVOS dataset show that our method achieves state-of-the-art performance with significantly faster inference time, e.g., 86.1 J&F at 42 FPS on DAVIS and 84.4 J&F at 23 FPS on YouTube-VOS.
Traffic Sign Detection With Event Cameras and DCNN
Jul 27, 2022



In recent years, event cameras (DVS - Dynamic Vision Sensors) have been used in vision systems as an alternative or supplement to traditional cameras. They are characterised by high dynamic range, high temporal resolution, low latency, and reliable performance in limited lighting conditions -- parameters that are particularly important in the context of advanced driver assistance systems (ADAS) and self-driving cars. In this work, we test whether these rather novel sensors can be applied to the popular task of traffic sign detection. To this end, we analyse different representations of the event data: event frame, event frequency, and the exponentially decaying time surface, and apply video frame reconstruction using a deep neural network called FireNet. We use the deep convolutional neural network YOLOv4 as a detector. For particular representations, we obtain a detection accuracy in the range of 86.9-88.9% mAP@0.5. The use of a fusion of the considered representations allows us to obtain a detector with higher accuracy of 89.9% mAP@0.5. In comparison, the detector for the frames reconstructed with FireNet is characterised by an accuracy of 72.67% mAP@0.5. The results obtained illustrate the potential of event cameras in automotive applications, either as standalone sensors or in close cooperation with typical frame-based cameras.
A Local Optimization Framework for Multi-Objective Ergodic Search
Jul 06, 2022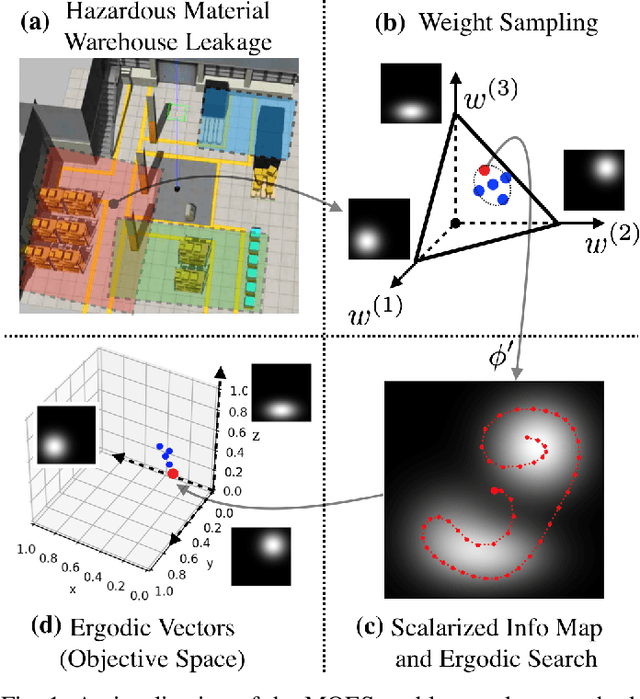
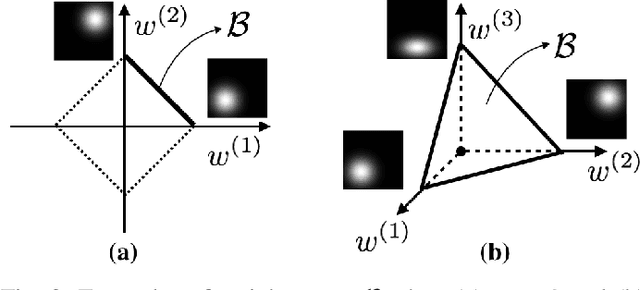
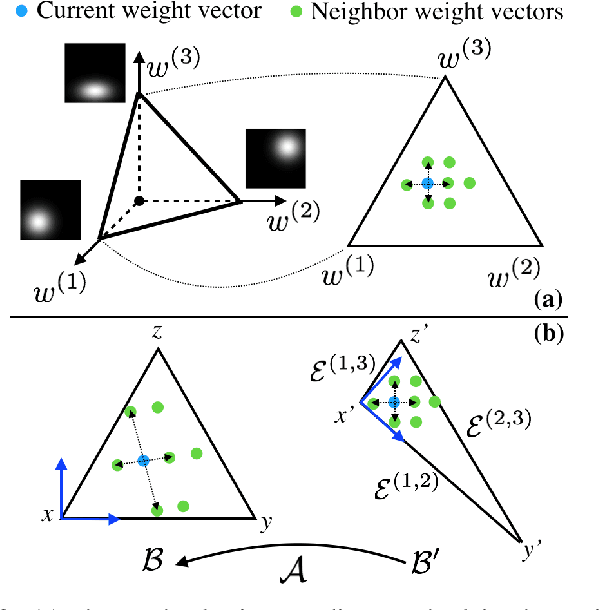
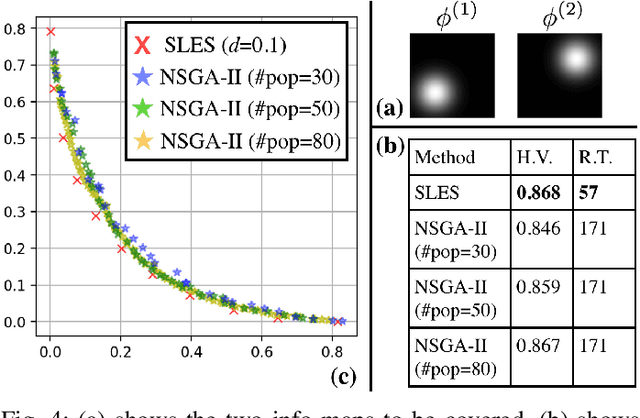
Robots have the potential to perform search for a variety of applications under different scenarios. Our work is motivated by humanitarian assistant and disaster relief (HADR) where often it is critical to find signs of life in the presence of conflicting criteria, objectives, and information. We believe ergodic search can provide a framework for exploiting available information as well as exploring for new information for applications such as HADR, especially when time is of the essence. Ergodic search algorithms plan trajectories such that the time spent in a region is proportional to the amount of information in that region, and is able to naturally balance exploitation (myopically searching high-information areas) and exploration (visiting all locations in the search space for new information). Existing ergodic search algorithms, as well as other information-based approaches, typically consider search using only a single information map. However, in many scenarios, the use of multiple information maps that encode different types of relevant information is common. Ergodic search methods currently do not possess the ability for simultaneous nor do they have a way to balance which information gets priority. This leads us to formulate a Multi-Objective Ergodic Search (MOES) problem, which aims at finding the so-called Pareto-optimal solutions, for the purpose of providing human decision makers various solutions that trade off between conflicting criteria. To efficiently solve MOES, we develop a framework called Sequential Local Ergodic Search (SLES) that converts a MOES problem into a "weight space coverage" problem. It leverages the recent advances in ergodic search methods as well as the idea of local optimization to efficiently approximate the Pareto-optimal front. Our numerical results show that SLES runs distinctly faster than the baseline methods.
Probabilistic forecasts of extreme heatwaves using convolutional neural networks in a regime of lack of data
Aug 01, 2022
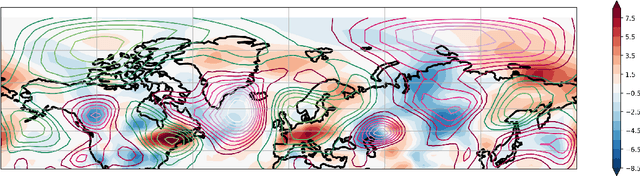
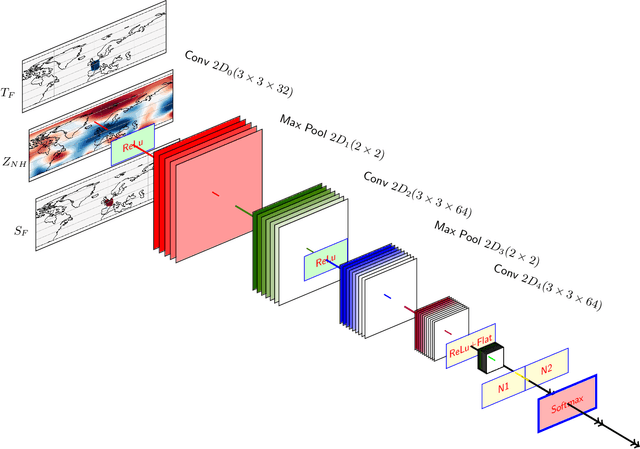
Understanding extreme events and their probability is key for the study of climate change impacts, risk assessment, adaptation, and the protection of living beings. In this work we develop a methodology to build forecasting models for extreme heatwaves. These models are based on convolutional neural networks, trained on extremely long 8,000-year climate model outputs. Because the relation between extreme events is intrinsically probabilistic, we emphasise probabilistic forecast and validation. We demonstrate that deep neural networks are suitable for this purpose for long lasting 14-day heatwaves over France, up to 15 days ahead of time for fast dynamical drivers (500 hPa geopotential height fields), and also at much longer lead times for slow physical drivers (soil moisture). The method is easily implemented and versatile. We find that the deep neural network selects extreme heatwaves associated with a North-Hemisphere wavenumber-3 pattern. We find that the 2 meter temperature field does not contain any new useful statistical information for heatwave forecast, when added to the 500 hPa geopotential height and soil moisture fields. The main scientific message is that training deep neural networks for predicting extreme heatwaves occurs in a regime of drastic lack of data. We suggest that this is likely the case for most other applications to large scale atmosphere and climate phenomena. We discuss perspectives for dealing with the lack of data regime, for instance rare event simulations, and how transfer learning may play a role in this latter task.
NeuralBlox: Real-Time Neural Representation Fusion for Robust Volumetric Mapping
Oct 18, 2021
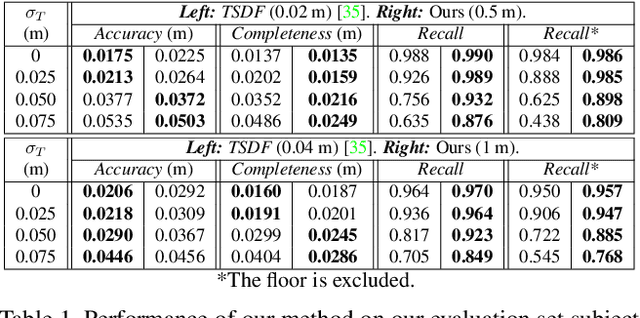
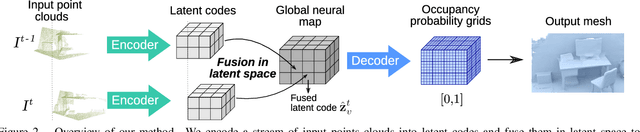

We present a novel 3D mapping method leveraging the recent progress in neural implicit representation for 3D reconstruction. Most existing state-of-the-art neural implicit representation methods are limited to object-level reconstructions and can not incrementally perform updates given new data. In this work, we propose a fusion strategy and training pipeline to incrementally build and update neural implicit representations that enable the reconstruction of large scenes from sequential partial observations. By representing an arbitrarily sized scene as a grid of latent codes and performing updates directly in latent space, we show that incrementally built occupancy maps can be obtained in real-time even on a CPU. Compared to traditional approaches such as Truncated Signed Distance Fields (TSDFs), our map representation is significantly more robust in yielding a better scene completeness given noisy inputs. We demonstrate the performance of our approach in thorough experimental validation on real-world datasets with varying degrees of added pose noise.
Modeling Associative Plasticity between Synapses to Enhance Learning of Spiking Neural Networks
Jul 24, 2022
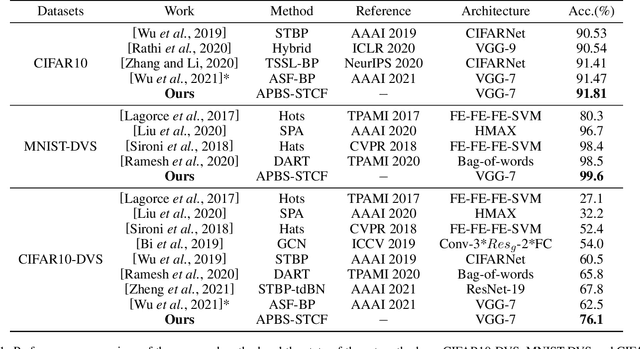
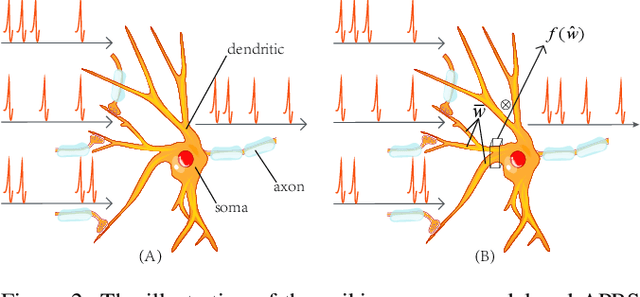
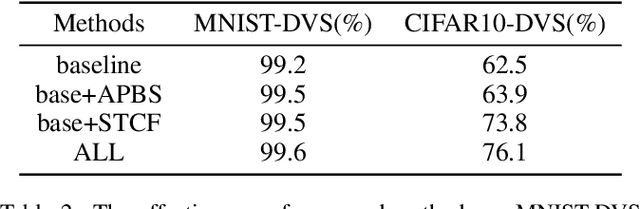
Spiking Neural Networks (SNNs) are the third generation of artificial neural networks that enable energy-efficient implementation on neuromorphic hardware. However, the discrete transmission of spikes brings significant challenges to the robust and high-performance learning mechanism. Most existing works focus solely on learning between neurons but ignore the influence between synapses, resulting in a loss of robustness and accuracy. To address this problem, we propose a robust and effective learning mechanism by modeling the associative plasticity between synapses (APBS) observed from the physiological phenomenon of associative long-term potentiation (ALTP). With the proposed APBS method, synapses of the same neuron interact through a shared factor when concurrently stimulated by other neurons. In addition, we propose a spatiotemporal cropping and flipping (STCF) method to improve the generalization ability of our network. Extensive experiments demonstrate that our approaches achieve superior performance on static CIFAR-10 datasets and state-of-the-art performance on neuromorphic MNIST-DVS, CIFAR10-DVS datasets by a lightweight convolution network. To our best knowledge, this is the first time to explore a learning method between synapses and an extended approach for neuromorphic data.
Efficient Distance-Optimal Tethered Path Planning in Planar Environments: The Workspace Convexity
Aug 08, 2022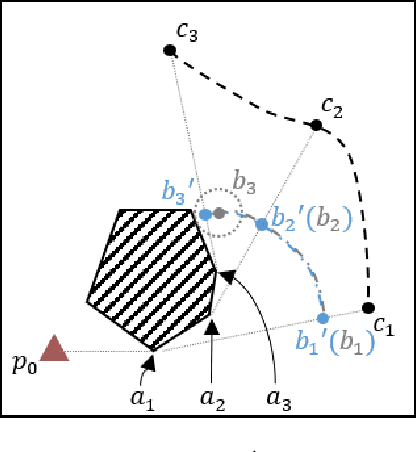
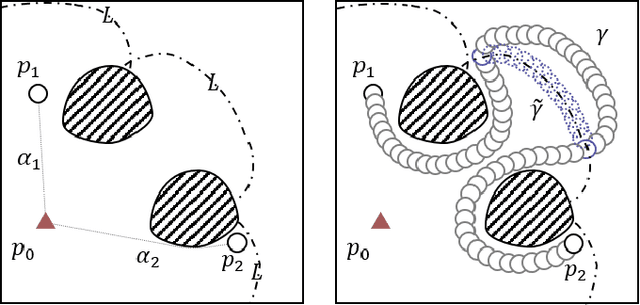
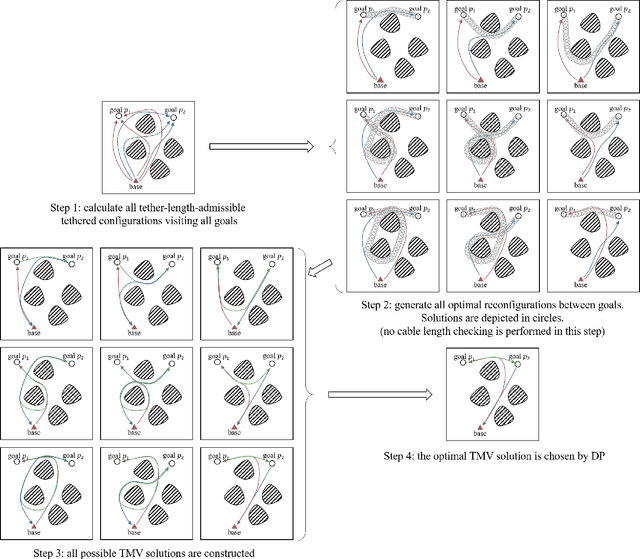
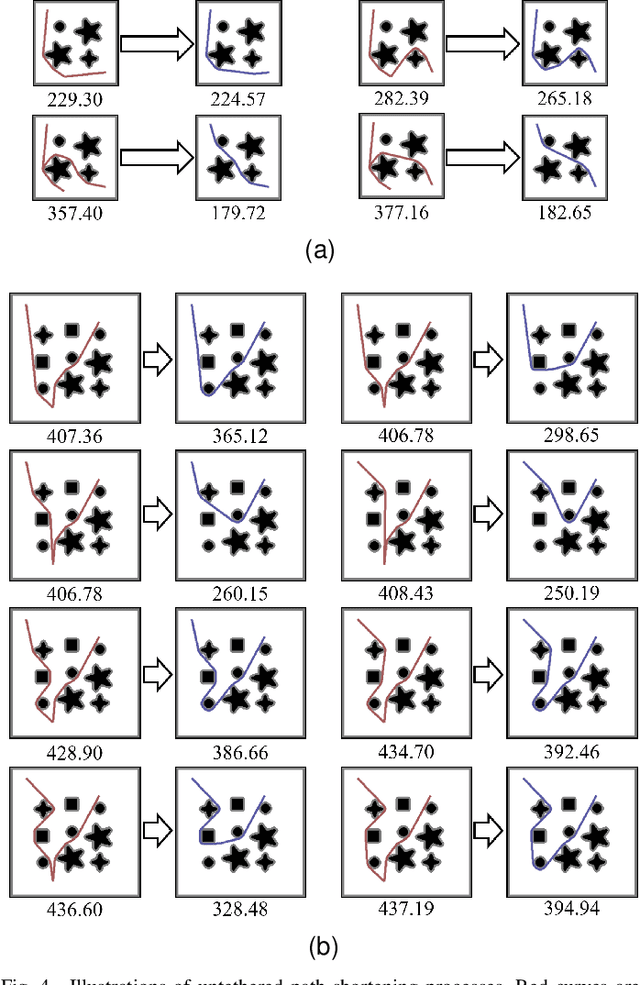
The main contribution of this paper is the proof of the convexity of the omni-directional tethered robot workspace (namely, the set of all tether-length-admissible robot configurations), as well as a set of distance-optimal tethered path planning algorithms that leverage the workspace convexity. The workspace is proven to be topologically a simply-connected subset and geometrically a convex subset of the set of all configurations. As a direct result, the tether-length-admissible optimal path between two configurations is proven exactly the untethered collision-free locally shortest path in the homotopy specified by the concatenation of the tether curve of the given configurations, which can be simply constructed by performing an untethered path shortening process in the 2D environment instead of a path searching process in the pre-calculated workspace. The convexity is an intrinsic property to the tethered robot kinematics, thus has universal impacts on all high-level distance-optimal tethered path planning tasks: The most time-consuming workspace pre-calculation (WP) process is replaced with a goal configuration pre-calculation (GCP) process, and the homotopy-aware path searching process is replaced with untethered path shortening processes. Motivated by the workspace convexity, efficient algorithms to solve the following problems are naturally proposed: (a) The optimal tethered reconfiguration (TR) planning problem is solved by a locally untethered path shortening (UPS) process, (b) The classic optimal tethered path (TP) planning problem (from a starting configuration to a goal location whereby the target tether state is not assigned) is solved by a GCP process and $n$ UPS processes, where $n$ is the number of tether-length-admissible configurations that visit the goal location, (c) The optimal tethered motion to visit a sequence of multiple goal locations, referred to as
Finite-time System Identification and Adaptive Control in Autoregressive Exogenous Systems
Aug 26, 2021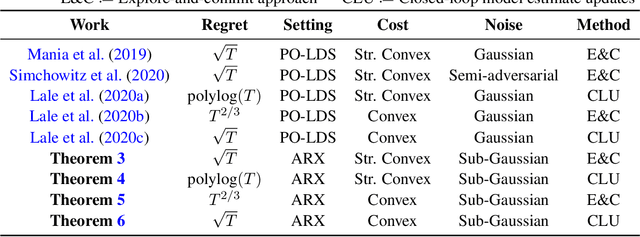
Autoregressive exogenous (ARX) systems are the general class of input-output dynamical systems used for modeling stochastic linear dynamical systems (LDS) including partially observable LDS such as LQG systems. In this work, we study the problem of system identification and adaptive control of unknown ARX systems. We provide finite-time learning guarantees for the ARX systems under both open-loop and closed-loop data collection. Using these guarantees, we design adaptive control algorithms for unknown ARX systems with arbitrary strongly convex or convex quadratic regulating costs. Under strongly convex cost functions, we design an adaptive control algorithm based on online gradient descent to design and update the controllers that are constructed via a convex controller reparametrization. We show that our algorithm has $\tilde{\mathcal{O}}(\sqrt{T})$ regret via explore and commit approach and if the model estimates are updated in epochs using closed-loop data collection, it attains the optimal regret of $\text{polylog}(T)$ after $T$ time-steps of interaction. For the case of convex quadratic cost functions, we propose an adaptive control algorithm that deploys the optimism in the face of uncertainty principle to design the controller. In this setting, we show that the explore and commit approach has a regret upper bound of $\tilde{\mathcal{O}}(T^{2/3})$, and the adaptive control with continuous model estimate updates attains $\tilde{\mathcal{O}}(\sqrt{T})$ regret after $T$ time-steps.
Hyperbolic Temporal Knowledge Graph Embeddings with Relational and Time Curvatures
Jun 08, 2021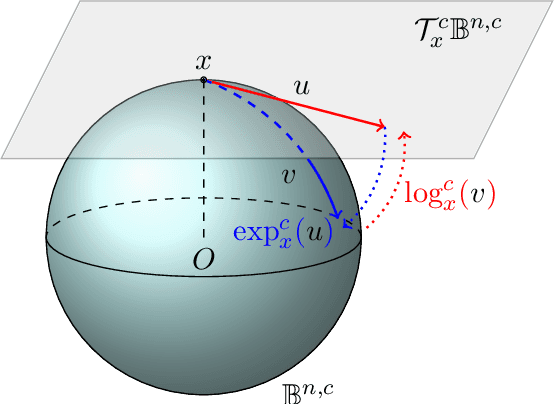


Knowledge Graph (KG) completion has been excessively studied with a massive number of models proposed for the Link Prediction (LP) task. The main limitation of such models is their insensitivity to time. Indeed, the temporal aspect of stored facts is often ignored. To this end, more and more works consider time as a parameter to complete KGs. In this paper, we first demonstrate that, by simply increasing the number of negative samples, the recent AttH model can achieve competitive or even better performance than the state-of-the-art on Temporal KGs (TKGs), albeit its nontemporality. We further propose Hercules, a time-aware extension of AttH model, which defines the curvature of a Riemannian manifold as the product of both relation and time. Our experiments show that both Hercules and AttH achieve competitive or new state-of-the-art performances on ICEWS04 and ICEWS05-15 datasets. Therefore, one should raise awareness when learning TKGs representations to identify whether time truly boosts performances.